- Categories:
MATCH_
Recognizes matches of a pattern in a set of rows. MATCH_RECOGNIZE accepts a set of rows (from a table,
view, subquery, or other source) as input, and returns all matches for a given row pattern within this
set. The pattern is defined similarly to a regular expression.
The clause can return either:
- All the rows belonging to each match.
- One summary row per match.
MATCH_RECOGNIZE is typically used to detect events in time series. For example, MATCH_RECOGNIZE can search a
stock price history table for shapes like V (down followed by up) or W (down, up, down, up).
MATCH_RECOGNIZE is an optional subclause of the FROM clause.
Note
You cannot use the MATCH_RECOGNIZE clause in a recursive common table expression (CTE).
Syntax¶
Required subclauses¶
DEFINE: Defining symbols¶
Symbols (also known as “pattern variables”) are the building blocks of the pattern.
A symbol is defined by an expression. If the expression evaluates to true for a row, the symbol is assigned to that row. A row can be assigned multiple symbols.
Symbols that are not defined in the DEFINE clause, but are used in the pattern, are always assigned to all
rows. Implicitly, they are equivalent to the following example:
Patterns are defined based on symbols and operators.
PATTERN: Specifying the pattern to match¶
The pattern defines a valid sequence of rows that represents a match. The pattern is defined like a regular expression (regex) and is built from symbols, operators, and quantifiers.
For example, suppose that symbol S1 is defined as stock_price < 55, and symbol S2 is defined
as stock price > 55. The following pattern specifies a sequence of rows in which the stock price increased
from less than 55 to greater than 55:
The following is a more complex example for a pattern definition:
The following section describes the individual components of this pattern in detail.
Note
MATCH_RECOGNIZE uses backtracking to match patterns. As is the case with other regular expression engines that use backtracking, some combinations of patterns and data to match can take a long time to execute, which can result in high computation costs.
To improve performance, define a pattern that is as specific as possible:
- Make sure that each row matches only one symbol or a small number of symbols
- Avoid using symbols that match every row (e.g. symbols not in the
DEFINEclause or symbols that are defined as true) - Define an upper limit for quantifiers (e.g.
{,10}instead of*).
For example, the following pattern can result in increased costs if no rows match:
If there is an upper limit to the number of rows that you want to match, you can specify that limit in the quantifiers to
improve performance. In addition, rather than specifying that you want to find any_symbol that follows symbol1, you can
look for a row that is not symbol1 (not_symbol1, in this example);
In general, you should monitor the query execution time to verify that the query is not taking longer than expected.
- Symbols:
A symbol matches to a row that symbol was assigned to. The following symbols are available:
-
symbol. For example,S1, … ,S4Those are symbols that were defined in theDEFINEsubclause and are evaluated per row. (These can also include symbols that were not defined and are automatically assigned to all rows.) -
^(Start of partition.) This is a virtual symbol that denotes the start of a partition and has no row associated with it. You can use it to require a match to start only at the beginning of a partition.For an example, see Matching Patterns Relative to the Beginning or End of a Partition.
-
$(End of partition.) This is a virtual symbol that denotes the end of a partition and has no row associated with it. You can use it to require a match to end only at the end of a partition.For an example, see Matching Patterns Relative to the Beginning or End of a Partition.
- Quantifiers:
A quantifier can be placed following a symbol or operation. A quantifier denotes the minimum and maximum number of occurrences of the associated symbol or operation. The following quantifiers are available:
Quantifier Meaning +1 or more. For example, ( {- S3 -} S4 )+.*0 or more. For example, S2*?.?0 or 1. {n}Exactly n. {n,}n or more. {,m}0 to m. {n, m}n to m. For example, PERMUTE(S1, S2){1,2}.
By default, quantifiers are in “greedy mode”, which means they try to match the maximum quantity if possible. To put a
quantifier into “reluctant mode”, in which the quantifier tries to match the minimum quantity if possible,
place a ? after the quantifier (e.g. S2*?).
- Operators:
Operators specify in which order symbols or other operations should occur in the sequence of rows to form a valid match. The following operators are available:
Operator Meaning ... ...(space)Concatenation. Specifies that a symbol or operation should follow another one. For example, S1 S2means that the condition defined forS2should occur after the condition defined forS1.{- ... -}Exclusion. Excludes the contained symbols or operations from the output. For example, {- S3 -}excludes operatorS3from the output. Excluded rows will not appear in the output, but will be included in the evaluation ofMEASURESexpressions.( ... )Grouping. Used to override the precedence of an operator or to apply the same quantifier for symbols or operations in the group. In this example, the quantifier +applies to the sequence{- S3 -} S4, not merelyS4.PERMUTE(..., ...)Permutation. Matches any permutation of the specified patterns. For example, PERMUTE(S1, S2)matches eitherS1 S2orS2 S1.PERMUTE()takes an unlimited number of arguments.... | ...Alternative. Specifies that either the first symbol or operation or the other one should occur. For example, ( S3 S4 ) | PERMUTE(S1, S2). The alternative operator has precedence over the concatenation operator.
Optional subclauses¶
ORDER BY: Sorting the rows before matching¶
{ORDER BY orderItem1 [ , orderItem2 ... ]}Where:
Define the order of the rows as you would for window functions. This is the order in which the individual rows of each partition are passed to the
MATCH_RECOGNIZEoperator.For more information, see Partitioning and Sorting the Rows.
PARTITION BY: Partitioning the rows into windows¶
{PARTITION BY <expr1> [ , <expr2> ... ]}Partition the input set of rows as you would for window functions.
MATCH_RECOGNIZEperforms matching individually for each resulting partition.Partitioning not only groups rows that are related to each other, but also leverages Snowflake’s distributed data processing capability because separate partitions can be processed in parallel.
For more information about partitioning, see Partitioning and Sorting the Rows.
MEASURES: Specifying additional output columns¶
“Measures” are optional additional columns that are added to the output of the MATCH_RECOGNIZE operator.
The expressions in the MEASURES subclause have the same capabilities as the expressions in the DEFINE
subclause. For further information, see Symbols.
Within the MEASURES subclause, the following functions specific to MATCH_RECOGNIZE are available:
MATCH_NUMBER()Returns the sequential number of the match. The MATCH_NUMBER starts from 1, and is incremented for each match.MATCH_SEQUENCE_NUMBER()Returns the row number within a match. The MATCH_SEQUENCE_NUMBER is sequential and starts from 1.CLASSIFIER()Returns a TEXT value that contains the symbol that the respective row matched. For example, if a row matched the symbolGT75, then theCLASSIFIERfunction returns the string “GT75”.
Note
When specifying measures, remember the restrictions mentioned in the Limitations on window functions used in DEFINE and MEASURES section.
ROW(S) PER MATCH: Specifying the rows to return¶
Specifies which rows are returned for a successful match. This subclause is optional.
ALL ROWS PER MATCH: Return all rows in the match.ONE ROW PER MATCH: Return one summary row for each match, regardless of how many rows are in the match. This is the default.
Be aware of the following special cases:
-
Empty Matches: An empty match happens if a pattern is able to match against zero rows. For instance, if the pattern is defined as
A*and the first row at the beginning of a matching attempt is assigned to symbolB, then an empty match including only that row is generated, because the*quantifier in theA*pattern allows 0 occurrences ofAto be treated as a match. TheMEASURESexpressions are evaluated differently for this row:- The CLASSIFIER function returns NULL.
- Window functions return NULL.
- The COUNT function returns 0.
-
Unmatched Rows: If a row was not matched against the pattern, it is called an unmatched row.
MATCH_RECOGNIZEcan be configured to return unmatched rows, too. For unmatched rows, expressions in theMEASURESsubclause return NULL.
-
Exclusions
The exclusion syntax
({- ... -})in the pattern definition allows users to exclude certain rows from the output. If all matched symbols in the pattern were excluded, no row is generated for that match ifALL ROWS PER MATCHwas specified. Note that the MATCH_NUMBER is incremented anyway. Excluded rows are not part of the result, but are included for the evaluation ofMEASURESexpressions.When using the exclusion syntax, the ROWS PER MATCH subclause can be specified as follows:
-
ONE ROW PER MATCH (default)
Returns exactly one row for each successful match. The default window function semantic for window functions in the
MEASURESsubclause isFINAL.The output columns of the
MATCH_RECOGNIZEoperator are all expressions given in thePARTITION BYsubclause and allMEASURESexpressions. All resulting rows of a match are grouped by the expressions given in thePARTITION BYsubclause and theMATCH_NUMBERusing theANY_VALUEaggregation function for all measures. Therefore, if measures evaluate to a different value for different rows of the same match, then the output is non-deterministic.Omitting the
PARTITION BYandMEASURESsubclause results in an error indicating that the result does not include any columns.For empty matches, a row is generated. Unmatched rows are not part of the output.
-
ALL ROWS PER MATCHReturns a row for each row that is part of the match, except for rows that were matched to a portion of the pattern that was marked for exclusion.
Excluded rows are still taken into account in computations in the
MEASURESsubclause.Matches might overlap based on the
AFTER MATCH SKIP TOsubclause, so the same row might appear multiple times in the output.The default window function semantic for window functions in the
MEASURESsubclause isRUNNING.The output columns of the
MATCH_RECOGNIZEoperator are the columns of the set of rows being input and the columns defined in theMEASURESsubclause.The following options are available for
ALL ROWS PER MATCH:SHOW EMPTY MATCHES (default)Add empty matches to the output. Unmatched rows are not output.OMIT EMPTY MATCHESNeither empty matches nor unmatched rows are output. However, the MATCH_NUMBER is still incremented by an empty match.WITH UNMATCHED ROWSAdds empty matches and unmatched rows to the output. If this clause is used, then the pattern must not contain exclusions.
For an example that uses exclusion to reduce irrelevant output, see Search for Patterns in Non-Adjacent Rows.
-
AFTER MATCH SKIP: Specifying where to continue after a match¶
This subclause specifies where to continue the matching after a positive match was found.
-
PAST LAST ROW (default)Continue matching after the last row of the current match.
This prevents matches that contain overlapping rows. For example, if you have a stock pattern that contains 3
Vshapes in a row, thenPAST LAST ROWfinds oneWpattern, not two. -
TO NEXT ROWContinue matching after the first row of the current match.
This allows matches that contain overlapping rows. For example, if you have a stock pattern that contains 3
Vshapes in a row, thenTO NEXT ROWfinds twoWpatterns (the first pattern is based on the first twoVshapes, and the secondWshape is based on the second and thirdVshapes; thus both patterns contain the sameV). -
TO [ { FIRST | LAST } ] <symbol>Continue matching at the first or last (default) row that was matched to the given symbol.
At least one row needs to be mapped to the given symbol or an error is raised.
If this does not skip past the first row of the current match, then an error is raised.
Usage notes¶
Expressions in DEFINE and MEASURES clauses¶
The DEFINE and MEASURES clauses allow expressions. Those expressions can be complex and can include
window functions and special navigational functions (which are a type of
window function).
In most respects, expressions in DEFINE and MEASURES follow the rules for expressions elsewhere in Snowflake
SQL syntax. However, there are some differences, which are described below:
- Window Functions:
Navigational functions allow references to other rows besides the current row. For example, to create an expression that defines a drop in price, you need to compare the price in one row to the price in another row. The navigational functions are:
-
PREV( expr [ , offset [, default ] ] )Navigate to the previous row within the current match in the MEASURES subclause.This function is currently not available in the DEFINE subclause. Instead, you can use LAG which navigates to the previous row within the current window frame.
