Cortex Search¶
Get started with Cortex Search
Visão geral¶
O Cortex Search permite uma pesquisa “difusa” de baixa latência e alta qualidade em seus dados Snowflake. Ele oferece uma ampla variedade de experiências de pesquisa para usuários Snowflake, incluindo aplicativos Retrieval Augmented Generation (RAG) que aproveitam os modelos de linguagem grandes (Large Language Models, LLMs).
O Cortex Search permite que você comece a usar um mecanismo de busca híbrido (vetor e palavra-chave) em seus dados de texto em minutos, sem precisar se preocupar com incorporação, manutenção de infraestrutura, ajuste de parâmetro de qualidade de pesquisa ou atualizações contínuas de índice. Isso significa que você pode gastar menos tempo em infraestrutura e ajuste de qualidade de pesquisa e mais tempo desenvolvendo experiências de bate-papo e pesquisa de alta qualidade usando seus dados. Confira os tutoriais do Cortex Search para obter instruções passo a passo sobre como usar o Cortex Search para potencializar aplicativos de bate-papo de AI e pesquisa.
Quando usar o Cortex Search¶
Os dois principais casos de uso do Cortex Search são geração aumentada de recuperação (RAG) e pesquisa empresarial.
Mecanismo RAG para chatbotsLLM: use o Cortex Search como um mecanismo RAG para aplicativos de bate-papo com seus dados de texto, aproveitando a pesquisa semântica para obter respostas personalizadas e contextualizadas.
Pesquisa corporativa: use o Cortex Search como um backend para uma barra de pesquisa de alta qualidade incorporada ao seu aplicativo.
Cortex Search para RAG¶
A geração aumentada de recuperação (RAG) é uma técnica para recuperar dados de uma base de conhecimento para aprimorar a resposta gerada de um grande modelo de linguagem. O diagrama de arquitetura a seguir mostra como você pode combinar o Cortex Search com o Cortex LLM Functions para criar chatbots corporativos com RAG usando seus dados do Snowflake como base de conhecimento.
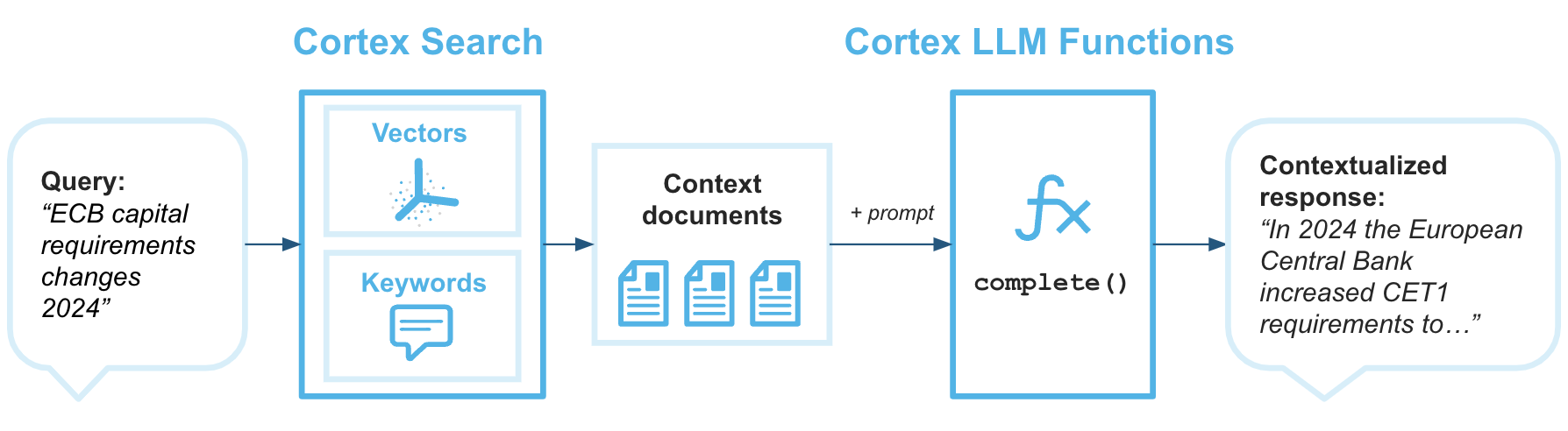
O Cortex Search é o mecanismo de recuperação que fornece ao Grande modelo de linguagem o contexto necessário para retornar respostas baseadas em seus dados proprietários mais atualizados.
