Snowpipe Streaming high-performance architecture¶
Die High-Performance-Architektur für Snowpipe Streaming wurde für moderne, datenintensive Unternehmen entwickelt, die Einblicke in nahezu Echtzeit benötigen. Diese Architektur der nächsten Generation verbessert den Durchsatz, die Effizienz und die Flexibilität für die Echtzeit-Aufnahme in Snowflake erheblich.
Informationen zur klassischen Architektur finden Sie unter Klassische Snowpipe Streaming-Architektur. Erläuterungen zu den Unterschieden zwischen dem klassischen SDK und dem leistungsstarken SDK finden Sie unter Vergleich zwischen leistungsstarken und klassischen Snowpipe Streaming-SDKs.
Software-Anforderungen¶
Java
Erfordert Java 11 oder höher.
SDK-Maven-Repository: Snowpipe Streaming Java SDK
API-Referenz: Java SDK-Referenz
Python
Erfordert Python Version 3.9 oder höher.
SDK-PyPI-Repository: Snowpipe Streaming Python SDK
API-Referenz: Python-SDK-Referenz
Wichtige Funktionen¶
Durchsatz und Latenzzeit:
Hoher Durchsatz: Entwickelt, um Aufnahmegeschwindigkeiten von bis zu 10 GB/s pro Tabelle zu unterstützen.
Einblicke fast in Echtzeit: Erzielt End-to-End-Latenzen von der Aufnahme bis zur Abfrage innerhalb von 5 bis 10 Sekunden.
Abrechnung:
Vereinfachte, transparente, durchsatzbasierte Abrechnung. Weitere Informationen dazu finden Sie unter Snowpipe Streaming high-performance architecture: Understand your costs.
Flexible Aufnahme:
Java SDK und Python SDK: Verwenden Sie das neue
snowpipe-streamingSDK, das über einen Rust-basierten Client-Core für verbesserte clientseitige Performance und geringeren Ressourcenverbrauch verfügt.REST API: Bietet einen direkten Datenaufnahmepfad, der die Integration für einfache Workloads, IoT-Gerätendaten und Edge-Bereitstellungen vereinfacht.
Bemerkung
Wir empfehlen, mit dem Snowpipe Streaming-SDK über die REST API zu beginnen, um von der verbesserten Leistung und dem einfacheren Einstieg zu profitieren.
Optimierte Datenverarbeitung:
Schwebende Transformationen: Unterstützt die Datenbereinigung und -umformung während der Aufnahme mit der COPY-Befehlssyntax innerhalb des PIPE-Objekts.
Verbesserte Kanalsichtbarkeit: Verbesserter Einblick in den Aufnahmestatus, vor allem durch die Ansicht Kanalverlauf in Snowsight und eine neue
GET_CHANNEL_STATUSAPI.
Diese Architektur wird empfohlen für:
Konsistente Aufnahme von Streaming-Workloads mit hohem Volumen.
Echtzeit-Analysen und Dashboards für zeitkritische Entscheidungen.
Effiziente Integration von Daten aus IoT-Geräten und Edge-Implementierungen.
Unternehmen, die transparente, vorhersehbare und durchsatzbasierte Preise für die Streaming-Aufnahme suchen.
Neue Konzepte: Das PIPE-Objekt¶
Während Kernkonzepte wie Kanäle und Offset-Tokens von Snowpipe Streaming Classic übernommen wurden, führt diese Architektur das PIPE-Objekt als zentrale Komponente ein.
Das PIPE-Endpunkt ist ein benanntes Snowflake-Objekt, das als Einstiegspunkt und Definitionsschicht für alle eingelesenen Streaming-Daten dient. Es bietet Folgendes:
Definition der Datenverarbeitung: Definiert, wie Streaming-Daten verarbeitet werden, bevor sie in die Zieltabelle übertragen werden. Dies schließt die serverseitige Pufferung für Transformationen oder Schemazuordnung ein.
