Designing high-performance external functions¶
This topic provides information about concurrency, reliability, and scalability of external functions, including information about using asynchronous external functions.
Asynchronous vs. Synchronous remote services¶
A remote service can be synchronous or asynchronous.
- synchronous:
A call to a synchronous remote service is a blocking call. The remote service does not send any response until the results are ready. The service can’t be polled.
Synchronous code is easier to implement than asynchronous code.
- asynchronous:
An asynchronous remote service can be polled while the caller waits for results.
Asynchronous handling reduces sensitivity to timeouts.
For more information about asynchronous services, see Microsoft’s description of Asynchronous Request-Reply Pattern . (The information is not limited to Microsoft Azure.)
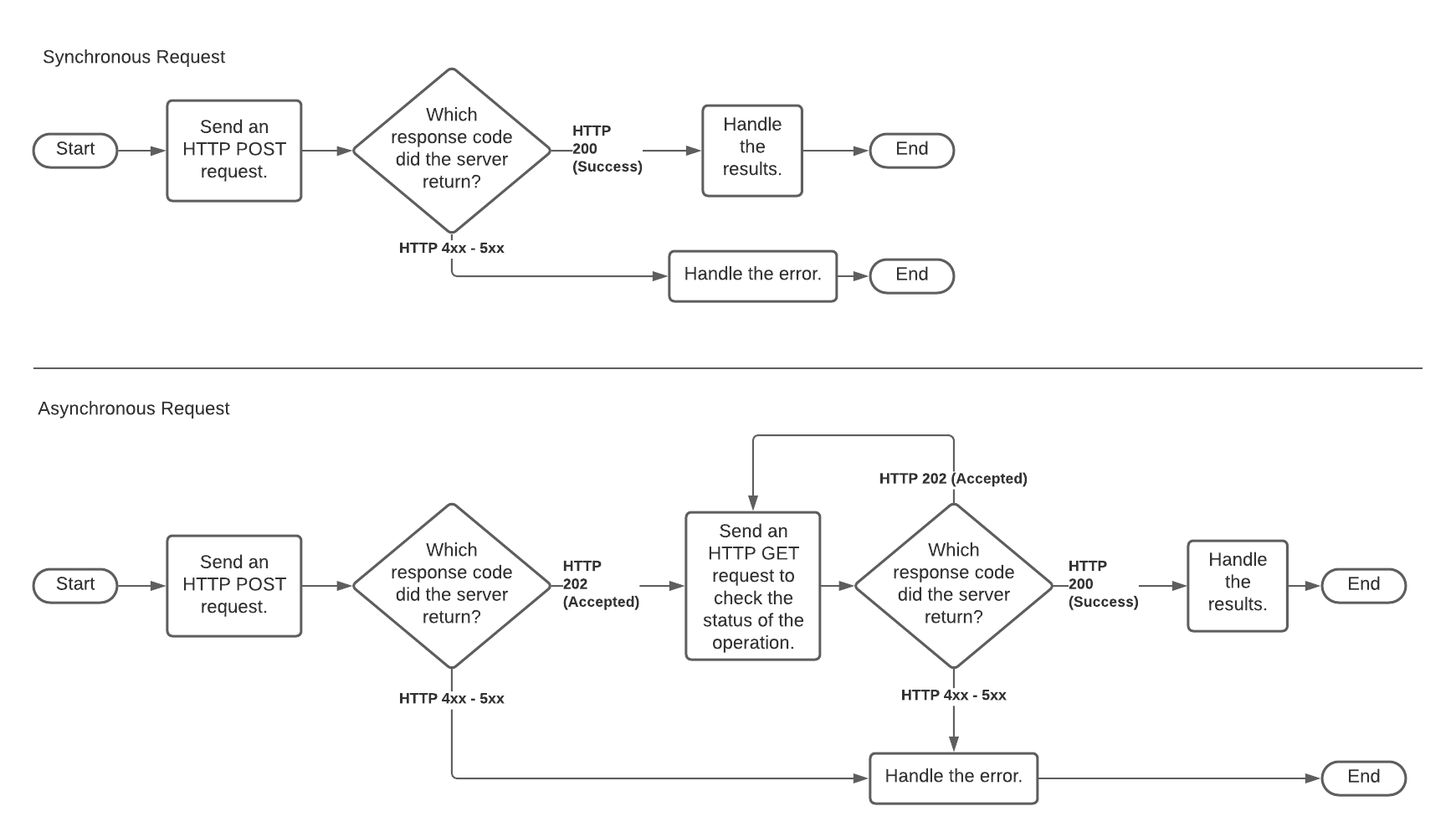
A synchronous remote service receives an HTTP POST request, processes the request, and returns the result. Depending upon how long it takes to process the data, there can be a significant delay between the time that request is received and the results are returned.
