Analysieren von Daten mit Fensterfunktionen¶
Dieses Thema enthält einführende konzeptionelle Informationen über die Fensterfunktionen. Wenn Sie bereits mit der Verwendung von Fensterfunktionen vertraut sind, werden Ihnen die folgenden Referenzinformationen vielleicht ausreichen:
Fensterfunktionen, die eine Liste der Funktionen und Verknüpfungen zu den einzelnen Funktionsbeschreibungen enthält.
Syntax und Verwendung von Fensterfunktionen, die allgemeine Syntaxregeln für alle Fensterfunktionen beschreibt.
Einführung¶
Eine Fensterfunktion ist eine analytische SQL-Funktion, die auf einer Gruppe von zusammenhängenden Zeilen, einer sogenannten Partition, operiert. Eine Partition ist in der Regel eine logische Gruppe von Zeilen entlang einer bekannten Dimension, wie Produktkategorie, Speicherort, Zeitraum oder Geschäftseinheit. Funktionsergebnisse werden für jede Partition in Bezug auf einen impliziten oder expliziten Fensterrahmen berechnet. Ein Fensterrahmen ist ein fester oder variabler Satz von Zeilen in Bezug auf die aktuelle Zeile. Die aktuelle Zeile ist eine einzelne Eingabezeile, für die das Funktionsergebnis gerade berechnet wird. Funktionsergebnisse werden innerhalb jeder Partition Zeile für Zeile berechnet, und jede Zeile im Fensterrahmen ist die aktuelle Zeile.
Die Syntax, die diese Verhaltensweise definiert, ist die OVER-Klausel für die Funktion. In vielen Fällen unterscheidet die OVER-Klausel eine Fensterfunktion von einer regulären SQL-Funktion mit dem gleichen Namen (wie AVG oder SUM). Die OVER-Klausel besteht aus drei Hauptkomponenten:
Eine PARTITION BY-Klausel
Eine ORDER BY-Klausel
Spezifikation eines Fensterrahmens
Je nach Funktion oder Abfrage können alle diese Komponenten optional sein; eine Fensterfunktion mit einer leeren OVER-Klausel ist gültig: OVER(). In den meisten analytischen Abfragen erfordern Fensterfunktionen jedoch eine oder mehrere explizite OVER-Klauselkomponenten. Sie können eine Fensterfunktion in jedem Kontext aufrufen, der andere SQL Funktionen unterstützt. In den folgenden Abschnitten werden die Konzepte hinter den Fensterfunktionen näher erläutert und einige einführende Beispiele vorgestellt. Vollständige Informationen zur Syntax finden Sie unter Syntax und Verwendung von Fensterfunktionen.
Fensterfunktionen versus Aggregatunktionen¶
Eine gute Möglichkeit, sich mit Fensterfunktionen vertraut zu machen, ist der Vergleich von regulären Aggregatfunktionen mit ihren Gegenstücken, den Fensterfunktionen. Mehrere standardmäßige Aggregatfunktionen, wie SUM, COUNT und AVG, haben entsprechende Fensterfunktionen mit demselben Namen. Um die beiden zu unterscheiden, beachten Sie Folgendes:
Bei einer Aggregatfunktion besteht die Eingabe aus einer Gruppe von Zeilen und die Ausgabe aus genau einer Zeile.
Bei einer Fensterfunktion besteht die Eingabe aus jeder Zeile innerhalb einer Partition, und die Ausgabe aus einer Zeile pro Eingabezeile.
Die Aggregatfunktion SUM zum Beispiel gibt einen einzigen Gesamtwert für alle eingegebenen Zeilen zurück, während eine Fensterfunktion mehrere Gesamtwerte zurückgibt: einen für jede Zeile (die aktuelle Zeile) im Verhältnis zu allen anderen Zeilen in der Partition.
Um zu sehen, wie das funktioniert, erstellen und laden Sie zunächst die Tabelle menu_items, die die Kosten und Preise für die Foodtruck-Menüangebote enthält. Verwenden Sie eine reguläre Funktion AVG, um die durchschnittlichen Kosten für Speisen in verschiedenen Kategorien zu ermitteln:
Beachten Sie, dass die Funktion ein gruppiertes Ergebnis für avg_cogs zurückgibt.
Alternativ können Sie auch eine OVER-Klausel angeben und AVG als Fensterfunktion verwenden. (Das Ergebnis ist auf 15 Zeilen der 60-zeiligen Tabelle beschränkt.)
Beachten Sie, dass die Funktion einen Durchschnitt für jede Zeile in jeder Partition zurückgibt und die Berechnung zurücksetzt, wenn sich der Wert der Partitionierungsspalte ändert. Um den Wert der Fensterfunktion deutlicher zu machen, fügen Sie der Funktionsdefinition eine ORDER BY-Klausel und einen Fensterrahmen hinzu. Geben Sie neben den Durchschnittswerten auch die Rohwerte von menu_cogs_usd zurück, damit Sie sehen können, wie die spezifischen Berechnungen funktionieren. Diese Abfrage ist ein einfaches Beispiel für einen „gleitenden Durchschnitt“, eine gleitende Berechnung, die von einem expliziten Fensterrahmen abhängt. Weitere Beispiele dieser Art finden Sie unter Analysieren von Zeitreihendaten.
Der Fensterrahmen passt die Durchschnittsberechnungen so an, dass nur die aktuelle Zeile und die beiden darauf folgenden Zeilen (innerhalb der Partition) berücksichtigt werden. Die letzte Zeile in einer Partition hat keine nachfolgenden Zeilen, sodass der Durchschnitt für die letzte Beverage-Zeile beispielsweise dem entsprechenden menu_cogs_usd-Wert entspricht (0.65). Die Ausgabe der Fensterfunktion hängt von der einzelnen Zeile ab, die an die Funktion übergeben wird, und den Werten der anderen Zeilen, die für den Fensterrahmen in Frage kommen.
Bemerkung
Bei Verwendung von Fensterfunktionen mit ORDER BY-Klauseln sorgen dafür, dass die Reihenfolge deterministisch ist. Wenn mehrere Zeilen denselben Wert für ORDER BY-Spalten haben, fügen Sie zusätzliche Spalten als Unterscheidungskriterium hinzu, um konsistente, vorhersehbare Ergebnisse über alle Abfrageausführungen hinweg sicherzustellen. In diesem Beispiel wurde menu_cogs_usd als Unterscheidungskriterium hinzugefügt, da mehrere Zeilen denselben Wert für menu_price_usd haben können.
Sortieren der Zeilen für Fensterfunktionen¶
Das vorherige Beispiel der Funktion AVG verwendet eine Klausel ORDER BY innerhalb der Definition der Funktion, um sicherzustellen, dass der Fensterrahmen Daten unterliegt, die sortiert sind (in diesem Fall nach menu_price_usd).
Zwei Arten von Fensterfunktionen erfordern eine ORDER BY-Klausel:
Mit Fensterfunktionen mit expliziten Fensterrahmen können Sie fortlaufende Operationen auf Teilmengen der Zeilen in jeder Partition ausführen, wie z. B. die Berechnung einer laufenden Summe oder eines gleitenden Durchschnitts. Ohne eine ORDER BY-Klausel ist der Fensterrahmen bedeutungslos; die Menge der „vorangehenden“ und „nachfolgenden“ Zeilen muss deterministisch sein.
Ranking-Fensterfunktionen, wie CUME_DIST, RANK und DENSE_RANK, die Informationen basierend auf dem „Rangs“ einer Zeile zurückgeben. Wenn Sie beispielsweise Läden in absteigender Reihenfolge nach dem Gewinn pro Monat einstufen, wird der Laden mit dem höchsten Gewinn auf Rang 1 eingestuft, der Laden mit dem zweitgrößten Gewinn auf Rang 2 und so weiter.
Die ORDER BY-Klausel für eine Fensterfunktion unterstützt dieselbe Syntax wie die ORDER BY-Hauptklausel, die die endgültigen Ergebnisse einer Abfrage sortiert. Diese beiden ORDER BY-Klauseln sind getrennt und unterschiedlich. Eine ORDER BY-Klausel innerhalb einer OVER Klausel steuert nur die Reihenfolge, in der die Fensterfunktion die Zeilen verarbeitet; sie steuert nicht die Ausgabe der gesamten Abfrage. In vielen Fällen werden Ihre Abfragen von Fensterfunktionen beide Arten von ORDER BY-Klauseln enthalten.
Bemerkung
Die ORDER BY-Klausel für Fensterfunktionen unterstützt nicht die Verwendung einer Ordinalposition, wie z. B. OVER (PARTITION BY 1 ORDER BY 2). In diesem Kontext wird 2 als Konstante 2 interpretiert; sie bezieht sich nicht auf die zweite Spalte in der Abfrage.
Die PARTITION BY- und ORDER BY-Klauseln innerhalb der OVER-Klausel sind ebenfalls unabhängig. Sie können die ORDER BY-Klausel ohne die PARTITION BY-Klausel verwenden und umgekehrt.
Prüfen Sie die Syntax für die einzelnen Fensterfunktionen, bevor Sie Abfragen schreiben. Die Syntaxanforderungen der ORDER BY-Klausel variieren je nach Funktion:
Einige Fensterfunktionen erfordern eine ORDER BY-Klausel.
Einige Fensterfunktionen verwenden eine ORDER BY-Klausel, wenn eine vorhanden ist, benötigen diese jedoch nicht.
Einige Fensterfunktionen erlauben keine ORDER BY-Klausel.
Einige Fensterfunktionen interpretieren eine ORDER BY-Klausel als einen impliziten Fensterrahmen.
Vorsicht
Im Allgemeinen ist SQL eine explizite Sprache, die nur wenige implizite Klauseln enthält. Bei einigen Fensterfunktionen impliziert die ORDER BY-Klausel jedoch einen Fensterrahmen. Weitere Details dazu finden Sie unter Nutzungshinweise für Fensterrahmen.
Da ein Verhalten, das eher implizit als explizit ist, zu schwer verständlichen Ergebnissen führen kann, empfiehlt Snowflake, Fensterrahmen explizit zu deklarieren.
Verwenden verschiedener Arten von Fensterrahmen¶
Fensterrahmen werden explizit oder implizit definiert. Sie hängen vom Vorhandensein einer ORDER BY-Klausel innerhalb der OVER-Klausel ab:
Für die explizite Syntax des Rahmens siehe
windowFrameClauseunter Syntax. Sie können offene Begrenzungen definieren: vom Anfang der Partition bis zur aktuellen Zeile, von der aktuellen Zeile bis zum Ende der Partition oder vollständig „unbegrenzt“ von Ende zu Ende. Alternativ können Sie auch explizite Offsets (inklusive) verwenden, die sich auf die aktuelle Zeile in der Partition beziehen.Implizite Rahmen werden standardmäßig verwendet, wenn die OVER-Klausel keine
windowFrameClauseenthält. Der Standardrahmen hängt von der jeweiligen Funktion ab. Siehe auch Nutzungshinweise für Fensterrahmen.
Rangbezogene versus zeilenbezogene Fensterrahmen¶
Snowflake unterstützt zwei Haupttypen von Fensterrahmen:
- Zeilenbasiert:
Eine exakte Sequenz von Zeilen gehört zum Rahmen, basierend auf einem physischen Offset von der aktuellen Zeile. Zum Beispiel bedeutet
5 PRECEDINGdie fünf Zeilen vor der aktuellen Zeile. Der Offset muss eine Zahl sein. ROWS-Modus ist inklusive und bezieht sich immer auf die aktuelle Zeile. Wenn die angegebene Anzahl der vorangehenden oder nachfolgenden Zeilen über die Beschränkungen der Partition hinausgeht, behandelt Snowflake den Wert als NULL.Wenn der Rahmen nicht explizit nummeriert ist, sondern offene Grenzen hat, gilt ein ähnlicher physischer Offset. Zum Beispiel bedeutet ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, dass der Rahmen aus allen Zeilen (null oder mehr) besteht, die physisch vor der aktuellen Zeile liegen, sowie der aktuellen Zeile selbst.
- Bereichsbasiert:
Ein logischer Zeilenbereich gehört zum Rahmen, wenn ein Offset vom ORDERBY-Wert für die aktuelle Zeile angegeben wird. Zum Beispiel bedeutet
5 PRECEDINGZeilen mit ORDER BY-Werten, die den ORDER BY-Wert der aktuellen Zeile haben, plus oder minus maximal 5 (plus für DESC Reihenfolge, minus für ASC Reihenfolge). Der Offset-Wert kann eine Zahl oder ein Intervall sein.Wenn der Rahmen keine nummerierten, sondern offene Grenzen hat, gilt ein ähnlicher logischer Offset. Zum Beispiel bedeutet RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, dass der Rahmen aus allen Zeilen besteht, die physisch vor der aktuellen Zeile liegen, der aktuellen Zeile selbst und allen angrenzenden Zeilen, die denselben ORDER BY Wert haben wie die aktuelle Zeile. Bei einem RANGE-Fensterrahmen bedeutet CURRENT ROW nicht die physische Zeile, sondern alle Zeilen, die denselben ORDER BY-Wert haben wie die aktuelle physische Zeile.
Die Unterscheidungen in ROWS BETWEEN- und RANGE BETWEEN-Fensterrahmen sind wichtig, weil Abfragen von Fensterfunktionen sehr unterschiedliche Ergebnisse liefern können, abhängig vom Ausdruck ORDER BY, den Daten in den Tabellen und der genauen Definition des Rahmens. Die folgenden Beispiele verdeutlichen die Unterschiede in der Verhaltensweise.
Vergleich von RANGE BETWEEN und ROWS BETWEEN mit expliziten Offsets¶
Ein rangbezogener Fensterrahmen erfordert eine ORDER BY-Spalte oder einen Ausdruck und eine RANGE BETWEEN-Angabe. Die logische Begrenzung des Fensterrahmens hängt von dem ORDER BY-Wert (eine numerische Konstante oder ein Intervall-Literal) für die aktuelle Zeile ab.
Eine Zeitreihentabelle mit dem Namen heavy_weather ist zum Beispiel wie folgt definiert:
Beispielzeilen in dieser Tabelle sehen wie folgt aus:
Angenommen, eine Abfrage berechnet einen gleitenden 3-Stunden-Durchschnitt (AVG) über die Spalte precip (Niederschlag), unter Verwendung eines nach start_time geordneten Fensterrahmens:
Bei den obigen Beispielzeilen fallen, wenn die aktuelle Zeile 2021-12-30 11:23:00.000 ist (die erste Beispielzeile), nur die nächsten beiden Zeilen in den Rahmen (2021-12-30 11:43:00.000 und 2021-12-30 13:53:00.000). Die nachfolgenden Zeitstempel liegen mehr als 3 Stunden später.
Wenn Sie jedoch den Fensterrahmen auf ein 1-Tages-Intervall ändern, fallen alle Beispielzeilen, die auf die aktuelle Zeile folgen, in den Rahmen, da sie alle Zeitstempel am gleichen Datum haben (2021-12-30):
Wenn Sie diese Syntax von RANGE BETWEEN in ROWS BETWEEN ändern würden, müsste der Rahmen feste Grenzen angeben, die eine exakte Anzahl von Zeilen darstellen: die aktuelle Zeile plus die folgende exakte geordnete Anzahl von Zeilen, z. B. 1, 3 oder 10 Zeilen, unabhängig von den Werten, die der Ausdruck ORDER BY zurückgibt.
Siehe auch Beispiel für RANGE BETWEEN mit expliziten numerischen Offsets.
Vergleichen Sie RANGE BETWEEN und ROWS BETWEEN mit offenen Grenzen¶
Im folgenden Beispiel werden die Ergebnisse verglichen, wenn die folgenden Fensterrahmen für dieselbe Gruppe von Zeilen berechnet werden:
Dieses Beispiel wählt aus einer kleinen Tabelle mit dem Namen menu_items aus. Siehe Erstellen und Laden der „menu_items“-Tabelle.
Die SUM-Fensterfunktion aggregiert die menu_price_usd-Werte für jede menu_category-Partition. Anhand der ROWS BETWEEN-Syntax können Sie leicht erkennen, wie die laufenden Summen innerhalb jeder Partition kumuliert werden.
Wenn die Syntax RANGE BETWEEN mit einer ansonsten identischen Abfrage verwendet wird, sind die Berechnungen zunächst nicht so offensichtlich. Sie hängen von einer anderen Interpretation von aktuelle Zeile ab: die aktuelle Zeile selbst plus alle benachbarten Zeilen, die denselben ORDER BY-Wert haben wie diese Zeile.
Zum Beispiel sind die sum_price-Werte für die zweite und dritte Zeile im Ergebnis beide 8.00, weil der ORDER BY-Wert für diese Zeilen derselbe ist. Diese Verhaltensweise tritt an zwei weiteren Stellen im Resultset auf, wo sum_price nacheinander als 24.00 und 12.00 berechnet wird.
Fensterrahmen für kumulative und gleitende Berechnungen¶
Fensterrahmen sind ein sehr flexibler Mechanismus zur Durchführung verschiedener Arten von analytischen Abfragen, einschließlich kumulativer Berechnungen und gleitender Berechnungen. Um zum Beispiel kumulierte Summen zu erhalten, können Sie einen Fensterrahmen angeben, der an einem festen Punkt beginnt und sich Zeile für Zeile durch die gesamte Partition bewegt:
Ein weiteres Beispiel für diese Art von Rahmen könnte Folgendes sein:
Die Anzahl der Zeilen, die für diese Rahmen in Frage kommen, ist variabel, aber die Anfangs- und Endpunkte der Rahmen sind fixiert. Dabei werden benannte Grenzen anstelle von numerischen oder Intervallgrenzen verwendet.
Wenn Sie möchten, dass die Berechnung der Fensterfunktion über eine bestimmte Anzahl (oder einen bestimmten Bereich) von Zeilen weitergeht, können Sie explizite Offsets verwenden:
In diesem Fall ist das Ergebnis ein gleitender Rahmen, der aus maximal sieben Zeilen besteht (3 + aktuelle Zeile + 3). Ein weiteres Beispiel für diese Art von Rahmen könnte Folgendes sein:
Fensterrahmen können eine Mischung aus benannten Grenzen und expliziten Offsets enthalten.
Gleitende Fensterrahmen¶
Ein gleitender Fensterrahmen ist ein Rahmen mit fester Breite, der entlang der Partitionszeilen „gleitet“ und jedes Mal einen anderen Partitionsausschnitt abdeckt. Die Anzahl der Zeilen im Rahmen bleibt gleich, außer am Anfang oder Ende einer Partition, wo er weniger Zeilen enthalten kann.
Gleitende Fenster werden häufig zur Berechnung von gleitenden Durchschnitten verwendet, die auf einem Intervall fester Größe (z. B. einer Anzahl von Tagen) basieren. Der Durchschnitt gleitet, weil sich die tatsächlichen Werte im Intervall mit der Zeit (oder einem anderen Faktor) ändern, obwohl die Größe des Intervalls konstant ist.
Beispielsweise analysieren Börsenanalysten häufig Aktien, die teilweise auf dem gleitenden 13-Wochen-Durchschnitt des Aktienkurses basieren. Der heutige gleitende Durchschnittspreis ist der Durchschnittspreis am Ende des heutigen Tages und der Preis am Ende jedes Tages in den letzten 13 Wochen. Wenn Aktien an 5 Tagen der Woche gehandelt werden und in den letzten 13 Wochen keine Feiertage verzeichnet wurden, ist der gleitende Durchschnitt der Durchschnittspreis an jedem der letzten 65 Handelstage (einschließlich des heutigen).
Das folgende Beispiel zeigt, was mit einem gleitenden 13-Wochen-Durchschnitt (91 Tage) eines Aktienkurses am letzten Juni-Tag und an den ersten Juli-Tagen passiert:
Am 30. Juni gibt die Funktion den Durchschnittspreis für den Zeitraum 1. April bis 30. Juni (einschließlich) zurück.
Am 1. Juli gibt die Funktion den Durchschnittspreis für den Zeitraum 2. April bis 1. Juli (einschließlich) zurück.
Am 2. Juli gibt die Funktion den Durchschnittspreis für den Zeitraum 3. April bis 2. Juli (einschließlich) zurück.
Das folgende Beispiel verwendet ein kleines (3-tägiges) gleitendes Fenster über die ersten 7 Tage des Monats. In diesem Beispiel wird die Tatsache berücksichtigt, dass die Partition zu Beginn des Zeitraums möglicherweise nicht voll ist:
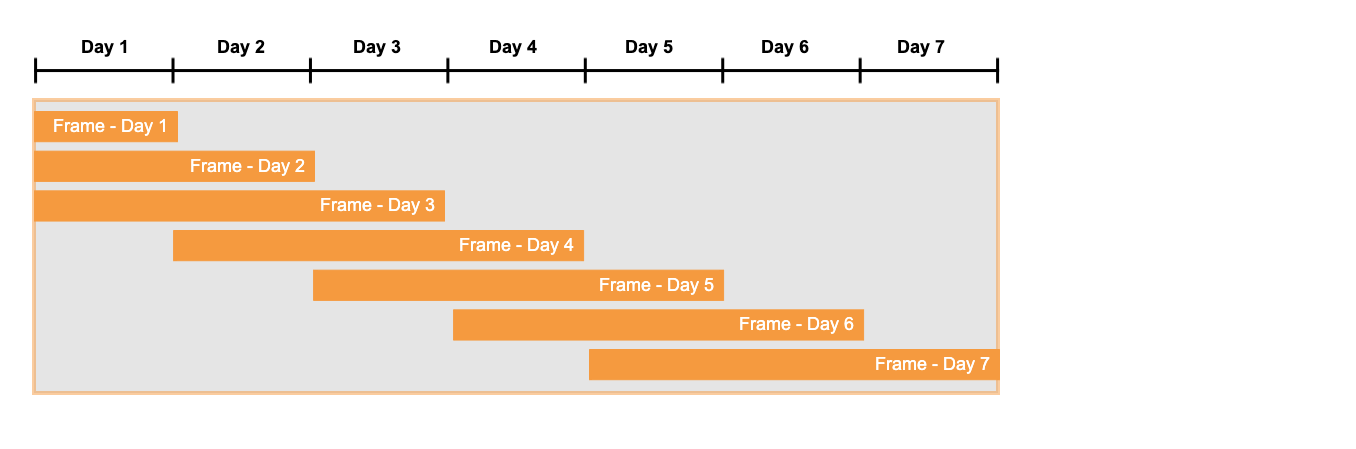
Wie Sie in dem entsprechenden Mockup eines Abfrageergebnisses sehen können, enthält die letzte Spalte die Umsatzsumme der letzten drei Tage. So weist beispielsweise Tag 4 einen Spaltenwert von 36 auf, was die Summe der Umsätze von Tage 2, 3 und 4 (11 + 12 + 13) ist:
Rangbezogene Fensterfunktionen¶
Die Syntax für eine Ranking-Fensterfunktion ist im Wesentlichen dieselbe wie die Syntax für andere Fensterfunktionen. Zu den Funktionen gehören:
Ranking-Fensterfunktionen erfordern die ORDER BY-Klausel innerhalb der OVER-Klausel.
Für einige Ranking-Funktionen, wie z. B. RANK selbst, ist keine Eingabe erforderlich. Bei der RANK-Funktion basiert der zurückgegebene Wert ausschließlich auf der numerischen Rangfolge, die durch die ORDER BY-Klausel innerhalb der OVER-Klausel bestimmt wird. Daher ist es nicht erforderlich, einen Spaltennamen oder einen Ausdruck an die -Funktion zu übergeben.
Die einfachste Ranking-Funktion heißt RANK. Sie können diese Funktion verwenden, um:
Erstellen einer Rangliste der Verkäufer nach Umsatz (Verkäufe) vom höchsten zum niedrigsten Wert.
Erstellen einer Rangliste der Länder auf Basis des Pro-Kopf-BIP (Einkommen pro Person) vom höchsten zum niedrigsten Wert.
Erstellen einer Rangliste der Länder hinsichtlich Luftverschmutzung vom niedrigsten zum höchsten Wert.
Diese Funktion bezeichnet einfach die numerische Rangposition einer Zeile in einer geordneten Menge von Zeilen. Die erste Zeile hat den Rang 1, die zweite den Rang 2 und so weiter. Das folgende Beispiel zeigt die Rangfolge von Vertriebsmitarbeitern auf der Grundlage von Amount Sold:
Die Zeilen müssen bereits sortiert sein, bevor die Ranglisten zugewiesen werden können. Daher müssen Sie eine ORDER BY-Klausel innerhalb der OVER-Klausel verwenden.
Nehmen wir folgendes Beispiel: Sie möchten wissen, wo Ihr Geschäftsgewinn unter den Filialen der Geschäftskette liegt (d. h. ob Ihr Geschäft an erster, zweiter, dritter usw. Stelle steht). In diesem Beispiel wird jedes Geschäft nach seiner Rentabilität in der jeweiligen Stadt geordnet. Die Zeilen sind in absteigender Reihenfolge angeordnet (höchster Gewinn zuerst), sodass der profitabelste Laden den Rang 1 hat:
Bemerkung
Die Spalte net_profit muss nicht als Argument an die Funktion RANK übergeben werden. Stattdessen werden die Eingabezeilen nach net_profit sortiert. Die Funktion RANK muss lediglich die Position der Zeile (1, 2, 3, usw.) innerhalb der Partition zurückgeben.
Die Ausgabe einer Ranking-Funktion ist abhängig von:
Von der einzelnen Zeile, die an die Funktion übergeben wurde.
Die Werte der anderen Zeilen in der Partition.
Die Reihenfolge aller Zeilen in der Partition.
Snowflake bietet mehrere verschiedene Funktionen für das Ranking. Eine Auflistung dieser Funktionen und weitere Einzelheiten zu ihrer Syntax finden Sie unter Fensterfunktionen.
Verwenden Sie die folgende Abfrage, um Ihr Geschäft mit allen anderen Geschäften der Kette zu vergleichen und nicht nur mit anderen Filialen in Ihrer Stadt:
In der folgenden Abfrage wird die erste ORDER BY-Klausel verwendet, um die Verarbeitung durch die Fensterfunktion zu steuern, und die zweite ORDER BY-Klausel, um die Reihenfolge der Ausgabe der gesamten Abfrage zu steuern:
Illustriertes Beispiel¶
Das folgende Beispiel verwendet ein Verkaufsszenario, um die vielen der oben beschriebenen Konzepte zu veranschaulichen:
Angenommen, Sie möchten einen Finanzbericht erstellen, der verschiedene Werte auf Basis der Umsätze der letzten Woche anzeigt:
Tägliche Verkäufe
Rangfolge innerhalb der Woche (d. h. Umsätze von höchstem zu niedrigstem für die Woche)
Bisherige Umsätze dieser Woche (d. h. die „kumulierte Summe“ für alle Tage vom Wochenbeginn bis einschließlich des aktuellen Tages)
Gesamtumsatz der Woche
Gleitender Drei-Tages-Durchschnitt (d. h. der Durchschnitt des aktuellen Tages und der beiden vorangegangenen Tage)
Der Bericht könnte ungefähr wie folgt aussehen:
Die SQL für diese Abfrage ist etwas komplex. Anstatt das Beispiel als einzelne Abfrage anzuzeigen, wird die SQL für die einzelnen Spalten aufgeschlüsselt.
In einem realen Szenario hätten Sie wahrscheinlich Daten aus mehreren Jahren. Um die Summen und Durchschnittswerte für eine bestimmte Datenwoche zu berechnen, müssten wir daher ein Fenster für eine Woche oder einen Filter verwenden, der in etwa wie folgt aussieht:
In diesem Beispiel gehen wir jedoch davon aus, dass die Tabelle nur die Daten der letzten Woche enthält.
Berechnen des Umsatzrankings¶
Die Spalte Rank wird mithilfe der Funktion RANK berechnet:
Obwohl der Zeitraum 7 Tage umfasst, gibt es nur 5 verschiedene Ränge (1, 2, 3, 5, 6). Es gab zwei Gleichstände (für den 3. und den 6. Platz), daher gibt es keine Zeilen mit den Rängen 4 oder 7.
Berechnen der bisherigen Umsätze dieser Woche¶
Die Spalte Sales So Far This Week wird mit SUM als Fensterfunktion mit einem Fensterrahmen berechnet:
Diese Abfrage ordnet die Zeilen nach Datum und berechnet dann für jedes Datum die Umsatzsumme vom Beginn des Fensters bis zum aktuellen Datum (einschließlich).
Berechnen des Gesamtumsatzes dieser Woche¶
Die Spalte Total Sales This Week wird mit SUM berechnet.
Berechnen eines gleitenden Drei-Tage-Durchschnitts¶
Die Spalte 3-Day Moving Average wird mit AVG als Fensterfunktion mit einem Fensterrahmen berechnet:
Der Unterschied zwischen diesem Fensterrahmen und dem zuvor beschriebenen Fensterrahmen ist der Ausgangspunkt: eine feste Begrenzung im Gegensatz zu einem expliziten Offset.
Alle Funktionsbeispiele zusammenfügen¶
Hier ist die endgültige Version der Abfrage, die alle Spalten enthält:
Zusätzliche Beispiele¶
In diesem Abschnitt finden Sie weitere Beispiele für Fensterfunktionen und erfahren, wie die Klauseln PARTITION BY und ORDER BY zusammenwirken.
In diesen Beispielen werden folgende Tabelle und Daten verwendet:
Fensterfunktion mit ORDER BY-Klausel¶
Die ORDERBY-Klausel steuert die Reihenfolge der Daten in jedem Fenster (und jeder Partition, wenn es mehr als eine Partition gibt). Dies ist nützlich, wenn Sie im Laufe der Zeit, in der immer wieder neue Zeilen hinzugefügt werden, eine „aktuelle Summe“ anzeigen möchten.
Eine laufende Summe kann entweder vom Anfang des Fensters bis (inklusive) zur aktuellen Zeile berechnet werden oder von der aktuellen Zeile bis zum Ende des Fensters.
Eine Abfrage kann ein „gleitendes“ Fenster verwenden, bei dem es sich um ein Fenster mit fester Breite handelt, das n angegebene Zeilen relativ zur aktuellen Zeile verarbeitet, beispielsweise die 10 neuesten Zeilen (einschließlich der aktuellen Zeile).
Fensterrahmen mit festen Grenzen¶
Wenn der Fensterrahmen eine feste Begrenzung hat, können die Werte vom Anfang des Fensters bis zur aktuellen Zeile (oder von der aktuellen Zeile bis zum Ende des Fensters) berechnet werden:
Das Abfrageergebnis enthält zusätzliche Kommentare, die zeigen, wie die Spalte CUMULATIVE_SUM_QUANTITY berechnet wurde:
Fensterrahmen mit expliziten Offsets¶
In der Finanzwelt untersuchen Analysten häufig „gleitende Durchschnittswerte“.
Beispielsweise sehen Sie möglicherweise ein Diagramm, in dem die X-Achse die Zeit ist und auf der Y-Achse der Durchschnittspreis einer Aktie in den letzten 13 Wochen angezeigt wird (d. h. der gleitende 13-Wochen-Durchschnitt). In einem Diagramm mit dem gleitenden 13-Wochen-Durchschnitt eines Aktienkurses ist der für den 30. Juni angezeigte Preis nicht der Aktienkurs am 30. Juni, sondern der Durchschnitts-Preis der Aktie über die letzten 13 Wochen bis einschließlich 30. Juni (d. h. für den Zeitraum 1. April bis 30. Juni). Der Wert am 1. Juli ist der Durchschnittspreis für den Zeitraum 2. April bis 1. Juli. Der Wert am 2. Juli ist der Durchschnittspreis für den Zeitraum 3. April bis 2. Juli und so weiter. Jeden Tag addieren wir den aktuellen Tageswert zum gleitenden Durchschnitt und entfernen den ältesten Tageswert. Auf diese Weise werden täglichen Schwankungen ausgeglichen und Trends besser erkennbar.
Gleitende Durchschnitte können unter Verwendung eines gleitenden Fensterrahmens berechnet werden. Der Rahmen hat eine bestimmte Breite in Zeilen. In dem oben genannten Beispiel zum Aktienkurs sind es 13 Wochen (91 Tage), sodass das gleitende Fenster 91 Tage aufweisen würde. Wenn die Messung einmal pro Tag durchgeführt wird (z. B. am Ende des Tages), wäre das Fenster 91 Zeilen „breit“.
So definieren Sie ein Fenster mit einer Breite von 91 Zeilen:
Bemerkung
Der ursprüngliche Fensterrahmen könnte weniger als 91 Tage breit sein. Angenommen, Sie möchten den gleitenden 13-Wochen-Durchschnitt einer Aktie erhalten. Wenn der Bestand zum ersten Mal am 1. April erstellt wurde, sind am 3. April nur Preisinformationen für 3 Tage vorhanden, sodass das Fenster nur 3 Zeilen breit ist.
Das folgende Beispiel zeigt das Ergebnis der Summierung über einen gleitendes Fensterrahmen, der groß genug ist, um zwei Samples aufzunehmen:
Das Abfrageergebnis enthält zusätzliche Kommentare, die zeigen, wie die Spalte SLIDING_SUM_QUANTITY berechnet wurde:
Beachten Sie, dass die Funktionalität für das gleitende Fenster nicht ohne die ORDER BY-Klausel verwendet werden kann. Die Funktion hängt von der Reihenfolge der Zeilen ab, die den Fensterrahmen betreten und verlassen.
Laufende Summen mit PARTITION BY- und ORDER BY-Klauseln¶
Sie können PARTITIONBY- und ORDERBY-Klauseln kombinieren, um aktuelle Summen in Partitionen abzurufen. In diesem Beispiel ist die Partition auf einen Monat festgelegt. Da die Summen nur für eine Partition gelten, wird die Summe zu Beginn jedes neuen Monats auf 0 zurückgesetzt:
Das Abfrageergebnis enthält zusätzliche Kommentare, aus denen hervorgeht, wie die Spalte MONTHLY_CUMULATIVE_SUM_QUANTITY berechnet wurde:
Sie können Partitionen und gleitende Fensterrahmen kombinieren. Im folgenden Beispiel ist das gleitende Fenster normalerweise zwei Zeilen breit. Jedes Mal, wenn eine neue Partition (d. h. ein neuer Monat) erreicht wird, beginnt das gleitende Fenster bei der ersten Zeile dieser Partition:
Das Abfrageergebnis enthält zusätzliche Kommentare, aus denen hervorgeht, wie die Spalte MONTHLY_SLIDING_SUM_QUANTITY berechnet wurde:
Das Verhältnis eines Wertes zu einer Summe von Werten berechnen¶
Sie können die Funktion RATIO_TO_REPORT verwenden, um das Verhältnis eines Wertes zur Summe der Werte in einer Partition zu berechnen und dann das Verhältnis als Prozentsatz dieser Summe zurückzugeben. Die Funktion dividiert den Wert in der aktuellen Zeile durch die Summe der Werte in allen Zeilen einer Partition.
Die Klausel PARTITION BY definiert Partitionen für die Spalte city. Wenn Sie den prozentualen Gewinn bezogen auf die gesamte Kette und nicht nur die Geschäfte in einer bestimmten Stadt anzeigen möchten, lassen Sie die PARTITION BY-Klausel weg: