Chaves de clustering e tabelas clusterizadas¶
Em geral, o Snowflake produz dados clusterizados corretamente em tabelas; entretanto, com o tempo, particularmente porque o DML ocorre em tabelas muito grandes (como definido pela quantidade de dados na tabela, não pelo número de linhas), os dados em algumas linhas da tabela podem não mais se clusterizar de forma ideal nas dimensões desejadas.
Para melhorar o clustering das micropartições subjacentes da tabela, você sempre pode classificar manualmente as linhas nas colunas-chave da tabela e reinseri-las na tabela; no entanto, a execução dessas tarefas pode ser incômoda e cara.
Em vez disso, o Snowflake suporta a automatização dessas tarefas designando uma ou mais colunas/expressões de tabela como uma chave de clustering para a tabela. Uma tabela com uma chave de clustering definida é considerada como clusterizada.
Você pode clusterizar exibições materializadas, assim como tabelas. As regras para clustering de tabelas e exibições materializadas são geralmente as mesmas. Para algumas dicas adicionais específicas para exibições materializadas, consulte Exibições materializadas e clustering e Práticas recomendadas para exibições materializadas.
Atenção
As chaves de clustering não são destinadas a todas as tabelas devido aos custos de clusterizar inicialmente os dados e manter o clustering. O clustering é ideal quando:
Você requer o tempo de resposta mais rápido possível, independentemente do custo.
Seu melhor desempenho na consulta compensa os créditos necessários para clusterizar e manter a tabela.
Para obter mais informações sobre a escolha das tabelas a serem clusterizadas, consulte: Considerações para escolher o clustering para uma tabela.
O que é uma chave de clustering?¶
Uma chave de clustering é um subconjunto de colunas em uma tabela (ou expressões em uma tabela) que são explicitamente designadas para colocalizar os dados na tabela nas mesmas micropartições. Isto é útil para tabelas muito grandes onde a ordenação não foi ideal (no momento em que os dados foram inseridos/carregados) ou um extenso DML fez com que o clustering natural da tabela se degradasse.
Alguns indicadores gerais que podem ajudar a determinar se deve-se definir uma chave de clustering para uma tabela incluem:
As consultas na tabela ocorrem mais lentamente do que o esperado ou se degradaram notavelmente ao longo do tempo.
A profundidade do clustering para a tabela é grande.
Uma chave de clustering pode ser definida na criação da tabela (usando o comando CREATE TABLE) ou posteriormente (usando o comando ALTER TABLE). A chave de clustering de uma tabela também pode ser alterada ou descartada a qualquer momento.
Atenção
As chaves de clustering não podem ser definidas para tabelas híbridas. Nas tabelas híbridas, os dados são sempre ordenados por chave primária.
Benefícios da definição de chaves de clustering (para tabelas muito grandes)¶
O uso de uma chave de clustering para colocalizar linhas semelhantes nas mesmas micropartições permite vários benefícios para tabelas muito grandes, inclusive:
Melhorar a eficiência de verificação em consultas, ignorando os dados que não correspondem aos predicados de filtragem.
Melhorar a compactação das colunas do que em tabelas sem clustering. Isto é especialmente verdadeiro quando outras colunas estão fortemente correlacionadas com as colunas que compõem a chave de clustering.
Após uma chave ter sido definida em uma tabela, nenhuma administração adicional é necessária, a menos que você decida descartar ou modificar a chave. Toda a manutenção futura nas linhas da tabela (para garantir um clustering ideal) é realizada automaticamente pelo Snowflake.
Embora o clustering possa melhorar substancialmente o desempenho e reduzir o custo de algumas consultas, os recursos de computação utilizados para realizar o clustering consomem créditos. Como tal, você deve clusterizar somente quando as consultas se beneficiarem substancialmente com o clustering.
Tipicamente, as consultas se beneficiam do clustering quando as filtram ou ordenam segundo a chave de clustering para a tabela. A classificação é comumente feita para operações ORDER BY, para operações GROUP BY e para algumas junções. Por exemplo, a junção seguinte provavelmente faria com que o Snowflake realizasse uma operação de ordenação:
Neste pseudoexemplo, o Snowflake provavelmente ordenará os valores em my_materialized_view.col1 ou my_table.col1. Por exemplo, se os valores em my_table.col1 estiverem ordenados, então como a exibição materializada está sendo verificada, o Snowflake pode rapidamente encontrar a linha correspondente em my_table.