-
NEXT( expr [ , offset [ , default ] ] )Navigate to the next row within the current window frame. This function is equivalent to LEAD. -
FIRST( expr )Navigate to the first row of the current match in the MEASURES subclause.This function is currently not available in the DEFINE subclause. Instead, you can use FIRST_VALUE which navigates to the first row of the current window frame.
-
LAST( expr )Navigate to the last row of the current window frame. This function is similar to LAST_VALUE, but for LAST the window frame is limited to the current row of the current matching attempt when LAST is used within the DEFINE subclause.
For an example that uses the navigational functions, see Returning Information About the Match.
In general, when a window function is used inside a
MATCH_RECOGNIZEclause, the window function does not require its ownOVER (PARTITION BY ... ORDER BY ...)clause. The window is implicitly determined by thePARTITION BYandORDER BYof theMATCH_RECOGNIZEclause. (However, see Limitations on window functions used in DEFINE and MEASURES for some exceptions.)In general, the window frame is also derived implicitly from the current context in which the window function is being used. The lower bound of the frame is defined as described below:
In the
DEFINEsubclause:The frame starts at the beginning of the current matching attempt except when using
LAG,LEAD,FIRST_VALUE, andLAST_VALUE.In the
MEASURESsubclause:The frame starts at the beginning of the match that was found.
The edges of the window frame can be specified by using either
RUNNINGorFINALsemantics.RUNNING:In general, the frame ends at the current row. However, the following exceptions exist:
- In the
DEFINEsubclause, forLAG,LEAD,FIRST_VALUE,LAST_VALUE, andNEXT, the frame ends at the last row of the window. - In the
MEASURESsubclause, forPREV,NEXT,LAG, andLEAD, the frame ends at the last row of the window.
In the
DEFINEsubclause,RUNNINGis the default (and the only allowed) semantic.In the
MEASURESsubclause, when theALL ROWS PER MATCHsubclause is used,RUNNINGis the default.FINAL:The frame ends at the last row of the match.
FINALis allowed only in theMEASURESsubclause. It is the default there whenONE ROW PER MATCHapplies.-
- Symbol Predicates:
Expressions within the
DEFINEandMEASURESsubclauses allow symbols as predicates for column references.The
<symbol>indicates a row that was matched, and the<column>identifies a specific column within that row.A predicated column reference means that the surrounding window function only looks at rows that were finally mapped to the specified symbol.
Predicated column references can be used outside and inside of a window function. If used outside of a window function,
<symbol>.<column>is the same asLAST(<symbol>.<column>). Inside of a window function, all column references either need to be predicated with the same symbol or are all non-predicated.The following explains how navigational-related functions behave with predicated column references:
{PREV/LAG( ... <symbol>.<column> ... , <offset>)}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>, and then goes<offset>(default is 1) rows backwards, ignoring the symbol those rows were mapped to. If the searched part of the frame does not contain a row mapped to<symbol>or the search would go beyond the edge of the frame, then NULL is returned.{NEXT/LEAD( ... <symbol>.<column> ... , <offset>)}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>, and then goes<offset>(default is 1) rows forward, ignoring the symbol those rows were mapped to. If the searched part of the frame does not contain a row mapped to<symbol>or the search would go beyond the edge of the frame, then NULL is returned.{FIRST/FIRST_VALUE( ... <symbol>.<column> ... )}Searches the window frame forwards starting from and including the first row up to and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>. If the searched part of the frame does not contain a row mapped to<symbol>, NULL is returned.{LAST/LAST_VALUE( ... <symbol>.<column> ... )}Searches the window frame backwards starting from and including the current row (or last row in case of aFINALsemantic) for the first row that was finally mapped to the specified<symbol>. If the searched part of the frame does not contain a row mapped to<symbol>, NULL is returned.
Note
Restrictions on window functions are documented in the Limitations on window functions used in DEFINE and MEASURES section.
Limitations on window functions used in DEFINE and MEASURES¶
Expressions in the DEFINE and MEASURES subclauses can include window functions. However, there are some
limitations on using window functions in these subclauses. These limitations are shown in the table below:
Function DEFINE (Running) [column/symbol.column] MEASURES (Running) [column/symbol.column] MEASURES (Final) [column/symbol.column] Column ✔ / ❌ ✔ / ❌ ✔ / ✔ PREV(…) ❌ / ❌ ✔ / ❌ ✔ / ❌ NEXT(…) ✔ / ❌ ✔ / ❌ ✔ / ❌ FIRST(…) ❌ / ❌ ✔ / ❌ ✔ / ✔ LAST(…) ✔ / ❌ ✔ / ❌ ✔ / ✔ LAG() ✔ / ❌ ✔ / ❌ ✔ / ❌ LEAD() ✔ / ❌ ✔ / ❌ ✔ / ❌ FIRST_VALUE() ✔ / ❌ ✔ / ❌ ✔ / ✔ LAST_VALUE() ✔ / ❌ ✔ / ❌ ✔ / ✔ Aggregations [1] ✔ / ❌ ✔ / ✔ ✔ / ✔ Other window functions [1] ✔ / ❌ ✔ / ❌ ✔ / ❌
The MATCH_RECOGNIZE-specific functions MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER(), and CLASSIFIER() are
currently not available in the DEFINE subclause.
Troubleshooting¶
Error message: “SELECT with no columns” when using ONE ROW PER MATCH¶
When you use the ONE ROW PER MATCH clause, only columns and expressions from the PARTITION BY and MEASURES
subclauses are allowed in the projection clause of the SELECT. If you try to use MATCH_RECOGNIZE without either a
PARTITION BY or MEASURES clause, you get an error similar to SELECT with no columns.
For more information about ONE ROW PER MATCH vs. ALL ROWS PER MATCH,
see Generating One Row for Each Match vs Generating All Rows for Each Match.
Examples¶
The topic Identifying Sequences of Rows That Match a Pattern contains many examples, including some that are simpler than
most of the examples here. If you are not already familiar with MATCH_RECOGNIZE, then you might want to read those
examples first.
Some of the examples below use the following table and data:
The following graph shows the shapes of the curves:
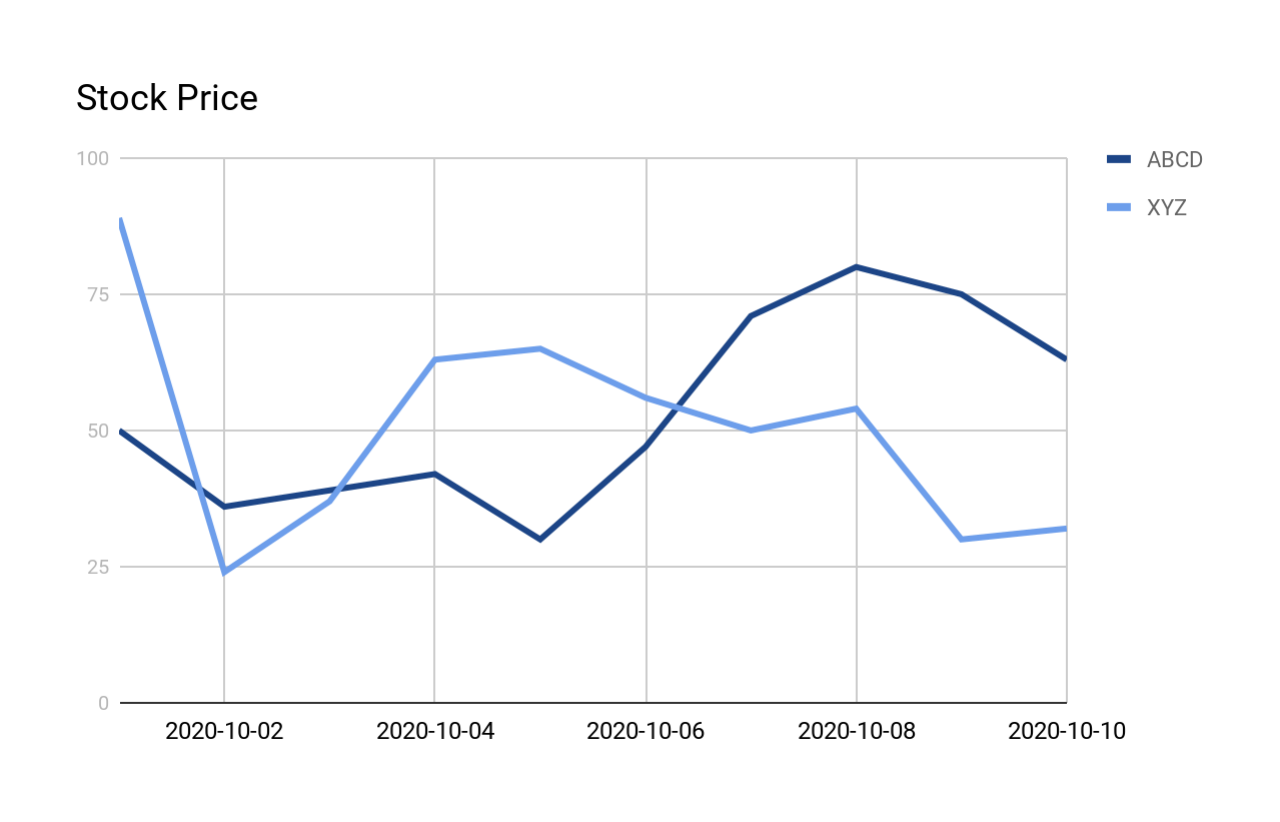
Report one summary row for each V shape¶
The following query searches for all V shapes in the previously presented stock_price_history. The output is
explained in more detail after the query and output.
The output shows one row per match (regardless of how many rows were part of the match).
The output includes the following columns:
- COMPANY: The stock symbol for the company.
- The MATCH_NUMBER is a sequential number identifying which match this was within this data set (e.g. the first match has MATCH_NUMBER 1, the second match has MATCH_NUMBER 2, etc.). If the data was partitioned, then the MATCH_NUMBER is the sequential number within the partition (in this example, for each company/stock).
- START_DATE: The date at which this occurrence of the pattern starts.
- END_DATE: The date at which this occurrence of the pattern ends.
- ROWS_IN_SEQUENCE: This is the number of rows in the match. For example, the first match is based on the prices measured on 4 days (October 1 through October 4), so ROWS_IN_SEQUENCE is 4.
- NUM_DECREASES: This is the number of days (within the match) that the price went down. For example, in the first match, the price went down for 1 day and then went up for 2 days, so NUM_DECREASES is 1.
- NUM_INCREASES: This is the number of days (within the match) that the price went up. For example, in the first match, the price went down for 1 day and then went up for 2 days, so NUM_INCREASES is 2.
Report all rows for all matches for one company¶
This example returns all rows within each match (not just one summary row per match). This pattern searches for rising prices of the ‘ABCD’ company:
Omit empty matches¶
This searches for price ranges above the average of the whole chart of a company. This example omits empty matches. Note, however, that empty matches nonetheless increment the MATCH_NUMBER:
Demonstrate the WITH UNMATCHED ROWS option¶
This example demonstrates the WITH UNMATCHED ROWS option. Like the
Omit empty matches example above, this example searches for price ranges
above the average price of each company’s chart. Note that the quantifier in this query is +, while the
quantifier in the previous query was *:
Demonstrate symbol predicates in the MEASURES clause¶
This example shows the use of <symbol>.<column> notation with symbol predicates: