Parameters¶
Snowflake provides parameters that let you control the behavior of your account, individual user sessions, and objects. All parameters have default values. You can set these parameters and override them at different levels, depending on the parameter type (account, session, or object).
Parameter hierarchy and types¶
This section describes the different types of parameters and the levels at which each type can be set. There are three types of parameters:
The following diagram illustrates the hierarchical relationship between the different parameter types and how individual parameters can be overridden at each level:
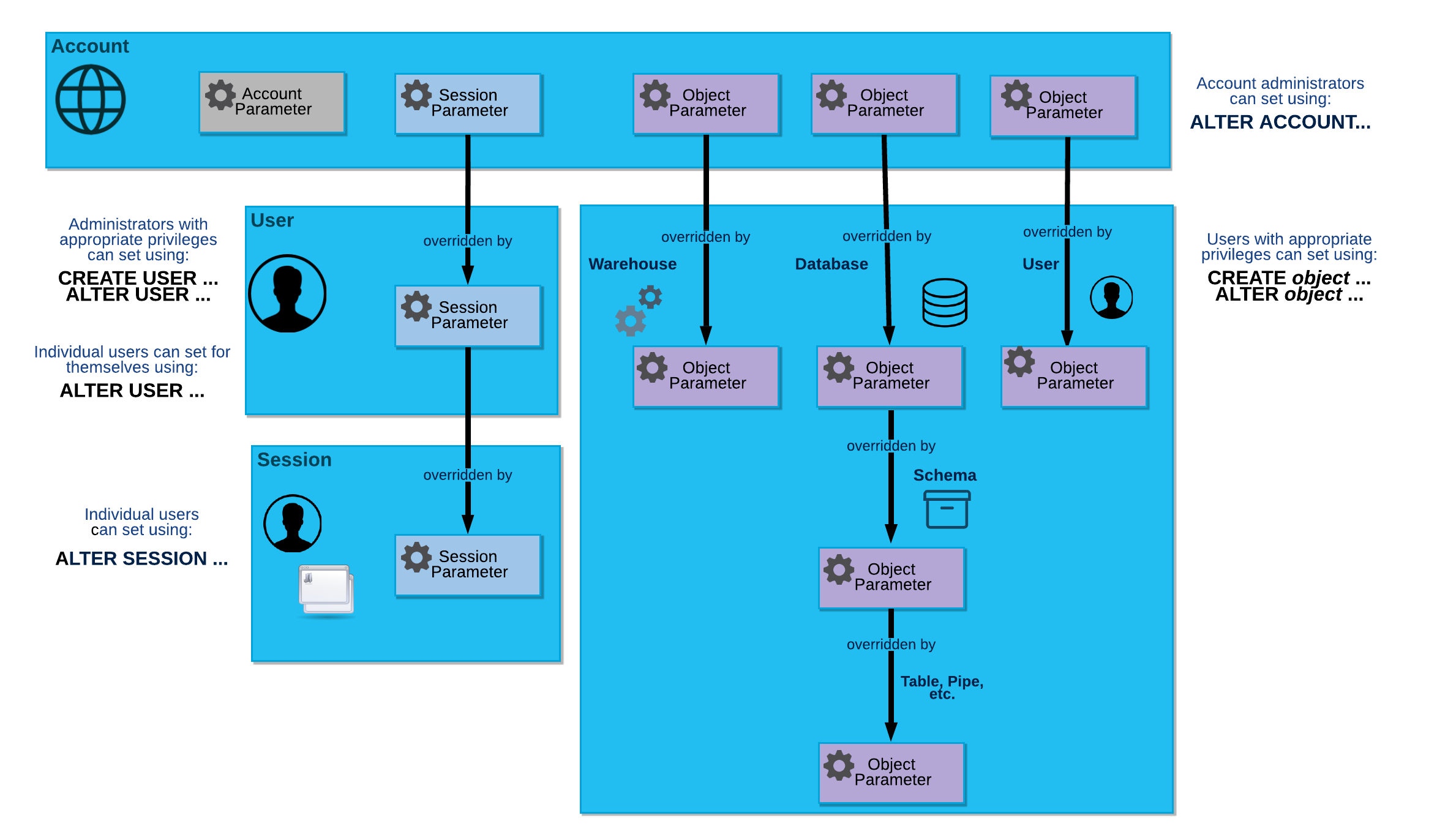
Account parameters¶
You can only set account parameters at the account level, if you are using a role that has been granted the privilege to set the parameter. To set an account parameter, you run the ALTER ACCOUNT command.
Snowflake provides the following account parameters:
| Parameter | Notes |
|---|---|
| ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES | Used to specify the file extensions allowed in private workspaces for the account. |
| ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_SHARED_WORKSPACES | Used to specify the file extensions allowed in shared workspaces for the account. |
| ALLOW_BIND_VALUES_ACCESS | Used to allow clients to access bind variable values. |
| ALLOW_CLIENT_MFA_CACHING | |
| ALLOW_ID_TOKEN | Used to enable connection caching in browser-based single sign-on (SSO) for Snowflake-provided clients. |
| ALLOWED_SPCS_WORKLOAD_TYPES | Used to specify the workload types that are allowed in your account to deploy to Snowpark Container Services. |
| CLIENT_ENCRYPTION_KEY_SIZE | Used for encryption of files staged for data loading or unloading; might require additional installation and configuration (see description for details). |
| COCO_CLOUD_AGENTS_NON_SNOWFLAKE_EGRESS_DISABLED | Used to disable non-Snowflake network egress from the Cortex Code Cloud Agents sandbox for the account. |
| COCO_SNOWSIGHT_ALLOW_ALL_PERMISSION_OPTIONS_DISABLED | Used to disable the allow-all permission options for tool calls (for example, SQL execution or Bash) in Cortex Code in Snowsight. |
| CORTEX_ENABLED_CROSS_REGION | Used to enable cross-region processing of Snowflake Cortex calls in a different region if the call cannot be processed in your account region. |
| DEFAULT_DBT_VERSION | Used to set the default version for all future dbt project objects created in an account. |
| DISABLE_USER_PRIVILEGE_GRANTS | Used to disable granting of privileges directly to users. For more information, see GRANT privileges to USERS Usage notes. |
| DISALLOWED_SPCS_WORKLOAD_TYPES | Used to specify the workload types that are disallowed in your account to deploy to Snowpark Container Services. |
| ENABLE_AUTOMATIC_SENSITIVE_DATA_CLASSIFICATION_LOG | Controls whether events from sensitive data classification are logged to the user event table. |
| ENABLE_BUDGET_EVENT_LOGGING | Controls whether events from budgets are logged to the event table. |
| ENABLE_DUAL_STACK_LOAD_BALANCER | Enables IPv6 ingress by adding dual-stack (IPv4 + IPv6) endpoints for the account (AWS only). |
| ENABLE_EGRESS_COST_OPTIMIZER | Used to enable or disable listing auto-fulfillment egress cost egress optimization. |
| ENABLE_IDENTIFIER_FIRST_LOGIN | |
| ENABLE_INTERNAL_STAGES_PRIVATELINK | Allows the SYSTEM$GET_PRIVATELINK_CONFIG function to return the private-internal-stages key in the query result. |
| ENABLE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK | Allows the SYSTEM$GET_PRIVATELINK_CONFIG function to return the privatelink-snowflake-managed-storage-volume-nfs and privatelink-snowflake-managed-storage-volume-fs keys in the query result on Azure deployments. |
| ENABLE_NOTEBOOK_CREATION_IN_PERSONAL_DB | Used to enable or disable private notebooks on a Snowflake account. |
| ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT | Used to enable enforcement of SNOWFLAKE_FULL encryption for Snowpark Container Services block-storage volumes and snapshots. |
| ENABLE_TAG_PROPAGATION_EVENT_LOGGING | Controls whether Snowflake collects telemetry data for tag propagation. |
| ENABLE_TRI_SECRET_AND_REKEY_OPT_OUT_FOR_IMAGE_REPOSITORY | Used to specify an image Repository’s choice to opt out of Tri-Secret Secure and Periodic rekeying. |
| ENABLE_WORKSPACE_FILE_CONTENT_SEARCH | Controls whether Universal Search indexes the contents of workspace files, enabling it to search within workspace files, return more complete results, and better rank them by relevance. |
| ENFORCE_NETWORK_RULES_FOR_INTERNAL_STAGES | |
| ENFORCE_NETWORK_RULES_FOR_SNOWFLAKE_MANAGED_STORAGE_VOLUME | |
| EXTERNAL_OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST | |
| INITIAL_REPLICATION_SIZE_LIMIT_IN_TB | |
| LISTING_AUTO_FULFILLMENT_REPLICATION_REFRESH_SCHEDULE | Used to set the refresh schedule for all listings in an account. |
| MAP_SCIM_USERNAME_TO_ENTERPRISE_ATTR | Controls how SCIM user attributes map to the Snowflake NAME and LOGIN_NAME properties. |
| MIN_DATA_RETENTION_TIME_IN_DAYS | Used to set the minimum data retention period for retaining historical data for Time Travel operations. |
| NETWORK_POLICY | This is the only account parameter that can be set by either account administrators (i.e users with the ACCOUNTADMIN system role) or security administrators (i.e users with the SECURITYADMIN system role). For more information, see Object parameters. |
| OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST | |
| PERIODIC_DATA_REKEYING | |
| READ_CONSISTENCY_MODE | |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | |
| SQL_TRACE_QUERY_TEXT | Used to specify whether to capture the SQL text of a traced SQL statement. |
| SSO_LOGIN_PAGE | |
| USE_WORKSPACES_FOR_SQL | Used to enable or disable Workspaces as the default SQL editor for the account. |
Note
By default, account parameters are not displayed in the output of SHOW PARAMETERS. For information about viewing account parameters, see Viewing the Parameters and Their Values (in this topic).
Session parameters¶
Most parameters are session parameters, which you can set at the following levels:
- Account:
Account administrators can run the ALTER ACCOUNT command to set session parameters for the account.
The values that you set at this level become the default values for individual users and their sessions.
- User:
Administrators with the appropriate privileges (typically, a user who has been granted the SECURITYADMIN role) can run the ALTER USER command to override session parameters for individual users. In addition, individual users can run the ALTER USER command to override default sessions parameters for themselves.
The values set that you set for a user become the default values in any session started by that user.
- Session:
Users can run the ALTER SESSION command to override session parameters for the current session.
Note
By default, only session parameters are displayed in the output of SHOW PARAMETERS. For information about viewing account and object parameters, see Viewing the Parameters and Their Values (in this topic).
Object parameters¶
You can set object parameters at the following levels:
- Account:
Account administrators can run the ALTER ACCOUNT command to set object parameters for objects in the account.
The values that you set at this level become the default values for individual objects created in the account.
- Object:
Users with the appropriate privileges can run the CREATE <object> or ALTER <object> commands to override object parameters for an individual object.
Snowflake provides the following object parameters:
| Parameter | Object Type | Notes |
|---|---|---|
| AUTO_EVENT_LOGGING | Snowflake Scripting stored procedure | |
| BASE_LOCATION_PREFIX | Database, Schema | Specifies a prefix to use in the write path for Apache Iceberg™ table files. |
| CATALOG | Database, Schema, Apache Iceberg™ table | |
| CATALOG_SYNC | Account, Database, Schema, Apache Iceberg™ table | This parameter is only supported for Snowflake-managed Iceberg tables that you sync with Open Catalog. |
| CORTEX_CODE_CLI_DAILY_EST_CREDIT_LIMIT_PER_USER | User | Sets a daily estimated credit usage limit per user for Cortex Code CLI. |
| CORTEX_CODE_DESKTOP_DAILY_EST_CREDIT_LIMIT_PER_USER | User | Sets a daily estimated credit usage limit per user for Cortex Code Desktop. |
| CORTEX_CODE_SNOWSIGHT_DAILY_EST_CREDIT_LIMIT_PER_USER | User | Sets a daily estimated credit usage limit per user for Cortex Code in Snowsight. |
| CORTEX_MODELS_ALLOWLIST | Cortex AI Functions and models | Comma-separated names of allowed Cortex language models, 'All', or 'None'. |
| DATA_METRIC_SCHEDULE | Table | Specifies the schedule to run the data metric functions associated to the table. All data metric functions on the table or view follow the same schedule. |
| DATA_RETENTION_TIME_IN_DAYS | Database, Schema, Table | |
| DEFAULT_DDL_COLLATION | Database, Schema, Table | |
| DEFAULT_METADATA_WRITE_FORMAT | Account, Database, Schema | Sets the default metadata write format for CREATE TABLE and ALTER TABLE. For more information, see Configure Iceberg as the default metadata format for tables. |
| DEFAULT_NOTEBOOK_COMPUTE_POOL_CPU | Database, Schema | System compute pools |
| DEFAULT_NOTEBOOK_COMPUTE_POOL_GPU | Database, Schema | System compute pools |
| DEFAULT_STREAMLIT_COMPUTE_POOL | Account | Configuring your own preferred compute pools for Streamlit apps |
| DEFAULT_STREAMLIT_NOTEBOOK_WAREHOUSE | Account, Database, Schema | |
| DISABLE_UI_DOWNLOAD_BUTTON | Account, User | |
| ENABLE_DATA_COMPACTION | Account, Database, Schema, Apache Iceberg™ table | This parameter is only supported for Snowflake-managed Iceberg tables. |
| ENABLE_ICEBERG_MERGE_ON_READ | Account, Database, Schema, Apache Iceberg™ table | |
| ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR | User | Affects the query history for queries that fail because of syntax or parsing errors. |
| ENABLE_UNREDACTED_SECURE_OBJECT_ERROR | User | Affects redaction of error messages related to secure objects in metadata. |
| EVENT_TABLE | Database, Account | |
| EXTERNAL_VOLUME | Database, Schema, Apache Iceberg™ table | |
| ICEBERG_DEFAULT_DDL_COLLATION | Account, Database, Schema, Table | Sets the default collation for new string columns on Snowflake-managed Iceberg tables. |
| ICEBERG_TIMESTAMP_DEFAULT_PRECISION | Session | Specifies the default precision for Apache Iceberg™ timestamp columns when no precision is specified in DDL. |
| ICEBERG_VERSION | Apache Iceberg™ table | |
| ICEBERG_VERSION_DEFAULT | Account, Database, Schema | |
| LOG_LEVEL | Account, Database, Schema, DCM project, Stored Procedure, Function, Dynamic Table, Iceberg table, Task, Service. | Log messages from logging APIs. |
| LOG_EVENT_LEVEL | Account, Database, Schema, DCM project, Stored Procedure, Function, Dynamic Table, Iceberg table, Task, Service. | Log events (record type EVENT) written to the event table. |
| MAX_CONCURRENCY_LEVEL | Warehouse | |
| MAX_DATA_EXTENSION_TIME_IN_DAYS | Database, Schema, Table | |
| METRIC_LEVEL | Account, Database, Schema, Stored Procedure, Function | |
| NETWORK_POLICY | User | This is the only user parameter that can be set by either account administrators (users with the ACCOUNTADMIN system role) or security administrators (users with the SECURITYADMIN system role). If this parameter is set on the account and a user in the same account, the user-level network policy overrides the account-level network policy. |
| OAUTH_AUTHORIZATION_SERVER | Account, Database, Schema | Specifies the name of an External OAuth security integration to use as the authorization server for MCP server Protected Resource Metadata discovery and token enforcement. |
| OAUTH_SCOPES_SUPPORTED | Account, Database, Schema | Specifies a comma-separated list of OAuth scopes advertised in MCP server Protected Resource Metadata. |
| PATH_LAYOUT | Apache Iceberg™ table | Specifies the path layout for Parquet data files written to partitioned Iceberg tables. |
| PURGE_ON_DROP_TABLE | Database, Schema, Apache Iceberg™ table | When set to TRUE on a catalog-linked database, schema, or table, automatically forwards the purge intent to the external catalog whenever the table is dropped. Applies only to externally managed Iceberg tables in a catalog-linked database. |
| PIPE_EXECUTION_PAUSED | Schema, Pipe | |
| PREVENT_UNLOAD_TO_INLINE_URL | User | |
| PREVENT_UNLOAD_TO_INTERNAL_STAGES | User | |
| REPLACE_INVALID_CHARACTERS | Database, Schema, file format, Apache Iceberg™ table | Can only be set for Iceberg tables that use an external Iceberg catalog. |
| ROW_TIMESTAMP | Database, Schema, Table | Use this parameter to enable row timestamps on your tables. For more information, see Use row timestamps to measure latency in your pipelines. |
| ROW_TIMESTAMP_DEFAULT | Database, Schema, Table | Use this parameter to set row timestamps by default for new tables in a container. For more information, see Use row timestamps to measure latency in your pipelines. |
| SERVERLESS_TASK_MAX_STATEMENT_SIZE | Database, Schema, Task, Account | |
| SERVERLESS_TASK_MIN_STATEMENT_SIZE | Database, Schema, Task, Account | |
| SERVICE_CALLER_TOKEN_VALIDITY_SECS | Account, Database, Schema, Service | Controls how long a caller’s rights login token is valid for Snowpark Container Services. |
| STATEMENT_QUEUED_TIMEOUT_IN_SECONDS | Warehouse | Also a session parameter (can be set at both the object and session levels). For inheritance and override details, see the parameter description. |
| STATEMENT_TIMEOUT_IN_SECONDS | Warehouse | Also a session parameter (can be set at both the object and session levels). For inheritance and override details, see the parameter description. |
| STORAGE_SERIALIZATION_POLICY | Database, Schema, Apache Iceberg™ table | This parameter is only supported for Iceberg tables that use Snowflake as the catalog. |
| SUSPEND_ALERT_AFTER_NUM_FAILURES | Account, Database, Schema, Alert | |
| SUSPEND_TASK_AFTER_NUM_FAILURES | Database, Schema, Task | |
| TASK_AUTO_RETRY_ATTEMPTS | Database, Schema, Task | |
| TRACE_LEVEL | Account, Database, Schema, Stored Procedure, Function | |
| USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE | Database, Schema, Task | |
| USER_TASK_MINIMUM_TRIGGER_INTERVAL_IN_SECONDS | Database, Schema, Task | |
| USER_TASK_TIMEOUT_MS | Database, Schema, Task |
Note
By default, object parameters are not displayed in the output of SHOW PARAMETERS. For information about viewing object parameters, see Viewing the Parameters and Their Values (in this topic).
Viewing the parameters and their values¶
To view the parameters that are set and their default values, run the SHOW PARAMETERS command. You can run the command with different command parameters to display different types of parameter:
- Viewing session parameters
- Viewing object parameters
- Viewing all parameters (including account and object parameters)
- Limiting the list of parameters by name
Viewing session parameters¶
By default, the command displays only session parameters:
Viewing object parameters¶
To display the object parameters for a specific object, include the IN clause with the object type and name. For example:
Viewing all parameters (including account and object parameters)¶
To display all parameters, including account and object parameters, include the IN ACCOUNT clause:
Limiting the list of parameters by name¶
You can specify the LIKE clause to limit the list of parameters by name. For example:
-
To display the session parameters with names containing “time”:
-
To display all the parameters with names starting with “time”:
Note
You must specify the LIKE clause before the IN clause.
ABORT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies the action that Snowflake performs for in-progress queries if connectivity is lost due to abrupt termination of a session (e.g. network outage, browser termination, service interruption).
- Values:
TRUE: In-progress queries are aborted 5 minutes after connectivity is lost.FALSE: In-progress queries are completed.- Default:
FALSE
Note
-
For client drivers, closing the connection from the client side (such as calling
connection.close()) is different from actually logging out from the Snowflake session. Closing the connection can be associated with cleaning up resources owned by the connection, including but not limited to performing a session logout. Performing a session logout also implies that any queries still running in the same session (for example, queries submitted asynchronously) are canceled after a couple of minutes when the session is logged out, even if the ABORT_DETACHED_QUERY parameter is set tofalse(the default value).Therefore, some Snowflake drivers implement their own business logic to decide whether session logout is performed when the connection is closed.
Currently, this functionality is implemented in the following drivers:
-
Most queries require compute resources in order to be executed. These resources are provided by virtual warehouses, which consume credits while running. If the Snowflake session is not terminated when the connection closes, warehouses might continue running and consuming credits to complete any queries that were in progress at the time the connection was closed, up to the value of the STATEMENT_TIMEOUT_IN_SECONDS parameter, which has a default of two days.
ACTIVE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
Sets the profiler to use for the session when profiling Python handler code.
- Values:
'LINE': To have the profile focus on line use activity.'MEMORY': To have the profile focus on memory use activity.- Default:
None.
ACCOUNT_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the file extensions that are allowed in private workspaces for the account. The value is a comma-separated list of extensions, for example:
.ipynb,.sql,.txt. If the parameter is empty (default), all file extensions are allowed.When the allow list is non-empty:
- Only the listed extensions are permitted; all others are blocked.
- Files uploaded through Workspaces with a non-allowed extension will immediately fail to upload.
- If a file is renamed to use a non-allowed extension, the file becomes inaccessible within the workspace.
- Pre-existing files with disallowed extensions will not appear in Workspaces.
- Users can still use the Snowflake CLI
PUTcommand to upload files with non-allowed extensions to a workspace’s virtual stage or a Notebook Project Object’s virtual stage. However, these files are inaccessible and cannot be used, viewed, downloaded (viaGET), or listed (viaLIST) from within the workspace or Notebook Project Object environment. - To maintain core workspace functionality, include
.ipynband.sqlin the allow list. - Files without an extension (for example,
Makefile) are not allowed once the list is non-empty. - Dotfiles (for example,
.gitignoreor.venv) must be explicitly added to the list. - Extension matching is case-sensitive. For example, if
.txtis in the list,.TXTis not allowed.
- Default:
Empty string (all extensions allowed)
ACCOUNT_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the file extensions that are allowed in shared workspaces for the account. The value is a comma-separated list of extensions, for example:
.ipynb,.sql,.txt. If the parameter is empty (default), all file extensions are allowed.When the allow list is non-empty:
- Only the listed extensions are permitted; all others are blocked.
- Files uploaded through Workspaces with a non-allowed extension will immediately fail to upload.
- If a file is renamed to use a non-allowed extension, the file becomes inaccessible within the workspace.
- Pre-existing files with disallowed extensions will not appear in Workspaces.
- Users can still use the Snowflake CLI
PUTcommand to upload files with non-allowed extensions to a workspace’s virtual stage or a Notebook Project Object’s virtual stage. However, these files are inaccessible and cannot be used, viewed, downloaded (viaGET), or listed (viaLIST) from within the workspace or Notebook Project Object environment. - To maintain core workspace functionality, include
.ipynband.sqlin the allow list. - Files without an extension (for example,
Makefile) are not allowed once the list is non-empty. - Dotfiles (for example,
.gitignoreor.venv) must be explicitly added to the list. - Extension matching is case-sensitive. For example, if
.txtis in the list,.TXTis not allowed. - Files with disallowed extensions that originate from a connected Git repository are visible to the user but remain inaccessible within the workspace.
- Default:
Empty string (all extensions allowed)
ALLOW_
- Type:
Account — Can only be set for Account
- Data Type:
Boolean
- Description:
Specifies whether clients can access bind variable values by using the BIND_VALUES table function, the QUERY_HISTORY Account Usage view, the QUERY_HISTORY Organization Usage view, or the QUERY_HISTORY function. For more information, see Retrieve bind variable values.
- Values:
TRUE: Allows the retrieval of bind variable values.FALSE: Doesn’t allow retrieval of bind variable values.- Default:
TRUE
ALLOW_
- Type:
Account — Can only be set for Account
- Data Type:
Boolean
- Description:
Specifies whether an MFA token can be saved in the client-side operating system keystore to promote continuous, secure connectivity without users needing to respond to an MFA prompt at the start of each connection attempt to Snowflake. For details and the list of supported Snowflake-provided clients, see Using MFA token caching to minimize the number of prompts during authentication — *optional*.
- Values:
TRUE: Stores an MFA token in the client-side operating system keystore to enable the client application to use the MFA token whenever a new connection is established. While true, users are not prompted to respond to additional MFA prompts.FALSE: Does not store an MFA token. Users must respond to an MFA prompt whenever the client application establishes a new connection with Snowflake.- Default:
FALSE
ALLOW_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether a connection token can be saved in the client-side operating system keystore to promote continuous, secure connectivity without users needing to enter login credentials at the start of each connection attempt to Snowflake. For details and the list of supported Snowflake-provided clients, see Using connection caching to minimize the number of prompts for authentication — *Optional*.
- Values:
TRUE: Stores a connection token in the client-side operating system keystore to enable the client application to perform browser-based SSO without prompting users to authenticate whenever a new connection is established.FALSE: Does not store a connection token. Users are prompted to authenticate whenever the client application establishes a new connection with Snowflake. SSO to Snowflake is still possible if this parameter is set to false.- Default:
FALSE
ALLOWED_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the workload types that are allowed in your account to deploy to Snowpark Container Services. Also see DISALLOWED_SPCS_WORKLOAD_TYPES.
- Values:
The value is a comma-separated list of the following supported workload types:
USER: Any workloads directly deployed by users.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit in Snowflake.MODEL_SERVING: ML Model Serving.ML_JOB: Snowflake ML Jobs.ALL: All workloads.
- Default:
ALL
Note
If you configure both ALLOWED_SPCS_WORKLOAD_TYPES and DISALLOWED_SPCS_WORKLOAD_TYPES, DISALLOWED_SPCS_WORKLOAD_TYPES takes precedence. For example, if you configure both these parameters and specify the NOTEBOOK workload, NOTEBOOK workloads aren’t allowed to run on Snowpark Container Services.
AUTO_
- Type:
Object (for Snowflake Scripting stored procedures)
- Data Type:
String (Constant)
- Description:
Controls whether Snowflake Scripting log messages and trace events are ingested automatically into the event table. To set this parameter, run the ALTER PROCEDURE command.
- Values:
-
LOGGING: Automatically adds the following additional logging information to the event table when a procedure is executed:- BEGIN/END of a Snowflake Scripting block.
- BEGIN/END of a child job request.
This information is added to the event table only if the effective LOG_LEVEL is set to
TRACEfor the stored procedure. -
TRACING: Automatically adds the following additional trace information to the event table when a stored procedure is executed:- Exception catching.
- Information about child job execution.
- Child job statistics.
- Stored procedure statistics, including execution time and input values.
This information is added to the event table only if the effective TRACE_LEVEL is set to
ALWAYSorON_EVENTfor the stored procedure. -
ALL: Automatically adds both the logging information added for theLOGGINGvalue and the trace information added for theTRACINGvalue. -
OFF: Does not automatically add logging information or trace information to the event table.
-
- Default:
OFF
For more information about using this parameter, see Setting levels for logging, metrics, and tracing, Automatically add log messages about blocks and child jobs, and Automatically emit trace events for child jobs and exceptions.
AUTOCOMMIT¶
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether autocommit is enabled for the session. Autocommit determines whether a DML statement, when executed without an active transaction, is automatically committed after the statement successfully completes. For more information, see Transactions.
Note
Setting this parameter to
FALSEstops usage data from being saved to the ORGANIZATION_USAGE schema of an organization account.- Values:
TRUE: Autocommit is enabled.FALSE: Autocommit is disabled, meaning DML statements must be explicitly committed or rolled back.- Default:
TRUE
Note
The FALSE value isn’t supported for tasks.
AUTOCOMMIT_
- Type:
N/A
- Data Type:
Boolean
- Description:
For Snowflake internal use only. View-only parameter that indicates whether API support for autocommit is enabled for your account. If the value is
TRUE, you can enable or disable autocommit through the APIs for the following drivers/connectors:
BASE_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Specifies a prefix for Snowflake to use in the write path for Snowflake-managed Apache Iceberg™ tables. For more information, see data and metadata directories for Iceberg tables.
- Values:
Any valid string prefix that complies with the storage naming conventions of your cloud provider.
- Default:
None
BINARY_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
The format of VARCHAR values passed as input to VARCHAR-to-BINARY conversion functions. For more information, see Binary input and output.
- Values:
HEX,BASE64, orUTF8/UTF-8- Default:
HEX
BINARY_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
The format for VARCHAR values returned as output by BINARY-to-VARCHAR conversion functions. For more information, see Binary input and output.
- Values:
HEXorBASE64- Default:
HEX
CATALOG¶
- Type:
Object (for databases, schemas, and Apache Iceberg™ tables) — Can be set for Account » Database » Schema » Iceberg table
- Data Type:
String
- Description:
Specifies the catalog for Apache Iceberg™ tables. For more information, see the Iceberg table documentation.
- Values:
SNOWFLAKEor any valid catalog integration identifier.- Default:
None
CATALOG_
- Type:
Object (for databases, schemas, and Iceberg tables) — Can be set for Account » Database » Schema » Iceberg Table
- Data Type:
String
- Description:
Specifies the name of your catalog integration for Snowflake Open Catalog. Snowflake syncs tables that use the specified catalog integration with your Snowflake Open Catalog account. For more information, see Sync a Snowflake-managed table with Snowflake Open Catalog.
- Values:
The name of any existing catalog integration for Open Catalog.
- Default:
None
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Clients:
JDBC
- Description:
Enables users to log the data values bound to PreparedStatements.
To see the values, you must not only set this session-level parameter to
TRUE, but also set the connection parameter namedTRACINGto eitherINFOorALL.- Set
TRACINGtoALLto see all debugging information and all binding information. - Set
TRACINGtoINFOto see the binding parameter values and less other debug information.
Caution
If you bind confidential information, such as medical diagnoses or passwords, that information is logged. Snowflake recommends making sure that the log file is secure, or only using test data, when you set this parameter to
TRUE.- Set
- Values:
TRUEorFALSE.- Default:
FALSE
CLIENT_
- Type:
Account — Can be set only for Account
- Data Type:
Integer
- Clients:
Any
- Description:
Specifies the AES encryption key size, in bits, used by Snowflake to encrypt/decrypt files stored on internal stages (for loading/unloading data) when you use the
SNOWFLAKE_FULLencryption type.- Values:
128or256- Default:
128
Note
- This parameter is not used for encrypting/decrypting files stored in external stages (that is, S3 buckets or Azure containers). Encryption/decryption of these files is accomplished using an external encryption key explicitly specified in the COPY command or in the named external stage referenced in the command.
- If you are using the JDBC driver and you wish to set this parameter to 256 (for strong encryption), additional JCE policy files must be installed on each client machine from which data is loaded/unloaded. For more information about installing the required files, see Java requirements for the JDBC Driver.
- If you are using the Python connector (or SnowSQL) and you wish to set this parameter to 256 (for strong encryption), no additional installation or configuration tasks are required.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Clients:
JDBC, ODBC
- Description:
Parameter that specifies the maximum amount of memory the JDBC driver or ODBC driver should use for the result set from queries (in MB).
For the JDBC driver:
- To simplify JVM memory management, the parameter sets a global maximum memory usage limit for all queries.
- CLIENT_RESULT_CHUNK_SIZE specifies the maximum size of each set (or chunk) of query results to download (in MB). The driver might require additional memory to process a chunk; if so, it will adjust memory usage during runtime to process at least one thread/query. Verify that CLIENT_MEMORY_LIMIT is set significantly higher than CLIENT_RESULT_CHUNK_SIZE to ensure sufficient memory is available.
For the ODBC driver:
- This parameter is supported in version 2.22.0 and higher.
CLIENT_RESULT_CHUNK_SIZEis not supported.
Note
- The driver will attempt to honor the parameter value, but will cap usage at 80% of your system memory.
- The memory usage limit set in this parameter does not apply to any other JDBC or ODBC driver operations (e.g. connecting to the database, preparing a query, or PUT and GET statements).
- Values:
Any valid number of megabytes.
- Default:
1536(effectively 1.5 GB)Most users should not need to set this parameter. If this parameter is not set by the user, the driver starts with the default specified above.
In addition, the JDBC driver actively manages its memory conservatively to avoid using up all available memory.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Clients:
JDBC, ODBC
- Description:
For specific ODBC functions and JDBC methods, this parameter can change the default search scope from all databases/schemas to the current database/schema. The narrower search typically returns fewer rows and executes more quickly.
For example, the
getTables()JDBC method accepts a database name and schema name as arguments, and returns the names of the tables in the database and schema. If the database and schema arguments arenull, then by default, the method searches all databases and all schemas in the account. Setting CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX toTRUEnarrows the search to the current database and schema specified by the connection context.In essence, setting this parameter to
TRUEcreates the following precedence for database and schema:- Values passed as arguments to the functions/methods.
- Values specified in the connection context (if any).
- Default (all databases and all schemas).
For more details, see the information below.
This parameter applies to the following:
-
JDBC driver methods (for the
DatabaseMetaDataclass):getColumnsgetCrossReferencegetExportedKeysgetForeignKeysgetFunctionsgetImportedKeysgetPrimaryKeysgetSchemasgetTables
-
ODBC driver functions:
SQLTablesSQLColumnsSQLPrimaryKeysSQLForeignKeysSQLGetFunctionsSQLProcedures
- Values:
TRUE: If the database and schema arguments arenull, then the driver retrieves metadata for only the database and schema specified by the connection context.The interaction is described in more detail in the table below.
FALSE: If the database and schema arguments arenull, then the driver retrieves metadata for all databases and schemas in the account.- Default:
FALSE- Additional Notes:
The connection context refers to the current database and schema for the session, which can be set using any of the following options:
- Specify the default namespace for the user who connects to Snowflake (and initiates the session). This can be set for the user through the CREATE USER or ALTER USER command, but must be set before the user connects.
- Specify the database and schema when connecting to Snowflake through the driver.
- Issue a USE DATABASE or USE SCHEMA command within the session.
If the database or schema was specified by more than one of these, then the most recent one applies.
When CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX is set to
TRUE:
Note
For the JDBC driver, this behavior applies to version 3.6.27 (and higher). For the ODBC driver, this behavior applies to version 2.12.96 (and higher).
If you want to search only the connection context database, but want to search all schemas within that database, see CLIENT_METADATA_USE_SESSION_DATABASE.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Clients:
JDBC
- Description:
This parameter applies to only the methods affected by CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.
This parameter applies only when both of the following conditions are met:
- CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX is
FALSEor unset. - No database or schema is passed to the relevant ODBC function or JDBC method.
For specific ODBC functions and JDBC methods, this parameter can change the default search scope from all databases to the current database. The narrower search typically returns fewer rows and executes more quickly.
For more details, see the information below.
- CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX is
- Values:
TRUE:The driver searches all schemas in the connection context’s database. (For more details about the connection context, see the documentation for CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.)
FALSE:The driver searches all schemas in all databases.
- Default:
FALSE- Additional Notes:
When the database is null and the schema is null and CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX is FALSE:
CLIENT_METADATA_USE_SESSION_DATABASE Behavior FALSE All schemas in all databases are searched. TRUE All schemas in the current database are searched.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Clients:
JDBC, ODBC, Python, .NET
- Description:
Parameter that specifies the number of threads used by the client to pre-fetch large result sets. The driver will attempt to honor the parameter value, but defines the minimum and maximum values (depending on your system’s resources) to improve performance.
- Values:
1to10- Default:
4Most users should not need to set this parameter. If this parameter is not set by the user, the driver starts with the default specified above, but also actively manages its thread count conservatively to avoid using up all available memory.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Clients:
JDBC, Node.js, SQL API, Go
- Description:
Parameter that specifies the maximum size of each set (or chunk) of query results to download (in MB). The JDBC driver downloads query results in chunks.
Also see CLIENT_MEMORY_LIMIT.
- Values:
16to160- Default:
160Most users should not need to set this parameter. If this parameter is not set by the user, the driver starts with the default specified above, but also actively manages its memory conservatively to avoid using up all available memory.
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Clients:
JDBC
- Description:
Parameter that indicates whether to match column name case-insensitively in
ResultSet.get*methods in JDBC.- Values:
TRUE: matches column names case-insensitively.FALSE: matches column names case-sensitively.- Default:
FALSE
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Clients:
.NET, Golang, JDBC, Node.js, ODBC, Python,
- Description:
Parameter that indicates whether to force a user to log in again after a period of inactivity in the session.
- Values:
TRUE: Snowflake keeps the session active indefinitely as long as the connection is active, even if there is no activity from the user.FALSE: The user must log in again after four hours of inactivity.- Default:
FALSE
Note
Currently, the parameter only takes effect while initiating the session. You can modify the parameter value within the session level by executing an ALTER SESSION command, but it does not affect the session keep-alive functionality, such as extending the session. For information about setting the parameter at the session level, see the client documentation:
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Clients:
SnowSQL, JDBC, ODBC, Python, Node.js
- Description:
Number of seconds in-between client attempts to update the token for the session.
- Values:
900to3600- Default:
3600
CLIENT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Clients:
Any
- Description:
Specifies the TIMESTAMP_* variation to use when binding timestamp variables for JDBC or ODBC applications that use the bind API to load data.
- Values:
TIMESTAMP_LTZorTIMESTAMP_NTZ- Default:
TIMESTAMP_LTZ
CORTEX_
- Type:
User — Can be set for Account » User
- Data Type:
Number
- Description:
Sets a daily estimated credit usage limit per user for Cortex Code CLI. Snowflake tracks the user’s estimated credit usage over a rolling 24-hour window and blocks access to the Cortex Code CLI when usage reaches the configured limit. Only users with the
ACCOUNTADMINrole, or a role with sufficient privileges to modify the account or user object, can set this parameter. For more information, see Cost controls for CoCo.- Values:
-1: No limit. The user has unlimited access.0: Access is blocked entirely for the user.- Positive number: Access is blocked when the user’s estimated credit usage in the past 24 hours exceeds this value.
- Default:
-1(no limit)
CORTEX_
- Type:
User — Can be set for Account » User
- Data Type:
Number
- Description:
Sets a daily estimated credit usage limit per user for Cortex Code Desktop. Snowflake tracks the user’s estimated credit usage over a rolling 24-hour window and blocks access to Cortex Code Desktop when usage reaches the configured limit. Only users with the
ACCOUNTADMINrole, or a role with sufficient privileges to modify the account or user object, can set this parameter. For more information, see Cost controls for CoCo.- Values:
-1: No limit. The user has unlimited access.0: Access is blocked entirely for the user.- Positive number: Access is blocked when the user’s estimated credit usage in the past 24 hours exceeds this value.
- Default:
-1(no limit)
COCO_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether the Cortex Code Cloud Agents sandbox in Snowflake can make outbound network connections to hosts outside Snowflake. For more information, see Cloud Agents.
- Values:
TRUE: Non-Snowflake network egress from the Cloud Agents sandbox is disabled.FALSE: Non-Snowflake network egress to platform-configured package registries and build tooling is allowed.- Default:
FALSE
Example:
COCO_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether allow-all permission options are available to users in Cortex Code in Snowsight. When Cortex Code requests permission to run a tool call (for example, SQL execution or Bash), users are normally offered two allow-all options: Allow <tool> in this chat and Always allow <tool>. Setting this parameter to
TRUEdisables both options for all tool types.- Values:
TRUE: Both allow-all permission options (Allow <tool> in this chat and Always allow <tool>) are disabled for all tool types in Cortex Code in Snowsight. Users must approve each tool call individually.FALSE: Both allow-all permission options are available to users.- Default:
FALSE
Example:
CORTEX_
- Type:
User — Can be set for Account » User
- Data Type:
Number
- Description:
Sets a daily estimated credit usage limit per user for Cortex Code in the Snowsight web interface. Snowflake tracks the user’s estimated credit usage over a rolling 24-hour window and blocks access to Cortex Code in Snowsight when usage reaches the configured limit. Only users with the
ACCOUNTADMINrole, or a role with sufficient privileges to modify the account or user object, can set this parameter. For more information, see Cost controls for CoCo.- Values:
-1: No limit. The user has unlimited access.0: Access is blocked entirely for the user.- Positive number: Access is blocked when the user’s estimated credit usage in the past 24 hours exceeds this value.
- Default:
-1(no limit)
CORTEX_
Warning
CORTEX_MODELS_ALLOWLIST is being deprecated. Starting in August 2026, you can no longer change this parameter to a new value — the only permitted change will be to set it to 'None'. Later in 2026, the parameter will be removed entirely. Snowflake recommends migrating to role-based access control (RBAC) for Cortex models, which provides finer-grained, per-role control.
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the models that users in the account can access. Use this parameter to allowlist models for all users in the account. If you need to provide specific users with access beyond what you’ve specified in the allowlist, use role-based access control instead. For more information, see Account-level allowlist parameter.
When users make a request, Snowflake Cortex evaluates the parameter to determine whether the user can access the model.
- Values:
-
'All': Provides access to all models, including fine-tuned models.Example:
-
'model1,model2,...': Provides access to the models specified in a comma-separated list.Model names are case-sensitive and must be specified in lowercase.
Example:
-
'None': Prevents access to any model.Example:
-
- Default:
'All'
CORTEX_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the regions where an inference request may be processed in case the request cannot be processed in the region where request is originally placed. Specifying
DISABLEDdisables cross-region inferencing. For examples and details, see Cross-region inference.- Values:
This parameter can be set to one of the following:
DISABLEDANY_REGION- Comma-separated list including one or more of the following values:
AWS_JPAWS_APJAWS_AUAWS_EUAWS_USAWS_GLOBALAZURE_EUAZURE_USAZURE_GLOBALGCP_USGCP_GLOBAL
Explanation of each parameter value
Value Behavior DISABLEDInference requests will be handled in:
- The region where the request is placed.
ANY_REGIONInference requests may be routed to:
- Any region that supports cross-region inference (listed in this table) and that has availability, including the region where the request is placed.
AWS_JPInference requests will be handled in the region where the request is placed and in the following AWS regions
- AWS Asia Pacific (Tokyo) ap-northeast-1
- AWS Asia Pacific (Osaka) ap-northeast-3
AWS_APJInference requests will be handled in the region where the request is placed and in the following AWS regions
- AWS Asia Pacific (Tokyo) ap-northeast-1
- AWS Asia Pacific (Seoul) ap-northeast-2
- AWS Asia Pacific (Osaka) ap-northeast-3
- AWS Asia Pacific (Mumbai) ap-south-1
- AWS Asia Pacific (Hyderabad) ap-south-2
- AWS Asia Pacific (Singapore) ap-southeast-1
- AWS Asia Pacific (Sydney) ap-southeast-2
- AWS Asia Pacific (Melbourne) ap-southeast-4
AWS_AUInference requests will be handled in the region where the request is placed and in the following AWS regions
- AWS Asia Pacific (Sydney) ap-southeast-2
- AWS Asia Pacific (Melbourne) ap-southeast-4
AWS_EUInference requests will be handled in the region where the request is placed and in the following AWS regions, which are (and will be) located within the European Union:
- AWS Europe (Frankfurt) eu-central-1
- AWS Europe (Stockholm) eu-north-1
- AWS Europe (Milan) eu-south-1
- AWS Europe (Spain) eu-south-2
- AWS Europe (Ireland) eu-west-1
- AWS Europe (Paris) eu-west-3
AWS_USInference requests will be handled in the region where the request is placed and in the following AWS regions, which are (and will be) located within the United States:
- AWS US East (N. Virginia) us-east-1
- AWS US East (Ohio) us-east-2
- AWS US West (Oregon) us-west-2
AWS_GlobalInference requests will be handled in the region where the request is placed and in any AWS commercial region. AZURE_EUInference requests will be handled in the region where the request is placed and in the following Azure regions, which are (and will be) located within the European Union:
- Azure Europe (Netherlands) westeurope
- Azure Europe (France) francecentral
- Azure Europe (Germany) germanywestcentral
- Azure Europe (Italy) italynorth
- Azure Europe (Poland) polandcentral
- Azure Europe (Spain) spaincentral
- Azure Europe (Sweden) swedencentral
AZURE_USInference requests will be handled in the region where the request is placed and in the following Azure regions, which are (and will be) located within the United States:
- Azure US (Virginia) eastus2
- Azure US (Virginia) eastus
- Azure US (California) westus
- Azure US (Phoenix) westus3
- Azure US (Illinois) northcentralus
- Azure US (Texas) southcentralus
AZURE_GlobalInference requests will be handled in the region where the request is placed and in any Azure commercial region. GCP_USInference requests will be handled in the region where the request is placed and in the following GCP regions, which are (and will be) located within the United States:
- GCP US (Iowa) us-central1
- GCP US (Oregon) us-west1
- GCP US (Las Vegas) us-west4
- GCP US (N. Virginia) us-east4
GCP_GlobalInference requests will be handled in the region where the request is placed and in any GCP commercial region. - Default:
The default value depends on when and where the account was created:
ANY_REGIONfor new accounts in new organizations within commercial regions created after March 9, 2026.DISABLEDfor all other accounts, including government regions.
CSV_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the format for TIMESTAMP values in CSV files downloaded from Snowsight.
If this parameter is not set, TIMESTAMP_LTZ_OUTPUT_FORMAT will be used for TIMESTAMP_LTZ values, TIMESTAMP_TZ_OUTPUT_FORMAT will be used for TIMESTAMP_TZ and TIMESTAMP_NTZ_OUTPUT_FORMAT for TIMESTAMP_NTZ values.
For more information, see Date and time input and output formats or Download your query results.
- Values:
Any valid, supported timestamp format.
- Default:
No value.
DATA_
- Type:
Object (for tables)
- Data type:
String
- Description:
Specifies the schedule to run the data metric functions associated to the table.
- Values:
The schedule can be based on a defined number of minutes, a cron expression, or a DML event on the table that does not involve reclustering. For details, see:
- Default:
60 MINUTE
DATA_
- Type:
Object (for databases, schemas, and tables) — Can be set for Account » Database » Schema » Table
- Data Type:
Integer
- Description:
Number of days for which Snowflake retains historical data for performing Time Travel actions (SELECT, CLONE, UNDROP) on the object. A value of
0effectively disables Time Travel for the specified database, schema, or table. For more information, see Understanding & using Time Travel.- Values:
0or1(for Standard Edition)0to90(for Enterprise Edition or higher)- Default:
1
DATE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the input format for the DATE data type. For more information, see Date and time input and output formats.
- Values:
Any valid, supported date format or
AUTO(
AUTOspecifies that Snowflake attempts to automatically detect the format of dates stored in the system during the session)- Default:
AUTO
DATE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the DATE data type. For more information, see Date and time input and output formats.
- Values:
Any valid, supported date format
- Default:
YYYY-MM-DD
DEFAULT_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the dbt version used for a dbt project object when no
DBT_VERSIONis specified in the CREATE DBT PROJECT statement. Changing this parameter doesn’t affect existing dbt project objects. It only applies to projects created afterward when an explicitDBT_VERSIONattribute is not specified. This allows organization administrators to opt into newer versions (for example, changing the default to1.11.11) without requiring users to manually update CREATE DBT PROJECT DDL statements for every individual project. For more information, see Set the account-level default version.- Values:
1.9.4,1.10.15,1.11.11,2.0.0-preview.175, or2.0.0-preview.186- Default:
1.9.4
DEFAULT_
- Type:
Object (for databases, schemas, and tables) — Can be set for Account » Database » Schema » Table
- Data Type:
String
- Description:
Sets the default collation used for the following DDL operations:
- CREATE TABLE
- ALTER TABLE … ADD COLUMN
Setting this parameter forces all subsequently created columns in the affected objects (table, schema, database, or account) to have the specified collation as the default, unless the collation for the column is explicitly defined in the DDL.
For example, if
DEFAULT_DDL_COLLATION = 'en-ci', then the following two statements are equivalent:Note
This parameter isn’t supported for dynamic tables and Apache Iceberg™ tables. For Iceberg tables, use ICEBERG_DEFAULT_DDL_COLLATION instead. This parameter isn’t supported on indexed columns for hybrid tables.
- Values:
Any valid, supported collation specification.
- Default:
Empty string
Note
To set the default collation for the account, use the following command:
The default collation for table columns can be set at the table, schema, or database level during creation or any time afterwards:
DEFAULT_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Specifies the default metadata write format for new tables created with
CREATE TABLEandALTER TABLEin this scope. When set toICEBERG, Snowflake creates Apache Iceberg™ tables without theICEBERGkeyword.For more information, see Configure Iceberg as the default metadata format for tables.
Important
To set this parameter to
ICEBERG, you must also setCATALOG = 'SNOWFLAKE'at the database level.Note
In a catalog-linked database, this parameter is always
ICEBERGand can’t be changed.- Values:
SNOWFLAKE: New tables use the standard Snowflake table format.ICEBERG: New tables are created as Apache Iceberg™ tables whenCATALOG = 'SNOWFLAKE'is set at the database level.- Default:
SNOWFLAKE
DEFAULT_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Sets the preferred CPU compute pool used for Notebooks on CPU Container Runtime.
- Values:
Name of a compute pool in your account.
- Default:
SYSTEM_COMPUTE_POOL_CPU (see System compute pools).
DEFAULT_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Sets the preferred GPU compute pool used for Notebooks on GPU Container Runtime.
- Values:
Name of a compute pool in your account.
- Default:
SYSTEM_COMPUTE_POOL_GPU (see System compute pools).
DEFAULT_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Sets the default artifact repository used for resolving Python packages in newly created UDFs, UDTFs, UDAFs, and stored procedures. When this parameter is set, functions and procedures that specify PACKAGES but do not explicitly specify an ARTIFACT_REPOSITORY will use this default repository.
The priority order for repository resolution is: function-level > schema-level > database-level > account-level.
- Values:
snowflake.snowpark.pypi_shared_repository: Source packages from PyPI.snowflake.snowpark.anaconda_shared_repository: Source packages from Anaconda.
- Default:
None (packages are sourced from the system default if no repository is specified at any level).
DEFAULT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the default ordering of NULL values in a result set.
The ordering of NULL values in rows depend on the ORDER BY clause:
- When the sort order is ASC (the default) and this parameter is set to
LAST(the default), NULL values are returned last. Therefore, unless specified otherwise, NULL values are considered to be higher than any non-NULL values. - When the sort order is ASC and this parameter is set to
FIRST, NULL values are returned first. - When the sort order is DESC and this parameter is set to
FIRST, NULL values are returned last. - When the sort order is DESC and this parameter is set to
LAST, NULL values are returned first.
If a NULL ordering is specified in the ORDER BY clause with NULLS FIRST or NULLS LAST, then the specified ordering takes precedence over any value of DEFAULT_NULL_ORDERING.
- Values:
FIRST: NULL values are lower than any non-NULL values.LAST: NULL values are higher than any non-NULL values.- Default:
LAST
DEFAULT_
- Type:
Account — Can only be set for Account
- Data Type:
String
- Description:
Specifies the default compute pool to use for container-runtime Streamlit apps.
When you run CREATE STREAMLIT, if you specify a container runtime in the RUNTIME_NAME property and don’t specify the COMPUTE_POOL property, Snowflake uses the compute pool specified the DEFAULT_STREAMLIT_COMPUTE_POOL parameter. This default compute pool is resolved at creation time. Updating DEFAULT_STREAMLIT_COMPUTE_POOL won’t update the COMPUTE_POOL property on existing Streamlit apps. For more information, see Configuring your own preferred compute pools for Streamlit apps.
- Values:
Name of a compute pool in your account.
- Default:
SYSTEM_COMPUTE_POOL_CPU
DEFAULT_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Specifies the name of the default warehouse to use when creating a notebook.
For more information, see ALTER ACCOUNT, ALTER DATABASE, and ALTER SCHEMA.
- Values:
The name of any existing warehouse.
- Default:
SYSTEM$STREAMLIT_NOTEBOOK_WH
DISABLE_
- Type:
Object (for users) — Can be set for Account > User
- Data Type:
Boolean
- Description:
Controls whether users in an account see a button to download data in Snowsight, such as a table returned from running a query in a worksheet.
If the button to download is hidden in Snowsight, users can still download or export data using third-party software.
- Values:
TRUE: Users in the account don’t see a button to download data in Snowsight.FALSE: Users in the account see a button to download data in Snowsight.- Default:
FALSE
DISABLE_
- Type:
Object (for users) — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether users in an account can grant privileges directly to other users.
Disabling user privilege grants (that is, setting DISABLE_USER_PRIVILEGE_GRANTS to
TRUE) doesn’t affect existing grants to users. Existing grants to users continue to confer privileges to those users. For more information, see GRANT <privileges> … TO USER.- Values:
TRUE: Users in the account cannot grant privileges to another user.FALSE: Users in the account can grant privileges to another user.- Default:
FALSE
DISALLOWED_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Specifies the workload types that are disallowed in your account to deploy to Snowpark Container Services. Also see ALLOWED_SPCS_WORKLOAD_TYPES.
- Values:
The value is a comma-separated list of the following supported workload types:
USER: Any workloads directly deployed by users.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit in Snowflake.MODEL_SERVING: ML Model Serving.ML_JOB: Snowflake ML Jobs.ALL: All workloads.
- Default:
Empty string
Note
If you configure both DISALLOWED_SPCS_WORKLOAD_TYPES and ALLOWED_SPCS_WORKLOAD_TYPES parameters, Snowflake first applies DISALLOWED_SPCS_WORKLOAD_TYPES. For example, if you configure both these parameters and specify the NOTEBOOK workload, NOTEBOOK workloads are not allowed to run on Snowpark Container Services.
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether events from sensitive data classification are logged in the user event table.
- Values:
TRUE: Snowflake logs events for sensitive data classification in the user event table.FALSE: Events for sensitive data classification are not logged.- Default:
TRUE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether telemetry data is collected for budgets.
- Values:
TRUE: Snowflake logs telemetry data that is related to budgets to an event table.FALSE: Snowflake doesn’t log telemetry data that is related to budgets.- Default:
TRUE
ENABLE_
- Type:
Object (for databases, schemas, and Iceberg tables) — Can be set for Account » Database » Schema » Iceberg Table
- Data Type:
Boolean
- Description:
Specifies whether Snowflake should enable data compaction on Snowflake-managed Apache Iceberg™ tables.
- Values:
TRUE: Snowflake performs data compaction on the tables.FALSE: Snowflake doesn’t perform data compaction on the tables.- Default:
TRUE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Enables IPv6 ingress for the account by configuring dual-stack (IPv4 + IPv6) endpoints at the edge. When enabled, the account hostname resolves to both A (IPv4) and AAAA (IPv6) DNS records, allowing compatible clients and networks to connect over IPv6 without application changes. This parameter is available on AWS deployments only.
Existing IPv4 traffic continues to work. Enabling this parameter adds IPv6 as an additional path for compatible clients.
To restrict access based on IPv6 addresses after enabling dual-stack endpoints, create network rules with
TYPE = IPV6and add them to a network policy. For dual-stack networks where clients connect over both IPv4 and IPv6, create separate network rules for each address family to ensure complete coverage.For more information, see IPv6 addresses.
- Values:
TRUE: The account hostname resolves to both IPv4 (A) and IPv6 (AAAA) records, enabling IPv6 ingress.FALSE: The account hostname resolves to IPv4 (A) records only.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Enables or disables the Listing Cross-cloud auto-fulfillment Egress cost optimizer.
- Values:
TRUE: Enable the Egress cost optimizer.FALSE: Disable the Egress cost optimizer.- Default:
FALSE
For more information see Auto-fulfillment for listings.
ENABLE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether the output returned by the GET_DDL function contains data type synonyms specified in the original DDL statement. Data type synonyms are also called data type aliases.
- Values:
TRUE: Show the data type aliases specified in the original DDL statement.FALSE: Replace the data type aliases specified in the original DDL statement with standard Snowflake data type names.
You can set this parameter to TRUE to generate DDL statements using the GET_DDL function that specify data type aliases as defined in the original SQL statements, which might be required to preserve data model integrity during migrations.
The following are examples of data type aliases:
- CHAR is an alias for the VARCHAR data type.
- BIGINT is an alias for the NUMBER data type.
- DATETIME is an alias for the TIMESTAMP_NTZ data type.
The following statement creates a table using the aliases for the data types:
When this parameter is set to FALSE, the GET_DDL function returns the following output:
When this parameter is set to TRUE, the GET_DDL function returns the following output:
- Default:
FALSE
ENABLE_
- Type:
Object (for databases, schemas, and Apache Iceberg™ tables) — Can be set for Account » Database » Schema » Iceberg table
- Data Type:
Boolean
- Description:
Specifies whether to enable merge-on-read behavior for Snowflake-managed Apache Iceberg™ tables. For more information, see Use row-level deletes.
- Values:
TRUE: Enable merge-on-read behavior:- If you use the Iceberg v2 format with Iceberg tables, Snowflake uses merge-on-read with positional delete files for row-level deletes.
- If you use the Iceberg v3 format with Iceberg tables, Snowflake uses merge-on-read with deletion vectors for row-level deletes when conditions are met.
For more information about merge-on-read and copy-on-write behavior, see Use row-level deletes.
Note
To specify the Iceberg version for tables, use the ICEBERG_VERSION_DEFAULT parameter or ICEBERG_VERSION parameter.
FALSE: Enables copy-on-write behavior for DML operations.- Default:
TRUE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Determines the login flow for users. When enabled, Snowflake prompts users for their username or email address before presenting authentication methods. For details, see Identifier-first login.
- Values:
TRUE: Snowflake uses an identifier-first login flow to authenticate users.FALSE: Snowflake presents all possible login options, even if those options don’t apply to a particular user.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether the SYSTEM$GET_PRIVATELINK_CONFIG function returns the
private-internal-stageskey in the query result. The corresponding value in the query result is used during the configuration process for private connectivity to internal stages. The value of this parameter also affects the behavior of system functions related to private connectivity. For example,TRUEenables SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS andFALSEturns off SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS.- Values:
TRUE: Returns theprivate-internal-stageskey and value in the query result.FALSE: Doesn’t return theprivate-internal-stageskey and value in the query result.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Allows the SYSTEM$GET_PRIVATELINK_CONFIG function to return the
privatelink-snowflake-managed-storage-volume-nfsandprivatelink-snowflake-managed-storage-volume-fskeys in the query result on Azure deployments.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether public URLs for Snowflake-hosted app services (Streamlit in Snowflake, Snowflake Notebooks, and Snowpark Container Services) use a per-account URL format. When enabled, the unique subdomains used by these services will have a different hostname format with a suffix unique to the account that enabled the parameter.
You may need to run SYSTEM$ISSUE_PER_ACCOUNT_APP_SERVICE_CERTIFICATE to enable this parameter.
The per-account URL format uses
app-id.orgname-account-name.region.cloud.snowflake.appinstead of a format likeapp-id.region.snowflake.apporapp-id-orgname-account_name.snowflakecomputing.app. After enabling, the format will appear as a wildcard record under SYSTEM$ALLOWLIST with typeAPP_SERVICE_PUBLIC_WILDCARD.Benefits of per-account URLs:
- Simplified firewall rules: A single wildcard entry scoped to your account
(
*.orgname-accountname.region.cloud.snowflake.app) replaces broad wildcards like*.snowflakecomputing.app, giving your network team finer-grained control. - Reduced data exfiltration risk: Because the wildcard is account-scoped, users can’t reach app services hosted by other Snowflake accounts through your network allowlist.
- Consistent URL format: All Snowflake-hosted app services (Streamlit, Notebooks, and Snowpark Container Services) share the same hostname pattern, making DNS and certificate management simpler.
Enabling this parameter doesn’t prevent accessing SPCS applications through their older hostnames.
- Simplified firewall rules: A single wildcard entry scoped to your account
(
- Values:
TRUE: App service URLs use the per-account format.FALSE: App service URLs use the legacy non-per-account-scoped format.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether private link URLs for Snowflake-hosted app services (Streamlit in Snowflake, Snowflake Notebooks, and Snowpark Container Services) use a per-account URL format. When enabled, the unique subdomains used by these services will have a different hostname format with a suffix unique to the account that enabled the parameter.
You may need to run SYSTEM$ISSUE_PER_ACCOUNT_APP_SERVICE_CERTIFICATE to enable this parameter.
The per-account private link URL format uses
app-id.sis.orgname-account-name.region.cloud.privatelink.snowflake.appinstead of the legacy non-account-scoped format. This lets you create a single CNAME record scoped to your account for all app services, reducing DNS configuration and addressing data exfiltration concerns. After enabling, the format is visible in SYSTEM$GET_PRIVATELINK_CONFIG inapp-service-privatelink-urland will appear as a wildcard record under :doc:/sql-reference/functions/system_allowlistwith typeAPP_SERVICE_PRIVATELINK_WILDCARD.Update your private DNS entries and firewall rules to use the URL format before enabling the parameter. The
app-service-privatelink-url-nextkey will contain the format prior to enabling.Benefits of per-account private link URLs:
- Simplified DNS configuration: A single CNAME record scoped to your account
(
*.orgname-accountname.region.cloud.privatelink.snowflake.app) covers all app services, replacing per-deployment wildcard records. - Reduced data exfiltration risk: Because the wildcard is account-scoped, private link traffic can’t be routed to app services hosted by other Snowflake accounts.
- Consistent URL format: All Snowflake-hosted app services (Streamlit, Notebooks, and Snowpark Container Services) share the same private link hostname pattern, simplifying certificate and DNS management.
- Multi-account DNS routing: If your private DNS zone is shared across multiple Snowflake accounts, per-account wildcards let you route traffic to the correct account without conflicting CNAME records.
Enabling this parameter doesn’t prevent accessing SPCS applications through their older hostnames.
- Simplified DNS configuration: A single CNAME record scoped to your account
(
- Values:
TRUE: App service private link URLs use the per-account format.FALSE: App service private link URLs use the legacy deployment-scoped format.- Default:
FALSE
ENABLE_
- Type:
User — Can be set for Account > User
- Data Type:
Boolean
- Description:
Specifies whether users can create private notebooks (stored in their personal databases). When TRUE, users in the account can create private notebooks (assuming other necessary privileges are granted).
- Values:
TRUE: Enables users to create private notebooks.FALSE: Prevents users from creating private notebooks.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Enables enforcement of SNOWFLAKE_FULL encryption type for Snowpark Container Services block-storage volumes and snapshots.
- Values:
TRUE: Enforces creation of SPCS block-storage volumes and snapshots only with the SNOWFLAKE_FULL encryption type. The SNOWFLAKE_SSE encryption type isn’t permitted. All existing block-storage volumes and snapshots with the SNOWFLAKE_SSE encryption type must be migrated to SNOWFLAKE_FULL before enabling this parameter. Setting the parameter value to TRUE with existing SNOWFLAKE_FULL encrypted volumes or snapshots results in an error.FALSE: Both SNOWFLAKE_SSE and SNOWFLAKE_FULL encryption types are permitted for SPCS block-storage volumes and snapshots in the account.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether telemetry data is collected for automatic tag propagation.
- Values:
TRUE: Snowflake logs telemetry data that is related to tag propagation to an event table.FALSE: Snowflake doesn’t log telemetry data that is related to tag propagation.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies the choice for the image repository to opt out of Tri-Secret Secure and Periodic rekeying.
- Values:
TRUE: Opts out Tri-Secret Secure and periodic rekeying for the image repository.FALSE: Disallows the creation of an image repository for Tri-Secret Secure and periodic rekeying for accounts. Similarly, disallows enabling Tri-Secret Secure and periodic rekeying for accounts that have enabled image repository.- Default:
FALSE
ENABLE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether Snowflake may capture – in an event table – log messages or trace event data for unhandled exceptions in procedure or UDF handler code. For more information, see Capturing messages from unhandled exceptions.
- Values:
TRUE: Data about unhandled exceptions is captured as log or trace data if logging and tracing are enabled.FALSE: Data about unhandled exceptions is not captured.- Default:
TRUE
ENABLE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether to set the schema for unloaded Parquet files based on the logical column data types (that is, the types in the unload SQL query or source table) or on the unloaded column values (that is, the smallest data types and precision that support the values in the output columns of the unload SQL statement or source table).
- Values:
TRUE: The schema of unloaded Parquet data files is determined by the column values in the unload SQL query or source table. Snowflake optimizes table columns by setting the smallest precision that accepts all of the values. The unloader follows this pattern when writing values to Parquet files. The data type and precision of an output column are set to the smallest data type and precision that support its values in the unload SQL statement or source table. Accept this setting for better performance and smaller data files.FALSE: The schema is determined by the logical column data types. Set this value for a consistent output file schema.- Default:
TRUE
ENABLE_
- Type:
User — Can be set for Account » User
- Data Type:
Boolean
- Description:
Controls whether query text is redacted if a SQL query fails due to a syntax or parsing error. If
FALSE, the content of a failed query is redacted in the views, pages, and functions that provide a query history.Only users with a role that is granted or inherits the AUDIT privilege can set the ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR parameter.
When using the ALTER USER command to set the parameter to
TRUEfor a particular user, modify the user that you want to see the query text, not the user who executed the query (if those are different users).- Values:
TRUE: Disables the redaction of query text for queries that fail due to a syntax or parsing error.FALSE: Redacts the contents of a query from the views, pages, and functions that provide a query history when a query fails due to a syntax or parsing error.- Default:
FALSE
ENABLE_
- Type:
User — Can be set for Account » User
- Data Type:
Boolean
- Description:
Controls whether error messages related to secure objects are redacted in metadata. For more information, see Secure objects: Redaction of information in error messages.
Only users with a role that is granted or inherits the AUDIT privilege can set the ENABLE_UNREDACTED_SECURE_OBJECT_ERROR parameter.
When using the ALTER USER command to set the parameter to
TRUEfor a particular user, modify the user that you want to see the redacted error messages in metadata, not the user who caused the error.- Values:
TRUE: Disables the redaction of error messages related to secure objects in metadata.FALSE: Redacts the contents of error messages related to secure objects in metadata.- Default:
FALSE
ENABLE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls whether Universal Search indexes the contents of workspace files, enabling it to search within workspace files, return more complete results, and better rank them by relevance.
- Values:
TRUE: Universal Search indexes both file metadata (such as file name, folder name, workspace name) and file content, and searches both parts for keywords and semantically related content.FALSE: Universal Search indexes and searches file metadata only. Because search has incomplete information, results may be incomplete or sub-optimally ranked.- Default:
TRUE
ENFORCE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether a network policy that uses network rules can restrict access to AWS internal stages.
This parameter has no effect on network policies that do not use network rules.
This account-level parameter affects both account-level and user-level network policies.
For details about using network policies and network rules to restrict access to AWS internal stages, including the use of this parameter, see Protecting internal stages on AWS.
- Values:
TRUE: Allows network policies that use network rules to restrict access to AWS internal stages. The network rule must also use the appropriateMODEandTYPEto restrict access to the internal stage.FALSE: Network policies never restrict access to internal stages.- Default:
FALSE
ENFORCE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether a network policy that uses network rules can restrict access to AWS Snowflake-managed storage volumes.
This parameter has no effect on network policies that do not use network rules.
This account-level parameter affects only account-level network policies.
For details about using network policies and network rules to restrict access to Snowflake-managed storage volumes, see Protecting Snowflake-managed storage volumes on AWS.
- Values:
TRUE: Allows network policies that use network rules to restrict access to Snowflake-managed storage volumes. The network rule must also use the appropriateMODEandTYPEto restrict access to the volume.FALSE: Network policies never restrict access to Snowflake-managed storage volumes.- Default:
FALSE
ERROR_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether to return an error when the MERGE command is used to update or delete a target row that joins multiple source rows and the system cannot determine the action to perform on the target row.
- Values:
TRUE: An error is returned that includes values from one of the target rows that caused the error.FALSE: No error is returned and the merge completes successfully, but the results of the merge are nondeterministic.- Default:
TRUE
ERROR_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether to return an error when the UPDATE command is used to update a target row that joins multiple source rows and the system cannot determine the action to perform on the target row.
- Values:
TRUE: An error is returned that includes values from one of the target rows that caused the error.FALSE: No error is returned and the update completes, but the results of the update are nondeterministic.- Default:
FALSE
EVENT_
- Type:
Object — Can be set for Account » Database
- Data Type:
String
- Description:
Specifies the name of the event table for logging messages from stored procedures and UDFs contained by the object with which the event table is associated.
Associating an event table with a database is available in Enterprise Edition or higher.
- Values:
Any existing event table created by executing the CREATE EVENT TABLE command.
- Default:
None
EXTERNAL_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Determines whether the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN roles can be used as the primary role when creating a Snowflake session based on the access token from the External OAuth authorization server.
- Values:
TRUE: Adds the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN roles to theEXTERNAL_OAUTH_BLOCKED_ROLES_LISTproperty of the External OAuth security integration, which means these roles cannot be used as the primary role when creating a Snowflake session using External OAuth authentication.FALSE: Removes the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN from the list of blocked roles defined by theEXTERNAL_OAUTH_BLOCKED_ROLES_LISTproperty of the External OAuth security integration.- Default:
TRUE
EXTERNAL_
Object (for databases, schemas, and Apache Iceberg™ tables) — Can be set for Account » Database » Schema » Iceberg table
- Data Type:
String
- Description:
Specifies the external volume for Apache Iceberg™ tables. For more information, see the Iceberg table documentation.
- Values:
Any valid external volume identifier.
- Default:
None
GEOGRAPHY_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
Display format for GEOGRAPHY values.
For EWKT and EWKB, the SRID is always 4326 in the output. Refer to the note on EWKT and EWKB handling.
- Values:
GeoJSON,WKT,WKB,EWKT, orEWKB- Default:
GeoJSON
GEOMETRY_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
Display format for GEOMETRY values.
- Values:
GeoJSON,WKT,WKB,EWKT, orEWKB- Default:
GeoJSON
HYBRID_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Description:
Number of seconds to wait while trying to acquire row-level locks on a hybrid table, before timing out and aborting the statement.
- Values:
0to any integer (no limit). A value of0disables lock waiting (that is, the statement must acquire the lock immediately or abort). This value specifies how long the statement will wait for all of the row-level locks it needs to acquire after each execution attempt (1 hour by default). If the statement cannot acquire all of the locks, it can be retried, and the same waiting period is applied.- Default:
3600(1 hour)
See also LOCK_TIMEOUT.
ICEBERG_
- Type:
Object (for databases, schemas, and tables) — Can be set for Account » Database » Schema » Table
- Data Type:
String
- Description:
Sets the default collation used for new string columns on Snowflake-managed Iceberg tables during the following DDL operations:
- CREATE TABLE
- ALTER TABLE … ADD COLUMN
Setting this parameter forces all subsequently created string columns on Snowflake-managed Iceberg tables in the affected object (table, schema, database, or account) to have the specified collation as the default, unless the collation for the column is explicitly defined in the DDL.
For example, if
ICEBERG_DEFAULT_DDL_COLLATION = 'en-ci'is set on a database, then the following two statements are equivalent:This parameter works the same way as DEFAULT_DDL_COLLATION but applies only to Snowflake-managed Iceberg tables.
For more information about collation on Iceberg tables, see Collation support on Iceberg tables.
- Values:
Any valid, supported collation specification.
- Default:
Empty string
ICEBERG_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Description:
Specifies the default precision for an Apache Iceberg™ timestamp column when no precision is specified in a DDL statement (for example, CREATE ICEBERG TABLE). For more information, see Iceberg v3 data types.
- Values:
6: Microsecond precision.9: Nanosecond precision.Any other value returns an error.
- Default:
6
ICEBERG_
Note
For more information about other Iceberg v3 features that Snowflake supports, see Apache Iceberg™ tables: Support for Apache Iceberg™ v3.
- Type:
Object (for Apache Iceberg™ tables) — Can be set only for Apache Iceberg™ tables
- Data Type:
Integer
- Description:
Specifies the version of the Apache Iceberg™ specification that the table conforms to. If you use the ICEBERG_VERSION_DEFAULT parameter to specify the default Iceberg version at a higher level, this parameter overrides the default. You can specify an Iceberg version for Snowflake-managed Iceberg tables and externally managed Iceberg tables that you create in a catalog-linked database.
Caution
Before you use other engines to upgrade an Iceberg tables format-version in table properties to v3, ensure that the table isn’t used by engines or applications that don’t yet support v3. Downgrading format versions isn’t supported in the Apache Iceberg specification. Therefore, all readers and writers must support v3. The default version for Iceberg tables in Snowflake is v2, which can be configured to v3 if needed. Using Snowflake to perform in-place version upgrades isn’t supported at this time.
Note
You can set this parameter when creating an Iceberg table using the CREATE ICEBERG TABLE (Snowflake as the Iceberg catalog) or CREATE ICEBERG TABLE (Iceberg REST catalog) command. You can’t use the ALTER ICEBERG TABLE command to change this configuration for an existing table.
- Values:
2: The table conforms with Iceberg version 2.3: The table conforms with Iceberg version 3.- Default:
2
ICEBERG_
Note
For more information about other Iceberg v3 features that Snowflake supports, see Apache Iceberg™ tables: Support for Apache Iceberg™ v3.
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
Integer
- Description:
Specifies the version of the Apache Iceberg™ specification to conform to when creating new Snowflake-managed Iceberg tables.
Caution
Before you use other engines to upgrade an Iceberg tables format-version in table properties to v3, ensure that the table isn’t used by engines or applications that don’t yet support v3. Downgrading format versions isn’t supported in the Apache Iceberg specification. Therefore, all readers and writers must support v3. The default version for Iceberg tables in Snowflake is v2, which can be configured to v3 if needed. Using Snowflake to perform in-place version upgrades isn’t supported at this time.
Note
To set the version for a specific table, set the ICEBERG_VERSION parameter instead. See ICEBERG_VERSION.
- Values:
2: The table conforms with Iceberg version 2.3: The table conforms with Iceberg version 3.- Default:
2
INITIAL_
- Type:
Account — Can be set only for Account
- Data Type:
Number.
- Description:
Sets the maximum estimated size limit for the initial replication of a primary database to a secondary database (in TB). Set this parameter on any account that stores a secondary database. This size limit helps prevent accounts from accidentally incurring large database replication charges.
To remove the size limit, set the value to
0.0.Note that there is currently no default size limit applied to subsequent refreshes of a secondary database.
- Values:
0.0and above with a scale of at least 1 (e.g.20.5,32.25,33.333, etc.).- Default:
10.0
JDBC_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether to allow PUT and GET commands access to local file systems.
- Values:
TRUE: JDBC enables PUT and GET commands.FALSE: JDBC disables PUT and GET commands.- Default:
TRUE
JDBC_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies how JDBC processes columns that have a scale of zero (
0).- Values:
TRUE: JDBC processes a column whose scale is zero as BIGINT.FALSE: JDBC processes a column whose scale is zero as DECIMAL.- Default:
TRUE
JDBC_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies how JDBC processes TIMESTAMP_NTZ values.
By default, when the JDBC driver fetches a value of type TIMESTAMP_NTZ from Snowflake, it converts the value to “wallclock” time using the client JVM timezone.
Users who want to keep UTC timezone for the conversion can set this parameter to
TRUE.This parameter applies only to the JDBC driver.
- Values:
TRUE: The driver uses UTC to get the TIMESTAMP_NTZ value in “wallclock” time.FALSE: The driver uses the client JVM’s current timezone to get the TIMESTAMP_NTZ value in “wallclock” time.- Default:
FALSE
JDBC_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether the JDBC Driver uses the time zone of the JVM or the time zone of the session (specified by the TIMEZONE parameter) for the
getDate(),getTime(), andgetTimestamp()methods of theResultSetclass.- Values:
TRUE: The JDBC Driver uses the time zone of the session.FALSE: The JDBC Driver uses the time zone of the JVM.- Default:
TRUE
JSON_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Description:
Specifies the number of blank spaces to indent each new element in JSON output in the session. Also specifies whether to insert newline characters after each element.
- Values:
0to16(a value of
0returns compact output by removing all blank spaces and newline characters from the output)- Default:
2
Note
This parameter does not affect JSON unloaded from a table into a file using the COPY INTO <location> command. The command always unloads JSON data in the NDJSON format:
- Each record from the table separated by a newline character.
- Within each record, compact formatting (that is, no spaces or newline characters).
JS_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies how the Snowflake Node.js Driver processes numeric columns that have a scale of zero (
0), for example INTEGER or NUMBER(p, 0).- Values:
TRUE: JavaScript processes a column whose scale is zero as Bigint.FALSE: JavaScript processes a column whose scale is zero as Number.- Default:
FALSE
Note
By default, Snowflake INTEGER columns (including BIGINT, NUMBER(p, 0), etc.) are converted to JavaScript’s Number data type. However, the largest legal Snowflake integer values are larger than the largest legal JavaScript Number values. To convert Snowflake INTEGER columns to JavaScript Bigint, which can store larger values than JavaScript Number, set the session parameter JS_TREAT_INTEGER_AS_BIGINT.
For examples of how to use this parameter, see Fetching integer data types as Bigint.
LISTING_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Sets the time interval used to refresh the application package based data products to other regions.
- Values:
-
num MINUTES:A value between
1and11520. Must include the unit MINUTES. -
USING CRON expr time_zone:Specifies a cron expression and time zone for the refresh. Supports a subset of standard cron utility syntax.
For a list of time zones, see the Wikipedia topic list of tz database time zones. The cron expression consists of the following fields:
The following special characters are supported:
-
*: Wildcard. Specifies any occurrence of the field. -
L: Stands for “last”. When used in the day-of-week field, it allows you to specify constructs such as “the last Friday” (“5L”) of a given month. In the day-of-month field, it specifies the last day of the month. -
/<n>: Indicates the nth instance of a given unit of time. Each quanta of time is computed independently. For example, if4/3is specified in the month field, then the refresh is scheduled for April, July, and October. For example, every three months, starting with the fourth month of the year. The same schedule is maintained in subsequent years. That is, the refresh is not scheduled to run in January (3 months after the October run).
-
Note
- The cron expression currently evaluates against the specified time zone only. Altering the TIMEZONE parameter value for the account (or setting the value at the user or session level) does not change the time zone for the refresh.
- The cron expression defines all valid run times for the refresh. Snowflake attempts to refresh listings based on this schedule; however, any valid run time is skipped if a previous run has not completed before the next valid run time starts.
- When both a specific day of month and day of week are included in the cron expression, then the refresh is scheduled on days
satisfying either the day of month or the day of week. For example,
SCHEDULE = 'USING CRON 0 0 10-20 * TUE,THU UTC'schedules a refresh at 0 a.m. on the tenth to twentieth day of any month and also on any Tuesday or Thursday outside of those dates.
-
- Default:
None
LOCK_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer
- Description:
Number of seconds to wait while trying to lock a resource, before timing out and aborting the statement.
- Values:
0to any integer (no limit). A value of0disables lock waiting (the statement must acquire the lock immediately or abort). If multiple resources need to be locked by the statement, the timeout applies separately to each lock attempt.- Default:
43200(12 hours)
See also HYBRID_TABLE_LOCK_TIMEOUT.
LOG_
- Type:
Session — Can be set for Account » User » Session
Object (for databases, schemas, DCM projects, stored procedures, UDFs, dynamic tables, Iceberg tables, tasks, services) — Can be set for:
- Account » Database » Schema » DCM project
- Account » Database » Schema » Procedure
- Account » Database » Schema » Function
- Account » Database » Schema » Dynamic table
- Account » Database » Schema » Iceberg table (externally managed)
- Account » Database » Schema » Task
- Account » Database » Schema » Service
- Data Type:
String (Constant)
- Description:
Specifies the severity level of log messages produced through logging APIs that should be ingested and made available in the active event table. Log messages at the specified level (and at more severe levels) are ingested. For more information about log levels, see Setting levels for logging, metrics, and tracing.
- Values:
TRACEDEBUGINFOWARNERRORFATALOFF
- Default:
OFF- Additional Notes:
The following table lists the levels of log messages ingested when you set the
LOG_LEVELparameter to a level.LOG_LEVEL Parameter Setting Levels of Log Messages Ingested TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERROR(Only for Java UDFs, Java UDTFs, and Java and Scala stored procedures. For more information, see Setting levels for logging, metrics, and tracing.)FATAL
If this parameter is set in both the session and the object (or schema, database, or account), the more verbose value is used. See How Snowflake determines the level in effect.
LOG_
- Type:
Session — Can be set for Account » User » Session
Object (for databases, schemas, DCM projects, stored procedures, UDFs, dynamic tables, Iceberg tables, tasks, services) — Can be set for:
- Account » Database » Schema » DCM project
- Account » Database » Schema » Procedure
- Account » Database » Schema » Function
- Account » Database » Schema » Dynamic table
- Account » Database » Schema » Iceberg table (externally managed)
- Account » Database » Schema » Task
- Account » Database » Schema » Service
- Data Type:
String (Constant)
- Description:
Specifies the severity level of log events (rows with record type EVENT) that should be ingested and made available in the active event table. Log events at the specified level (and at more severe levels) are ingested. For the supported severity values and how levels combine, see Setting levels for logging, metrics, and tracing.
- Values:
TRACEDEBUGINFOWARNERRORFATALOFF
- Default:
OFF- Additional Notes:
The following table lists the levels of log events ingested when you set the
LOG_EVENT_LEVELparameter to a level.LOG_EVENT_LEVEL Parameter Setting Levels of Log Events Ingested TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERRORFATAL
If this parameter is set in both the session and the object (or schema, database, or account), the more verbose value is used. See How Snowflake determines the level in effect.
LOGIN_
- Type:
Account
- Data type:
VARCHAR
- Description:
View-only parameter that contains a JSON object summarizing the values that someone set for the
LOGIN_IDP_REDIRECTaccount property.The JSON object contains a mapping between Snowflake interfaces and SAML security integrations. SAML security integrations are used to implement single sign-on (SSO) authentication. If an interface is mapped to a SAML security integration, then users who access the interface are redirected to the third-party identity provider (IdP) to authenticate; they never see the Snowflake login screen.
For a conceptual overview and configuration examples, see Automatically redirecting users to your identity provider. For the syntax used to set the property, see ALTER ACCOUNT.
MAP_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Controls how SCIM user attributes map to the Snowflake user
NAMEandLOGIN_NAMEproperties.When set to
TRUE, theuserNameattribute in SCIM requests maps only toLOGIN_NAME, and thesnowflakeUserNameenterprise extension attribute maps toNAME. Both attributes must be specified in POST and PUT requests.When set to
FALSE, bothNAMEandLOGIN_NAMEare set from theuserNameattribute.For more information about the SCIM user attribute mapping, see User attributes. For IdP-specific configuration, see Okta SCIM integration with Snowflake and Microsoft Entra ID SCIM integration with Snowflake.
- Values:
TRUE/FALSE- Default:
FALSE
MAX_
- Type:
Object (for warehouses) — Can be set for Account » Warehouse
- Data Type:
Number
- Description:
Specifies the concurrency level for SQL statements (that is, queries and DML) executed by a warehouse. When the level is reached, the operation performed depends on whether the warehouse is a single-cluster or multi-cluster warehouse:
- Single-cluster or multi-cluster (in Maximized mode): Statements are queued until already-allocated resources are freed or additional resources are provisioned, which can be accomplished by increasing the size of the warehouse.
- Multi-cluster (in Auto-scale mode): Additional clusters are started.
MAX_CONCURRENCY_LEVEL can be used in conjunction with the STATEMENT_QUEUED_TIMEOUT_IN_SECONDS parameter to ensure a warehouse is never backlogged.
In general, it limits the number of statements that can be executed concurrently by a warehouse cluster, but there are exceptions. In the following cases, the actual number of statements executed concurrently by a warehouse might be more or less than the specified level:
- Smaller, more basic statements: More statements might execute concurrently because small statements generally execute on a subset of the available compute resources in a warehouse. This means they only count as a fraction towards the concurrency level.
- Larger, more complex statements: Fewer statements might execute concurrently.
- Default:
8
Tip
This value is a default only and can be changed at any time:
- Lowering the concurrency level for a warehouse can limit the number of concurrent queries running in a warehouse. When fewer queries are competing for the warehouse’s resources at a given time, a query can potentially be given more resources, which might result in faster query performance, particularly for a large/complex and multi-statement query.
- Raising the concurrency level for a warehouse might decrease the compute resources that are available for a statement; however, it does not always limit the total number of concurrent queries that can be executed by the warehouse, nor does it necessarily impact total warehouse performance, which depends on the nature of the queries being executed.
Note that, as described earlier, this parameter impacts multi-cluster warehouses (in Auto-scale mode) because Snowflake automatically starts a new cluster within the multi-cluster warehouse to avoid queuing. Thus, lowering the concurrency level for a multi-cluster warehouse (in Auto-scale mode) potentially increases the number of active clusters at any time.
Also, remember that Snowflake automatically allocates resources for each statement when it is submitted and the allocated amount is dictated by the individual requirements of the statement. Based on this, and through observations of user query patterns over time, we’ve selected a default that balances performance and resource usage.
As such, before changing the default, we recommend that you test the change by adjusting the parameter in small increments and observing the impact against a representative set of your queries.
MAX_
- Type:
Object (for databases, schemas, and tables) — Can be set for Account » Database » Schema » Table
- Data Type:
Integer
- Description:
Maximum number of days Snowflake can extend the data retention period for tables to prevent streams on the tables from becoming stale. By default, if the DATA_RETENTION_TIME_IN_DAYS setting for a source table is less than 14 days, and a stream has not been consumed, Snowflake temporarily extends this period to the stream’s offset, up to a maximum of 14 days, regardless of the Snowflake Edition for your account. The MAX_DATA_EXTENSION_TIME_IN_DAYS parameter enables you to limit this automatic extension period to control storage costs for data retention or for compliance reasons.
This parameter can be set at the account, database, schema, and table levels. Note that setting the parameter at the account or schema level only affects tables for which the parameter has not already been explicitly set at a lower level (e.g. at the table level by the table owner). A value of 0 effectively disables the automatic extension for the specified database, schema, or table. For more information about streams and staleness, see Introduction to streams.
- Values:
0to90(90 days) — a value of0disables the automatic extension of the data retention period. To increase the maximum value for tables in your account, contact Snowflake Support.- Default:
14
Note
- This parameter can cause data to be retained longer than the default data retention. Before increasing it, confirm that the new value fits your compliance requirements.
- Table retention is not extended for streams on shared tables. If you share a table, ensure that you set the table retention time long enough for your data consumer to consume the stream. If a provider shares a table with, for example, 7 days’ retention and keeps the 14-day default extension, the stream will be stale after 14 days in the provider account and after 7 days in the consumer account.
METRIC_
- Type:
Session — Can be set for Account » User » Session
Object (for databases, schemas, stored procedures, and UDFs) — Can be set for Account » Database » Schema » Procedure and Account » Database » Schema » Function
- Data Type:
String (Constant)
- Description:
Controls how metrics data is ingested into the event table. For more information about metric levels, see Setting levels for logging, metrics, and tracing.
- Values:
ALL: All metrics data will be recorded in the event table.NONE: No metrics data will be recorded in the event table.- Default:
NONE
MULTI_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Integer (Constant)
- Clients:
SQL API, JDBC, .NET, ODBC
- Description:
Number of statements to execute when using the multi-statement capability.
- Values:
0: Variable number of statements.1: One statement.More than
1: When MULTI_STATEMENT_COUNT is set as a session parameter, you can specify the exact number of statements to execute.Negative numbers are not permitted.
- Default:
1
MIN_
- Type:
Account — Can be set only for Account
- Data Type:
Integer
- Description:
Minimum number of days for which Snowflake retains historical data for performing Time Travel actions (SELECT, CLONE, UNDROP) on an object. If a minimum number of days for data retention is set on an account, the data retention period for an object is determined by MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
For more information, see Understanding & using Time Travel.
- Values:
0or1(for Standard Edition)0to90(for Enterprise Edition or higher)- Default:
0
Note
-
This parameter only applies to permanent tables and does not apply to the following objects:
- Transient tables
- Temporary tables
- External tables
- Materialized views
- Streams
-
This parameter can only be set and unset by account administrators (that is, users with the ACCOUNTADMIN role or other role that is granted the ACCOUNTADMIN role).
-
Setting the minimum data retention time does not alter any existing DATA_RETENTION_TIME_IN_DAYS parameter value set on databases, schemas, or tables. The effective retention time of a database, schema, or table is MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
NETWORK_
- Type:
Account — Can be set only for Account (can be set by account administrators and security administrators)
- Type:
Object (for users) — Can be set for Account » User
- Data Type:
String
- Description:
Specifies the network policy to enforce for your account. Network policies enable restricting access to your account based on users’ IP address. For more details, see Controlling network traffic with network policies.
- Values:
Any existing network policy (created using CREATE NETWORK POLICY)
- Default:
None
Note
This is the only account parameter that can be set by security administrators (i.e users with the SECURITYADMIN system role) or higher.
NOORDER_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether the ORDER or NOORDER property is set by default when you create a new sequence or add a new table column.
The ORDER and NOORDER properties determine whether or not the values are generated for the sequence or auto-incremented column in increasing or decreasing order.
- Values:
-
TRUE: When you create a new sequence or add a new table column, the NOORDER property is set by default.NOORDER specifies that the values are not guaranteed to be in increasing order.
For example, if a sequence has
START 1 INCREMENT 2, the generated values might be1,3,101,5,103, etc.NOORDER can improve performance when multiple INSERT operations are performed concurrently (for example, when multiple clients are executing multiple INSERT statements).
-
FALSE: When you create a new sequence or add a new table column, the ORDER property is set by default.ORDER specifies that the values generated for a sequence or auto-incremented column are in increasing order (or, if the interval is a negative value, in decreasing order).
For example, if a sequence or auto-incremented column has
START 1 INCREMENT 2, the generated values might be1,3,5,7,9, etc.
If you set this parameter, the value that you set overrides the value in the 2024_01 behavior change bundle.
-
- Default:
TRUE
ODBC_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies how ODBC processes columns that have a scale of zero (
0).- Values:
TRUE: ODBC processes a column whose scale is zero as BIGINT.FALSE: ODBC processes a column whose scale is zero as DECIMAL.- Default:
FALSE
OAUTH_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Determines whether the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN roles can be used as the primary role when creating a Snowflake session based on the access token from Snowflake’s authorization server.
- Values:
TRUE: Adds the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN roles to theBLOCKED_ROLES_LISTproperty of the Snowflake OAuth security integration, which means these roles cannot be used as the primary role when creating a Snowflake session using Snowflake OAuth.FALSE: Removes the ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN, and SECURITYADMIN from the list of blocked roles defined by theBLOCKED_ROLES_LISTproperty of the Snowflake OAuth security integration.- Default:
TRUE
OAUTH_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Specifies the name of an External OAuth security integration to bind to MCP servers in the applicable scope. When set, MCP servers use the specified integration as their authorization server in Protected Resource Metadata discovery responses, enabling MCP clients to authenticate with the external identity provider (IdP) rather than Snowflake OAuth.
Snowflake also enforces the binding on OAuth access to MCP server endpoints: a presented OAuth token must have been issued by the bound integration. Tokens from Snowflake OAuth or from a different External OAuth integration are rejected. This check applies only to OAuth calls against MCP server endpoints; other authenticators and non-MCP endpoints aren’t affected.
The named integration must be an existing
EXTERNAL_OAUTHsecurity integration. The integration is validated at SET time. If the integration is later dropped or disabled, MCP servers in the affected scope publish an emptyauthorization_serverslist in Protected Resource Metadata and don’t fall back to Snowflake OAuth until a valid integration is configured again.This parameter follows account-to-database-to-schema lineage inheritance. Each MCP server resolves the nearest ancestor scope with a non-NULL value.
For more information, see:
- Default:
NULL (when NULL at all levels, MCP servers use Snowflake OAuth)
OAUTH_
- Type:
Object (for databases and schemas) — Can be set for Account » Database » Schema
- Data Type:
String
- Description:
Specifies a comma-separated list of OAuth scopes advertised in MCP server Protected Resource Metadata responses. The scopes tell MCP clients which OAuth scopes to request when authenticating.
Accepted scope values:
session:role:all: Accepted unconditionally. Uses the user’sDEFAULT_ROLE(Snowflake OAuth behavior, equivalent to omitting a role scope). Not meaningful to a third-party identity provider (IdP).session:role-any: Accepted unconditionally. Allows any primary role granted to the user when any-role mode is enabled on the bound authorization server. For External OAuth, that requiresEXTERNAL_OAUTH_ANY_ROLE_MODE = ENABLEorENABLE_FOR_PRIVILEGEon the security integration.session:role:<role_name>: The specified role must exist at SET time. If the role is dropped later, the scope remains in Protected Resource Metadata, but authentication using that scope fails during the OAuth flow.- Free-form scope strings: Accepted as opaque strings for use with external IdPs. Meaningful only when OAUTH_AUTHORIZATION_SERVER is also set.
This parameter follows account-to-database-to-schema lineage inheritance and resolves independently from OAUTH_AUTHORIZATION_SERVER.
For more information, see:
- Default:
NULL. When NULL at all levels with Snowflake OAuth, MCP servers advertise
session:role:all. When NULL while OAUTH_AUTHORIZATION_SERVER is set, MCP servers advertisesession:role-anyif the bound integration hasEXTERNAL_OAUTH_ANY_ROLE_MODE = ENABLEorENABLE_FOR_PRIVILEGE; otherwise they advertise an empty list.
OPT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether DML error logging is allowed.
- Values:
TRUE: DML error logging isn’t turned on, regardless of whether it is turned on for specific tables.FALSE: DML error logging behaves normally:- DML error logging is turned on for tables that have the ERROR_LOGGING table-level parameter set
to
TRUE. - DML error logging is turned off for tables that have the ERROR_LOGGING table-level parameter set
to
FALSE.
- DML error logging is turned on for tables that have the ERROR_LOGGING table-level parameter set
to
- Default:
FALSE
For more information, see DML error logging.
PERIODIC_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
This parameter only applies to Enterprise Edition (or higher). It enables/disables re-encryption of table data with new keys on a yearly basis to provide additional levels of data protection.
You can enable and disable rekeying at any time. Enabling/disabling rekeying does not result in gaps in your encrypted data:
- If rekeying is enabled for a period of time and then disabled, all data already tagged for rekeying is rekeyed, but no further data is rekeyed until you re-enable it again.
- If rekeying is re-enabled, Snowflake automatically rekeys all data that has keys which meet the criteria (that is, keys that are older than one year).
For more information about rekeying of encrypted data, see Understanding Encryption Key Management in Snowflake.
- Values:
TRUE: Data is rekeyed after one year has passed since the data was last encrypted. Rekeying occurs in the background so no down-time is experienced and the affected data/table is always available.FALSE: Data is not rekeyed.- Default:
FALSE
Note
There are charges associated with data rekeying because, after data is rekeyed, the old data (with the previous key encryption) is maintained in Fail-safe for the standard time period (7 days). For this reason, periodic rekeying is disabled by default. To enable periodic rekeying, you must explicitly enable it.
Also, Fail-safe charges for rekeying are not listed individually in your monthly statement; they are included in the Fail-safe total for your account each month.
For more information about Fail-safe, see Understanding and viewing Fail-safe.
PIPE_
- Type:
Object — Can be set for Account » Schema » Pipe
- Data Type:
Boolean
- Description:
Specifies whether to pause a running pipe, primarily in preparation for transferring ownership of the pipe to a different role:
- An account administrator (user with the ACCOUNTADMIN role) can set this parameter at the account level, effectively pausing or resuming all pipes in the account.
- A user with the MODIFY privilege on a schema can pause or resume all pipes in the schema.
- The pipe owner can set this parameter for a pipe.
Note that setting the parameter at the account or schema level only affects pipes for which the parameter has not already been explicitly set at a lower level (e.g. at the pipe level by the pipe owner).
This enables the practical use case in which an account administrator can pause all pipes at the account level, while a pipe owner can still have an individual pipe running.
- Values:
TRUE: Pauses the pipe. When the parameter is set to this value, the SYSTEM$PIPE_STATUS function shows theexecutionStateasPAUSED. Note that the pipe owner can continue to submit files to a paused pipe; however, the files are not processed until the pipe is resumed.FALSE: Resumes the pipe, but only if ownership of the pipe has not been transferred while it was paused. When the parameter is set to this value, the SYSTEM$PIPE_STATUS function shows theexecutionStateasRUNNING.If ownership of the pipe was transferred to another role after the pipe was paused, this parameter cannot be used to resume the pipe. Instead, use the SYSTEM$PIPE_FORCE_RESUME function to explicitly force the pipe to resume.
This enables the new owner to use SYSTEM$PIPE_STATUS to evaluate the pipe status (e.g. determine how many files are waiting to be loaded) before resuming the pipe.
- Default:
FALSE(pipes are running by default)
Note
In general, pipes do not need to paused, except for transferring ownership.
PATH_
- Type:
Object (for Apache Iceberg™ tables) — Can be set for Iceberg table
- Data Type:
String (Constant)
- Description:
Specifies the path layout that Snowflake uses when writing Parquet data files to Iceberg tables. You can specify this parameter when you create a table or when you modify a table by using the ALTER ICEBERG TABLE command.
Note
For externally managed tables that you create in a standard Snowflake database, Snowflake infers and honors the partitioning scheme that is specified by the remote catalog.
- Values:
-
FLAT: Snowflake writes all Parquet data files under thedata/directory for the table. -
HIERARCHICAL: Snowflake writes partitioned data under thedata/directory for the table by using a hierarchical path layout. With this layout, each partition column is represented as a directory level in the path. To define these partition columns, use the PARTITION BY parameter. This layout is also called “Hive-style” partitioning.If you specify the hierarchical layout but don’t specify a PARTITION BY clause with the command, Snowflake stores the Parquet data files by using a flat layout path. You can use the ALTER ICEBERG TABLE command to set PATH_LAYOUT for an existing table.
-
- Default:
FLAT
For more information, see Data and metadata directories.
PURGE_
- Type:
Object — Can be set for catalog-linked database, schema, or externally managed Iceberg table
- Data Type:
Boolean
- Description:
When set to
TRUE, automatically forwards the purge intent to the external Iceberg catalog whenever a table is dropped using DROP ICEBERG TABLE or via the implicit drop performed by CREATE OR REPLACE ICEBERG TABLE. Snowflake forwards purge intent in the drop-table request to the catalog. Snowflake never deletes external data files directly — the external catalog is responsible for the actual file deletion.This parameter is equivalent to specifying the
PURGEkeyword on individualDROP TABLEorCREATE OR REPLACE TABLEstatements, but applies automatically to every qualifying drop within the scope (database, schema, or table) where it is set.This parameter can only be set on catalog-linked databases, schemas, or externally managed Iceberg tables. Setting it on other object types results in an error.
Note
If you use the AWS Glue Data Catalog as your external catalog, the catalog does not honor the purge flag, so the underlying table files are retained regardless of this parameter’s value. This behavior is specific to the AWS Glue Data Catalog implementation.
- Default:
FALSE
For more information and examples, see Dropping an Iceberg table.
PREVENT_
- Type:
Object (for users) — Can be set for Account » User
- Data Type:
Boolean
- Description:
Specifies whether to prevent ad hoc data unload operations to external cloud storage locations (that is, COPY INTO <location> statements that specify the cloud storage URL and access settings directly in the statement). For an example, see Unloading data from a table directly to files in an external location.
- Values:
TRUE: COPY INTO <location> statements must reference either a named internal (Snowflake) or external stage or an internal user or table stage. A named external stage must store the cloud storage URL and access settings in its definition.FALSE: Ad hoc data unload operations to external cloud storage locations are permitted.- Default:
FALSE
PREVENT_
- Type:
User — Can be set for Account » User
- Data Type:
Boolean
- Description:
Specifies whether to prevent data unload operations to internal (Snowflake) stages using COPY INTO <location> statements.
- Values:
TRUE: Unloading data from Snowflake tables to any internal stage, including user stages, table stages, or named internal stages is prevented.FALSE: Unloading data to internal stages is permitted, limited only by the default restrictions of the stage type:- The current user can only unload data to their own user stage.
- Users can only unload data to table stages when their active role has the OWNERSHIP privilege on the table.
- Users can only unload data to named internal stages when their active role has the WRITE privilege on the stage.
- Default:
FALSE
PYTHON_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the fully-qualified name of the stage in which to save a report when profiling Python handler code.
- Values:
Fully-qualified name of the stage in which to save the report.
- Use a temporary stage to store output only for the duration of the session.
- Use a permanent stage to preserve the profiler output outside of the scope of a session.
For more information, see Specify the Snowflake stage where profile output should be written.
- Default:
''
PYTHON_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the list of Python modules to include in a report when profiling Python handler code.
Use this parameter to specify modules that are contained in staged handlers or that contain dependencies that you want to include in the profile.
- Values:
A comma-separated list of Python module names.
For examples, see Including modules with the PYTHON_PROFILER_MODULES parameter and Profiling staged handler code.
- Default:
''
QUERY_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (up to 2000 characters)
- Description:
Optional string that can be used to tag queries and other SQL statements executed within a session. The tags are displayed in the output of the QUERY_HISTORY , QUERY_HISTORY_BY_* functions.
- Default:
None
QUOTED_
- Type:
Session — Can be set for Account » User » Session
Object — Can be set for Account » Database » Schema » Table
- Data Type:
Boolean
- Description:
Specifies whether letters in double-quoted object identifiers are stored and resolved as uppercase letters. By default, Snowflake preserves the case of alphabetic characters when storing and resolving double-quoted identifiers. (see Identifier resolution.) You can use this parameter in situations in which third-party applications always use double quotes around identifiers.
Note
Changing this parameter from the default value can affect your ability to find objects that were previously created with double-quoted mixed case identifiers. Refer to Impact of changing the parameter.
When set on a table, schema, or database, the setting only affects the evaluation of table names in the bodies of views and user-defined functions (UDFs). If your account uses double-quoted identifiers that should be treated as case-insensitive and you plan to share a view or UDF with an account that treats double-quoted identifiers as case-sensitive, you can set this on the view or UDF that you plan to share. This allows the other account to resolve the table names in the view or UDF correctly.
- Values:
TRUE: Letters in double-quoted identifiers are stored and resolved as uppercase letters.FALSE: The case of letters in double-quoted identifiers is preserved. Snowflake resolves and stores the identifiers in the specified case.For more information, see Identifier resolution.
- Default:
FALSE
For example:
| Identifier | Param set to FALSE (default) | Param set to TRUE | |
|---|---|---|---|
"columnname" | resolves to: | columnname | COLUMNNAME |
"columnName" | resolves to: | columnName | COLUMNNAME |
"ColumnName" | resolves to: | ColumnName | COLUMNNAME |
"COLUMNNAME" | resolves to: | COLUMNNAME | COLUMNNAME |
READ_
- Type:
Account — Can be set only for Account
- Data Type:
String
- Description:
Defines the level of consistency guarantees that are required for sessions with near-concurrent changes.
- Values:
SESSION: Changes are immediately visible to subsequent queries within the same session but not always immediately across sessions.GLOBAL: Changes are immediately visible to subsequent queries across concurrently running sessions, but with a small impact on query response times (usually milliseconds).- Default:
SESSION
For more information, see Read consistency across sessions.
REPLACE_
- Type:
Object — Can be set for Account » Database » Schema » Iceberg table
- Data Type:
Boolean
- Description:
Specifies whether to replace invalid UTF-8 characters with the Unicode replacement character (�) in query results for Apache Iceberg™ tables that use an external catalog.
- Values:
TRUE: Snowflake replaces invalid UTF-8 characters with the Unicode replacement character.FALSE: Snowflake leaves invalid UTF-8 characters unchanged. Snowflake returns a user error message if it encounters an invalid UTF-8 character.- Default:
FALSE
REQUIRE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether to require a storage integration object as cloud credentials when creating a named external stage (using CREATE STAGE) to access a private cloud storage location.
- Values:
TRUE: Creating an external stage to access a private cloud storage location requires referencing a storage integration object as cloud credentials.FALSE: Creating an external stage does not require referencing a storage integration object. Users can instead reference explicit cloud provider credentials, such as secret keys or access tokens, if they have been configured for the storage location.- Default:
FALSE
REQUIRE_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
Specifies whether to require using a named external stage that references a storage integration object as cloud credentials when loading data from or unloading data to a private cloud storage location.
- Values:
TRUE: Loading data from or unloading data to a private cloud storage location requires using a named external stage that references a storage integration object; specifying a named external stage that references explicit cloud provider credentials, such as secret keys or access tokens, produces a user error.FALSE: Users can load data from or unload data to a private cloud storage location using a named external stage that references explicit cloud provider credentials.If PREVENT_UNLOAD_TO_INLINE_URL is FALSE, then users can specify the explicit cloud provider credentials directly in the COPY statement.
- Default:
FALSE
ROWS_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Number
- Clients:
SQL API
- Description:
Specifies the maximum number of rows returned in a result set.
- Values:
0to any number (no limit) — a value of0specifies no maximum.- Default:
0
S3_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the DNS name of an Amazon S3 interface endpoint. Requests sent to the internal stage of an account via AWS PrivateLink for Amazon S3 use this endpoint to connect.
For more information, see Accessing Internal stages with dedicated interface endpoints.
- Values:
Valid region-scoped DNS Name of an S3 interface endpoint.
The standard format begins with an asterisk (
*) and ends withvpce.amazonaws.com(e.g.*.vpce-sd98fs0d9f8g.s3.us-west-2.vpce.amazonaws.com). For more details about obtaining this value, refer to AWS configuration.Alternative formats include
bucket.vpce-xxxxxxxx.s3.<region>.vpce.amazonaws.comandvpce-xxxxxxxx.s3.<region>.vpce.amazonaws.com.- Default:
Empty string
SAML_
- Type:
Account — Can be set only for Account
- Data Type:
JSON
- Description:
Enables federated authentication. This deprecated parameter enables federated authentication. This parameter accepts a JSON object, enclosed in single quotes, with the following fields:
Where:
certificateSpecifies the certificate (generated by the IdP) that verifies communication between the IdP and Snowflake.
issuerIndicates the Issuer/EntityID of the IdP.
Optional.
For information on how to obtain this value in Okta and AD FS, see Migrating to a SAML2 security integration.
ssoUrlSpecifies the URL endpoint (provided by the IdP) where Snowflake sends the SAML requests.
typeSpecifies the type of IdP used for federated authentication (
"OKTA","ADFS","Custom").labelSpecifies the button text for the IdP in the Snowflake login page. The default label is
Single Sign On. If you change the default label, the label you specify can only contain alphanumeric characters (special characters and blank spaces are not currently supported).Note that, if the
"type"field is"Okta", a value for thelabelfield does not need to be specified because Snowflake displays the Okta logo in the button.
For more information, including examples of setting the parameter, see Migrating to a SAML2 security integration.
- Default:
None
SEARCH_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the path to search to resolve unqualified object names in queries. For more information, see Name resolution in queries.
- Values:
Comma-separated list of identifiers. An identifier can be a fully or partially qualified schema name.
- Default:
$current, $publicFor more information about the default settings, see default search path.
Note
- You cannot set this parameter within a client connection string, such as a JDBC or ODBC connection string. You must establish a session before setting a search path.
- This parameter isn’t supported for tasks.
SERVERLESS_
- Type:
Object — Can be set for Account » Database » Schema » Task
- Data Type:
String
- Description:
Specifies the maximum allowed warehouse size for Serverless tasks.
- Values:
Any traditional warehouse size:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. The maximum size isX2LARGE.Also supports the syntax:
XXLARGE.- Default:
X2LARGE
SERVERLESS_
- Type:
Object — Can be set for Account » Database » Schema » Task
- Data Type:
String
- Description:
Specifies the minimum allowed warehouse size for Serverless tasks.
- Values:
Any traditional warehouse size:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. The maximum size isX2LARGE.Also supports the syntax:
XXLARGE.- Default:
XSMALL
SERVICE_
- Type:
Object — Can be set for Account » Database » Schema » Service
- Data Type:
Integer
- Description:
Controls how long a caller’s rights login token is valid, in seconds, for Snowpark Container Services services that use caller’s rights (
executeAsCaller: true). For more information, see Configuring the login token validity.You can set this parameter at the account, database, schema, or service level. The most specific level takes precedence. For example, if the account is set to 7 days but a specific service is set to 1 hour, that service uses 1 hour. When you unset the parameter at a given level, the value falls back to the next level in the hierarchy (service → schema → database → account → default).
Setting this parameter requires the MANAGE SERVICE CALLER ACCESS privilege on the account. Only the ACCOUNTADMIN and SECURITYADMIN roles can grant this privilege.
The following examples show how to set the token lifetime at different levels:
To revert to the default behavior, unset the parameter:
- Values:
120to604800(2 minutes to 7 days)- Default:
120
SIMULATED_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the name of a consumer account to simulate for testing/validating shared data, particularly shared secure views. When this parameter is set in a session, shared views return rows as if executed in the specified consumer account rather than the provider account.
Note
Simulations only succeed when the current role is the owner of the view. If the current role does not own the view, simulations fail with the error:
For more information, see About Secure Data Sharing and Create and configure shares.
- Default:
None
Important
This is a session parameter, which means it can be set at the account level; however, it only applies to testing queries on shared views. Because the parameter affects all queries in a session, it should never be set at the account level.
SQL_
- Type:
Account — Can be set only for Account
- Data Type:
String (Constant)
- Description:
Specifies whether to capture the SQL text of a traced SQL statement.
- Values:
ON: Traces that follow a SQL statement will capture text of the SQL and store it in the event table.OFF: Traces do not capture SQL text in the event table.For more information, see Setting levels for logging, metrics, and tracing and SQL statement tracing.
- Default:
OFF
SSO_
- Type:
Account — Can be set only for Account
- Data Type:
Boolean
- Description:
This deprecated parameter disables preview mode for testing SSO (after enabling federated authentication) before rolling it out to users:
- Values:
TRUE: Preview mode is disabled and users will see the button for Snowflake-initiated SSO for your identity provider (as specified in SAML_IDENTITY_PROVIDER) in the Snowflake main login page.FALSE: Preview mode is enabled and SSO can be tested using the following URL:- If your account is in US West:
https://<account_identifier>.snowflakecomputing.com/console/login?fedpreview=true - If your account is in any other region:
https://<account_identifier>.<region_id>.snowflakecomputing.com/console/login?fedpreview=true
For more information, see:
- If your account is in US West:
- Default:
FALSE
STATEMENT_
- Type:
Session and Object (for warehouses)
Can be set for Account » User » Session; can also be set for individual warehouses
- Data Type:
Number
- Description:
Amount of time, in seconds, a SQL statement (query, DDL, DML, and so on) remains queued for a warehouse before it is canceled by the system. This parameter can be used in conjunction with the MAX_CONCURRENCY_LEVEL parameter to ensure a warehouse is never backlogged.
The parameter can be set at different levels in the session hierarchy (on the account, user, and session). If the parameter is set at more than one level, the rules described in Session parameters determine which value is used.
The parameter can also be set for an individual warehouse to control the runtime for all SQL statements processed by the warehouse. When the parameter is set in both the session hierarchy and the warehouse, the timeout is the lowest non-zero value of the two parameters.
For example, assume the parameter is set to the following values at different levels:
- User - 10
- Session - 20
- Warehouse - 15
In this case, the value of the parameter set on the warehouse is used (15) because it is less than the value set in the session hierarchy (20). The parameter set on the user (10) isn’t considered because it is overridden by the parameter set in the session.
Note
When both STATEMENT_QUEUED_TIMEOUT_IN_SECONDS and USER_TASK_TIMEOUT_MS are set, the value of USER_TASK_TIMEOUT_MS takes precedence.
When comparing the values of these two parameters, note that STATEMENT_QUEUED_TIMEOUT_IN_SECONDS is set in units of seconds, while USER_TASK_TIMEOUT_MS uses units of milliseconds.
- Values:
0to any number (no limit) — a value of0specifies that no timeout is enforced. A statement will remained queued as long as the queue persists.- Default:
0(no timeout)
STATEMENT_
- Type:
Session and Object (for warehouses)
Can be set for Account » User » Session; can also be set for individual warehouses
- Data Type:
Number
- Description:
Amount of time, in seconds, after which a running SQL statement (query, DDL, DML, and so on) is canceled by the system.
The parameter can be set at different levels in the session hierarchy (on the account, user, and session). If the parameter is set at more than one level, the rules described in Session parameters determine which value is used.
The parameter can also be set for an individual warehouse to control the runtime for all SQL statements processed by the warehouse. When the parameter is set in both the session hierarchy and the warehouse, the timeout is the lowest non-zero value of the two parameters.
For example, assume the parameter is set to the following values at different levels:
- User - 10
- Session - 20
- Warehouse - 15
In this case, the value of the parameter set on the warehouse is used (15) because it is less than the value set in the session hierarchy (20). The parameter set on the user (10) isn’t considered because it is overridden by the parameter set in the session.
When both USER_TASK_TIMEOUT_MS and STATEMENT_TIMEOUT_IN_SECONDS are set, the timeout is the lowest non-zero value of the two parameters. When comparing the values of these two parameters, note that STATEMENT_TIMEOUT_IN_SECONDS is set in units of seconds, while USER_TASK_TIMEOUT_MS uses units of milliseconds.
The parameter setting applies to all of the time taken by the statement, including queue time, locked time, execution time, compilation time, and so on. It applies to the overall time taken by the statement, not just the warehouse execution time.
- Values:
0to604800(7 days) — a value of0specifies that the maximum timeout value is enforced.- Default:
172800(2 days)
STORAGE_
- Type:
Object (for databases, schemas, and Apache Iceberg™ tables) — Can be set for Account » Database » Schema » Iceberg table
- Data Type:
String (Constant)
- Description:
Specifies the storage serialization policy for Snowflake-managed Apache Iceberg™ tables.
- Values:
COMPATIBLE: Snowflake performs encoding and compression that ensures interoperability with third-party compute engines.OPTIMIZED: Snowflake performs encoding and compression that ensures the best table performance within Snowflake.- Default:
OPTIMIZED
STRICT_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
This parameter specifies whether JSON output in a session is compatible with the general standard (as described by http://json.org).
By design, Snowflake allows JSON input that contains non-standard values; however, these non-standard values might result in Snowflake outputting JSON that is incompatible with other platforms and languages. This parameter, when enabled, ensures that Snowflake outputs valid/compatible JSON.
- Values:
TRUE: Strict JSON output is enabled, enforcing the following behavior:- Missing and undefined values in input mapped to JSON NULL.
- Non-finite numeric values in input (Infinity, -Infinity, NaN, etc.) mapped to strings with valid JavaScript representations. This enables compatibility with JavaScript and also allows conversion of these values back to numeric values.
FALSE: Strict JSON output is not enabled.- Default:
FALSE
For example:
| Non-standard JSON Input | Param set to FALSE (default) | Param set to TRUE | |
|---|---|---|---|
[289, 2188,] | outputs: | [ 289, 2188, undefined ] | [ 289, 2188, null ] |
[undefined, undefined] | outputs: | [ undefined, undefined ] | [ null, null ] |
[Infinity,inf,-Infinity,-inf] | outputs: | [ Infinity, Infinity, -Infinity, -Infinity ] | [ "Infinity", "Infinity", "-Infinity", "-Infinity" ] |
[NaN,nan] | outputs: | [ NaN, NaN ] | [ "NaN", "NaN" ] |
SUSPEND_
- Type:
Object (for accounts, databases, schemas, and alerts) — Can be set for Account » Database » Schema » Alert
- Data Type:
Integer
- Description:
Number of consecutive failed alert runs after which an alert is suspended automatically. Failed alert runs include runs in which the SQL code in the condition or action either produces a user error or times out (for example, runs that end in the
ACTION_FAILEDorCONDITION_FAILEDstate). Alert runs that are skipped, canceled, or that fail due to a system error are considered indeterminate and are not included in the count of failed alert runs.When the parameter is set to
0, the alert is not automatically suspended.When the parameter is set to a value greater than
0, the alert is automatically suspended after the specified number of consecutive failed runs. There is no upper limit.When you explicitly set the parameter value at the account, database, or schema level, the change is applied to alerts contained in the modified object during their next scheduled run.
Suspending or resuming an alert resets its count of failed alert runs.
Manually executing an alert using EXECUTE ALERT also affects the count of failed alert runs.
- Values:
0- Disabled (the alert is not automatically suspended).- Default:
0
SUSPEND_
- Type:
Object (for databases, schemas, and tasks) — Can be set for Account » Database » Schema » Task
- Data Type:
Integer
- Description:
Number of consecutive failed task runs after which a standalone task or task graph root task is suspended automatically. Failed task runs include runs in which the SQL code in the task body either produces a user error or times out. Task runs that are skipped, canceled, or that fail due to a system error are considered indeterminate and are not included in the count of failed task runs.
When the parameter is set to
0, the failed task is not automatically suspended.When the parameter is set to a value greater than
0, the following behavior applies to runs of standalone tasks or task graph root tasks:-
A standalone task is automatically suspended after the specified number of consecutive task runs either fail or time out.
-
A root task is automatically suspended after the specified number of times in consecutive runs after any single task in a task graph fails or times out, after all
TASK_AUTO_RETRY_ATTEMPTSfor that task.For example, if a root task has
SUSPEND_TASK_AFTER_NUM_FAILURESset to 3, and it has a child task withTASK_AUTO_RETRY_ATTEMPTSset to 3, then after that child task fails 9 consecutive times, the root task is suspended.
The default value for the parameter is set to
10, which means that the task is automatically suspended after 10 consecutive failed task runs.When you explicitly set the parameter value at the account, database, or schema level, the change is applied to tasks contained in the modified object during their next scheduled run (including any child task in a task graph run in progress).
Suspending a standalone task resets its count of failed task runs. Suspending the root task of a task graph resets the count for each task in the task graph.
-
- Values:
0- No upper limit.- Default:
10
TASK_
- Type:
Object (for databases, schemas, and tasks) — Can be set for Account » Database » Schema » Task
- Data Type:
Integer
- Description:
Specifies the number of automatic task graph retry attempts. If any task graphs complete in a
FAILEDstate, Snowflake can automatically retry the task graphs from the last task in the graph that failed. Failed task runs include runs in which the SQL code in the task body either produces a user error or times out. Task runs that are skipped or canceled are considered indeterminate and are not included in the count of failed task runs.The automatic task graph retry is disabled by default. To enable this feature, set
TASK_AUTO_RETRY_ATTEMPTSto a value greater than0.When you set the parameter value at the account, database, or schema level, the change is applied to tasks contained in the modified object during their next scheduled run.
- Values:
0- No upper limit.- Default:
0
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether the DATEADD function (and its aliases) always consider a day to be exactly 24 hours for expressions that span multiple days.
- Values:
TRUE: A day is always exactly 24 hours.FALSE: A day is not always 24 hours.- Default:
FALSE
Important
If set to TRUE, the actual time of day might not be preserved when daylight saving time (DST) is in effect. For example:
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the input format for the TIMESTAMP data type alias. For more information, see Date and time input and output formats.
- Values:
Any valid, supported timestamp format or
AUTO(
AUTOspecifies that Snowflake attempts to automatically detect the format of timestamps stored in the system during the session)- Default:
AUTO
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the TIMESTAMP_LTZ data type. If CSV_TIMESTAMP_FORMAT is not set, TIMESTAMP_LTZ_OUTPUT_FORMAT is used when downloading CSV files. For more information, see Date and time input and output formats.
- Values:
Any valid, supported timestamp format
- Default:
None
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the TIMESTAMP_NTZ data type. If CSV_TIMESTAMP_FORMAT is not set, TIMESTAMP_NTZ_OUTPUT_FORMAT is used when downloading CSV files. For more information, see Date and time input and output formats.
- Values:
Any valid, supported timestamp format
- Default:
YYYY-MM-DD HH24:MI:SS.FF3
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the TIMESTAMP data type alias. For more information, see Date and time input and output formats.
- Values:
Any valid, supported timestamp format
- Default:
YYYY-MM-DD HH24:MI:SS.FF3 TZHTZM
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the TIMESTAMP_* variation that the TIMESTAMP data type alias maps to.
- Values:
TIMESTAMP_LTZ,TIMESTAMP_NTZ, orTIMESTAMP_TZ- Default:
TIMESTAMP_NTZ
TIMESTAMP_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the TIMESTAMP_TZ data type. If CSV_TIMESTAMP_FORMAT is not set, TIMESTAMP_TZ_OUTPUT_FORMAT is used when downloading CSV files. For more information, see Date and time input and output formats.
- Values:
Any valid, supported timestamp format
- Default:
None
TIMEZONE¶
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
Specifies the time zone for the session.
- Values:
You can specify a time zone name or a link name from release 2025b of the IANA Time Zone Database (e.g.
America/Los_Angeles,Europe/London,UTC,Etc/GMT, etc.).- Default:
America/Los_Angeles
Note
- Time zone names are case-sensitive and must be enclosed in single quotes (e.g.
'UTC'). - Snowflake does not support the majority of timezone abbreviations (e.g.
PDT,EST, etc.) because a given abbreviation might refer to one of several different time zones. For example,CSTmight refer to Central Standard Time in North America (UTC-6), Cuba Standard Time (UTC-5), and China Standard Time (UTC+8).
TIME_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the input format for the TIME data type. For more information, see Date and time input and output formats.
- Values:
Any valid, supported time format or
AUTO(
AUTOspecifies that Snowflake attempts to automatically detect the format of times stored in the system during the session)- Default:
AUTO
TIME_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the display format for the TIME data type. For more information, see Date and time input and output formats.
- Values:
Any valid, supported time format
- Default:
HH24:MI:SS
TRACE_
- Type:
Session — Can be set for Account » User » Session
Object (for databases, schemas, stored procedures, and UDFs) — Can be set for Account » Database » Schema » Procedure and Account » Database » Schema » Function
- Data Type:
String (Constant)
- Description:
Controls how trace events are ingested into the event table. For more information about trace levels, see Setting levels for logging, metrics, and tracing.
- Values:
ALWAYS: All spans and trace events will be recorded in the event table.ON_EVENT: Trace events will be recorded in the event table only when your stored procedures or UDFs explicitly add events.OFF: No spans or trace events will be recorded in the event table.- Default:
OFF
Note
When tracing events, you must also set the LOG_LEVEL parameter to one of its supported values.
TRANSACTION_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
BOOLEAN
- Description:
Specifies the action to perform when a statement issued within a non-autocommit transaction returns with an error.
- Values:
TRUE: The non-autocommit transaction is aborted. All statements issued inside that transaction will fail until a commit or rollback statement is executed to close that transaction.FALSE: The non-autocommit transaction is not aborted.- Default:
FALSE
TRANSACTION_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String
- Description:
Specifies the isolation level for transactions in the user session.
- Values:
READ COMMITTED(only currently-supported value)- Default:
READ COMMITTED
TWO_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Number
- Description:
Specifies the “century start” year for 2-digit years (that is, the earliest year such dates can represent). This parameter prevents ambiguous dates when importing or converting data with the
YYdate format component (years represented as 2 digits).- Values:
1900to2100(any value outside of this range returns an error)- Default:
1970
For example:
| Year | Param set to 1900 | Param set to 1970 (default) | Param set to 1980 | Param set to 1990 | Param set to 2000 | |
|---|---|---|---|---|---|---|
00 | becomes: | 1900 | 2000 | 2000 | 2000 | 2000 |
79 | becomes: | 1979 | 1979 | 2079 | 2079 | 2079 |
89 | becomes: | 1989 | 1989 | 1989 | 2089 | 2089 |
99 | becomes: | 1999 | 1999 | 1999 | 1999 | 2099 |
UNSUPPORTED_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
String (Constant)
- Description:
Determines if an unsupported (non-default) value specified for a constraint property returns an error.
- Values:
IGNORE: Snowflake does not return an error for unsupported values.FAIL: Snowflake returns an error for unsupported values.- Default:
IGNORE
Important
This parameter does not determine whether the constraint is created. Snowflake does not create constraints using unsupported values, regardless of how this parameter is set.
For more information, see Constraint properties.
USE_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Boolean
- Description:
Specifies whether to reuse persisted query results, if available, when a matching query is submitted.
- Values:
TRUE: When a query is submitted, Snowflake checks for matching query results for previously-executed queries and, if a matching result exists, uses the result instead of executing the query. This can help reduce query time because Snowflake retrieves the result directly from the cache.FALSE: Snowflake executes each query when submitted, regardless of whether a matching query result exists.- Default:
TRUE
USER_
- Type:
Object (for databases, schemas, and tasks) — Can be set for Account » Database » Schema » Task
- Data Type:
String
- Description:
Specifies the size of the compute resources to provision for the first run of the task, before a task history is available for Snowflake to determine an ideal size. Once a task has successfully completed a few runs, Snowflake ignores this parameter setting. If the task history is unavailable for a given task, the compute resources revert to this initial size.
Note
This parameter applies only to serverless tasks.
The size is equivalent to the compute resources available when creating a warehouse. If the parameter is omitted, the first runs of the task are executed using a medium-sized (
MEDIUM) warehouse.You can change the initial size for individual tasks (using ALTER TASK) after the task is created but before it has run successfully once. Changing the parameter after the first run of this task starts has no effect on the compute resources for current or future task runs.
Note that suspending and resuming a task does not remove the task history used to size the compute resources. The task history is only removed if the task is recreated (using the CREATE OR REPLACE TASK syntax).
- Values:
Any traditional warehouse size:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. The maximum size isX2LARGE.Also supports the syntax:
XXLARGE.- Default:
MEDIUM
USER_
- Type:
Object (for databases, schemas, and tasks) — Can be set for Account » Database » Schema » Task
- Data Type:
Number
- Description:
Defines how frequently a triggered task can execute in seconds. If a task is triggered again while it’s running, Snowflake waits the specified number of seconds (after the previous run was scheduled) before starting the next run.
If you set this parameter to more than 12 hours for a task, the task runs every 12 hours.
- Values:
10-604800(1 week).- Default:
30
USER_
- Type:
Object (for databases, schemas, and tasks) — Can be set for Account » Database » Schema » Task
- Data Type:
Number
- Description:
Specifies the time limit on a single run of the task before it times out (in milliseconds).
Note
- Before you increase the time limit for tasks significantly, consider whether the SQL statements in the task definitions could be optimized (either by rewriting the statements or using stored procedures) or whether the warehouse size for tasks with user-managed compute resources should be increased.
- When both STATEMENT_TIMEOUT_IN_SECONDS and USER_TASK_TIMEOUT_MS are set, the timeout is the lowest non-zero value of the two parameters.
- When both STATEMENT_QUEUED_TIMEOUT_IN_SECONDS and USER_TASK_TIMEOUT_MS are set, the value of USER_TASK_TIMEOUT_MS takes precedence.
For more information about USER_TASK_TIMEOUT_MS, see CREATE TASK…USER_TASK_TIMEOUT.
- Values:
0-604800000(7 days). A value of0specifies that the maximum timeout value is enforced.- Default:
3600000(1 hour)
USE_
- Type:
Account — Can be set only for Account
- Data Type:
String (Constant)
- Description:
Controls whether the Workspaces editor is the default SQL editing experience for the account.
- Values:
always: Set the account-wide default editor to be Workspaces for all users.never: Revert to the previous editor and temporarily ignore any Snowflake-managed BCR that makes Workspaces the default.For more information, see Workspaces.
WEEK_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Number
- Description:
Specifies how the weeks in a given year are computed.
- Values:
0: The semantics used are equivalent to the ISO semantics, in which a week belongs to a given year if at least 4 days of that week are in that year.1: January 1 is included in the first week of the year and December 31 is included in the last week of the year.- Default:
0(ISO-like behavior)
Tip
1 is the most common value, based on feedback we’ve received. For more information, including examples, see Calendar weeks and weekdays.
WEEK_
- Type:
Session — Can be set for Account » User » Session
- Data Type:
Number
- Description:
Specifies the first day of the week (used by week-related date functions).
- Values:
0: Legacy Snowflake behavior is used (ISO-like semantics).1(Monday) to7(Sunday): All the week-related functions use weeks that start on the specified day of the week.- Default:
0(legacy Snowflake behavior)
Tip
1 is the most common value, based on feedback we’ve received. For more information, including examples, see Calendar weeks and weekdays.