Exemplo: criar e consultar um Cortex Search Service¶
Este exemplo mostra as etapas de criação de um Cortex Search Service e sua consulta usando a RESTAPI. Consulte o tópico Como consultar o Cortex Search Service para obter mais detalhes sobre consultas ao serviço.
Este exemplo usa um amostra de conjunto de dados de transcrição de suporte ao cliente.
Execute os seguintes comandos para configurar o banco de dados de exemplo e o esquema.
Execute os seguintes comandos SQL para criar o conjunto de dados.
Criação do serviço¶
Você pode criar um Cortex Search Service com uma única consulta SQL ou do Snowflake AI & ML Studio. Quando você cria um Cortex Search Service, o Snowflake realiza transformações em seus dados de origem para prepará-los para distribuição de baixa latência. As seções a seguir mostram como criar um serviço usando ambos SQL e no Snowflake AI & ML Studio em Snowsight.
Nota
Quando você cria um serviço de pesquisa, o índice de pesquisa é criado como parte do processo de criação. Isso significa que a instrução CREATECORTEXSEARCHSERVICE pode levar mais tempo para ser concluída para conjuntos de dados maiores.
Uso de SQL¶
O exemplo a seguir demonstra como criar um Cortex Search Service com CREATE CORTEX SEARCH SERVICE o conjunto de dados de transcrição de suporte ao cliente de amostra criado na seção anterior.
Este comando aciona a construção do serviço de pesquisa para seus dados. Neste exemplo:
Consultas ao serviço procurarão correspondências na coluna
transcript_text.O parâmetro
TARGET_LAGdetermina que o Cortex Search Service verificará atualizações na tabela basesupport_transcriptsaproximadamente uma vez por dia.As colunas
regioneagent_idserão indexadas para que possam ser retornadas junto com os resultados das consultas na colunatranscript_text.A coluna
regionestará disponível como uma coluna de filtro ao consultar a colunatranscript_text.O warehouse
cortex_search_whserá usado para materializar os resultados da consulta especificada inicialmente e sempre que a tabela base for alterada.
Nota
Dependendo do tamanho do warehouse especificado na consulta e do número de linhas na sua tabela, esse comando CREATE pode levar várias horas para ser concluído.
A Snowflake recomenda usar um warehouse dedicado de tamanho não maior que MEDIUM para cada serviço.
As colunas no campo ATTRIBUTES devem ser incluídas na consulta de origem, por meio de enumeração explícita ou curinga, (
*).
Uso de Snowsight¶
Siga estas etapas para criar um Cortex Search Service em Snowsight:
Faça login na Snowsight.
Escolha uma função que tenha a função de banco de dados SNOWFLAKE.CORTEX_USER concedida.
No menu de navegação, selecione AI & ML » Cortex Search.
Selecione Create.
Selecione uma função e um warehouse.
A função deve receber a função de banco de dados SNOWFLAKE.CORTEX_USER. O warehouse é usado para materializar os resultados da consulta de origem quando o serviço é criado e atualizado.
Selecione um banco de dados e um esquema no qual o serviço é definido.
Insira um nome para o seu serviço e selecione Next.
Selecione os dados a serem indexados.
Para selecionar uma tabela ou exibição, selecione Table or view.
Selecione a tabela ou exibição que contém os dados de texto a serem indexados para pesquisa e selecione Next. Para este exemplo, selecione a tabela
support_transcripts.Para selecionar arquivos de uma área de preparação, selecione Stage. (Versão preliminar)
Selecione a área de preparação que contém os arquivos a serem indexados para pesquisa e selecione Next.
Nota
Se você quiser especificar várias fontes de dados ou executar transformações ao definir seu serviço, use SQL.
Se você selecionou Table or view:
Selecione as colunas que deseja incluir nos resultados da pesquisa, por exemplo,
transcript_text,regioneagent_id, e depois selecione Next.Selecione a coluna que será pesquisada, por exemplo,
transcript_texte selecione Next.Se você quiser filtrar os resultados da pesquisa com base em colunas específicas, selecione as colunas e, depois, Next. Se você não precisar de nenhum filtro, selecione Skip this option.
Se você selecionou Stage (versão preliminar):
Selecione o destino para seus dados processados e, depois, Next.
Selecione os parâmetros de configuração para o serviço.
Defina seu atraso de destino, que é a quantidade de tempo que o conteúdo do seu serviço deve ficar atrás das atualizações dos dados base, e então selecione Create.
A etapa final confirma que seu serviço foi criado e exibe o nome do serviço e sua fonte de dados.
Nota
Quando você cria o serviço a partir de Snowsight, o nome do serviço fica entre aspas duplas. Para obter detalhes sobre o que isso significa ao fazer referência ao serviço em SQL, consulte Identificadores entre aspas duplas.
Concessão de permissões de uso¶
Depois que o serviço e o índice forem criados, você pode conceder uso no serviço, seu banco de dados e esquema para outras funções, como customer_support.
Pré-visualização do serviço¶
Para confirmar se o serviço está preenchido com dados corretamente, você pode visualizar o serviço por meio da função SEARCH_PREVIEW de um ambiente SQL:
Exemplo de resposta de consulta bem-sucedida:
Esta resposta confirma que o serviço está preenchido com dados e fornece resultados razoáveis para a consulta fornecida.
Você também pode usar a função de tabela CORTEX_SEARCH_DATA_SCAN para inspecionar o conteúdo do serviço.
Consulta do serviço do seu aplicativo¶
Depois de criar o serviço de pesquisa, conceder uso a ele para sua função e visualizá-lo, agora você pode consulta -lo em seu aplicativo usando o API Python.
O código a seguir mostra o uso da API Python para recuperar o tíquete de suporte mais relevante para uma consulta sobre internet issues, filtrado para retornar resultados na região North America:
Exemplo de resposta de consulta bem-sucedida:
O Cortex Search Services retorna todas as colunas especificadas no campo columns da sua consulta.
Privilégios obrigatórios¶
Para criar um Cortex Search Service, sua função deve ter os privilégios necessários para usar as funções de incorporação do Cortex, o que requer a concessão da função de banco de dados SNOWFLAKE.CORTEX_USER ou SNOWFLAKE.CORTEX_EMBED_USER para a função de criador de serviço. Você também deve ter os seguintes privilégios:
O privilégio CREATE CORTEX SEARCH SERVICE ou OWNERSHIP no esquema em que você cria o serviço.
O privilégio SELECT na(s) tabela(s) ou exibição(ões) subjacente(s) que o serviço consulta.
O privilégio USAGE no warehouse que atualiza o serviço.
O rastreamento de alterações deve ser habilitado em todos os objetos subjacentes usados por um Cortex Search Service. Para obter mais informações sobre os requisitos de rastreamento de alterações, consulte Requisitos de rastreamento de alterações.
Para consultar um Cortex Search Service, a função do usuário que faz a consulta deve ter privilégios USAGE no próprio serviço, bem como no banco de dados e esquema em que o serviço reside. Consulte os Requisitos de controle de acesso do Cortex Search Access.
Para suspender ou retomar um Cortex Search Service usando o comando ALTER, a função do usuário que faz a consulta deve ter o privilégio OPERATE no serviço. Consulte ALTER CORTEX SEARCH SERVICE.
Importante
O Cortex Search Services realiza buscas com os direitos do proprietário e seguem o mesmo modelo de segurança de outros objetos Snowflake executados com os direitos do proprietário. Para obter mais informações, consulte Requisitos de controle de acesso do Cortex Search
Como entender a qualidade do Cortex Search¶
O Cortex Search utiliza um conjunto de modelos de recuperação e classificação para fornecer um alto nível de qualidade de pesquisa com pouca ou nenhuma necessidade de ajuste. Internamente, o Cortex Search adota uma abordagem “híbrida” para recuperar e classificar documentos. Cada consulta de pesquisa utiliza:
Pesquisa vetorial para recuperar documentos semanticamente semelhantes.
Pesquisa por palavra-chave para recuperar documentos lexicamente semelhantes.
Reclassificação semântica para reclassificar os documentos mais relevantes no conjunto de resultados.
Essa abordagem de recuperação híbrida, juntamente com uma etapa de reclassificação semântica, alcança alta qualidade de pesquisa em uma ampla gama de conjuntos de dados e consultas.
Você pode personalizar a pontuação dos resultados da pesquisa aplicando aumentos numéricos, diminuições de tempo, ajustando os pesos dos componentes ou desativando a reclassificação. Para obter mais informações, consulte Personalizando a pontuação do Cortex Search.
Modelos de incorporação do Cortex Search¶
O Cortex Search permite que os usuários selecionem um modelo de incorporação hospedado para ser aproveitado no estágio de pesquisa vetorial da recuperação. Os seguintes modelos de incorporação estão disponíveis no Cortex Search.
Importante
A precificação do modelo varia. A precificação do modelo canônico está disponível na tabela de consumo de serviços do Snowflake. Se um preço mostrado abaixo for diferente do preço mostrado para o modelo na tabela de consumo de serviços do Snowflake, a tabela deverá prevalecer.
Nome do modelo |
Dimensões de saída |
Tamanho da janela de contexto (tokens) |
Suporte a idiomas |
Descrição |
|---|---|---|---|---|
|
768 |
512 |
Somente em inglês |
O modelo de incorporação mais prático do Snowflake, somente em inglês. Esse modelo de código aberto, com 110 milhões de parâmetros, produz os tempos de indexação mais rápidos dos modelos disponíveis no Cortex Search. Para obter mais informações, consulte a postagem no blog Arctic Embed 1.5 e o cartão do modelo Arctic Embed 1.5. |
|
1024 |
512 |
Multilíngue |
Modelo de incorporação multilíngue do Snowflake com excelente relação custo-desempenho e uma janela de contexto de 512 tokens. Esse modelo de código aberto e 568 milhões de parâmetros produz alta qualidade em conjuntos de dados em inglês e em outros idiomas. Para obter mais informações, consulte a postagem no blog Arctic Embed 2 e o cartão do modelo Arctic Embed 2. |
|
1024 |
8192 |
Multilíngue |
Modelo de incorporação multilíngue da Snowflake com excelente relação custo-desempenho e uma janela de contexto aumentada de 8.000 tokens. Esse modelo de código aberto e 568 milhões de parâmetros produz alta qualidade em conjuntos de dados em inglês e em outros idiomas. |
|
1024 |
32,000 |
Multilíngue |
Modelo de incorporação multilíngue do Voyage. Esse modelo produz alta qualidade em conjuntos de dados em inglês e em outros idiomas. Para obter mais informações, consulte a postagem do blog Voyage Multilingual 2 |
Alguns modelos de incorporação estão disponíveis apenas em determinadas regiões da nuvem para o Cortex Search. Para obter uma lista de disponibilidade por modelo e por região, consulte Disponibilidade regional do Cortex Search.
Cada modelo tem características diferentes de desempenho, custo, tamanho da janela de contexto e qualidade. Analise cuidadosamente as especificações do modelo para determinar o melhor modelo para sua carga de trabalho específica. Consulte a tabela de consumo de serviços do Snowflake para uma visualização mais precisa do custo de cada modelo em créditos por milhão de tokens.
Tokens, janelas de contexto de modelo e divisão de texto¶
Token é uma sequência de caracteres e a menor unidade que pode ser processada por um modelo de linguagem grande. Como aproximação, um token é equivalente a cerca de 3/4 de uma palavra em inglês, ou cerca de 4 caracteres. Para calcular o número de tokens em uma cadeia de caracteres, use a função COUNT_TOKENS do Cortex. Por exemplo, calcular os tokens de uma cadeia de caracteres a ser incorporada com o modelo snowflake-arctic-embed-m-v1.5:
Cada modelo de incorporação de vetores oferece suporte a uma janela de contexto de tamanho fixo para entradas de texto, indicada na tabela de modelo de incorporação anterior. Durante a indexação e o processamento, quando o número de tokens em um valor na coluna de pesquisa excede o tamanho da janela de contexto, o Cortex Search trunca a cadeia de caracteres no tamanho da janela de contexto antes de incorporá-la ao espaço vetorial para pesquisa semântica. No entanto, o Cortex Search usa o corpo completo do texto para recuperação baseada em palavras-chave.
O Snowflake inclui funções internas para ajudar na divisão de texto em partes menores. Para obter mais informações, consulte SPLIT_TEXT_RECURSIVE_CHARACTER.
Para os melhores resultados de pesquisa com o Cortex Search, a Snowflake recomenda dividir o texto na coluna de pesquisa em partes de no máximo 512 tokens (cerca de 385 palavras em inglês). Embora existam modelos de incorporação de contexto mais longos disponíveis atualmente, como snowflake-arctic-embed-l-v2.0-8k, pesquisas mostram que um tamanho de bloco menor geralmente resulta em maior qualidade de recuperação e resposta de LLM downstream. Com partes menores, a recuperação pode ser mais precisa para uma determinada consulta e, na geração aumentada de recuperação (Retrieval-Augmented Generation, RAG), o LLM downstream recebe partes de texto que são mais relevantes para a consulta.
Atualizações¶
O conteúdo exibido em um Cortex Search Service é baseado nos resultados de uma consulta específica. Quando os dados subjacentes a um Cortex Search Service mudam, o serviço é atualizado para refletir essas alterações. Essas atualizações são chamadas de atualização. Este processo é automatizado e envolve a análise da consulta que está subjacente à tabela.
Os Cortex Search Services têm as mesmas propriedades de atualização das tabelas dinâmicas. Consulte o tópico Compreensão da inicialização e atualização de tabelas dinâmicas para entender as características de atualização de um Cortex Search Service.
A consulta de origem para um Cortex Search Service deve ser candidata à atualização incremental de tabela dinâmica. Para obter detalhes sobre esses requisitos, consulte Suporte para atualizações incrementais. Essa restrição foi criada para evitar quaisquer custos indesejados associados à computação de incorporação de vetores. Para obter mais informações sobre as construções que não são suportadas para atualização incremental de tabela dinâmica, consulte Consultas compatíveis para tabelas dinâmicas.
Chaves primárias¶
A chave primária de um Cortex Search Service é um conjunto opcional de colunas que identifica exclusivamente cada linha na consulta de origem (ou seja, apenas uma linha tem essa combinação exata de valores nas colunas designadas). Para serem usadas com o Cortex Search Services, as colunas de chave primária devem ser do tipo de dados TEXT.
Uma chave primária pode ser especificada ao criar o serviço da seguinte forma:
As colunas de chave primária dos serviços existentes podem ser modificadas com ALTER CORTEX SEARCH SERVICE ... SET PRIMARY KEY (...). Para sintaxe detalhada, consulte ALTER CORTEX SEARCH SERVICE.
Os serviços com chaves primárias podem usar um caminho de atualização otimizado quando os dados subjacentes ao serviço são alterados. Esse caminho otimizado pode resultar em reduções significativas no custo e na latência de uma atualização. Com essa otimização ativada, o serviço de pesquisa compacta periodicamente as informações do índice geradas durante uma atualização. Você pode especificar uma frequência de destino para atualizações de índice definindo a propriedade FULL_INDEX_BUILD_INTERVAL_DAYS no serviço. Para obter detalhes da sintaxe, consulte CREATE CORTEX SEARCH SERVICE e ALTER CORTEX SEARCH SERVICE.
Nota
FULL_INDEX_BUILD_INTERVAL_DAYS é um destino flexível. Reconstruções completas podem ocorrer com mais frequência do que o intervalo especificado para otimizar o desempenho do serviço com base em fatores como atraso do destino do serviço, taxa de alteração nos dados de origem do serviço e tamanho geral do serviço.
Consultas a serviços com chaves primárias também podem usar o operador de filtro da @primarykey.
Importante
O conjunto de valores das colunas de chave primária deve ser exclusivo para cada linha na consulta de origem. As duplicatas são ignoradas no índice de pesquisa resultante.
Cortex Search de vários índices¶
O Cortex Search pode indexar várias colunas ou usar incorporações vetoriais personalizadas para consultas, permitindo flexibilidade adicional na forma como o Cortex Search Service interpreta dados e responde às solicitações dos usuários. Você deve usar o Cortex Search de vários índices quando tiver um caso de uso que apresenta um ou mais destes itens:
Vários campos de pesquisa: os usuários precisam pesquisar em diferentes campos de um registro.
Incorporações vetoriais fornecidas pelo usuário: você tem incorporações vetoriais pré-computadas para uma ou mais colunas antes da ingestão no Cortex Search Service.
Tipos de pesquisa combinados: você deseja oferecer suporte à pesquisa em diferentes campos com preferência a um tipo de pesquisa.
Use índices de texto para campos em que as correspondências exatas ou difusas de palavras-chave são importantes. Alguns exemplos são códigos, nomes e categorias de produtos.
Use índices vetoriais para campos com conteúdo de texto mais longo em que a compreensão semântica é importante. Exemplos incluem descrições de produtos, avaliações de usuários e casos de suporte.
Relevância específica do campo: campos distintos dos seus dados devem contribuir de forma diferente para a relevância do resultado de uma pesquisa.
Por exemplo, para um caso de uso de pesquisa de catálogo de produtos, você pode criar um serviço de vários índices em que:
Os nomes e SKUs dos produtos são índices de texto para correspondência lexical precisa.
As descrições dos produtos são índices vetoriais para correspondência semântica.
Os nomes de categoria e marca são índices de texto e vetoriais para oferecer suporte a correspondências lexical e semântica.
Para ver exemplos de criação de um Cortex Search Service de vários índices, consulte CREATE CORTEX SEARCH SERVICE … TEXT INDEXES .. VECTOR INDEXES. Para ver exemplos de consulta de um serviço de vários índices, leia Consultar um Cortex Search Service – Consultas de vários índices.
Incorporações vetoriais fornecidas pelo usuário¶
O Cortex Search de vários índices permite usar incorporações vetoriais pré-computadas de qualquer modelo de incorporação (incluindo modelos de código aberto, comerciais e treinados sob medida). Use as incorporações vetoriais fornecidas pelo usuário quando:
Você quiser usar um modelo de incorporação que não esteja disponível nativamente no Cortex Search ou quiser reutilizar incorporações que você já gerou para reduzir custos e melhorar o desempenho.
Você quiser combinar suas incorporações vetoriais com índices de texto do Cortex Search para recuperação híbrida.
Quando você especifica um nome de coluna simples na cláusula VECTOR INDEXES, mas não especifica um modelo, o Cortex Search trata o conteúdo da coluna como incorporações vetoriais fornecidas pelo usuário. Os vetores fornecidos pelo usuário são indexados como estão e não incorrem em nenhum custo de incorporação.
Nota
Não é possível carregar vetores diretamente em uma tabela Snowflake. Em vez disso, converta uma matriz de números para o tipo de dados VECTOR ao inserir ou atualizar dados na tabela de origem do seu Cortex Search Service. Consulte Conversão de vetores para obter detalhes e exemplos de como fazer isso.
O Cortex Search escolhe um dos seguintes modos no momento da pesquisa, dependendo se você fornece um vetor de consulta ou um texto de consulta em sua solicitação de pesquisa:
Modo |
Tempo de indexação |
Tempo de consulta |
|---|---|---|
Totalmente gerenciado pelo usuário |
Fornecer vetores em uma coluna VECTOR |
Fornecer um vetor de consulta via multi_index_query |
Gerenciado pelo usuário com incorporações de consulta gerenciadas |
Fornecer vetores em uma coluna VECTOR |
O Cortex Search incorpora o texto da consulta usando o modelo especificado |
Suspensão de indexação e serviço¶
Semelhante às tabelas dinâmicas, o Cortex Search Services suspende automaticamente o estado de indexação quando encontra cinco falhas consecutivas de atualização relacionadas à consulta de origem. Se você encontrar essa falha no seu serviço, poderá exibição o erro SQL específico usando DESCRIBE CORTEX SEARCH SERVICE ou Exibição CORTEX_SEARCH_SERVICES. A saída de ambos inclui as seguintes colunas:
A coluna INDEXING_STATE, que é SUSPENDED para um serviço suspenso.
A coluna INDEXING_ERROR, que contém o erro SQL específico encontrado na consulta de origem.
Depois que o problema raiz for resolvido, você poderá retomar o serviço com o ALTER CORTEX SEARCH SERVICE <nome> RESUME INDEXING. Para sintaxe detalhada, consulte ALTER CORTEX SEARCH SERVICE.
Considerações sobre custo¶
Um Cortex Search Service incorre em custo das seguintes maneiras:
Categoria |
Descrição |
|---|---|
Computação de warehouse virtual |
Um Cortex Search Service requer um warehouse virtual para atualizar o serviço: para executar consultas em objetos de base quando eles são inicializados e atualizados, incluindo a orquestração de trabalhos de incorporação de texto e a criação do índice de pesquisa. Essas operações usam recursos de computação, que consomem créditos. Se nenhuma alteração for identificada durante uma atualização, os créditos do warehouse virtual não serão consumidos, pois não há novos dados para atualizar. |
Computação de tokens EMBED_TEXT |
Um Cortex Search Service incorpora automaticamente cada linha de texto na coluna de pesquisa especificada no parâmetro |
Cortex Search de vários índices |
Os serviços do Cortex Search Services de vários índices têm custos dependentes de como você incorpora tokens e do número de colunas indexadas. Vetores de incorporação maiores ou números mais altos de colunas de índice geram custos mais elevados. As incorporações são computadas cada vez que uma linha é inserida ou atualizada. As incorporações são processadas incrementalmente na avaliação da consulta de origem, de modo que o custo de incorporação é incorrido apenas para documentos adicionados ou alterados. |
Computação de serviços |
Um Cortex Search Service usa computação de serviço multilocatário, separada de um warehouse virtual fornecido pelo usuário, para estabelecer um serviço de baixa latência e alta taxa de transferência. O custo de computação para esse componente é incorrido por GB por mês (GB/mo) de dados indexados não compactados, em que os dados indexados são os dados fornecidos pelo usuário na consulta de origem do Cortex Search, além de incorporações de vetor computados em nome do usuário. Você incorre nesses custos enquanto o serviço estiver disponível para responder às consultas, mesmo que nenhuma consulta seja atendida durante um determinado período. Para obter a taxa de crédito de serviços do Cortex Search por GB/mo de dados indexados, consulte a Snowflake Service Consumption Table. |
Armazenamento |
O Cortex Search Services materializa a consulta de origem em uma tabela armazenada em sua conta. Esta tabela é transformada em estruturas de dados otimizadas para serviços de baixa latência, também armazenadas em sua conta. O armazenamento da tabela e das estruturas de dados intermediárias é baseado em uma taxa fixa por terabyte (TB). |
Computação de serviços de nuvem |
Os Cortex Search Services usam a computação dos serviços de nuvem para identificar alterações nos objetos de base subjacentes e se o warehouse virtual precisa ser chamado. O custo de computação dos serviços de nuvem está sujeito à restrição de que a Snowflake cobra apenas se o custo diário dos serviços de nuvem for superior a 10% do custo diário do warehouse da conta. |
Para obter as práticas recomendadas de gerenciamento de custos de um Cortex Search Service, consulte Entendendo o custo dos Cortex Search Services.
Para visualizar os custos de consumo relacionados ao serviços de AI para cada Cortex Search Service em sua conta, agregados diariamente, consulte a exibição CORTEX_SEARCH_DAILY_USAGE_HISTORY
Limitações conhecidas¶
O uso do Cortex Search está sujeito às seguintes limitações:
Tamanho da tabela base: o resultado da consulta materializada no serviço de pesquisa deve ter menos de 100 milhões de linhas para manter o desempenho ideal do serviço. Se o resultado materializado de sua consulta tiver mais de 100 milhões de linhas, a consulta de criação falhará com um erro.
Nota
Para aumentar os limites de escala de linha em um Cortex Search Service acima de 100 milhões, entre em contato com sua equipe de conta Snowflake.
Taxa de transferência e limitação de taxa: o Cortex Search retorna o código de status HTTP 429 se um cliente envia solicitações muito rapidamente ou se o serviço fica sobrecarregado. A lógica do cliente que chama o serviço de pesquisa deve implementar a lógica de espera e nova tentativa para processar essas respostas 429 normalmente.
Nota
Para aumentar a taxa de transferência acima de 20 QPS para um único serviço de pesquisa, ou 140 QPS para todos os serviços na conta, entre em contato com a equipe de conta Snowflake.
Construções de consulta: as consultas de origem do Cortex Search Service devem obedecer às mesmas restrições de consulta que as tabelas dinâmicas. Consulte Limitações da tabela dinâmica para obter mais detalhes.
Retenção de dados: o Cortex Search Services tem os mesmos requisitos que as tabelas dinâmicas em relação a retenções de dados. Especificamente, não é possível definir o parâmetro do objeto DATA_RETENTION_TIME_IN_DAYS em suas tabelas base como zero nem definir esse parâmetro no esquema ou banco de dados que contém o serviço de pesquisa. Além disso, os serviços de pesquisa poderão ficar obsoletos se não forem atualizados em MAX_DATA_EXTENSION_TIME_IN_DAYS. Depois que ficarem obsoletos, eles deverão ser recriados para retomar as atualizações. Consulte Limitações da tabela dinâmica para saber mais detalhes.
Clonagem: o Cortex Search Services não oferece suporte à clonagem. A Snowflake não garante um cronograma específico, mas pretende incluir esse recurso em uma versão futura.
Imutabilidade de tabela: Durante a execução, os Cortex Search Services exigem que as tabelas que eles acessam não sejam modificadas ou descartadas. Para atualizar com segurança as tabelas usadas por um Cortex Search Service, interrompa o serviço antes de fazer alterações.
Disponibilidade regional¶
O suporte a esse recurso está disponível para contas nas seguintes regiões Snowflake. A disponibilidade dos modelos de incorporação específicos em uma região está indicada com uma marca de seleção.
Provedor de nuvem
|
Região
|
snowflake-arctic-embed-m-v1.5 |
snowflake-arctic-embed-l-v2.0 |
snowflake-arctic-embed-l-v2.0-8k |
voyage-multilingual-2 |
|---|---|---|---|---|---|
AWS
|
US West 2 (Oregon)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US East 2 (Ohio)
|
✔ |
✔ |
✔ |
|
AWS
|
US East 1 (N. Virginia)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US East (Commercial Gov - N. Virginia)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Canada (Central)
|
✔ |
✔ |
✔ |
|
AWS
|
South America (São Paulo)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe (Ireland)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe (London)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe Central 1 (Frankfurt)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Europa (Estocolmo)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Tokyo)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Asia Pacific (Mumbai)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Sydney)
|
✔ |
✔ |
✔ |
|
AWS
|
Ásia Pacífico (Jakarta)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Seoul)
|
✔ |
✔ |
✔ |
|
Azure
|
East US 2 (Virginia)
|
✔ |
✔ |
✔ |
|
Azure
|
West US 2 (Washington)
|
✔ |
✔ |
✔ |
|
Azure
|
South Central US (Texas)
|
✔ |
✔ |
✔ |
|
Azure
|
UK Sul (Londres)
|
✔ |
✔ |
✔ |
|
Azure
|
North Europe (Ireland)
|
✔ |
✔ |
✔ |
|
Azure
|
West Europe (Netherlands)
|
✔ |
✔ |
✔ |
✔ |
Azure
|
Switzerland North (Zürich)
|
✔ |
✔ |
✔ |
|
Azure
|
Central India (Pune)
|
✔ |
✔ |
✔ |
|
Azure
|
Japan East (Tokyo, Saitama)
|
✔ |
✔ |
✔ |
|
Azure
|
Southeast Asia (Singapore)
|
✔ |
✔ |
✔ |
|
Azure
|
Australia East (New South Wales)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 2 (London)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 3 (Frankfurt)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 4 (Netherlands)
|
✔ |
✔ |
✔ |
|
GCP
|
Oriente Médio Central 2 (Dammam)
|
✔ |
✔ |
✔ |
|
GCP
|
US Central 1 (Iowa)
|
✔ |
✔ |
✔ |
|
GCP
|
US East 4 (N. Virginia)
|
✔ |
✔ |
✔ |
Nota
Você pode especificar o parâmetro de inferência entre regiões em qualquer uma das regiões acima para acessar modelos que não são diretamente compatíveis com sua região padrão.
O Cortex Search está disponível nas seguintes regiões apenas usando a inferência entre regiões. Para usar o Cortex Search com inferência entre regiões, use o parâmetro de inferência entre regiões.
AWS Europe (Paris)
Europa AWS (Zurique)
AWS Asia Pacific (Singapore)
AWS Asia Pacific (Osaka)
Azure Canada Central (Toronto)
Azure Central US (Iowa)
Azure UAE North (Dubai)
Nota
Ao usar a inferência entre regiões, a latência da consulta entre regiões depende da infraestrutura do provedor de nuvem e do status da rede. A Snowflake recomenda que você teste seu caso de uso específico com a inferência entre regiões habilitada.
Avisos legais¶
A classificação dos dados de entradas e saídas é definido na tabela a seguir.
Classificação de dados de entrada |
Classificação de dados de saída |
Designação |
|---|---|---|
Usage Data |
Customer Data |
As funções disponíveis ao público em geral são recursos de AI cobertos. As funções em versão preliminar são recursos de AI em versão preliminar. [1] |
Para obter informações adicionais, consulte AI e ML Snowflake.