Build a data processing pipeline using a directory table¶
Crie um pipeline de processamento de dados combinando uma tabela de diretório, que rastreia e armazena metadados no nível de arquivo em um estágio, com outros objetos Snowflake, como fluxos e tarefas.
Um fluxo registra as alterações na linguagem de manipulação de dados (DML) feitas em uma tabela de diretório, tabela, tabela externa ou as tabelas subjacentes em uma exibição. Uma tarefa executa uma única ação, que pode ser um comando SQL ou uma função definida pelo usuário (UDF) extensa. É possível programar uma tarefa para ser executada periodicamente ou executar uma tarefa sob demanda.
Exemplo: criar um pipeline simples para processar PDFs¶
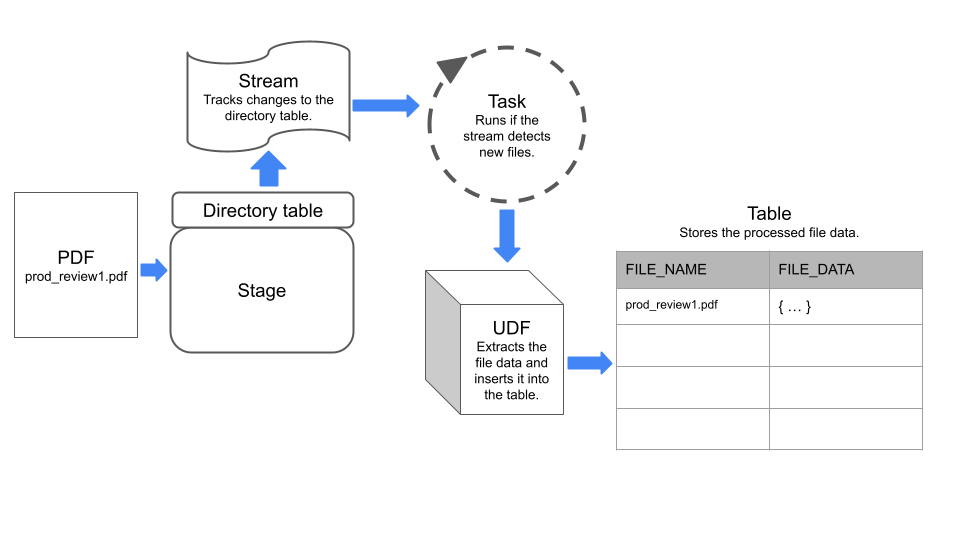
Este exemplo cria um pipeline de processamento de dados simples que faz o seguinte:
Detecta arquivos PDF adicionados a um estágio.
Extrai dados dos arquivos.
Insere os dados em uma tabela Snowflake.
O pipeline usa um fluxo para detectar alterações em uma tabela de diretórios no estágio e uma tarefa que executa uma UDF para extrair dados dos arquivos.
O diagrama a seguir resume como funciona o pipeline de exemplo:
Etapa 1: criar um estágio com uma tabela de diretório habilitada¶
Crie um fluxo na tabela de diretório especificando o estágio ao qual a tabela de diretório pertence. O fluxo rastreará as alterações na tabela de diretório. Na etapa 5 deste exemplo, usamos esse fluxo para construir uma tarefa.
CREATESTREAMmy_pdf_streamONSTAGEmy_pdf_stage;
Etapa 3: criar uma função definida pelo usuário para analisar PDFs¶
Crie uma UDF que extraia dados dos arquivos PDF. A tarefa que você criar em uma etapa posterior chamará essa UDF para processar os arquivos recém-adicionados ao estágio.
A instrução de exemplo a seguir cria uma UDF Python chamada PDF_PARSE que processa os arquivos PDF que contêm dados de revisão do produto. A UDF extrai dados de campos de formulário usando a biblioteca PyPDF2. Ela retorna um dicionário que contém os nomes e valores dos formulários como pares chave-valor.
Etapa 4: criar uma tabela para armazenar o conteúdo do arquivo¶
Em seguida, crie uma tabela onde cada linha armazene informações sobre um arquivo no estágio em colunas denominadas file_name e file_data. A tarefa que você criar em uma etapa posterior carregará os dados nessa tabela.
Crie uma tarefa agendada que verifique o fluxo em busca de novos arquivos no estágio e insira os dados do arquivo na tabela prod_reviews.
A instrução a seguir cria uma tarefa agendada usando o fluxo criado anteriormente. A tarefa usa a função SYSTEM$STREAM_HAS_DATA para verificar se o fluxo contém registros de captura de dados de alterações (CDC).
CREATEORREPLACETASKload_new_file_dataWAREHOUSE='MY_WAREHOUSE'SCHEDULE='1 minute'COMMENT='Process new files on the stage and insert their data into the prod_reviews table.'WHENSYSTEM$STREAM_HAS_DATA('my_pdf_stream')ASINSERTINTOprod_reviews(SELECTrelative_pathasfile_name,PDF_PARSE(build_scoped_file_url('@my_pdf_stage',relative_path))asfile_dataFROMmy_pdf_streamWHEREMETADATA$ACTION='INSERT');
Etapa 6: executar a tarefa para testar o pipeline¶
Para verificar se o pipeline funciona, você pode adicionar arquivos ao estágio, executar manualmente a tarefa e consultar a tabela product_reviews.
Comece adicionando alguns arquivos PDF ao estágio my_pdf_stage e depois atualize o estágio.
Você pode consultar o fluxo para verificar se ele registrou os dois arquivos PDF que adicionamos ao estágio.
SELECT*FROMmy_pdf_stream;
Agora, execute a tarefa para processar os arquivos PDF e atualizar a tabela product_reviews.
EXECUTE TASKload_new_file_data;+----------------------------------------------------------+| status ||----------------------------------------------------------|| Task LOAD_NEW_FILE_DATA is scheduled to run immediately. |+----------------------------------------------------------+1Row(s)produced.TimeElapsed: 0.178s
Consulte a tabela product_reviews para ver se a tarefa adicionou uma linha para cada arquivo PDF.
Por fim, você pode criar uma exibição que analise os objetos da coluna FILE_DATA em colunas separadas. Você pode então consultar a exibição para analisar e trabalhar com o conteúdo do arquivo.
CREATEORREPLACEVIEWprod_review_info_vASWITHfile_dataAS(SELECTfile_name,parse_json(file_data)ASfile_dataFROMprod_reviews)SELECTfile_name,file_data:FirstName::varcharASfirst_name,file_data:LastName::varcharASlast_name,file_data:"Middle Name"::varcharASmiddle_name,file_data:Product::varcharASproduct,file_data:"Purchase Date"::dateASpurchase_date,file_data:Recommend::varcharASrecommended,build_scoped_file_url(@my_pdf_stage,file_name)ASscoped_review_urlFROMfile_data;SELECT*FROMprod_review_info_v;+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| FILE_NAME | FIRST_NAME | LAST_NAME | MIDDLE_NAME | PRODUCT | PURCHASE_DATE | RECOMMENDED | SCOPED_REVIEW_URL ||------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|| prod_review1.pdf | John | Johnson | Michael | Tennis Shoes | 2022-03-15 | Yes | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/RZ4s%2bJLa6iHmLouHA79b94tg%2f3SDA%2bOQX01pAYo%2bl6gAxiLK8FGB%2bv8L2QSB51tWP%2fBemAbpFd%2btKfEgKibhCXN2QdMCNraOcC1uLdR7XV40JRIrB4gDYkpHxx3HpCSlKkqXeuBll%2fyZW9Dc6ZEtwF19GbnEBR9FwiUgyqWjqSf4KTmgWKv5gFCpxwqsQgofJs%2fqINOy%2bOaRPa%2b65gcnPpY2Dc1tGkJGC%2fT110Iw30cKuMGZ2HU%3d || prod_review2.pdf | Emily | Smith | Ann | Red Skateboard | 2023-01-10 | MayBe | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/g3glgIbGik3VOmgcnltZxVNQed8%2fSBehlXbgdZBZqS1iAEsFPd8pkUNB1DSQEHoHfHcWLsaLblAdSpPIZm7wDwaHGvbeRbLit6nvE%2be2LHOsPR1UEJrNn83o%2fZyq4kVCIgKeSfMeGH2Gmrvi82JW%2fDOyZJITgCEZzpvWGC9Rmnr1A8vux47uZj9MYjdiN2Hho3uL9ExeFVo8FUtR%2fHkdCJKIzCRidD5oP55m9p2ml2yHOkDJW50%3d |+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+