Gruppierungsschlüssel und geclusterte Tabellen¶
Im Allgemeinen erzeugt Snowflake gut geclusterte Daten in Tabellen. Im Laufe der Zeit, insbesondere wenn DML auf sehr großen Tabellen (durch Datenmenge in der Tabelle definiert, nicht durch die Anzahl der Zeilen) ausgeführt wird, werden die Daten einiger Tabellenzeilen jedoch nicht mehr optimal nach gewünschten Dimensionen geclustert.
Um das Clustering der zugrunde liegenden Mikropartitionen zu verbessern, können Sie die Zeilen in den Schlüsselspalten manuell sortieren und erneut in die Tabelle einfügen. Diese Aufgaben wären jedoch wahrscheinlich umständlich und teuer.
Stattdessen unterstützt Snowflake die Automatisierung dieser Aufgaben, indem eine oder mehrere Tabellenspalten/-ausdrücke als Gruppierungsschlüssel für die Tabelle festgelegt werden. Eine Tabelle mit einem definierten Gruppierungsschlüssel gilt als geclustert.
Sie können materialisierte Ansichten sowie Tabellen clustern. Die Regeln für das Clustering von Tabellen und materialisierten Ansichten sind im Allgemeinen dieselben. Einige zusätzliche Hinweise für materialisierte Ansichten finden Sie unter Materialisierte Ansichten und Clustering und Bewährte Methoden für materialisierte Ansichten.
Achtung
Gruppierungsschlüssel sind nicht für alle Tabellen vorgesehen, da die Kosten für das anfängliche Clustering der Daten und die Aufrechterhaltung des Clustering hoch sind. Clustering ist in folgenden Fällen optimal:
Sie benötigen die schnellstmögliche Reaktionszeit, unabhängig von den Kosten.
Die verbesserte Abfrageleistung gleicht die für das Clustern und die Pflege der Tabelle erforderlichen Credits aus.
Weitere Informationen zur Auswahl der zu clusternden Tabellen finden Sie unter Hinweise zur Auswahl des Clustering für eine Tabelle.
Was ist ein Gruppierungsschlüssel?¶
Ein Gruppierungsschlüssel ist eine Teilmenge von Spalten oder Ausdrücken einer Tabelle, die explizit dazu bestimmt sind, Daten in denselben Mikropartitionen der Tabelle zusammenzulegen. Dies ist nützlich für sehr große Tabellen, bei denen die Reihenfolge nicht ideal war (zum Zeitpunkt des Einfügens/Ladens der Daten) oder bei denen umfangreiche DML-Anweisungen das normale Clustering der Tabelle beeinträchtigt haben.
Anhand der folgenden allgemeinen Indikatoren lässt sich bestimmen, ob ein Gruppierungsschlüssel für eine Tabelle definiert werden sollten:
Die Abfrageperformance der Tabelle ist langsamer als erwartet oder hat sich im Laufe der Zeit merklich verschlechtert.
Die Clustering-Tiefe für die Tabelle ist groß.
Ein Gruppierungsschlüssel kann bei der Tabellenerstellung (mit dem Befehl CREATE TABLE) oder anschließend (mit dem Befehl ALTER TABLE) definiert werden. Der Gruppierungsschlüssel für eine Tabelle kann auch jederzeit geändert oder gelöscht werden.
Achtung
Gruppierungsschlüssel können nicht für Hybridtabellen definiert werden. In Hybridtabellen sind die Daten immer nach dem Primärschlüssel sortiert.
Vorteile der Definition von Gruppierungsschlüsseln (für sehr große Tabellen)¶
Die Verwendung eines Gruppierungsschlüssels zum gleichzeitigen Auffinden ähnlicher Zeilen in denselben Mikropartitionen bietet mehrere Vorteile für sehr große Tabellen:
Effizienteres Scannen bei Abfragen durch Überspringen von Daten, die nicht mit Filterprädikaten übereinstimmen.
Bessere Spaltenkomprimierung als in Tabellen ohne Gruppierungsschlüssel. Dies gilt insbesondere, wenn andere Spalten stark mit den Spalten korrelieren, die den Gruppierungsschlüssel umfassen.
Nachdem ein Schlüssel für eine Tabelle definiert wurde, ist keine zusätzliche Verwaltung erforderlich, es sei denn, Sie möchten den Schlüssel löschen oder ändern. Alle zukünftigen Wartungsarbeiten an den Zeilen in der Tabelle (um ein optimales Clustering sicherzustellen) werden automatisch von Snowflake ausgeführt.
Obwohl das Clustering die Leistung erheblich verbessern und die Kosten einiger Abfragen senken kann, verbrauchen die für das Clustering benötigten Computeressourcen Credits. Daher sollten Sie nur dann Cluster erstellen, wenn Abfragen vom Clustering erheblich profitieren.
In der Regel profitieren Abfragen vom Clustering, wenn die Abfragen auf dem Gruppierungsschlüssel der Tabelle filtern oder sortieren. Das Sortieren wird normalerweise für ORDER BY-Operationen, für GROUP BY-Operationen und für einige Verknüpfungen (Join) durchgeführt. Beispielsweise würde der folgende Join Snowflake wahrscheinlich veranlassen, eine Sortieroperation auszuführen:
In diesem Pseudocodebeispiel sortiert Snowflake die Werte wahrscheinlich entweder nach my_materialized_view.col1 oder my_table.col1. Wenn beispielsweise die Werte in my_table.col1 sortiert sind, kann Snowflake beim Scannen der materialisierten Ansicht die entsprechende Zeile in my_table schnell finden.
Je häufiger eine Tabelle abgefragt wird, desto mehr Vorteile bietet Clustering. Je häufiger eine Tabelle geändert wird, desto teurer wird es, das Clustering aufrechtzuerhalten. Daher ist Clustering in der Regel am kosteneffektivsten bei Tabellen, die häufig abgefragt werden und sich nur selten ändern.
Bemerkung
Nachdem Sie einen Gruppierungsschlüssel für eine Tabelle definiert haben, werden die Zeilen nicht notwendigerweise sofort aktualisiert. Snowflake führt nur dann eine automatisierte Wartung durch, wenn die Tabelle von der Operation profitieren würde. Weitere Details dazu finden Sie unter Reclustering (unter diesem Thema) und unter Automatic Clustering.
Hinweise zur Auswahl des Clustering für eine Tabelle¶
Unabhängig davon, ob Sie schnellere Antwortzeiten oder niedrigere Gesamtkosten wünschen, ist Clustering am besten für eine Tabelle geeignet, die alle folgenden Kriterien erfüllt:
Die Tabelle enthält eine große Anzahl von Mikropartitionen. In der Regel bedeutet dies, dass die Tabelle mehrere Terabytes (TB) an Daten enthält.
Die Abfragen profitieren vom Clustering. In der Regel bedeutet dies, dass eine oder beide der folgenden Bedingungen erfüllt sind:
Die Abfragen sind selektiv. Mit anderen Worten: Die Abfragen müssen nur einen kleinen Prozentsatz der Zeilen (und damit in der Regel einen kleinen Prozentsatz der Mikropartitionen) in der Tabelle lesen.
Die Abfragen sortieren die Daten. (Die Abfragen enthalten z. B. eine ORDER BY-Klausel für die Tabelle.)
Ein hoher Prozentsatz der Abfragen kann von demselben Gruppierungsschlüssel profitieren. Mit anderen Worten, viele bzw. die meisten Abfragen selektieren oder sortieren nach denselben wenigen Spalten.
Wenn Ihr Ziel in erster Linie darin besteht, die Gesamtkosten zu senken, dann sollte jede geclusterte Tabelle einen hohen Anteil an Abfragen mit DML-Operationen (INSERT/UPDATE/DELETE) aufweisen. Dies bedeutet in der Regel, dass die Tabelle häufig abgefragt und selten aktualisiert wird. Wenn Sie eine Tabelle clustern möchten, auf der viele DML-Operationen ausgeführt werden, sollten Sie in Betracht ziehen, die DML-Anweisungen in großen, unregelmäßig ausgeführten Batches zu gruppieren.
