SnowConvert: Transact DMLs¶
Between¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Quellcode
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcBetween
AS
BEGIN
declare @aValue int = 1;
IF(@aValue BETWEEN 1 AND 2)
return 1
END;
GO
Erwarteter Code
CREATE OR REPLACE PROCEDURE ProcBetween ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let AVALUE = 1;
if (SELECT(` ? BETWEEN 1 AND 2`,[AVALUE])) {
return 1;
}
$$;
Bekannte Probleme ¶
Es wurden keine Probleme gefunden.
Bulk Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Die direkte Übersetzung für BULK INSERT ist die Snowflake COPY INTO-Anweisung. COPY INTO verwendet nicht direkt den Dateipfad, um die Werte abzurufen. Die Datei sollte vorher in einer STAGE vorhanden sein. Auch die in BULK INSERT verwendeten Optionen sollten in einem Snowflake FILE FORMAT angegeben werden, das von STAGE oder direkt von COPY INTO verwendet wird.
Um eine Datei zu STAGE hinzuzufügen, sollten Sie den Befehl PUT verwenden. Beachten Sie, dass der Befehl nur von der Datei SnowSQL CLI ausgeführt werden kann. Hier ist ein Beispiel für die Schritte, die wir vor der Ausführung von COPY INTO durchführen sollten:
-- Additional Params: -t JavaScript
CREATE PROCEDURE PROCEDURE_SAMPLE
AS
CREATE TABLE #temptable
([col1] varchar(100),
[col2] int,
[col3] varchar(100))
BULK INSERT #temptable FROM 'C:\test.txt'
WITH
(
FIELDTERMINATOR ='\t',
ROWTERMINATOR ='\n'
);
GO
CREATE OR REPLACE FILE FORMAT FILE_FORMAT_638434968243607970
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n';
CREATE OR REPLACE STAGE STAGE_638434968243607970
FILE_FORMAT = FILE_FORMAT_638434968243607970;
--** SSC-FDM-TS0004 - PUT STATEMENT IS NOT SUPPORTED ON WEB UI. YOU SHOULD EXECUTE THE CODE THROUGH THE SNOWFLAKE CLI **
PUT file://C:\test.txt @STAGE_638434968243607970 AUTO_COMPRESS = FALSE;
CREATE OR REPLACE PROCEDURE PROCEDURE_SAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
EXEC(`CREATE OR REPLACE TEMPORARY TABLE T_temptable
(
col1 VARCHAR(100),
col2 INT,
col3 VARCHAR(100))`);
EXEC(`COPY INTO T_temptable FROM @STAGE_638434968243607970/test.txt`);
$$
Wie Sie im obigen Code sehen, identifiziert SnowConvert alle BULK INSERTS im Code, und für jede Instanz wird ein neues STAGE und FILE FORMAT erstellt, bevor die Kopie zur Ausführung kommt. Darüber hinaus wird nach der Erstellung von STAGE auch ein PUT-Befehl erstellt, um die Datei dem Stagingbereich hinzuzufügen.
Die Namen der generierten Anweisungen werden automatisch anhand des aktuellen Zeitstempels in Sekunden generiert, um Kollisionen zwischen ihren Verwendungen zu vermeiden.
Schließlich werden alle Optionen für die Masseneinfügung, sofern zutreffend, den Dateiformatoptionen zugeordnet. Wenn die Option in Snowflake nicht unterstützt wird, wird sie kommentiert und eine Warnung hinzugefügt. Siehe auch [SSC-FDM-TS0004](../../general/technical-documentation/issues-and-troubleshooting/functional-difference/sqlServerFDM. md#ssc-fdm-ts0004).
Unterstützte Bulk-Optionen¶
SQL Server |
Snowflake |
|---|---|
FORMAT |
TYPE |
FIELDTERMINATOR |
FIELD_DELIMITER |
FIRSTROW |
SKIP_HEADER |
ROWTERMINATOR |
RECORD_DELIMITER |
FIELDQUOTE |
FIELD_OPTIONALLY_ENCLOSED_BY |
Zugehörige EWIs¶
[SSC-FDM-TS0004](../../general/technical-documentation/issues-and-troubleshooting/functional-difference/sqlServerFDM. md#ssc-fdm-ts0004): PUT STATEMENT IS NOT SUPPORTED ON WEB UI.
Allgemeiner Tabellenausdruck (CTE)¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Allgemeine Tabellenausdrücke werden in Snowflake SQL standardmäßig unterstützt.
Snowflake SQL-Syntax¶
Unterabfrage:
[ WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
Rekursiver CTE:
[ WITH [ RECURSIVE ]
<cte_name1> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause )
[ , <cte_name2> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
[ , <cte_nameN> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
]
SELECT ...
Wobei:
anchorClause ::=
SELECT <anchor_column_list> FROM ...
recursiveClause ::=
SELECT <recursive_column_list> FROM ... [ JOIN ... ]
Besondere Details¶
Das Schlüsselwort RECURSIVE existiert nicht in T-SQL, und die Transformation fügt das Schlüsselwort nicht aktiv zum Ergebnis hinzu. Der Ausgabecode wird um eine Warnung ergänzt, um auf diese Verhaltensweise hinzuweisen.
Allgemeiner Tabellenausdruck mit SELECT INTO¶
Die folgende Transformation findet statt, wenn der Ausdruck WITH von einer SELECT INTO-Anweisung gefolgt wird, und er wird in eine TEMPORARY TABLE umgewandelt wird.
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2 FROM t1 poh WHERE poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employee WHERE BUSINESSENTITYID = (SELECT col1 FROM ctetable)
),
finalCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employeeCte
) SELECT * INTO #table2 FROM finalCte;
SELECT * FROM #table2;
Snowflake:
CREATE OR REPLACE TEMPORARY TABLE T_table2 AS
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
t1 poh
WHERE
poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employee
WHERE
BUSINESSENTITYID = (SELECT
col1
FROM
ctetable
)
),
finalCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employeeCte
)
SELECT
*
FROM
finalCte;
SELECT
*
FROM
T_table2;
Allgemeiner Tabellenausdruck mit anderen Ausdrücken¶
Die folgende Transformation findet statt, wenn der Ausdruck WITH von den Anweisungen INSERT oder DELETE gefolgt wird.
SQL Server:
WITH CTE AS( SELECT * from table1)
INSERT INTO Table2 (a,b,c,d)
SELECT a,b,c,d
FROM CTE
WHERE e IS NOT NULL;
Snowflake:
INSERT INTO Table2 (a, b, c, d)
WITH CTE AS( SELECT
*
from
table1
)
SELECT
a,
b,
c,
d
FROM
CTE AS CTE
WHERE
e IS NOT NULL;
Allgemeiner Tabellenausdruck mit Delete From Tabellenausdruck¶
Für diese Transformation gilt das nur für eine CTE (Allgemeiner Tabellenausdruck) mit einem Delete From, allerdings nur für einige bestimmte CTEs. Es darf nur eine CTE haben, und sie muss innerhalb einer Funktion von ROW_NUMBER oder RANK haben.
Der Zweck von CTE mit der Funktion Delete muss es sein, Duplikate aus einer Tabelle zu entfernen. Falls CTE mit Delete eine andere Art von Daten entfernen will, wird diese Transformation nicht angewendet.
Sehen wir uns ein Beispiel an. Für ein funktionierendes Beispiel müssen wir zunächst eine Tabelle mit einigen Daten erstellen.
CREATE TABLE WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue NVARCHAR(258)
);
Insert into WithQueryTest values(100, 100, 'First');
Insert into WithQueryTest values(200, 200, 'Second');
Insert into WithQueryTest values(300, 300, 'Third');
Insert into WithQueryTest values(400, 400, 'Fourth');
Insert into WithQueryTest values(100, 100, 'First');
Beachten Sie, dass es einen doppelten Wert gibt. Die Zeilen 8 und 12 fügen denselben Wert ein. Jetzt werden wir die doppelten Zeilen in einer Tabelle eliminieren.
WITH Duplicated AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) AS RN
FROM WithQueryTest
)
DELETE FROM Duplicated
WHERE Duplicated.RN > 1
Wenn wir einen Select aus der Tabelle ausführen, wird das folgende Ergebnis angezeigt
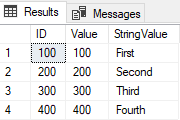
Beachten Sie, dass es keine duplizierten Zeilen gibt. Um die Funktionalität dieses CTE mit Delete in Snowflake zu erhalten, erfolgt einen Transformation in
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest AS SELECT
*
FROM PUBLIC.WithQueryTest
QUALIFY ROW_NUMBER()
OVER (PARTITION BY ID ORDER BY ID) = 1 ;
Wie Sie sehen, wird die Abfrage in eine Create Or Replace-Tabelle umgewandelt.
Lassen Sie uns das in Snowflake ausprobieren. Um das zu testen, benötigen wir auch die Tabelle.
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue VARCHAR(258)
);
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Insert into PUBLIC.WithQueryTest values(200, 200, 'Second');
Insert into PUBLIC.WithQueryTest values(300, 300, 'Third');
Insert into PUBLIC.WithQueryTest values(400, 400, 'Fourth');
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Wenn wir nun das Ergebnis der Transformation ausführen und dann ein Select, um zu prüfen, ob die doppelten Zeilen gelöscht wurden, wäre dies das Ergebnis.
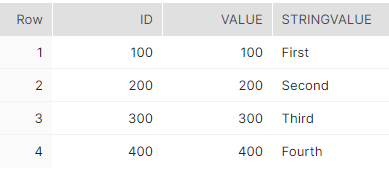
Allgemeiner Tabellenausdruck mit der Anweisung MERGE¶
Die folgende Transformation findet statt, wenn der Ausdruck WITH von der Anweisung MERGE gefolgt wird, und er wird in eine MERGE INTO umgewandelt.
SQL Server:
WITH ctetable(col1, col2) as
(
SELECT col1, col2
FROM t1 poh
where poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT col1 FROM ctetable
)
MERGE
table1 AS target
USING finalCte AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN UPDATE SET target.ID = source.Col1
WHEN NOT MATCHED THEN INSERT (ID, col1) VALUES (source.COL1, source.COL1 );
Snowflake:
MERGE INTO table1 AS target
USING (
--** SSC-PRF-TS0001 - PERFORMANCE WARNING - RECURSION FOR CTE NOT CHECKED. MIGHT REQUIRE RECURSIVE KEYWORD **
WITH ctetable (
col1,
col2
) as
(
SELECT
col1,
col2
FROM
t1 poh
where
poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT
col1
FROM
ctetable
)
SELECT
*
FROM
finalCte
) AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN
UPDATE SET
target.ID = source.Col1
WHEN NOT MATCHED THEN
INSERT (ID, col1) VALUES (source.COL1, source.COL1);
Allgemeiner Tabellenausdruck mit der Anweisung UPDATE¶
Die folgende Transformation findet statt, wenn auf den Ausdruck WITH eine Anweisung UPDATE folgt. Er wird in eine UPDATE-Anweisung umgewandelt.
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2
FROM table2 poh
WHERE poh.col1 = 5 and poh.col2 = 4
)
UPDATE tab1
SET ID = 8, COL1 = 8
FROM table1 tab1
INNER JOIN ctetable CTE ON tab1.ID = CTE.col1;
Snowflake:
UPDATE dbo.table1 tab1
SET
ID = 8,
COL1 = 8
FROM
(
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
table2 poh
WHERE
poh.col1 = 5 and poh.col2 = 4
)
SELECT
*
FROM
ctetable
) AS CTE
WHERE
tab1.ID = CTE.col1;
Bekannte Probleme ¶
Es wurden keine Probleme gefunden.
Zugehörige EWIs¶
[SSC-EWI-0108](../../general/technical-documentation/issues-and-troubleshooting/conversion-issues/generalEWI. md#ssc-ewi-0108): Die folgende Unterabfrage stimmt mit mindestens einem der als ungültig angesehenen Muster überein und kann Kompilierungsfehler verursachen.
[SSC-PRF-TS0001](../../general/technical-documentation/issues-and-troubleshooting/performance-review/README. md#ssc-prf-ts0001): Leistungswarnung – Rekursion für CTE nicht überprüft. Könnte ein rekursives Schlüsselwort erfordern.
Delete¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Beschreibung¶
Entfernt eine oder mehrere Zeilen aus einer Tabelle oder Ansicht in SQL Server. Weitere Informationen zu SQL Server Delete finden Sie hier.
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
Beispielhafte Quellcode-Muster ¶
Die Transformation für die Anweisung DELETE ist ziemlich einfach, wenn auch mit einigen Vorbehalten. Einer dieser Vorbehalte ist die Art und Weise, wie Snowflake mehrere Quellen in der FROM-Klausel unterstützt. Es gibt jedoch eine Entsprechung in Snowflake, wie unten gezeigt.
SQL Server
DELETE T1 FROM TABLE2 T2, TABLE1 T1 WHERE T1.ID = T2.ID
Snowflake
DELETE FROM
TABLE1 T1
USING TABLE2 T2
WHERE
T1.ID = T2.ID;
Bemerkung
Beachten Sie, dass das Vorhandensein von TABLE2 T2 in der FROM-Klausel die Erstellung der USING-Klausel erfordert, da das ursprüngliche DELETE für T1 galt.
¶
Duplikate aus einer Tabelle löschen¶
Die folgende Dokumentation erläutert ein gängiges Muster zum Entfernen doppelter Zeilen aus einer Tabelle in SQL Server. Bei diesem Ansatz wird die Funktion ROW_NUMBER verwendet, um die Daten auf der Grundlage der key_value zu partitionieren, die eine oder mehrere durch Kommas getrennte Spalten sein können. Löschen Sie dann alle Datensätze, die einen Zeilennummernwert größer als 1 erhalten haben. Dieser Wert zeigt an, dass es sich bei den Datensätzen um Duplikate handelt. Sie können die referenzierte Dokumentation lesen, um die Verhaltensweise dieser Methode zu verstehen und sie nachzustellen.
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY ( {expression} )
)
FROM original_table
) AS T
WHERE DupRank > 1
Das folgende Beispiel verwendet diesen Ansatz zum Entfernen von Duplikaten aus einer Tabelle und ihrer Entsprechung in Snowflake. Die Transformation besteht aus einer INSERT OVERWRITE -Anweisung, die die Tabelle abschneidet (alle Daten entfernt) und dann die Zeilen in derselben Tabelle wieder einfügt, wobei die duplizierten Zeilen ignoriert werden. Der Ausgabecode wird unter Berücksichtigung der gleichen PARTITION BY- und ORDER BY-Klauseln generiert, die im Originalcode verwendet wurden.
SQL Server
Erstellen Sie eine Tabelle mit doppelten Zeilen
create table duplicatedRows(
someID int,
col2 bit,
col3 bit,
col4 bit,
col5 bit
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Doppelte Zeilen entfernen
DELETE f FROM (
select someID, row_number() over (
partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc
) as rownum
from
duplicatedRows
) f where f.rownum > 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Snowflake
Erstellen Sie eine Tabelle mit doppelten Zeilen
create table duplicatedRows(
someID int,
col2 BOOLEAN,
col3 BOOLEAN,
col4 BOOLEAN,
col5 BOOLEAN
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Doppelte Zeilen entfernen
insert overwrite into duplicatedRows
SELECT
*
FROM
duplicatedRows
QUALIFY
ROW_NUMBER()
over
(partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc) = 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Warnung
Bedenken Sie, dass es mehrere Variationen dieses Musters geben kann, die aber alle auf demselben Prinzip beruhen und dieselbe Struktur haben.
Bekannte Probleme¶
Es wurden keine Probleme gefunden.
Zugehörige EWIs¶
Keine zugehörigen EWIs.
Drops¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
DROP TABLE¶
Syntax in Transact-SQL¶
DROP TABLE [ IF EXISTS ] <table_name> [ ,...n ]
[ ; ]
Syntax in Snowflake¶
DROP TABLE [ IF EXISTS ] <name> [ CASCADE | RESTRICT ]
Übersetzung¶
Die Übersetzung für einzelne DROP TABLE-Anweisungen ist sehr einfach. Solange nur eine Tabelle in der Anweisung gelöscht wird, bleibt sie unverändert.
Beispiel:
DROP TABLE IF EXISTS [table_name]
DROP TABLE IF EXISTS table_name;
Der einzige bemerkenswerte Unterschied zwischen SQL Server und Snowflake tritt auf, wenn die Eingabeanweisung mehr als eine Tabelle fallen lässt. In diesen Szenarien wird für jede Tabelle, die gelöscht werden soll, eine andere DROP TABLE-Anweisung erstellt.
Beispiel:
DROP TABLE IF EXISTS [table_name], [table_name2], [table_name3]
DROP TABLE IF EXISTS table_name;
DROP TABLE IF EXISTS table_name2;
DROP TABLE IF EXISTS table_name3;
Bekannte Probleme ¶
Es wurden keine Probleme gefunden.
Zugehörige EWIs ¶
Keine zugehörigen EWIs.
Exists¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Typen von Unterabfragen¶
Unterabfragen können als korreliert oder unkorrelierte kategorisiert werden:
Eine korrelierte Unterabfrage verweist auf eine oder mehrere Spalten außerhalb der Unterabfrage. (Die Spalten werden normalerweise in der WHERE-Klausel der Unterabfrage referenziert.) Eine korrelierte Unterabfrage kann als Filter für die Tabelle betrachtet werden, auf die sie verweist, als ob die Unterabfrage für jede Zeile der Tabelle in der äußeren Abfrage ausgewertet würde.
Eine unkorrelierte Unterabfrage enthält keine derartigen externen Spaltenverweise. Sie ist eine unabhängige Abfrage, deren Ergebnisse einmal an die äußere Abfrage zurückgegeben und von dieser verwendet werden (nicht pro Zeile).
Die Anweisung EXISTS wird als korrelierte Unterabfrage betrachtet.
Quellcode
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcExists
AS
BEGIN
IF(EXISTS(Select AValue from ATable))
return 1;
END;
Erwarteter Code
CREATE OR REPLACE PROCEDURE ProcExists ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
if (SELECT(` EXISTS(Select
AValue
from
ATable
)`)) {
return 1;
}
$$;
Bekannte Probleme ¶
Es wurden keine Probleme gefunden.
Zugehörige EWIs ¶
Keine zugehörigen EWIs.
IN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Der IN Operator prüft, ob ein Ausdruck in den Werten enthalten ist, die von einer Unterabfrage zurückgegeben werden.
Quellcode
-- Additional Params: -t JavaScript
CREATE PROCEDURE dbo.SP_IN_EXAMPLE
AS
DECLARE @results as VARCHAR(50);
SELECT @results = COUNT(*) FROM TABLE1
IF @results IN (1,2,3)
SELECT 'is IN';
ELSE
SELECT 'is NOT IN';
return
GO
-- =============================================
-- Example to execute the stored procedure
-- =============================================
EXECUTE dbo.SP_IN_EXAMPLE
GO
Erwarteter Code
CREATE OR REPLACE PROCEDURE dbo.SP_IN_EXAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let RESULTS;
SELECT(` COUNT(*) FROM
TABLE1`,[],(value) => RESULTS = value);
if ([1,2,3].includes(RESULTS)) {
} else {
}
return;
$$;
-- =============================================
-- Example to execute the stored procedure
-- =============================================
CALL dbo.SP_IN_EXAMPLE();
Bekannte Probleme ¶
Es wurden keine Probleme gefunden.
Zugehörige EWIs ¶
Keine zugehörigen EWIs.
Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Beschreibung¶
Fügt eine oder mehrere Zeilen zu einer Tabelle oder einer Ansicht in SQL Server hinzu. Weitere Informationen zu SQL Server Insert finden Sie hier.
Syntax-Vergleich¶
Die grundlegende Insert-Grammatik ist in beiden SQL-Sprachen gleich. Es gibt jedoch noch einige andere Syntaxelemente in SQL Server, die Unterschiede aufweisen. So kann der Entwickler beispielsweise mit dem Zuweisungsoperator einen Wert zu einer Spalte hinzufügen. Die genannte Syntax wird ebenfalls in die grundlegende Insert-Syntax umgewandelt.
Snowflake
INSERT [ OVERWRITE ] INTO <target_table> [ ( <target_col_name> [ , ... ] ) ]
{
VALUES ( { <value> | DEFAULT | NULL } [ , ... ] ) [ , ( ... ) ] |
<query>
}
SQL Server
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
Beispielhafte Quellcode-Muster ¶
Grundlegendes INSERT¶
SQL Server¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
Snowflake¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
INSERT mit Zuweisungsoperator¶
SQL Server¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
Snowflake¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
INSERT ohne INTO¶
SQL Server¶
INSERT exampleTable VALUES ('Hello', 23);
Snowflake¶
INSERT INTO exampleTable VALUES ('Hello', 23);
INSERT mit einem allgemeinen Tabellenausdruck¶
SQL Server¶
WITH ctevalues (textCol, numCol) AS (SELECT 'cte string', 155)
INSERT INTO exampleTable SELECT * FROM ctevalues;
Snowflake¶
INSERT INTO exampleTable
WITH ctevalues (
textCol,
numCol
) AS (SELECT 'cte string', 155)
SELECT
*
FROM
ctevalues AS ctevalues;
INSERT mit Tabellen-DML-Faktor mit MERGE als DML¶
Dieser Fall ist so spezifisch, da die INSERT-Anweisung eine SELECT-Abfrage und die FROM-Klausel der genannten SELECT-Anweisung eine MERGE DML-Anweisung enthält. Auf der Suche nach einer Entsprechung in Snowflake werden die nächsten Anweisungen erstellt: eine temporäre Tabelle, die konvertierte MERGE-Anweisung und schließlich die INSERT-Anweisung.
SQL Server¶
INSERT INTO T3
SELECT
col1,
col2
FROM (
MERGE T1 USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN
INSERT VALUES ( T2.col1, T2.col2 )
WHEN MATCHED THEN
UPDATE SET T1.col2 = t2.col2
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2
) AS MERGE_OUT
WHERE ACTION_OUT='UPDATE';
Snowflake¶
--** SSC-FDM-TS0026 - DELETE CASE IS NOT BEING CONSIDERED, PLEASE CHECK IF THE ORIGINAL MERGE PERFORMS IT **
CREATE OR REPLACE TEMPORARY TABLE MERGE_OUT AS
SELECT
CASE WHEN T1.$1 IS NULL THEN 'INSERT' ELSE 'UPDATE' END ACTION_OUT,
T2.col1,
T2.col2
FROM T2 LEFT JOIN T1 ON T1.col1 = T2.col1;
MERGE INTO T1
USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN INSERT VALUES (T2.col1, T2.col2)
WHEN MATCHED THEN UPDATE SET T1.col2 = t2.col2
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2 ;
INSERT INTO T3
SELECT col1, col2
FROM MERGE_OUT
WHERE ACTION_OUT ='UPDATE';
Warnung
NOTE: Wie der Name des Musters andeutet, ist es NUR für Fälle gedacht, in denen der Insert mit einem Select kommt, dessen Body eine MERGE-Anweisung enthält.
Bekannte Probleme¶
1. Syntaxelemente, die besondere Zuordnungen erfordern:
[INTO]: Dieses Schlüsselwort ist in Snowflake obligatorisch und sollte hinzugefügt werden, wenn es nicht vorhanden ist.
[DEFAULT VALUES]: Fügt den Standardwert in alle in der Einfügung angegebenen Spalten ein. Sollte in VALUES umgewandelt werden (DEFAULT, DEFAULT, …), die Anzahl der hinzugefügten DEFAULTs entspricht der Anzahl der Spalten, die durch die Einfügung geändert werden. Im Moment wird eine Warnung hinzugefügt.
SQL Server
INSERT INTO exampleTable DEFAULT VALUES;
#### Snowflake
!!!RESOLVE EWI!!! /*** SSC-EWI-0073 - PENDING FUNCTIONAL EQUIVALENCE REVIEW FOR 'INSERT WITH DEFAULT VALUES' NODE ***/!!!
INSERT INTO exampleTable DEFAULT VALUES;
2. Syntaxelemente werden nicht unterstützt oder sind irrelevant:
[TOP (Ausdruck) [PERCENT]]: Gibt die Anzahl oder den Prozentsatz der Zeilen an, die eingefügt werden sollen. Nicht unterstützt.
[rowset_function\_limited]: Es handelt sich entweder um OPENQUERY() oder OPENROWSET(), die zum Lesen von Daten von entfernten Servern verwendet werden. Nicht unterstützt.
[WITH table\_hint_limited]: Diese werden verwendet, um Lese-/Schreibsperren für Tabellen zu erhalten. Nicht relevant in Snowflake.
[<OUTPUT-Klausel]: Gibt eine Tabelle oder ein Resultset an, in das die eingefügten Zeilen ebenfalls eingefügt werden. Nicht unterstützt.
[execute_statement]: Kann verwendet werden, um eine Abfrage zum Abrufen von Daten auszuführen. Nicht unterstützt.
[dml_table_source]: Ein temporäres Resultset, das durch die OUTPUT-Klausel einer anderen DML-Anweisung erzeugt wurde. Nicht unterstützt.
3. Der DELETE-Fall wird nicht berücksichtigt.
Für das Muster_INSERT mit Tabellen-DML-Faktor und MERGE als DML_ wird der Fall DELETE in der Lösung nicht berücksichtigt. Wenn also die Anweisung zum Zusammenführen des Quellcodes einen DELETE-Fall enthält, sollten Sie bedenken, dass sie möglicherweise nicht wie erwartet funktioniert.
Zugehörige EWIs¶
[SSC-EWI-0073](../../general/technical-documentation/issues-and-troubleshooting/conversion-issues/generalEWI. md#ssc-ewi-0073): Überprüfung der Funktionsäquivalenz ausstehend.
[SSC-FDM-TS0026](../../general/technical-documentation/issues-and-troubleshooting/functional-difference/sqlServerFDM. md#ssc-fdm-ts0026): DELETE-Fall wird nicht berücksichtigt.
Merge¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Syntax-Vergleich¶
Snowflake SQL-Syntax:
MERGE
INTO <target_table>
USING <source>
ON <join_expr>
{ matchedClause | notMatchedClause } [ ... ]
Transact-SQL-Syntax:
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
Beispiel¶
Angenommen, es gibt folgenden Quellcode:
MERGE
INTO
targetTable WITH(KEEPIDENTITY, KEEPDEFAULTS, HOLDLOCK, IGNORE_CONSTRAINTS, IGNORE_TRIGGERS, NOLOCK, INDEX(value1, value2, value3)) as tableAlias
USING
tableSource AS tableAlias2
ON
mergeSetCondition > mergeSetCondition
WHEN MATCHED BY TARGET AND pi.Quantity - src.OrderQty >= 0
THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list)
OPTION(RECOMPILE);
Sie können in etwa Folgendes erwarten:
MERGE INTO targetTable as tableAlias
USING tableSource AS tableAlias2
ON mergeSetCondition > mergeSetCondition
WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN
UPDATE SET
pi.Quantity = pi.Quantity - src.OrderQty
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list);
Zugehörige EWIs¶
[SSC-EWI-0021](../../general/technical-documentation/issues-and-troubleshooting/conversion-issues/generalEWI. md#ssc-ewi-0021): Syntax wird in Snowflake nicht unterstützt.
Auswählen¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Beschreibung¶
Ermöglicht die Auswahl von einer oder mehreren Zeilen oder Spalten einer oder mehrerer Tabellen in SQL Server.
Weitere Informationen zu SQL Server Select finden Sie hier.
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY <order_by_expression> ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
Beispielhafte Quellcode-Muster ¶
SELECT WITH COLUMN ALIASES¶
Das folgende Beispiel zeigt, wie Sie Spalten-Aliase in Snowflake verwenden können. Es wird erwartet, dass die ersten beiden Spalten aus dem SQL Server-Code mit dem Schlüsselwort AS von einer Zuweisungsform in eine normalisierte Form umgewandelt werden. In der dritten und vierten Spalte werden gültige Snowflake-Formate verwendet.
SQL Server
SELECT
MyCol1Alias = COL1,
MyCol2Alias = COL2,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM TABLE1;
Snowflake
SELECT
COL1 AS MyCol1Alias,
COL2 AS MyCol2Alias,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM
TABLE1;
SELECT TOP¶
Der Grundfall von SQL Server Select Top wird von Snowflake unterstützt. Es gibt jedoch drei weitere Fälle, die nicht unterstützt werden. Sie können diese im Abschnitt „Bekannte Probleme“ überprüfen.
SQL Server
SELECT TOP 1 * from ATable;
Snowflake
SELECT TOP 1
*
from
ATable;
SELECT INTO¶
Das folgende Beispiel zeigt, dass SELECT INTO in CREATE TABLE AS umgewandelt wird, weil es in Snowflake keine Entsprechung für SELECT INTO gibt und eine Tabelle auf der Grundlage einer Abfrage mit CREATE TABLE AS erstellt werden muss.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1;
Ein weiterer Fall ist die Einbeziehung von Mengenoperatoren wie EXCEPT und INTERSECT. Die Transformation ist im Grunde die gleiche wie die vorherige.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1
EXCEPT
SELECT * FROM TABLE2
INTERSECT
SELECT * FROM TABLE3;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1
EXCEPT
SELECT
*
FROM
TABLE2
INTERSECT
SELECT
*
FROM
TABLE3;
Bekannte Probleme¶
SELECT TOP Zusätzliche Argumente¶
Da die Schlüsselwörter PERCENT und WITH TIES das Ergebnis beeinflussen und von Snowflake nicht unterstützt werden, werden sie auskommentiert und als Fehler hinzugefügt.
SQL Server
SELECT TOP 1 PERCENT * from ATable;
SELECT TOP 1 WITH TIES * from ATable;
SELECT TOP 1 PERCENT WITH TIES * from ATable;
Snowflake
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT FOR¶
Da die FOR-Klausel in Snowflake nicht unterstützt wird, wird sie auskommentiert und bei der Transformation als Fehler hinzugefügt.
SQL Server
SELECT column1, column2 FROM my_table FOR XML PATH('');
Snowflake
SELECT
--** SSC-FDM-TS0016 - XML COLUMNS IN SNOWFLAKE MIGHT HAVE A DIFFERENT FORMAT **
FOR_XML_UDF(OBJECT_CONSTRUCT('column1', column1, 'column2', column2), '')
FROM
my_table;
SELECT OPTION¶
Die OPTION-Klausel wird von Snowflake nicht unterstützt. Sie wird auskommentiert und als Warnung während der Transformation hinzugefügt.
Warnung
Beachten Sie, dass die Anweisung OPTION aus der Transformation entfernt wurde, da sie in Snowflake nicht relevant ist oder nicht benötigt wird.
SQL Server
SELECT column1, column2 FROM my_table OPTION (HASH GROUP, FAST 10);
Snowflake
SELECT
column1,
column2
FROM
my_table;
SELECT WITH¶
Die WITH-Klausel wird von Snowflake nicht unterstützt. Sie wird auskommentiert und als Warnung während der Transformation hinzugefügt.
Warnung
Beachten Sie, dass die Anweisung WITH(NOLOCK, NOWAIT) aus der Transformation entfernt wurde, da sie in Snowflake nicht relevant ist oder nicht benötigt wird.
SQL Server
SELECT AValue from ATable WITH(NOLOCK, NOWAIT);
Snowflake
SELECT
AValue
from
ATable;
Zugehörige EWIs¶
[SSC-EWI-0040](../../general/technical-documentation/issues-and-troubleshooting/conversion-issues/generalEWI. md#ssc-ewi-0040): Anweisung wird nicht unterstützt.
[SSC-FDM-TS0016](../../general/technical-documentation/issues-and-troubleshooting/functional-difference/sqlServerFDM. md#ssc-fdm-ts0016): XML-Spalten in Snowflake haben möglicherweise ein anderes Format
Mengenoperatoren¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Die Mengenoperatoren in TSQL und Snowflake weisen dieselbe Syntax und dieselben unterstützten Szenarien auf (EXCEPT, INTERSECT, UNION und UNION ALL), mit Ausnahme von MINUS, das in TSQL nicht unterstützt wird, was zu demselben Code bei der Konvertierung führt.
SELECT LastName, FirstName FROM employees
UNION ALL
SELECT FirstName, LastName FROM contractors;
SELECT ...
INTERSECT
SELECT ...
SELECT ...
EXCEPT
SELECT ...
Truncate (Kürzen)¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Quellcode
TRUNCATE TABLE TABLE1;
Übersetzter Code
TRUNCATE TABLE TABLE1;
Zugehörige EWIs¶
Keine zugehörigen EWIs.
Update¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Bemerkung
Einige Teile des Ausgabecodes wurden aus Gründen der Übersichtlichkeit weggelassen.
Beschreibung¶
Ändert vorhandene Daten in einer Tabelle oder Ansicht in SQL Server. Weitere Informationen zu SQL Server Update finden Sie hier.
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
Beispielhafte Quellcode-Muster ¶
Grundlegendes UPDATE¶
Die Konvertierung für eine reguläre UPDATE-Anweisung ist sehr einfach. Da die grundlegende Struktur von UPDATE in Snowflake standardmäßig unterstützt wird, sind die Ausreißer die Teile, bei denen Sie einige Unterschiede feststellen werden, überprüfen Sie diese im Abschnitt Bekannte Probleme.
SQL Server¶
Update UpdateTest1
Set Col1 = 5;
Snowflake
Update UpdateTest1
Set
Col1 = 5;
Kartesische Produkte¶
SQL Server erlaubt das Hinzufügen von zirkulären Referenzen zwischen der Zieltabelle der Aktualisierungsanweisung und der FROM-Klausel. Bei der Ausführung entfernt der Datenbankoptimierer jedes erzeugte kartesische Produkt. Andernfalls optimiert Snowflake dieses Szenario derzeit nicht und erzeugt ein kartesisches Produkt, das im Ausführungsplan überprüft werden kann. \
Um dies zu beheben, wird bei einem JOIN, bei dem eine der Tabellen mit dem Aktualisierungsziel übereinstimmt, diese Referenz entfernt und zur WHERE-Klausel hinzugefügt. Sie wird verwendet, um die Daten zu filtern und eine Mengenoperation zu vermeiden.
SQL Server¶
UPDATE [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY]
SET
BusinessEntityID = b.BusinessEntityID ,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY] AS a
RIGHT OUTER JOIN [HumanResources].[EmployeeDepartmentHistory] AS b
ON a.BusinessEntityID = b.BusinessEntityID and a.ShiftID = b.ShiftID;
Snowflake
UPDATE HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY a
SET
BusinessEntityID = b.BusinessEntityID,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM
HumanResources.EmployeeDepartmentHistory AS b
WHERE
HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.BusinessEntityID = b.BusinessEntityID(+)
AND HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.ShiftID = b.ShiftID(+);
Bekannte Probleme¶
OUTPUT-Klausel.¶
Die OUTPUT-Klausel wird von Snowflake nicht unterstützt.
SQL Server¶
Update UpdateTest2
Set Col1 = 5
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
Snowflake
Update UpdateTest2
Set
Col1 = 5
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
CTE¶
Die WITH CTE-Klausel wird in die interne Abfrage in der Aktualisierungsanweisung verschoben, um von Snowflake unterstützt zu werden.
SQL Server¶
With ut as (select * from UpdateTest3)
Update x
Set Col1 = 5
from ut as x;
Snowflake
UPDATE UpdateTest3
Set
Col1 = 5
FROM
(
WITH ut as (select
*
from
UpdateTest3
)
SELECT
*
FROM
ut
) AS x;
TOP-Klausel.¶
Die TOP-Klausel wird von Snowflake nicht unterstützt.
SQL Server¶
Update TOP(10) UpdateTest4
Set Col1 = 5;
Snowflake
Update
-- !!!RESOLVE EWI!!! /*** SSC-EWI-0021 - TOP CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
-- TOP(10)
UpdateTest4
Set
Col1 = 5;
WITH TABLE HINT LIMITED¶
Die UPDATE WITH-Klausel wird von Snowflake nicht unterstützt.
SQL Server¶
Update UpdateTest5 WITH(TABLOCK)
Set Col1 = 5;
Snowflake
Update UpdateTest5
Set
Col1 = 5;
Zugehörige EWIs¶
[SSC-EWI-0021](../../general/technical-documentation/issues-and-troubleshooting/conversion-issues/generalEWI. md#ssc-ewi-0021): Syntax wird in Snowflake nicht unterstützt.
Alternative für UPDATE mit JOIN¶
Dieser Abschnitt ist noch in Arbeit, die Informationen können sich in Zukunft ändern.
Description
Das Muster UPDATE FROM wird verwendet, um Daten auf der Grundlage von Daten aus anderen Tabellen zu aktualisieren. Diese SQLServer-Dokumentation enthält ein einfaches Beispiel.
Sie finden die entsprechende SQL Server-Syntax in der Dokumentation.
SQL Server-Syntax
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: Die Tabelle oder Ansicht, die Sie aktualisieren.SET: Gibt die Spalten und ihre neuen Werte an. DieSET-Klausel weist einer oder mehreren Spalten einen neuen Wert (oder Ausdruck) zu.FROM: Wird verwendet, um eine oder mehrere Quelltabellen anzugeben (wie ein Join). Damit können Sie festlegen, woher die Daten für die Aktualisierung kommen.WHERE: Gibt an, welche Zeilen auf der Grundlage der Bedingung(en) aktualisiert werden sollen. Ohne diese Klausel würden alle Zeilen der Tabelle aktualisiert werden.OPTION (query_hint): Gibt Hinweise zur Optimierung von Abfragen an.
Snowflake-Syntax
Die Snowflake-Syntax können Sie auch in der Snowflake-Dokumentation nachlesen.
Bemerkung
Snowflake unterstützt keine JOINs in UPDATE Klauseln.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
[ WHERE <condition> ]
Erforderliche Parameter
_
target_table:_Gibt die zu aktualisierende Tabelle an._
col_name:Gibt den Namen einer Spalte in _target_tablean. Geben Sie nicht den Tabellennamen an.UPDATE t1 SET t1.col = 1ist beispielsweise ungültig._
value:_ Gibt den neuen Wert an, der in _col_name_ festgelegt werden soll.
Optionale Parameter
FROM``_additional_tables:_ Gibt eine oder mehrere Tabellen an, die zur Auswahl der zu aktualisierenden Zeilen oder zum Setzen neuer Werte verwendet werden sollen.Beachten Sie, dass die Wiederholung der Zieltabelle zu einem Self-Join führt.WHERE``Bedingung:_ Der Ausdruck, der die Zeilen in der Zieltabelle angibt, die aktualisiert werden sollen. Standard: Kein Wert (alle Zeilen der Zieltabelle werden aktualisiert)
Zusammenfassung der Übersetzung¶
| SQL Server JOIN type | Snowflake Best Alternative |
|---|---|
Single INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN + Agregate condition | Use subquery + IN Operation |
Single LEFT JOIN | Use subquery + IN Operation |
Multiple LEFT JOIN | Use Snowflake
|
Multiple RIGHT JOIN | Use Snowflake
|
| Single RIGHT JOIN | Use the table in the FROM clause and add filters in the WHERE clause as needed. |
Hinweis 1: Ein einfaches JOIN kann die Tabelle in der FROM-Klausel verwenden und bei Bedarf Filter in der WHERE-Klausel hinzufügen.
Hinweis 2: Andere Ansätze können einen (+)-Operanden enthalten, um die JOINs zu definieren.
Beispielhafte Quellcode-Muster ¶
Datenkonfiguration¶
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
);
CREATE OR REPLACE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
Data Insertion for samples
-- Insert Customer Data
INSERT INTO Customers (CustomerID, CustomerName) VALUES (1, 'John Doe');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (2, 'Jane Smith');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (3, 'Alice Johnson');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (4, 'Bob Lee');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (5, 'Charlie Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (6, 'David White');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (7, 'Eve Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (8, 'Grace Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (9, 'Hank Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (10, 'Ivy Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (11, 'Jack Grey');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (12, 'Kim Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (13, 'Leo Purple');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (14, 'Mona Pink');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (15, 'Nathan Orange');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (16, 'Olivia Cyan');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (17, 'Paul Violet');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (18, 'Quincy Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (19, 'Rita Silver');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (20, 'Sam Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (21, 'Tina Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (22, 'Ursula Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (23, 'Vince Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (24, 'Wendy Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (25, 'Xander White');
-- Insert Product Data
INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Laptop', 999.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Smartphone', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (3, 'Tablet', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (4, 'Headphones', 149.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (5, 'Monitor', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (6, 'Keyboard', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (7, 'Mouse', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (8, 'Camera', 599.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (9, 'Printer', 99.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (10, 'Speaker', 129.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (11, 'Charger', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (12, 'TV', 699.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (13, 'Smartwatch', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (14, 'Projector', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (15, 'Game Console', 399.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (16, 'Speaker System', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (17, 'Earphones', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (18, 'USB Drive', 15.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (19, 'External Hard Drive', 79.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (20, 'Router', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (21, 'Printer Ink', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (22, 'Flash Drive', 9.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (23, 'Gamepad', 34.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (24, 'Webcam', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (25, 'Docking Station', 129.99);
-- Insert Orders Data
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (1, 1, 1, 2, '2024-11-01');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (2, 2, 2, 1, '2024-11-02');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (3, 3, 3, 5, '2024-11-03');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (4, 4, 4, 3, '2024-11-04');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (5, NULL, 5, 7, '2024-11-05'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (6, 6, 6, 2, '2024-11-06');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (7, 7, NULL, 4, '2024-11-07'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (8, 8, 8, 1, '2024-11-08');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (9, 9, 9, 3, '2024-11-09');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (10, 10, 10, 2, '2024-11-10');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (11, 11, 11, 5, '2024-11-11');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (12, 12, 12, 2, '2024-11-12');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (13, NULL, 13, 8, '2024-11-13'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (14, 14, NULL, 4, '2024-11-14'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (15, 15, 15, 3, '2024-11-15');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (16, 16, 16, 2, '2024-11-16');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (17, 17, 17, 1, '2024-11-17');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (18, 18, 18, 4, '2024-11-18');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (19, 19, 19, 3, '2024-11-19');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (20, 20, 20, 6, '2024-11-20');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (21, 21, 21, 3, '2024-11-21');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (22, 22, 22, 5, '2024-11-22');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (23, 23, 23, 2, '2024-11-23');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (24, 24, 24, 4, '2024-11-24');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (25, 25, 25, 3, '2024-11-25');
Fall 1: Einzelnes INNER JOIN-Update¶
Wenn die Tabelle INNER JOIN innerhalb der FROM-Anweisungen verwendet wird, wird sie automatisch zu INNER JOIN. Beachten Sie, dass es mehrere Ansätze zur Unterstützung von JOINs in UPDATE-Anweisungen in Snowflake gibt. Dies ist eines der einfachsten Muster, um die Lesbarkeit zu gewährleisten.
SQL Server¶
UPDATE Orders
SET Quantity = 10
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'John Doe';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Menge |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 10
FROM
Customers C
WHERE
C.CustomerName = 'John Doe'
AND O.CustomerID = C.CustomerID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Menge |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Andere Ansätze:
MERGE INTO
MERGE INTO Orders O
USING Customers C
ON O.CustomerID = C.CustomerID
WHEN MATCHED AND C.CustomerName = 'John Doe' THEN
UPDATE SET O.Quantity = 10;
IN Operation
UPDATE Orders O
SET O.Quantity = 10
WHERE O.CustomerID IN
(SELECT CustomerID FROM Customers WHERE CustomerName = 'John Doe');
Fall 2: Update mehrere INNER JOIN¶
SQL Server¶
UPDATE Orders
SET Quantity = 5
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerName = 'Alice Johnson' AND P.ProductName = 'Tablet';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Menge |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 5
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Menge |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Fall 3: Update mehrere INNER JOIN mit Aggregatbedingungen¶
SQL Server¶
UPDATE Orders
SET Quantity = 6
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Menge |
Preis (price) |
|---|---|---|---|
11 |
Jack Grey |
6 |
29,99 |
18 |
Quincy Brown |
6 |
15,99 |
20 |
Sam Green |
6 |
89,99 |
22 |
Ursula Rot |
6 |
9,99 |
24 |
Wendy Schwarz |
6 |
49,99 |
Snowflake¶
UPDATE Orders O
SET Quantity = 6
WHERE O.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND O.ProductID IN (SELECT ProductID FROM Products WHERE Price < 200);
-- Select changes
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Menge |
Preis (price) |
|---|---|---|---|
11 |
Jack Grey |
6 |
29,99 |
18 |
Quincy Brown |
6 |
15,99 |
20 |
Sam Green |
6 |
89,99 |
22 |
Ursula Rot |
6 |
9,99 |
24 |
Wendy Schwarz |
6 |
49,99 |
Fall 4: Update einzelner LEFT JOIN¶
SQL Server¶
UPDATE Orders
SET Quantity = 13
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13;
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Menge |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Snowflake¶
UPDATE Orders
SET Quantity = 13
WHERE OrderID IN (
SELECT O.OrderID
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13
);
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Menge |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Bemerkung
Dieser Ansatz funktioniert in Snowflake nicht, da er die erforderlichen Zeilen nicht aktualisiert:
UPDATE Orders O SET O.Quantity = 13 FROM Customers C WHERE O.CustomerID = C.CustomerID AND C.CustomerID IS NULL AND O.ProductID = 13;
Fall 5: Update mehrere LEFT JOIN und RIGHT JOIN¶
Dies ist ein komplexeres Muster. Um mehrere LEFT JOINs zu übersetzen, sehen Sie sich bitte das folgende Muster an:
Bemerkung
LEFT JOIN und RIGHT JOIN hängen von der Reihenfolge in der FROM-Klausel ab.
UPDATE [target_table_name]
SET [all_set_statements]
FROM [all_left_join_tables_separated_by_comma]
WHERE [all_clauses_into_the_ON_part]
SQL Server¶
UPDATE Orders
SET
Quantity = C.CustomerID
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Menge |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Snowflake¶
UPDATE Orders O
SET O.Quantity = C.CustomerID
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Menge |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Fall 6: Update gemischte INNER JOIN und LEFT JOIN¶
SQL Server¶
UPDATE Orders
SET Quantity = 4
FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Menge |
|---|---|---|
null |
null |
4 |
Snowflake¶
UPDATE Orders O
SET Quantity = 4
WHERE O.ProductID IN (SELECT ProductID FROM Products WHERE ProductName = 'Monitor')
AND O.CustomerID IS NULL;
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Menge |
|---|---|---|
null |
null |
4 |
Fall 7: Update einzelner RIGHT JOIN¶
SQL Server¶
UPDATE O
SET O.Quantity = 1000
FROM Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 1000
FROM Customers C
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Probleme kennen¶
Da
UPDATEin Snowflake die Verwendung vonJOINsnicht direkt erlaubt, kann es Fälle geben, die nicht den beschriebenen Mustern entsprechen.
UPDATE mit LEFT und RIGHT JOIN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Warnung
Teilweise unterstützt in Snowflake
Beschreibung ¶
Das Muster UPDATE FROM wird verwendet, um Daten auf der Grundlage von Daten aus anderen Tabellen zu aktualisieren. Diese SQLServer-Dokumentation enthält ein einfaches Beispiel.
Sie finden die entsprechende SQL Server-Syntax in der Dokumentation.
SQL Server-Syntax¶
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: Die Tabelle oder Ansicht, die Sie aktualisieren.SET: Gibt die Spalten und ihre neuen Werte an. DieSET-Klausel weist einer oder mehreren Spalten einen neuen Wert (oder Ausdruck) zu.FROM: Wird verwendet, um eine oder mehrere Quelltabellen anzugeben (wie ein Join). Damit können Sie festlegen, woher die Daten für die Aktualisierung kommen.WHERE: Gibt an, welche Zeilen auf der Grundlage der Bedingung(en) aktualisiert werden sollen. Ohne diese Klausel würden alle Zeilen der Tabelle aktualisiert werden.OPTION (query_hint): Gibt Hinweise zur Optimierung von Abfragen an.
Snowflake-Syntax¶
Die Snowflake-Syntax können Sie auch in der Snowflake-Dokumentation nachlesen.
Bemerkung
Snowflake unterstützt keine JOINs in UPDATE Klauseln.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
Erforderliche Parameter
_
target_table:_Gibt die zu aktualisierende Tabelle an._
col_name:Gibt den Namen einer Spalte in _target_tablean. Geben Sie nicht den Tabellennamen an.UPDATE t1 SET t1.col = 1ist beispielsweise ungültig._
value:_ Gibt den neuen Wert an, der in _col_name_ festgelegt werden soll.
Optionale Parameter
FROM``_additional_tables:_ Gibt eine oder mehrere Tabellen an, die zur Auswahl der zu aktualisierenden Zeilen oder zum Setzen neuer Werte verwendet werden sollen.Beachten Sie, dass die Wiederholung der Zieltabelle zu einem Self-Join führt.WHERE``Bedingung:_ Der Ausdruck, der die Zeilen in der Zieltabelle angibt, die aktualisiert werden sollen. Standard: Kein Wert (alle Zeilen der Zieltabelle werden aktualisiert)
Zusammenfassung der Übersetzung¶
Wie in der Beschreibung der Grammatik erläutert, gibt es keine direkte äquivalente Lösung für JOINs innerhalb der UPDATE-Klausel. Aus diesem Grund besteht der Ansatz zur Umwandlung dieser Anweisungen darin, den Operator (+) zu der Spalte hinzuzufügen, die logischerweise die erforderlichen Daten in die Tabelle einfügt. Dieser Operator (+) wird zu den Fällen hinzugefügt, auf die die Tabellen im Abschnitt LEFT/RIGHT JOIN verweisen.
Beachten Sie, dass es auch andere Sprachen gibt, die diesen Operator (+) verwenden und dass die Position des Operators die Art der Verknüpfung bestimmen kann. In diesem speziellen Fall bestimmt in Snowflake nicht die Position den Verknüpfungstyp, sondern die Verknüpfung mit den logisch benötigten Tabellen und Spalten.
Auch wenn es andere Alternativen gibt, wie MERGE-Klausel oder die Verwendungen einer CTE, sind diese Alternativen bei komplexen Abfragen oft schwer lesbar und umfangreich.
Beispielhafte Quellcode-Muster ¶
Datenkonfiguration¶
CREATE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
);
CREATE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
);
CREATE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
);
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
CREATE OR REPLACE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
LEFT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM GenericTable1 T1
LEFT JOIN GenericTable2 T2 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4
LEFT JOIN GenericTable3 T3 ON
T3.Col1 = T2.Col5 AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM
GenericTable2 T2,
GenericTable3 T3
WHERE
T2.Col1(+) COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2(+) = T1.Col2
AND T2.Col3(+) = T1.Col3
AND T2.Col4(+) = T1.Col4
AND T3.Col1(+) = T2.Col5
AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
RIGHT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5
FROM GenericTable2 T2
RIGHT JOIN GenericTable1 T1 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4;
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 _ |
null |
2 |
A2 |
B2 |
C2 |
X2 _ |
null |
3 |
A3 |
B3 |
C3 |
X3 _ |
null |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5
FROM
GenericTable2 T2,
GenericTable1 T1
WHERE
T2.Col1 COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2 = T1.Col2(+)
AND T2.Col3 = T1.Col3(+)
AND T2.Col4 = T1.Col4(+);
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 _ |
null |
2 |
A2 |
B2 |
C2 |
X2 _ |
null |
3 |
A3 |
B3 |
C3 |
X3 _ |
null |
Bekannte Probleme¶
Es kann Muster geben, die aufgrund von Unterschieden in der Logik nicht übersetzt werden können.
Wenn Ihr Abfragemuster zutrifft, überprüfen Sie nicht-deterministische Zeilen: „Wenn eine FROM-Klausel eine JOIN zwischen Tabellen enthält (z. B.
t1undt2), kann eine Zielzeile int1mit mehr als einer Zeile in der Tabellet2verknüpft werden (d.h. übereinstimmen). Wenn dies der Fall ist, wird die Zielzeile als mehrfach verknüpfte Zeile bezeichnet. Beim Aktualisieren einer mehrfach verknüpften Zeile steuert der Sitzungsparameter ERROR_ON_NONDETERMINISTIC_UPDATE das Ergebnis der Aktualisierung“ (Snowflake-Dokumentation).