An asynchronous remote service receives an HTTP POST request and returns a (usually almost immediate) acknowledgement that the request was received. The caller (Snowflake) then executes a polling loop in which it issues one or more HTTP GET requests (usually with a significant delay between each request) to check the status of asynchronous processing. A GET does not send any data in the request body, but contains the same headers as the original POST.
Asynchronous remote services are useful when a remote service exceeds the timeouts built into components such as the proxy service (e.g. Amazon API Gateway).
A remote service is not necessarily purely synchronous or purely asynchronous. A remote service can operate synchronously and asynchronously at different times, depending upon factors such as the amount of data in the request, the number of other requests being processed, etc.
Snowflake’s implementation of external functions is generally compatible with both synchronous and asynchronous third party function libraries.
The diagram below contrasts synchronous and asynchronous processing. The upper path is synchronous. The lower path (which includes one or more HTTP GET requests) is asynchronous.
To view examples of synchronous and asynchronous external functions, see Snowflake Sample Functions.
Synchronous remote service¶
Before a user can call an external function, developers and Snowflake account administrators must configure Snowflake to access the proxy service. Typically, the steps are done in approximately the order shown below (starting from the right-hand side of the diagram above and moving leftward towards Snowflake).
-
A developer must write the remote service, and that remote service must be exposed via the HTTPS proxy service. For example, the remote service might be a Python function running on AWS Lambda and exposed via a resource in the Amazon API Gateway.
-
In Snowflake, an ACCOUNTADMIN or a role with the CREATE INTEGRATION privilege must create an “API integration” object that contains authentication information that enables Snowflake to communicate with the proxy service. The API integration is created with the SQL command CREATE API INTEGRATION.
-
A Snowflake user must execute the SQL command CREATE EXTERNAL FUNCTION. The user must use a role that has USAGE privilege on the API integration and has sufficient privileges to create functions.
Note
The CREATE EXTERNAL FUNCTION command does not actually create an external function in the sense of loading code that will be “executed outside Snowflake”. Instead, the CREATE EXTERNAL FUNCTION command creates a database object that indirectly references the code that executes outside Snowflake. More precisely, the CREATE EXTERNAL FUNCTION command creates an object that contains:
- The URL of the resource in the HTTPS proxy service that acts as a relay function.
- The name of the API integration to use to authenticate to the proxy service.
- A name that is effectively an alias for the remote service. This alias is used in SQL commands,
for example
SELECT MyAliasForRemoteServiceXYZ(col1) ...;
The alias in Snowflake, the HTTPS proxy service resource’s name, and the remote service’s name can all be different. (Using the same name for all three can simplify administration, however.)
Although the steps described above are the most common way of executing an external function, some variations are allowed. For example:
- The remote service might not be the final step in the chain; the remote service could call yet another remote service to do part of the work.
- If the remote service doesn’t accept and return JSON-formatted data, then the HTTPS proxy service’s resource (the relay function) could convert the data from JSON format to another format (and convert the returned data back to JSON).
- Although Snowflake recommends that the remote service behave as a true function (i.e. a piece of code that accepts 0 or more input parameters and returns an output) that has no side effects and keeps no state information, this is not strictly required. The remote service could perform other tasks, for example sending alerts if a value (such as a temperature reading in the data) is dangerously high. In rare cases, the remote service might keep state information, for example the total number of alerts issued.
Asynchronous remote service¶
An asynchronous remote service is useful when a remote service exceeds the timeouts built into components such as the proxy service.
An asynchronous remote service involves the same components (client, Snowflake, proxy service, and remote service) and the same general steps as described above. However, the details of the HTTP requests and responses are different.
Asynchronous behavior is implemented by the person who writes the remote service (and by Snowflake). SQL statements are the same for asynchronous remote services as for synchronous remote services.
If you are writing your own remote service and want to make it compatible with Snowflake’s asynchronous handling, write the remote service to behave as follows:
- When it initially receives an HTTP POST for a specific batch of rows, the remote service returns HTTP code 202 (“Processing…”).
- If the remote service receives any HTTP GET requests after the POST but before the output is ready, the remote service returns HTTP code 202.
- After the remote service has generated all of the output rows, it waits for the next HTTP GET with the same batch ID, and then returns the rows received, along with HTTP code 200 (“Successful completion…”).
In short, for each batch received, the remote service returns 202 until the results are ready, after which the next GET receives the results and an HTTP 200.
For each batch, Snowflake works with the asynchronous remote service as follows:
-
Snowflake sends an HTTP POST that contains the data to process, along with a unique batch ID.
-
If Snowflake receives an HTTP 202 response, then Snowflake loops until one of the following is true:
- Snowflake receives the data and an HTTP 200.
- Snowflake’s internal timeout is reached.
- Snowflake receives an error (e.g. HTTP response code 5XX).
In each iteration of the loop, Snowflake delays, then issues an HTTP GET that contains the same batch ID as the corresponding HTTP POST’s batch ID, so that the remote service can return information for the correct batch.
The delay inside the loop starts out short but grows longer for each HTTP 202 response received until Snowflake’s timeout is reached.
-
If Snowflake’s timeout is reached before HTTP 200 is returned, then Snowflake aborts the SQL query.
Currently, Snowflake’s timeout is 10 minutes (600 seconds) and is not user-configurable. This timeout might change in the future.
Note
The frequency with which queries hit timeouts depends in part upon the scalability of the remote service. If your remote service times out frequently, then see also the discussion of Scalability.
Scalability¶
The remote service, the proxy service, and any other steps between Snowflake and the remote service, must be able to handle the peak workloads sent to them.
Some cloud platform providers have default usage limits or other quotas for proxy services and remote services, which can limit the throughput of external function calls.
Larger Snowflake warehouse sizes can increase the concurrency with which requests are sent, which might exceed the proxy service’s quota.
Users can see how many times Snowflake had to retry sending request batches (due to throttling or other errors) for a query by looking at the value for Retries due to transient errors on the query profile.
Scalability of the remote service¶
Developers who write remote services should consider:
- The frequency with which the remote service will be called.
- The number of rows sent per call.
- The resources required to process each row.
- The time distribution of calls (peak vs. average).
Capacity might need to increase over time as the callers change from a few developers and testers to an entire organization. If the remote service is used by multiple organizations, capacity might need to increase as the number of organizations increases. Furthermore, as the number and diversity of organizations increase, the size and timing of workloads might become more difficult to predict.
The remote service provider is responsible for providing enough capacity to handle peak workloads. Different techniques can be used to scale the service. If the remote service is managed by the author of the remote service, then the author might need to explicitly provision the service with enough capacity to handle peaks. Alternatively, the author might decide to use a hosted auto-scaled/elastic service, such as AWS Lambda.
Remote services should return HTTP response code 429 when overloaded. If Snowflake sees HTTP 429, Snowflake scales back the rate at which it sends rows, and retries sending batches of rows that were not processed successfully.
For more information about troubleshooting scalability issues, see Troubleshooting scalability and performance issues.
If remote service invocations time out because each individual invocation takes a long time, rather than because the system is generally overloaded, then see the description of how to build an Asynchronous remote service.
Scalability of the proxy service¶
The proxy service should also be scalable. Fortunately, proxy services provided by major cloud providers are generally scalable.
However, some proxy services, including Amazon API Gateway and Azure API Management, have default usage limits. When the request rate exceeds the limit, these proxy services throttle requests. If necessary, you might need to ask AWS or Azure to increase your quota on your proxy service.
Users who develop or administer external functions should remember the following platform-specific information:
- Amazon API Gateway:
The Amazon API Gateway is itself a managed AWS service, which auto-scales to users’ workloads. Users should be familiar with various limits of API Gateway .
The Amazon API Gateway can be configured to help scale the remote service. Specifically, the API Gateway can be configured to enable caching and/or throttling of requests to reduce the load on the remote service if needed:
Because throttling can affect timeouts and retries, users might also want to review information about how Snowflake handles timeouts and retries:
- Azure API Management Service:
For Azure API Management, the limits depend on the SKU chosen for the service. The limits are documented in the API Management limits section of the Azure Subscription Service Limits .
Because throttling can affect timeouts and retries, users might also want to review information about how Snowflake handles timeouts and retries:
Troubleshooting scalability and performance issues¶
- Use the QUERY_HISTORY , QUERY_HISTORY_BY_* function to observe performance characteristics and help debug performance issues.
- Use the Query History page page to see average latency per request.
- Use the Query History page page to see how many times requests were retried due to transient errors, including those listed in the section titled Do not assume that the remote service is passed each row exactly once.
- Monitor your remote service resource usage to see how it scales to the load, and ensure that the remote service has enough capacity to serve peak load.
- Utilize logging in the Amazon API Gateway or in the remote service to get per-request details.
- Control the concurrency with which Snowflake sends requests to their remote service. For more details, see concurrency.
- Return HTTP Response Code 429 from the remote service when it is overloaded. Return this as early as possible, rather than wait for latency to increase.
- Take into account the proxy service timeout. For example, as of July 2020, the timeout for Amazon API Gateway is 30 seconds. Timeouts can be caused by various factors, including overloading of the remote service.
Snowflake attempts to retry transient errors/timeouts within a reasonable time, but if the service continues to be overloaded, and retries do not succeed, eventually the query is aborted.
Concurrency¶
Resource requirements depend upon the way that rows are distributed across calls (many parallel calls with a few rows each vs. one call with the same total number of rows). A system that supports high capacity does not necessarily support high concurrency, and vice-versa. You should estimate the peak concurrency required, as well as the largest reasonable individual workloads, and provide enough resources to handle both types of peaks.
Furthermore, the concurrency estimate should take into account that Snowflake can parallelize external function calls. A single query from a single user might cause multiple calls to the remote service in parallel. Several factors affect the number of concurrent calls from Snowflake to a proxy service or remote service, including:
- The number of concurrent users who are running queries with external functions.
- The size of each user’s query.
- The amount of compute resources in the virtual warehouse (i.e. the warehouse size).
- The number of warehouses.
Handling concurrency properly can be particularly complex if external functions have side effects. The results can vary depending upon the order in which user’s rows are processed. (Snowflake recommends that you avoid writing or using remote services that have side effects.)
Reliability¶
Depending upon where the remote service is running, you might need to consider:
- Reliability.
- Error-handling.
- Debugging.
- Upgrading (if the remote service might add new features or need bug fixes).
If the remote service is not stateless, you might also need to consider recovery after failure. (Snowflake strongly recommends that remote services be stateless.)
For information about timeouts and retries, see Account for timeout errors and Do not assume that the remote service is passed each row exactly once.