Bevor Sie sich für das Clustering einer Tabelle entscheiden, empfiehlt Snowflake auch nachdrücklich, einen repräsentativen Satz von Abfragen auf der Tabelle zu testen, um einige grundlegende Leistungsdaten zu ermitteln.
Strategien zur Auswahl von Gruppierungsschlüsseln¶
Ein einzelner Gruppierungsschlüssel kann eine oder mehrere Spalten oder Ausdrücke enthalten. Für die meisten Tabellen empfiehlt Snowflake maximal 3 oder 4 Spalten (oder Ausdrücke) pro Schlüssel. Das Hinzufügen von mehr als 3-4 Spalten erhöht tendenziell eher die Kosten als den Nutzen.
Die Auswahl geeigneter Spalten/Ausdrücke als Gruppierungsschlüssel kann erhebliche Auswirkungen auf die Abfrageleistung haben. Die Analyse des Workloads führt in der Regel zu den passenden Kandidaten für den Gruppierungsschlüssel.
Snowflake empfiehlt, die Schlüssel in der folgenden Reihenfolge zu priorisieren:
Clusterspalten, die besonders häufig in selektiven Filtern verwendet werden. Bei vielen Faktentabellen, die an datumsbasierten Abfragen beteiligt sind (z. B. „WHERE Rechnungsdatum > x AND Rechnungsdatum <= y“), ist die Auswahl der Datumsspalte eine gute Idee. Bei Ereignistabellen ist der Ereignistyp möglicherweise eine gute Wahl, wenn eine große Anzahl unterschiedlicher Ereignistypen vorhanden ist. (Wenn Ihre Tabelle nur eine geringe Anzahl verschiedener Ereignistypen enthält, lesen Sie die folgenden Kommentare zur Kardinalität, bevor Sie eine Ereignisspalte als Gruppierungsschlüssel auswählen.)
Wenn Platz für zusätzliche Gruppierungsschlüssel vorhanden ist, sollten Sie Spalten berücksichtigen, die häufig in Join-Prädikaten verwendet werden, z. B. „FROM Tabelle1 JOIN Tabelle2 ON Tabelle2.Spalte_A = Tabelle1.Spalte_B“.
Wenn Sie Abfragen normalerweise nach zwei Dimensionen filtern (z. B. Spalte application_id und Spalte user_status), kann das Clustering in beiden Spalten die Leistung verbessern.
Die Anzahl unterschiedlicher Werte (d. h. die Kardinalität) in einer Spalte bzw. einem Ausdruck ist ein kritischer Aspekt bei der Auswahl des Gruppierungsschlüssels. Es ist wichtig, einen Gruppierungsschlüssel zu wählen, der Folgendes aufweist:
Eine ausreichend große Anzahl unterschiedlicher Werte, um ein effektives Verkürzen der Tabelle zu ermöglichen.
Eine so kleine Anzahl von unterschiedlichen Werten wie möglich, sodass Snowflake Zeilen effektiv in den gleichen Mikropartitionen gruppieren kann.
Bei einer Spalte mit sehr geringer Kardinalität wird möglicherweise nur ein minimales Pruning vorgenommen, z. B. bei einer Spalte mit dem Namen IS_NEW_CUSTOMER, die nur boolesche Werte enthält. Auf der anderen Seite ist eine Spalte mit sehr hoher Kardinalität normalerweise auch kein guter Kandidat für die direkte Verwendung als Gruppierungsschlüssel. Beispielsweise eignet sich eine Spalte, die Zeitstempelwerte im Nanosekundenbereich enthält, nicht als Gruppierungsschlüssel.
Tipp
Wenn eine Spalte (oder ein Ausdruck) eine höhere Kardinalität aufweist, ist die Wartung des Clusterings für diese Spalte im Allgemeinen teurer.
Die Kosten für das Clustering auf einem eindeutigen Schlüssel sind möglicherweise höher als der Vorteil des Clusterings auf diesem Schlüssel, insbesondere wenn punktuelle Suchläufe nicht der primäre Anwendungsfall für diese Tabelle sind.
Wenn Sie eine Spalte mit sehr hoher Kardinalität als Gruppierungsschlüssel verwenden möchten, empfiehlt Snowflake, den Schlüssel für die Spalte als Ausdruck und nicht direkt für die Spalte zu definieren, um so die Anzahl der unterschiedlichen Werte zu reduzieren. Der Ausdruck sollte die ursprüngliche Reihenfolge der Spalte beibehalten, damit die minimalen und maximalen Werte in jeder Partition weiterhin eine Verkürzung ermöglichen.
Wenn beispielsweise eine Faktentabelle eine TIMESTAMP-Spalte c_timestamp mit vielen diskreten Werten enthält (viel mehr als die Anzahl der Mikropartitionen in der Tabelle), kann ein Gruppierungsschlüssel für die Spalte definiert werden, indem die Zeitstempelwerte in Datumsangaben umgewandelt werden (z. B. to_date(c_timestamp)). Dies würde die Kardinalität auf die Gesamtzahl von Tagen reduzieren, was zu wesentlich besseren Verkürzungsergebnissen führt.
Als weiteres Beispiel können Sie eine Zahl mithilfe von TRUNC und einem negativen Wert für die Skala auf weniger signifikante Stellen kürzen (z. B. TRUNC(123456789, -5)).
Tipp
Wenn Sie einen Gruppierungsschlüssel über mehrere Spalten einer Tabelle definieren, ist die Reihenfolge wichtig, in der die Schlüssel in der CLUSTER BY-Klausel angegeben werden. In der Regel empfiehlt Snowflake, die Spalten von niedrigster Kardinalität zu höchster Kardinalität zu ordnen. Wenn Sie eine Spalte mit höherer Kardinalität vor eine Spalte mit niedrigerer Kardinalität setzen, wird die Effizienz der Clusterbildung in der letzteren Spalte im Allgemeinen verringert.
Tipp
Beim Clustering auf einem Textfeld verfolgen die Clusterschlüssel-Metadaten nur die ersten Bytes (typischerweise 5 oder 6 Bytes). Beachten Sie, dass dies bei Multi-Byte-Zeichensätzen weniger als 5 Zeichen sein kann.
In einigen Fällen kann das Clustering auf Spalten, die in GROUP BY- oder ORDER BY-Klauseln verwendet werden, hilfreich sein. Das Clustering für diese Spalten ist jedoch in der Regel weniger hilfreich als das Clustering für Spalten, die häufig in Filter- oder JOIN-Operationen verwendet werden. Wenn Sie Spalten haben, die häufig in Filter-/Join-Operationen verwendet werden, und andere Spalten, die in ORDER BY- oder GROUP BY-Operationen verwendet werden, sind die Spalten in den Filter-/Join-Operationen besser geeignet.
Reclustering¶
Wenn DML-Operationen (INSERT, UPDATE, DELETE, MERGE, COPY) auf einer geclusterte Tabelle ausgeführt werden, sind die Daten in der Tabelle danach möglicherweise weniger geclustert. Ein periodisches/regelmäßiges Reclustering der Tabelle ist erforderlich, um ein optimales Clustering sicherzustellen.
Beim Reclustering verwendet Snowflake den Gruppierungsschlüssel einer geclusterten Tabelle, um die Spaltendaten neu zu organisieren, sodass verwandte Datensätze in dieselbe Mikropartition verschoben werden. Diese DML-Operation löscht alle betroffenen Datensätze und fügt sie gemäß Gruppierungsschlüssel wieder ein.
Bemerkung
Das Reclustering erfolgt in Snowflake automatisch. Es ist keine Wartung erforderlich. Weitere Details dazu finden Sie unter Automatic Clustering.
Für bestimmte Konten wurde das manuelle Reclustering jedoch als veraltet eingestuft, ist jedoch weiterhin zulässig. Weitere Details dazu finden Sie unter Manuelles Reclustering.
Auswirkung von Reclustering auf Credit- und Speicherverbrauch¶
Ähnlich wie alle DML-Operationen in Snowflake werden beim Reclustering Credits verbraucht. Die Anzahl der in Anspruch genommenen Credits hängt von der Größe der Tabelle und der Datenmenge ab, auf der das Reclustering ausgeführt werden muss.
Reclustering führt auch zu Speicherkosten. Jedes Mal, wenn Daten einem Reclustering unterzogen werden, werden die Zeilen auf Basis des Gruppierungsschlüssels physisch gruppiert. Snowflake generiert dann neue Mikropartitionen für die Daten. Das Hinzufügen einer kleinen Anzahl von Zeilen zu einer Tabelle kann dazu führen, dass alle Mikropartitionen, die diese Werte enthalten, neu erstellt werden.
Dieser Prozess kann zu einem erheblichen Datenumschlag führen, da die ursprünglichen Mikropartitionen als gelöscht markiert werden, jedoch im System verbleiben, um Time Travel und Fail-safe zu ermöglichen. Die ursprünglichen Mikropartitionen werden erst nach Ablauf der Time Travel-Aufbewahrungsfrist und der nachfolgenden Fail-safe-Frist gelöscht (d. h. mindestens 8 Tage und bis zu 97 Tage bei erweitertem Time Travel mit der Snowflake Enterprise Edition oder höher). Dies führt typischerweise zu erhöhten Speicherkosten. Weitere Informationen dazu finden Sie unter Snowflake Time Travel & Fail-safe.
Wichtig
Bevor Sie Gruppierungsschlüssel für eine Tabelle definieren, sollten Sie die damit verbundenen Credit- und Speicherkosten prüfen.
Beispiel zum Reclustering¶
Aufbauend auf der Clustering-Abbildung aus dem vorherigen Thema wird in dieser Abbildung veranschaulicht, wie durch das Reclustering einer Tabelle das Scannen von Mikropartitionen reduziert und so die Abfrageleistung verbessert werden kann:
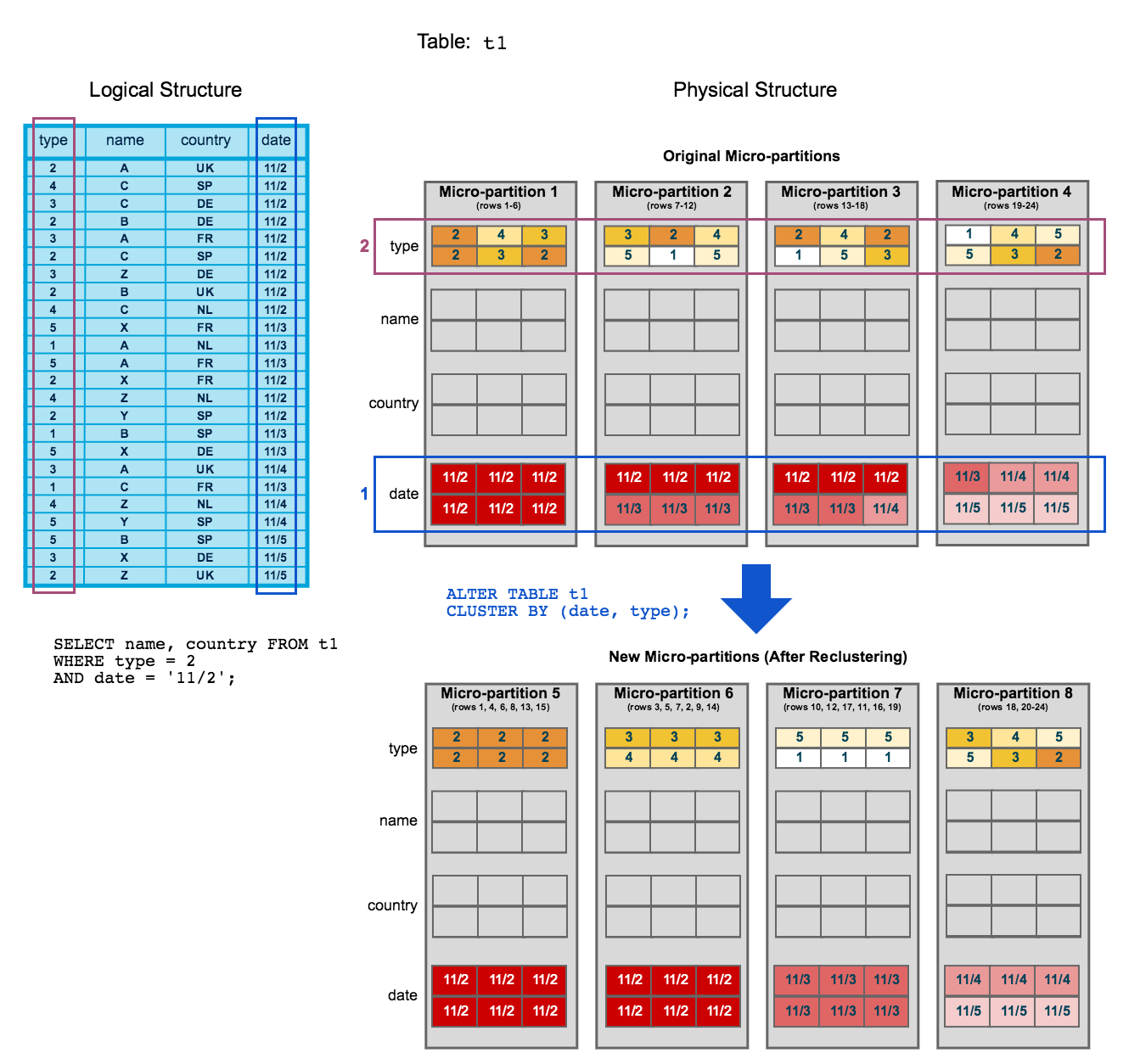
Zu Beginn wird die Tabelle
t1natürlich nachdateüber die Mikropartitionen 1–4 hinweg gruppiert.Die Abfrage (in der Abbildung) erfordert das Scannen der Mikropartitionen 1, 2 und 3.
dateundtypesind als Gruppierungsschlüssel definiert. Beim Reclustering der Tabelle werden neue Mikropartitionen (5–8) erstellt.Nach dem Reclustering scannt dieselbe Abfrage nur die Mikropartition 5.
Nach dem Reclustering gilt weiterhin:
Die Mikropartition 5 hat einen konstanten Zustand erreicht (d. h. sie kann durch Reclustering nicht mehr verbessert werden) und wird daher bei der Berechnung von Tiefe und Überlappung für künftige Wartung ausgeschlossen. In einer gut geclusterten, großen Tabelle fallen die meisten Mikropartitionen in diese Kategorie.
Die ursprünglichen Mikropartitionen (1–4) werden als gelöscht markiert, aber sie werden nicht aus dem System entfernt, denn sie werden für Time Travel und Fail-safe aufbewahrt.
Bemerkung
Dieses Beispiel zeigt die Auswirkungen von Reclustering bei äußerst kleinem Datenumfang. Hochgerechnet auf eine sehr große Tabelle (bestehend aus Millionen von Mikropartitionen) kann das Reclustering erheblichen Einfluss auf das Scannen und somit die Abfrageleistung haben.
Definieren gruppierter Tabellen¶
Berechnen der Clusterinformationen für eine Tabelle¶
Verwenden Sie die Systemfunktion SYSTEM$CLUSTERING_INFORMATION, um die Clustering-Details einschließlich der Clustering-Tiefe für eine bestimmte Tabelle zu berechnen. Diese Funktion kann für beliebige Spalten in jeder Tabelle ausgeführt werden, unabhängig davon, ob die Tabelle über einen expliziten Gruppierungsschlüssel verfügt:
Wenn eine Tabelle über einen expliziten Gruppierungsschlüssel verfügt, wird als Eingabeargumente der Funktion nur der Namen der Tabelle benötigt.
Wenn eine Tabelle nicht über einen expliziten Gruppierungsschlüssel verfügt (oder eine Tabelle über einen Gruppierungsschlüssel verfügt, Sie jedoch das Verhältnis zu anderen Spalten in der Tabelle berechnen möchten), verwendet die Funktion die gewünschten Spalten als zusätzliche Eingabeargumente.
Definieren eines Gruppierungsschlüssels für eine Tabelle¶
Ein Gruppierungsschlüssel kann beim Erstellen einer Tabelle definiert werden, indem an CREATE TABLE eine CLUSTER BY-Klausel angehängt wird:
Jeder Gruppierungsschlüssel besteht aus Tabellenspalten/Ausdrücken, die einen beliebigen Datentyp haben können, außer GEOGRAPHY, VARIANT, OBJECT oder ARRAY. Ein Gruppierungsschlüssel kann Folgendes enthalten:
Basisspalten
Ausdrücke auf Basisspalten
Ausdrücke auf Pfaden in VARIANT-Spalten
Beispiel:
Wichtige Nutzungshinweise¶
Für jede VARCHAR-Spalte werden bei der derzeitigen Implementierung des Clustering nur die ersten 5 Byte verwendet.
Wenn die ersten N Zeichen für jede Zeile gleich sind oder keine ausreichende Kardinalität bieten, dann sollte das Clustering auf einer Teilzeichenfolge in Betracht gezogen werden, die nach den identischen Zeichen beginnt und eine optimale Kardinalität aufweist. (Weitere Informationen zur optimalen Kardinalität finden Sie unter Strategien zur Auswahl von Gruppierungsschlüsseln.) Beispiel:
Wenn Sie zwei oder mehr Spalten/Ausdrücke als Gruppierungsschlüssel einer Tabelle definieren, hat die Reihenfolge der Schlüssel Auswirkungen auf das Clustering der Daten in Mikropartitionen.
Weitere Details dazu finden Sie unter Strategien zur Auswahl von Gruppierungsschlüsseln (unter diesem Thema).
Ein vorhandener Gruppierungsschlüssel wird kopiert, wenn eine Tabelle mit CREATE TABLE … CLONE erstellt wird. Automatic Clustering wird jedoch für die geklonte Tabelle angehalten und muss fortgesetzt werden.
Ein vorhandener Gruppierungsschlüssel wird nicht unterstützt, wenn eine Tabelle mit CREATE TABLE … AS SELECT erstellt wird. Sie können jedoch einen Gruppierungsschlüssel definieren, nachdem die Tabelle erstellt wurde.
Das Definieren eines Gruppierungsschlüssels direkt über VARIANT-Spalten wird nicht unterstützt. Sie können jedoch eine VARIANT-Spalte in einem Gruppierungsschlüssel angeben, wenn Sie einen Ausdruck bestehend aus Pfad und Zieltyp angeben.
Ändern des Gruppierungsschlüssels einer Tabelle¶
Sie können jederzeit einen Gruppierungsschlüssel zu einer vorhandenen Tabelle hinzufügen oder den vorhandenen Gruppierungsschlüssel einer Tabelle mit ALTER TABLE ändern:
Beispiel:
Wichtige Nutzungshinweise¶
Beim Hinzufügen eines Gruppierungsschlüssels zu einer Tabelle, die bereits mit Daten gefüllt ist, dürfen nicht alle Ausdrücke im Gruppierungsschlüssel angegeben werden. Ob eine bestimmte Funktion unterstützt wird, können Sie mit SHOW FUNCTIONS prüfen:
show functions like 'function_name';Die Ausgabe enthält am Ende eine Spalte
valid_for_clustering. Diese Spalte zeigt an, ob die Funktion in einem Gruppierungsschlüssel für eine ausgefüllte Tabelle verwendet werden kann.Das Ändern des Gruppierungsschlüssels einer Tabelle hat erst dann Auswirkungen auf vorhandene Datensätze der Tabelle, wenn diese von Snowflake einem Reclustering unterzogen wird.
Löschen des Gruppierungsschlüssels einer Tabelle¶
Sie können den Gruppierungsschlüssel einer Tabelle jederzeit mit ALTER TABLE löschen:
Beispiel: