Benutzerdefinierte Aggregatfunktionen (UDAFs) nehmen eine oder mehrere Zeilen als Eingabe entgegen und erzeugen eine einzelne Zeile als Ausgabe. Sie arbeiten mit Werten über mehrere Zeilen hinweg, um mathematische Berechnungen wie Summe, Durchschnitt, Zählung, Ermitteln von Minimum- oder Maximumwert, Standardabweichung und Schätzung sowie andere nicht mathematische Operationen auszuführen.
Python UDAFs bietet Ihnen die Möglichkeit, eigene Aggregatfunktionen zu schreiben, die den systemdefinierten Funktionen von Snowflake SQL Aggregatfunktionen ähnlich sind.
aggregate_state hat eine maximale Größe von 64 MB in einer serialisierten Version. Versuchen Sie also, die Größe des Aggregatzustands zu steuern.
Sie können eine UDAF nicht als Fensterfunktion (d. h. mit einer OVER-Klausel) aufrufen.
IMMUTABLE wird bei einer Aggregatfunktion nicht unterstützt (wenn Sie den Parameter AGGREGATE verwenden). Daher sind alle Aggregatfunktionen standardmäßig VOLATILE.
Benutzerdefinierte Aggregatfunktionen können nicht in Verbindung mit der WITHIN GROUP-Klausel verwendet werden. Abfragen werden nicht ausgeführt.
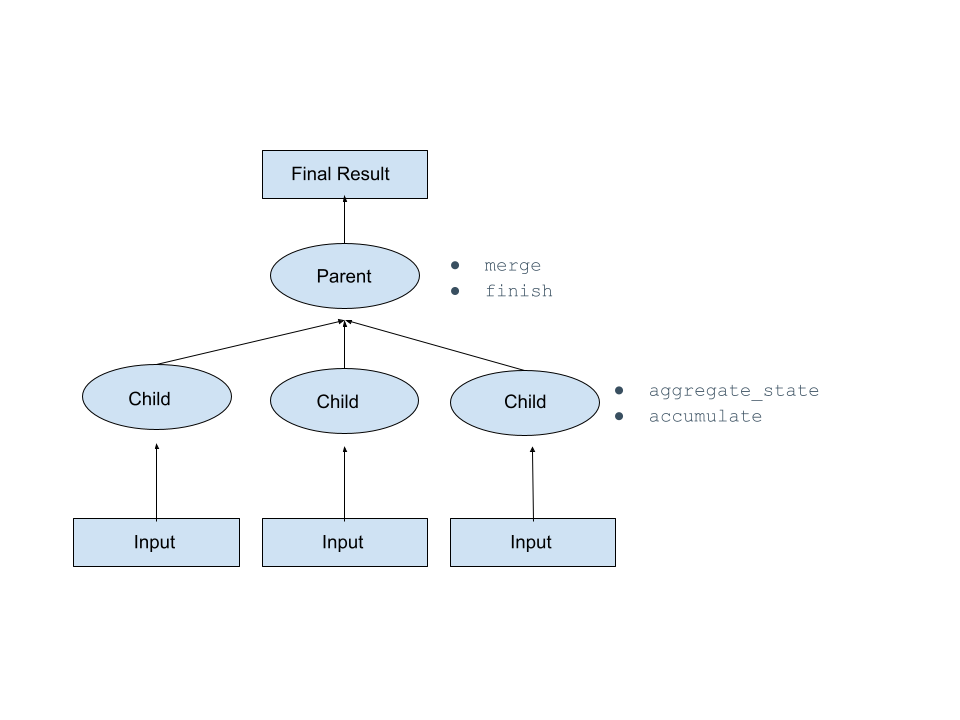
Eine Aggregatfunktion aggregiert die Zustände in untergeordneten Knoten. Anschließend werden diese aggregierten Zustände serialisiert und an den übergeordneten Knoten gesendet, wo sie zusammengeführt werden und das Endergebnis berechnet wird.
Um eine Aggregatfunktion zu definieren, müssen Sie eine Python-Klasse definieren (die der Handler der Funktion ist), die Methoden enthält, die Snowflake zur Laufzeit aufruft. Diese Methoden werden in der folgenden Tabelle beschrieben. Beispiele finden Sie an anderer Stelle unter diesem Thema.
Methode
Anforderung
Beschreibung
__init__
Erforderlich
Initialisiert den internen Status eines Aggregats.
Der Code im folgenden Beispiel definiert eine benutzerdefinierte Aggregatfunktion (UDAF) python_sum, die die Summe der numerischen Werte zurückgibt.
Erstellen Sie den UDAF.
CREATEORREPLACEAGGREGATEFUNCTIONPYTHON_SUM(aINT)RETURNSINTLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonSum'AS$$classPythonSum:def__init__(self):# This aggregate state is a primitive Python data type.self._partial_sum=0@propertydefaggregate_state(self):returnself._partial_sumdefaccumulate(self,input_value):self._partial_sum+=input_valuedefmerge(self,other_partial_sum):self._partial_sum+=other_partial_sumdeffinish(self):returnself._partial_sum$$;
Vergleichen Sie die Ergebnisse mit der Ausgabe der systemdefinierten Snowflake SQL-Funktion SUM, und überzeugen Sie sich, dass das Ergebnis dasselbe ist.
SELECTsum(col)FROMsales;
Gruppieren Sie die Summenwerte in der Verkaufstabelle nach dem Artikeltyp.
Der Code im folgenden Beispiel definiert eine benutzerdefinierte Aggregatfunktion python_avg, die den Durchschnitt der numerischen Werte zurückgibt.
Erstellen Sie die Funktion.
CREATEORREPLACEAGGREGATEFUNCTIONpython_avg(aINT)RETURNSFLOATLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonAvg'AS$$fromdataclassesimportdataclass@dataclassclassAvgAggState:count:intsum:intclassPythonAvg:def__init__(self):# This aggregate state is an object data type.self._agg_state=AvgAggState(0,0)@propertydefaggregate_state(self):returnself._agg_statedefaccumulate(self,input_value):sum=self._agg_state.sumcount=self._agg_state.countself._agg_state.sum=sum+input_valueself._agg_state.count=count+1defmerge(self,other_agg_state):sum=self._agg_state.sumcount=self._agg_state.countother_sum=other_agg_state.sumother_count=other_agg_state.countself._agg_state.sum=sum+other_sumself._agg_state.count=count+other_countdeffinish(self):sum=self._agg_state.sumcount=self._agg_state.countreturnsum/count$$;
Rufen Sie die benutzerdefinierte Funktion python_avg auf.
SELECTpython_avg(price)FROMsales;
Vergleichen Sie die Ergebnisse mit der Ausgabe der systemdefinierten Snowflake SQL-Funktion AVG, und überzeugen Sie sich, dass das Ergebnis dasselbe ist.
SELECTavg(price)FROMsales;
Gruppieren Sie die Durchschnittswerte in der Verkaufstabelle nach dem Artikeltyp.
Der Code im folgenden Beispiel gibt eine Liste der größten Werte für k zurück. Der Code akkumuliert negierte Eingabewerte auf einem Min-Heap und gibt dann die obersten k größten Werte zurück.
CREATEORREPLACEAGGREGATEFUNCTIONpythonTopK(inputINT,kINT)RETURNSARRAYLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonTopK'AS$$importheapqfromdataclassesimportdataclassimportitertoolsfromtypingimportList@dataclassclassAggState:minheap:List[int]k:intclassPythonTopK:def__init__(self):self._agg_state=AggState([],0)@propertydefaggregate_state(self):returnself._agg_state@staticmethoddefget_top_k_items(minheap,k):# Return k smallest elements if there are more than k elements on the min heap.if(len(minheap)>k):return[heapq.heappop(minheap)foriinrange(k)]returnminheapdefaccumulate(self,input,k):self._agg_state.k=k# Store the input as negative value, as heapq is a min heap.heapq.heappush(self._agg_state.minheap,-input)# Store only top k items on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)defmerge(self,other_agg_state):k=self._agg_state.kifself._agg_state.k>0elseother_agg_state.k# Merge two min heaps by popping off elements from one and pushing them onto another.while(len(other_agg_state.minheap)>0):heapq.heappush(self._agg_state.minheap,heapq.heappop(other_agg_state.minheap))# Store only k elements on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)deffinish(self):return[-xforxinself._agg_state.minheap]$$;
CREATEORREPLACETABLEnumbers_table(num_columnINT);INSERTINTOnumbers_tableSELECT5FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT1FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT9FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT7FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT10FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT3FROMTABLE(GENERATOR(ROWCOUNT=>10));-- Return top 15 largest values from numbers_table.SELECTpythonTopK(num_column,15)FROMnumbers_table;