Automação do Snowpipe para Amazon S3¶
Este tópico fornece instruções para acionar cargas de dados do Snowpipe a partir de estágios externos no S3 automaticamente usando notificações Amazon Simple Queue Service (SQS) para um bucket S3.
A Snowflake recomenda que você envie apenas eventos suportados para o Snowpipe para reduzir custos, ruído de eventos e latência.
Suporte para a plataforma de nuvem¶
O acionamento de cargas de dados automatizadas do Snowpipe usando mensagens de evento S3 conta com o suporte por contas Snowflake hospedadas em todas as plataformas de nuvem compatíveis.
Tráfego de rede¶
Nota para clientes do Virtual Private Snowflake (VPS) e AWS PrivateLink:
Automatizar o Snowpipe usando notificações do Amazon SQS funciona bem. Entretanto, embora o armazenamento em nuvem AWS dentro de um VPC (incluindo VPS) possa se comunicar com seus próprios serviços de mensagens (Amazon SQS, Amazon Simple Notification Service), este tráfego flui entre servidores na rede segura da Amazon fora do VPC; portanto, este tráfego não é protegido pelo VPC.
Configuração de acesso seguro ao armazenamento em nuvem¶
Nota
Se você já tiver configurado o acesso seguro ao bucket S3 que armazena seus arquivos de dados, pode pular esta seção.
Esta seção descreve como usar as integrações de armazenamento para permitir que o Snowflake leia e grave dados em um bucket Amazon S3 referenciado em um estágio externo (ou seja, S3). As integrações são objetos Snowflake nomeados e de primeira classe que evitam a necessidade de passar credenciais explícitas de provedores de nuvens, tais como chaves secretas ou tokens de acesso. Os objetos de integração armazenam uma ID de usuário de gerenciamento de identidade e acesso (IAM) da AWS. Um administrador em sua organização concede ao usuário IAM da integração permissões na conta AWS.
Uma integração também pode listar buckets (e caminhos opcionais) que limitam os locais que os usuários podem especificar ao criar estágios externos que utilizam a integração.
Nota
Completar as instruções nesta seção requer permissões na AWS para criar e gerenciar políticas e funções de IAM. Se você não for um administrador AWS, peça a seu administrador AWS que complete estas tarefas.
Observe que, atualmente, o acesso ao armazenamento S3 em regiões governamentais usando uma integração de armazenamento está limitado a contas Snowflake hospedadas na AWS na mesma região governamental. Há suporte para o acesso ao seu armazenamento S3 a partir de uma conta hospedada fora da região governamental usando credenciais diretas.
O diagrama a seguir mostra o fluxo de integração para um estágio S3:
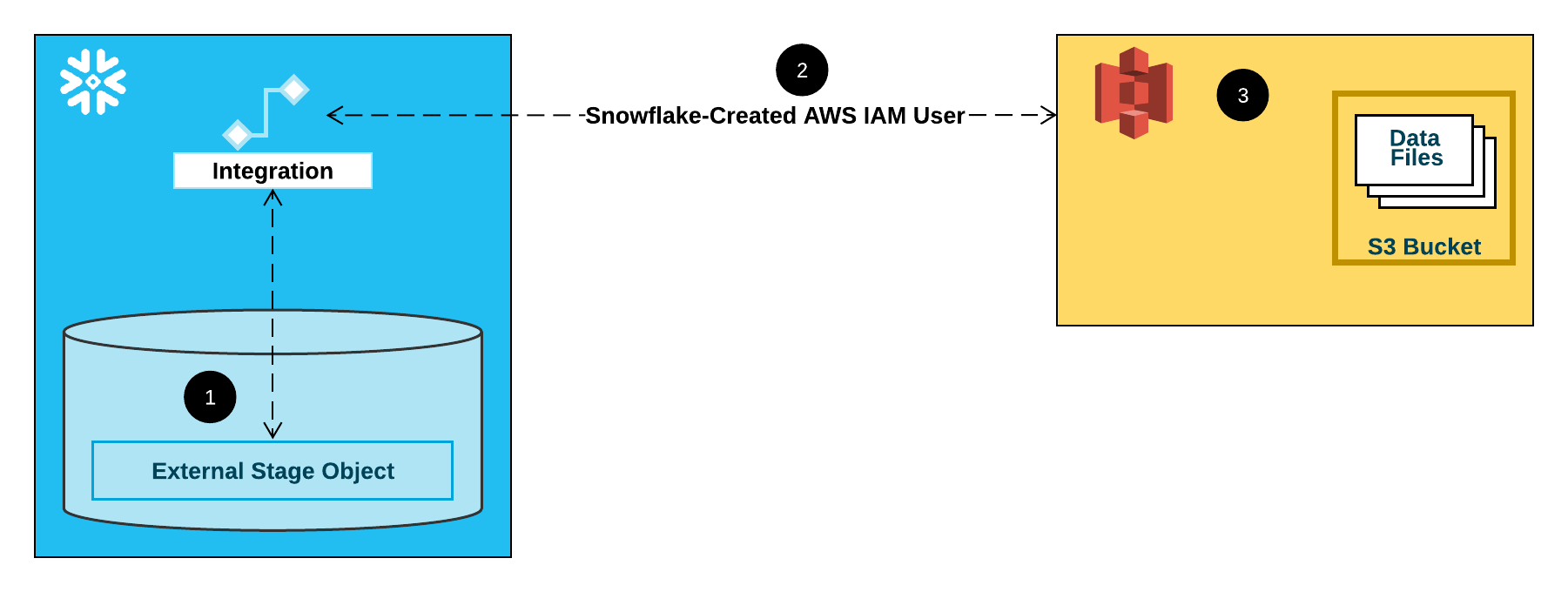
Um estágio externo (ou seja, S3) faz referência a um objeto de integração de armazenamento em sua definição.
O Snowflake associa automaticamente a integração do armazenamento com um usuário IAM do S3 criado para sua conta. O Snowflake cria um único usuário IAM que é referenciado por todas as integrações de armazenamento S3 em sua conta Snowflake.
Um administrador AWS em sua organização concede permissões ao usuário IAM para acessar o bucket referenciado na definição do estágio. Observe que muitos objetos de preparação externo podem fazer referência a diferentes buckets e caminhos e usar a mesma integração de armazenamento para autenticação.
Quando um usuário carrega ou descarrega dados de ou para um estágio, o Snowflake verifica as permissões concedidas ao usuário IAM no bucket antes de permitir ou negar o acesso.
Nota
Recomendamos esta opção, o que evita a necessidade de fornecer credenciais IAM ao acessar o armazenamento em nuvem. Consulte Configuração de acesso seguro ao Amazon S3 para opções adicionais de acesso ao armazenamento.
Etapa 1: configurar permissões de acesso para o bucket S3¶
Requisitos de controle de acesso do AWS¶
O Snowflake requer as seguintes permissões em um bucket S3 e pasta para poder acessar os arquivos na pasta (e subpastas):
s3:GetBucketLocations3:GetObjects3:GetObjectVersions3:ListBucket
Como prática recomendada, a Snowflake recomenda a criação de uma política IAM para o acesso do Snowflake ao bucket S3. Você pode então anexar a política à função e usar as credenciais de segurança geradas pela AWS para a função para acessar os arquivos no bucket.
Criação de uma política IAM¶
As seguintes instruções passo a passo descrevem como configurar as permissões de acesso para o Snowflake em seu Console de gerenciamento AWS para que você possa acessar seu bucket S3.
Faça login no Console de gerenciamento AWS.
No painel inicial, pesquise e selecione IAM.
Selecione Account settings no painel de navegação à esquerda.
Em Security Token Service (STS), na lista Endpoints, encontre a região do Snowflake onde sua conta está localizada. Se o STS status estiver inativo, mude o seletor para Active.
Selecione Policies no painel de navegação à esquerda.
Selecione Create Policy.
Para Policy editor, selecione JSON.
Adicione um documento de política que permitirá ao Snowflake acessar o bucket S3 e a pasta.
A seguinte política (em formato JSON) fornece ao Snowflake as permissões necessárias para carregar ou descarregar dados usando um único bucket e caminho de pasta.
Copie e cole o texto no editor de políticas:
Nota
Certifique-se de substituir
bucketeprefixpelo nome real do bucket e prefixo do caminho da pasta.Os Nomes de recurso da Amazon (ARN) para buckets em regiões governamentais têm um prefixo
arn:aws-us-gov:s3:::.
Nota
Definir a condição
"s3:prefix":como["*"]ou["<caminho>/*"]concede acesso a todos os prefixos no bucket ou caminho no bucket especificado, respectivamente.Observe que as políticas AWS oferecem suporte a uma variedade de diferentes casos de uso de segurança.
Selecione Next.
Insira um Policy name (por exemplo,
snowflake_access) e uma Description opcional.Selecione Create policy.
Etapa 2: crie a função IAM no AWS¶
Para configurar permissões de acesso para Snowflake no AWS Management Console, faça o seguinte:
Na seção de navegação à esquerda do painel de gerenciamento de identidade e acesso (IAM), selecione Roles.
Selecione Create role.
Selecione AWS account como o tipo de entidade confiável.
Selecione Another AWS account
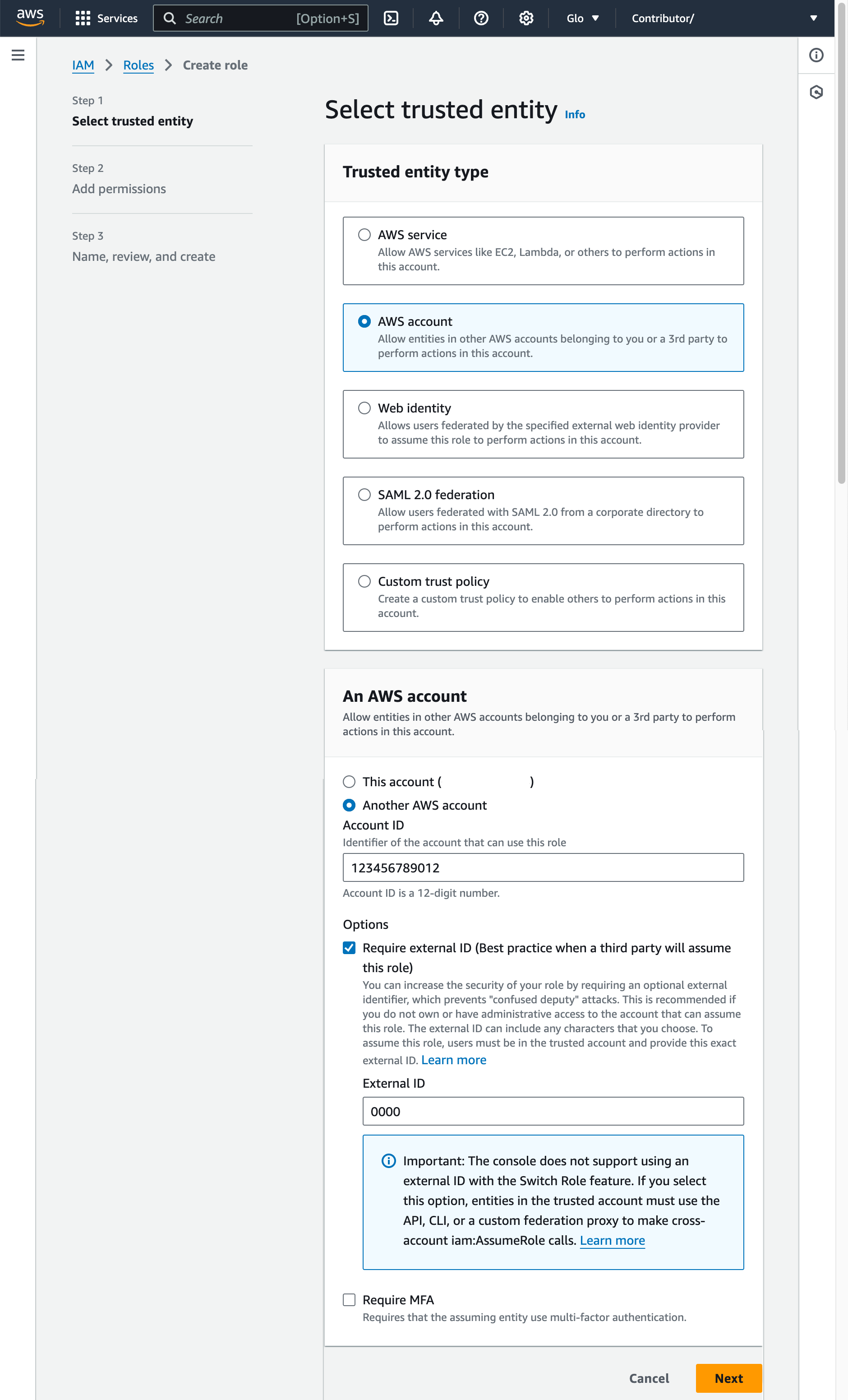
No campo Account ID, digite temporariamente sua própria ID de conta AWS. Mais tarde, você modificará a relação de confiança e concederá acesso ao Snowflake.
Selecione a opção Require external ID. Um ID externo é usado para conceder acesso aos seus recursos AWS (como buckets S3) a terceiros, como o Snowflake.
Insira um ID de espaço reservado como
0000. Em uma etapa posterior, você modificará a relação de confiança para sua função IAM e especificará o ID externo de sua integração de armazenamento.Selecione Next.
Selecione a política que você criou em Etapa 1: configure permissões de acesso ao bucket S3 (neste tópico).
Selecione Next.
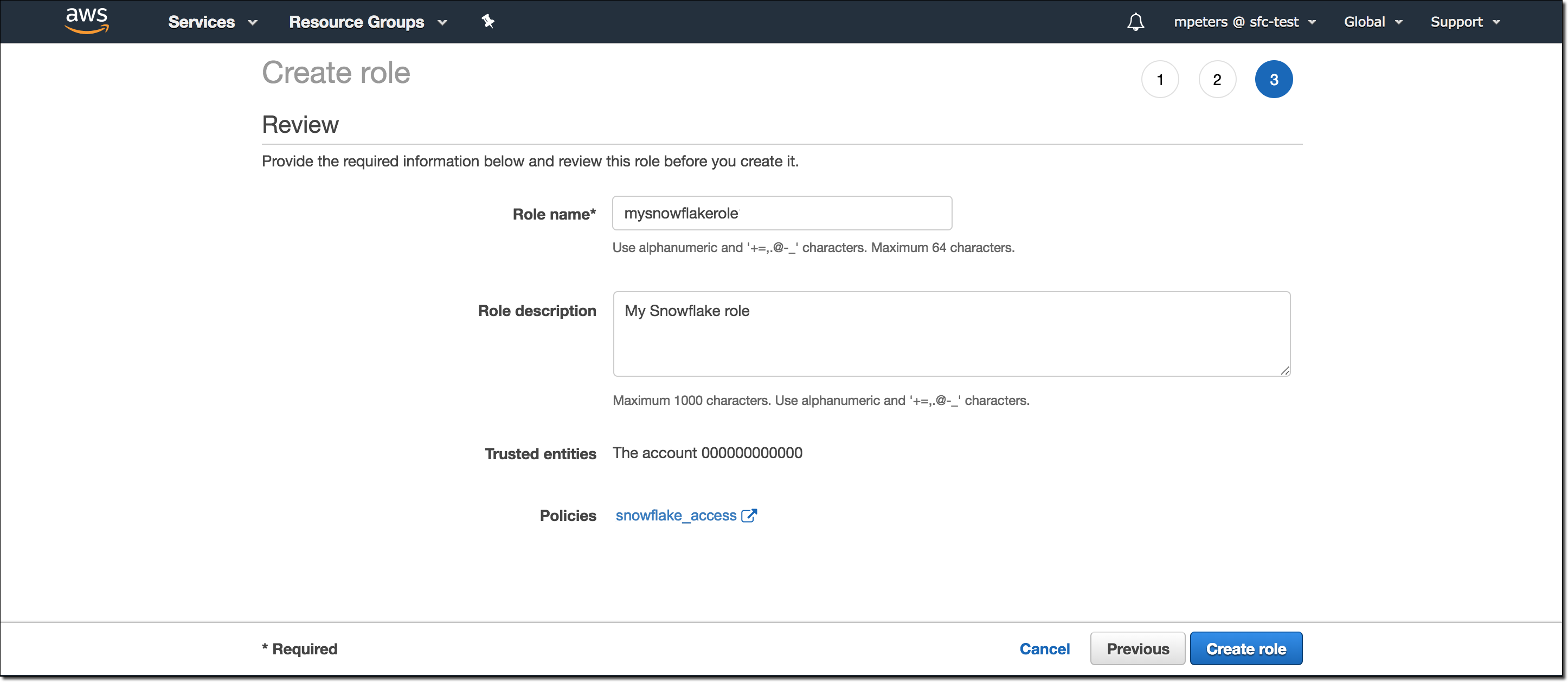
Digite um nome e descrição para a função e selecione Create role.
Agora você criou uma política IAM para um bucket, criou uma função IAM e anexou a política à função.
Na página de resumo da função, localize e registre o valor Role ARN. Na próxima etapa, você criará uma integração do Snowflake que faz referência a essa função.
Nota
O Snowflake armazena em cache as credenciais temporárias por um período que não pode exceder o tempo de expiração de 60 minutos. Se você revogar o acesso do Snowflake, os usuários podem conseguir listar arquivos e acessar dados a partir do local de armazenamento em nuvem até que o cache expire.
Etapa 3: crie uma integração de armazenamento em nuvem no Snowflake¶
Crie uma integração de armazenamento usando o comando CREATE STORAGE INTEGRATION. Uma integração de armazenamento é um objeto Snowflake que armazena um usuário de gerenciamento de identidade e acesso gerado (IAM) para seu armazenamento em nuvem S3, juntamente com um conjunto opcional de locais de armazenamento permitidos ou bloqueados (ou seja, buckets). Os administradores do provedor de nuvem em sua organização concedem permissões para os locais de armazenamento ao usuário gerado. Esta opção permite que os usuários evitem fornecer credenciais ao criar estágios ou carregar dados.
Uma única integração de armazenamento pode oferecer suporte a vários estágios externos (ou seja, S3). A URL na definição do estágio deve estar alinhada com os buckets S3 (e caminhos opcionais) especificados para o parâmetro STORAGE_ALLOWED_LOCATIONS.
Nota
Somente administradores de conta (usuários com a função ACCOUNTADMIN) ou uma função com o privilégio global CREATE INTEGRATION podem executar este comando SQL.
Onde:
integration_nameé o nome da nova integração.iam_roleé o nome do recurso da Amazon (ARN) da função que você criou na Etapa 2: crie a função IAM no AWS (neste tópico).protocolé um dos seguintes:s3refere-se ao armazenamento S3 em regiões AWS públicas fora da China.s3chinarefere-se ao armazenamento S3 em regiões AWS públicas na China.s3govrefere-se ao armazenamento S3 em regiões governamentais.
bucketé o nome de um bucket S3 que armazena seus arquivos de dados (por exemplo,mybucket). O parâmetro STORAGE_ALLOWED_LOCATIONS obrigatório e o parâmetro STORAGE_BLOCKED_LOCATIONS opcional restringem ou bloqueiam o acesso a estes buckets, respectivamente, quando os estágios que fazem referência a esta integração são criados ou modificados.pathé um caminho opcional que pode ser usado para proporcionar um controle granular sobre objetos no bucket.