Aktivieren von Transformationen: Ermöglicht eine Datenmanipulation während der Übertragung (z. B. Filtern, Neuordnen von Spalten, einfache Ausdrücke) durch Einbinden einer COPY-Syntax für die Befehlstransformation.
Unterstützte Tabellenfunktionen: Verarbeitet die Datenaufnahme in Tabellen mit definierten Clusteringschlüsseln, DEFAULTwert-Spalten und AUTOINCREMENT- (oder IDENTITY-)Spalten.
Verwalten von Schemas: Hilft bei der Definition des erwarteten Schemas der eingehenden Streaming-Daten und dessen Zuordnung zu Zieltabellenspalten und ermöglicht so eine serverseitige Schemavalidierung.
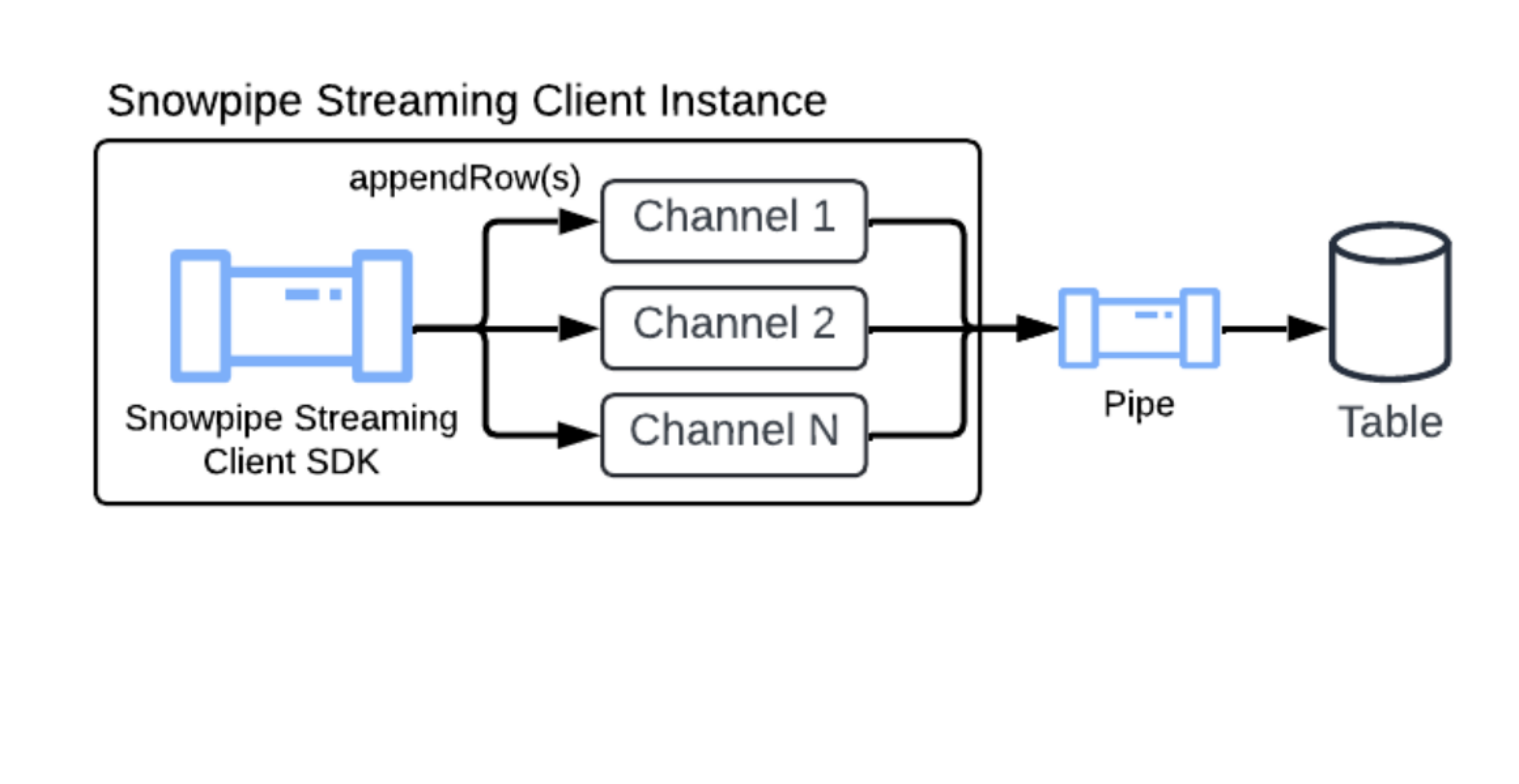
Standard-Pipe¶
Um den Einrichtungsprozess für Snowpipe Streaming zu vereinfachen, stellt Snowflake für jede Zieltabelle eine Standard-Pipe bereit. So können Sie sofort mit dem Streaming von Daten beginnen, ohne CREATE PIPE DDL-Anweisungen manuell ausführen zu müssen.
Die Standard-Pipe ist für jede Tabelle implizit verfügbar und bietet eine vereinfachte, vollständig verwaltete Benutzererfahrung:
Erstellung nach Bedarf: Die Standard-Pipe wird bei Bedarf nur erstellt, wenn der erste erfolgreiche Aufruf des Typs „pipe-info“ oder „open-channel“ für die Zieltabelle ausgeführt wurde. Kunden können die Pipe nur anzeigen oder beschreiben (mithilfe von SHOW PIPES oder DESCRIBE PIPE), nachdem sie durch einen dieser Aufrufe instanziiert wurde.
Namenskonvention: Die Standard-Pipe folgt einer bestimmten, vorhersehbaren Namenskonvention:
Format:
<TABLE_NAME>-STREAMINGBeispiel: Wenn der Name Ihrer Zieltabelle
MY_TABLElautet, heißt die Standard-PipeMY_TABLE-STREAMING.
Vollständig von Snowflake verwaltet: Diese Standard-Pipe wird vollständig von Snowflake verwaltet. Die Kundschaft kann keine Änderungen daran vornehmen, wie z. B. das Erstellen (CREATE), Ändern (ALTER) oder Löschen (DROP) der Standard-Pipe.
Sichtbarkeit: Obwohl die Verwaltung automatisch erfolgt, kann die Kundschaft die Standard-Pipe wie eine normale Pipe überprüfen. Die Kundschaft kann sie mithilfe der Befehle SHOW PIPES, DESCRIBE PIPE, SHOW CHANNELS anzeigen; außerdem ist sie in den Metadatenansichten von Account Usage enthalten: ACCOUNT_USAGE.PIPES, ACCOUNT_USAGE.METERING_HISTORY oder ORGANIZATION_USAGE.PIPES.
Die Standard-Pipe ist auf Einfachheit ausgelegt und hat gewisse Einschränkungen:
Keine Transformationen: Der interne Mechanismus für die Standard-Pipe verwendet
MATCH_BY_COLUMN_NAMEin der zugrunde liegenden Kopieranweisung. Es werden keine bestimmten Datentransformationen unterstützt.Kein Pre-Clustering: Die Standard-Pipe unterstützt kein Pre-Clustering für die Zieltabelle.
Wenn Ihr Streaming-Workflow bestimmte Transformationen erfordert – z. B. Umwandeln, Filtern oder komplexe Logik – oder Sie Pre-Clustering verwenden müssen, müssen Sie Ihre eigene benannte Pipe manuell erstellen. Weitere Informationen dazu finden Sie unter CREATE PIPE.
Bei der Konfiguration des Snowpipe Streaming SDK oder der REST API können Sie in Ihrer Clientkonfiguration auf den Namen der Standard-Pipe verweisen, um mit dem Streaming zu beginnen. Weitere Informationen dazu finden Sie unter Tutorial: Erste Schritte mit der leistungsstarken Snowpipe Streaming-Architektur SDK und Tutorial: Erste Schritte mit der Snowpipe Streaming REST API unter Verwendung von cURL und JWT.
Vorab-Clustering von Daten während der Aufnahme¶
Snowpipe Streaming kann Daten während der Aufnahme clustern, was die Abfrageleistung der Zieltabellen verbessert. Dieses Feature sortiert die Daten direkt während der Aufnahme, bevor sie übertragen werden. Wenn Sie die Daten auf diese Weise sortieren, wird die Organisation für schnellere Abfragen optimiert. auto-clustering feature on the destination table. Disabling auto-clustering can lead to degraded query performance over time.
Um das Vorab-Clustering nutzen zu können, müssen für Ihre Zieltabelle Gruppierungsschlüssel definiert sein. Sie können dieses Feature dann aktivieren, indem Sie den Parameter CLUSTER_AT_INGEST_TIME auf TRUE in der COPY INTO-Anweisung festlegen, wenn Sie die Snowpipe Streaming-Pipe erstellen oder ersetzen.
Weitere Informationen dazu finden Sie unter CLUSTER_AT_INGEST_TIME. Dieses Feature ist nur für die High-Performance-Architektur verfügbar.
Wichtig
Wenn Sie das Pre-Clustering-Feature verwenden, müssen Sie sicherstellen, dass Sie das Auto-Clustering-Feature für die Zieltabelle nicht deaktivieren. Das Deaktivieren von Auto-Clustering kann im Laufe der Zeit zu einer Beeinträchtigung der Abfrage führen.
Unterstützung der Schemaentwicklung¶
Snowpipe Streaming unterstützt die automatische Tabellenschemaentwicklung. Mit diesem Feature können sich Ihre Datenpipelines nahtlos an veränderte Datenstrukturen anpassen. Wenn dies aktiviert ist, kann Snowflake die Zieltabelle automatisch erweitern, indem neue Spalten hinzugefügt werden, die im eingehenden Stream erkannt werden, und NOT NULL-Einschränkungen gelöscht werden, um neue Datenmuster aufnehmen zu können. Weitere Informationen finden Sie unter Tabellenschemaentwicklung.
Einschränkungen¶
Nur native Tabellen: Die Schemaentwicklung wird nur für Standard-Snowflake-Tabellen unterstützt. Externe Tabellen und Iceberg-Tabellen werden nicht unterstützt.
Keine Spaltenerweiterung: Die Genauigkeit, Skalierung oder Länge vorhandener Spalten kann nicht automatisch erhöht werden.
Keine Unterstützung strukturierter Typen: Die Schemaentwicklung wird für strukturierte Datentypen nicht unterstützt, zum Beispiel strukturierte OBJECT- oder ARRAY-Spalten. Neue Spalten, die strukturierte Typen enthalten, werden jedoch als VARIANT abgeleitet, wodurch JSON-Objekte und -Arrays unterstützt werden.
Unterschiede zu Snowpipe Streaming Classic¶
Für Benutzer, die mit der klassischen Architektur vertraut sind, bringt die High-Performance-Architektur die folgenden Änderungen mit sich:
Neue SDK und APIs: Erfordert die neue
snowpipe-streamingSDK (Java-SDK und REST API), was eine Aktualisierung des Client-Codes für die Migration erforderlich macht.PIPE-Objektanforderung: Alle Datenaufnahmen, Konfigurationen (z. B. Transformationen) und Schemadefinitionen werden über das serverseitige PIPE-Objekt verwaltet, eine Abkehr von der eher clientgesteuerten Konfiguration von Classic.
Kanalzuordnung: Client-Anwendungen öffnen Kanäle gegen ein bestimmtes PIPE-Objekt, nicht direkt gegen eine Zieltabelle.
Schema-Validierung: Übergang von der primär clientseitigen (Classic-SDK) zur serverseitigen Durchsetzung durch Snowflake, basierend auf dem PIPE-Objekt.
Anforderungen für die Migration: Es ist erforderlich, den Code der Client-Anwendung für das neue SDK zu ändern und PIPE-Objekte in Snowflake zu definieren.