SnowConvert : DMLs Transact¶
Between¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Code source
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcBetween
AS
BEGIN
declare @aValue int = 1;
IF(@aValue BETWEEN 1 AND 2)
return 1
END;
GO
Code attendu
CREATE OR REPLACE PROCEDURE ProcBetween ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let AVALUE = 1;
if (SELECT(` ? BETWEEN 1 AND 2`,[AVALUE])) {
return 1;
}
$$;
Problèmes connus ¶
Aucun problème n’a été constaté.
Bulk Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
La traduction directe de BULK INSERT est l’instruction Snowflake COPY INTO. COPY INTO n’utilise pas directement le chemin du fichier pour récupérer les valeurs. Le fichier doit exister au préalable dans un STAGE. De même, les options utilisées dans BULK INSERT doivent être spécifiées dans un Snowflake FILE FORMAT qui sera consommé par STAGE ou directement par COPY INTO.
Pour ajouter un fichier à un STAGE, vous devez utiliser la commande PUT. Notez que la commande ne peut être exécutée qu’à partir de SnowSQL CLI. Voici un exemple des étapes à suivre avant d’exécuter un COPY INTO :
-- Additional Params: -t JavaScript
CREATE PROCEDURE PROCEDURE_SAMPLE
AS
CREATE TABLE #temptable
([col1] varchar(100),
[col2] int,
[col3] varchar(100))
BULK INSERT #temptable FROM 'C:\test.txt'
WITH
(
FIELDTERMINATOR ='\t',
ROWTERMINATOR ='\n'
);
GO
CREATE OR REPLACE FILE FORMAT FILE_FORMAT_638434968243607970
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n';
CREATE OR REPLACE STAGE STAGE_638434968243607970
FILE_FORMAT = FILE_FORMAT_638434968243607970;
--** SSC-FDM-TS0004 - PUT STATEMENT IS NOT SUPPORTED ON WEB UI. YOU SHOULD EXECUTE THE CODE THROUGH THE SNOWFLAKE CLI **
PUT file://C:\test.txt @STAGE_638434968243607970 AUTO_COMPRESS = FALSE;
CREATE OR REPLACE PROCEDURE PROCEDURE_SAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
EXEC(`CREATE OR REPLACE TEMPORARY TABLE T_temptable
(
col1 VARCHAR(100),
col2 INT,
col3 VARCHAR(100))`);
EXEC(`COPY INTO T_temptable FROM @STAGE_638434968243607970/test.txt`);
$$
Comme vous le voyez dans le code ci-dessus, SnowConvert identifie tous les BULK INSERTS dans le code, et pour chaque instance, un nouveau STAGE et FILE FORMAT seront créés avant que la copie ne soit exécutée. En outre, après la création de la commande STAGE, une commande PUT sera également créée afin d’ajouter le fichier à la zone de préparation.
Les noms des instructions générées sont générés automatiquement en utilisant l’horodatage actuel en secondes, afin d’éviter les collisions entre leurs utilisations.
Enfin, toutes les options de bulk insert sont mappées aux options de format de fichier, le cas échéant. Si l’option n’est pas prise en charge par Snowflake, elle sera commentée et un avertissement sera ajouté. Voir aussi SSC-FDM-TS0004.
Options bulk prises en charge¶
SQL Server |
Snowflake |
|---|---|
FORMAT |
TYPE |
FIELDTERMINATOR |
FIELD_DELIMITER |
FIRSTROW |
SKIP_HEADER |
ROWTERMINATOR |
RECORD_DELIMITER |
FIELDQUOTE |
FIELD_OPTIONALLY_ENCLOSED_BY |
EWIs connexes¶
SSC-FDM-TS0004 : PUT STATEMENT IS NOT SUPPORTED ON WEB UI.
Expression de table commune (CTE)¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Les expressions de table communes sont prises en charge par défaut dans Snowflake SQL.
Syntaxe Snowflake SQL¶
Sous-requête :
[ WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
CTE récursive :
[ WITH [ RECURSIVE ]
<cte_name1> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause )
[ , <cte_name2> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
[ , <cte_nameN> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
]
SELECT ...
Où :
anchorClause ::=
SELECT <anchor_column_list> FROM ...
recursiveClause ::=
SELECT <recursive_column_list> FROM ... [ JOIN ... ]
Détails notables¶
Le mot-clé RECURSIVE n’existe pas dans T-SQL, et la transformation n’ajoute pas activement le mot-clé au résultat. Un avertissement est ajouté au code de sortie afin d’indiquer ce comportement.
Expression de table commune avec SELECT INTO¶
La transformation suivante se produit lorsque l’expression WITH est suivie d’une instruction SELECT INTO et qu’elle sera transformée en une TEMPORARY TABLE.
SQL Server :
WITH ctetable(col1, col2) AS
(
SELECT col1, col2 FROM t1 poh WHERE poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employee WHERE BUSINESSENTITYID = (SELECT col1 FROM ctetable)
),
finalCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employeeCte
) SELECT * INTO #table2 FROM finalCte;
SELECT * FROM #table2;
Snowflake :
CREATE OR REPLACE TEMPORARY TABLE T_table2 AS
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
t1 poh
WHERE
poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employee
WHERE
BUSINESSENTITYID = (SELECT
col1
FROM
ctetable
)
),
finalCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employeeCte
)
SELECT
*
FROM
finalCte;
SELECT
*
FROM
T_table2;
Expression de table commune avec d’autres expressions¶
La transformation suivante se produit lorsque l’expression WITH est suivie d’instructions INSERT ou DELETE.
SQL Server :
WITH CTE AS( SELECT * from table1)
INSERT INTO Table2 (a,b,c,d)
SELECT a,b,c,d
FROM CTE
WHERE e IS NOT NULL;
Snowflake :
INSERT INTO Table2 (a, b, c, d)
WITH CTE AS( SELECT
*
from
table1
)
SELECT
a,
b,
c,
d
FROM
CTE AS CTE
WHERE
e IS NOT NULL;
Expression de table commune avec Delete From¶
Cette transformation ne s’appliquera qu’aux CTE (expressions de table communes) avec Delete From, mais seulement pour des CTE spécifiques. Il ne doit avoir qu’une seule CTE, et il doit avoir à l’intérieur une fonction de ROW_NUMBER ou RANK.
L’objectif de la CTE avec Delete doit être de supprimer les doublons d’une table. Dans le cas où la CTE avec Delete vise à supprimer un autre type de données, cette transformation ne s’appliquera pas.
Prenons un exemple. Pour un exemple concret, nous devons d’abord créer une table contenant des données.
CREATE TABLE WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue NVARCHAR(258)
);
Insert into WithQueryTest values(100, 100, 'First');
Insert into WithQueryTest values(200, 200, 'Second');
Insert into WithQueryTest values(300, 300, 'Third');
Insert into WithQueryTest values(400, 400, 'Fourth');
Insert into WithQueryTest values(100, 100, 'First');
Notez qu’il y a une valeur en double. Les lignes 8 et 12 insèrent la même valeur. Nous allons maintenant éliminer les lignes en double dans une table.
WITH Duplicated AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) AS RN
FROM WithQueryTest
)
DELETE FROM Duplicated
WHERE Duplicated.RN > 1
Si nous exécutons un Select à partir de la table, le résultat sera le suivant
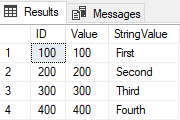
Notez qu’il n’y a pas de lignes dupliquées. Afin de conserver la fonctionnalité de ces CTE avec Delete in Snowflake, il sera transformé en
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest AS SELECT
*
FROM PUBLIC.WithQueryTest
QUALIFY ROW_NUMBER()
OVER (PARTITION BY ID ORDER BY ID) = 1 ;
Comme vous pouvez le constater, la requête est transformée en Create ou Replace Table.
Essayons-le dans Snowflake. Pour le tester, nous avons également besoin de la table.
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue VARCHAR(258)
);
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Insert into PUBLIC.WithQueryTest values(200, 200, 'Second');
Insert into PUBLIC.WithQueryTest values(300, 300, 'Third');
Insert into PUBLIC.WithQueryTest values(400, 400, 'Fourth');
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Maintenant, si nous exécutons le résultat de la transformation, puis un Select pour vérifier si les lignes dupliquées ont été supprimées, voici le résultat.
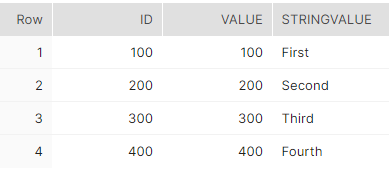
Expression de table commune avec l’instruction MERGE¶
La transformation suivante se produit lorsque l’expression WITH est suivie de l’instruction MERGE et qu’elle sera transformée en MERGE INTO.
SQL Server :
WITH ctetable(col1, col2) as
(
SELECT col1, col2
FROM t1 poh
where poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT col1 FROM ctetable
)
MERGE
table1 AS target
USING finalCte AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN UPDATE SET target.ID = source.Col1
WHEN NOT MATCHED THEN INSERT (ID, col1) VALUES (source.COL1, source.COL1 );
Snowflake :
MERGE INTO table1 AS target
USING (
--** SSC-PRF-TS0001 - PERFORMANCE WARNING - RECURSION FOR CTE NOT CHECKED. MIGHT REQUIRE RECURSIVE KEYWORD **
WITH ctetable (
col1,
col2
) as
(
SELECT
col1,
col2
FROM
t1 poh
where
poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT
col1
FROM
ctetable
)
SELECT
*
FROM
finalCte
) AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN
UPDATE SET
target.ID = source.Col1
WHEN NOT MATCHED THEN
INSERT (ID, col1) VALUES (source.COL1, source.COL1);
Expression de table commune avec l’instruction UPDATE¶
La transformation suivante se produit lorsque l’expression WITH est suivie d’une instruction UPDATE et qu’elle sera transformée en UPDATE instruction.
SQL Server :
WITH ctetable(col1, col2) AS
(
SELECT col1, col2
FROM table2 poh
WHERE poh.col1 = 5 and poh.col2 = 4
)
UPDATE tab1
SET ID = 8, COL1 = 8
FROM table1 tab1
INNER JOIN ctetable CTE ON tab1.ID = CTE.col1;
Snowflake :
UPDATE dbo.table1 tab1
SET
ID = 8,
COL1 = 8
FROM
(
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
table2 poh
WHERE
poh.col1 = 5 and poh.col2 = 4
)
SELECT
*
FROM
ctetable
) AS CTE
WHERE
tab1.ID = CTE.col1;
Problèmes connus ¶
Aucun problème n’a été constaté.
EWIs connexes¶
SSC-EWI-0108 : La sous-requête suivante correspond à au moins un des modèles considérés comme invalides et peut produire des erreurs de compilation.
SSC-PRF-TS0001 : Avertissement de performance - la récursivité pour CTE n’a pas été vérifiée. Peut nécessiter un mot-clé récursif.
Supprimer¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Description¶
Supprime une ou plusieurs lignes d’une table ou d’une vue dans SQL Server. Pour plus d’informations sur SQL Server Delete, cliquez ici.
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
Échantillons de modèles de sources ¶
La transformation de l’instruction DELETE est assez simple, avec quelques mises en garde. L’une de ces mises en garde concerne la manière dont Snowflake prend en charge les sources multiples dans la clause FROM. Il existe toutefois un équivalent dans Snowflake, comme indiqué ci-dessous.
SQL Server
DELETE T1 FROM TABLE2 T2, TABLE1 T1 WHERE T1.ID = T2.ID
Snowflake
DELETE FROM
TABLE1 T1
USING TABLE2 T2
WHERE
T1.ID = T2.ID;
Note
Notez que, puisque le DELETE d’origine concernait T1, la présence de TABLE2 T2 dans la clause FROM exige la création de la clause USING.
¶
Supprimer les doublons d’une table¶
La documentation suivante explique un modèle courant utilisé pour supprimer les lignes dupliquées d’une table dans le SQL Server. Cette approche utilise la fonction ROW_NUMBER pour partitionner les données sur la base de la key_value qui peut être une ou plusieurs colonnes séparées par des virgules. Ensuite, supprimez tous les enregistrements dont la valeur du numéro de ligne est supérieure à 1. Cette valeur indique que les enregistrements sont des doublons. Vous pouvez consulter la documentation référencée pour comprendre le comportement de cette méthode et la recréer.
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY ( {expression} )
)
FROM original_table
) AS T
WHERE DupRank > 1
L’exemple suivant utilise cette approche pour supprimer les doublons d’une table et son équivalent dans Snowflake. La transformation consiste à exécuter une instruction INSERT OVERWRITE qui tronque la table (supprime toutes les données) et insère à nouveau les lignes de la même table en ignorant celles qui sont dupliquées. Le code de sortie est généré en tenant compte des mêmes clauses PARTITION BY et ORDER BY que celles utilisées dans le code d’origine.
SQL Server
Create table avec des lignes dupliquées
create table duplicatedRows(
someID int,
col2 bit,
col3 bit,
col4 bit,
col5 bit
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Supprimer les lignes en double
DELETE f FROM (
select someID, row_number() over (
partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc
) as rownum
from
duplicatedRows
) f where f.rownum > 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Snowflake
Create table avec des lignes dupliquées
create table duplicatedRows(
someID int,
col2 BOOLEAN,
col3 BOOLEAN,
col4 BOOLEAN,
col5 BOOLEAN
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Supprimer les lignes en double
insert overwrite into duplicatedRows
SELECT
*
FROM
duplicatedRows
QUALIFY
ROW_NUMBER()
over
(partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc) = 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Avertissement
Considérez qu’il peut exister plusieurs variantes de ce modèle, mais qu’elles sont toutes basées sur le même principe et présentent la même structure.
Problèmes connus¶
Aucun problème n’a été constaté.
EWIs connexes¶
Pas d’EWIs connexes.
Drops¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
DROP TABLE¶
Syntaxe dans Transact-SQL¶
DROP TABLE [ IF EXISTS ] <table_name> [ ,...n ]
[ ; ]
Syntaxe dans Snowflake¶
DROP TABLE [ IF EXISTS ] <name> [ CASCADE | RESTRICT ]
Traduction¶
La traduction des instructions DROP TABLE simples est très facile. Tant qu’il n’y a qu’une seule table supprimée dans l’instruction, elle est laissée telle quelle.
Par exemple :
DROP TABLE IF EXISTS [table_name]
DROP TABLE IF EXISTS table_name;
La seule différence notable entre SQL Server et Snowflake apparaît lorsque l’instruction d’entrée supprime plus d’une table. Dans ce cas, une instruction DROP TABLE différente est créée pour chaque table supprimée.
Par exemple :
DROP TABLE IF EXISTS [table_name], [table_name2], [table_name3]
DROP TABLE IF EXISTS table_name;
DROP TABLE IF EXISTS table_name2;
DROP TABLE IF EXISTS table_name3;
Problèmes connus ¶
Aucun problème n’a été constaté.
EWIs connexes ¶
Pas d’EWIs connexes.
Exists¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Types de sous-requêtes¶
Les sous-requêtes peuvent être classées comme corrélées ou non corrélées :
Une sous-requête corrélée fait référence à une ou plusieurs colonnes à l’extérieur de la sous-requête. (Les colonnes sont généralement référencées dans la clause WHERE de la sous-requête.) Une sous-requête corrélée peut être considérée comme un filtre sur la table à laquelle elle se réfère, comme si la sous-requête était évaluée sur chaque ligne de la table dans la requête externe.
Une sous-requête non corrélée ne présente pas de telles références de colonnes externes. Il s’agit d’une requête indépendante dont les résultats sont renvoyés et utilisés une fois par la requête externe (et non par ligne).
L’instruction EXISTS est considérée comme une sous-requête corrélée.
Code source
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcExists
AS
BEGIN
IF(EXISTS(Select AValue from ATable))
return 1;
END;
Code attendu
CREATE OR REPLACE PROCEDURE ProcExists ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
if (SELECT(` EXISTS(Select
AValue
from
ATable
)`)) {
return 1;
}
$$;
Problèmes connus ¶
Aucun problème n’a été constaté.
EWIs connexes ¶
Pas d’EWIs connexes.
IN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
L’opérateur IN vérifie si une expression est incluse dans les valeurs retournées par une sous-requête.
Code source
-- Additional Params: -t JavaScript
CREATE PROCEDURE dbo.SP_IN_EXAMPLE
AS
DECLARE @results as VARCHAR(50);
SELECT @results = COUNT(*) FROM TABLE1
IF @results IN (1,2,3)
SELECT 'is IN';
ELSE
SELECT 'is NOT IN';
return
GO
-- =============================================
-- Example to execute the stored procedure
-- =============================================
EXECUTE dbo.SP_IN_EXAMPLE
GO
Code attendu
CREATE OR REPLACE PROCEDURE dbo.SP_IN_EXAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let RESULTS;
SELECT(` COUNT(*) FROM
TABLE1`,[],(value) => RESULTS = value);
if ([1,2,3].includes(RESULTS)) {
} else {
}
return;
$$;
-- =============================================
-- Example to execute the stored procedure
-- =============================================
CALL dbo.SP_IN_EXAMPLE();
Problèmes connus ¶
Aucun problème n’a été constaté.
EWIs connexes ¶
Pas d’EWIs connexes.
Insérer¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Description¶
Ajoute une ou plusieurs lignes à une table ou à une vue dans SQL Server. Pour plus d’informations sur SQL Server Insert, cliquez ici.
Comparaison des syntaxes¶
La grammaire de base des insertions est équivalente entre les deux langages SQL. Toutefois, d’autres éléments de syntaxe de SQL Server présentent des différences. Par exemple, l’un d’eux permet au développeur d’ajouter une valeur à une colonne en utilisant l’opérateur d’assignation. La syntaxe mentionnée sera également transformée en syntaxe d’insertion de base.
Snowflake
INSERT [ OVERWRITE ] INTO <target_table> [ ( <target_col_name> [ , ... ] ) ]
{
VALUES ( { <value> | DEFAULT | NULL } [ , ... ] ) [ , ( ... ) ] |
<query>
}
SQL Server
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
Échantillons de modèles de sources ¶
INSERT de base¶
SQL Server¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
Snowflake¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
INSERT avec l’opérateur d’assignation¶
SQL Server¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
Snowflake¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
INSERT sans INTO¶
SQL Server¶
INSERT exampleTable VALUES ('Hello', 23);
Snowflake¶
INSERT INTO exampleTable VALUES ('Hello', 23);
INSERT avec expression de la table commune¶
SQL Server¶
WITH ctevalues (textCol, numCol) AS (SELECT 'cte string', 155)
INSERT INTO exampleTable SELECT * FROM ctevalues;
Snowflake¶
INSERT INTO exampleTable
WITH ctevalues (
textCol,
numCol
) AS (SELECT 'cte string', 155)
SELECT
*
FROM
ctevalues AS ctevalues;
INSERT avec facteur DML de table avec MERGE comme DML¶
Ce cas est tellement spécifique que l’instruction INSERT contient une requête SELECT, et la clause FROM de l’instruction SELECT mentionnée contient une instruction MERGE DML. En cherchant un équivalent dans Snowflake, les instructions suivantes sont créées : une table temporaire, l’instruction merge convertie, et enfin, l’instruction insert.
SQL Server¶
INSERT INTO T3
SELECT
col1,
col2
FROM (
MERGE T1 USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN
INSERT VALUES ( T2.col1, T2.col2 )
WHEN MATCHED THEN
UPDATE SET T1.col2 = t2.col2
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2
) AS MERGE_OUT
WHERE ACTION_OUT='UPDATE';
Snowflake¶
--** SSC-FDM-TS0026 - DELETE CASE IS NOT BEING CONSIDERED, PLEASE CHECK IF THE ORIGINAL MERGE PERFORMS IT **
CREATE OR REPLACE TEMPORARY TABLE MERGE_OUT AS
SELECT
CASE WHEN T1.$1 IS NULL THEN 'INSERT' ELSE 'UPDATE' END ACTION_OUT,
T2.col1,
T2.col2
FROM T2 LEFT JOIN T1 ON T1.col1 = T2.col1;
MERGE INTO T1
USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN INSERT VALUES (T2.col1, T2.col2)
WHEN MATCHED THEN UPDATE SET T1.col2 = t2.col2
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2 ;
INSERT INTO T3
SELECT col1, col2
FROM MERGE_OUT
WHERE ACTION_OUT ='UPDATE';
Avertissement
NOTE : Comme le nom du modèle l’indique, cela concerne ONLY les cas où l’insertion est accompagnée d’une sélection… dont le corps contient une instruction MERGE.
Problèmes connus¶
1. Éléments de syntaxe nécessitant un mappage particulier :
[INTO] : Ce mot-clé est obligatoire dans Snowflake et doit être ajouté s’il n’est pas présent.
[DEFAULT VALUES] : Insère la valeur par défaut dans toutes les colonnes spécifiées dans l’insertion. Doit être transformé en VALUES (DEFAULT, DEFAULT, …), la quantité de DEFAULTs ajoutés est égale au nombre de colonnes que l’insertion modifiera. Pour l’instant, un avertissement a été ajouté.
SQL Server
INSERT INTO exampleTable DEFAULT VALUES;
#### Snowflake
!!!RESOLVE EWI!!! /*** SSC-EWI-0073 - PENDING FUNCTIONAL EQUIVALENCE REVIEW FOR 'INSERT WITH DEFAULT VALUES' NODE ***/!!!
INSERT INTO exampleTable DEFAULT VALUES;
2. Éléments de syntaxe non pris en charge ou non pertinents :
[TOP (expression) [PERCENT]] : Indique la quantité ou le pourcentage de lignes qui seront insérées. Non pris en charge.
[rowset_fonction_limited] : Il s’agit soit de OPENQUERY(), soit de OPENROWSET(), utilisé pour lire des données à partir de serveurs distants. Non pris en charge.
[WITH table_hint_limited] : Elles sont utilisées pour obtenir des verrous en lecture/écriture sur les tables. Non pertinent pour Snowflake.
[<OUTPUT Clause>] : Spécifie une table ou un jeu de résultats dans lequel les lignes insérées seront également insérées. Non pris en charge.
[execute_statement] : Peut être utilisé pour exécuter une requête afin d’obtenir des données. Non pris en charge.
[dml_table_source] : Un jeu de résultats temporaire généré par la clause OUTPUT d’une autre instruction DML. Non pris en charge.
3. Le cas DELETE n’est pas envisagé.
Pour le modèle INSERT avec Table DML Factor avec MERGE comme modèle DML, le cas DELETE n’est pas pris en compte dans la solution. Par conséquent, si l’instruction de fusion du code source contient le cas DELETE, veuillez tenir compte du fait qu’elle pourrait ne pas fonctionner comme prévu.
EWIs connexes¶
SSC-EWI-0073 : En attente de l’examen de l’équivalence fonctionnelle.
SSC-FDM-TS0026 : Le cas DELETE n’est pas pris en compte.
Fusionner¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Comparaison des syntaxes¶
Syntaxe de Snowflake SQL :
MERGE
INTO <target_table>
USING <source>
ON <join_expr>
{ matchedClause | notMatchedClause } [ ... ]
Syntaxe Transact-SQL :
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
Exemple¶
Étant donné le code source suivant :
MERGE
INTO
targetTable WITH(KEEPIDENTITY, KEEPDEFAULTS, HOLDLOCK, IGNORE_CONSTRAINTS, IGNORE_TRIGGERS, NOLOCK, INDEX(value1, value2, value3)) as tableAlias
USING
tableSource AS tableAlias2
ON
mergeSetCondition > mergeSetCondition
WHEN MATCHED BY TARGET AND pi.Quantity - src.OrderQty >= 0
THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list)
OPTION(RECOMPILE);
Vous pouvez vous attendre à obtenir un résultat similaire au suivant :
MERGE INTO targetTable as tableAlias
USING tableSource AS tableAlias2
ON mergeSetCondition > mergeSetCondition
WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN
UPDATE SET
pi.Quantity = pi.Quantity - src.OrderQty
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list);
EWIs connexes¶
SSC-EWI-0021 : Syntaxe non prise en charge par Snowflake.
Sélectionner¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Description¶
Permet de sélectionner une ou plusieurs lignes ou colonnes d’une ou plusieurs tables dans SQL Server.
Pour plus d’informations sur SQL Server Select, cliquez ici.
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY <order_by_expression> ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
Échantillons de modèles de sources ¶
SELECT WITH COLUMN ALIASES¶
L’exemple suivant montre comment utiliser les alias de colonne dans Snowflake. Les deux premières colonnes, issues du code SQL Server, sont censées être transformées d’une forme d’affectation en une forme normalisée à l’aide du mot-clé AS. Les troisième et quatrième colonnes utilisent des formats Snowflake valides.
SQL Server
SELECT
MyCol1Alias = COL1,
MyCol2Alias = COL2,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM TABLE1;
Snowflake
SELECT
COL1 AS MyCol1Alias,
COL2 AS MyCol2Alias,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM
TABLE1;
SELECT TOP¶
Le cas de base de SQL Server Select Top est pris en charge par Snowflake. Cependant, il existe trois autres cas qui ne sont pas pris en charge. Vous pouvez les consulter dans la section Problèmes connus.
SQL Server
SELECT TOP 1 * from ATable;
Snowflake
SELECT TOP 1
*
from
ATable;
SELECT INTO¶
L’exemple suivant montre que SELECT INTO est transformé en CREATE TABLE AS, parce que dans Snowflake il n’y a pas d’équivalent pour SELECT INTO et que pour créer une table basée sur une requête, il faut utiliser CREATE TABLE AS.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1;
Un autre cas consiste à inclure des opérateurs d’ensemble tels que EXCEPT et INTERSECT. La transformation est fondamentalement la même que la précédente.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1
EXCEPT
SELECT * FROM TABLE2
INTERSECT
SELECT * FROM TABLE3;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1
EXCEPT
SELECT
*
FROM
TABLE2
INTERSECT
SELECT
*
FROM
TABLE3;
Problèmes connus¶
Arguments supplémentaires SELECT TOP¶
Comme les mots-clés PERCENT et WITH TIES affectent le résultat et qu’ils ne sont pas pris en charge par Snowflake, ils seront commentés et ajoutés en tant qu’erreurs.
SQL Server
SELECT TOP 1 PERCENT * from ATable;
SELECT TOP 1 WITH TIES * from ATable;
SELECT TOP 1 PERCENT WITH TIES * from ATable;
Snowflake
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT FOR¶
La clause FOR n’étant pas prise en charge par Snowflake, elle est commentée et ajoutée en tant qu’erreur lors de la transformation.
SQL Server
SELECT column1, column2 FROM my_table FOR XML PATH('');
Snowflake
SELECT
--** SSC-FDM-TS0016 - XML COLUMNS IN SNOWFLAKE MIGHT HAVE A DIFFERENT FORMAT **
FOR_XML_UDF(OBJECT_CONSTRUCT('column1', column1, 'column2', column2), '')
FROM
my_table;
SELECT OPTION¶
La clause OPTION n’est pas prise en charge par Snowflake. Elle sera commentée et ajoutée en tant qu’avertissement lors de la transformation.
Avertissement
Notez que l’instruction OPTION a été supprimée de la transformation parce qu’elle n’est pas pertinente ou n’est pas nécessaire dans Snowflake.
SQL Server
SELECT column1, column2 FROM my_table OPTION (HASH GROUP, FAST 10);
Snowflake
SELECT
column1,
column2
FROM
my_table;
SELECT WITH¶
La clause WITH n’est pas prise en charge par Snowflake. Elle sera commentée et ajoutée en tant qu’avertissement lors de la transformation.
Avertissement
Notez que l’instruction WITH(NOLOCK, NOWAIT) a été supprimée de la transformation car elle n’est pas pertinente ou n’est pas nécessaire dans Snowflake.
SQL Server
SELECT AValue from ATable WITH(NOLOCK, NOWAIT);
Snowflake
SELECT
AValue
from
ATable;
EWIs connexes¶
SSC-EWI-0040 : Instruction non prise en charge.
SSC-FDM-TS0016 : Les colonnes XML dans Snowflake peuvent avoir un format différent
Opérateurs Set¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Les opérateurs d’ensemble dans TSQL et Snowflake présentent la même syntaxe et les mêmes scénarios pris en charge (EXCEPT, INTERSECT, UNION et UNION ALL), à l’exception de MINUS qui n’est pas pris en charge dans TSQL, ce qui donne le même code lors de la conversion.
SELECT LastName, FirstName FROM employees
UNION ALL
SELECT FirstName, LastName FROM contractors;
SELECT ...
INTERSECT
SELECT ...
SELECT ...
EXCEPT
SELECT ...
Truncate¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Code source
TRUNCATE TABLE TABLE1;
Code traduit
TRUNCATE TABLE TABLE1;
EWIs connexes¶
Pas d’EWIs connexes.
Mettre à jour¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Certaines parties du code de sortie sont omises pour des raisons de clarté.
Description¶
Modifie les données existantes dans une table ou une vue de SQL Server. Pour plus d’informations sur la mise à jour du serveur SQL, cliquez ici.
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
Échantillons de modèles de sources ¶
UPDATE de base¶
La conversion pour une instruction ordinaire UPDATE est très simple. Comme la structure de base UPDATE est prise en charge par défaut dans Snowflake, les valeurs aberrantes sont les parties où vous allez constater des différences ; vérifiez-les dans la section Problèmes connus.
SQL Server¶
Update UpdateTest1
Set Col1 = 5;
Snowflake
Update UpdateTest1
Set
Col1 = 5;
Produits cartésiens¶
SQL Server autorise l’ajout de références circulaires entre la table cible de l’instruction de mise à jour et la clause FROM / Lors de l’exécution, l’optimiseur de base de données supprime tout produit cartésien généré. Dans le cas contraire, Snowflake n’optimise actuellement pas ce scénario, produisant un produit cartésien qui peut être vérifié dans le plan d’exécution.\
Pour résoudre ce problème, s’il existe un JOIN dont l’une des tables est identique à la cible de la mise à jour, cette référence est supprimée et ajoutée à la clause WHERE, et elle est utilisée pour simplement filtrer les données et éviter d’effectuer une opération d’ensemble.
SQL Server¶
UPDATE [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY]
SET
BusinessEntityID = b.BusinessEntityID ,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY] AS a
RIGHT OUTER JOIN [HumanResources].[EmployeeDepartmentHistory] AS b
ON a.BusinessEntityID = b.BusinessEntityID and a.ShiftID = b.ShiftID;
Snowflake
UPDATE HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY a
SET
BusinessEntityID = b.BusinessEntityID,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM
HumanResources.EmployeeDepartmentHistory AS b
WHERE
HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.BusinessEntityID = b.BusinessEntityID(+)
AND HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.ShiftID = b.ShiftID(+);
Problèmes connus¶
Clause OUTPUT¶
La clause OUTPUT n’est pas prise en charge par Snowflake.
SQL Server¶
Update UpdateTest2
Set Col1 = 5
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
Snowflake
Update UpdateTest2
Set
Col1 = 5
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
CTE¶
La clause WITH CTE est déplacée vers la requête interne dans l’instruction de mise à jour pour être prise en charge par Snowflake.
SQL Server¶
With ut as (select * from UpdateTest3)
Update x
Set Col1 = 5
from ut as x;
Snowflake
UPDATE UpdateTest3
Set
Col1 = 5
FROM
(
WITH ut as (select
*
from
UpdateTest3
)
SELECT
*
FROM
ut
) AS x;
Clause TOP¶
La clause TOP n’est pas prise en charge par Snowflake.
SQL Server¶
Update TOP(10) UpdateTest4
Set Col1 = 5;
Snowflake
Update
-- !!!RESOLVE EWI!!! /*** SSC-EWI-0021 - TOP CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
-- TOP(10)
UpdateTest4
Set
Col1 = 5;
WITH TABLE HINT LIMITED¶
La clause Update WITH n’est pas prise en charge par Snowflake.
SQL Server¶
Update UpdateTest5 WITH(TABLOCK)
Set Col1 = 5;
Snowflake
Update UpdateTest5
Set
Col1 = 5;
EWIs connexes¶
SSC-EWI-0021 : Syntaxe non prise en charge par Snowflake.
Alternative pour UPDATE avec JOIN¶
Les informations de cette section, en cours de modification, sont sujettes à modification.
Description
Le modèle UPDATE FROM est utilisé pour mettre à jour les données en fonction des données provenant d’autres tables. La documentation SQLServer fournit un échantillon simple.
Examinez la syntaxe SQL Server suivante de la documentation.
Syntaxe SQL Server
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: La table ou la vue que vous mettez à jour.SET: Spécifie les colonnes et leurs nouvelles valeurs. La clauseSETattribue une nouvelle valeur (ou expression) à une ou plusieurs colonnes.FROM: Utilisé pour spécifier une ou plusieurs tables sources (comme une jointure). Il permet de définir d’où proviennent les données pour effectuer la mise à jour.WHERE: Spécifie quelles lignes doivent être mises à jour en fonction de la ou des conditions. Sans cette clause, toutes les lignes de la table seraient mises à jour.OPTION (query_hint): Spécifie les indices pour l’optimisation des requêtes.
Syntaxe Snowflake
La syntaxe Snowflake peut également être consultée dans la documentation Snowflake.
Note
Snowflake ne prend pas en charge la clause JOINs dans UPDATE.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
[ WHERE <condition> ]
Paramètres requis
_
target_table :_spécifie la table à mettre à jour._
col_name :spécifie le nom d’une colonne dans _target_table. Ne pas inclure le nom de la table. Par exemple,UPDATE t1 SET t1.col = 1n’est pas valable._
value:spécifie la nouvelle valeur à mettre en ensemble dans _col_name.
Paramètres facultatifs
FROM``_additional_tables :_ Spécifie une ou plusieurs tables à utiliser pour sélectionner les lignes à mettre à jour ou pour définir de nouvelles valeurs. Notez que la répétition de la table cible entraîne une auto-jonctionWHERE``_condition :_L’expression qui spécifie les lignes de la table cible à mettre à jour. Par défaut : aucune valeur (toutes les lignes de la table cible sont mises à jour)
Résumé de la traduction¶
| SQL Server JOIN type | Snowflake Best Alternative |
|---|---|
Single INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN + Agregate condition | Use subquery + IN Operation |
Single LEFT JOIN | Use subquery + IN Operation |
Multiple LEFT JOIN | Use Snowflake
|
Multiple RIGHT JOIN | Use Snowflake
|
| Single RIGHT JOIN | Use the table in the FROM clause and add filters in the WHERE clause as needed. |
Note-1 : Un JOIN simple peut utiliser la table dans la clause FROM et ajouter des filtres dans la clause WHERE selon les besoins.
Note-2 : D’autres approches peuvent inclure l’opérande (+) pour définir l’adresse JOINs.
Échantillons de modèles de sources ¶
Données de configuration¶
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
);
CREATE OR REPLACE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
Data Insertion for samples
-- Insert Customer Data
INSERT INTO Customers (CustomerID, CustomerName) VALUES (1, 'John Doe');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (2, 'Jane Smith');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (3, 'Alice Johnson');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (4, 'Bob Lee');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (5, 'Charlie Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (6, 'David White');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (7, 'Eve Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (8, 'Grace Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (9, 'Hank Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (10, 'Ivy Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (11, 'Jack Grey');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (12, 'Kim Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (13, 'Leo Purple');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (14, 'Mona Pink');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (15, 'Nathan Orange');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (16, 'Olivia Cyan');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (17, 'Paul Violet');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (18, 'Quincy Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (19, 'Rita Silver');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (20, 'Sam Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (21, 'Tina Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (22, 'Ursula Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (23, 'Vince Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (24, 'Wendy Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (25, 'Xander White');
-- Insert Product Data
INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Laptop', 999.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Smartphone', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (3, 'Tablet', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (4, 'Headphones', 149.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (5, 'Monitor', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (6, 'Keyboard', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (7, 'Mouse', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (8, 'Camera', 599.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (9, 'Printer', 99.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (10, 'Speaker', 129.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (11, 'Charger', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (12, 'TV', 699.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (13, 'Smartwatch', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (14, 'Projector', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (15, 'Game Console', 399.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (16, 'Speaker System', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (17, 'Earphones', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (18, 'USB Drive', 15.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (19, 'External Hard Drive', 79.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (20, 'Router', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (21, 'Printer Ink', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (22, 'Flash Drive', 9.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (23, 'Gamepad', 34.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (24, 'Webcam', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (25, 'Docking Station', 129.99);
-- Insert Orders Data
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (1, 1, 1, 2, '2024-11-01');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (2, 2, 2, 1, '2024-11-02');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (3, 3, 3, 5, '2024-11-03');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (4, 4, 4, 3, '2024-11-04');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (5, NULL, 5, 7, '2024-11-05'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (6, 6, 6, 2, '2024-11-06');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (7, 7, NULL, 4, '2024-11-07'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (8, 8, 8, 1, '2024-11-08');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (9, 9, 9, 3, '2024-11-09');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (10, 10, 10, 2, '2024-11-10');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (11, 11, 11, 5, '2024-11-11');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (12, 12, 12, 2, '2024-11-12');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (13, NULL, 13, 8, '2024-11-13'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (14, 14, NULL, 4, '2024-11-14'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (15, 15, 15, 3, '2024-11-15');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (16, 16, 16, 2, '2024-11-16');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (17, 17, 17, 1, '2024-11-17');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (18, 18, 18, 4, '2024-11-18');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (19, 19, 19, 3, '2024-11-19');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (20, 20, 20, 6, '2024-11-20');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (21, 21, 21, 3, '2024-11-21');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (22, 22, 22, 5, '2024-11-22');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (23, 23, 23, 2, '2024-11-23');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (24, 24, 24, 4, '2024-11-24');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (25, 25, 25, 3, '2024-11-25');
Cas 1 : Mise à jour de INNER JOIN simple¶
Pour INNER JOIN, si la table est utilisée à l’intérieur des instructions FROM, elle devient automatiquement INNER JOIN. Notez qu’il existe plusieurs approches pour prendre en charge les JOINs dans les instructions UPDATE dans Snowflake. Il s’agit de l’un des modèles les plus simples pour garantir la lisibilité.
SQL Server¶
UPDATE Orders
SET Quantity = 10
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'John Doe';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Quantité |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 10
FROM
Customers C
WHERE
C.CustomerName = 'John Doe'
AND O.CustomerID = C.CustomerID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Quantité |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Autres approches :
MERGE INTO
MERGE INTO Orders O
USING Customers C
ON O.CustomerID = C.CustomerID
WHEN MATCHED AND C.CustomerName = 'John Doe' THEN
UPDATE SET O.Quantity = 10;
IN Operation
UPDATE Orders O
SET O.Quantity = 10
WHERE O.CustomerID IN
(SELECT CustomerID FROM Customers WHERE CustomerName = 'John Doe');
Cas 2 : Mise à jour de plusieurs INNER JOIN¶
SQL Server¶
UPDATE Orders
SET Quantity = 5
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerName = 'Alice Johnson' AND P.ProductName = 'Tablet';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Quantité |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 5
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Quantité |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Cas 3 : Mise à jour de plusieurs INNER JOIN avec condition d’agrégation¶
SQL Server¶
UPDATE Orders
SET Quantity = 6
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Quantité |
Prix |
|---|---|---|---|
11 |
Jack Grey |
6 |
29,99 |
18 |
Quincy Brown |
6 |
15,99 |
20 |
Sam Green |
6 |
89,99 |
22 |
Ursula Red |
6 |
9,99 |
24 |
Wendy Black |
6 |
49,99 |
Snowflake¶
UPDATE Orders O
SET Quantity = 6
WHERE O.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND O.ProductID IN (SELECT ProductID FROM Products WHERE Price < 200);
-- Select changes
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Quantité |
Prix |
|---|---|---|---|
11 |
Jack Grey |
6 |
29,99 |
18 |
Quincy Brown |
6 |
15,99 |
20 |
Sam Green |
6 |
89,99 |
22 |
Ursula Red |
6 |
9,99 |
24 |
Wendy Black |
6 |
49,99 |
Cas 4 : Mise à jour de LEFT JOIN unique¶
SQL Server¶
UPDATE Orders
SET Quantity = 13
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13;
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Quantité |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Snowflake¶
UPDATE Orders
SET Quantity = 13
WHERE OrderID IN (
SELECT O.OrderID
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13
);
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Quantité |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Note
Cette approche dans Snowflake ne fonctionnera pas car elle ne met pas à jour les lignes nécessaires :
UPDATE Orders O SET O.Quantity = 13 FROM Customers C WHERE O.CustomerID = C.CustomerID AND C.CustomerID IS NULL AND O.ProductID = 13;
Cas 5 : Mise à jour de plusieurs LEFT JOIN et RIGHT JOIN¶
Ce modèle est plus complexe. Pour traduire plusieurs LEFT JOINs, veuillez consulter le modèle suivant :
Note
LEFT JOIN et RIGHT JOIN dépendront de l’ordre de la clause FROM.
UPDATE [target_table_name]
SET [all_set_statements]
FROM [all_left_join_tables_separated_by_comma]
WHERE [all_clauses_into_the_ON_part]
SQL Server¶
UPDATE Orders
SET
Quantity = C.CustomerID
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Quantité |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Snowflake¶
UPDATE Orders O
SET O.Quantity = C.CustomerID
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Quantité |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Cas 6 : Mise à jour de INNER JOIN et LEFT JOIN mixte¶
SQL Server¶
UPDATE Orders
SET Quantity = 4
FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Quantité |
|---|---|---|
null |
null |
4 |
Snowflake¶
UPDATE Orders O
SET Quantity = 4
WHERE O.ProductID IN (SELECT ProductID FROM Products WHERE ProductName = 'Monitor')
AND O.CustomerID IS NULL;
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Quantité |
|---|---|---|
null |
null |
4 |
Cas 7 : Mise à jour de RIGHT JOIN unique¶
SQL Server¶
UPDATE O
SET O.Quantity = 1000
FROM Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 1000
FROM Customers C
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Problèmes connus¶
Comme
UPDATEdans Snowflake ne permet pas l’utilisation directe deJOINs, certains cas peuvent ne pas correspondre aux modèles décrits.
UPDATE avec LEFT et RIGHT JOIN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Avertissement
Partiellement pris en charge dans Snowflake
Description ¶
Le modèle UPDATE FROM est utilisé pour mettre à jour les données en fonction des données provenant d’autres tables. La documentation SQLServer fournit un échantillon simple.
Examinez la syntaxe SQL Server suivante de la documentation.
Syntaxe SQL Server¶
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: La table ou la vue que vous mettez à jour.SET: Spécifie les colonnes et leurs nouvelles valeurs. La clauseSETattribue une nouvelle valeur (ou expression) à une ou plusieurs colonnes.FROM: Utilisé pour spécifier une ou plusieurs tables sources (comme une jointure). Il permet de définir d’où proviennent les données pour effectuer la mise à jour.WHERE: Spécifie quelles lignes doivent être mises à jour en fonction de la ou des conditions. Sans cette clause, toutes les lignes de la table seraient mises à jour.OPTION (query_hint): Spécifie les indices pour l’optimisation des requêtes.
Syntaxe Snowflake¶
La syntaxe Snowflake peut également être consultée dans la documentation Snowflake.
Note
Snowflake ne prend pas en charge la clause JOINs dans UPDATE.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
Paramètres requis
_
target_table :_spécifie la table à mettre à jour._
col_name :spécifie le nom d’une colonne dans _target_table. Ne pas inclure le nom de la table. Par exemple,UPDATE t1 SET t1.col = 1n’est pas valable._
value:spécifie la nouvelle valeur à mettre en ensemble dans _col_name.
Paramètres facultatifs
FROM``_additional_tables :_ Spécifie une ou plusieurs tables à utiliser pour sélectionner les lignes à mettre à jour ou pour définir de nouvelles valeurs. Notez que la répétition de la table cible entraîne une auto-jonctionWHERE``_condition :_L’expression qui spécifie les lignes de la table cible à mettre à jour. Par défaut : aucune valeur (toutes les lignes de la table cible sont mises à jour)
Résumé de la traduction¶
Comme expliqué dans la description de la grammaire, il n’existe pas de solution équivalente directe pour JOINs à l’intérieur de la classe UPDATE. Pour cette raison, l’approche pour transformer ces instructions consiste à ajouter l’opérateur (+) sur la colonne qui, logiquement, ajoutera les données requises dans la table. Cet opérateur (+) est ajouté aux cas dans lesquels les tables sont référencées dans la section LEFT/RIGHT JOIN.
Notez que d’autres langues utilisent cet opérateur (+) et que la position de l’opérateur peut déterminer le type de jointure. Dans ce cas de Snowflake, ce n’est pas la position qui détermine le type de jointure, mais l’association avec les tables et les colonnes logiquement nécessaires.
Même s’il existe d’autres alternatives comme la clause MERGE ou les usages d’une CTE ; ces alternatives ont tendance à devenir difficiles à lire lorsqu’il y a des requêtes complexes, et à s’étendre.
Échantillons de modèles de sources ¶
Données de configuration¶
CREATE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
);
CREATE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
);
CREATE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
);
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
CREATE OR REPLACE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
LEFT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM GenericTable1 T1
LEFT JOIN GenericTable2 T2 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4
LEFT JOIN GenericTable3 T3 ON
T3.Col1 = T2.Col5 AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM
GenericTable2 T2,
GenericTable3 T3
WHERE
T2.Col1(+) COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2(+) = T1.Col2
AND T2.Col3(+) = T1.Col3
AND T2.Col4(+) = T1.Col4
AND T3.Col1(+) = T2.Col5
AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
RIGHT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5
FROM GenericTable2 T2
RIGHT JOIN GenericTable1 T1 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4;
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5
FROM
GenericTable2 T2,
GenericTable1 T1
WHERE
T2.Col1 COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2 = T1.Col2(+)
AND T2.Col3 = T1.Col3(+)
AND T2.Col4 = T1.Col4(+);
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Problèmes connus¶
Il se peut que certains modèles ne puissent être traduits en raison de différences de logique.
Si votre modèle de requête s’applique, passez en revue les lignes non déterministes : « Lorsqu’une clause FROM contient un conteneur JOIN entre des tables (par exemple
t1ett2), une ligne cible danst1peut être jointe (c’est-à-dire correspondre) à plus d’une ligne dans la tablet2. Dans ce cas, la ligne cible est appelée ligne à jointures multiples. Lors de la mise à jour d’une ligne multi-joints, le paramètre de session ERROR\ON_NONDETERMINISTIC_UPDATE contrôle le résultat de la mise à jour » (documentation Snowflake).