O exemplo a seguir cria uma integração que permite acesso a todos os buckets da conta, mas bloqueia o acesso às pastas sensitivedata definidas.
Os estágios externos adicionais que também utilizam esta integração podem fazer referência aos buckets e caminhos permitidos:
Nota
Opcionalmente, use o parâmetro STORAGE_AWS_EXTERNAL_ID para especificar seu próprio ID externo. Você pode escolher esta opção para usar o mesmo ID externo em vários volumes externos e/ou integrações de armazenamento.
Etapa 4: recupere o usuário de AWS IAM para sua conta Snowflake¶
Para recuperar o ARN do usuário IAM que foi criado automaticamente para sua conta Snowflake, use o DESCRIBE INTEGRATION.
Onde:
integration_nameé o nome da integração que você criou em Etapa 3: Criar uma integração de armazenamento em nuvem no Snowflake (neste tópico).
Por exemplo:
Registre os valores para as seguintes propriedades:
Propriedade
Descrição
STORAGE_AWS_IAM_USER_ARNO usuário AWS IAM criado para sua conta Snowflake; por exemplo,
arn:aws:iam::123456789001:user/abc1-b-self1234. O Snowflake fornece um único usuário IAM para toda a sua conta Snowflake. Todas as integrações de armazenamento S3 na sua conta usam esse usuário IAM.STORAGE_AWS_EXTERNAL_IDO ID externo que o Snowflake usa para estabelecer uma relação de confiança com AWS. Se você não especificou um ID externo (
STORAGE_AWS_EXTERNAL_ID) ao criar a integração de armazenamento, o Snowflake gerará um ID para você usar.Você fornece esses valores na próxima seção.
Etapa 5: Conceda ao usuário IAM permissões do usuário para acessar objetos de bucket¶
As seguintes instruções passo a passo descrevem como configurar as permissões de acesso IAM ao Snowflake em seu Console de gerenciamento AWS para que você possa usar um bucket S3 para carregar e descarregar dados:
Entre no Console de Gerenciamento da AWS.
Selecione IAM.
Selecione Roles no painel de navegação à esquerda.
Selecione a função que você criou na Etapa 2: crie a função IAM no AWS (neste tópico).
Selecione a guia Trust relationships.
Selecione Edit trust policy.
Modifique o documento da política com os valores de saída DESC STORAGE INTEGRATION que você registrou na Etapa 4: recupere o usuário AWS IAM para sua conta Snowflake (neste tópico):
Documento de política da função IAM
Onde:
snowflake_user_arné o valor STORAGE_AWS_IAM_USER_ARN que você registrou.snowflake_external_idé o valor STORAGE_AWS_EXTERNAL_ID que você registrou.Neste exemplo, o valor
snowflake_external_idéMYACCOUNT_SFCRole=2_a123456/s0aBCDEfGHIJklmNoPq=.Nota
Por razões de segurança, se você criar uma nova integração de armazenamento (ou recriar uma integração de armazenamento existente usando a sintaxe CREATE OR REPLACE STORAGE INTEGRATION) sem especificar um ID externo, a nova integração tem um ID externo diferente e não poderá resolver a relação de confiança a menos que a política de confiança seja atualizada.
Selecione Update policy para salvar suas alterações.
Nota
O Snowflake armazena em cache as credenciais temporárias por um período que não pode exceder o tempo de expiração de 60 minutos. Se você revogar o acesso do Snowflake, os usuários podem ser capazes de listar arquivos e carregar dados a partir do local de armazenamento em nuvem até que o cache expire.
Nota
Você pode usar a função SYSTEM$VALIDATE_STORAGE_INTEGRATION para validar a configuração de sua integração de armazenamento.
Determinação da opção correta¶
Antes de prosseguir, determine se existe uma notificação de evento S3 para o caminho de destino (ou “prefixo”, na terminologia AWS) em seu bucket S3 onde seus arquivos de dados estão localizados. As regras da AWS proíbem a criação de notificações conflitantes para o mesmo caminho.
As seguintes opções para automatizar o Snowpipe usando o Amazon SQS têm suporte:
Opção 1. Notificação de novo evento S3: Crie uma notificação de evento para o caminho de destino em seu bucket S3. A notificação de evento informa o Snowpipe através de uma fila SQS quando os arquivos estão prontos para serem carregados.
Importante
Se existir uma notificação de evento conflitante para seu bucket S3, use a opção 2 em seu lugar.
Opção 2. Notificação de evento existente: Configure o Amazon Simple Notification Service (SNS) como um transmissor para compartilhar notificações para um determinado caminho com vários pontos de extremidade (ou “assinantes”, por exemplo, filas SQS filas ou cargas de trabalho Lambda AWS), incluindo a fila SQS do Snowflake para automação do Snowpipe. Uma notificação de evento S3 publicada por SNS informa o Snowpipe através de uma fila SQS quando os arquivos estão prontos para serem carregados.
Nota
Recomendamos esta opção se você planeja usar Replicação de histórico de carregamento, canal e estágio. Você também pode migrar da opção 1 para a opção 2 depois de criar um grupo de replicação ou failover. Para obter mais informações, consulte Migração para Amazon Simple Notification Service (SNS).
Opção 3. Configuração do Amazon EventBridge para automatizar o Snowpipe: Semelhante à opção 2, você também pode ativar o Amazon EventBridge para os buckets S3 e criar regras para enviar notificações para os tópicos SNS.
Opção 1: criação de uma notificação de novo evento S3 para automatizar o Snowpipe¶
Este tópico descreve a opção mais comum para acionar o carregamento automático de dados do Snowpipe usando notificações do Amazon SQS (Simple Queue Service) para um bucket S3. As etapas explicam como criar uma notificação de evento para o caminho de destino (ou “prefixo”, em terminologia AWS) em seu bucket S3 onde seus arquivos de dados são armazenados.
Importante
Se existir uma notificação de evento conflitante para seu bucket S3, use Opção 2: Configuração do Amazon SNS para automatizar o Snowpipe usando notificações SQS (neste tópico). As regras da AWS proíbem a criação de notificações conflitantes para o mesmo caminho de destino.
O diagrama a seguir mostra o fluxo do processo de ingestão automática do Snowpipe:
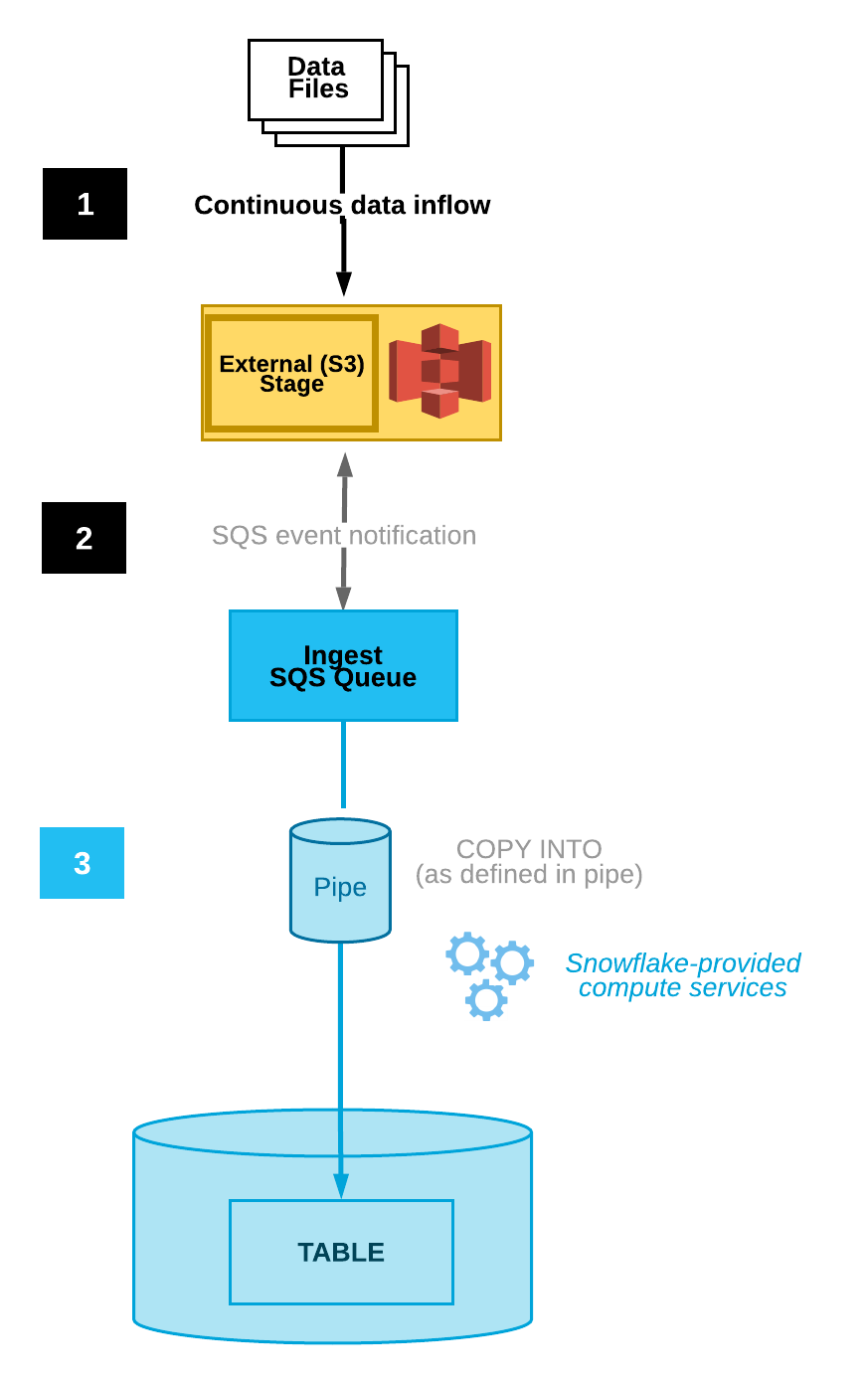
Os arquivos de dados são carregados em um estágio.
Uma notificação de evento S3 informa o Snowpipe através de uma fila SQS que os arquivos estão prontos para serem carregados. O Snowpipe copia os arquivos em uma fila.
Um warehouse virtual fornecido pelo Snowflake carrega os dados dos arquivos enfileirados na tabela de destino com base nos parâmetros definidos no canal especificado.
Nota
As instruções neste tópico presumem que uma tabela de destino já existe no banco de dados Snowflake onde seus dados serão carregados.
Etapa 1: criar um estágio (se necessário)¶
Crie um estágio externo que faça referência ao seu bucket S3 usando o comando CREATE STAGE. O Snowpipe busca seus arquivos de dados do estágio e os enfileira temporariamente antes de carregá-los na tabela de destino. Você também pode usar um estágio externo já existente.
Nota
Para configurar o acesso seguro ao local de armazenamento na nuvem, consulte Configuração de acesso seguro ao armazenamento em nuvem (neste tópico).
Para fazer referência a uma integração de armazenamento na instrução CREATE STAGE, a função deve ter o privilégio USAGE para o objeto de integração de armazenamento.
O exemplo a seguir cria um estágio chamado mystage no esquema ativo para a sessão do usuário. O URL de armazenamento em nuvem inclui o caminho files. O estágio faz referência a uma integração de armazenamento chamada my_storage_int:
Etapa 2: criar um canal com ingestão automática habilitada¶
Crie um canal usando o comando CREATE PIPE. O canal define a instrução COPY INTO <tabela> usada pelo Snowpipe para carregar os dados da fila de ingestão na tabela de destino.
O exemplo a seguir cria um canal chamado mypipe no esquema ativo para a sessão do usuário. O canal carrega os dados dos arquivos preparados no estágio mystage na tabela mytable:
O parâmetro AUTO_INGEST = TRUE especifica a leitura de notificações de eventos enviadas de um bucket S3 para uma fila SQS quando novos dados estiverem prontos para serem carregados.
Importante
Compare a referência do estágio na definição do canal com os canais existentes. Verifique se os caminhos de diretório para o mesmo bucket S3 não se sobrepõem; caso contrário, vários canais poderiam carregar o mesmo conjunto de arquivos de dados várias vezes, em uma ou mais tabelas de destino. Isto pode acontecer, por exemplo, quando vários estágios fazem referência ao mesmo bucket S3 com diferentes níveis de granularidade, como s3://mybucket/path1 e s3://mybucket/path1/path2. Neste caso de uso, se os arquivos forem preparados em s3://mybucket/path1/path2, os canais para ambos os estágios carregariam uma cópia dos arquivos.
Isto é diferente da configuração manual do Snowpipe (com ingestão automática desabilitada), que requer que os usuários enviem um conjunto de arquivos nomeado a uma API REST para enfileirar os arquivos para carregamento. Com a ingestão automática habilitada, cada canal recebe uma lista de arquivos gerada a partir das notificações de eventos S3. É necessário um cuidado adicional para evitar a duplicação de dados.
Etapa 3: configurar a segurança¶
Para cada usuário que irá executar cargas de dados contínuas usando o Snowpipe, conceder privilégios suficientes de controle de acesso aos objetos para a carga de dados (ou seja, o banco de dados, esquema e tabela de destino; o objeto de preparação e o canal).
Nota
Para seguir o princípio geral do “menor privilégio”, recomendamos a criação de um usuário e função separados a serem usados para a ingestão de arquivos usando um canal. O usuário deve ser criado com esta função padrão.
A utilização do Snowpipe requer uma função com os seguintes privilégios:
Objeto |
Privilégio |
Notas |
|---|---|---|
Canal nomeado |
OWNERSHIP |
|
Estágio nomeado |
USAGE , READ |
|
Formato de arquivo nomeado |
USAGE |
Opcional; necessário apenas se o estágio que você criou na Etapa 1: criar um estágio (se necessário) fizer referência a um formato de arquivo nomeado. |
Banco de dados de destino |
USAGE |
|
Esquema de destino |
USAGE |
|
Tabela de destino |
INSERT , SELECT |
Use o comando GRANT <privilégios> … TO ROLE para conceder privilégios à função.
Nota
Somente administradores de segurança (ou seja, usuários com a função SECURITYADMIN) ou superior, ou outra função com o privilégio CREATE ROLE para a conta e o privilégio global MANAGE GRANTS, podem criar funções e conceder privilégios.
Por exemplo, crie uma função chamada snowpipe_role que possa acessar um conjunto de objetos de banco de dados snowpipe_db.public, bem como um canal chamado mypipe; então, conceda a função a um usuário:
Etapa 4: configurar notificações de eventos¶
Configure notificações de eventos para seu bucket S3 para notificar o Snowpipe quando novos dados estiverem disponíveis para carregar. O recurso de ingestão automática depende de filas SQS para entregar notificações de eventos do S3 para o Snowpipe.
Para facilitar o uso, as filas SQS do Snowpipe são criadas e gerenciadas pelo Snowflake. A saída do comando SHOW PIPES exibe o Nome de recurso da Amazon (ARN) de sua fila SQS.
Execute o comando SHOW PIPES:
Observe o ARN da fila SQS para o estágio na coluna
notification_channel. Copie o ARN para um local conveniente.Nota
Seguindo as diretrizes do AWS, o Snowflake designa no máximo uma fila SQS por região do AWS S3. Uma fila SQS pode ser compartilhada entre vários buckets na mesma região a partir da mesma conta AWS. A fila SQS coordena as notificações para todos os canais que conectam os estágios externos do bucket S3 às tabelas de destino. Quando um arquivo de dados é carregado no bucket, todos os canais que correspondem ao caminho do diretório de estágios realizam uma carga única do arquivo em suas tabelas de destino correspondentes.
Entre no console Amazon S3.
Configure uma notificação de evento para seu bucket S3 usando as instruções fornecidas na documentação Amazon S3. Complete os campos da seguinte forma:
Name: Nome da notificação de evento (por exemplo,
Auto-ingest Snowflake).Events: Selecione a opção ObjectCreate (All).
Send to: Selecione SQS Queue a partir da lista suspensa.
SQS: Selecione Add SQS queue ARN a partir da lista suspensa.
SQS queue ARN: Cole o nome da fila SQS da saída SHOW PIPES.
Nota
Estas instruções criam uma única notificação de evento que monitora a atividade para todo o bucket S3. Esta é a abordagem mais simples. Esta notificação trata de todos os canais configurados em um nível mais granular no diretório do bucket S3. O Snowpipe carrega somente arquivos de dados como especificado nas definições de canal. Observe, entretanto, que um alto volume de notificações para atividades fora de uma definição de canal pode ter um impacto negativo na velocidade com a qual o Snowpipe filtra as notificações e toma medidas.
Alternativamente, nas etapas acima, configure um ou mais caminhos e/ou extensões de arquivo (ou prefixos e sufixos, em terminologia AWS) para filtrar a atividade de eventos. Para instruções, consulte as informações sobre filtragem de nomes de chave de objeto no tópico da documentação AWS relevante. Repita essas etapas para cada caminho ou extensão de arquivo adicional que deseja que a notificação monitore.
Observe que a AWS limita o número destas configurações de fila de notificação a um máximo de 100 por bucket S3.
Observe também que a AWS não permite configurações de fila sobrepostas (em várias notificações de eventos) para o mesmo bucket S3. Por exemplo, se uma notificação existente for configurada para s3://mybucket/load/path1, então não será possível criar outra notificação em um nível superior, tal como s3://mybucket/load, ou vice-versa.
O Snowpipe com ingestão automática está configurado!
Quando novos arquivos de dados são adicionados ao bucket S3, a notificação de evento informa o Snowpipe para carregá-los na tabela de destino definida no canal.
Etapa 5: carregar arquivos históricos¶
Para carregar qualquer lista de pendências de arquivos de dados que existiam no estágio externo antes que as notificações SQS fossem configuradas, consulte Carregamento de dados históricos.
Etapa 6: excluir arquivos preparados¶
Exclua os arquivos preparados depois de carregar os dados com sucesso e não precisar mais dos arquivos. Para obter instruções, consulte Exclusão de arquivos preparados depois que o Snowpipe carrega os dados.
Opção 2: configuração do Amazon SNS para automatizar o Snowpipe usando notificações SQS¶
Esta seção descreve como acionar o carregamento automático de dados do Snowpipe usando notificações do Amazon SQS (Simple Queue Service) para um bucket S3. Os passos explicam como configurar o Amazon Simple Notification Service (SNS) como um transmissor para publicar notificações de eventos de seu bucket S3 para múltiplos assinantes (por exemplo, filas SQS ou cargas de trabalho Lambda AWS), incluindo a fila SQS do Snowflake para automação do Snowpipe.
Nota
Estas instruções presumem que existe uma notificação de evento para o caminho de destino em seu bucket S3 onde seus arquivos de dados estão localizados. Se não houver nenhuma notificação de evento:
Siga a Opção 1: criação de uma notificação de novo evento S3 para automatizar o Snowpipe (neste tópico).
Crie uma notificação de evento para seu bucket S3 e, em seguida, prossiga com as instruções neste tópico. Para obter informações, consulte a documentação do Amazon S3.
O diagrama a seguir mostra o fluxo do processo para ingestão automática do Snowpipe com Amazon SNS:
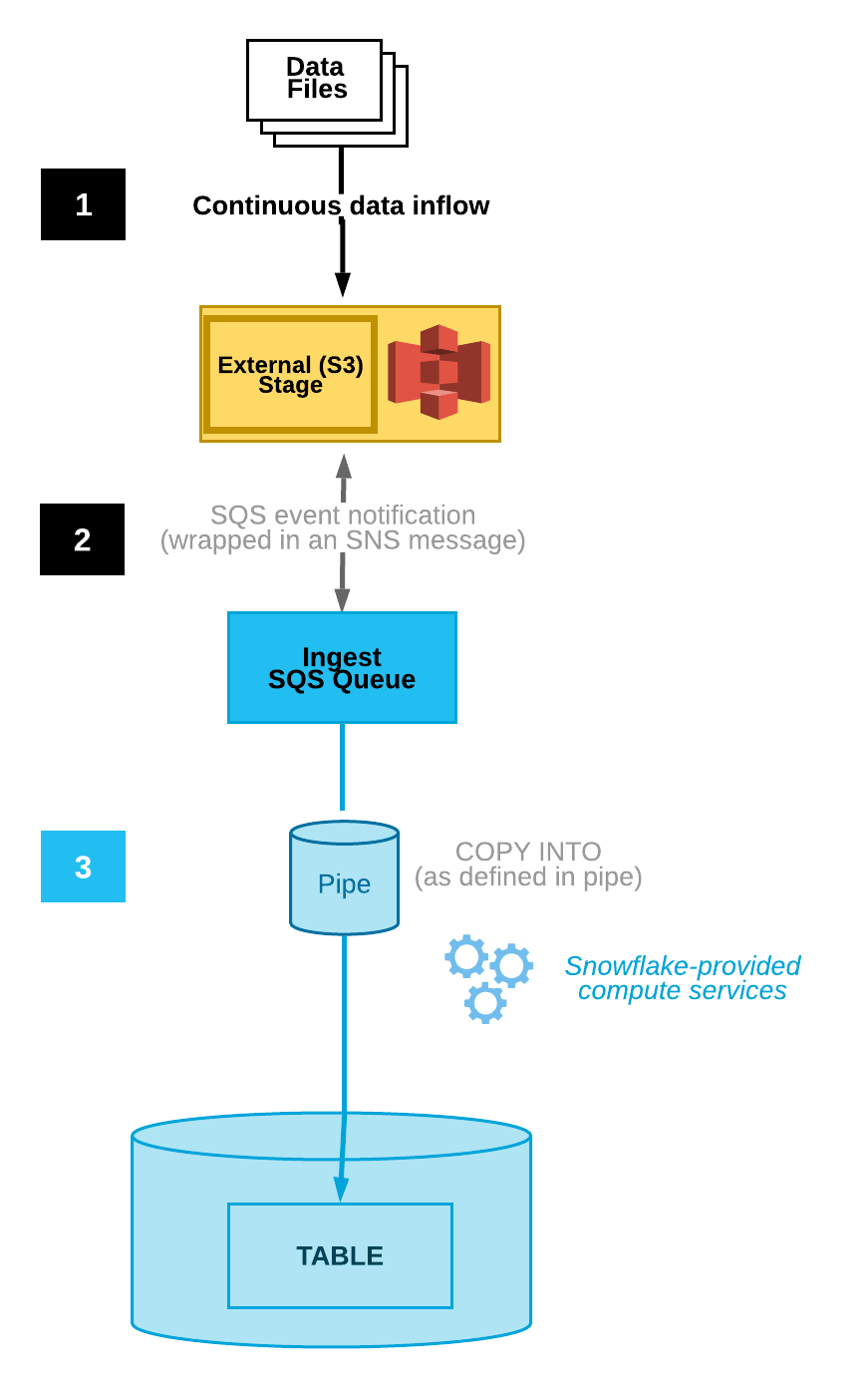
Os arquivos de dados são carregados em um estágio.
Uma notificação de evento S3 publicada por SNS informa o Snowpipe através de uma fila SQS que os arquivos estão prontos para serem carregados. O Snowpipe copia os arquivos em uma fila.
Um warehouse virtual fornecido pelo Snowflake carrega os dados dos arquivos enfileirados na tabela de destino com base nos parâmetros definidos no canal especificado.
Nota
As instruções presumem que uma tabela de destino já existe no banco de dados Snowflake onde seus dados serão carregados.
A ingestão automática do Snowpipe é compatível com tópicos SNS AWS criptografado por KMS. Para obter mais informações, consulte Criptografia em rest.
Pré-requisito: Criar um tópico e assinatura do Amazon SNS¶
Crie um tópico do SNS em sua conta AWS para tratar todas as mensagens para o local do estágio do Snowflake em seu bucket S3.
Inscreva seus destinos de destino para as notificações de eventos do S3 (por exemplo, outras filas do SQS ou cargas de trabalho do AWS Lambda) nesse tópico. O SNS publica notificações de eventos para seu bucket para todos os assinantes do tópico.
Para instruções, consulte a documentação do SNS.
Etapa 1: Inscreva a fila SQS do Snowflake no tópico do SNS¶
Entre no Console de Gerenciamento da AWS.
No painel inicial, escolha Simple Notification Service (SNS).
Escolha Topics no painel de navegação à esquerda.
Localize o tópico para seu bucket S3. Observe o ARN do tópico.
Usando um cliente Snowflake, consulte a função SYSTEM$GET_AWS_SNS_IAM_POLICY do sistema com seu ARN do tópico SNS:
A função retorna uma política IAM que concede a uma fila SQS do Snowflake permissão para se inscrever no tópico SNS.
Por exemplo:
Volte para o Console de gerenciamento AWS. Escolha Topics no painel de navegação à esquerda.
Selecione o tópico para seu bucket S3 e clique no botão Edit. A página Edit é aberta.
Clique em Access policy - Optional para expandir esta área da página.
Mesclar a adição da política IAM da função SYSTEM$GET_AWS_SNS_IAM_POLICY resulta no documento JSON.
Por exemplo:
Política IAM original (abreviada):
Política IAM mesclada:
Adicione mais uma concessão de política para permitir que o S3 publique notificações de eventos para o bucket no tópico SNS.
Por exemplo (usando o ARN do tópico SNS e o bucket S3 usado ao longo destas instruções):
Política IAM mesclada:
Clique em Save changes.
Etapa 2: criar um estágio (se necessário)¶
Crie um estágio externo que faça referência ao seu bucket S3 usando o comando CREATE STAGE. O Snowpipe busca seus arquivos de dados do estágio e os enfileira temporariamente antes de carregá-los na tabela de destino.
Você também pode usar um estágio externo já existente.
Nota
Para configurar o acesso seguro ao local de armazenamento na nuvem, consulte Configuração de acesso seguro ao armazenamento em nuvem (neste tópico).
O exemplo a seguir cria um estágio chamado mystage no esquema ativo para a sessão do usuário. O URL de armazenamento em nuvem inclui o caminho files. O estágio faz referência a uma integração de armazenamento chamada my_storage_int:
Etapa 3: criar um canal com ingestão automática habilitada¶
Crie um canal usando o comando CREATE PIPE. O canal define a instrução COPY INTO <tabela> usada pelo Snowpipe para carregar os dados da fila de ingestão na tabela de destino. Na instrução COPY, identifique o ARN do tópico SNS de Pré-requisito: criar um tópico e assinatura do Amazon SNS.
O exemplo a seguir cria um canal chamado mypipe no esquema ativo para a sessão do usuário. O canal carrega os dados dos arquivos preparados no estágio mystage na tabela mytable:
Onde:
AUTO_INGEST = TRUEEspecifica a leitura de notificações de eventos enviadas de um bucket S3 para uma fila SQS quando novos dados estiverem prontos para serem carregados.
AWS_SNS_TOPIC = '<sns_topic_arn>'Especifica o ARN para o tópico SNS de seu bucket S3; por exemplo,
arn:aws:sns:us-west-2:001234567890:s3_mybucketno exemplo atual. A instrução CREATE PIPE inscreve a fila SQS do Snowflake no tópico SNS especificado. Observe que o canal só copia arquivos na fila de ingestão acionada por notificações de eventos através do tópico SNS.
Para remover qualquer parâmetro de um canal, é necessário recriar o canal usando a sintaxe CREATE OR REPLACE PIPE.
Importante
Verifique se a referência do local de armazenamento na instrução COPY INTO <tabela> instrução não se sobrepõe à referência em canais existentes na conta. Caso contrário, vários canais poderiam carregar o mesmo conjunto de arquivos de dados nas tabelas de destino. Por exemplo, esta situação pode ocorrer quando múltiplas definições de canais fazem referência ao mesmo local de armazenamento com diferentes níveis de granularidade, como <local_de_armazenamento>/path1/ e <local_de_armazenamento>/path1/path2/. Neste exemplo, se os arquivos fossem preparados em <local_armazenamento>/path1/path2/, ambos os canais carregariam uma cópia dos arquivos.
Veja as instruções COPY INTO <tabela> nas definições de todos os canais da conta executando SHOW PIPES ou consultando a exibição PIPES em Account Usage ou a exibição PIPES no Information Schema.
Etapa 4: configurar a segurança¶
Para cada usuário que irá executar cargas de dados contínuas usando o Snowpipe, conceder privilégios suficientes de controle de acesso aos objetos para a carga de dados (ou seja, o banco de dados, esquema e tabela de destino; o objeto de preparação e o canal).
Nota
Para seguir o princípio geral do “menor privilégio”, recomendamos a criação de um usuário e função separados a serem usados para a ingestão de arquivos usando um canal. O usuário deve ser criado com esta função padrão.
A utilização do Snowpipe requer uma função com os seguintes privilégios:
Objeto |
Privilégio |
Notas |
|---|---|---|
Canal nomeado |
OWNERSHIP |
|
Integração de armazenamento nomeada |
USAGE |
Necessário se o estágio que você criou na Etapa 2: criar um estágio (se necessário) fizer referência a uma integração de armazenamento. |
Estágio nomeado |
USAGE , READ |
|
Formato de arquivo nomeado |
USAGE |
Necessário apenas se o estágio que você criou na Etapa 2: criar um estágio (se necessário) fizer referência a um formato de arquivo nomeado. |
Banco de dados de destino |
USAGE |
|
Esquema de destino |
USAGE |
|
Tabela de destino |
INSERT , SELECT |
Use o comando GRANT <privilégios> … TO ROLE para conceder privilégios à função.
Nota
Somente administradores de segurança (ou seja, usuários com a função SECURITYADMIN ou superior) podem criar funções.
Por exemplo, crie uma função chamada snowpipe_role que possa acessar um conjunto de objetos de banco de dados snowpipe_db.public, bem como um canal chamado mypipe; então, conceda a função a um usuário:
O Snowpipe com ingestão automática está configurado!
Quando novos arquivos de dados são adicionados ao bucket S3, a notificação de evento informa o Snowpipe para carregá-los na tabela de destino definida no canal.
Etapa 5: carregar arquivos históricos¶
Para carregar qualquer lista de pendências de arquivos de dados que existiam no estágio externo antes que as notificações SQS fossem configuradas, consulte Carregamento de dados históricos.
Etapa 6: excluir arquivos preparados¶
Exclua os arquivos preparados depois de carregar os dados com sucesso e não precisar mais dos arquivos. Para obter instruções, consulte Exclusão de arquivos preparados depois que o Snowpipe carrega os dados.
Opção 3: configuração do Amazon EventBridge para automatizar o Snowpipe¶
Semelhante à opção 2, você também pode configurar o Amazon EventBridge para automatizar o Snowpipe.
Etapa 1: Criar um tópico Amazon SNS¶
Siga Pré-requisito: Criar um tópico e assinatura do Amazon SNS e assinatura (neste tópico).
Etapa 2: Criar uma regra EventBridge para assinar buckets S3 e enviar notificações para o tópico SNS¶
Habilite o Amazon EventBridge para buckets S3.
Crie regras EventBridge para enviar notificações para o tópico SNS criado na etapa 1.
Etapa 3: configuração do Amazon SNS para automatizar o Snowpipe usando notificações SQS¶
Siga Opção 2: configuração do Amazon SNS para automatizar o Snowpipe usando notificações SQS (neste tópico)
Saída SYSTEM$PIPE_STATUS¶
A função SYSTEM$PIPE_STATUS recupera uma representação JSON do status atual de um canal.
Para canais com AUTO_INGEST definido como TRUE, a função retorna um objeto JSON contendo os seguintes pares nome/valor (se aplicável ao status atual do canal):
{«executionState»:»<valor>»,»oldestFileTimestamp»:<valor>,»pendingFileCount»:<valor>,»notificationChannelName»:»<valor>»,»numOutstandingMessagesOnChannel»:<valor>,»lastReceivedMessageTimestamp»:»<valor>»,»lastForwardedMessageTimestamp»:»<valor>»,»error»:<valor>,»fault»:<valor>}
Para descrições dos valores de saída, consulte o tópico de referência para a função SQL.