Snowpipe Streaming¶
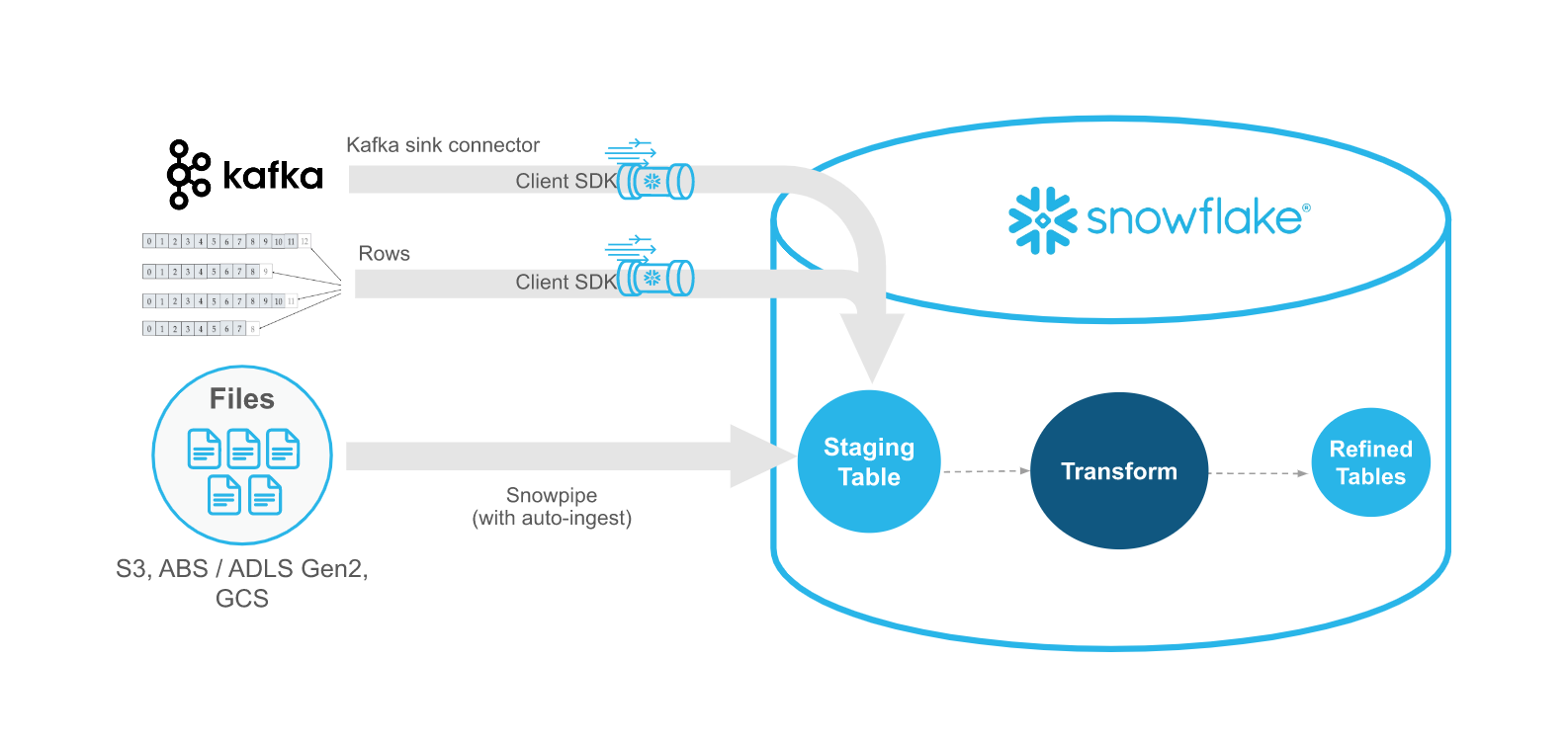
O Snowpipe Streaming é o serviço Snowflake para carregamento contínuo e de baixa latência de dados de streaming diretamente no Snowflake. Ele permite a ingestão e análise de dados quase em tempo real, o que é crucial para insights oportunos e respostas operacionais imediatas. Grandes volumes de dados de diversas fontes de streaming são disponibilizados para consulta e análise em segundos.
Valor do Snowpipe Streaming¶
Disponibilidade de dados em tempo real: ingere os dados à medida que eles chegam, ao contrário dos métodos tradicionais de carregamento em lote, dando suporte a casos de uso como painéis ao vivo, análises em tempo real e detecção de fraudes.
Cargas de trabalho de streaming eficientes: utiliza os Snowflake Ingest SDKs para gravar linhas diretamente nas tabelas, ignorando o armazenamento em nuvem intermediário. Essa abordagem direta reduz a latência e simplifica a arquitetura de ingestão.
Pipelines de dados simplificados: oferece uma abordagem simplificada para pipelines de dados contínuos de fontes como eventos de aplicativos, sensores IoT, fluxos de captura de dados de alterações (CDC) e filas de mensagens (por exemplo, Apache Kafka).
Sem servidor e dimensionável: como uma oferta sem servidor, ele dimensiona automaticamente os recursos de computação com base na carga de ingestão, eliminando o gerenciamento manual do warehouse para tarefas de ingestão.
Econômico para streaming: o faturamento é otimizado para ingestão de streaming, oferecendo potencialmente soluções mais econômicas para feeds de dados de alto volume e baixa latência em comparação com operações COPY frequentes e em pequenos lotes.
Com o Snowpipe Streaming, você pode criar aplicativos de dados em tempo real no Snowflake Data Cloud, para tomar decisões com base nos dados mais recentes disponíveis.
Implementações do Snowpipe Streaming¶
O Snowpipe Streaming oferece duas implementações distintas para atender a diversas necessidades de ingestão de dados e expectativas de desempenho: Snowpipe Streaming com arquitetura de alto desempenho (versão preliminar) e Snowpipe Streaming com arquitetura clássica:
Snowpipe Streaming com arquitetura de alto desempenho (versão preliminar)
A Snowflake projetou essa implementação de última geração para aumentar significativamente a taxa de transferência, otimizar o desempenho do streaming e fornecer um modelo de custo previsível, preparando o estágio para recursos avançados de streaming de dados.
Principais características:
SDK: utiliza o novo
snowpipe-streamingSDK.Preços: apresenta preços transparentes e baseados na taxa de transferência (créditos por GB não compactado).
Gerenciamento do fluxo de dados: utiliza o objeto PIPE para gerenciar o fluxo de dados e permitir transformações leves no momento da ingestão. Os canais são abertos para esse objeto PIPE.
Ingestão: oferece uma REST API para ingestão direta e leve de dados por meio do PIPE.
Validação de esquema: realizada no lado do servidor durante a ingestão em relação ao esquema definido no PIPE.
Desempenho: projetado para aumentar significativamente o rendimento e melhorar a eficiência das consultas nos dados ingeridos.
Incentivamos você a explorar essa arquitetura avançada, especialmente para novos projetos de streaming.
Snowpipe Streaming com arquitetura clássica
Essa é a implementação original e geralmente disponível, fornecendo uma solução confiável para pipelines de dados estabelecidos.
Principais características:
SDK: utiliza o snowflake-ingest-java SDK (todas as versões até a 4.x).
Gerenciamento de fluxo de dados: não usa o conceito de objeto PIPE para ingestão de streaming. Os canais são configurados e abertos diretamente nas tabelas de destino.
Preços: com base em uma combinação de recursos de computação sem servidor utilizados para ingestão e o número de conexões de clientes ativos.
Como escolher sua implementação¶
Considere suas necessidades imediatas e a estratégia de dados de longo prazo ao escolher uma implementação:
Novos projetos de streaming: recomendamos que avalie a arquitetura de alto desempenho do Snowpipe Streaming (versão preliminar) por seu design voltado ao futuro, melhor desempenho, escalabilidade e previsibilidade de custos.
Requisitos de desempenho: a arquitetura de alto desempenho foi criada para maximizar a taxa de transferência e otimizar o desempenho em tempo real.
Preferência de preços: a arquitetura de alto desempenho oferece preços claros e baseados na taxa de transferência, enquanto a arquitetura clássica cobra com base no uso da computação sem servidor e nas conexões do cliente.
Configurações existentes: os aplicativos existentes que usam a arquitetura clássica podem continuar funcionando. Para futuras expansões ou reprojetos, considere a possibilidade de migrar ou incorporar a arquitetura de alto desempenho.
Conjunto de recursos e gerenciamento: o objeto PIPE na arquitetura de alto desempenho introduz recursos aprimorados de gerenciamento e transformação que não estão presentes na arquitetura clássica.
Snowpipe Streaming versus Snowpipe¶
O Snowpipe Streaming foi criado para complementar o Snowpipe, não para substituí-lo. Use a Snowpipe Streaming API em cenários de streaming em que os dados são transmitidos com linhas (por exemplo, tópicos do Apache Kafka) em vez de gravados em arquivos. O API se encaixa em um fluxo de trabalho de ingestão que inclui um aplicativo Java personalizado existente que produz ou recebe registros. Com a API, você não precisa criar arquivos para carregar dados nas tabelas Snowflake e a API permite o carregamento automático e contínuo de fluxos de dados no Snowflake à medida que os dados ficam disponíveis.
A tabela a seguir descreve as diferenças entre Snowpipe Streaming e Snowpipe:
Categoria |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Forma dos dados a serem carregados |
Linhas |
Arquivos. Se seu pipeline de dados existente gerar arquivos em armazenamento de blobs, recomendamos o uso do Snowpipe em vez do API. |
Requisitos de software de terceiros |
Wrapper de código do aplicativo Java personalizado para Snowflake Ingest SDK |
Nenhum |
Ordenação de dados |
Inserções ordenadas dentro de cada canal |
Sem suporte. O Snowpipe pode carregar dados de arquivos em uma ordem diferente dos carimbos de data/hora de criação de arquivos no armazenamento em nuvem. |
Histórico de carregamento |
Histórico de carregamento registrado na exibição SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage) |
Histórico de carga registrado em COPY_HISTORY (Account Usage) e na função COPY_HISTORY (Information Schema) |
Objeto de canal |
A arquitetura clássica não requer um objeto canal: a API grava registros diretamente nas tabelas de destino. A arquitetura de alto desempenho requer um objeto de canal. |
Exige um objeto de canal que enfileira e carrega dados do arquivo preparado nas tabelas de destino. |
Requisitos de software¶
SDK de Java¶
Os SDKs Java específicos facilitam a interação com o serviço Snowpipe Streaming. Você pode fazer o download dos SDKs no Repósito Central Maven. As listas a seguir mostram os requisitos, que variam de acordo com a arquitetura do Snowpipe Streaming que você usa:
Para o Snowpipe Streaming com arquitetura de alto desempenho:
SDK: use o novo snowpipe-streaming SDK.
Versão do Java: requer Java 11 ou posterior.
Para o Snowpipe Streaming Classic:
SDK: use o snowflake-ingest-sdk versão 4.X ou posterior.
Versão do Java: requer Java 8 ou posterior.
Pré-requisito adicional: arquivos de política de jurisdição de força ilimitada Java Cryptography Extension (JCE) devem ser instalados em seu ambiente Java 8.
Importante
O SDK faz chamadas REST API para o Snowflake. Talvez seja necessário ajustar as regras de firewall de sua rede para permitir a conectividade.
Aplicativo de cliente personalizado¶
A API requer uma interface de aplicativo Java personalizada que possa injetar linhas de dados e tratar os erros que ocorrerem. Você deve garantir que o aplicativo seja executado continuamente e possa se recuperar de falhas. Para um determinado lote de linhas, a API oferece suporte ao equivalente a ON_ERROR = CONTINUE | SKIP_BATCH | ABORT.
CONTINUE: continuar a carregar as linhas de dados aceitáveis e retornar todos os erros.SKIP_BATCH: ignorar o carregamento e retornar todos os erros se algum erro for encontrado em todo o lote de linhas.ABORT(configuração padrão): anular todo o lote de linhas e lançar uma exceção quando o primeiro erro é encontrado.
No caso do Snowpipe Streaming Classic, o aplicativo faz validações de esquema usando a resposta dos métodos insertRow (linha única) ou insertRows (conjunto de linhas). Para conhecer o tratamento de erros da arquitetura de alto desempenho, consulte Tratamento de erros.
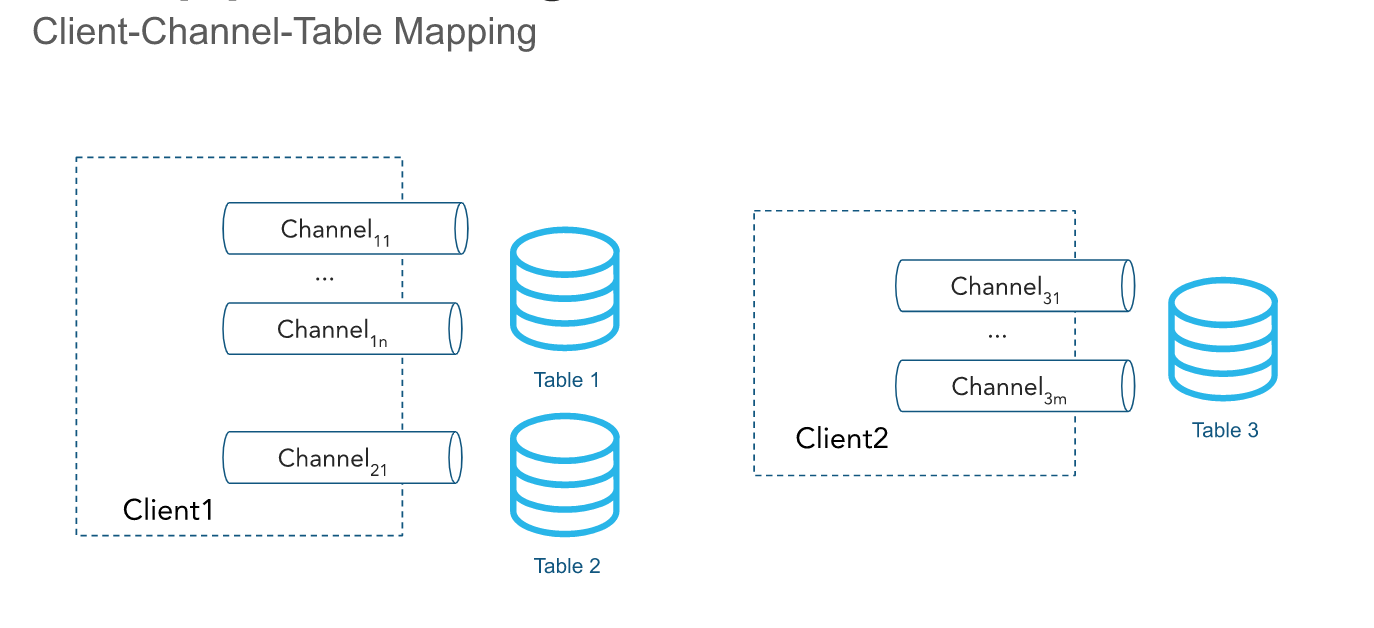
Canais¶
A API ingere linhas por meio de um ou mais canais. Um canal representa uma conexão lógica nomeada de streaming para o Snowflake para carregar dados em uma tabela. Um único canal mapeia exatamente uma tabela no Snowflake; no entanto, vários canais podem apontar para a mesma tabela. O SDK cliente pode abrir vários canais para várias tabelas; no entanto, o SDK não pode abrir canais entre contas. A ordenação das linhas e seus respectivos tokens offset são preservados dentro de um canal, mas não através de canais que apontam para a mesma tabela.
Os canais devem ter vida longa quando um cliente está inserindo dados ativamente e devem ser reutilizados à medida que as informações do token offset são retidas. Por padrão, os dados dentro do canal são automaticamente liberados a cada um segundo e o canal não precisa ser fechado. Para obter mais informações, consulte Latência.
Você pode descartar canais permanentemente usando a DropChannelRequest API quando não precisar mais do canal e dos metadados de deslocamento associados. Existem duas maneiras de descartar um canal:
Descartar um canal no fechamento. Os dados dentro do canal são automaticamente liberados antes que o canal seja descartado.
Descartar um canal às cegas. Não recomendamos isso porque a eliminação de um canal descarta cegamente todos os dados pendentes e pode invalidar os canais já abertos.
Você pode executar o comando SHOW CHANNELS para listar os canais para os quais você tem privilégios de acesso. Para obter mais informações, consulte SHOW CHANNELS.
Nota
Os canais inativos juntamente com tokens offset são excluídos automaticamente após 30 dias.
Tokens offset¶
Um token de deslocamento é uma cadeia de caracteres que um cliente pode incluir em suas solicitações de método de envio de linha (por exemplo, para linhas únicas ou múltiplas) para rastrear o progresso da ingestão por canal. Os métodos específicos usados são insertRow ou insertRows para a arquitetura clássica e appendRow ou appendRows para a arquitetura de alto desempenho. O token é inicializado como NULL na criação do canal e é atualizado quando as linhas com um token de offset fornecido são confirmadas no Snowflake por meio de um processo assíncrono. Os clientes podem fazer periodicamente solicitações do método getLatestCommittedOffsetToken para obter o token de deslocamento confirmado mais recente para um canal específico e usá-lo para raciocinar sobre o progresso da ingestão. Observe que esse token não é usado pelo Snowflake para realizar a desduplicação; no entanto, os clientes podem usar esse token para realizar a desduplicação usando seu código personalizado.
Quando um cliente reabre um canal, o último token offset persistente é devolvido. O cliente pode redefinir sua posição na fonte de dados ao usar o token para evitar o envio dos mesmos dados duas vezes. Observe que quando um evento de reabertura de canal ocorre, qualquer dado armazenado em Snowflake é descartado para evitar que seja comprometido.
Você pode usar o token de offset confirmado mais recente para realizar os seguintes casos de uso comuns:
Rastrear o progresso da ingestão
Verificar se um offset específico foi confirmado comparando-o com o último token de offset confirmado
Avançar o offset de origem e limpar os dados que já foram confirmados
Habilitar a desduplicação e garantir a entrega exata de dados uma única vez.
Por exemplo, o conector Kafka poderia ler um token offset de um tópico como <partição>:<offset> ou simplesmente <offset> se a partição estiver codificada no nome do canal. Considere o seguinte cenário:
O conector Kafka fica online e abre um canal correspondente a
Partition 1no tópico KafkaTcom o nome do canalT:P1.O conector começa a ler registros da partição Kafka.
O conector chama o API, fazendo uma solicitação de método
insertRowscom o offset associado ao registro como o token offset.Por exemplo, o token offset poderia ser
10, referindo-se ao décimo registro na partição Kafka.O conector faz periodicamente solicitações de método
getLatestCommittedOffsetTokenpara determinar o progresso de ingestão.
Se o conector Kafka falhar, então o seguinte procedimento poderia ser completado para retomar a leitura dos registros do offset correto para a partição Kafka:
O conector Kafka volta a ficar online e reabre o canal usando o mesmo nome do anterior.
O conector chama o API, fazendo uma solicitação de método
getLatestCommittedOffsetTokenpara obter o último offset comprometido para a partição.Por exemplo, suponha que o token offset persistente mais recente seja
20.O conector usa APIs de leitura Kafka para reiniciar um cursor correspondente ao offset mais 1 (
21neste exemplo).O conector retoma os registros de leitura. Nenhum dado duplicado é recuperado depois que o cursor de leitura é reposicionado com sucesso.
Em outro exemplo, um aplicativo lê logs de um diretório e usa o Snowpipe Streaming Client SDK para exportar esses logs para o Snowflake. Você poderia criar um aplicativo de exportação de logs que fizesse o seguinte:
Liste arquivos no diretório de logs.
Suponha que a estrutura de registro gere arquivos de log que podem ser ordenados lexicograficamente e que novos arquivos de registro são posicionados no fim desta ordenação.
Lê um arquivo de log linha por linha e chama o método API, fazendo solicitações de método
insertRowscom um token offset correspondente ao nome do arquivo de log e à contagem de linha ou posição do byte.Por exemplo, um token offset poderia ser
messages_1.log:20, ondemessages_1.logé o nome do arquivo de log e20é o número da linha.
Se o aplicativo travar ou precisar ser reiniciado, ele então chamaria o API, fazendo uma solicitação de método getLatestCommittedOffsetToken para recuperar um token offset que corresponde ao último arquivo e linha de log exportado. Continuando com o exemplo, isto poderia ser messages_1.log:20. O aplicativo abriria então messages_1.log e buscaria a linha 21 para evitar que a mesma linha de registro fosse ingerida duas vezes.
Nota
As informações do token offset podem ser perdidas. O token de offset é vinculado a um objeto de canal, e um canal é automaticamente limpo se nenhuma nova ingestão for realizada usando o canal por um período de 30 dias. Para evitar a perda do token offset, considere manter um offset separado e redefinir o token offset do canal, se necessário.
Funções offsetToken e continuationToken¶
offsetToken e continuationToken são usados para garantir exatamente uma entrega de dados, mas têm finalidades diferentes e são gerenciados por sistemas distintos. A principal diferença é quem controla o valor do token e o escopo de uso.
continuationToken(só se aplica à arquitetura de alto desempenho):Esse token é gerenciado pelo Snowflake e é essencial para manter o estado de uma única sessão de streaming contínua. Quando um cliente envia dados usando a API
Append Rows, o Snowflake retorna umcontinuationToken. O cliente deve utilizar esse token na próxima solicitação para garantir que os dados sejam recebidos na ordem correta e sem lacunas. O Snowflake usa o token para detectar e impedir dados duplicados no caso de um SDK tentar novamente.offsetToken(aplica-se tanto à arquitetura clássica quanto à de alto desempenho):Esse token é um identificador definido pelo usuário que permite uma entrega exata a partir de uma fonte externa. O Snowflake não usa esse token para suas próprias operações internas ou para impedir a reingestão. Em vez disso, o Snowflake simplesmente armazena esse valor. É responsabilidade do sistema externo (como um conector Kafka) ler o offsetToken do Snowflake e usá-lo para rastrear seu próprio progresso de ingestão, evitando o envio de dados duplicados caso o fluxo externo precise ser repetido.
Práticas recomendadas de entrega exatamente um¶
Conseguir uma entrega exatamente única pode ser um desafio, e a adesão aos seguintes princípios em seu código personalizado é fundamental:
Para garantir a recuperação adequada de exceções, falhas ou travamentos, você deve sempre reabrir o canal e reiniciar a ingestão usando o último token de offset confirmado.
Embora seu aplicativo possa manter seu próprio offset, é fundamental usar o último token de offset confirmado fornecido pelo Snowflake como a fonte da verdade e redefinir seu próprio offset de acordo.
A única instância em que seu próprio offset deve ser tratado como a fonte da verdade é quando o token de offset do Snowflake é definido ou redefinido como NULL. Um token de offset NULL geralmente significa uma das seguintes opções:
Esse é um novo canal, portanto, nenhum token de offset foi definido.
A tabela de destino foi descartada e recriada, portanto, o canal é considerado novo.
Não houve nenhuma atividade de ingestão no canal por 30 dias, então o canal foi limpo automaticamente e as informações do token offset foram perdidas.
Se necessário, você pode limpar periodicamente os dados de origem que já foram confirmados com base no último token offset confirmado e avançar seu próprio offset.
Se o esquema da tabela for modificado quando os canais do Snowpipe Streaming estiverem ativos, o canal deverá ser reaberto. O conector Snowflake Kafka lida com esse cenário automaticamente, mas se você usar o Snowflake Ingest SDK diretamente, precisará reabrir o canal.
Para obter mais informações sobre como o conector Kafka com o Snowpipe Streaming consegue uma entrega exata, consulte Semântica exatamente um.
Carregamento de dados em tabelas Apache Iceberg™¶
Com o Snowflake Ingest SDK versões 3.0.0 e posteriores, o Snowpipe Streaming pode ingerir dados em tabelas Apache Iceberg gerenciadas pelo Snowflake. O Snowpipe Streaming Ingest Java SDK oferece suporte ao carregamento em tabelas Snowflake padrão (não Iceberg) e em tabelas Iceberg.
Para obter mais informações, consulte Usando o Snowpipe Streaming Classic com tabelas Apache Iceberg™.
Latência¶
O Snowpipe Streaming libera automaticamente os dados nos canais a cada segundo. Você não precisa fechar o canal para que os dados sejam liberados.
Com o Snowflake Ingest SDK versões 2.0.4 e posteriores, você pode configurar a latência usando a opção MAX_CLIENT_LAG.
Para tabelas Snowflake padrão (não Iceberg), o
MAX_CLIENT_LAGpadrão é 1 segundo.Para tabelas Iceberg (compatíveis com o Snowflake Ingest SDK versões 3.0.0 e posteriores), o padrão de
MAX_CLIENT_LAGé 30 segundos.
A latência máxima pode ser configurada em até 10 minutos. Para mais informações, consulte MAX_CLIENT_LAG e configurações de latência recomendadas para Snowpipe Streaming.
Observe que o conector Kafka para Snowpipe Streaming possui seu próprio buffer. Depois que o tempo de liberação do buffer Kafka for atingido, os dados serão enviados com um segundo de latência para o Snowflake por meio do Snowpipe Streaming. Para obter mais informações, consulte buffer.flush.time.
Migração para arquivos otimizados na arquitetura clássica¶
O API grava as linhas dos canais em blobs no armazenamento em nuvem, que são então enviados para a tabela de destino. Inicialmente, os dados gravados em uma tabela de destino são armazenados em um formato de arquivo intermediário temporário. Neste estágio, a tabela é considerada uma “tabela mista”, porque os dados particionados são armazenados em uma mistura de arquivos nativos e intermediários. Um processo automatizado em segundo plano migra os dados dos arquivos intermediários ativos para arquivos nativos otimizados para operações de consulta e DML, conforme necessário.
Replicação na arquitetura clássica¶
Snowpipe Streaming oferece suporte à replicação e failover de tabelas do Snowflake preenchidas por Snowpipe Streaming e seus offsets de canal associados de uma conta de origem para uma conta de destino em diferentes regiões e em plataformas de nuvem.
A replicação não é compatível com a arquitetura de alto desempenho.
Para obter mais informações, consulte Replicação e Snowpipe Streaming.
Operações somente de inserção¶
O API está atualmente limitado a inserir linhas. Para modificar, apagar ou combinar dados, escreva os registros “brutos” em uma ou mais tabelas de preparação. Mescle, junte ou transforme os dados ao usar o pipeline de dados contínuos para inserir dados modificados nas tabelas de relatórios de destino.
Classes e interfaces¶
Para obter a documentação sobre as classes e interfaces da arquitetura clássica, consulte Snowflake Ingest SDK API.
Para conhecer as diferenças entre as arquiteturas clássica e de alto desempenho, consulte as diferenças de API.
Tipos de dados Java suportados¶
A tabela a seguir resume quais tipos de dados Java são suportados para ingestão nas colunas Snowflake:
Tipo de coluna Snowflake |
Tipo de dados Java permitidos |
|---|---|
|
|
|
|
|
|
|
|
|
Consulte detalhes da conversão booliana. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Privilégios de acesso obrigatórios¶
Chamar a Snowpipe Streaming API requer uma função com os seguintes privilégios:
Objeto |
Privilégio |
|---|---|
Tabela |
OWNERSHIP ou um mínimo de INSERT e EVOLVE SCHEMA (obrigatório apenas ao usar a evolução do esquema para o conector Kafka com Snowpipe Streaming) |
Banco de dados |
USAGE |
Esquema |
USAGE |
Canal |
OPERATE (obrigatório apenas para arquitetura de alto desempenho) |
Limitações¶
Para o Snowpipe Streaming Classic, esteja ciente das seguintes limitações:
O Snowpipe Streaming clássico não oferece suporte ao aumento dos limites de tamanho máximo para objetos de banco de dados – 128 MB para VARCHAR, VARIANT, ARRAYe OBJECT e 64 MB para BINARY, GEOGRAPHY e GEOMETRY — que fazem parte do pacote de mudanças de comportamento 2025_03.
O Fail-safe não é compatível com tabelas que contêm dados ingeridos pelo Snowpipe Streaming Classic. Para essas tabelas, você não pode usar o fail-safe para recuperação porque as operações fail-safe nessa tabela falham completamente.
O Snowpipe Streaming só oferece suporte ao uso de chaves AES 256-bit para criptografia de dados.
Se o Clustering automático também estiver ativado na mesma tabela em que o Snowpipe Streaming está inserindo, os custos de computação para a migração de arquivos poderão ser reduzidos. Para obter mais informações, consulte Práticas recomendadas para o Snowpipe Streaming Classic.
Os seguintes objetos ou tipos não são compatíveis:
Os tipos de dados GEOGRAPHY e GEOMETRY
Colunas com agrupamentos
Tabelas TEMPORARY
O número total de canais por tabela não pode exceder 10 mil. Recomendamos reutilizar canais quando necessário. Entre em contato com o Suporte da Snowflake se precisar abrir mais de 10 mil canais por tabela.
A arquitetura de alto desempenho tem outras considerações e limitações em comparação com a arquitetura clássica. Para obter mais informações, consulte as limitações da arquitetura de alto desempenho.