Parameter¶
Snowflake bietet Parameter, mit denen Sie das Verhalten Ihres Kontos, einzelner Benutzersitzungen und Objekte steuern können. Alle Parameter haben Standardwerte. Sie können diese Parameter je nach Parametertyp (Konto, Sitzung oder Objekt) auf verschiedenen Ebenen festlegen und überschreiben.
Parameterhierarchie und Typen¶
In diesem Abschnitt werden die verschiedenen Parametertypen und die Ebenen beschrieben, auf denen die einzelnen Typen festgelegt werden können. Es gibt drei Arten von Parametern:
Die folgende Abbildung veranschaulicht die hierarchische Beziehung zwischen den verschiedenen Parametertypen und wie einzelne Parameter auf jeder Ebene überschrieben werden können:
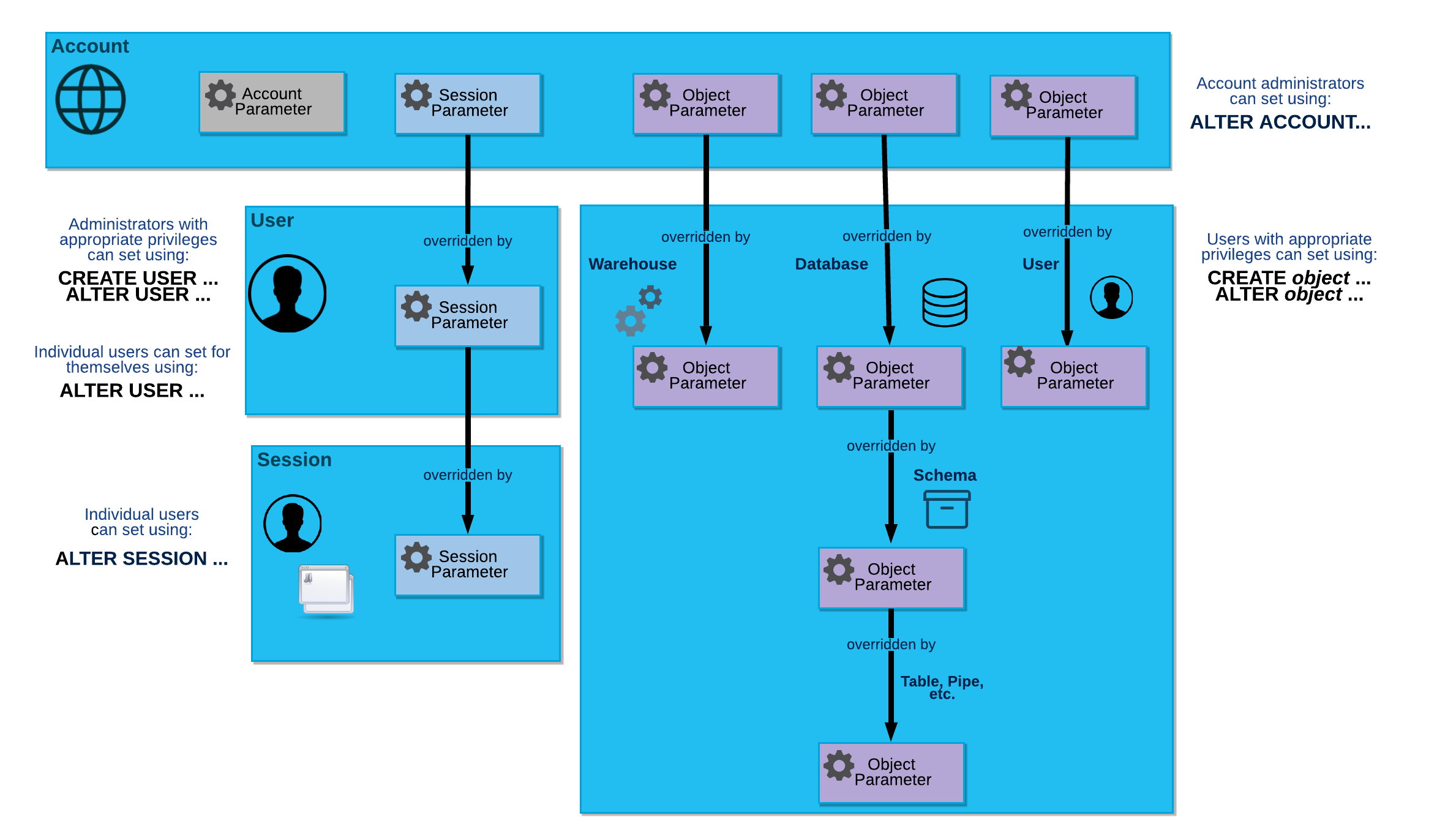
Kontoparameter¶
Sie können Kontoparameter nur dann auf Kontoebene festlegen, wenn Sie eine Rolle verwenden, der die Berechtigung zum Festlegen des Parameters erteilt wurde. Um einen Kontoparameter festzulegen, führen Sie den Befehl ALTER ACCOUNT aus.
Snowflake stellt die folgenden Kontoparameter bereit:
Parameter |
Anmerkungen |
|---|---|
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES |
Wird verwendet, um die in privaten Arbeitsbereichen des Kontos zulässigen Dateierweiterungen anzugeben. |
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_SHARED_WORKSPACES |
Dient zur Angabe der Dateierweiterungen, die in freigegebenen Arbeitsbereichen für das Konto zulässig sind. |
Wird verwendet, um Clients den Zugriff auf Bindungsvariablenwerte zu ermöglichen. |
|
Wird verwendet, um das Verbindungscaching in browserbasiertem Single Sign-On (SSO) für von Snowflake bereitgestellte Clients zu aktivieren. |
|
Wird verwenden, um die Workload-Typen anzugeben, die in Ihrem Konto in Snowpark Container Services bereitgestellt werden dürfen. |
|
Wird zur Verschlüsselung von zum Laden oder Entladen von Daten im Stagingbereich bereitgestellten Dateien verwendet. Erfordert möglicherweise zusätzliche Installations- und Konfigurationsaktivitäten (Details siehe Beschreibung). |
|
Wird verwendet, um die regionsübergreifende Verarbeitung von Snowflake Cortex-Anrufen in einer anderen Region zu ermöglichen, wenn der Aufruf nicht in Ihrer Kontoregion verarbeitet werden kann. |
|
Wird verwendet, um die Standardversion für alle zukünftigen dbt-Projektobjekte festzulegen, die in einem Konto erstellt werden. |
|
Wird verwendet, um die Gewährung von Berechtigungen direkt an Benutzer zu deaktivieren. Weitere Informationen finden Sie in den Nutzungshinweisen zu GRANT-Berechtigungen für Benutzer (USERS). |
|
Wird verwendet, um die Workload-Typen anzugeben, die in Ihrem Konto nicht für Snowpark Container Services bereitgestellt werden dürfen. |
|
Steuert, ob Ereignisse aus der Klassifizierung sensibler Daten in der Ereignistabelle des Benutzers protokolliert werden. |
|
Steuert, ob Ereignisse aus Budgets in der Ereignistabelle protokolliert werden. |
|
Wird verwendet, um die Optimierung der ausgehenden Kosten für die automatische Ausführung von Freigabeangeboten zu aktivieren oder zu deaktivieren. |
|
Erlaubt der Funktion SYSTEM$GET_PRIVATELINK_CONFIG, den Schlüssel |
|
Erlaubt, dass die SYSTEM$GET_PRIVATELINK_CONFIG-Funktion, die Schlüssel |
|
Wird zum Aktivieren oder Deaktivieren von privaten Notebooks auf einem Snowflake-Konto verwendet. |
|
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT |
Wird verwendet, um die Durchsetzung der SNOWFLAKE_FULL-Verschlüsselung für Blockspeicher-Volumes und Snapshots von Snowpark Container Services zu ermöglichen. |
Steuert, ob Snowflake Telemetriedaten für die Tag-Weitergabe sammelt. |
|
Dient zur Angabe der Entscheidung eines Image-Repository, Tri-Secret Secure und Periodische Wiederverschlüsselung nicht zu verwenden. |
|
Dient zum Festlegen des Aktualisierungszeitplans für alle Freigabeangebote in einem Konto. |
|
Ermöglicht die Festlegung der minimalen Datenaufbewahrungsfrist für historische Daten von Time Travel-Operationen. |
|
Dies ist der einzige Kontoparameter, der entweder von Kontoadministratoren (d. h. Benutzern mit der Systemrolle ACCOUNTADMIN) oder Sicherheitsadministratoren (d. h. Benutzern mit der Systemrolle SECURITYADMIN) festgelegt werden kann. . Weitere Informationen finden Sie unter Objektparameter. |
|
Wird verwendet, um anzugeben, ob der SQL-Text einer verfolgten SQL-Anweisung erfasst werden soll. |
|
Wird zum Aktivieren oder Deaktivieren von Workspaces als SQL-Standardeditor für das Konto verwendet. |
Bemerkung
Kontoparameter werden in der Ausgabe von :emph:` standardmäßig nicht:doc:/sql-reference/sql/show-parameters` angezeigt. Informationen zum Anzeigen von Kontoparametern finden Sie unter Anzeigen von Parametern und deren Werten (in diesem Thema).
Sitzungsparameter¶
Die meisten Parameter sind Sitzungsparameter, die Sie auf folgenden Ebenen festlegen können:
- Konto:
Kontoadministratoren können mit dem Befehl ALTER ACCOUNT Sitzungsparameter für das Konto festlegen.
Die Werte, die Sie auf dieser Ebene festlegen, werden zu den Standardwerten für einzelne Benutzer und deren Sitzungen.
- Benutzer:
Administratoren mit den entsprechenden Berechtigungen (normalerweise ein Benutzer, dem die Rolle SECURITYADMIN erteilt wurde), können den Befehl ALTER USER ausführen, um Sitzungsparameter für einzelne Benutzer zu überschreiben. Darüber hinaus können einzelne Benutzer den Befehl ALTER USER ausführen, um die Standard-Sitzungsparameter für sich selbst zu überschreiben.
Die Werte, die Sie für einen Benutzer festlegen, werden zu den Standardwerten in jeder Sitzung, die von diesem Benutzer gestartet wird.
- Sitzung:
Benutzer können den Befehl ALTER SESSION ausführen, um Sitzungsparameter für die aktuelle Sitzung zu überschreiben.
Bemerkung
Standardmäßig werden nur Sitzungsparameter in der Ausgabe von SHOW PARAMETERS angezeigt. Informationen zum Anzeigen von Konto- und Objektparametern finden Sie unter Anzeigen von Parametern und deren Werten (in diesem Thema).
Objektparameter¶
Sie können Objektparameter auf folgenden Ebenen festlegen:
- Konto:
Kontoadministratoren können mit dem Befehl ALTER ACCOUNT Objektparameter für Objekte im Konto festlegen.
Die Werte, die Sie auf dieser Ebene festlegen, werden zu den Standardwerten für einzelne Objekte, die im Konto erstellt werden.
- Objekt:
Benutzer mit den geeigneten Berechtigungen können die Befehle CREATE <Objekt> oder ALTER <Objekt> verwenden, um Objektparameter für ein einzelnes Objekt zu überschreiben.
Snowflake stellt die folgenden Objektparameter bereit:
Parameter |
Objekttyp |
Anmerkungen |
|---|---|---|
Gespeicherte Snowflake Scripting-Prozedur |
||
Datenbank, Schema |
Gibt ein Präfix an, das im Schreibpfad für Apache Iceberg™-Tabellendateien verwendet werden soll. |
|
Datenbank, Schema, Apache Iceberg™-Tabelle |
||
Konto, Datenbank, Schema, Apache Iceberg™-Tabelle |
Dieser Parameter wird nur für von Snowflake verwaltete Iceberg-Tabellen unterstützt, die Sie mit Open Catalog synchronisieren. |
|
Cortex-AI-Funktionen und Modelle |
Durch Kommas getrennte Namen der zulässigen Cortex-Sprachmodelle, |
|
Tabelle |
Gibt den Zeitplan für die Ausführung der mit der Tabelle verbundenen Datenmetrikfunktionen an. Alle Datenmetrikfunktionen in der Tabelle oder Ansicht folgen demselben Zeitplan. |
|
Datenbank, Schema, Tabelle |
||
Datenbank, Schema, Tabelle |
||
Datenbank, Schema |
||
Datenbank, Schema |
||
Konto |
Konfigurieren Ihrer eigenen bevorzugten Computepools für Streamlit-Apps |
|
Konto, Datenbank, Schema |
||
Konto, Benutzer |
||
Konto, Datenbank, Schema, Apache Iceberg™-Tabelle |
Dieser Parameter wird nur für von Snowflake verwaltete Iceberg-Tabellen unterstützt. |
|
Konto, Datenbank, Schema, Apache Iceberg™-Tabelle |
||
Benutzer |
Beeinflusst den Abfrageverlauf für Abfragen, die aufgrund von Syntax- oder Parsing-Fehlern fehlschlagen. |
|
Benutzer |
Beeinflusst die Ausblendung von Fehlermeldungen im Zusammenhang mit sicheren Objekten in Metadaten. |
|
Datenbank, Konto |
||
Datenbank, Schema, Apache Iceberg™-Tabelle |
||
Apache Iceberg™-Tabelle |
||
Konto, Datenbank, Schema |
||
Konto, Datenbank, Schema, DCM-Projekt, gespeicherte Prozedur, Funktion, dynamische Tabelle, Iceberg-Tabelle, Aufgabe, Service. |
Protokollmeldungen aus Protokollierungs-APIs. |
|
Konto, Datenbank, Schema, DCM-Projekt, gespeicherte Prozedur, Funktion, dynamische Tabelle, Iceberg-Tabelle, Aufgabe, Service. |
Protokollereignisse (Datensatztyp EVENT), die in die Ereignistabelle geschrieben wurden. |
|
Warehouse |
||
Datenbank, Schema, Tabelle |
||
Konto, Datenbank, Schema, gespeicherte Prozedur, Funktion |
||
Benutzer |
Dies ist der einzige Benutzerparameter, der entweder von Kontoadministratoren (d. h. Benutzern mit der Systemrolle ACCOUNTADMIN) oder Sicherheitsadministratoren (d. h. Benutzern mit der Systemrolle SECURITYADMIN) festgelegt werden kann. Wenn dieser Parameter für das Konto und einen Benutzer desselben Kontos festgelegt ist, hat die Netzwerkrichtlinie auf Benutzerebene Vorrang vor der Netzwerkrichtlinie auf Kontoebene. |
|
Apache Iceberg™-Tabelle |
Gibt das Pfad-Layout für Parquet-Datendateien an, die in partitionierte Iceberg-Tabellen geschrieben werden. |
|
Schema, Pipe |
||
Benutzer |
||
Benutzer |
||
Datenbank, Schema, Dateiformat, Apache Iceberg™-Tabelle |
Kann nur für Iceberg-Tabellen festgelegt werden, die einen externen Iceberg-Katalog verwenden. |
|
|
Datenbank, Schema, Tabelle |
Verwenden Sie diesen Parameter, um Zeilenzeitstempel für Ihre Tabellen zu aktivieren. Weitere Informationen dazu finden Sie unter Verwenden von Zeilenzeitstempeln, um die Latenz in Ihren Pipelines zu messen. |
|
Datenbank, Schema, Tabelle |
Verwenden Sie diesen Parameter, um für neue Tabellen in einem Container standardmäßig Zeilenzeitstempel festzulegen. Weitere Informationen dazu finden Sie unter Verwenden von Zeilenzeitstempeln, um die Latenz in Ihren Pipelines zu messen. |
Datenbank, Schema, Aufgabe, Konto |
||
Datenbank, Schema, Aufgabe, Konto |
||
Warehouse |
Auch ein Sitzungsparameter (kann sowohl auf Objekt- als auch auf Sitzungsebene eingestellt werden). Informationen zur Vererbung und zum Überschreiben finden Sie in der Parameterbeschreibung. |
|
Warehouse |
Auch ein Sitzungsparameter (kann sowohl auf Objekt- als auch auf Sitzungsebene eingestellt werden). Informationen zur Vererbung und zum Überschreiben finden Sie in der Parameterbeschreibung. |
|
Datenbank, Schema, Apache Iceberg™-Tabelle |
Dieser Parameter wird nur für Iceberg-Tabellen unterstützt, die Snowflake als Katalog verwenden. |
|
Datenbank, Schema, Aufgabe |
||
Datenbank, Schema, Aufgabe |
||
Konto, Datenbank, Schema, gespeicherte Prozedur, Funktion |
||
Datenbank, Schema, Aufgabe |
||
Datenbank, Schema, Aufgabe |
||
Datenbank, Schema, Aufgabe |
Bemerkung
Standardmäßig werden Objektparameter nicht in der Ausgabe von SHOW PARAMETERS angezeigt. Informationen zum Anzeigen von Objektparametern finden Sie unter Anzeigen von Parametern und deren Werten (in diesem Thema).
Anzeigen von Parametern und deren Werten¶
Um die eingestellten Parameter und deren Standardwerte anzuzeigen, führen Sie den Befehl SHOW PARAMETERS aus. Sie können den Befehl mit verschiedenen Befehlsparametern ausführen, um verschiedene Arten von Parametern anzuzeigen:
Anzeigen von Sitzungsparametern¶
Standardmäßig zeigt der Befehl nur Sitzungsparameter an:
Anzeigen von Objektparametern¶
Um die Objektparameter für ein bestimmtes Objekt anzuzeigen, fügen Sie dem Objekttyp und dem Namen eine IN-Klausel hinzu. Beispiel:
Anzeigen aller Parameter (einschließlich Konto- und Objektparameter)¶
Um alle Parameter anzuzeigen, einschließlich Konto- und Objektparameter, fügen Sie die IN ACCOUNT-Klausel ein:
Beschränken der Liste der Parameter nach Namen¶
Sie können die LIKE-Klausel angeben, um die Liste der Parameter nach Namen einzuschränken. Beispiel:
So zeigen Sie die Sitzungsparameter an, deren Namen „time“ enthalten:
So zeigen Sie die Sitzungsparameter an, deren Namen mit „time“ beginnen:
Bemerkung
Sie müssen die LIKE-Klausel vor der IN-Klausel angeben.
ABORT_DETACHED_QUERY¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt die Aktion an, die Snowflake für laufende Abfragen ausführt, wenn die Verbindung aufgrund einer abrupten Beendigung einer Sitzung (z. B. Netzwerkausfall, Browserbeendigung, Dienstunterbrechung) unterbrochen wird.
- Werte:
TRUE: In Ausführung befindliche Abfragen werden 5 Minuten nach Verbindungsverlust abgebrochen.FALSE: In Bearbeitung befindliche Abfragen werden abgeschlossen.- Standard:
FALSE
Bemerkung
Für Client-Treiber unterscheidet sich das Schließen der Verbindung von der Client-Seite aus (z. B. der Aufruf von
connection.close()) vom tatsächlichen Abmelden von der Snowflake-Sitzung. Das Schließen der Verbindung kann mit der Bereinigung von Ressourcen verbunden sein, die zur Verbindung gehören, einschließlich, aber nicht beschränkt auf die Durchführung einer Sitzungsabmeldung. Das Ausführen einer Sitzungsabmeldung bedeutet auch, dass alle Abfragen, die noch in derselben Sitzung ausgeführt werden (z. B. asynchron übermittelte Abfragen), nach ein paar Minuten abgebrochen werden, wenn die Sitzung abgemeldet wird, auch wenn der Parameter ABORT_DETACHED_QUERY auffalseeingestellt ist (der Standardwert).Daher implementieren einige Snowflake-Treiber ihre eigene Geschäftslogik, um zu entscheiden, ob ein Abmelden der Sitzung durchgeführt wird, wenn die Verbindung geschlossen wird.
Derzeit ist diese Funktionalität in den folgenden Treibern implementiert:
Die meisten Abfragen erfordern Computeressourcen, um ausgeführt werden zu können. Diese Ressourcen werden von virtuellen Warehouses bereitgestellt, die während des Betriebs Credits verbrauchen. Wenn die Snowflake-Sitzung beim Schließen der Verbindung nicht beendet wird, werden Warehouses möglicherweise weiterhin ausgeführt und verbrauchen Credits, um alle Abfragen abzuschließen, die sich zum Zeitpunkt des Schließens der Verbindung noch in Ausführung befanden, bis zum Wert des Parameters STATEMENT_TIMEOUT_IN_SECONDS mit einem Standardwert von zwei Tagen.
ACTIVE_PYTHON_PROFILER¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Legt den Profiler fest, der für die Sitzung beim Profiling des Python-Handler-Codes verwendet wird.
- Werte:
'LINE': Das Profil soll sich auf die Aktivität der Zeilennutzung konzentrieren.'MEMORY': Das Profil soll sich auf die Aktivität der Speichernutzung konzentrieren.- Standard:
Keine.
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Dateierweiterungen an, die in privaten Arbeitsbereichen für das Konto zulässig sind. Der Wert ist eine durch Kommas getrennte Liste von Erweiterungen, zum Beispiel:
.ipynb,.sql,.txt. Wenn der Parameter leer ist (Standard), sind alle Dateierweiterungen zulässig.Wenn die Zulassungsliste nicht leer ist:
Nur die aufgeführten Erweiterungen sind erlaubt; alle anderen sind blockiert.
Dateien, die über Workspaces mit einer nicht zulässigen Erweiterung hochgeladen werden, schlagen sofort fehl.
Wenn eine Datei umbenannt wird, um eine nicht zulässige Erweiterung zu verwenden, kann im Arbeitsbereich nicht mehr auf die Datei zugegriffen werden.
Bereits vorhandene Dateien mit nicht zulässigen Erweiterungen werden nicht in Arbeitsbereichen angezeigt.
Benutzende können den
PUT-Befehl der Snowflake-CLI weiterhin zum Hochladen von Dateien mit nicht zulässigen Erweiterungen in den virtuellen Stagingbereich eines Arbeitsbereichs oder virtuellen Stagingbereichs eines Notebook-Projektobjekts verwenden. Diese Dateien sind jedoch nicht zugänglich und können innerhalb des Arbeitsbereichs oder der Notebook-Projektobjektumgebung nicht verwendet, angezeigt oder heruntergeladen (überGET) oder aufgelistet (über``LIST``) werden.Um die Kernfunktionalität des Arbeitsbereichs aufrechtzuerhalten, schließen Sie
.ipynbund.sqlin die Zulassungsliste ein.Dateien ohne eine Erweiterung (z. B.``Makefile``) sind nicht zulässig, sobald die Liste nicht leer ist.
Dotfiles (z. B.``.gitignore`` oder
.venv) müssen explizit zur Liste hinzugefügt werden.Beim Abgleich von Erweiterungen wird zwischen Groß- und Kleinschreibung unterschieden. Beispiel: Wenn
.txtin der Liste ist, ist.TXTnicht zulässig.
- Standard:
Leere Zeichenfolge (alle Erweiterungen erlaubt)
ALLOW_BIND_VALUES_ACCESS¶
- Typ:
Objekt – Kann nur für Konto eingestellt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Clients auf Werte von Bindungsvariablen durch Verwendung der BIND_VALUES-Tabellenfunktion, der QUERY_HISTORY Account Usage-Ansicht, der QUERY_HISTORY Organization Usage-Ansicht oder der QUERY_HISTORY-Funktion zugreifen können. Weitere Informationen dazu finden Sie unter Abrufen der Werte der Bindungsvariablen.
- Werte:
TRUE: Ermöglicht das Abrufen von Bindungsvariablenwerten.FALSE: Ermöglicht nicht das Abrufen von Bindungsvariablenwerten.- Standard:
TRUE
ALLOW_CLIENT_MFA_CACHING¶
- Typ:
Objekt – Kann nur für Konto eingestellt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob ein MFA-Token im Keystore des clientseitigen Betriebssystems gespeichert werden kann, um für eine kontinuierliche, sichere Konnektivität zu sorgen, ohne dass Benutzer zu Beginn jedes Verbindungsversuchs zu Snowflake auf eine MFA-Eingabeaufforderung reagieren müssen. Einzelheiten und die Liste der unterstützten von Snowflake bereitgestellten Clients finden Sie unter Verwenden von MFA-Tokencaching zur Minimierung der Anzahl von Eingabeaufforderungen bei der Authentifizierung – Optional.
- Werte:
TRUE: Speichert ein MFA-Token im Keystore des clientseitigen Betriebssystems, damit die Clientanwendung beim Herstellen einer neuen Verbindung das MFA-Token verwenden kann. Bei „true“ werden Benutzer nicht aufgefordert, auf zusätzliche MFA-Eingabeaufforderungen zu reagieren.FALSE: Speichert kein MFA-Token. Benutzer müssen auf eine MFA-Eingabeaufforderung reagieren, wenn die Clientanwendung eine neue Verbindung mit Snowflake herstellt.- Standard:
FALSE
ALLOW_ID_TOKEN¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob ein Verbindungstoken im Keystore des clientseitigen Betriebssystems gespeichert werden kann, um eine kontinuierliche, sichere Konnektivität sicherzustellen, ohne dass Benutzer zu Beginn jedes Verbindungsversuchs zu Snowflake Anmeldeinformationen eingeben müssen. Einzelheiten und die Liste der unterstützten von Snowflake bereitgestellten Clients finden Sie unter Verwenden von Verbindungscaching zum Minimieren der Anzahl der Eingabeaufforderungen für die Authentifizierung – Optional.
- Werte:
TRUE: Speichert ein Verbindungstoken im Keystore des clientseitigen Betriebssystems, damit die Clientanwendung browserbasiertes SSO ausführen kann, ohne Benutzer zur Authentifizierung aufzufordern, wenn eine neue Verbindung hergestellt wird.FALSE: Speichert kein Verbindungstoken. Benutzer werden aufgefordert, sich zu authentifizieren, wenn die Clientanwendung eine neue Verbindung mit Snowflake herstellt. SSO für Verbindung zu Snowflake ist weiterhin möglich, wenn dieser Parameter auf „false“ gesetzt ist.- Standard:
FALSE
ALLOWED_SPCS_WORKLOAD_TYPES¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Workload-Typen an, die in Ihrem Konto in Snowpark Container Services bereitgestellt werden dürfen. Siehe auch DISALLOWED_SPCS_WORKLOAD_TYPES.
- Werte:
Der Wert ist eine durch Kommas getrennte Liste der folgenden unterstützten Workload-Typen:
USER: Alle Workloads, die direkt von Benutzenden bereitgestellt werden.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit in Snowflake.MODEL_SERVING: ML Model Serving.ML_JOB: Snowflake ML-Jobs.ALL: Alle Workloads.
- Standard:
ALL
Bemerkung
Wenn Sie ALLOWED_SPCS_WORKLOAD_TYPES und DISALLOWED_SPCS_WORKLOAD_TYPES konfigurieren, hatDISALLOWED_SPCS_WORKLOAD_TYPES Vorrang. Wenn Sie beispielsweise beide Parameter konfigurieren und die Workload NOTEBOOK angeben, dürfen NOTEBOOK-Workloads nicht auf Snowpark Container Services ausgeführt werden.
AUTO_EVENT_LOGGING¶
- Typ:
Objekt (für gespeicherte Snowflake Scripting-Prozeduren)
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Steuert, ob Protokollmeldungen und Ablaufverfolgungsereignisse von Snowflake Scripting automatisch in die Ereignistabelle aufgenommen werden. Um diesen Parameter festzulegen, führen Sie den Befehl ALTER PROCEDURE aus.
- Werte:
LOGGING: Fügt automatisch die folgenden zusätzlichen Protokollierungsinformationen zur Ereignistabelle hinzu, wenn eine Prozedur ausgeführt wird:BEGIN/END eines Snowflake Scripting-Blocks.
BEGIN/END einer untergeordneten Jobanfrage.
Diese Informationen werden der Ereignistabelle nur hinzugefügt, wenn die effektive LOG_LEVEL für die gespeicherte Prozedur auf
TRACEeingestellt ist.TRACING: Fügt automatisch die folgenden zusätzlichen Ablaufverfolgungsinformationen zur Ereignistabelle hinzu, wenn eine gespeicherte Prozedur ausgeführt wird:Abfangen von Ausnahmen.
Informationen über die Ausführung von untergeordneten Jobs.
Statistiken über untergeordnete Jobs.
Statistiken zu gespeicherten Prozeduren, einschließlich Ausführungszeit und Eingabewerte.
Diese Informationen werden der Ereignistabelle nur hinzugefügt, wenn die effektive TRACE_LEVEL für die gespeicherte Prozedur auf
ALWAYSoderON_EVENTeingestellt ist.ALL: Fügt automatisch sowohl die für den WertLOGGINGhinzugefügten Protokollierungsinformationen als auch die für den WertTRACINGhinzugefügten Ablaufverfolgungsinformationen hinzu.OFF: Fügt der Ereignistabelle nicht automatisch Protokollierungs- oder Ablaufverfolgungsinformationen hinzu.
- Standard:
OFF
Weitere Informationen zur Verwendung dieses Parameters finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung, Automatisches Hinzufügen von Protokollmeldungen über Blöcke und untergeordnete Jobs und Automatische Ablaufverfolgung für untergeordnete Jobs und Ausnahmen.
AUTOCOMMIT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Autocommit für die Sitzung aktiviert ist. Autocommit bestimmt, ob eine DML-Anweisung automatisch committet wird, wenn die Anweisung ohne aktive Transaktion ausgeführt wird, nachdem die Anweisung erfolgreich abgeschlossen wurde. Weitere Informationen dazu finden Sie unter Transaktionen.
Bemerkung
Durch das Einstellen dieses Parameters auf
FALSEwird verhindert, dass Nutzungsdaten im ORGANIZATION_USAGE-Schema eines Organisationskonto gespeichert werden.- Werte:
TRUE: Autocommit ist aktiviert.FALSE: Autocommit ist deaktiviert, d. h. DML-Anweisungen müssen explizit committet oder rückgängig gemacht werden.- Standard:
TRUE
Bemerkung
Der FALSE-Wert wird für -Aufgaben nicht unterstützt.
AUTOCOMMIT_API_SUPPORTED (schreibgeschützt)¶
- Typ:
N/A
- Datentyp:
Boolesch
- Beschreibung:
Nur für den internen Gebrauch von Snowflake. Schreibgeschützter Parameter, der angibt, ob die API-Unterstützung für Autocommit für Ihr Konto aktiviert ist. Wenn der Wert
TRUEist, können Sie Autocommit über APIs für die folgenden Treiber/Konnektoren aktivieren oder deaktivieren:
BASE_LOCATION_PREFIX¶
- Typ:
Objekt (für Datenbanken und Schemas) – Kann festgelegt werden für Konto » Datenbank » Schema
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt ein Präfix für Snowflake an, das im Schreibpfad für von Snowflake verwaltete Apache Iceberg™-Tabellen verwendet werden soll. Weitere Informationen finden Sie unter Daten- und Metadatenverzeichnisse für Iceberg-Tabellen.
- Werte:
Ein beliebiges gültiges Zeichenfolgenpräfix, das den Speicher-Namenskonventionen Ihres Cloudanbieters entspricht.
- Standard:
Keine
BINARY_INPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Das Format der VARCHAR-Werte, die als Eingabewerte an VARCHAR-BINARY-Konvertierungsfunktionen übergeben werden. Weitere Informationen dazu finden Sie unter Eingabe und Ausgabe von Binärdaten.
- Werte:
HEX,BASE64oderUTF8/UTF-8- Standard:
HEX
BINARY_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Das Format für VARCHAR-Werte, die von BINARY-VARCHAR-Konvertierungsfunktionen zurückgegeben werden. Weitere Informationen dazu finden Sie unter Eingabe und Ausgabe von Binärdaten.
- Werte:
HEXoderBASE64- Standard:
HEX
CATALOG¶
- Typ:
Objekt (für Datenbanken, Schemas und Apache Iceberg™-Tabellen) — Kann eingestellt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Katalog für Apache Iceberg™-Tabellen an. Weitere Informationen dazu finden Sie in der Dokumentation zu Iceberg-Tabellen.
- Werte:
SNOWFLAKEoder ein anderer gültiger Katalogintegration-Bezeichner.- Standard:
Keine
CATALOG_SYNC¶
- Typ:
Objekt (für Datenbanken, Schemas und Iceberg-Tabellen) – Kann festgelegt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Namen Ihrer Katalogintegration für Snowflake Open Catalog an. Snowflake synchronisiert Tabellen, die die angegebene Katalogintegration verwenden, mit Ihrem Snowflake Open Catalog-Konto. Weitere Informationen dazu finden Sie unter Eine Snowflake-verwaltete Tabelle mit Snowflake Open Catalog synchronisieren.
- Werte:
Der Name einer bestehenden Katalogintegration für Open Catalog.
- Standard:
Keine
CLIENT_ENABLE_LOG_INFO_STATEMENT_PARAMETERS¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Clients:
JDBC
- Beschreibung:
Ermöglicht Benutzern das Protokollieren der an PreparedStatements gebundenen Datenwerte.
Um die Werte anzuzeigen, müssen Sie nicht nur diesen Parameter auf Sitzungsebene auf
TRUEsetzen, sondern auch den Verbindungsparameter mit dem NamenTRACINGaufINFOoderALL.Setzen Sie
TRACINGaufALL, um alle Debugging-Informationen und alle Bindungsinformationen anzuzeigen.Setzen Sie
TRACINGaufINFO, um die Bindungsparameterwerte und wenige andere Debugging-Informationen anzuzeigen.
Vorsicht
Wenn Sie vertrauliche Informationen, wie z. B. medizinische Diagnosen oder Kennwörter, eingeben, werden diese Informationen protokolliert. Snowflake empfiehlt, sicherzustellen, dass die Protokolldatei sicher ist, oder nur Testdaten zu verwenden, wenn Sie diesen Parameter auf
TRUEsetzen.- Werte:
TRUEoderFALSE.- Standard:
FALSE
CLIENT_ENCRYPTION_KEY_SIZE¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Ganzzahl (Integer)
- Clients:
Beliebig
- Beschreibung:
Gibt bei Verwendung des Verschlüsselungstyps
SNOWFLAKE_FULLdie AES-Verschlüsselungsschlüsselgröße in Bit an, die von Snowflake verwendet wird, um Dateien zu verschlüsseln/entschlüsseln, die in internen Stagingbereichen (zum Laden/Entladen von Daten) gespeichert sind.- Werte:
128oder256- Standard:
128
Bemerkung
Dieser Parameter wird nicht zum Verschlüsseln/Entschlüsseln von Dateien verwendet, die in externen Stagingbereichen (d. h. S3-Buckets oder Azure-Containern) gespeichert sind. Die Verschlüsselung/Entschlüsselung dieser Dateien erfolgt mithilfe eines externen Verschlüsselungsschlüssels, der explizit im COPY-Befehl oder in dem im Befehl angegebenen externen Stagingbereich angegeben ist.
Wenn Sie den JDBC-Treiber verwenden und diesen Parameter auf 256 setzen (für eine starke Verschlüsselung), müssen auf jedem Clientcomputer, von dem Daten geladen/entladen werden, zusätzliche JCE-Richtliniendateien installiert werden. Weitere Informationen zum Installieren der erforderlichen Dateien finden Sie unter Java-Anforderungen an den JDBC-Treiber.
Wenn Sie den Python-Konnektor (oder SnowSQL) verwenden und diesen Parameter auf 256 setzen (für starke Verschlüsselung), sind keine zusätzlichen Installations- oder Konfigurationsaufgaben erforderlich.
CLIENT_MEMORY_LIMIT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Clients:
JDBC, ODBC
- Beschreibung:
Parameter, der die maximale Speichermenge (in MB) angibt, die der JDBC- oder ODBC-Treiber für Resultsets von Abfragen verwenden darf.
JDBC-Treiber:
Um die JVM-Speicherverwaltung zu vereinfachen, legt der Parameter ein maximales globales Speichernutzungslimit für alle Abfragen fest.
CLIENT_RESULT_CHUNK_SIZE gibt die maximale Größe (in MB) jedes Sets (oder Blocks) der herunterzuladenden Abfrageergebnisse an. Der Treiber benötigt möglicherweise zusätzlichen Speicher, um einen Block zu verarbeiten. Wenn dies der Fall ist, wird die Speichernutzung zur Laufzeit so angepasst, dass mindestens ein Thread bzw. eine Abfrage verarbeitet wird. Vergewissern Sie sich, dass CLIENT_MEMORY_LIMIT deutlich höher als CLIENT_RESULT_CHUNK_SIZE eingestellt ist, um sicherzustellen, dass ausreichend Speicher verfügbar ist.
ODBC-Treiber:
Dieser Parameter wird ab Version 2.22.0 unterstützt.
CLIENT_RESULT_CHUNK_SIZEwird nicht unterstützt.
Bemerkung
Der Treiber versucht, den Parameterwert einzuhalten, begrenzt jedoch die Nutzung auf 80 % des Arbeitsspeichers Ihres Systems.
Das in diesem Parameter festgelegte Speichernutzungslimit gilt nicht für andere JDBC- oder ODBC-Treiberoperationen (z. B. Herstellen einer Verbindung mit der Datenbank, Vorbereiten einer Abfrage oder PUT- und GET-Anweisungen).
- Werte:
Jede gültige Anzahl von Megabytes.
- Standard:
1536(effektiv 1,5 GB)Die meisten Benutzer sollten diesen Parameter nicht einstellen müssen. Wenn dieser Parameter nicht vom Benutzer festgelegt wird, beginnt der Treiber mit der oben angegebenen Standardeinstellung.
Darüber hinaus verwaltet der JDBC-Treiber aktiv seinen Arbeitsspeicher, um zu vermeiden, dass der gesamte verfügbare Speicher belegt wird.
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Clients:
JDBC, ODBC
- Beschreibung:
Für bestimmte ODBC-Funktionen und JDBC-Methoden kann mit diesem Parameter der Standardsuchbereich aller Datenbanken/Schemas auf die aktuelle Datenbank bzw. das aktuelle Schema geändert werden. Bei einer eingegrenzten Suche werden normalerweise weniger Zeilen zurückgegeben und die Suche wird schneller ausgeführt.
Beispielsweise akzeptiert die JDBC-Methode
getTables()einen Datenbanknamen und einen Schemanamen als Argumente und gibt die Namen der Tabellen in der Datenbank und im Schema zurück. Wenn die Datenbank- und Schemaargumentenullsind, durchsucht die Methode standardmäßig alle Datenbanken und alle Schemas im Konto. Wenn Sie CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX aufTRUEsetzen, wird die Suche auf die aktuelle Datenbank und das aktuelle Schema eingegrenzt, die im Verbindungskontext angegeben sind.Wenn Sie diesen Parameter auf
TRUEsetzen, wird im Wesentlichen die folgende Rangfolge für Datenbank und Schema erstellt:Werte, die als Argumente an die Funktionen/Methoden übergeben wurden.
Im Verbindungskontext angegebene Werte (falls vorhanden).
Standard (alle Datenbanken und alle Schemas).
Weitere Details dazu finden Sie weiter unten.
Dieser Parameter gilt für Folgendes:
JDBC-Treibermethoden (für Klasse
DatabaseMetaData):getColumnsgetCrossReferencegetExportedKeysgetForeignKeysgetFunctionsgetImportedKeysgetPrimaryKeysgetSchemasgetTables
ODBC-Treiberfunktionen:
SQLTablesSQLColumnsSQLPrimaryKeysSQLForeignKeysSQLGetFunctionsSQLProcedures
- Werte:
TRUE: Wenn die Datenbank- und Schemaargumentenullsind, ruft der Treiber Metadaten nur für die Datenbank und das Schema ab, die im Verbindungskontext angegeben sind.Die Interaktion wird in der folgenden Tabelle ausführlicher beschrieben.
FALSE: Wenn die Datenbank- und Schemaargumentenullsind, ruft der Treiber Metadaten für alle Datenbanken und Schemas im Konto ab.- Standard:
FALSE- Zusätzliche Anmerkungen:
Der Verbindungskontext bezieht sich auf die aktuelle Datenbank und das aktuelle Schema der Sitzung, die mit einer der folgenden Optionen festgelegt werden kann:
Geben Sie den Standard-Namespace für den Benutzer an, der eine Verbindung zu Snowflake herstellt (und die Sitzung initiiert). Dies kann für den Benutzer über den Befehl CREATE USER oder ALTER USER festgelegt werden, muss aber vor dem Verbinden eingestellt werden.
Geben Sie die Datenbank und das Schema an, wenn Sie über den Treiber eine Verbindung zu Snowflake herstellen.
Führen Sie innerhalb der Sitzung einen USE DATABASE- oder USE SCHEMA-Befehl aus.
Wenn bei der Angabe von Datenbank oder Schema nicht nur eine dieser Optionen verwendet wurde, gilt die zuletzt verwendete Option.
Wenn CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX auf
TRUEgesetzt ist:Datenbankargument
Schemaargument
Verwendete Datenbank
Verwendetes Schema
Ungleich NULL
Ungleich NULL
Argument
Argument
Ungleich NULL
NULL
Argument
Alle Schemas
NULL
Ungleich NULL
Verbindungssyntax
Argument
NULL
NULL
Verbindungssyntax
Sitzungskontext
Bemerkung
Für den JDBC-Treiber gilt dieses Verhalten für Version 3.6.27 (und höher). Für den ODBC-Treiber gilt dieses Verhalten für Version 2.12.96 (und höher).
Wenn Sie nur die Verbindungskontextdatenbank durchsuchen möchten, aber alle Schemas in dieser Datenbank, dann finden Sie weitere Informationen unter CLIENT_METADATA_USE_SESSION_DATABASE.
CLIENT_METADATA_USE_SESSION_DATABASE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Clients:
JDBC
- Beschreibung:
Dieser Parameter gilt nur für die von CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX betroffenen Methoden.
Dieser Parameter gilt nur, wenn beide der folgenden Bedingungen erfüllt sind:
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX ist auf
FALSEoder nicht gesetzt.Weder Datenbank noch Schema werden an die entsprechende ODBC-Funktion oder JDBC-Methode übergeben.
Für bestimmte ODBC-Funktionen und JDBC-Methoden kann dieser Parameter den Standardsuchbereich aller Datenbanken der aktuellen Datenbank ändern. Bei einer eingegrenzten Suche werden normalerweise weniger Zeilen zurückgegeben und die Suche wird schneller ausgeführt.
Weitere Details dazu finden Sie weiter unten.
- Werte:
TRUE:Der Treiber durchsucht alle Schemas in der Datenbank des Verbindungskontexts. (Weitere Informationen zum Verbindungskontext finden Sie in der Dokumentation zu CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.)
FALSE:Der Treiber durchsucht alle Schemas in allen Datenbanken.
- Standard:
FALSE- Zusätzliche Anmerkungen:
Wenn die Datenbank null und das Schema null und CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX FALSE ist:
CLIENT_METADATA_USE_SESSION_DATABASE
Verhalten
FALSE
Es werden alle Schemas in allen Datenbanken durchsucht.
TRUE
Es werden alle Schemas der aktuellen Datenbank durchsucht.
CLIENT_PREFETCH_THREADS¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Clients:
JDBC, ODBC, Python, .NET
- Beschreibung:
Parameter, der die Anzahl der Threads angibt, die vom Client vorab zum Abrufen großer Resultsets verwendet werden. Der Treiber versucht, den Parameterwert einzuhalten, definiert jedoch Mindest- und Höchstwerte (abhängig von den Ressourcen Ihres Systems), um die Leistung zu verbessern.
- Werte:
1bis10- Standard:
4Die meisten Benutzer sollten diesen Parameter nicht einstellen müssen. Wenn dieser Parameter nicht vom Benutzer festgelegt wird, beginnt der Treiber mit der oben angegebenen Standardeinstellung, verwaltet jedoch aktiv die Thread-Anzahl konservativ, um zu vermeiden, dass der gesamte verfügbare Speicher belegt wird.
CLIENT_RESULT_CHUNK_SIZE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Clients:
JDBC, Node.js, SQL API, Go
- Beschreibung:
Parameter, der die maximale Größe jedes Sets (oder Blocks) der herunterzuladenden Abfrageergebnisse (in MB) angibt. Der JDBC-Treiber lädt Abfrageergebnisse in Blöcken herunter.
Siehe auch CLIENT_MEMORY_LIMIT.
- Werte:
16bis160- Standard:
160Die meisten Benutzer sollten diesen Parameter nicht einstellen müssen. Wenn dieser Parameter nicht vom Benutzer festgelegt wird, beginnt der Treiber mit der oben angegebenen Standardeinstellung, verwaltet seinen Speicher jedoch aktiv und konservativ, um zu vermeiden, dass der gesamte verfügbare Speicher belegt wird.
CLIENT_RESULT_COLUMN_CASE_INSENSITIVE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Clients:
JDBC
- Beschreibung:
Parameter, der angibt, ob bei
ResultSet.get*-Methoden in JDBC bei einem Vergleich der Spaltennamen die Groß-/Kleinschreibung berücksichtigt werden soll.- Werte:
TRUE: Vergleicht Spaltennamen ohne Berücksichtigung der Groß-/Kleinschreibung.FALSE: Vergleicht Spaltennamen unter Berücksichtigung der Groß-/Kleinschreibung.- Standard:
FALSE
CLIENT_SESSION_KEEP_ALIVE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Clients:
.NET, Golang, JDBC, Node.js, ODBC, Python,
- Beschreibung:
Parameter, der angibt, ob sich ein Benutzer nach einem Zeitraum der Inaktivität in einer Sitzung erneut anmelden muss.
- Werte:
TRUE: Snowflake hält die Sitzung unbegrenzt aktiv, solange die Verbindung aktiv ist, auch wenn der Benutzer inaktiv ist.FALSE: Nach vier Stunden Inaktivität muss sich der Benutzer erneut anmelden.- Standard:
FALSE
Bemerkung
Derzeit ist der Parameter nur bei der Initiierung der Sitzung wirksam. Sie können den Parameterwert innerhalb der Sitzungsebene ändern, indem Sie den Befehl ALTER SESSION ausführen. Dies hat jedoch keinen Einfluss auf die Funktion zur Aufrechterhaltung der Sitzung, wie z. B. die Verlängerung der Sitzung. Informationen zum Festlegen des Parameters auf Sitzungsebene finden Sie in der jeweiligen Clientdokumentation:
CLIENT_SESSION_KEEP_ALIVE_HEARTBEAT_FREQUENCY¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Clients:
SnowSQL, JDBC, Python, Node.js
- Beschreibung:
Anzahl der Sekunden zwischen den Versuchen des Clients, das Token für die Sitzung zu aktualisieren.
- Werte:
900bis3600- Standard:
3600
CLIENT_TIMESTAMP_TYPE_MAPPING¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Clients:
Beliebig
- Beschreibung:
Gibt die Variation TIMESTAMP_* an, die beim Binden von Zeitstempelvariablen für JDBC- oder ODBC-Anwendungen verwendet werden soll, welche zum Laden von Daten die Bind-API verwenden.
- Werte:
TIMESTAMP_LTZoderTIMESTAMP_NTZ- Standard:
TIMESTAMP_LTZ
CORTEX_MODELS_ALLOWLIST¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt die Modelle fest, auf die die Benutzer des Kontos zugreifen können. Verwenden Sie diesen Parameter, um Modelle für alle Benutzer des Kontos zuzulassen. Wenn Sie bestimmten Benutzern einen Zugriff gewähren müssen, der über das hinausgeht, was Sie in der Zulassungsliste angegeben haben, verwenden Sie stattdessen eine rollenbasierte Zugriffssteuerung. Weitere Informationen dazu finden Sie unter Parameter für die Zulassungsliste auf Kontoebene.
Wenn Benutzer eine Anfrage stellen, wertet Snowflake Cortex den Parameter aus, um festzustellen, ob der Benutzer auf das Modell zugreifen kann.
- Werte:
'All': Ermöglicht den Zugriff auf alle Modelle, einschließlich der Fine-Tuning-Modelle.Beispiel:
'model1,model2,...': Ermöglicht den Zugriff auf die in einer durch Kommas getrennten Liste angegebenen Modelle.Beispiel:
'None': Verhindert den Zugriff auf ein beliebiges Modell.Beispiel:
- Standard:
'All'
CORTEX_ENABLED_CROSS_REGION¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Regionen an, in denen eine Anfrage bearbeitet werden kann, falls die Anfrage nicht in der Region bearbeitet werden kann, in der die Anfrage ursprünglich platziert wurde. Die Angabe von
DISABLEDdeaktiviert das regionsübergreifende Inferencing. Beispiele und Details finden Sie unter Regionenübergreifende Inferenz.- Werte:
Dieser Parameter kann auf einen der folgenden Werte festgelegt werden:
DISABLEDANY_REGIONDurch Kommas getrennte Liste, die einen oder mehrere der folgenden Werte enthält:
AWS_APJAWS_AUAWS_EUAWS_USAWS_GLOBALAZURE_EUAZURE_USAZURE_GLOBALGCP_USGCP_GLOBAL
Erläuterung der einzelnen Parameterwerte¶ Wert
Verhalten
DISABLEDInferenzanfragen werden verarbeitet in:
Die Region, in der die Anfrage gestellt wird.
ANY_REGIONInferenzanfragen können weitergeleitet werden an:
Jede Region, die regionsübergreifende Ableitung unterstützt (in dieser Tabelle aufgeführt) und über die entsprechende Verfügbarkeit verfügt, einschließlich der Region, in der die Anfrage gestellt wird.
AWS_APJAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden AWS-Regionen
AWS Asien-Pazifik (Tokio) ap-northeast-1
AWS Asien-Pazifik (Seoul) ap-northeast-2
AWS Asien-Pazifik (Osama) ap-northeast-3
AWS Asien-Pazifik (Mumbai) ap-south-1
AWS Asien-Pazifik (Hyderabad) ap-south-2
AWS Asien-Pazifik (Singapur) ap-southeast-1
AWS Asien-Pazifik (Sydney) ap-southeast-2
AWS Asien-Pazifik (Melbourne) ap-southeast-4
AWS_AUAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden AWS-Regionen
AWS Asien-Pazifik (Sydney) ap-southeast-2
AWS Asien-Pazifik (Melbourne) ap-southeast-4
AWS_EUAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden AWS-Regionen, die sich innerhalb der Europäischen Union befinden (und befinden werden):
AWS Europa (Frankfurt) eu-central-1
AWS Europa (London) eu-north-1
AWS Europa (Mailand) eu-south-1
AWS Europa (Spanien) eu-south-2
AWS Europa (Irland) eu-west-1
AWS Europa (Paris) eu-west-3
AWS_USAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden AWS-Regionen, die sich innerhalb der Vereinigten Staaten befinden (und befinden werden):
AWS US East (N. Virginia) us-east-1
AWS US East (Ohio) us-east-2
AWS US West (Oregon) us-west-2
AWS_GlobalAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in einer beliebigen kommerziellen AWS-Region.
AZURE_EUAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden Azure-Regionen, die sich innerhalb der Europäischen Union befinden (und befinden werden):
Azure Europa (Niederlande) westeurope
Azure Europa (Frankreich) francecentral
Azure Europa (Deutschland) germanywestcentral
Azure Europa (Italien) italynorth
Azure Europa (Polen) polandcentral
Azure Europa (Spanien) spaincentral
Azure Europa (Schweden) swedencentral
AZURE_USAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden Azure-Regionen, die sich innerhalb der Vereinigten Staaten befinden (und befinden werden):
Azure US (Virginia) eastus2
Azure US (Virginia) eastus
Azure US (Kalifornien) westus
Azure US (Phoenix) westus3
Azure US (Illinois) northcentralus
Azure US (Texas) Southcentralus
AZURE_GlobalAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in einer beliebigen kommerziellen Azure-Region.
GCP_USAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in den folgenden GCP-Regionen, die sich innerhalb der Vereinigten Staaten befinden (und befinden werden):
GCP US (Iowa) us-central1
GCP US (Oregon) us-west1
GCP US (Las Vegas) us-west4
GCP US (N. Virginia) us-east4
GCP_GlobalAbleitungsanfragen werden in der Region verarbeitet, in der die Anfrage gestellt wird, und in einer beliebigen kommerziellen GCP-Region.
- Standard:
Der Standardwert hängt davon ab, wann und wo das Konto erstellt wurde:
ANY_REGIONfür neue Konten in neuen Organisationen in kommerziellen Regionen, die nach dem 9. März 2026 erstellt wurden.DISABLEDfür alle anderen Konten, einschließlich Regionen für Regierungsbehörden.
CSV_TIMESTAMP_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Format für TIMESTAMP-Werte in CSV-Dateien an, die über die Snowsight heruntergeladen wurden.
Wenn dieser Parameter nicht gesetzt ist, wird TIMESTAMP_LTZ_OUTPUT_FORMAT für TIMESTAMP_LTZ Werte, TIMESTAMP_TZ_OUTPUT_FORMAT für TIMESTAMP_TZ und TIMESTAMP_NTZ_OUTPUT_FORMAT für TIMESTAMP_NTZ Werte verwendet.
Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit oder Abfrageergebnisse herunterladen.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat
- Standard:
Kein Wert.
DATA_METRIC_SCHEDULE¶
- Typ:
Objekt (für Tabellen)
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Zeitplan für die Ausführung der mit der Tabelle verbundenen Datenmetrikfunktionen an.
- Werte:
Der Zeitplan kann auf einer bestimmten Anzahl von Minuten, einem Cron-Ausdruck oder einem DML-Ereignis in der Tabelle basieren, das kein Reclustering beinhaltet. Weitere Details dazu finden Sie unter:
- Standard:
60 MINUTE
DATA_RETENTION_TIME_IN_DAYS¶
- Typ:
Objekt (für Datenbanken, Schemas und Tabellen) – Kann festgelegt werden für Konto » Datenbank » Schema » Tabelle
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Anzahl der Tage, für die Snowflake historische Daten zu einem Objekt zur Durchführung von Time Travel-Aktionen (SELECT, CLONE, UNDROP) speichert. Der Wert
0deaktiviert Time Travel für die angegebene Datenbank, das angegebene Schema oder die angegebene Tabelle. Weitere Informationen dazu finden Sie unter Verstehen und Verwenden von Time Travel.- Werte:
0oder1(für Standard Edition)0bis90(für Enterprise Edition oder höher)- Standard:
1
DATE_INPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Eingabeformat für den Datentyp DATE an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Datumsformat oder
AUTO(
AUTOgibt an, dass Snowflake versucht, das Format der im System gespeicherten Daten während der Sitzung automatisch zu ermitteln.)- Standard:
AUTO
DATE_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentyp DATE an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Datumsformat
- Standard:
YYYY-MM-DD
DEFAULT_DBT_VERSION¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Specifies the default version for all future dbt project objects created in an account. Setting this value on the account enables organization administrators to opt-in to newer versions (for example, changing the default to
1.10.15) without requiring users to manually update CREATE DBT PROJECT DDL statements for every individual project. For more information, see Standardversion auf Kontoebene festlegen.- Werte:
1.9.4oder1.10.15- Standard:
1.9.4
DEFAULT_DDL_COLLATION¶
- Typ:
Objekt (für Datenbanken, Schemas und Tabellen) – Kann festgelegt werden für Konto » Datenbank » Schema » Tabelle
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt die Standardsortierung für die folgenden DDL-Operationen fest:
ALTER TABLE … ADD COLUMN
Wenn Sie diesen Parameter festlegen, wird für alle nachfolgend erstellten Spalten in den betroffenen Objekten (Tabelle, Schema, Datenbank oder Konto) die angegebene Sortierung als Standardsortierung festgelegt, sofern die Sortierung für die Spalte nicht ausdrücklich in der DDL angegeben ist.
Wenn beispielsweise
DEFAULT_DDL_COLLATION = 'en-ci'ist, sind die folgenden beiden Anweisungen äquivalent:Bemerkung
Dieser Parameter wird nicht für dynamische Tabellen und Apache Iceberg™-Tabellen unterstützt. Dieser Parameter wird bei indizierten Spalten für Hybridtabellen nicht unterstützt.
- Werte:
Jede gültige, unterstützte Sortierungsspezifikation.
- Standard:
Leere Zeichenfolge
Bemerkung
Verwenden Sie die folgenden Befehle, um die Standardsortierung für das Konto festzulegen:
Die Standardsortierung für Tabellenspalten kann während der Erstellung oder zu einem späteren Zeitpunkt auf Tabellen-, Schema- oder Datenbankebene festgelegt werden:
CREATE TABLE oder ALTER TABLE
DEFAULT_NOTEBOOK_COMPUTE_POOL_CPU¶
- Typ:
Objekt (für Datenbanken und Schemas) – Kann festgelegt werden für Konto » Datenbank » Schema
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt den bevorzugten CPU-Computepool fest, der für Notebooks auf CPU Container Runtime verwendet wird.
- Werte:
Name eines Computepools in Ihrem Konto.
- Standard:
SYSTEM_COMPUTE_POOL_CPU (siehe System-Computepools).
DEFAULT_NOTEBOOK_COMPUTE_POOL_GPU¶
- Typ:
Objekt (für Datenbanken und Schemas) – Kann festgelegt werden für Konto » Datenbank » Schema
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt den bevorzugten GPU-Computepool fest, der für Notebooks auf GPU Container Runtime verwendet wird.
- Werte:
Name eines Computepools in Ihrem Konto.
- Standard:
SYSTEM_COMPUTE_POOL_GPU (siehe System-Computepools).
DEFAULT_NULL_ORDERING¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt die Standardreihenfolge der NULL-Werte in einem Resultset fest.
Die Reihenfolge der NULL-Werte in den Zeilen hängt von der ORDER BY-Klausel ab:
Wenn die Sortierreihenfolge ASC ist (Standardeinstellung) und dieser Parameter auf
LASTgesetzt ist (Standardeinstellung), werden NULL-Werte zuletzt zurückgegeben. Sofern nicht anders angegeben, gelten daher die NULL-Werte als höher als alle Nicht-NULL-Werte.Wenn die Sortierreihenfolge ASC ist und dieser Parameter auf
FIRSTgesetzt ist, werden NULL-Werte zuerst zurückgegeben.Wenn die Sortierreihenfolge DESC ist und dieser Parameter auf
FIRSTgesetzt ist, werden NULL-Werte zuletzt zurückgegeben.Wenn die Sortierreihenfolge DESC ist und dieser Parameter auf
LASTgesetzt ist, werden NULL-Werte zuerst zurückgegeben.
Wenn in der Klausel ORDER BY mit NULLS FIRST oder NULLS LAST eine NULL-Reihenfolge angegeben wird, dann hat die angegebene Reihenfolge Vorrang vor jedem Wert von DEFAULT_NULL_ORDERING.
- Werte:
FIRST: NULL-Werte sind niedriger als Nicht-NULL-Werte.LAST: NULL-Werte sind höher als Nicht-NULL-Werte.- Standard:
LAST
DEFAULT_STREAMLIT_COMPUTE_POOL¶
- Typ:
Objekt – Kann nur für Konto eingestellt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Standard-Computepool an, der für Streamlit-Apps der Container-Laufzeit verwendet werden soll.
Wenn Sie beim Ausführen von CREATESTREAMLIT eine Container-Laufzeit in der Eigenschaft RUNTIME_NAME angeben und nicht die Eigenschaft COMPUTE_POOL festlegen, verwendet Snowflake den im Parameter DEFAULT_STREAMLIT_COMPUTE_POOL angegebenen Computepool. Dieser Standard-Computepool wird zum Zeitpunkt der Erstellung aufgelöst. Durch die Aktualisierung vonDEFAULT_STREAMLIT_COMPUTE_POOL wird die Eigenschaft COMPUTE_POOL für bestehende Streamlit-Apps nicht aktualisiert. Weitere Informationen dazu finden Sie unter Konfigurieren Ihrer eigenen bevorzugten Computepools für Streamlit-Apps.
- Werte:
Name eines Computepools in Ihrem Konto.
- Standard:
SYSTEM_COMPUTE_POOL_CPU
DEFAULT_STREAMLIT_NOTEBOOK_WAREHOUSE¶
- Typ:
Objekt (für Datenbanken und Schemas) – Kann festgelegt werden für Konto » Datenbank » Schema
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Namen des Standard-Warehouse an, das bei der Erstellung eines Notebook verwendet werden soll.
Weitere Informationen dazu finden Sie unter ALTER ACCOUNT, ALTER DATABASE und ALTER SCHEMA.
- Werte:
Der Name eines vorhandenen Warehouse.
- Standard:
SYSTEM$STREAMLIT_NOTEBOOK_WH
DISABLE_USER_PRIVILEGE_GRANTS¶
- Typ:
Objekt (für Benutzer) — Kann nur für Konto eingestellt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob Benutzer eines Kontos anderen Benutzern direkt Berechtigungen erteilen können.
Das Deaktivieren von Benutzerberechtigungen (d. h. das Einstellen von DISABLE_USER_PRIVILEGE_GRANTS auf
TRUE) hat keine Auswirkungen auf bestehende Zuweisungen für Benutzende. Bestehende Benutzerberechtigungen gewähren diesen Benutzenden weiterhin die entsprechenden Privilegien. Weitere Informationen dazu finden Sie unter GRANT <Berechtigungen> … TO USER.- Werte:
TRUE: Die Benutzer des Kontos können einem anderen Benutzer keine Berechtigungen erteilen.FALSE: Die Benutzer des Kontos können einem anderen Benutzer Berechtigungen erteilen.- Standard:
FALSE
DISALLOWED_SPCS_WORKLOAD_TYPES¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Workload-Typen an, die in Ihrem Konto nicht in Snowpark Container Services bereitgestellt werden dürfen. Siehe auch ALLOWED_SPCS_WORKLOAD_TYPES.
- Werte:
Der Wert ist eine durch Kommas getrennte Liste der folgenden unterstützten Workload-Typen:
USER: Alle Workloads, die direkt von Benutzenden bereitgestellt werden.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit in Snowflake.MODEL_SERVING: ML Model Serving.ML_JOB: Snowflake ML-Jobs.ALL: Alle Workloads.
- Standard:
Leere Zeichenfolge
Bemerkung
Wenn Sie die Parameter DISALLOWED_SPCS_WORKLOAD_TYPES und ALLOWED_SPCS_WORKLOAD_TYPES konfigurieren, wendet Snowflake zuerst DISALLOWED_SPCS_WORKLOAD_TYPES an. Wenn Sie beispielsweise beide Parameter konfigurieren und die Workload NOTEBOOK angeben, dürfen NOTEBOOK-Workloads nicht auf Snowpark Container Services ausgeführt werden.
ENABLE_AUTOMATIC_SENSITIVE_DATA_CLASSIFICATION_LOG¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob Ereignisse von Klassifizierung sensibler Daten in der Ereignistabelle des Benutzers protokolliert werden.
- Werte:
TRUE: Snowflake protokolliert Ereignisse zur Klassifizierung sensibler Daten in der Ereignistabelle des Benutzers.FALSE: Ereignisse zur Klassifizierung sensibler Daten werden nicht protokolliert.- Standard:
TRUE
ENABLE_BUDGET_EVENT_LOGGING¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob Telemetriedaten für die Budgets gesammelt werden.
- Werte:
TRUE: Snowflake protokolliert Telemetriedaten für Budgets in einer Ereignistabelle.FALSE: Snowflake protokolliert keine Telemetriedaten für Budgets.- Standard:
TRUE
ENABLE_DATA_COMPACTION¶
- Typ:
Objekt (für Datenbanken, Schemas und Iceberg-Tabellen) – Kann festgelegt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Snowflake die Datenkomprimierung auf von Snowflake verwalteten Apache Iceberg™-Tabellen aktivieren soll.
- Werte:
TRUE: Snowflake führt die Datenkomprimierung für die Tabellen aus.FALSE: Snowflake führt keine Datenkomprimierung für die Tabellen durch.- Standard:
TRUE
ENABLE_EGRESS_COST_OPTIMIZER¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Aktiviert oder deaktiviert den Egress Cost Optimizer im Rahmen der Cloud-übergreifenden automatischen Ausführung für das Freigabeangebot.
- Werte:
TRUE: Aktivieren Sie den Egress Cost Optimizer.FALSE: Deaktivieren Sie den Egress Cost Optimizer.- Standard:
FALSE
Weitere Informationen dazu finden Sie unter Automatische Ausführung für Freigabeangebote.
ENABLE_GET_DDL_USE_DATA_TYPE_ALIAS¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die von der GET_DDL-Funktion zurückgegebene Ausgabe Datentypsynonyme enthält, die in der ursprünglichen DDL-Anweisung angegeben sind. Datentyp-Synonyme werden auch Datentyp-Aliasse genannt.
- Werte:
TRUE: Zeigen Sie die in der ursprünglichenDDL-Anweisung angegebenen Datentyp-Aliasse an.FALSE: Ersetzen Sie die in der ursprünglichen DDL-Anweisung angegebenen Datentyp-Aliasse mit Standard-Snowflake-Datentypnamen.
Sie können diesen Parameter auf TRUE einstellen, um DDL-Anweisungen unter Verwendung der GET_DDL-Funktion zu generieren, die Datentyp-Aliasse wie in den ursprünglichen SQL-Anweisungen definiert angeben, die erforderlich sein können, um die Integrität des Datenmodells während der Migration zu wahren.
Im Folgenden finden Sie Beispiele für Datentyp-Aliasse:
CHAR ist ein Alias für den VARCHAR-Datentyp.
BIGINT ist ein Alias für den NUMBER-Datentyp.
DATETIME ist ein Alias für den TIMESTAMP_NTZ-Datentyp.
Die folgende Anweisung erstellt eine Tabelle unter Verwendung der Aliasse für die Datentypen:
Wenn dieser Parameter auf FALSE eingestellt ist, gibt die GET_DDL-Funktion die folgende Ausgabe zurück:
Wenn dieser Parameter auf TRUE eingestellt ist, gibt die GET_DDL-Funktion die folgende Ausgabe zurück:
- Standard:
FALSE
ENABLE_ICEBERG_MERGE_ON_READ¶
- Typ:
Objekt (für Datenbanken, Schemas und Apache Iceberg™-Tabellen) — Kann eingestellt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob das Merge-on-Read-Verhalten für von Snowflake verwaltete Apache Iceberg™-Tabellen-Tabellen aktiviert werden soll. Weitere Informationen dazu finden Sie unter Löschungen auf Zeilenebene verwenden.
- Werte:
TRUE: Aktivieren des Merge-on-Read-Verhaltens:Wenn Sie das Iceberg v2-Format mit Iceberg-Tabellen verwenden, können Zeilenlöschungen mithilfe von positionsbezogene Löschdateien durchgeführt werden.
Wenn Sie das Iceberg v3 -Format mit Iceberg-Tabellen verwenden, können Zeilenlöschungen mithilfe von Löschvektoren durchgeführt werden.
Weitere Informationen zum Merge-on-Read- and Copy-on-Write-Verhalten finden Sie unter Löschungen auf Zeilenebene verwenden.
Bemerkung
Um die Iceberg-Version für Tabellen anzugeben, verwenden Sie den Parameter ICEBERG_VERSION_DEFAULT oder den Parameter ICEBERG_VERSION.
FALSE: Aktiviert das Copy-on-Write-Verhalten fürDML-Vorgänge.- Standard:
TRUE
ENABLE_IDENTIFIER_FIRST_LOGIN¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Bestimmt den Anmeldeablauf für Benutzer. Wenn diese Option aktiviert ist, fordert Snowflake die Benutzer zur Eingabe ihres Benutzernamens oder ihrer E-Mail-Adresse auf, bevor die Authentifizierungsmethoden angezeigt werden. Weitere Details dazu finden Sie unter ID-First-Anmeldung.
- Werte:
TRUE: Snowflake verwendet für die Authentifizierung der Benutzer einen ID-First-Anmeldeablauf.FALSE: Snowflake zeigt alle möglichen Anmeldeoptionen an, auch wenn diese Optionen nicht für einen bestimmten Benutzer zutreffen.- Standard:
FALSE
ENABLE_INTERNAL_STAGES_PRIVATELINK¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die Funktion SYSTEM$GET_PRIVATELINK_CONFIG den Schlüssel
private-internal-stagesim Abfrageergebnis zurückgibt. Der entsprechende Wert im Abfrageergebnis wird während des Konfigurationsvorgangs für private Konnektivität zu internen Stagingbereichen verwendet. Der Wert dieses Parameters beeinflusst auch das Verhalten von Systemfunktionen im Zusammenhang mit der privaten Konnektivität. Beispiel:TRUEaktiviert SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS und ``FALSE``deaktiviert SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS.- Werte:
TRUE: Gibt den Schlüsselprivate-internal-stagesund den Wert im Abfrageergebnis zurück.FALSE: Gibt den Schlüsselprivate-internal-stagesund den Wert im Abfrageergebnis nicht zurück.- Standard:
FALSE
ENABLE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die SYSTEM$GET_PRIVATELINK_CONFIG-Funktion die Schlüssel
privatelink-snowflake-managed-storage-volume-nfsund``privatelink-snowflake-managed-storage-volume-fs`` im Abfrageergebnis zu Azure-Bereitstellungen zurückgibt. Die entsprechenden Werte im Abfrageergebnis werden verwendet, wenn die private Konnektivität zu von Snowflake verwalteten Speichervolumes konfiguriert wird. Der Wert dieses Parameters beeinflusst auch das Verhalten von Systemfunktionen im Zusammenhang mit privater Konnektivität. Beispiel:TRUEaktiviert SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS undFALSEdeaktiviert SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS.- Werte:
TRUE: Gibt die Schlüsselprivatelink-snowflake-managed-storage-volume-nfsund``privatelink-snowflake-managed-storage-volume-fs`` und Werte im Abfrageergebnis für Azure-Bereitstellungen zurück.FALSE: Gibt diese Schlüssel und Werte im Abfrageergebnis nicht zurück.- Standard:
FALSE
ENABLE_NOTEBOOK_CREATION_IN_PERSONAL_DB¶
- Typ:
Benutzer – Kann für Konto > Benutzer festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Benutzer (in ihren persönlichen Datenbanken gespeicherte) private Notebooks erstellen können. Wenn TRUE, können Benutzer im Konto private Notebooks erstellen (vorausgesetzt, es werden andere erforderliche Berechtigungen erteilt).
- Werte:
TRUE: Ermöglicht Benutzern das Erstellen privater Notebooks.FALSE: Verhindert, dass Benutzer private Notebooks erstellen.- Standard:
FALSE
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Ermöglicht die Durchsetzung des SNOWFLAKE_FULL-Verschlüsselungstyps für Blockspeicher-Volumes und Snapshots von Snowpark Container Services.
- Werte:
TRUE: Erzwingt die Erstellung von SPCS -Blockspeicher-Volumes und Snapshots ausschließlich mit dem SNOWFLAKE_FULL-Verschlüsselungstyp. Der SNOWFLAKE_SSE-Verschlüsselungstyp ist nicht zulässig. Alle vorhandenen Blockspeicher-Volumes und Snapshots mit dem SNOWFLAKE_SSE-Verschlüsselungstyp müssen auf SNOWFLAKE_FULL migriert werden, bevor Sie diesen Parameter aktivieren. Das Einstellen des Werts des Parameters auf TRUE bei mit SNOWFLAKE_FULL verschlüsselten bestehenden Volumes oder Snapshots führt zu einem Fehler.FALSE: Sowohl der SNOWFLAKE_SSE- als auch der SNOWFLAKE_FULL-Verschlüsselungstyp sind für SPCS-Blockspeicher-Volumes und Snapshots im Konto zulässig.- Standard:
FALSE
ENABLE_TAG_PROPAGATION_EVENT_LOGGING¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob Telemetriedaten für die automatische Tag-Weitergabe gesammelt werden.
- Werte:
TRUE: Snowflake protokolliert Telemetriedaten im Zusammenhang mit der Tag-Weitergabe an eine Ereignistabelle.FALSE: Snowflake protokolliert keine Telemetriedaten im Zusammenhang mit der Tag-Weitergabe.- Standard:
FALSE
ENABLE_TRI_SECRET_AND_REKEY_OPT_OUT_FOR_IMAGE_REPOSITORY¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt die Wahl für das Image-Repository an, sich gegen Tri-Secret Secure und Periodische Wiederverschlüsselung zu entscheiden.
- Werte:
TRUE: Image-Repository verwendet kein Tri-Secret Secure und keine periodische Wiederverschlüsselung (Periodic Rekeying).FALSE: Verhindert das Erstellen eines Image-Repository für Tri-Secret Secure und die periodische Wiederverschlüsselung für Konten. Ebenso wird das Aktivieren von Tri-Secret Secure und periodischer Wiederverschlüsselung für Konten, bei denen das Image-Repository aktiviert ist, unterbunden.- Standard:
FALSE
ENABLE_UNHANDLED_EXCEPTIONS_REPORTING¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Snowflake in einer Ereignistabelle Protokollmeldungen oder Ablaufverfolgungsereignisse für unbehandelte Ausnahmen mit Prozedur- oder UDF-Handler-Code erfassen darf. Weitere Informationen dazu finden Sie unter Erfassen von Meldungen aus unbehandelten Ausnahmen.
- Werte:
TRUE: Daten zu unbehandelten Ausnahmen werden als Protokoll- oder Ablaufverfolgungsdaten erfasst, wenn Protokollierung und Ablaufverfolgung aktiviert sind.FALSE: Daten zu nicht behandelte Ausnahmen werden nicht erfasst.- Standard:
TRUE
ENABLE_UNLOAD_PHYSICAL_TYPE_OPTIMIZATION¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob das Schema für entladene Parquet-Dateien basierend auf den Datentypen der logischen Spalte (d. h. den Typen in der SQL-Entladeabfrage oder der Quelltabelle) oder den entladenen Spaltenwerten (d. h. die kleinsten Datentypen und Genauigkeiten, die die Werte in den Ausgabespalten der SQL-Entladeanweisung oder der Quelltabelle unterstützen) festgelegt werden soll.
- Werte:
TRUE: Das Schema für entladene Parquet-Datendateien wird durch die Spaltenwerte in der SQL-Entladeabfrage oder der Quelltabelle bestimmt. Snowflake optimiert Tabellenspalten, indem die kleinste Genauigkeit festgelegt wird, die alle Werte akzeptiert. Der Entlader folgt diesem Muster, wenn Werte in Parquet-Dateien geschrieben werden. Der Datentyp und die Genauigkeit einer Ausgabespalte werden auf den kleinsten Datentyp und die kleinste Genauigkeit festgelegt, die ihre Werte in der unload-SQL-Anweisung oder in der Quelltabelle unterstützen. Akzeptieren Sie diese Einstellung, um die Leistung zu verbessern und kleinere Datendateien zu erhalten.FALSE: Das Schema wird durch die Datentypen der logischen Spalten bestimmt. Legen Sie diesen Wert für ein konsistentes Ausgabedateischema fest.- Standard:
TRUE
ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR¶
- Typ:
Benutzer – Kann für Konto » Benutzer festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob bei Fehlschlagen einer SQL-Abfrage aufgrund eines Syntax- oder Parsing-Fehlers Abfragetext ausgeblendet wird. Bei
FALSEwird der Inhalt einer fehlgeschlagenen Abfrage in den Ansichten, Seiten und Funktionen, die einen Abfrageverlauf bereitstellen, ausgeblendet.Nur Benutzer mit einer Rolle, der die Berechtigung AUDIT erteilt wurde oder die diese Berechtigung geerbt hat, können den Parameter ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR festlegen.
Wenn Sie den Befehl ALTER USER verwenden, um den Parameter für einen bestimmten Benutzer auf
TRUEzu setzen, ändern Sie den Benutzer, der den Abfragetext sehen soll, und nicht den Benutzer, der die Abfrage ausgeführt hat (falls es sich um verschiedene Benutzer handelt).- Werte:
TRUE: Deaktiviert das Ausblenden von Abfragetext bei Abfragen, die aufgrund eines Syntax- oder Parsing-Fehlers fehlschlagen.FALSE: Blendet bei Fehlschlagen einer Abfrage aufgrund eines Syntax- oder Parsing-Fehlers den Abfragetext in Ansichten, Seiten und Funktionen aus, die einen Abfrageverlauf bereitstellen.- Standard:
FALSE
ENABLE_UNREDACTED_SECURE_OBJECT_ERROR¶
- Typ:
Benutzer – Kann für Konto » Benutzer festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Steuert, ob Fehlermeldungen im Zusammenhang mit sicheren Objekten in den Metadaten geschwärzt werden. Weitere Informationen dazu finden Sie unter Sichere Objekte: Redigieren von Informationen in Fehlermeldungen.
Nur Benutzer mit einer Rolle, der die Berechtigung AUDIT erteilt wurde oder die diese Berechtigung geerbt hat, können den Parameter ENABLE_UNREDACTED_SECURE_OBJECT_ERROR festlegen.
Wenn Sie den Befehl ALTER USER verwenden, um den Parameter für einen bestimmten Benutzer auf
TRUEzu setzen, ändern Sie den Benutzer, der die geschwärzten Fehlermeldungen in den Metadaten sehen soll, nicht den Benutzer, der den Fehler verursacht hat.- Werte:
TRUE: Deaktiviert die Ausblendung von Fehlermeldungen in Bezug auf sichere Objekte in den Metadaten.FALSE: Blendet den Inhalt von Fehlermeldungen in Bezug auf sichere Objekte in den Metadaten aus.- Standard:
FALSE
ENFORCE_NETWORK_RULES_FOR_INTERNAL_STAGES¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob eine Netzwerkrichtlinie, die Netzwerkregeln verwendet, den Zugriff auf interne AWS-Stagingbereiche einschränken kann.
Dieser Parameter hat keine Auswirkungen auf Netzwerkrichtlinien, die keine Netzwerkregeln verwenden.
Dieser Parameter auf Kontoebene betrifft sowohl Netzwerkrichtlinien auf Konto- als auch auf Benutzerebene.
Einzelheiten zur Verwendung von Netzwerkrichtlinien und -regeln zur Beschränkung des Zugriffs auf interne AWS-Stagingbereich, einschließlich der Verwendung dieses Parameters, finden Sie unter Schutz der internen Stagingbereiche auf AWS.
- Werte:
TRUE: Erlaubt Netzwerkrichtlinien, die Zugriff auf interne AWS-Stagingbereiche durch Netzwerkregeln beschränken. Die Netzwerkregel muss auch den entsprechendenMODEundTYPEverwenden, um Zugriff auf interne Stagingbereiche zu beschränken.FALSE: Netzwerkrichtlinien beschränken niemals den Zugriff auf interne Stagingbereiche.- Standard:
FALSE
ENFORCE_NETWORK_RULES_FOR_SNOWFLAKE_MANAGED_STORAGE_VOLUME¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob eine Netzwerkrichtlinie, die Netzwerkregeln verwendet, den Zugriff auf von Snowflake verwaltete AWS-Speichervolumes einschränken kann.
Dieser Parameter hat keine Auswirkungen auf Netzwerkrichtlinien, die keine Netzwerkregeln verwenden.
Dieser Parameter auf Kontoebene betrifft nur Netzwerkrichtlinien auf Kontoebene.
Details zur Verwendung von Netzwerkrichtlinien und -regeln zur Beschränkung des Zugriffs auf von Snowflake verwaltete Speichervolumes finden Sie unter Schutz von Snowflake verwalteten Speichervolumes in AWS.
- Werte:
TRUE: Erlaubt Netzwerkrichtlinien, die Netzwerkregeln verwenden, um den Zugriff auf von Snowflake verwaltete Speichervolumes zu beschränken. Die Netzwerkregel muss auch den entsprechendenMODEundTYPEverwenden, um Zugriff auf das Volume zu beschränken.FALSE: Netzwerkrichtlinien beschränken niemals den Zugriff auf von Snowflake verwaltete Speichervolumes.- Standard:
FALSE
ERROR_ON_NONDETERMINISTIC_MERGE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob ein Fehler zurückgegeben werden soll, wenn der Befehl MERGE zum Aktualisieren oder Löschen einer Zielzeile verwendet wird, die mehrere Quellzeilen verknüpft, und das System nicht ermitteln kann, welche Aktion in der Zielzeile ausgeführt werden soll.
- Werte:
TRUE: Es wird ein Fehler zurückgegeben, der Werte aus einer der Zielzeilen enthält, die den Fehler verursacht haben.FALSE: Es wurde kein Fehler zurückgegeben, und die Zusammenführung wurde erfolgreich abgeschlossen. Die Ergebnisse der Zusammenführung sind jedoch nicht deterministisch.- Standard:
TRUE
ERROR_ON_NONDETERMINISTIC_UPDATE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob ein Fehler zurückgegeben werden soll, wenn der Befehl UPDATE zum Aktualisieren einer Zielzeile verwendet wird, die mehrere Quellzeilen verknüpft, und das System nicht bestimmen kann, welche Aktion in der Zielzeile ausgeführt werden soll.
- Werte:
TRUE: Es wird ein Fehler zurückgegeben, der Werte aus einer der Zielzeilen enthält, die den Fehler verursacht haben.FALSE: Es wurde kein Fehler zurückgegeben, und die Aktualisierung wurde abgeschlossen. Die Ergebnisse der Aktualisierung sind jedoch nicht deterministisch.- Standard:
FALSE
EVENT_TABLE¶
- Typ:
Objekt — Kann für Konto- »-Datenbank eingestellt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Namen der Ereignistabelle für die Protokollierung von Meldungen aus gespeicherten Prozeduren und UDFs an, die in dem Objekt enthalten sind, mit dem die Ereignistabelle verknüpft ist.
Die Verknüpfung einer Ereignistabelle mit einer Datenbank ist in Enterprise Edition oder höher verfügbar.
- Werte:
Jede vorhandene Ereignistabelle, die durch Ausführen des Befehls CREATE EVENT TABLE erstellt wurde.
- Standard:
Keine
EXTERNAL_OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Bestimmt, ob die ACCOUNTADMIN-, ORGADMIN-, GLOBALORGADMIN- und SECURITYADMIN-Rollen als Primärrolle verwendet werden können, wenn eine Snowflake-Sitzung auf Basis des Zugriffstokens vom External OAuth-Autorisierungsserver erstellt wird.
- Werte:
TRUE: Fügt die ACCOUNTADMIN-, ORGADMIN-, GLOBALORGADMIN- und SECURITYADMIN-Rollen derEXTERNAL_OAUTH_BLOCKED_ROLES_LIST-Eigenschaft der External OAuth-Sicherheitsintegration hinzu, was bedeutet, dass diese Rollen beim Erstellen einer Snowflake-Sitzung mit External OAuth-Authentifizierung nicht als Primärrolle verwendet werden können.FALSE: Entfernt ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN und SECURITYADMIN aus der Liste der gesperrten Rollen, die durch dieEXTERNAL_OAUTH_BLOCKED_ROLES_LIST-Eigenschaft der External-OAuth-Sicherheitsintegration definiert sind.- Standard:
TRUE
EXTERNAL_VOLUME¶
Objekt (für Datenbanken, Schemas und Apache Iceberg™-Tabellen) — Kann eingestellt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das externe Volume für Apache Iceberg™-Tabellen an. Weitere Informationen dazu finden Sie in der Dokumentation zu Iceberg-Tabellen.
- Werte:
Jeder gültige Bezeichner eines externen Volumes.
- Standard:
Keine
GEOGRAPHY_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Anzeigeformat für GEOGRAPHY-Werte.
Für EWKT und EWKB ist die SRID in der Ausgabe immer „4326“. Siehe Hinweis zur Verwendung von EWKT und EWKB.
- Werte:
GeoJSON,WKT,WKB,EWKToderEWKB- Standard:
GeoJSON
GEOMETRY_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Anzeigeformat für GEOMETRY-Werte.
- Werte:
GeoJSON,WKT,WKB,EWKToderEWKB- Standard:
GeoJSON
HYBRID_TABLE_LOCK_TIMEOUT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Anzahl der Sekunden, die gewartet werden soll, während versucht wird, Sperren auf Zeilenebene für eine Hybridtabelle zu erwerben, gewartet werden soll, bevor das Zeitlimit überschritten und die Anweisung abgebrochen wird.
- Werte:
0auf eine beliebige Ganzzahl (keine Beschränkung). Ein Wert von0deaktiviert das Warten auf Sperren (d. h. die Anweisung muss die Sperre sofort erhalten oder abbrechen). Dieser Wert gibt an, wie lange die Anweisung nach jedem Ausführungsversuch auf alle Sperren auf Zeilenebene wartet, die sie erwerben muss (standardmäßig 1 Stunde). Wenn die Anweisung nicht alle Sperren erwerben kann, kann sie erneut versucht werden, und es gilt dieselbe Wartezeit.- Standard:
3600(1 Stunde)
Siehe auch LOCK_TIMEOUT.
ICEBERG_VERSION¶
- Typ:
Objekt (für Apache Iceberg™-Tabellen) – kann nur für Apache Iceberg™-Tabellen festgelegt werden
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Gibt die Version der Apache Iceberg™-Spezifikation an, der die Tabelle entspricht. Wenn Sie den Parameter ICEBERG_VERSION_DEFAULT verwenden, um die Iceberg-Standardversion auf einer höheren Ebene anzugeben, überschreibt dieser Parameter den Standardwert. Sie können eine Iceberg-Version für von Snowflake verwaltete Iceberg-Tabellen und extern verwaltete Iceberg-Tabellen angeben, die Sie in einer katalogverknüpften Datenbank erstellen.
Vorsicht
Bevor Sie andere Engines verwenden, um die Formatversion einer Iceberg-Tabelle in den Tabelleneigenschaften auf Version 3 zu aktualisieren, stellen Sie sicher, dass die Tabelle nicht von Engines oder Anwendungen verwendet wird, die noch nicht Version 3 unterstützen. Das Herabstufen von Formatversionen wird in der Apache Iceberg-Spezifikation nicht unterstützt. Daher müssen alle Reader und Writer Version 3 unterstützen. Die Standardversion für Iceberg-Tabellen in Snowflake ist Version 2, die bei Bedarf auf Version 3 geändert werden kann. Die Verwendung von Snowflake zur Durchführung von In-Place-Versions-Upgrades wird derzeit nicht unterstützt.
Bemerkung
Sie können diesen Parameter festlegen, wenn Sie eine Iceberg-Tabelle unter Verwendung des Befehls CREATE ICEBERG TABLE (Snowflake als Iceberg-Katalog) oder des Befehls CREATE ICEBERG TABLE (Iceberg REST Katalog) erstellen. Sie können nicht den Befehl ALTERICEBERGTABLE verwenden, um diese Konfiguration für eine bestehende Tabelle zu ändern.
- Werte:
2: Die Tabelle entspricht der Iceberg-Version 2.3: Die Tabelle entspricht der Iceberg-Version 3.- Standard:
2
ICEBERG_VERSION_DEFAULT¶
- Typ:
Objekt (für Datenbanken und Schemas) – Kann festgelegt werden für Konto » Datenbank » Schema
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Gibt die Version der Apache Iceberg™-Spezifikation an, mit der neue von Snowflake verwaltete Iceberg-Tabellen konform sein sollen.
Vorsicht
Bevor Sie andere Engines verwenden, um die Formatversion einer Iceberg-Tabelle in den Tabelleneigenschaften auf Version 3 zu aktualisieren, stellen Sie sicher, dass die Tabelle nicht von Engines oder Anwendungen verwendet wird, die noch nicht Version 3 unterstützen. Das Herabstufen von Formatversionen wird in der Apache Iceberg-Spezifikation nicht unterstützt. Daher müssen alle Reader und Writer Version 3 unterstützen. Die Standardversion für Iceberg-Tabellen in Snowflake ist Version 2, die bei Bedarf auf Version 3 geändert werden kann. Die Verwendung von Snowflake zur Durchführung von In-Place-Versions-Upgrades wird derzeit nicht unterstützt.
Bemerkung
Um die Version für eine bestimmte Tabelle festzulegen, geben Sie stattdessen den Parameter ICEBERG_VERSION an. Siehe ICEBERG_VERSION.
- Werte:
2: Die Tabelle entspricht der Iceberg-Version 2.3: Die Tabelle entspricht der Iceberg-Version 3.- Standard:
2
INITIAL_REPLICATION_SIZE_LIMIT_IN_TB¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zahl.
- Beschreibung:
Legt die maximale, geschätzte Größenbeschränkung fest, die bei der erstmaligen Replikation einer Primärdatenbank in eine Sekundärdatenbank (in TB) angewendet wird. Setzen Sie diesen Parameter für jedes Konto, das eine sekundäre Datenbank speichert. Durch diese Größenbeschränkung wird verhindert, dass Konten versehentlich hohe Gebühren für Datenbankreplikationen verursachen.
Um die Größenbeschränkung aufzuheben, setzen Sie den Wert auf
0.0.Beachten Sie, dass für nachfolgende Aktualisierungen einer Sekundärdatenbank derzeit keine Standardgrößenbeschränkung gilt.
- Werte:
0.0und darüber mit einer Dezimalstellenzahl (scale) von mindestens 1 (z. B.20.5,32.25,33.333usw.).- Standard:
10.0
JDBC_ENABLE_PUT_GET¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Legt fest, ob die Befehle PUT und GET Zugriff auf lokale Dateisysteme erhalten sollen.
- Werte:
TRUE: JDBC aktiviert die Befehle PUT und GET.FALSE: JDBC deaktiviert die Befehle PUT und GET.- Standard:
TRUE
JDBC_TREAT_DECIMAL_AS_INT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, wie JDBC Spalten verarbeitet, die eine Dezimalstellenzahl von null (
0) haben.- Werte:
TRUE: JDBC verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als BIGINT.FALSE: JDBC verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als DECIMAL.- Standard:
TRUE
JDBC_TREAT_TIMESTAMP_NTZ_AS_UTC¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, wie JDBC TIMESTAMP_NTZ-Werte verarbeitet.
Wenn der JDBC-Treiber einen Wert des Typs TIMESTAMP_NTZ von Snowflake abruft, konvertiert der Treiber den Wert standardmäßig in die aufgewendete Zeit unter Verwendung der JVM-Zeitzone des Clients.
Benutzer, die bei der Konvertierung die Zeitzone UTC beibehalten möchten, können diesen Parameter auf
TRUEsetzen.Dieser Parameter gilt nur für den JDBC-Treiber.
- Werte:
TRUE: Der Treiber verwendet UTC, um den TIMESTAMP_NTZ-Wert als aufgewendete Zeit zu erhalten.FALSE: Der Treiber verwendet die aktuelle JVM-Zeitzone des Clients, um den TIMESTAMP_NTZ-Wert als aufgewendete Zeit zu erhalten.- Standard:
FALSE
JDBC_USE_SESSION_TIMEZONE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob der JDBC-Treiber für die Methoden
getDate(),getTime()undgetTimestamp()derResultSet-Klasse die Zeitzone der JVM oder die Zeitzone der Sitzung (angegeben durch den Parameter TIMEZONE) verwendet.- Werte:
TRUE: Der JDBC-Treiber verwendet die Zeitzone der Sitzung.FALSE: Der JDBC-Treiber verwendet die Zeitzone der JVM.- Standard:
TRUE
JSON_INDENT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Gibt die Anzahl der Leerzeichen an, um die jedes neue Element in der JSON-Ausgabe in der Sitzung eingerückt wird. Gibt außerdem an, ob nach jedem Element Zeilenumbrüche eingefügt werden sollen.
- Werte:
0bis16(Der Wert
0gibt eine kompakte Ausgabe zurück, indem alle Leerzeichen und Zeilenumbrüche aus der Ausgabe entfernt werden.)- Standard:
2
Bemerkung
Dieser Parameter wirkt sich nicht auf JSON-Ausgaben aus, die mit dem Befehl COPY INTO <Speicherort> aus einer Tabelle in eine Datei entladen werden. Der Befehl entlädt JSON-Daten immer im NDJSON-Format:
Jeder Datensatz aus der Tabelle wird durch ein Zeilenumbruchzeichen getrennt.
Kompakte Formatierung innerhalb jedes Datensatzes (d. h. keine Leerzeichen oder Zeilenumbrüche).
JS_TREAT_INTEGER_AS_BIGINT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, wie der Snowflake-Node.js-Treiber numerische Spalten mit einer Dezimalstellenzahl von null (
0) verarbeitet, z. B. INTEGER oder NUMBER(p, 0).- Werte:
TRUE: JavaScript verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als BIGINT.FALSE: JavaScript verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als NUMBER.- Standard:
FALSE
Bemerkung
Standardmäßig werden INTEGER-Spalten in Snowflake (einschließlich BIGINT, NUMBER(p, 0) usw.) in den JavaScript-Datentyp Zahl (Number) konvertiert. Die größten zulässigen Snowflake-Ganzzahlwerte sind jedoch größer als die größten zulässigen JavaScript-Zahlenwerte. Um Snowflake-INTEGER-Spalten in JavaScript Bigint zu konvertieren, in denen größere Werte als JavaScript Number gespeichert werden können, legen Sie den Sitzungsparameter JS_TREAT_INTEGER_AS_BIGINT fest.
Beispiele zur Verwendung dieses Parameters finden Sie unter Abrufen von Ganzzahl-Datentypen als Bigint.
LISTING_AUTO_FULFILLMENT_REPLICATION_REFRESH_SCHEDULE¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Legt das Zeitintervall fest, in dem die auf Anwendungspaketen basierenden Datenprodukte für andere Regionen aktualisiert werden.
- Werte:
num MINUTES:Ein Wert zwischen
1und11520. Muss die Einheit MINUTES enthalten.USING CRON expr time_zone:Gibt einen Cron-Ausdruck und eine Zeitzone für die Aktualisierung an. Unterstützt eine Teilmenge der Standardsyntax des Cron-Dienstprogramms.
Eine Liste der Zeitzonen finden Sie unter dem Wikipedia-Thema list of tz database time zones (Liste der Zeitzonen aus der Zeitzonen-Datenbank). Der Cron-Ausdruck besteht aus folgenden Feldern:
Folgende Sonderzeichen werden unterstützt:
*Platzhalter. Gibt jedes vorkommende Feld an.
LSteht für „last“ (letzte). Bei Verwendung im Feld Wochentag können Sie Konstrukte wie „den letzten Freitag“ („5L“) eines bestimmten Monats angeben. Im Feld Tag des Monats wird der letzte Tag des Monats angegeben.
/nZeigt die n-te Instanz einer bestimmten Zeiteinheit an. Jeder Zeitanteil wird unabhängig berechnet. Wenn beispielsweise
4/3im Monatsfeld angegeben ist, dann wird die Aktualisierung für April, Juli und Oktober geplant. Zum Beispiel alle drei Monate, beginnend mit dem vierten Monat des Jahres. In den Folgejahren wird derselbe Zeitplan beibehalten. Das heißt, die Aktualisierung ist nicht für eine Ausführung im Januar (3 Monate nach der Oktober-Ausführung) geplant.
Bemerkung
Der Cron-Ausdruck wird derzeit nur für die angegebene Zeitzone ausgewertet. Durch Ändern des TIMEZONE-Parameterwerts für das Konto (oder Festlegen des Werts auf Benutzer- oder Sitzungsebene) wird die Zeitzone für das Aktualisieren nicht geändert.
Der Cron-Ausdruck definiert alle gültigen Ausführungszeiten für das Aktualisieren. Snowflake versucht, die Freigabeangebote auf der Grundlage dieses Zeitplans zu aktualisieren. Eine gültige Laufzeit wird jedoch übersprungen, wenn eine vorherige Laufzeit nicht vor dem Start der nächsten gültigen Laufzeit abgeschlossen wurde.
Wenn sowohl ein bestimmter Tag des Monats als auch ein bestimmter Wochentag im Cron-Ausdruck enthalten sind, wird die Aktualisierung an Tagen geplant, die entweder dem Tag des Monats oder dem Wochentag entsprechen. Beispielsweise plant
SCHEDULE = 'USING CRON 0 0 10-20 * TUE,THU UTC'eine Aktualisierung um 0:00 Uhr an jedem 10. bis 20. Tag des Monats und auch an jedem Dienstag oder Donnerstag außerhalb dieser Tage.
- Standard:
Keine
LOCK_TIMEOUT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Anzahl der Sekunden, die gewartet werden soll, während versucht wird, eine Ressource zu sperren, bevor das Zeitlimit überschritten und die Anweisung abgebrochen wird.
- Werte:
0auf eine beliebige Ganzzahl (keine Beschränkung). Ein Wert von0deaktiviert das Warten auf Sperren (die Anweisung muss die Sperre sofort erhalten oder abbrechen). Wenn mehrere Ressourcen durch die Anweisung gesperrt werden müssen, gilt das Timeout für jeden Sperrversuch separat- Standard:
43200(12 Stunden)
Siehe auch HYBRID_TABLE_LOCK_TIMEOUT.
LOG_LEVEL¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
Objekt (für Datenbanken, Schemas, DCM-Projekte, gespeicherte Prozeduren, UDFs, dynamische Tabellen, Iceberg-Tabellen, Aufgaben, Services) – kann festgelegt werden für:
Konto » Datenbank » Schema » DCM-Projekt
Konto » Datenbank » Schema » Prozedur
Konto » Datenbank » Schema » Funktion
Konto » Datenbank » Schema » Dynamische Tabelle
Konto » Datenbank » Schema » Iceberg-Tabelle (extern verwaltet)
Konto » Datenbank » Schema » Aufgabe
Konto » Datenbank » Schema » Service
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Gibt den Schweregrad der Protokollmeldungen an, die durch Protokollierungs-APIs erzeugt werden, die in die aktive Ereignistabelle aufgenommen und zur Verfügung gestellt werden sollen. Protokollmeldungen des angegebenen Schweregrads (und mit höherem Schweregrad) werden erfasst. Weitere Informationen zu Protokolliergraden finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung.
- Werte:
TRACEDEBUGINFOWARNERRORFATALOFF
- Standard:
OFF- Zusätzliche Anmerkungen:
In der folgenden Tabelle sind die Schweregrade der Protokollmeldungen aufgeführt, die aufgenommen werden, wenn Sie den Parameter
LOG_LEVELauf einen Schweregrad setzen.Einstellungen für den LOG_LEVEL-Parameter
Schweregrade von aufgenommenen Protokollmeldungen
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERROR(Nur für Java-UDFs, Java-UDTFs sowie gespeicherte Prozeduren in Java und Scala. Weitere Informationen dazu finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung).FATAL
Wenn dieser Parameter sowohl in der Sitzung als auch im Objekt (oder Schema, Datenbank, Konto) gesetzt ist, wird der Wert mit der größeren Ausführlichkeit verwendet. Siehe Wie Snowflake den effektiven Grad bestimmt.
LOG_EVENT_LEVEL¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
Objekt (für Datenbanken, Schemas, DCM-Projekte, gespeicherte Prozeduren, UDFs, dynamische Tabellen, Iceberg-Tabellen, Aufgaben, Services) – kann festgelegt werden für:
Konto » Datenbank » Schema » DCM-Projekt
Konto » Datenbank » Schema » Prozedur
Konto » Datenbank » Schema » Funktion
Konto » Datenbank » Schema » Dynamische Tabelle
Konto » Datenbank » Schema » Iceberg-Tabelle (extern verwaltet)
Konto » Datenbank » Schema » Aufgabe
Konto » Datenbank » Schema » Service
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Gibt den Schweregrad von Protokollereignissen an (Zeilen mit Datensatztyp EVENT), die in der aktiven Ereignistabelle erfasst und zur Verfügung gestellt werden sollen. Protokollmeldungen des angegebenen Schweregrads (und mit höherem Schweregrad) werden erfasst. Weitere Informationen zu den unterstützten Schweregraden und der Kombination der Grade finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung.
- Werte:
TRACEDEBUGINFOWARNERRORFATALOFF
- Standard:
OFF- Zusätzliche Anmerkungen:
In der folgenden Tabelle sind die Schweregrade der Protokollereignisse aufgeführt, die aufgenommen werden, wenn Sie den Parameter
LOG_EVENT_LEVELauf einen Schweregrad setzen.Einstellungen für den LOG_EVENT_LEVEL-Parameter
Schweregrade von aufgenommenen Protokollereignissen
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERRORFATAL
Wenn dieser Parameter sowohl in der Sitzung als auch im Objekt (oder Schema, Datenbank, Konto) gesetzt ist, wird der Wert mit der größeren Ausführlichkeit verwendet. Siehe Wie Snowflake den effektiven Grad bestimmt.
LOGIN_IDP_REDIRECT (schreibgeschützt)¶
- Typ:
Konto
- Datentyp:
VARCHAR
- Beschreibung:
Schreibgeschützter Parameter, der ein JSON-Objekt enthält, das die Werte zusammenfasst, die jemand für die
LOGIN_IDP_REDIRECT-Eigenschaft des Kontos festgelegt hat.Das JSON -Objekt enthält eine Zuordnung zwischen Snowflake-Schnittstellen und SAML-Sicherheitsintegrationen. SAML-Sicherheitsintegrationen werden verwendet, um die Authentifizierung mit Single Sign-On (SSO) zu implementieren. Wenn eine Schnittstelle einer SAML-Sicherheitsintegration zugeordnet ist, dann werden Benutzende, die auf die Schnittstelle zugreifen, zur Authentifizierung an den externen Identitätsanbieter (IdP) umgeleitet; sie sehen nie den Snowflake Anmeldebildschirm.
For a conceptual overview and configuration examples, see Automatisches Umleiten der Benutzer zu Ihrem Identitätsanbieter. For the syntax used to set the property, see ALTER ACCOUNT.
MAX_CONCURRENCY_LEVEL¶
- Typ:
Objekt (für Warehouses) – Kann festgelegt werden für Konto » Warehouse
- Datentyp:
Zahl
- Beschreibung:
Gibt den Parallelitätsgrad für SQL-Anweisungen (Abfragen und DML) an, die von einem Warehouse ausgeführt werden. Wenn der Grad erreicht ist, hängt die ausgeführte Operation davon ab, ob es sich bei dem Warehouse um ein Einzel-Cluster-Warehouse oder ein Multi-Cluster-Warehouse handelt:
Einzelcluster oder Multi-Cluster (im Modus „Maximiert“): Anweisungen werden in die Warteschlange gestellt, bis bereits zugewiesene Ressourcen freigegeben oder zusätzliche Ressourcen bereitgestellt werden. Dies kann durch Vergrößern des Warehouse erreicht werden.
Multi-Cluster (im Modus „Automatische Skalierung“): Zusätzliche Cluster werden gestartet.
MAX_CONCURRENCY_LEVEL kann in Verbindung mit dem Parameter STATEMENT_QUEUED_TIMEOUT_IN_SECONDS verwendet werden, um sicherzustellen, dass ein Warehouse niemals in Rückstand gerät.
Im Allgemeinen ist die Anzahl der Anweisungen begrenzt, die von einem Warehouse-Cluster gleichzeitig ausgeführt werden können, aber es gibt auch Ausnahmen. Im folgenden Fall kann die tatsächliche Anzahl der Anweisungen, die gleichzeitig von einem Warehouse ausgeführt werden, über oder unter dem angegebenen Wert liegen:
Kleine, weniger komplexe Anweisungen: Mehr Anweisungen können gleichzeitig ausgeführt werden, da kleine, weniger komplexe Anweisungen im Allgemeinen auf einer Teilmenge der Computeressourcen eines Warehouses ausgeführt werden. Dies bedeutet, dass sie nur mit einem Bruchteil in den Parallelitätsgrad eingehen.
Größere, komplexere Anweisungen: Es werden möglicherweise weniger Anweisungen gleichzeitig ausgeführt.
- Standard:
8
Tipp
Dieser Wert ist nur ein Standardwert und kann jederzeit verändert werden:
Durch Herabsetzen des Parallelitätsgrads eines Warehouses kann die Anzahl der gleichzeitig ausgeführten Abfragen in einem Warehouse begrenzt werden. Wenn zu einem bestimmten Zeitpunkt weniger Abfragen um die Ressourcen des Warehouses konkurrieren, können einer Abfrage potenziell mehr Ressourcen zugewiesen werden, was zu einer schnelleren Verarbeitung der Abfrage führen kann, insbesondere bei großen/komplexen Abfragen mit mehreren Anweisungen.
Durch Erhöhen des Parallelitätsgrads eines Warehouses kann dazu führen, dass für eine Anweisung weniger Computeressourcen zur Verfügung stehen. Dadurch wird die Anzahl der gleichzeitigen Abfragen, die vom Warehouse ausgeführt werden können, jedoch nicht immer begrenzt. Dies hat auch nicht notwendigerweise Einfluss auf die gesamte Warehouse-Performance, die von der Art der ausgeführten Abfragen abhängt.
Beachten Sie, dass sich dieser Parameter, wie zuvor beschrieben, auf Multi-Cluster-Warehouses auswirkt (im Modus „Automatische Skalierung“), da Snowflake automatisch einen neuen Cluster im Multi-Cluster-Warehouse startet, um die Warteschlange zu vermeiden. Wenn Sie den Parallelitätsgrad für ein Warehouse mit mehreren Clustern (im Modus „Automatische Skalierung“) verringern, erhöht sich dadurch möglicherweise jederzeit die Anzahl der aktiven Cluster.
Denken Sie auch daran, dass Snowflake bei der Übermittlung der Anweisungen automatisch Ressourcen zuweist und die zugewiesene Menge von den individuellen Anforderungen der Anweisung bestimmt wird. Auf dieser Grundlage und unter Verwendung unserer Beobachtungen von Benutzerabfragemustern haben wir einen Standard ausgewählt, der Leistung und Ressourcennutzung in Einklang bringt.
Wir empfehlen daher, vor dem Ändern der Standardeinstellung die Änderung zu testen, indem Sie den Parameter in kleinen Schritten anpassen und die Auswirkung auf einen repräsentativen Satz Ihrer Abfragen beobachten.
MAX_DATA_EXTENSION_TIME_IN_DAYS¶
- Typ:
Objekt (für Datenbanken, Schemas und Tabellen) – Kann festgelegt werden für Konto » Datenbank » Schema » Tabelle
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Maximale Anzahl von Tagen, für die Snowflake die Datenaufbewahrungsfrist für Tabellen verlängern kann, um zu verhindern, dass Streams auf den Tabellen veralten. Wenn die DATA_RETENTION_TIME_IN_DAYS-Einstellung für eine Quelltabelle weniger als 14 Tage beträgt und kein Stream verbraucht wurde, verlängert Snowflake standardmäßig diese Frist vorübergehend bis zum Offset des Streams um maximal 14 Tage, unabhängig von der Snowflake-Edition Ihres Kontos. Der MAX_DATA_EXTENSION_TIME_IN_DAYS-Parameter ermöglicht eine Begrenzung dieser automatischen Verlängerungsfrist, um die Speicherkosten für die Datenaufbewahrung zu kontrollieren oder aus Gründen der Compliance.
Der Parameter kann auf Konto-, Datenbank-, Schema- oder Tabellenebene festgelegt werden. Beachten Sie, dass sich das Festlegen des Parameters auf der Konto- oder Schemaebene nur auf Tabellen auswirkt, für die der Parameter noch nicht explizit auf einer niedrigeren Ebene festgelegt wurde (z. B. auf der Tabellen-Ebene vom Tabellen-Eigentümer). Der Wert 0 deaktiviert die automatische Verlängerung für die angegebene Datenbank, das angegebene Schema oder die angegebene Tabelle. Weitere Informationen zu Streams und zum Veralten finden Sie unter Introduction to streams.
- Werte:
0bis90(d. h. 90 Tage). Ein Wert von0deaktiviert die automatische Verlängerung der Datenaufbewahrungsfrist. Um den Maximalwert für Tabellen Ihres Kontos zu erhöhen, wenden Sie sich an den Snowflake-Support.- Standard:
14
Bemerkung
Dieser Parameter kann dazu führen, dass Daten länger als die Standard-Datenaufbewahrungsfrist aufbewahrt werden. Prüfen Sie vor dem Erhöhen des Werts, ob der neue Wert Ihren Compliance-Anforderungen gerecht wird.
Die Tabellenaufbewahrungszeit wird für Streams auf freigegebenen Tabellen nicht erweitert. Wenn Sie eine Tabelle freigeben, stellen Sie sicher, dass Sie die Einstellung für die Aufbewahrungsdauer der Tabelle lang genug ist, dass Ihr Datenverbraucher den Stream nutzen kann. Wenn ein Anbieter eine Tabelle mit einem Speicher von z. B. 7 Tagen freigibt und die standardmäßige Erweiterung von 14 Tagen beibehält, ist der Stream nach 14 Tagen im Anbieterkonto und nach 7 Tagen im Verbraucherkonto veraltet.
METRIC_LEVEL¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
Objekt (für Datenbanken, Schemas, gespeicherte Prozeduren und UDFs) – Kann festgelegt werden für Konto » Datenbank » Schema » Prozedur und Konto » Datenbank » Schema » Funktion
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Steuert, wie die Metrikdaten in die Ereignistabelle aufgenommen werden. Weitere Informationen zu metrischen Ebenen finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung.
- Werte:
ALL: Alle Metrikdaten werden in der Ereignistabelle aufgezeichnet.NONE: Es werden keine Metrikdaten in der Ereignistabelle aufgezeichnet.- Standard:
NONE
MULTI_STATEMENT_COUNT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Ganzzahl (Konstante)
- Clients:
SQL-API, JDBC, .NET, ODBC
- Beschreibung:
Anzahl der Anweisungen, die ausgeführt werden sollen, wenn die Funktion für mehrere Anweisungen verwendet wird.
- Werte:
0: variable Anzahl von Anweisungen.1: eine Anweisung.Größer als
1: Wenn MULTI_STATEMENT_COUNT als Sitzungsparameter festgelegt ist, können Sie die genaue Anzahl der auszuführenden Anweisungen angeben.Negative Zahlen sind nicht erlaubt.
- Standard:
1
MIN_DATA_RETENTION_TIME_IN_DAYS¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Minimale Anzahl der Tage, für die Snowflake historische Daten zu einem Objekt zur Durchführung von Time Travel-Aktionen (SELECT, CLONE, UNDROP) aufbewahrt. Wenn für ein Konto eine minimale Anzahl von Tagen für die Datenaufbewahrung festgelegt ist, wird die Datenaufbewahrungsfrist eines Objekts durch MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS) bestimmt.
Weitere Informationen dazu finden Sie unter Verstehen und Verwenden von Time Travel.
- Werte:
0oder1(für Standard Edition)0bis90(für Enterprise Edition oder höher)- Standard:
0
Bemerkung
Dieser Parameter gilt nur für permanente Tabellen und nicht für die folgenden Objekte:
Transiente Tabellen
Temporäre Tabellen
Externe Tabellen
Materialisierte Ansichten
Streams
Dieser Parameter kann nur von Kontoadministratoren (d. h. Benutzern mit der Rolle ACCOUNTADMIN oder einer anderen Rolle, der die Rolle ACCOUNTADMIN zugewiesen ist) festgelegt oder aufgehoben werden.
Die Einstellung der minimalen Datenaufbewahrungsdauer hat keine Auswirkungen auf den für Datenbanken, Schemas oder Tabellen festgelegten Parameterwert für DATA_RETENTION_TIME_IN_DAYS. Die geltende Aufbewahrungsdauer einer Datenbank, eines Schemas oder einer Tabelle ist MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
NETWORK_POLICY¶
- Typ:
Konto – Kann nur für Konto festgelegt werden (von Kontoadministratoren und auch von Systemadministratoren)
- Typ:
Objekt (für Benutzer) – Kann für Konto » Benutzer festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Netzwerkrichtlinie an, die für Ihr Konto durchgesetzt werden soll. Netzwerkrichtlinien ermöglichen die Beschränkung des Zugriffs auf Ihr Konto basierend auf der IP-Adresse der Benutzer. Weitere Details dazu finden Sie unter Steuern des Netzwerkdatenverkehrs mit Netzwerkrichtlinien.
- Werte:
Eine vorhandene Netzwerkrichtlinie (erstellt mit CREATE NETWORK POLICY)
- Standard:
Keine
Bemerkung
Dies ist der einzige Kontoparameter, der von Sicherheitsadministratoren (d. h. Benutzer mit der Rolle SECURITYADMIN) oder höher festgelegt werden kann.
NOORDER_SEQUENCE_AS_DEFAULT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die Eigenschaft ORDER oder NOORDER standardmäßig festgelegt wird, wenn Sie eine neue Sequenz erstellen oder eine neue Tabellenspalte hinzufügen.
Die Eigenschaften ORDER und NOORDER bestimmen, ob die Werte für die Sequenz oder für die automatisch inkrementierte Spalte in aufsteigender oder absteigender Reihenfolge generiert werden sollen oder nicht.
- Werte:
TRUE: Wenn Sie eine neue Sequenz erstellen oder eine neue Tabellenspalte hinzufügen, ist die Eigenschaft NOORDER standardmäßig festgelegt.NOORDER gibt an, dass nicht garantiert ist, dass die Werte in aufsteigender Reihenfolge sind.
Wenn beispielsweise eine Sequenz die Werte
START 1 INCREMENT 2hat, könnten die generierten Werte1,3,101,5,103usw. sein.NOORDER kann die Leistung verbessern, wenn mehrere INSERT-Operationen gleichzeitig ausgeführt werden (z- B., wenn mehrere Clients mehrere INSERT-Anweisungen ausführen).
FALSE: Wenn Sie eine neue Sequenz erstellen oder eine neue Tabellenspalte hinzufügen, ist die Eigenschaft ORDER standardmäßig festgelegt.ORDER gibt an, dass die Werte, die für eine Sequenz oder eine automatisch inkrementierte Spalte generiert werden, in aufsteigender Reihenfolge sind (oder, wenn das Intervall einen negativen Wert hat, in abnehmender Reihenfolge).
Wenn beispielsweise eine Sequenz oder eine automatisch inkrementierte Spalte die Werte
START 1 INCREMENT 2hat, könnten die generierten Werte1,3,5,7,9usw. sein.
Wenn Sie diesen Parameter festlegen, überschreibt dieser Wert den Wert im Verhaltensänderungs-Bundle 2024_01.
- Standard:
TRUE
ODBC_TREAT_DECIMAL_AS_INT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, wie ODBC Spalten verarbeitet, die eine Dezimalstellenzahl von null (
0) haben.- Werte:
TRUE: ODBC verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als BIGINT.FALSE: ODBC verarbeitet eine Spalte, deren Dezimalstellenzahl null ist, als DECIMAL.- Standard:
FALSE
OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Bestimmt, ob die Rollen ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN und SECURITYADMIN als Primärrolle verwendet werden können, wenn eine Snowflake-Sitzung auf Basis des Zugriffstokens vom Snowflake-Autorisierungsserver erstellt wird.
- Werte:
TRUE: Fügt die Rollen ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN und SECURITYADMIN der EigenschaftBLOCKED_ROLES_LISTder Snowflake OAuth-Sicherheitsintegration hinzu, was bedeutet, dass diese Rollen beim Erstellen einer Snowflake-Sitzung mit Snowflake OAuth nicht als Primärrolle verwendet werden können.FALSE: Entfernt ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN und SECURITYADMIN aus der Liste der gesperrten Rollen, die durch dieBLOCKED_ROLES_LIST-Eigenschaft der Snowflake-OAuth-Sicherheitsintegration definiert sind.- Standard:
TRUE
OPT_OUT_ERROR_LOGGING¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die DML-Fehlerprotokollierung zulässig ist.
- Werte:
TRUE: Die DML-Fehlerprotokollierung ist nicht aktiviert, unabhängig davon, ob sie für bestimmte Tabellen aktiviert ist.FALSE: Die DML-Fehlerprotokollierung verhält sich normal:Die DML-Fehlerprotokollierung ist für Tabellen aktiviert, bei denen der ERROR_LOGGING-Parameter auf Tabellenebene auf
TRUEeingestellt ist.Die DML-Fehlerprotokollierung ist für Tabellen deaktiviert, bei denen der ERROR_LOGGING-Parameter auf Tabellenebene auf
FALSEeingestellt ist.
- Standard:
FALSE
Weitere Informationen dazu finden Sie unter DML-Fehlerprotokollierung.
PERIODIC_DATA_REKEYING¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Dieser Parameter gilt nur für Enterprise Edition (oder höher). Er aktiviert/deaktiviert die Neuverschlüsselung von Tabellendaten mit neuen Schlüsseln auf jährlicher Basis, um zusätzlichen Datenschutz zu bieten.
Sie können die Wiederverschlüsselung jederzeit aktivieren und deaktivieren. Das Aktivieren/Deaktivieren der Wiederverschlüsselung führt nicht zu Lücken in den verschlüsselten Daten:
Wenn die Wiederverschlüsselung für einen bestimmten Zeitraum aktiviert ist und dann deaktiviert wird, werden alle Daten, die bereits für die Wiederverschlüsselung markiert wurden, erneut verschlüsselt. Weitere Daten werden jedoch erst wieder neu verschlüsselt, wenn Sie die Wiederverschlüsselung wieder aktivieren.
Wenn die Wiederverschlüsselung wieder aktiviert wird, werden alle Daten, deren Schlüssel die Kriterien erfüllen (d. h. Schlüssel, die älter als ein Jahr sind), automatisch von Snowflake neu verschlüsselt.
Weitere Informationen zur Wiederverschlüsselung verschlüsselter Daten finden Sie unter Hinweise zur Verwaltung von Verschlüsselungsschlüsseln in Snowflake.
- Werte:
TRUE: Die Daten werden ein Jahr nach der letzten Verschlüsselung neu verschlüsselt. Die Wiederverschlüsselung erfolgt im Hintergrund, sodass keine Ausfallzeiten auftreten und die betroffenen Daten/Tabellen immer verfügbar sind.FALSE: Daten werden nicht neu verschlüsselt.- Standard:
FALSE
Bemerkung
Mit der Wiederverschlüsselung von Daten sind Gebühren verbunden, da nach der Wiederverschlüsselung die alten Daten (mit der vorherigen Verschlüsselung) für den Standardzeitraum (7 Tage) in Fail-safe aufbewahrt werden. Aus diesem Grund ist die periodische Wiederverschlüsselung standardmäßig deaktiviert. Um die periodische Wiederverschlüsselung zu aktivieren, müssen Sie sie explizit aktivieren.
Außerdem werden Fail-safe-Gebühren für die Wiederverschlüsselung in Ihrer monatlichen Abrechnung nicht einzeln aufgeführt. Sie sind jeden Monat in der Fail-safe-Gesamtsumme für Ihr Konto enthalten.
Weitere Informationen zu Fail-safe finden Sie unter Erläuterungen zu und Anzeigen von Fail-safe.
PIPE_EXECUTION_PAUSED¶
- Typ:
Objekt – Kann festgelegt werden für Konto » Schema » Pipe
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob eine laufende Pipe angehalten werden soll, besonders in Vorbereitung auf die Übertragung der Eigentümerschaft der Pipe auf eine andere Rolle:
Ein Kontoadministrator (Benutzer mit der Rolle ACCOUNTADMIN) kann diesen Parameter auf Kontoebene festlegen, um alle Pipes im Konto effektiv anzuhalten oder fortzusetzen.
Ein Benutzer mit der Berechtigung MODIFY für ein Schema kann alle Pipes in dem Schema anhalten oder fortsetzen.
Der Pipeinhaber kann diesen Parameter für eine Pipe festlegen.
Beachten Sie, dass das Festlegen des Parameters auf der Konto- oder Schemaebene nur für Pipes gilt, für die der Parameter noch nicht explizit auf einer niedrigeren Ebene festgelegt wurde (z. B. auf der Pipe-Ebene vom Pipe-Eigentümer).
Dies ermöglicht den praktischen Anwendungsfall, bei dem ein Kontoadministrator alle Pipes auf Kontoebene anhalten kann, ein Pipe-Eigentümer aber dennoch eine eigene Pipe ausführen kann.
- Werte:
TRUE: Hält die Pipe an. Wenn der Parameter auf diesen Wert gesetzt ist, zeigt die Funktion SYSTEM$PIPE_STATUS denexecutionStatealsPAUSEDan. Beachten Sie, dass der Pipe-Eigentümer zwar weiterhin Dateien an eine angehaltene Pipe übermitteln kann, die Dateien jedoch erst nach Fortsetzung der Pipe verarbeitet.FALSE: Setzt die Pipe fort, jedoch nur, wenn die Eigentümerschaft der Pipe nicht übertragen wurde, während sie angehalten war. Wenn der Parameter auf diesen Wert gesetzt ist, zeigt die Funktion SYSTEM$PIPE_STATUS denexecutionStatealsRUNNINGan.Wenn die Eigentümerschaft der Pipe nach dem Anhalten der Pipe auf eine andere Rolle übertragen wurde, kann dieser Parameter nicht zum Fortsetzen der Pipe verwendet werden. Verwenden Sie stattdessen die Funktion SYSTEM$PIPE_FORCE_RESUME, um ein Fortsetzen der Pipe durchzusetzen.
Dies ermöglicht es dem neuen Eigentümer, den Pipestatus (z. B. wie viele Dateien darauf warten, geladen zu werden) mit SYSTEM$PIPE_STATUS zu bewerten, bevor er die Pipe fortsetzt.
- Standard:
FALSE(Pipes werden standardmäßig ausgeführt)
Bemerkung
Im Allgemeinen müssen Pipes nicht angehalten werden, außer für die Übertragung der Eigentümerschaft.
PATH_LAYOUT¶
- Typ:
Objekt (für Apache Iceberg™-Tabellen) – kann für Iceberg-Tabelle festgelegt werden
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Gibt das Pfad-Layout an, das Snowflake beim Schreiben von Parquet-Datendateien in Iceberg-Tabellen verwendet. Sie können diesen Parameter angeben, wenn Sie eine Tabelle erstellen, Sie können diesen Parameter jedoch nicht angeben, wenn Sie eine Tabelle ändern.
Bemerkung
Für extern verwaltete Tabellen, die Sie in einer Snowflake-Standarddatenbank erstellen, leitet Snowflake das von der Remotetabelle angegebene Partitionierungsschema ab und berücksichtigt es.
- Werte:
FLAT: Snowflake schreibt alle Parquet-Datendateien unter demdata/-Verzeichnis für die Tabelle.HIERARCHICAL: Snowflake schreibt partitionierte Daten unter demdata/-Verzeichnis für die Tabelle mithilfe eines hierarchischen Pfad-Layouts. Bei diesem Layout wird jede Partitionsspalte als Verzeichnisebene im Pfad dargestellt. Um diese Partitionsspalten zu definieren, verwenden Sie den Parameter PARTITION BY. Dieses Layout wird auch als „Hive-style“-Partitionierung bezeichnet.Wenn Sie das hierarchische Layout angeben, aber keine PARTITIONBY-Klausel mit dem Befehl festlegen, speichert Snowflake die Parquet-Datendateien in einem vereinfachten Layout-Pfad. Sie können den ALTERICEBERGTABLE-Befehl nicht verwenden, um später ein hierarchisches Pfad-Layout für die Tabelle zu aktivieren. Sie können diesen Parameter ohne Angabe einer PARTITIONBY-Klausel auf HIERARCHICAL setzen, wenn Sie die Partitionierung mit hierarchischen Pfaden momentan nicht verwenden möchten, dies aber in Zukunft möglicherweise tun werden.
- Standard:
FLAT
Weitere Informationen dazu finden Sie unter Daten- und Metadatenverzeichnisse.
PREVENT_UNLOAD_TO_INLINE_URL¶
- Typ:
Objekt (für Benutzer) – Kann für Konto » Benutzer festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Ad-hoc-Operationen zum Entladen von Daten an externe Cloudspeicherorte verhindert werden sollen (d. h. COPY INTO <Speicherort>-Anweisungen, die die Cloudspeicher-URL angeben und direkt in der Anweisung auf Einstellungen zugreifen). Ein Beispiel dazu finden Sie unter Entladen von Daten aus einer Tabelle direkt in Dateien an einem externen Speicherort.
- Werte:
TRUE: COPY INTO <Speicherort>-Anweisungen müssen entweder auf einen benannten internen (Snowflake) oder externen Stagingbereich oder auf einen internen Benutzer- oder Tabellen-Stagingbereich verweisen. Ein benannter externer Stagingbereich muss die Cloudspeicher-URL und die Zugriffseinstellungen in seiner Definition speichern.FALSE: Ad-hoc-Datenentladeoperationen an externe Cloudspeicherorte sind zulässig.- Standard:
FALSE
PREVENT_UNLOAD_TO_INTERNAL_STAGES¶
- Typ:
Benutzer – Kann für Konto » Benutzer festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Datenentladeoperationen zu internen (Snowflake) Stagingbereichen mit COPY INTO <Speicherort>-Anweisungen verhindert werden sollen.
- Werte:
TRUE: Daten werden aus Snowflake-Tabellen in einen internen Stagingbereich entladen, einschließlich Benutzer-, Tabellen- oder benannte interne Stagingbereiche.FALSE: Daten werden in interne Stagingbereiche entladen, wobei nur die Standardeinschränkungen des Stagingbereichtyps gelten:Der aktuelle Benutzer kann Daten nur in seinen eigenen Benutzer-Stagingbereich entladen.
Benutzer können nur dann Daten in Tabellen-Stagingbereiche entladen, wenn ihre aktive Rolle die OWNERSHIP-Berechtigung für die Tabelle hat.
Benutzer können nur dann Daten in benannte interne Stagingbereiche entladen, wenn ihre aktive Rolle die WRITE-Berechtigung für den Stagingbereich hat.
- Standard:
FALSE
PYTHON_PROFILER_TARGET_STAGE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den vollqualifizierten Namen des Stagingbereichs an, in dem ein Bericht beim Profiling des Python-Handler-Codes gespeichert werden soll.
- Werte:
Vollqualifizierter Name des Stagingbereichs, in dem der Bericht gespeichert werden soll.
Verwenden Sie einen temporären Stagingbereich, um die Ausgabe nur für die Dauer der Sitzung zu speichern.
Verwenden Sie einen permanenten Stagingbereich, um die Profiler-Ausgabe außerhalb einer Sitzung aufzubewahren.
Weitere Informationen dazu finden Sie unter Geben Sie den Snowflake-Stagingbereich an, in den die Profilausgabe geschrieben werden soll.
- Standard:
''
PYTHON_PROFILER_MODULES¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Liste der Python-Module an, die in einen Bericht beim Profiling des Python HandlerCodes aufgenommen werden sollen.
Verwenden Sie diesen Parameter, um Module anzugeben, die in Stagingbereichen enthalten sind oder die Abhängigkeiten enthalten, die Sie in das Profil aufnehmen möchten.
- Werte:
Eine durch Kommas getrennte Liste von Python-Modulnamen.
Beispiele finden Sie unter Einbindung von Modulen mit dem Parameter PYTHON_PROFILER_MODULES und Profiling von Stagingbereich-Handler-Code.
- Standard:
''
QUERY_TAG¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (bis zu 2.000 Zeichen)
- Beschreibung:
Optionale Zeichenfolge, die zum Markieren von Abfragen und anderen SQL-Anweisungen verwendet werden kann, die innerhalb einer Sitzung ausgeführt werden. Die Tags werden in der Ausgabe der Funktionen QUERY_HISTORY , QUERY_HISTORY_BY_* angezeigt.
- Standard:
Keine
QUOTED_IDENTIFIERS_IGNORE_CASE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
Objekt – Kann festgelegt werden für Konto » Datenbank » Schema » Tabelle
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob Buchstaben in Objektbezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, als Großbuchstaben gespeichert und aufgelöst werden sollen. Standardmäßig behält Snowflake beim Speichern und Auflösen von Bezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, die Groß-/Kleinschreibung von alphabetischen Zeichen bei (siehe Auflösung des Bezeichners). Sie können diesen Parameter in Situationen verwenden, in denen Drittanbieteranwendungen immer doppelte Anführungszeichen um Bezeichner verwenden.
Bemerkung
Das Ändern des Standardwerts dieses Parameters kann sich auf die Fähigkeit auswirken, Objekte zu finden, die zuvor mit Bezeichnern in doppelten Anführungszeichen und gemischter Groß-/Kleinschreibung erstellt wurden. Weitere Informationen dazu finden Sie unter Auswirkungen der Änderung des Parameters.
Wenn die Einstellung für eine Tabelle, ein Schema oder eine Datenbank festgelegt wurde, wirkt sie sich nur auf die Auswertung von Tabellennamen in den Textteilen von Ansichten und benutzerdefinierten Funktionen (UDFs) aus. Wenn Ihr Konto Bezeichner in doppelten Anführungszeichen verwendet, bei denen die Groß-/Kleinschreibung nicht beachtet werden soll, und Sie planen, eine Ansicht oder UDF für ein Konto freizugeben, bei dem bei Bezeichnern in doppelten Anführungszeichen die Groß-/Kleinschreibung beachtet wird, können Sie dies in der freizugebenden Ansicht oder UDF einstellen. Dadurch kann das andere Konto die Tabellennamen in der Ansicht oder UDF korrekt auflösen.
- Werte:
TRUE: Buchstaben in Bezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, werden als Großbuchstaben gespeichert und aufgelöst.FALSE: Die Groß-/Kleinschreibung der Buchstaben in Bezeichnern, die in doppelte Anführungszeichen eingeschlossen sind, wird beibehalten. Snowflake löst die Bezeichner auf und speichert sie in der angegebenen Schreibweise.Weitere Informationen dazu finden Sie unter Auflösung des Bezeichners.
- Standard:
FALSE
Beispiel:
Bezeichner |
Parameter auf |
Parameter auf |
|
|---|---|---|---|
|
wird aufgelöst in: |
|
|
|
wird aufgelöst in: |
|
|
|
wird aufgelöst in: |
|
|
|
wird aufgelöst in: |
|
|
READ_CONSISTENCY_MODE¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Definiert den Grad an Konsistenzgarantien, der für Sitzungen mit nahezu gleichzeitigen Änderungen erforderlich ist.
- Werte:
SESSION: Änderungen sind sofort für nachfolgende Abfragen innerhalb derselben Sitzung sichtbar, aber nicht immer sofort zwischen den Sitzungen.GLOBAL: Änderungen sind sofort für nachfolgende Abfragen in gleichzeitig laufenden Sitzungen sichtbar, haben aber nur geringe Auswirkungen auf die Antwortzeiten von Abfragen (in der Regel Millisekunden).- Standard:
SESSION
Weitere Informationen dazu finden Sie unter Lesekonsistenz über Sitzungen hinweg.
REPLACE_INVALID_CHARACTERS¶
- Typ:
Objekt – Kann festgelegt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob ungültige UTF-8-Zeichen in Abfrageergebnissen für Apache Iceberg™-Tabellen, die einen externen Katalog verwenden, durch das Unicode-Ersetzungszeichen (�) ersetzt werden sollen.
- Werte:
TRUE: Snowflake ersetzt ungültige UTF-8-Zeichen durch das Unicode-Ersetzungszeichen.FALSE: Snowflake lässt ungültige UTF-8-Zeichen unverändert. Snowflake gibt eine Fehlermeldung an den Benutzer zurück, wenn es auf ein ungültiges UTF-8-Zeichen stößt.- Standard:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob beim Erstellen eines benannten externen Stagingbereichs (mit CREATE STAGE) für den Zugriff auf einen privaten Cloudspeicherort ein Speicherintegrationsobjekt als Cloudanmeldeinformation erforderlich ist.
- Werte:
TRUE: Um einen externen Stagingbereich für den Zugriff auf einen privaten Cloudspeicherort zu erstellen, muss ein Speicherintegrationsobjekt als Cloudanmeldeinformation referenziert werden.FALSE: Zum Erstellen eines externen Stagingbereichs ist kein Verweis auf ein Speicherintegrationsobjekt erforderlich. Benutzer können stattdessen auf explizite Anmeldeinformationen des Cloudanbieters verweisen, z. B. geheime Schlüssel oder Zugriffstoken, falls diese für den Speicherort konfiguriert wurden.- Standard:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob beim Laden/Entladen von Daten von/in private Cloudspeicherorte die Verwendung eines benannten externen Stagingbereichs erforderlich ist, der auf ein Speicherintegrationsobjekt als Cloudanmeldeinformation verweist.
- Werte:
TRUE: Das Laden von Daten von oder das Entladen von Daten in private Cloudspeicherorte erfordert die Verwendung eines benannten externen Stagingbereichs, der auf ein Speicherintegrationsobjekt verweist. Die Angabe eines benannten externen Stagingbereichs, der auf explizite Anmeldeinformationen des Cloudanbieters verweist, z. B. geheime Schlüssel oder Zugriffstoken, führt zu einem Benutzerfehler.FALSE: Benutzer können Daten von/in private Cloudspeicherorte laden/entladen, indem sie einen benannten externen Stagingbereich verwenden, der auf explizite Anmeldeinformationen des Cloudanbieters verweist.Wenn PREVENT_UNLOAD_TO_INLINE_URL FALSE ist, können Benutzer die expliziten Anmeldeinformationen des Cloudanbieters direkt in der COPY-Anweisung angeben.
- Standard:
FALSE
ROWS_PER_RESULTSET¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zahl
- Clients:
SQL API
- Beschreibung:
Gibt die maximale Anzahl von Zeilen an, die in einem Resultset zurückgegeben werden.
- Werte:
0bis zu einer beliebigen Zahl (keine Begrenzung) – der Wert0gibt kein Maximum an.- Standard:
0
S3_STAGE_VPCE_DNS_NAME¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den DNS-Namen eines Amazon S3-Schnittstellenendpunkts an. Anfragen, die über AWS PrivateLink für Amazon S3 an den internen Stagingbereich eines Kontos gesendet werden, verwenden diesen Endpunkt zur Verbindung.
Weitere Informationen dazu finden Sie unter Zugriff auf interne Stagingbereiche mit dedizierten Schnittstellenendpunkten.
- Werte:
Gültiger regionalspezifischer DNS-Name eines S3-Schnittstellenendpunkts.
Das Standardformat beginnt mit einem Sternchen (
*) und endet mitvpce.amazonaws.com(z. B.*.vpce-sd98fs0d9f8g.s3.us-west-2.vpce.amazonaws.com). Weitere Einzelheiten zur Ermittlung dieses Wertes finden Sie unter AWS-Konfiguration.Alternative Formate sind
bucket.vpce-xxxxxxxx.s3.<region>.vpce.amazonaws.comundvpce-xxxxxxxx.s3.<region>.vpce.amazonaws.com.- Standard:
Leere Zeichenfolge
SAML_IDENTITY_PROVIDER¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
JSON
- Beschreibung:
Aktiviert die Verbundauthentifizierung. Dieser veraltete Parameter ermöglicht eine Verbundauthentifizierung. Dieser Parameter akzeptiert ein JSON-Objekt, das in einfache Anführungszeichen eingeschlossen ist, mit den folgenden Feldern:
Wobei:
certificateGibt das Zertifikat an (generiert vom IdP), das die Kommunikation zwischen dem IdP und Snowflake überprüft.
issuerZeigt den Aussteller bzw. die EntityID des IdP an.
Optional.
Informationen darüber, wie Sie diesen Wert in Okta und AD FS erhalten, finden Sie unter Migration zu einer SAML2-Sicherheitsintegration.
ssoUrlGibt den URL-Endpunkt an (bereitgestellt vom IdP), an den Snowflake die SAML-Anfragen sendet.
typeGibt den IdP-Typ an, der für die Verbundauthentifizierung verwendet wird (
"OKTA","ADFS","Custom").labelGibt den Text der Schaltfläche für den IdP auf der Anmeldeseite von Snowflake an. Die Standardbezeichnung lautet
Single Sign On. Wenn Sie die Standardbezeichnung ändern, darf die von Ihnen angegebene Bezeichnung nur alphanumerische Zeichen enthalten (Sonderzeichen und Leerzeichen werden derzeit nicht unterstützt).Wenn das Feld
"type""Okta"ist, muss kein Wert für das Feldlabelangegeben werden, da Snowflake das Okta-Logo in der Schaltfläche anzeigt.
Weitere Informationen sowie Beispiele zum Festlegen des Parameters finden Sie unter Migration zu einer SAML2-Sicherheitsintegration.
- Standard:
Keine
SEARCH_PATH¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den zu suchenden Pfad an, um unqualifizierte Objektnamen in Abfragen aufzulösen. Weitere Informationen dazu finden Sie unter Namensauflösung in Abfragen.
- Werte:
Kommagetrennte Liste von Bezeichnern. Ein Bezeichner kann ein vollständig oder teilweise qualifizierter Schemaname sein.
- Standard:
$current, $publicWeitere Informationen zu den Standardeinstellungen finden Sie unter Standardsuchpfad.
Bemerkung
Sie können diesen Parameter nicht innerhalb einer Client-Verbindungszeichenfolge festlegen, wie z. B. einer JDBC- oder ODBC-Verbindungszeichenfolge. Sie müssen erst eine Sitzung einrichten, bevor Sie einen Suchpfad festlegen können.
Dieser Parameter wird für Aufgaben nicht unterstützt.
SERVERLESS_TASK_MAX_STATEMENT_SIZE¶
- Typ:
Objekt – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die maximal zulässige Warehouse-Größe für Serverlose Aufgaben an.
- Werte:
Jede traditionelle Warehouse-Größe:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. Die maximale Größe istX2LARGE.Unterstützt auch die Syntax:
XXLARGE.- Standard:
X2LARGE
SERVERLESS_TASK_MIN_STATEMENT_SIZE¶
- Typ:
Objekt – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die minimal zulässige Warehouse-Größe für Serverlose Aufgaben an.
- Werte:
Jede traditionelle Warehouse-Größe:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. Die maximale Größe istX2LARGE.Unterstützt auch die Syntax:
XXLARGE.- Standard:
XSMALL
SIMULATED_DATA_SHARING_CONSUMER¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt den Namen eines Verbraucherkontos an, das zum Testen/Validieren von gemeinsam genutzten Daten, insbesondere von gemeinsam genutzten gesicherten Ansichten, simuliert werden soll. Wenn dieser Parameter in einer Sitzung festgelegt ist, geben freigegebene Ansichten Zeilen so zurück, als wären sie im angegebenen Verbraucherkonto ausgeführt worden und nicht im Anbieterkonto.
Bemerkung
Simulationen sind nur dann erfolgreich, wenn die aktuelle Rolle der Eigentümer der Ansicht ist. Wenn die aktuelle Rolle nicht Eigentümer der Ansicht ist, schlägt die Simulation mit folgendem Fehler fehl:
Weitere Informationen dazu finden Sie unter Über Secure Data Sharing und Freigaben erstellen und konfigurieren.
- Standard:
Keine
Wichtig
Dies ist ein Sitzungsparameter, d. h. er kann auf Kontoebene festgelegt werden. Dies gilt jedoch nur für das Testen von Abfragen bei gemeinsamen Ansichten. Da sich der Parameter auf alle Abfragen in einer Sitzung auswirkt, sollte er niemals auf der Kontoebene festgelegt werden.
SQL_TRACE_QUERY_TEXT¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Gibt an, ob der SQL-Text einer verfolgten SQL-Anweisung erfasst werden soll.
- Werte:
ON: Ablaufverfolgungen, die einer SQL-Anweisung folgen, erfassen den SQL-Text und speichern ihn in der Ereignistabelle.OFF: Ablaufverfolgungen erfassen SQL-Text nicht in der Ereignistabelle.Weitere Informationen dazu finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung und Ablaufverfolgung von SQL-Anweisungen.
- Standard:
OFF
SSO_LOGIN_PAGE¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Boolesch
- Beschreibung:
Dieser veraltete Parameter deaktiviert den Vorschaumodus für das Testen von SSO (nach Aktivierung der Verbundauthentifizierung), bevor das Rollout der Funktion an die Benutzer erfolgt:
- Werte:
TRUE: Der Vorschaumodus ist deaktiviert. Dem Benutzer wird auf der Snowflake-Hauptanmeldeseite die Schaltfläche für von Snowflake initiiertes SSO Ihres Identitätsanbieters (wie in SAML_IDENTITY_PROVIDER angegeben) angezeigt.FALSE: Der Vorschaumodus ist aktiviert, und SSO kann mit der folgenden URL getestet werden:Wenn sich Ihr Konto in US West befindet:
https://<Kontobezeichner>.snowflakecomputing.com/console/login?fedpreview=trueWenn sich Ihr Konto in einer anderen Region befindet:
https://<Kontobezeichner>.<Regions-ID>.snowflakecomputing.com/console/login?fedpreview=true
Weitere Informationen dazu finden Sie unter:
- Standard:
FALSE
STATEMENT_QUEUED_TIMEOUT_IN_SECONDS¶
- Typ:
Sitzung und Objekt (für Warehouses)
Kann für Konto » Benutzer » Sitzung festgelegt werden; kann auch für einzelne Warehouses festgelegt werden
- Datentyp:
Zahl
- Beschreibung:
Zeitdauer in Sekunden, die eine SQL-Anweisung (Abfrage, DDL, DML usw.) für ein Warehouse in der Warteschlange verbleibt, bevor sie vom System abgebrochen wird. Dieser Parameter kann zusammen mit dem Parameter MAX_CONCURRENCY_LEVEL verwendet werden, um sicherzustellen, dass ein Warehouse niemals zurückgestellt wird.
Der Parameter kann auf verschiedenen Ebenen der Sitzungshierarchie festgelegt werden (für Konto, Benutzende und Sitzung). Wenn der Parameter auf mehr als einer Ebene festgelegt ist, bestimmen die unter Sitzungsparameter beschriebenen Regeln, welcher Wert verwendet wird.
Der Parameter kann auch so festgelegt werden, dass ein einzelnes Warehouse die Laufzeit aller SQL-Anweisungen steuert, die vom Warehouse verarbeitet werden. Wenn der Parameter sowohl in der Sitzungshierarchie als auch im Warehouse festgelegt ist, ist das Timeout der niedrigste Nicht-Null-Wert der beiden Parameter.
Angenommen, der Parameter ist auf verschiedenen Ebenen auf die folgenden Werte eingestellt:
Benutzende : 10
Sitzung: 20
Warehouse: 15
In diesem Fall wird der Wert des für das Warehouse festgelegten Parameter (15) verwendet, da dieser kleiner ist als der in der Sitzungshierarchie festgelegte Wert (20). Der für Benutzende festgelegte Parameter (10) wird nicht berücksichtigt, da er durch den in der Sitzung festgelegten Parameter überschrieben wird.
Bemerkung
Wenn sowohl STATEMENT_QUEUED_TIMEOUT_IN_SECONDS als auch USER_TASK_TIMEOUT_MS eingestellt sind, hat der Wert von USER_TASK_TIMEOUT_MS Vorrang.
Beim Vergleich der Werte dieser beiden Parameter ist zu beachten, dass STATEMENT_QUEUED_TIMEOUT_IN_SECONDS in Einheiten von Sekunden und USER_TASK_TIMEOUT_MS in Einheiten von Millisekunden angegeben wird.
- Werte:
0bis zu einer beliebigen Zahl (keine Begrenzung) – der Wert0gibt an, dass kein Timeout erzwungen wird. Eine Anweisung verbleibt in der Warteschlange, solange die Warteschlange bestehen bleibt.- Standard:
0(kein Timeout)
STATEMENT_TIMEOUT_IN_SECONDS¶
- Typ:
Sitzung und Objekt (für Warehouses)
Kann für Konto » Benutzer » Sitzung festgelegt werden; kann auch für einzelne Warehouses festgelegt werden
- Datentyp:
Zahl
- Beschreibung:
Zeitdauer in Sekunden, nach der eine laufende SQL-Anweisung (Abfrage, DDL, DML usw.) vom System abgebrochen wird.
Der Parameter kann auf verschiedenen Ebenen der Sitzungshierarchie festgelegt werden (für Konto, Benutzende und Sitzung). Wenn der Parameter auf mehr als einer Ebene festgelegt ist, bestimmen die unter Sitzungsparameter beschriebenen Regeln, welcher Wert verwendet wird.
Der Parameter kann auch so festgelegt werden, dass ein einzelnes Warehouse die Laufzeit aller SQL-Anweisungen steuert, die vom Warehouse verarbeitet werden. Wenn der Parameter sowohl in der Sitzungshierarchie als auch im Warehouse festgelegt ist, ist das Timeout der niedrigste Nicht-Null-Wert der beiden Parameter.
Angenommen, der Parameter ist auf verschiedenen Ebenen auf die folgenden Werte eingestellt:
Benutzende : 10
Sitzung: 20
Warehouse: 15
In diesem Fall wird der Wert des für das Warehouse festgelegten Parameter (15) verwendet, da dieser kleiner ist als der in der Sitzungshierarchie festgelegte Wert (20). Der für Benutzende festgelegte Parameter (10) wird nicht berücksichtigt, da er durch den in der Sitzung festgelegten Parameter überschrieben wird.
Wenn sowohl USER_TASK_TIMEOUT_MS als auch STATEMENT_TIMEOUT_IN_SECONDS festgelegt sind, ist das Timeout der niedrigste Nicht-Null-Wert der beiden Parameter. Beim Vergleich der Werte dieser beiden Parameter ist zu beachten, dass STATEMENT_TIMEOUT_IN_SECONDS in Einheiten von Sekunden festgelegt wird, während USER_TASK_TIMEOUT_MS Einheiten von Millisekunden verwendet.
Die Parametereinstellung gilt für die gesamte Zeit, die die Anweisung benötigt, einschließlich für Warteschlangenzeit, Sperrzeit, Ausführungszeit, Kompilierungszeit usw. Sie gilt für die gesamte Zeit, die die Anweisung benötigt, und nicht nur für die Ausführungszeit des Warehouse.
- Werte:
0bis604800(7 Tage) – der Wert0gibt an, dass der maximale Timeout-Wert erzwungen wird.- Standard:
172800(2 Tage)
STORAGE_SERIALIZATION_POLICY¶
- Typ:
Objekt (für Datenbanken, Schemas und Apache Iceberg™-Tabellen) — Kann eingestellt werden für Konto » Datenbank » Schema » Iceberg-Tabelle
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Legt die Speicherserialisierungsrichtlinie für Snowflake-verwaltete Apache Iceberg™-Tabellen fest.
- Werte:
COMPATIBLE: Snowflake führt eine Codierung und Komprimierung durch, die die Interoperabilität mit Computing-Engines von Drittanbietern sicherstellt.OPTIMIZED: Snowflake führt die Codierung und Komprimierung aus, um eine optimale Tabellenperformance in Snowflake sicherzustellen.- Standard:
OPTIMIZED
STRICT_JSON_OUTPUT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Dieser Parameter gibt an, ob die JSON-Ausgabe in einer Sitzung mit dem allgemeinen Standard kompatibel ist (wie auf http://json.org beschrieben).
Snowflake erlaubt standardmäßig JSON-Eingaben, die nicht standardmäßige Werte enthalten. Diese nicht standardmäßigen Werte können jedoch dazu führen, dass Snowflake JSON ausgibt, das mit anderen Plattformen und Sprachen nicht kompatibel ist. Wenn dieser Parameter aktiviert ist, wird sichergestellt, dass die JSON-Ausgabe von Snowflake gültig/kompatibel ist.
- Werte:
TRUE: Die strikte JSON-Ausgabe ist aktiviert und setzt folgendes Verhalten durch:Fehlende und undefinierte Werte in der Eingabe werden JSON NULL zugeordnet.
Unendliche numerische Werte in der Eingabe (Infinity, -Infinity, NaN usw.), werden Zeichenfolgen mit gültigen JavaScript-Darstellungen zugeordnet. Dies ermöglicht die Kompatibilität mit JavaScript und die Umwandlung dieser Werte in numerische Werte.
FALSE: Die strikte JSON-Ausgabe ist nicht aktiviert.- Standard:
FALSE
Beispiel:
Nicht standardmäßige JSON-Eingabe |
Parameter auf |
Parameter auf |
|
|---|---|---|---|
|
Ausgaben: |
|
|
|
Ausgaben: |
|
|
|
Ausgaben: |
|
|
|
Ausgaben: |
|
|
SUSPEND_TASK_AFTER_NUM_FAILURES¶
- Typ:
Objekt (für Datenbanken, Schemas und Aufgaben) – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Anzahl der nacheinander fehlgeschlagenen Aufgabenausführungen, nach denen eine eigenständige Aufgabe oder die Stammaufgabe eines Task-Graphen automatisch angehalten wird. Zu den fehlgeschlagenen Aufgabenausführungen zählen solche, bei denen der SQL-Code im Textteil der Aufgabe entweder zu einem Benutzerfehler oder zu einem Timeout führt. Aufgabenausführungen, die übersprungen oder abgebrochen werden oder aufgrund eines Systemfehlers fehlschlagen, gelten als „unbestimmt“ und werden bei der Zählung der fehlgeschlagenen Aufgabenausführungen nicht berücksichtigt.
Wenn der Parameter auf
0gesetzt ist, wird die fehlgeschlagene Aufgabe nicht automatisch angehalten.Wenn der Parameter auf einen Wert größer als
0gesetzt wird, gilt für Ausführungen von eigenständigen Aufgaben bzw. von Stammaufgaben eines Task-Graphen das folgende Verhalten:Eine eigenständige Aufgabe wird automatisch angehalten, wenn die angegebene Anzahl aufeinanderfolgender Aufgabenausführungen entweder fehlschlägt oder eine Zeitüberschreitung verursacht.
Eine Stammaufgabe wird nach der angegebene Anzahl von aufeinanderfolgenden Ausführungen automatisch angehalten, wenn eine beliebige Einzelaufgabe im Task-Graphen fehlschlägt oder eine Zeitüberschreitung aufweist, nachdem alle
TASK_AUTO_RETRY_ATTEMPTSfür diese Aufgabe ausgeführt wurden.Wenn beispielsweise für eine Stammaufgabe
SUSPEND_TASK_AFTER_NUM_FAILURESauf 3 festgelegt ist und sie eine untergeordnete Aufgabe hat, für dieTASK_AUTO_RETRY_ATTEMPTSauf 3 festgelegt ist, dann wird die Stammaufgabe ausgesetzt, nachdem diese untergeordnete Aufgabe 9-mal hintereinander fehlgeschlagen ist.
Der Standardwert für den Parameter ist auf
10gesetzt, was bedeutet, dass die Aufgabe nach 10 aufeinanderfolgenden fehlgeschlagenen Aufgabenausführungen automatisch angehalten wird.Wenn Sie den Parameterwert explizit auf Konto-, Datenbank- oder Schemaebene festlegen, wird die Änderung bei der nächsten geplanten Ausführung der im geänderten Objekt enthaltenen Aufgaben wirksam (einschließlich aller untergeordneten Aufgaben einer gerade aktiven Task-Graph-Ausführung).
Durch das Anhalten einer eigenständigen Aufgabe wird der Zähler für die fehlgeschlagenen Aufgabenausführungen zurückgesetzt. Wenn Sie die Stammaufgabe eines Task-Graphen anhalten, wird der Zähler für jede Aufgabe im Task-Graphen zurückgesetzt.
- Werte:
0– Keine Obergrenze.- Standard:
10
TASK_AUTO_RETRY_ATTEMPTS¶
- Typ:
Objekt (für Datenbanken, Schemas und Aufgaben) – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Ganzzahl (Integer)
- Beschreibung:
Gibt die Anzahl der automatischen Wiederholungsversuche für den Task-Graphen an. Wenn ein Task-Graph mit Status
FAILEDabgeschlossen wird, kann Snowflake die Ausführung des Task-Graphen automatisch ab der letzten fehlgeschlagenen Aufgabe im Task-Graphen erneut versuchen. Zu den fehlgeschlagenen Aufgabenausführungen zählen solche, bei denen der SQL-Code im Textteil der Aufgabe entweder zu einem Benutzerfehler oder zu einem Timeout führt. Aufgabenläufe, die übersprungen oder abgebrochen werden, gelten als unbestimmt und werden bei der Zählung der fehlgeschlagenen Aufgabenläufe nicht berücksichtigt.Die automatische Wiederholung des Task-Graphen ist standardmäßig deaktiviert. Um dieses Feature zu aktivieren, setzen Sie
TASK_AUTO_RETRY_ATTEMPTSauf einen Wert größer als0.Wenn Sie den Parameterwert auf Konto-, Datenbank- oder Schemaebene festlegen, wird die Änderung bei der nächsten geplanten Ausführung der im geänderten Objekt enthaltenen Tasks wirksam.
- Werte:
0– Keine Obergrenze.- Standard:
0
TIMESTAMP_DAY_IS_ALWAYS_24H¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob die DATEADD-Funktion (und ihre Aliasnamen) bei Ausdrücken, die sich über mehrere Tage erstrecken, für einen Tag immer genau 24 Stunden berücksichtigt.
- Werte:
TRUE: Ein Tag hat immer genau 24 Stunden.FALSE: Ein Tag hat nicht immer 24 Stunden.- Standard:
FALSE
Wichtig
Bei Einstellung auf TRUE kann die tatsächliche Tageszeit nicht beibehalten werden, wenn die Sommerzeit (DST) gilt. Beispiel:
TIMESTAMP_INPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Eingabeformat für den Datentypalias TIMESTAMP an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat oder
AUTO(
AUTOgibt an, dass Snowflake versucht, das Format der im System gespeicherten Zeitstempel während der Sitzung automatisch zu ermitteln.)- Standard:
AUTO
TIMESTAMP_LTZ_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentyp TIMESTAMP_LTZ an. Wenn CSV_TIMESTAMP_FORMAT nicht festgelegt ist, wird das TIMESTAMP_LTZ_OUTPUT_FORMAT beim Herunterladen von CSV-Dateien verwendet. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat
- Standard:
Keine
TIMESTAMP_NTZ_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentyp TIMESTAMP_NTZ an. Wenn CSV_TIMESTAMP_FORMAT nicht festgelegt ist, wird das TIMESTAMP_NTZ_OUTPUT_FORMAT beim Herunterladen von CSV-Dateien verwendet. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat
- Standard:
YYYY-MM-DD HH24:MI:SS.FF3
TIMESTAMP_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentypalias TIMESTAMP an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat
- Standard:
YYYY-MM-DD HH24:MI:SS.FF3 TZHTZM
TIMESTAMP_TYPE_MAPPING¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Variation TIMESTAMP_* an, der der Aliasname des Datentyps TIMESTAMP zugeordnet ist.
- Werte:
TIMESTAMP_LTZ,TIMESTAMP_NTZoderTIMESTAMP_TZ- Standard:
TIMESTAMP_NTZ
TIMESTAMP_TZ_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentyp TIMESTAMP_TZ an. Wenn CSV_TIMESTAMP_FORMAT nicht festgelegt ist, wird das TIMESTAMP_TZ_OUTPUT_FORMAT beim Herunterladen von CSV-Dateien verwendet. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitstempelformat
- Standard:
Keine
TIMEZONE¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Gibt die Zeitzone für die Sitzung an.
- Werte:
Sie können einen Zeitzonennamen oder einen Verknüpfungsnamen aus Release 2025b der IANA-Zeitzonendatenbank angeben (z. B.
America/Los_Angeles,Europe/London,UTC,Etc/GMTusw.).- Standard:
America/Los_Angeles
Bemerkung
Bei Zeitzonennamen wird zwischen Groß-/Kleinschreibung unterschieden. Außerdem müssen sie in einfache Anführungszeichen gesetzt werden (z. B.
'UTC').Snowflake bietet keine Unterstützung für die meisten Zeitzonen abkürzungen (z. B.
PDT,ESTusw.), da sich eine bestimmte Abkürzung auf mehrere verschiedenen Zeitzonen beziehen kann. So kann sichCSTbeispielsweise auf die „Central Standard Time“ in Nordamerika (UTC-6), die „Cuba Standard Time“ (UTC-5) und die „China Standard Time“ (UTC+8) beziehen.
TIME_INPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Eingabeformat für den Datentyp TIME an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitformat oder
AUTO(
AUTOgibt an, dass Snowflake versucht, das Format der im System gespeicherten Zeiten während der Sitzung automatisch zu ermitteln.)- Standard:
AUTO
TIME_OUTPUT_FORMAT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt das Anzeigeformat für den Datentyp TIME an. Weitere Informationen dazu finden Sie unter Eingabe- und Ausgabeformate für Datum und Uhrzeit.
- Werte:
Jedes gültige, unterstützte Zeitformat
- Standard:
HH24:MI:SS
TRACE_LEVEL¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
Objekt (für Datenbanken, Schemas, gespeicherte Prozeduren und UDFs) – Kann festgelegt werden für Konto » Datenbank » Schema » Prozedur und Konto » Datenbank » Schema » Funktion
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Steuert, wie Ablaufverfolgungsereignisse in die Ereignistabelle aufgenommen werden. Weitere Informationen zu Ablaufverfolgungsebenen finden Sie unter Einstellung der Grade für Protokollierung, Metriken und Ablaufverfolgung.
- Werte:
ALWAYS: Alle Bereiche (Spans) und Ablaufverfolgungsereignisse werden in der Ereignistabelle erfasst.ON_EVENT: Ablaufverfolgungsereignisse werden nur in der Ereignistabelle erfasst, wenn Ereignisse explizit durch die gespeicherten Prozeduren oder UDFs hinzugefügt werden.OFF: Es werden keine Bereiche (Spans) und Ablaufverfolgungsereignisse in der Ereignistabelle erfasst.- Standard:
OFF
Bemerkung
Beim Verfolgen von Ereignissen müssen Sie auch den Parameter LOG_LEVEL auf einen der unterstützten Werte setzen.
TRANSACTION_ABORT_ON_ERROR¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
BOOLEAN
- Beschreibung:
Gibt die Aktion an, die ausgeführt werden soll, wenn eine Anweisung, die innerhalb einer Nicht-Autocommit-Transaktion ausgegeben wurde, mit einem Fehler zurückgegeben wird.
- Werte:
TRUE: Die Nicht-Autocommit-Transaktion wird abgebrochen. Alle innerhalb dieser Transaktion ausgegebenen Anweisungen schlagen fehl, bis eine Commit- oder Rollback-Anweisung ausgeführt wird, um diese Transaktion abzuschließen.FALSE: Die Nicht-Autocommit-Transaktion wird nicht abgebrochen.- Standard:
FALSE
TRANSACTION_DEFAULT_ISOLATION_LEVEL¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Isolationsebene für Transaktionen in der Benutzersitzung an.
- Werte:
READ COMMITTED(nur aktuell unterstützter Wert)- Standard:
READ COMMITTED
TWO_DIGIT_CENTURY_START¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zahl
- Beschreibung:
Gibt das Jahr des „Jahrhundertanfangs“ für zweistellige Jahre an (d. h. das früheste Jahr, das solche Daten darstellen können). Dieser Parameter verhindert mehrdeutige Datumsangaben beim Importieren oder Konvertieren von Daten mit der Datumsformatkomponente
YY(Jahre, die als zweistellige Ziffern dargestellt werden).- Werte:
1900bis2100(jeder Wert außerhalb dieses Bereichs gibt einen Fehler zurück)- Standard:
1970
Beispiel:
Jahr |
Parameter auf |
Parameter auf |
Parameter auf |
Parameter auf |
Parameter auf |
|
|---|---|---|---|---|---|---|
|
wird zu: |
|
|
|
|
|
|
wird zu: |
|
|
|
|
|
|
wird zu: |
|
|
|
|
|
|
wird zu: |
|
|
|
|
|
UNSUPPORTED_DDL_ACTION¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Bestimmt, ob ein für eine Einschränkungseigenschaft nicht unterstützter (nicht standardmäßiger) Wert einen Fehler zurückgibt.
- Werte:
IGNORE: Snowflake gibt keinen Fehler für nicht unterstützte Werte zurück.FAIL: Snowflake gibt einen Fehler für nicht unterstützte Werte zurück.- Standard:
IGNORE
Wichtig
Dieser Parameter bestimmt nicht, ob die Einschränkung erstellt wird. Snowflake erstellt keine Einschränkungen mit nicht unterstützten Werten, unabhängig davon, wie dieser Parameter festgelegt ist.
Weitere Informationen dazu finden Sie unter Einschränkungseigenschaften.
USE_CACHED_RESULT¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Boolesch
- Beschreibung:
Gibt an, ob persistierte Abfrageergebnisse, falls verfügbar, beim Senden einer übereinstimmenden Abfrage wiederverwendet werden sollen.
- Werte:
TRUE: Wenn eine Abfrage gesendet wird, sucht Snowflake nach übereinstimmenden Abfrageergebnissen für zuvor ausgeführte Abfragen. Wenn ein übereinstimmendes Ergebnis vorliegt, wird das Ergebnis verwendet, anstatt die Abfrage auszuführen. Dies kann dazu beitragen, die Abfragezeit zu verkürzen, da Snowflake das Ergebnis direkt aus dem Cache abruft.FALSE: Snowflake führt jede Abfrage beim Senden aus, unabhängig davon, ob ein übereinstimmendes Abfrageergebnis vorhanden ist.- Standard:
TRUE
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE¶
- Typ:
Objekt (für Datenbanken, Schemas und Aufgaben) – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Zeichenfolge (String)
- Beschreibung:
Gibt die Größe der Computeressourcen an, die für die erstmalige Ausführung der Aufgabe bereitgestellt werden sollen, bevor ein Aufgabenverlauf für Snowflake verfügbar ist, um eine ideale Größe zu ermitteln. Sobald eine Aufgabe mehrmals erfolgreich ausgeführt wurde, ignoriert Snowflake diese Parametereinstellung. Wenn der Aufgabenverlauf für eine bestimmte Aufgabe nicht verfügbar ist, kehren die Computeressourcen zu dieser ursprünglichen Größe zurück.
Bemerkung
Dieser Parameter gilt nur für serverlose Aufgaben.
Die Größe entspricht den Computeressourcen, die beim Erstellen eines Warehouses verfügbar sind. Wenn der Parameter weggelassen wird, werden die ersten Ausführungen der Aufgabe mit einem mittelgroßen (
MEDIUM) Warehouse ausgeführt.Sie können die Anfangsgröße von einzelnen Aufgaben ändern (mit ALTER TASK), nachdem die Aufgabe erstellt und bevor sie einmal erfolgreich ausgeführt wurde. Eine Änderung des Parameters nach Start der ersten Ausführung dieser Aufgabe hat keine Auswirkungen auf die Computeressourcen für aktuelle oder zukünftige Aufgabenausführungen.
Beachten Sie, dass das Anhalten und Fortsetzen einer Aufgabe nicht den Aufgabenverlauf entfernt, der zur Größenbestimmung der benötigten Computeressourcen verwendet wurde. Der Aufgabenverlauf wird nur entfernt, wenn die Aufgabe neu erstellt wird (mit der Syntax CREATE OR REPLACETASK).
- Werte:
Jede traditionelle Warehouse-Größe:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. Die maximale Größe istX2LARGE.Unterstützt auch die Syntax:
XXLARGE.- Standard:
MEDIUM
USER_TASK_MINIMUM_TRIGGER_INTERVAL_IN_SECONDS¶
- Typ:
Objekt (für Datenbanken, Schemas und Aufgaben) – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Zahl
- Beschreibung:
Legt fest, wie oft eine ausgelöste Aufgabe ausgeführt werden kann (in Sekunden). Wenn eine Aufgabe während der Ausführung erneut ausgelöst wird, wartet Snowflake die angegebene Anzahl von Sekunden (nachdem die vorherige Ausführung geplant wurde), bevor die nächste Ausführung gestartet wird.
Wenn Sie diesen Parameter für eine Aufgabe auf mehr als 12 Stunden einstellen, wird die Aufgabe alle 12 Stunden ausgeführt.
- Werte:
10-604800(1 Woche).- Standard:
30
USER_TASK_TIMEOUT_MS¶
- Typ:
Objekt (für Datenbanken, Schemas und Aufgaben) – Kann festgelegt werden für Konto » Datenbank » Schema » Aufgabe
- Datentyp:
Zahl
- Beschreibung:
Gibt das Zeitlimit für die einzelne Ausführung der Aufgabe an, bevor das Zeitlimit überschritten wird (in Millisekunden).
Bemerkung
Bevor Sie das Zeitlimit für Aufgaben erheblich erhöhen, sollten Sie prüfen, ob die SQL-Anweisungen in den Aufgabendefinitionen optimiert werden können (entweder durch Umschreiben der Anweisungen oder durch Verwendung von gespeicherten Prozeduren) oder ob die Warehouse-Größe für Aufgaben mit benutzerverwalteten Computeressourcen erhöht werden sollte.
Wenn sowohl STATEMENT_TIMEOUT_IN_SECONDS als auch USER_TASK_TIMEOUT_MS eingestellt sind, ist das Timeout der niedrigste Wert der beiden Parameter, der nicht Null ist.
Wenn sowohl STATEMENT_QUEUED_TIMEOUT_IN_SECONDS als auch USER_TASK_TIMEOUT_MS eingestellt sind, hat der Wert von USER_TASK_TIMEOUT_MS Vorrang.
Weitere Informationen zu USER_TASK_TIMEOUT_MS finden Sie unter CREATE TASK…USER_TASK_TIMEOUT.
- Werte:
0-604800000(7 Tage). Ein Wert von0gibt an, dass der maximale Timeout-Wert durchgesetzt wird.- Standard:
3600000(1 Stunde)
USE_WORKSPACES_FOR_SQL¶
- Typ:
Konto – Kann nur für Konto festgelegt werden
- Datentyp:
Zeichenfolge (Konstante)
- Beschreibung:
Steuert, ob der Arbeitsbereichs-Editor die SQL-Standardbearbeitungsumgebung für das Konto ist.
- Werte:
always: Stellen Sie den kontoweiten Standardeditor für alle Benutzende auf „Arbeitsbereiche“ ein.never: Gehen Sie zum vorherigen Editor zurück und ignorieren Sie vorübergehend von Snowflake verwaltete BCR, mit denen „Arbeitsbereiche“ als Standardeinstellung verwendet werden:Weitere Informationen dazu finden Sie unter Workspaces.
WEEK_OF_YEAR_POLICY¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zahl
- Beschreibung:
Gibt an, wie die Wochen in einem bestimmten Jahr berechnet werden.
- Werte:
0: Die verwendete Semantik entspricht der ISO-Semantik, bei der eine Woche zu einem bestimmten Jahr gehört, wenn sich mindestens 4 Tage dieser Woche in diesem Jahr befinden.1: Der 1. Januar liegt in der ersten Woche des Jahres und der 31. Dezember in der letzten Woche des Jahres.- Standard:
0(ISO-ähnliche Verhaltensweise)
Tipp
1 ist der häufigste Wert, basierend auf dem Feedback, das wir erhalten haben. Weitere Informationen, einschließlich Beispiele, finden Sie unter Kalenderwochen und Wochentage.
WEEK_START¶
- Typ:
Sitzung – Kann festgelegt werden für Konto » Benutzer » Sitzung
- Datentyp:
Zahl
- Beschreibung:
Gibt den ersten Tag der Woche an (wird von wochenbezogenen Datumsfunktionen verwendet).
- Werte:
0: Frühere Snowflake-Verhaltensweise wird verwendet (d. h. ISO-ähnliche Semantik)1(Montag) bis7(Sonntag): Alle wochenbezogenen Funktionen verwenden Wochen, die am angegebenen Wochentag beginnen.- Standard:
0(frühere Snowflake-Verhaltensweise)
Tipp
1 ist der häufigste Wert, basierend auf dem Feedback, das wir erhalten haben. Weitere Informationen, einschließlich Beispiele, finden Sie unter Kalenderwochen und Wochentage.