Snowpipe Streaming¶
Snowpipe Streaming é o serviço de ingestão em tempo real do Snowflake criado na arquitetura de alto desempenho. Ele permite que os aplicativos carreguem dados de streaming diretamente nas tabelas Snowflake à medida que as linhas chegam, sem preparar arquivos ou gerenciar o armazenamento intermediário. Os dados ficam disponíveis para consulta segundos após a ingestão, sendo ideais para casos de uso de telemetria de IoT e pipelines de captura de alterações nos dados (CDC) para detectar fraudes e fazer análises em tempo real.
O Snowpipe Streaming oferece:
Taxa de transferência de até 10GB/s por tabela
Até 5 segundos de latência de ingestão para consultas de ponta a ponta
Entrega exatamente uma vez pelo rastreamento de tokens com deslocamento integrado
Ingestão ordenada em cada canal
Streaming para tabelas Apache Iceberg gerenciadas pelo Snowflake
Por que usar o Snowpipe Streaming¶
Entrega exatamente uma vez: o rastreamento de tokens com deslocamento integrado permite semânticas “exatamente uma vez”. Seu aplicativo rastreia os deslocamentos confirmados e reproduções com base na última posição confirmada na recuperação, evitando duplicações e perda de dados. Para mais informações, consulte tokens com deslocamento e entrega exatamente uma vez.
Ingestão ordenada: as linhas são ingeridas em ordem dentro de cada canal. Os canais são mapeados para partições de origem (por exemplo, partições de tópicos Kafka), permitindo a repetição determinística e a recuperação sem perda.
Alta taxa de transferência, baixa latência: projetado para oferecer velocidades de ingestão de até 10GB /s por tabela, com dados disponíveis para consulta em apenas 5 segundos.
Transformações em andamento: limpeza, reformulação e transformação de dados durante a ingestão usando sintaxe de comando COPY dentro do objeto PIPE. Filtrar linhas, reordenar colunas, converter tipos e aplicar expressões antes que os dados sejam confirmados na tabela de destino, sem precisar de uma etapa ETL separada.
Pré-clustering no momento da ingestão: classifique os dados durante a ingestão para otimizar o desempenho de consulta em tabelas com chaves de clustering.
Suporte para tabelas Apache Iceberg: transmissão de dados para tabelas Iceberg gerenciadas pelo Snowflake, incluindo as tabelas Iceberg v2 e Iceberg v3. Para obter mais informações, consulte Arquitetura de alto desempenho do Snowpipe Streaming com tabelas Apache Iceberg™.
Evolução de esquemas: adapte automaticamente os esquemas de tabela às mudanças nas estruturas de dados. O Snowflake pode adicionar novas colunas detectadas no fluxo de entrada sem mudanças manuais de DDL.
** Pipelines simplificados**: SDKs gravam linhas diretamente em tabelas, sem precisar preparar arquivos ou armazenamento intermediário em nuvem.
Sem servidor e dimensionável: os recursos de computação são dimensionados automaticamente com base na carga de ingestão. Sem precisar gerenciar a infraestrutura.
Preços transparentes: faturamento baseado no processamento, calculado por créditos por GB não comprimido de dados ingeridos. Para obter mais informações, consulte Snowpipe Streaming high-performance architecture: Understand your costs.
Como se conectar¶
O Snowpipe Streaming oferece suporte a vários caminhos de ingestão para se ajustar a diferentes cargas de trabalho:
Integração |
Melhor para |
|---|---|
Aplicativos personalizados de alta taxa de transferência. Requer Java 11 ou posterior. |
|
Engenharia de dados e fluxos de trabalho nativos do Python. Requer Python 3.9 ou posterior. |
|
Cargas de trabalho leve, dispositivos IoT e implantações de borda. |
|
Ingestão de tópico Apache Kafka. |
SDKs Java e Python usam um novo núcleo de cliente baseado em Rust para melhorar o desempenho no cliente e diminuir o uso de recursos.
Nota
Recomendamos que você comece com oSDK do Snowpipe Streaming sobre API REST para se beneficiar do melhor desempenho e da experiência de introdução.
Para começar, consulte o Tutorial: Introdução ao SDK ou o Tutorial: Introdução à API REST.
Para detalhes técnicos sobre o objeto PIPE, canais, tokens com deslocamento e tipos de dados compatíveis, consulte Principais conceitos.
Recomendado para¶
Cargas de trabalho de streaming de alto volume que exigem taxa de transferência de até 10GB/s
Análise em tempo real e painéis com atualização de dados de até 5 segundos
Implantações de borda e IoT usando a API REST
Pipelines CDC (captura de alteração de dados) com garantia de entrega exatamente uma vez
Apache Kafka topic ingestion using the Snowflake Connector for Kafka
Fluxo para tabelas Apache Iceberg para análise em formato de tabela aberta
Nota
Procurando um fluxo SQL nativo? Consulte tabelas dinâmicas e:doc:fluxos</user-guide/streams-intro> com tarefas para pipelines declarativos de fluxo.
Snowpipe Streaming versus Snowpipe¶
O Snowpipe Streaming serve para complementar o Snowpipe, não para substituí-lo. Use o Snowpipe Streaming em contextos em que os dados chegam como linhas (por exemplo, tópicos do Apache Kafka, dispositivos IoT ou eventos de aplicativos) em vez de arquivos. Com o Snowpipe Streaming, você não precisa criar arquivos para carregar dados nas tabelas do Snowflake.
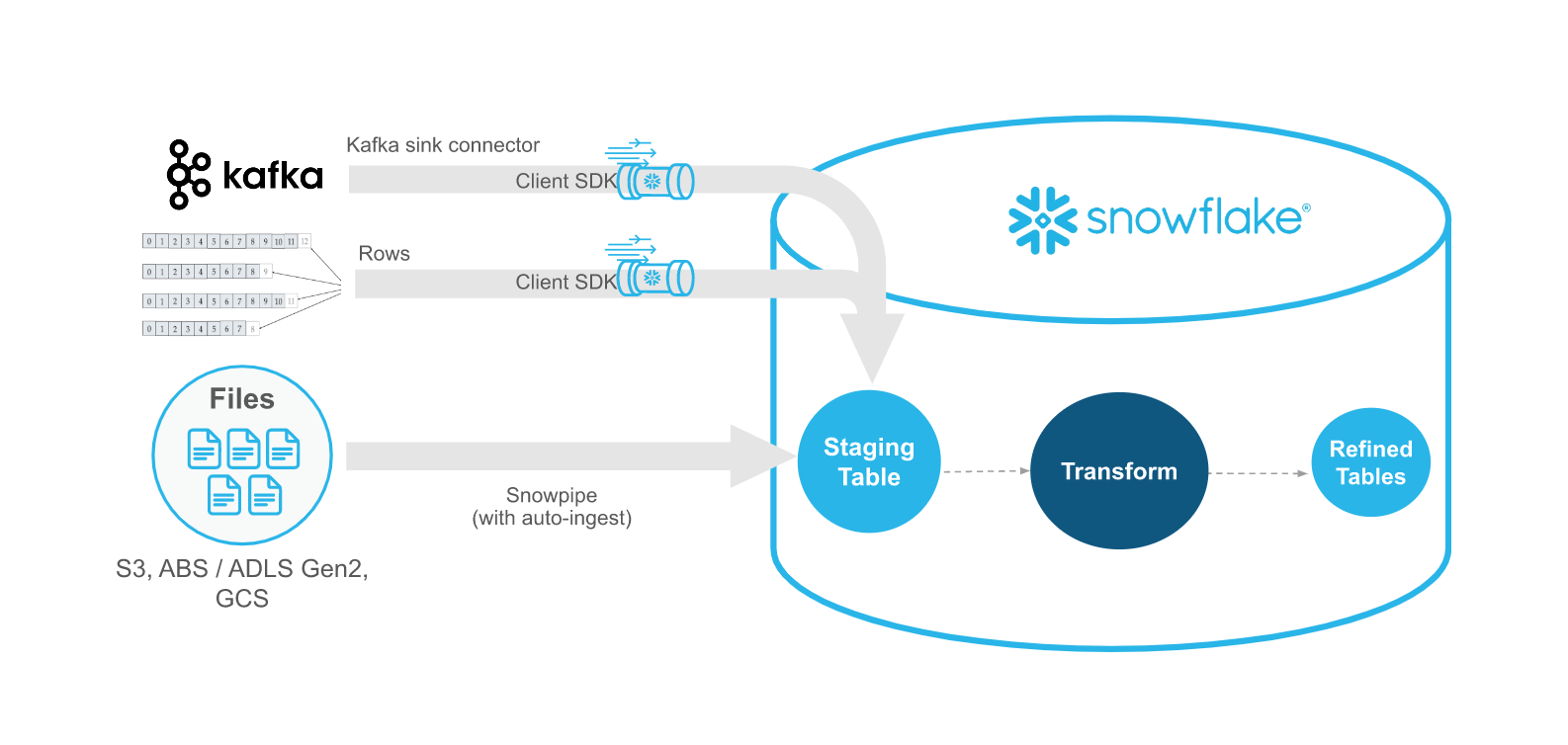
A tabela a seguir descreve as diferenças entre Snowpipe Streaming e Snowpipe:
Categoria |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Forma dos dados a serem carregados |
Linhas |
Arquivos. Se seu pipeline de dados atual gera arquivos em armazenamento de blobs, recomendamos usar o Snowpipe. |
Ordenação de dados |
Inserções ordenadas dentro de cada canal |
Sem suporte. O Snowpipe pode carregar dados de arquivos em uma ordem diferente dos carimbos de data/hora de criação de arquivos no armazenamento em nuvem. |
Histórico de carregamento |
Histórico de carregamento registrado na exibição SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage) |
Histórico de carga registrado em COPY_HISTORY (Account Usage) e na função COPY_HISTORY (Information Schema) |
Objeto de canal |
O objeto PIPE é a camada de processamento do servidor onde ocorre toda a ingestão do fluxo. Ele lida com a validação de esquema, transformações em andamento e pré-clustering. Um canal padrão é criado automaticamente para cada tabela, ou você pode criar um canal personalizado para processamento avançado. |
Um objeto de canal enfileira e carrega dados do arquivo preparado nas tabelas de destino. |
Nesta seção¶
Principais conceitos
Introdução
Destinos de ingestão
Operações
Referência
Arquitetura clássica¶
Importante
A arquitetura clássica, que utiliza o snowflake-ingest-sdk Java SDK, será descontinuado. nenhuma alteração imediata é necessária. As cargas de trabalho atuais continuam sendo totalmente compatíveis.
Para saber todos os detalhes, consulte o aviso de descontinuação planejada.
Se você tiver cargas de trabalho em execução na arquitetura clássica, consulte Arquitetura clássica. Para uma comparação detalhada das diferenças, consulte Comparação entre SDKs de alto desempenho e clássicas.
Se você estiver atualizando para a arquitetura de alto desempenho, consulte o Guia de migração.