Quanto mais frequentemente uma tabela é consultada, mais benefícios o clustering oferece. Entretanto, quanto mais frequentemente uma tabela muda, mais caro será mantê-la clusterizada. Portanto, o clustering é geralmente mais econômico para tabelas que são consultadas com frequência e que não mudam com frequência.
Nota
Depois de definir uma chave de clustering para uma tabela, as linhas não são necessariamente atualizadas imediatamente. O Snowflake só realiza a manutenção automatizada se a tabela for beneficiada pela operação. Para obter mais detalhes, consulte Reclustering (neste tópico) e Clustering automático.
Considerações para escolher o clustering para uma tabela¶
Quer você queira tempos de resposta mais rápidos ou custos gerais mais baixos, o clustering é melhor para uma tabela que atenda a todos os seguintes critérios:
A tabela contém um grande número de micropartições. Normalmente, isto significa que a tabela contém vários terabytes (TB) de dados.
As consultas podem aproveitar o clustering. Normalmente, isto significa que um ou ambos elementos são verdadeiros:
As consultas são seletivas. Em outras palavras, as consultas precisam ler apenas uma pequena porcentagem de linhas (e, portanto, geralmente uma pequena porcentagem de micropartições) na tabela.
As consultas ordenam os dados. (Por exemplo, a consulta contém uma cláusula ORDER BY para a tabela).
Uma alta porcentagem das consultas pode se beneficiar da(s) mesma(s) chave(s) de clustering. Em outras palavras, muitas/a maioria das consultas selecionam, ou ordenam, a(s) mesma(s) pouca(s) coluna(s).
Se seu objetivo é principalmente reduzir os custos gerais, então cada tabela clusterizada deve ter uma alta proporção de consultas para operações DML (INSERT/UPDATE/DELETE). Isso normalmente significa que a tabela é consultada com frequência e atualizada com pouca frequência. Se você quiser clusterizar uma tabela que experimente muito DML, então considere clusterizar instruções DML em lotes grandes e pouco frequentes.
Além disso, antes de escolher clusterizar uma tabela, o Snowflake fortemente recomenda que você teste um conjunto representativo de consultas na tabela para estabelecer algumas linhas de base de desempenho.
Estratégias para a seleção de chaves de clustering¶
Uma única chave de clustering pode conter uma ou mais colunas ou expressões. Para a maioria das tabelas, o Snowflake recomenda um máximo de 3 ou 4 colunas (ou expressões) por chave. Adicionar mais do que 3-4 colunas tende a aumentar os custos mais do que os benefícios.
A seleção das colunas/expressões certas para uma chave de clustering pode ter um impacto dramático no desempenho da consulta. A análise de sua carga de trabalho geralmente resultará em bons candidatos-chave para clustering.
O Snowflake recomenda que se dê prioridade às chaves na ordem abaixo:
Clusterize as colunas que são usadas mais ativamente em filtros seletivos. Para muitas tabelas de fatos envolvidos em consultas baseadas em datas (por exemplo, “WHERE data_da_fatura > x AND data da fatura <= y”), escolher a coluna de datas é uma boa ideia. Para tabelas de eventos, o tipo de evento pode ser uma boa escolha, se houver um grande número de tipos diferentes de eventos. (Se sua tabela tem apenas um pequeno número de tipos de eventos diferentes, então consulte os comentários sobre cardinalidade abaixo antes de escolher uma coluna de eventos como uma chave de clustering).
Se houver espaço para chaves de clustering adicionais, então considere colunas frequentemente utilizadas em predicados de junção, por exemplo “FROM tabela1 JOIN tabela2 ON tabela2.coluna_A = tabela1.coluna_B”.
Se você normalmente filtra as consultas por duas dimensões (por exemplo, as colunas application_id e user_status), então o clustering em ambas as colunas pode melhorar o desempenho.
O número de valores distintos (ou seja, cardinalidade) em uma coluna/expressão é um aspecto crítico para selecioná-la como uma chave de clustering. É importante escolher uma chave de clustering que tenha:
Um número suficientemente grande de valores distintos para permitir uma remoção eficaz na tabela.
Um número pequeno o suficiente de valores distintos para permitir que o Snowflake agrupe efetivamente as linhas nas mesmas micropartições.
Uma coluna com cardinalidade muito baixa pode gerar apenas uma remoção mínima, como uma coluna denominada IS_NEW_CUSTOMER que contém apenas valores booleanos. No outro extremo, uma coluna com uma cardinalidade muito alta também não costuma ser um bom candidato para usar como chave de clustering diretamente. Por exemplo, uma coluna que contém valores de carimbo de data/hora em nanossegundos não seria uma boa chave de clustering.
Dica
Em geral, se uma coluna (ou expressão) tem maior cardinalidade, então manter o clustering nessa coluna é mais caro.
O custo do clustering em uma chave única pode ser maior do que o benefício do clustering nessa chave, especialmente se pesquisas pontuais não forem o caso de uso principal para essa tabela.
Se você quiser usar uma coluna com muito alta cardinalidade como chave de clustering, o Snowflake recomenda definir a chave como uma expressão na coluna, em vez de diretamente na coluna, para reduzir o número de valores distintos. A expressão deve preservar a ordenação original da coluna para que os valores mínimos e máximos em cada partição ainda permitam a remoção.
Por exemplo, se uma tabela de fatos tiver uma coluna TIMESTAMP c_timestamp contendo muitos valores separados (muito mais do que o número de micropartições na tabela), então uma chave de clustering poderia ser definida na coluna, convertendo os valores em datas em vez de carimbos de data/hora (por exemplo, to_date(c_timestamp)). Isto reduziria a cardinalidade ao número total de dias, o que normalmente produz resultados muito melhores na remoção.
Como outro exemplo, você pode truncar um número para menos dígitos significativos usando as funções TRUNC e um valor negativo para a escala (por exemplo, TRUNC(123456789, -5)).
Dica
Se você estiver definindo uma chave de clustering de várias colunas para uma tabela, a ordem na qual as colunas são especificadas na cláusula CLUSTER BY é importante. Como regra geral, o Snowflake recomenda ordenar as colunas da cardinalidade mais baixa até a cardinalidade mais alta. Colocar uma coluna de maior cardinalidade antes de uma coluna de menor cardinalidade geralmente reduzirá a eficácia do clustering nesta última coluna.
Dica
Ao se clusterizar em um campo de texto, os metadados da chave de clustering rastreiam apenas os primeiros vários bytes (normalmente 5 ou 6 bytes). Note que para conjuntos de caracteres de múltiplos bytes, isto pode ser menos que 5 caracteres.
Em alguns casos, o clustering em colunas utilizadas nas cláusulas GROUP BY ou ORDER BY pode ser útil. Entretanto, o clustering nestas colunas é geralmente menos útil do que o clustering em colunas que são muito utilizadas em operações de filtragem ou JOIN. Se você tem algumas colunas que são muito utilizadas em operações de filtragem/junção e diferentes colunas que são utilizadas em operações ORDER BY ou GROUP BY, então favoreça as colunas utilizadas nas operações de filtragem e junção.
Reclustering¶
Como as operações DML (INSERT, UPDATE, DELETE, MERGE, COPY) são realizadas em uma tabela clusterizada, os dados na tabela podem se tornar menos clusterizados. O reclustering periódico/regular da tabela é necessário para manter um clustering otimizado.
Durante o reclustering, o Snowflake usa a chave de clustering para uma tabela clusterizada para reorganizar os dados da coluna, de modo que os registros relacionados sejam realocados para a mesma micropartição. Esta operação DML exclui os registros afetados e os reinsere novamente, clusterizados de acordo com a chave de clustering.
Nota
O reclustering no Snowflake é automático; não é necessária nenhuma manutenção. Para obter mais detalhes, consulte Clustering automático.
Entretanto, para certas contas, o reclustering manual foi desativado mas ainda é permitido. Para obter mais detalhes, consulte Reclustering manual.
Impacto do reclustering no crédito e no armazenamento¶
Semelhante a todas as operações DML no Snowflake, o reclustering consome créditos. O número de créditos consumidos depende do tamanho da tabela e da quantidade de dados que precisam ser reclusterizados.
O reclustering também resulta em custos de armazenamento. Cada vez que os dados são reclusterizados, as linhas são agrupadas fisicamente com base na chave de clustering para a tabela, o que faz o Snowflake gerar novas micropartições para a tabela. Adicionar até mesmo um pequeno número de linhas a uma tabela pode fazer com que todas as micropartições que contêm esses valores sejam recriadas.
Este processo pode criar uma significativa rotatividade de dados porque as micropartições originais são marcadas como excluídas, mas retidas no sistema para habilitar o Time Travel e o Fail-safe. As micropartições originais são limpas somente após o período de retenção do Time Travel e o subsequente período de Fail-safe (ou seja, mínimo de 8 dias e até 97 dias para o Time Travel estendido, se você estiver usando o Snowflake Enterprise Edition ou superior). Isso normalmente resulta no aumento dos custos de armazenamento. Para obter mais informações, consulte Snowflake Time Travel e Fail-safe.
Importante
Antes de definir uma chave de clustering para uma tabela, você deve considerar os custos de crédito e armazenamento associados.
Exemplo de reclustering¶
Com base no diagrama de clustering do tópico anterior, este diagrama ilustra como o reclustering de uma tabela pode ajudar a reduzir a verificação de micropartições para melhorar o desempenho da consulta:
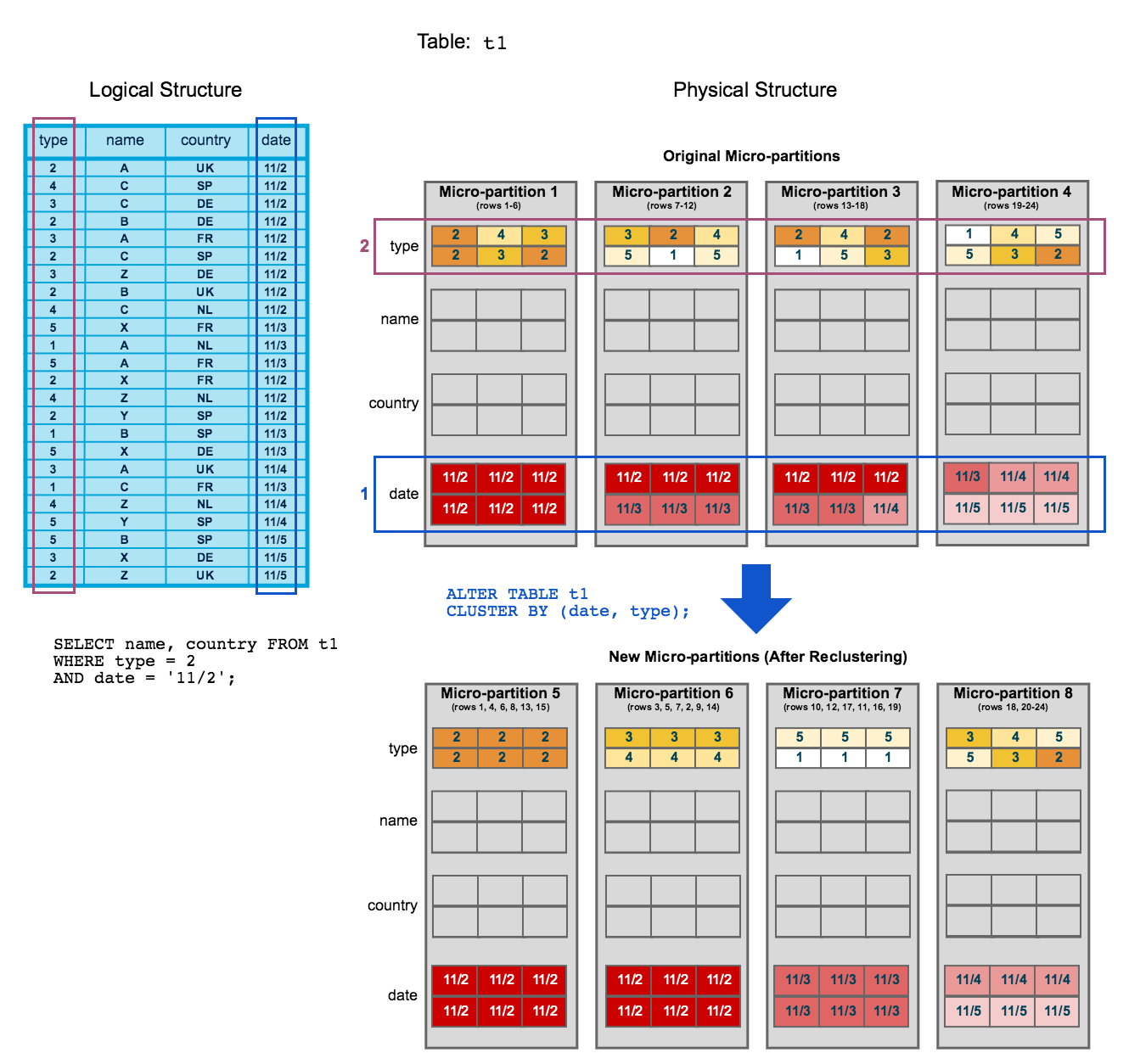
Para começar, a tabela
t1é naturalmente clusterizada pordatenas micropartições 1-4.A consulta (no diagrama) requer a verificação das micropartições 1, 2 e 3.
dateetypesão definidos como a chave de clustering. Quando a tabela é reclusterizada, novas micropartições (5-8) são criadas.Após o reclustering, a mesma consulta só verifica a micropartição 5.
Além disso, após o reclustering:
A micropartição 5 atingiu um estado constante (ou seja, não pode ser melhorada por reclustering) e, portanto, é excluída quando se calcula a profundidade e a sobreposição para manutenção futura. Em uma tabela grande e bem clusterizada, a maioria das micropartições se enquadrará nesta categoria.
As micropartições originais (1-4) são marcadas como excluídas, mas não são limpas do sistema; são retidas para o Time Travel e Fail-safe.
Nota
Este exemplo ilustra o impacto do reclustering em uma escala extremamente pequena. Extrapolado para uma tabela muito grande (ou seja, constituída de milhões de micropartições ou mais), o reclustering pode ter um impacto significativo na verificação e, portanto, no desempenho da consulta.
Definição de tabelas clusterizadas¶
Cálculo das informações de clustering para uma tabela¶
Use a função do sistema, SYSTEM$CLUSTERING_INFORMATION, para calcular os detalhes de clustering, incluindo a profundidade de clustering, para uma determinada tabela. Esta função pode ser executada em qualquer coluna em qualquer tabela, independentemente de a tabela ter uma chave de clustering explícita:
Se uma tabela tiver uma chave de clustering explícita, a função não requer nenhum argumento de entrada além do nome da tabela.
Se uma tabela não tem uma chave de clustering explícita (ou se uma tabela tem uma chave de clustering mas você quer calcular a relação em outras colunas da tabela), a função toma a(s) coluna(s) desejada(s) como um argumento de entrada adicional.
Definição de uma chave de clustering para uma tabela¶
Uma chave de clustering pode ser definida quando uma tabela é criada anexando uma cláusula CLUSTER BY a CREATE TABLE:
Onde cada chave de clustering consiste em uma ou mais colunas/expressões de tabela, que podem ser de qualquer tipo de dado, exceto GEOGRAPHY, VARIANT, OBJECT ou ARRAY. Uma chave de clustering pode conter qualquer um dos seguintes itens:
Colunas de base.
Expressões em colunas de base.
Expressões em caminhos de colunas VARIANT.
Por exemplo:
Notas de uso importantes¶
Para cada coluna VARCHAR, a implementação atual do clustering utiliza apenas os primeiros 5 bytes.
Se os primeiros caracteres N forem os mesmos para cada linha, ou não fornecerem cardinalidade suficiente, então considere o clustering em uma subcadeia de caracteres que comece depois dos caracteres que são idênticos e que tenha uma cardinalidade ideal. (Para obter mais informações sobre a cardinalidade ideal, consulte Estratégias para a seleção de chaves de clustering). Por exemplo:
Se você definir duas ou mais colunas/expressões como a chave de clustering para uma tabela, a ordem tem um impacto sobre como os dados são clusterizados em micropartições.
Para obter mais detalhes, consulte Estratégias para selecionar chaves de clustering (neste tópico).
Uma chave de clustering existente é copiada quando uma tabela é criada usando CREATE TABLE … CLONE. No entanto, o clustering automático é suspenso para a tabela clonada e deve ser retomada.
Uma chave de clustering existente não tem suporte quando uma tabela é criada usando CREATE TABLE … AS SELECT; entretanto, é possível definir uma chave de clustering depois que a tabela é criada.
A definição de uma chave de clustering diretamente sobre as colunas VARIANT não tem suporte; entretanto, é possível especificar uma coluna VARIANT em uma chave de clustering se você fornecer uma expressão que consista no caminho e no tipo de destino.
Alteração da chave de clustering para uma tabela¶
A qualquer momento, você pode adicionar uma chave de clustering a uma tabela existente ou alterar a chave de clustering existente para uma tabela usando ALTER TABLE:
Por exemplo:
Notas de uso importantes¶
Ao adicionar uma chave de clustering a uma tabela já preenchida com dados, nem todas as expressões podem ser especificadas na chave. Você pode verificar se uma função específica tem suporte usando SHOW FUNCTIONS:
show functions like 'function_name';A saída inclui uma coluna,
valid_for_clustering, no final da saída. Esta coluna mostra se a função pode ser usada em uma chave de clustering para uma tabela preenchida.A alteração da chave de clustering para uma tabela não afeta os registros existentes na tabela até que a tabela tenha sido reclusterizada pelo Snowflake.
Descarte das chaves de clustering para uma tabela¶
A qualquer momento, você pode descartar a chave de clustering para uma tabela usando ALTER TABLE:
Por exemplo: