Introduction to streams¶
Ein Streamobjekt erfasst an Tabellen vorgenommene Data Manipulation Language (DML)-Änderungen, einschließlich Einfügungen (einschließlich COPY INTO), Aktualisierungen und Löschvorgänge sowie Metadaten zu jeder Änderung, sodass mit den geänderten Daten Aktionen durchgeführt werden können. Dieser Vorgang wird als Change Data Capture (CDC) bezeichnet. Unter diesem Thema werden die wichtigsten Konzepte für die Erfassung von Änderungsdaten mithilfe von Streams vorgestellt.
Ein einzelner Tabellen-Stream verfolgt die Änderungen, die an Zeilen in einer Quelltabelle vorgenommen werden. Ein Tabellen-Stream (auch einfach als „Stream“ bezeichnet) stellt eine „Änderungstabelle“ zur Verfügung, die angibt, was sich auf Zeilenebene zwischen zwei Transaktionszeitpunkten in einer Tabelle geändert hat. Auf diese Weise können Sie eine Sequenz von Änderungsdatensätzen auf transaktionale Weise abfragen und verbrauchen.
Streams können erstellt werden, um Änderungsdaten zu den folgenden Objekten abzufragen:
Standardtabellen, einschließlich freigegebener Tabellen
Ansichten, einschließlich sicherer Ansichten
Offset storage¶
Bei der Erstellung eines Streams wird zuerst ein Snapshot jeder Zeile der Quelltabelle erfasst (z. B. Tabelle, externe Tabelle oder die zugrunde liegenden Tabellen einer Ansicht), indem ein Zeitpunkt (Offset genannt) als aktuelle Transaktionsversion der Tabelle initialisiert wird. Das vom Stream verwendete Änderungsnachverfolgungssystem zeichnet dann Informationen über die DML-Änderungen auf, die nach Erstellung dieses Snapshots ausgeführt wurden. Änderungsdatensätze geben den Status einer Zeile vor und nach der Änderung an. Änderungsinformationen spiegeln die Spaltenstruktur des nachverfolgten Quellobjekts wider und enthalten zusätzliche Metadatenspalten, die jedes Änderungsereignis beschreiben.
Streams verwenden das aktuelle Tabellenschema. Da Streams jedoch gelöschte Daten lesen können, um Änderungen im Laufe der Zeit zu verfolgen, können inkompatible Schemaänderungen zwischen dem Offset und der Erhöhung zu Abfragefehlern führen.
Beachten Sie, dass ein Stream selbst keine Tabellendaten enthält. Ein Stream speichert nur den Offset für das Quellobjekt und gibt CDC-Datensätze zurück, indem der Versionsverlauf für das Quellobjekt genutzt wird. Wenn der erste Stream für eine Tabelle erstellt wird, werden einige ausgeblendete Spalten zur Quelltabelle hinzugefügt, und dann beginnt das System mit dem Speichern von Metadaten zur Änderungsverfolgung. Diese Spalten verbrauchen nur wenig Speicherplatz. Die CDC-Datensätze, die beim Abfragen eines Streams zurückgegeben werden, basieren auf einer Kombination aus dem im Stream gespeicherten Offset und den in der Tabelle gespeicherten Änderungsverfolgungsmetadaten. Beachten Sie, dass bei Streams on Views die Änderungsverfolgung explizit für die Ansicht und die zugrunde liegenden Tabellen aktiviert werden muss, um die ausgeblendeten Spalten zu diesen Tabellen hinzuzufügen.
Es kann nützlich sein, sich einen Stream als Lesezeichen vorzustellen, das einen Zeitpunkt auf den Seiten eines Buches (d. h. des Quellobjekts) angibt. Ein Lesezeichen kann weggeworfen werden, und andere Lesezeichen können an anderen Stellen in einem Buch eingefügt werden. Ebenso kann ein Stream gelöscht werden, und andere Streams können zum selben oder zu unterschiedlichen Zeitpunkten erstellt werden (entweder indem die Streams zu unterschiedlichen Zeiten nacheinander erstellt werden oder indem Time Travel verwendet wird), um die Änderungsdatensätze für ein Objekt bei gleichen oder verschiedenen Offsets zu verarbeiten.
Ein Beispiel für einen Verbraucher von CDC-Datensätzen ist eine Datenpipeline , in der von den Daten in Stagingtabellen nur die transformiert und in andere Tabellen kopiert werden, die sich seit der letzten Extraktion geändert haben.
Table versioning¶
Eine neue Tabellenversion wird immer dann erstellt, wenn für eine Transaktion auf der Tabelle, die eine oder mehrere DML-Anweisungen enthält, ein Commit ausgeführt wird. Dies gilt für die folgenden Tabellentypen:
Standardtabellen
Verzeichnistabellen
Dynamische Tabellen
Externe Tabellen
Apache Iceberg™-Tabellen
Zugrunde liegende Tabellen für eine Ansicht
In der Transaktionshistorie einer Tabelle befindet sich zwischen zwei Tabellenversionen ein Stream-Offset. Die Abfrage eines Streams gibt die Änderungen zurück, die durch Transaktionen verursacht wurden, die nach dem Offset und zum oder vor dem aktuellen Zeitpunkt mit Commit bestätigt wurden.
Das folgende Beispiel zeigt eine Quelltabelle mit 10 mit Commit bestätigten Versionen in der Zeitachse. Der Offset von Stream s1 liegt derzeit zwischen den Tabellenversionen v3 und v4. Wenn der Stream abgefragt (oder verbraucht) wird, enthalten die zurückgegebenen Datensätze alle Transaktionen zwischen der Tabellenversion v4, der Version unmittelbar nach dem Stream-Offset in der Zeitachse der Tabelle, und einschließlich v10, der neuesten mit Commit bestätigten Tabellenversion in der Zeitachse.

Ein Stream stellt den minimalen Satz von Änderungen von seinem aktuellen Offset bis zur aktuellen Version der Tabelle bereit.
Mehrere Abfragen können unabhängig voneinander dieselben Änderungsdaten aus einem Stream verbrauchen, ohne den Offset zu ändern. Ein Stream erhöht den Offset nur, wenn er in einer DML-Transaktion verwendet wird. Dies schließt eine Transaktion Create Table As Select (CTAS) oder eine COPY INTO Speicherort-Transaktion ein, und diese Verhaltensweise gilt sowohl für explizite als auch für Autocommit-Transaktionen. (Beim Ausführen einer DML-Anweisung wird standardmäßig implizit eine Autocommit-Transaktion gestartet, und die Transaktion wird nach Abschluss der Anweisung mit COMMIT bestätigt. Dieses Verhalten wird mit dem Parameter AUTOCOMMIT gesteuert.) Das Abfragen eines Streams allein führt nicht zum Erhöhen des Offsets, auch nicht innerhalb einer expliziten Transaktion. Der Inhalt des Streams muss in einer DML-Anweisung verarbeitet werden.
Bemerkung
Um den Offset eines Datenstreams auf die aktuelle Tabellenversion vorzuverlegen, ohne die Änderungsdaten in einer DML-Operation zu verbrauchen, führen Sie eine der folgenden Aktionen durch:
Erstellen Sie den Stream neu (unter Verwendung der CREATE OR REPLACE STREAM-Syntax).
Fügen Sie die aktuellen Änderungsdaten in eine temporäre Tabelle ein. In der INSERT-Anweisung fragen Sie den Stream ab, fügen aber eine WHERE-Klausel ein, die alle Änderungsdaten herausfiltert (z. B.
WHERE 0 = 1).
Wenn eine SQL-Anweisung einen Stream innerhalb einer expliziten Transaktion abfragt, erfolgt die Abfrage des Streams an der Streamspitze (d. h. dem Zeitstempel), als die Transaktion begann und nicht als die Anweisung ausgeführt wurde. Dieses Verhalten betrifft sowohl DML-Anweisungen als auch CREATE TABLE … AS SELECT (CTAS)-Anweisungen, die eine neue Tabelle mit Zeilen aus einem vorhandenen Stream füllen.
Eine DML-Anweisung, die ein „Select“ auf einem Stream ausführt, verbraucht alle Änderungsdaten im Stream, vorausgesetzt, die Transaktion wurde erfolgreich mit Commit bestätigt. Um sicherzustellen, dass verschiedene Anweisungen auf dieselben Änderungsdatensätze im Stream zugreifen, müssen Sie sie mit einer expliziten Transaktionsanweisung (BEGIN .. COMMIT) umgeben. Dies sperrt den Stream. DML-Aktualisierungen am Quellobjekt in parallelen Transaktionen werden vom Änderungsverfolgungssystem verfolgt, aktualisieren den Stream jedoch erst, wenn für die explizite Transaktionsanweisung ein Commit ausgeführt wurde und die vorhandenen Änderungsdaten verbraucht wurden.
Repeatable read isolation¶
Streams unterstützen wiederholbare Leseisolation. Im wiederholbaren Lesemodus sehen verschiedene SQL-Anweisungen innerhalb einer Transaktion die gleichen Datensätze in einem Stream. Dies unterscheidet sich von dem für Tabellen unterstützten Read Committed-Modus, in dem Anweisungen alle Änderungen anzeigen, die von vorherigen Anweisungen vorgenommen wurden, die in derselben Transaktion ausgeführt wurden, obwohl für diese Änderungen noch kein Commit ausgeführt wurde.
Die Delta-Datensätze, die von Streams in einer Transaktion zurückgegeben werden, beinhalten den Bereich von der aktuellen Position des Streams bis zur Startzeit der Transaktion. Die Streamposition rückt zur Transaktionsstartzeit vor, wenn der Transaktions-Commit ausgeführt wird, andernfalls bleibt sie an der gleichen Position.
Betrachten Sie das folgende Beispiel:
Zeit |
Transaktion 1 |
Transaktion 2 |
|---|---|---|
1 |
Starten Sie eine Transaktion. |
|
2 |
Abfrage-Stream |
|
3 |
Aktualisieren Sie Zeilen in Tabelle |
|
4 |
Abfrage-Stream |
|
5 |
Führen Sie den Transaktions-Commit aus. Wenn der Stream in DML-Anweisungen innerhalb der Transaktion verbraucht wurde, rückt die Stream-Position zur Transaktionsstartzeit vor. |
|
6 |
Starten Sie eine Transaktion. |
|
7 |
Abfrage-Stream |
In Transaktion 1 werden allen Abfragen an Stream s1 dieselben Datensätze angezeigt. DML-Änderungen an Tabelle t1 werden nur dann im Stream aufgezeichnet, wenn für die Transaktion ein Commit ausgeführt wurde.
In Transaktion 2 werden Abfragen an den Stream die Änderungen angezeigt, die in der Tabelle in Transaktion 1 aufgezeichnet wurden. Beachten Sie aber Folgendes: Wenn Transaktion 2 begonnen hätte, bevor das Commit für Transaktion 1 ausgeführt worden wäre, hätten Abfragen an den Stream einen Snapshot des Streams von der Position des Streams bis zur Startzeit von Transaktion 2 zurückgegeben und keine der für Transaktion 1 committeten Änderungen wäre sichtbar.
Stream columns¶
Ein Stream speichert einen Offset für die Quelltabelle und keine tatsächlichen Tabellenspalten oder Daten. Bei Abfragen auf dem Stream erfolgen der Zugriff auf die historischen Daten und die Datenrückgabe in derselben Form wie bei Abfragen auf dem Quellobjekt (d. h. mit denselben Spaltennamen und derselben Reihenfolge), allerdings mit den folgenden zusätzlichen Spalten:
- METADATA$ACTION:
Gibt die erfasste DML-Operation (INSERT, DELETE) an.
- METADATA$ISUPDATE:
Gibt an, ob die Operation Teil einer UPDATE-Anweisung war. Aktualisierungen von Zeilen in der Quelltabelle werden als ein Paar von DELETE- und INSERT-Datensätzen im Stream dargestellt, wobei METADATA$ISUPDATE-Werte einer Metadatenspalte auf TRUE gesetzt sind.
Beachten Sie, dass Streams die Unterschiede zwischen zwei Offsets aufzeichnen. Wenn eine Zeile hinzugefügt und dann im aktuellen Offset aktualisiert wird, ist die Deltaänderung eine neue Zeile. Die Zeile METADATA$ISUPDATE zeichnet einen FALSE-Wert auf.
- METADATA$ROW_ID:
Gibt eine eindeutige, unveränderliche Zeilen-ID an, um Änderungen im Laufe der Zeit zu verfolgen. Wenn CHANGE_TRACKING für das Quellobjekt des Streams deaktiviert und später wieder aktiviert wird, kann sich die Zeilen-ID ändern.
Snowflake bietet die folgenden Garantien in Bezug auf METADATA$ROW_ID:
METADATA$ROW_ID hängt vom Quellobjekt des Streams ab.
Beispielsweise erzeugen ein Stream
stream1auf Tabelletable1und ein Streamstream2auf Tabelletable1dieselben METADATA$ROW_IDs für dieselben Zeilen, aber ein Streamstream_viewauf Ansichtview1erzeugt garantiert nicht dieselben METADATA$ROW_IDs wiestream1, selbst wennviewmit der AnweisungCREATE VIEW view AS SELECT * FROM table1definiert ist.Ein Stream auf einem Quellobjekt und ein Stream auf dem Klon des Quellobjekts erzeugen die gleichen METADATA$ROW_IDs für die Zeilen, die zum Zeitpunkt des Klonens existieren.
Ein Stream auf einem Quellobjekt und ein Stream auf dem Replikat des Quellobjekts erzeugen die gleichen METADATA$ROW_IDs für die replizierten Zeilen.
Types of streams¶
Die folgenden Streamtypen sind basierend auf den von jedem Stream aufgezeichneten Metadaten verfügbar:
- Standard:
Unterstützt für Streams auf Standardtabellen, dynamischen Tabellen, von Snowflake verwalteten Apache Iceberg™-Tabellen, Verzeichnis-Tabellen oder Ansichten. Ein Standard-Stream (d. h. ein Delta-Stream) verfolgt alle DML-Änderungen am Quellobjekt, einschließlich Einfügungen, Aktualisierungen und Löschungen (einschließlich Tabellenabbrüche). Dieser Streamtyp führt eine Verknüpfung (Join) für eingefügte und gelöschte Zeilen im Änderungsset durch, um das Delta auf Zeilenebene bereitzustellen. Als Gesamteffekt wird beispielsweise eine Zeile, die zwischen zwei Transaktionszeitpunkten in einer Tabelle eingefügt und dann gelöscht wird, im Delta entfernt (d. h. sie wird nicht zurückgegeben, wenn der Stream abgefragt wird).
Bemerkung
Standardstreams können keine Änderungsdaten für Geodaten abrufen. Es wird empfohlen, auf Objekten, die Geodaten enthalten, Nur-Anfügen-Streams zu erstellen.
- Nur-Anfügen:
Unterstützt für Streams auf Standardtabellen, dynamischen Tabellen, von Snowflake verwalteten Apache Iceberg™-Tabellen oder Ansichten. Ein Nur-Anfügen-Stream verfolgt ausschließlich Zeileneinfügungen. Aktualisierungs-, Lösch- und Abschneideoperationen werden von Nur-Anfügen-Streams nicht erfasst. Wenn z. B. zunächst 10 Zeilen in eine Tabelle eingefügt werden und dann 5 dieser Zeilen gelöscht werden, bevor der Offset für einen Nur-Anfügen-Stream erweitert wird, würde der Stream nur die 10 eingefügten Zeilen aufzeichnen.
Ein Nur-Anfügen-Stream gibt speziell die angefügten Zeilen zurück, was ihn deutlich leistungsfähiger macht als einen Standard-Stream für Extrahieren, Laden und Transformieren (ELT) und ähnliche Szenarios, die nur auf Zeileneinfügungen angewiesen sind. Beispiel: Eine Quelltabelle kann unmittelbar nach dem Verarbeiten der Zeilen eines Nur-Anfügen-Streams abgeschnitten werden, und das Löschen von Datensätzen produziert keinen Overhead, wenn der Stream das nächste Mal abgefragt oder verarbeitet wird.
Das Erstellen eines Nur-Anfügen-Streams in einem Zielkonto unter Verwendung eines sekundären Objekts als Quelle wird nicht unterstützt.
- Nur Einfügen:
Unterstützt für Streams auf extern verwalteten Apache Iceberg™- oder externen Tabellen. Bei Nur-Einfügen-Streams werden nur Zeileneinfügungen verfolgt. Löschoperationen, bei denen Zeilen aus einem eingefügten Set entfernt werden, werden nicht erfasst (d. h. NoOps). Wenn beispielsweise zwischen zwei beliebigen Offsets
File1aus dem Cloudspeicherort entfernt wird, auf den in der externen Tabelle verwiesen wird, undFile2hinzugefügt wird, gibt der Stream nur Datensätze für die Zeilen inFile2zurück, und zwar unabhängig davon, obFile1vor oder innerhalb des angeforderten Änderungsintervalls hinzugefügt wurde. Anders als beim Verfolgen von CDC-Daten für Standardtabellen wird der Zugriff auf die historischen Datensätze für Dateien im Cloudspeicher nicht von Snowflake geregelt oder für Snowflake garantiert.Überschriebene oder angehängte Dateien werden im Wesentlichen wie neue Dateien behandelt: Die alte Version der Datei wird aus dem Cloudspeicher entfernt, aber der Nur-Einfügen-Stream zeichnet die Löschoperation nicht auf. Die neue Version der Datei wird dem Cloudspeicher hinzugefügt, und der Nur-Einfügen-Stream zeichnet die Zeilen als Einfügeoperationen auf. Der Stream zeichnet die Differenz zwischen alter und neuer Dateiversion nicht auf. Beachten Sie, dass Anhänge möglicherweise keine automatische Aktualisierung der Metadaten der externen Tabelle auslösen, wie z. B. bei Verwendung von Azure AppendBlobs.
Data flow¶
Die folgende Abbildung zeigt, wie sich der Inhalt eines Standardstreams ändert, wenn Zeilen in der Quelltabelle aktualisiert werden. Immer, wenn eine DML-Anweisung die Inhalte des Streams verarbeitet hat, wechselt die Streamposition zur Nachverfolgung auf den nächsten Satz an DML-Änderungen in der Tabelle (d. h. den Änderungen in einer bestimmten Tabellenversion):
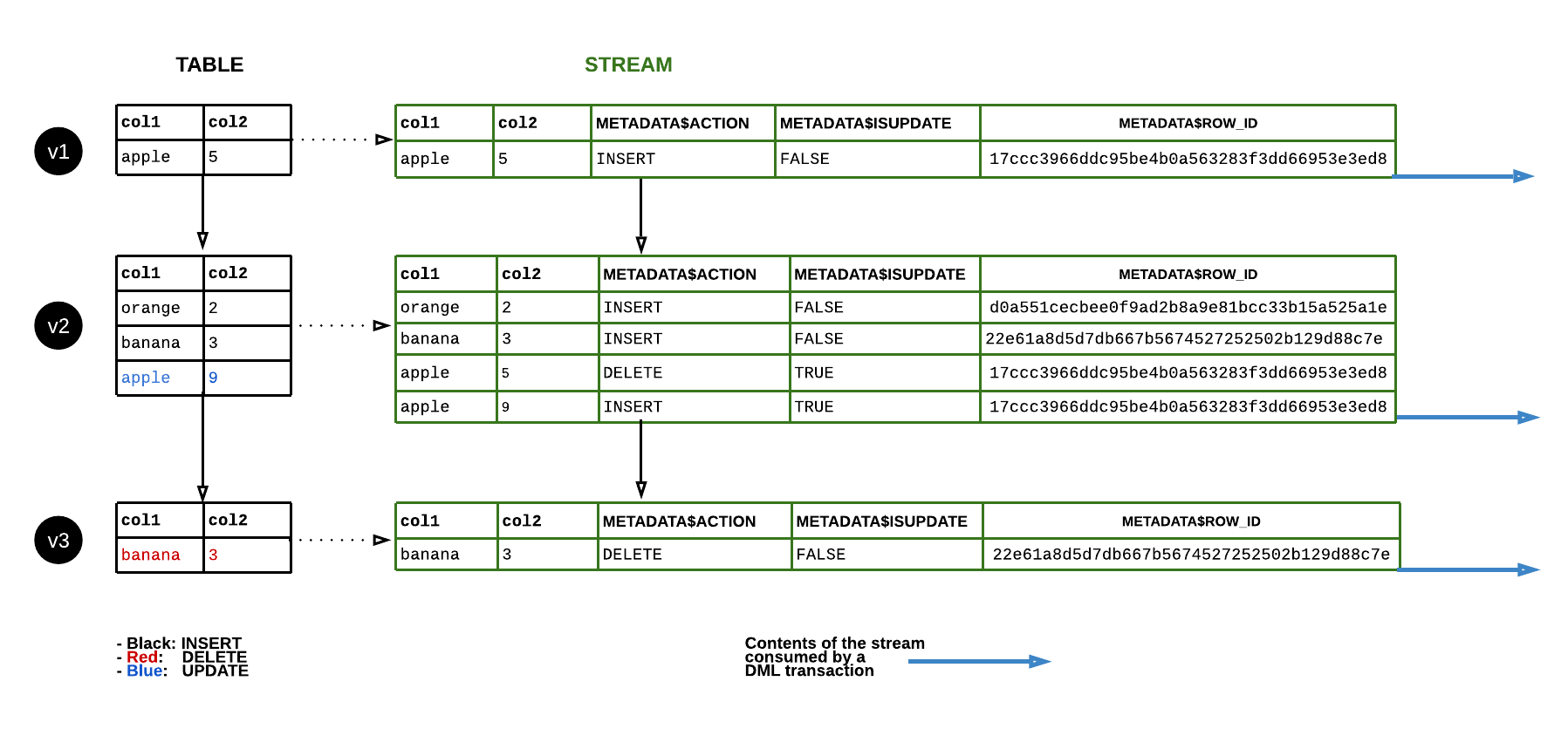
Data retention period and staleness¶
Ein Stream veraltet, wenn sein Offset außerhalb der Datenaufbewahrungsfrist seiner Quelltabelle (oder der zugrunde liegenden Tabellen einer Quellansicht) liegt. In einem veralteten Zustand sind historische Daten und alle ungenutzten Änderungsdatensätze für die Quelltabelle nicht mehr zugänglich. Um weiterhin neue Änderungsdatensätze zu verfolgen, müssen Sie den Stream mit dem Befehl CREATE STREAM neu erstellen.
Verbrauchen Sie die Stream-Datensätze innerhalb einer DML-Anweisung während der Aufbewahrungsfrist für die Tabelle, und verbrauchen Sie die Änderungsdaten regelmäßig vor dem STALE_AFTER-Zeitstempel (d. h. innerhalb der erweiterten Datenaufbewahrungsfrist für das Quellobjekt). Außerdem wird durch den Aufruf von SYSTEM$STREAM_HAS_DATA für den Stream verhindert, dass dieser veraltet, vorausgesetzt, der Stream ist leer und die Funktion SYSTEM$STREAM_HAS_DATA gibt FALSE zurück.
Weitere Informationen zu Datenaufbewahrungsfristen finden Sie unter Verstehen und Verwenden von Time Travel.
Bemerkung
Streams auf freigegebenen Tabellen oder Views verlängern die Datenaufbewahrungsfrist für die Tabelle bzw. die zugrunde liegenden Tabellen nicht. Weitere Informationen dazu finden Sie unter Streams auf freigegebenen Objekten.
Wenn die Datenaufbewahrungsfrist für eine Tabelle weniger als 14 Tage beträgt und kein Stream verbraucht wurde, verlängert Snowflake diese Frist vorübergehend, um ein Veralten des Streams zu verhindern. Die Aufbewahrungsfrist wird auf den Offset des Streams verlängert, standardmäßig bis maximal 14 Tage, unabhängig von Ihrer Snowflake-Edition. Die maximale Anzahl von Tagen, für die Snowflake die Datenaufbewahrungsfrist verlängern kann, wird durch den Parameterwert MAX_DATA_EXTENSION_TIME_IN_DAYS bestimmt. Sobald der Stream verarbeitet ist, wird die verlängerte Datenaufbewahrungsfrist wieder auf die Standardfrist der Tabelle zurückgesetzt.
In der folgenden Tabelle finden Sie Beispiele für die Werte DATA_RETENTION_TIME_IN_DAYS und MAX_DATA_EXTENSION_TIME_IN_DAYS, die angeben, wie oft der Inhalt des Streams verarbeitet werden sollte, um ein Veralten zu vermeiden:
DATA_RETENTION_TIME_IN_DAYS |
MAX_DATA_EXTENSION_TIME_IN_DAYS |
Streams in X Tagen verarbeiten |
|---|---|---|
14 |
0 |
14 |
1 |
14 |
14 |
0 |
90 |
90 |
Um den Status eines Streams zu überprüfen, verwenden Sie den Befehl DESCRIBE STREAM oder SHOW STREAMS. Der Zeitstempel der Spalte STALE_AFTER ist die erweiterte Datenaufbewahrungsfrist für das Quellobjekt. Sie zeigt an, wann der Stream voraussichtlich veraltet sein wird oder wann er veraltet ist, wenn der Zeitstempel in der Vergangenheit liegt. Dieser Zeitstempel wird berechnet, indem der größere Wert der Parametereinstellung DATA_RETENTION_TIME_IN_DAYS oder MAX_DATA_EXTENSION_TIME_IN_DAYS für das Quellobjekt zum letzten Zeitpunkt des Verbrauchs des Streams addiert wird.
Bemerkung
Wenn die Datenaufbewahrungsfrist für die Quelltabelle auf Schema- oder Datenbankebene festgelegt ist, muss die aktuelle Rolle Zugriff auf das Schema oder die Datenbank haben, um den STALE_AFTER-Wert berechnen zu können.
Durch das Einlesen von Änderungsdaten für einen Stream wird der STALE_AFTER-Zeitstempel aktualisiert. Auch wenn das Lesen des Streams noch einige Zeit nach dem STALE_AFTER-Zeitstempel möglich ist, kann der Stream jederzeit veralten. Die Spalte STALE zeigt an, ob der Stream voraussichtlich veraltet ist, auch wenn er möglicherweise noch nicht veraltet ist.
Um zu verhindern, dass ein Stream veraltet, verbrauchen Sie seine Änderungsdaten regelmäßig vor dem Zeitstempel STALE_AFTER (d. h. innerhalb der erweiterten Datenaufbewahrungsfrist für das Quellobjekt). Verlassen Sie sich nicht auf die Ergebnisse eines Streams, nachdem der Zeitraum von STALE_AFTER verstrichen ist, da die Funktion STREAM_HAS_DATA unerwartete Ergebnisse liefern könnte.
Nachdem der STALE_AFTER-Zeitstempel verstrichen ist, kann der Stream jederzeit veralten, auch wenn er keine unverbrauchten Datensätze enthält. Bei Abfragen eines Streams 0 Datensätze zurückgeben werden können, auch wenn es Änderungsdaten für das Quellobjekt gibt. Ein Nur-Anfügen-Stream verfolgt zum Beispiel nur das Einfügen von Zeilen, aber bei Aktualisierungs- und Löschvorgängen werden ebenfalls Änderungsdatensätze in ein Quellobjekt geschrieben. Außerdem erzeugen einige Tabellenschreibvorgänge, wie z. B. das Reclustering, keine Änderungsdaten. Wenn Sie Änderungsdaten für einen Datenstream verbrauchen, wird dessen Offset auf die Gegenwart vorverlegt, unabhängig davon, ob es dazwischen Änderungsdaten gibt.
Wichtig
Wenn Sie ein Objekt neu erstellen (mit der Syntax CREATE OR REPLACE TABLE), wird ihr Verlauf gelöscht, wodurch auch alle Streams auf der Tabelle oder Ansicht veraltet sind. Außerdem veraltet bei Neuerstellung oder Löschen einer der zugrunde liegenden Tabellen einer Ansicht jeder Stream der Ansicht.
Wenn eine Datenbank oder ein Schema, die bzw. das einen Stream enthält, und dessen Quelltabelle (oder die zugrunde liegenden Tabellen einer Quellansicht) geklont wird, kann derzeit auf keinen der nicht verbrauchten Datensätze im Streamklon zugegriffen werden. Dieses Verhalten ist konsistent mit Time Travel für Tabellen. Wenn eine Tabelle geklont wird, beginnen die historischen Daten für den Tabellenklon zu dem Zeitpunkt, an dem der Klon erstellt wurde.
Das Umbenennen eines Quellobjekts führt nicht dazu, dass ein Stream unterbrochen wird oder veraltet. Wenn ein Quellobjekt gelöscht und ein neues Objekt mit demselben Namen erstellt wird, werden außerdem alle mit dem ursprünglichen Objekt verknüpften Streams nicht mit dem neuen Objekt verknüpft.
Multiple consumers of streams¶
Wir empfehlen, dass Benutzer für jeden Verbraucher von Änderungsdatensätzen für ein Objekt einen separaten Stream erstellen. „Verbraucher“ bezieht sich dabei auf eine Aufgabe, ein Skript oder einen anderen Mechanismus, bei dem Änderungsdatensätze eines Objekts mithilfe einer DML-Transaktion genutzt („verbraucht“) werden. Wie bereits erwähnt, wird der Offset eines Streams nur dann erhöht, wenn er in einer DML-Transaktion verwendet wird. Dazu gehört eine Transaktion Create Table As Select (CTAS) oder eine COPY INTO Speicherort-Transaktion.
Verschiedene Verbraucher von Änderungsdaten in einem einzigen Datenstream rufen unterschiedliche Deltas ab, es sei denn, es wird Time Travel verwendet. Wenn die Änderungsdaten, die vom letzten Offset eines Datenstreams erfasst wurden, mit einer DML-Transaktion verbraucht werden, erhöht der Datenstrom den Offset. Die Änderungsdaten stehen für den nächsten Verbraucher nicht mehr zur Verfügung. Um dieselben Änderungsdaten eines Objekts verbrauchen zu können, erstellen Sie mehrere Streams für das Objekt. Ein Stream speichert nur einen Offset des Quellobjekts und nicht die eigentlichen Daten in den Tabellenspalten. Daher können Sie eine beliebige Anzahl von Streams für ein Objekt erstellen, ohne dass dies signifikante Kosten verursacht.
Streams on views¶
Streams on Views unterstützen sowohl lokale Ansichten als auch Ansichten, die mit Snowflake Secure Data Sharing freigegeben werden, einschließlich sicherer Ansichten. Beachten Sie, dass Streams Änderungen in materialisierten Ansichten nicht nachverfolgen können.
Streams sind auf Ansichten beschränkt, die die folgenden Anforderungen erfüllen:
- Zugrunde liegende Tabellen:
Alle zugrunde liegenden Tabellen müssen native Tabellen sein.
Die Ansicht kann nur die folgenden Operationen anwenden:
Projektionen
Filter
Innere Verknüpfungen und Kreuzverknüpfungen
UNION ALL
Verschachtelte Ansichten und Unterabfragen in der FROM-Klausel werden unterstützt, solange die vollständig erweiterte Abfrage die anderen Anforderungen in dieser Anforderungstabelle erfüllt.
- Abfrage auf Ansicht:
Allgemeine Anforderungen:
Die Abfrage kann eine beliebige Anzahl von Spalten auswählen.
Die Abfrage kann eine beliebige Anzahl von WHERE-Prädikaten enthalten.
Ansichten mit den folgenden Operationen werden noch nicht unterstützt:
GROUP BY-Klauseln
QUALIFY-Klauseln
Unterabfragen, die nicht in der FROM-Klausel enthalten sind
Korrelierte Unterabfragen
LIMIT-Klauseln
DISTINCT-Klauseln
Funktionen:
Die Funktionen in der Auswahlliste müssen systemdefinierte, skalare Funktionen sein.
- Änderungsverfolgung:
Die Änderungsverfolgung muss in den zugrunde liegenden Tabellen aktiviert sein.
Bevor Sie einen Stream für eine Ansicht erstellen, müssen Sie die Änderungsverfolgung für die zugrunde liegenden Tabellen für die Ansicht aktivieren. Anweisungen dazu finden Sie unter Enabling change tracking on views and underlying tables.
Join results behavior¶
Bei der Untersuchung der Ergebnisse eines Datenstreams, der Änderungen an einer Ansicht verfolgt, die eine Verknüpfung (Join) enthält, ist es wichtig zu verstehen, welche Daten verknüpft werden. Änderungen, die seit dem Stream-Offset in der linken Tabelle aufgetreten sind, werden mit der rechten Tabelle verknüpft. Änderungen, die seit dem Stream-Offset in der rechten Tabelle aufgetreten sind, werden mit der linken Tabelle verknüpft. Änderungen, die seit dem Stream-Offset in beiden Tabellen aufgetreten sind, werden jeweils miteinander verknüpft.
Betrachten Sie das folgende Beispiel:
Es werden zwei Tabellen erstellt:
create or replace table orders (id int, order_name varchar);
create or replace table customers (id int, customer_name varchar);
Eine Ansicht wird erstellt, um die beiden Tabellen anhand der id zu verknüpfen. Jede Zeile der einen Tabelle ist mit einer Zeile der anderen Tabelle verknüpft ist:
create or replace view ordersByCustomer as select * from orders natural join customers;
insert into orders values (1, 'order1');
insert into customers values (1, 'customer1');
Es wird ein Stream erstellt, der Änderungen an der Ansicht verfolgt:
create or replace stream ordersByCustomerStream on view ordersBycustomer;
Die Ansicht hat genau einen Eintrag und der Stream hat keinen, da es seit dem aktuellen Offset des Streams keine Änderungen an den Tabellen gab:
select * from ordersByCustomer;
+----+------------+---------------+
| ID | ORDER_NAME | CUSTOMER_NAME |
|----+------------+---------------|
| 1 | order1 | customer1 |
+----+------------+---------------+
select * exclude metadata$row_id from ordersByCustomerStream;
+----+------------+---------------+-----------------+-------------------+
| ID | ORDER_NAME | CUSTOMER_NAME | METADATA$ACTION | METADATA$ISUPDATE |
|----+------------+---------------+-----------------+-------------------|
+----+------------+---------------+-----------------+-------------------+
Sobald die zugrunde liegenden Tabellen aktualisiert wurden, führt die Auswahl von ordersByCustomerStream zu Datensätzen von orders × Δ customers + Δ orders × customers + Δ orders × Δ customers, wobei:
Δ
ordersund Δcustomerssind die Änderungen, die seit dem Stream-Offset an jeder Tabelle vorgenommen wurden.„orders“ und „customers“ sind der Gesamtinhalt der Tabellen zum aktuellen Stream-Offset.
Beachten Sie, dass aufgrund von Optimierungen in Snowflake die Kosten für die Berechnung dieses Ausdrucks nicht immer linear proportional zur Größe der Eingaben sind.
Wenn eine weitere Verknüpfungszeile in orders eingefügt wird, erhält ordersByCustomer eine neue Zeile:
insert into orders values (1, 'order2');
select * from ordersByCustomer;
+----+------------+---------------+
| ID | ORDER_NAME | CUSTOMER_NAME |
|----+------------+---------------|
| 1 | order1 | customer1 |
| 1 | order2 | customer1 |
+----+------------+---------------+
Die Auswahl von ordersByCustomersStream erstellt eine Zeile, weil Δ orders × customers die neue Einfügung enthält und orders × Δ customers + Δ orders × Δ customers leer ist:
select * exclude metadata$row_id from ordersByCustomerStream;
+----+------------+---------------+-----------------+-------------------+
| ID | ORDER_NAME | CUSTOMER_NAME | METADATA$ACTION | METADATA$ISUPDATE |
|----+------------+---------------+-----------------+-------------------|
| 1 | order2 | customer1 | INSERT | False |
+----+------------+---------------+-----------------+-------------------+
Wenn dann eine weitere Verknüpfungszeile in customers eingefügt wird, hat ordersByCustomer insgesamt drei neue Zeilen:
insert into customers values (1, 'customer2');
select * from ordersByCustomer;
+----+------------+---------------+
| ID | ORDER_NAME | CUSTOMER_NAME |
|----+------------+---------------|
| 1 | order1 | customer1 |
| 1 | order2 | customer1 |
| 1 | order1 | customer2 |
| 1 | order2 | customer2 |
+----+------------+---------------+
Die Auswahl von ordersByCustomersStream erstellt drei Zeilen, da Δ orders × customers, orders × Δ customers und Δ orders × Δ customers jeweils eine Zeile ergeben:
select * exclude metadata$row_id from ordersByCustomerStream;
+----+------------+---------------+-----------------+-------------------+
| ID | ORDER_NAME | CUSTOMER_NAME | METADATA$ACTION | METADATA$ISUPDATE |
|----+------------+---------------+-----------------+-------------------|
| 1 | order1 | customer2 | INSERT | False |
| 1 | order2 | customer1 | INSERT | False |
| 1 | order2 | customer2 | INSERT | False |
+----+------------+---------------+-----------------+-------------------+
Beachten Sie, dass bei Nur-Anfügen-Streams Δ orders und Δ customers nur Zeileneinfügungen enthalten, während orders und customers den vollständigen Inhalt der Tabellen einschließlich aller Aktualisierungen enthalten, die vor dem Stream-Offset erfolgt sind.
CHANGES clause: Read-only alternative to streams¶
Als Alternative zu Streams unterstützt Snowflake das Abfragen von Änderungsverfolgungsmetadaten für Tabellen mithilfe der CHANGES-Klausel für SELECT-Anweisungen. Die CHANGES-Klausel ermöglicht das Abfragen von Änderungsverfolgungsmetadaten zwischen zwei Zeitpunkten, ohne dass ein Stream mit einem expliziten Transaktionsoffset erstellt werden muss. Wenn Sie die CHANGES-Klausel verwenden, wird der Offset nicht erhöht (d. h. es werden keine Datensätze verarbeitet). Die Änderungsverfolgungsmetadaten zwischen verschiedenen Transaktionsstart- und -endpunkten können von mehreren Abfragen abgerufen werden. Für diese Option muss ein Transaktionsstartpunkt für die Metadaten mithilfe einer AT | BEFORE-Klausel angegeben werden. Der Endpunkt für das Änderungsverfolgungsintervall kann mit der optionalen END-Klausel festgelegt werden.
Ein Stream speichert die aktuelle Tabellenversion der Transaktion und ist in den meisten Szenarien die geeignete Quelle für CDC-Datensätze. Für seltene Szenarien, in denen der Offset für beliebige Zeiträume verwaltet werden muss, steht Ihnen die CHANGES-Klausel zur Verfügung.
Derzeit muss auch Folgendes erfüllt („true“) sein, bevor Änderungsverfolgungsmetadaten erfasst werden:
- Tabellen:
Aktivieren Sie entweder die Änderungsverfolgung für die Tabelle (mit ALTER TABLE … CHANGE_TRACKING = TRUE), oder erstellen Sie einen Stream auf der Tabelle (mit CREATE STREAM).
- Ansichten:
Aktivieren Sie die Änderungsverfolgung für die Ansicht und die ihr zugrunde liegenden Tabellen. Eine Anleitung dazu finden Sie unter Enabling change tracking on views and underlying tables.
Beim Aktivieren der Änderungsverfolgung werden der Tabelle einige ausgeblendete Spalten hinzugefügt, und dann wird mit dem Speichern von Metadaten zur Änderungsverfolgung begonnen. Die Werte in diesen ausgeblendeten CDC-Datenspalten liefern die Eingabe für die Metadaten-Spalten des Streams. Die Spalten verbrauchen wenig Speicherplatz.
Für den Zeitraum, bevor eine dieser Bedingungen erfüllt ist, sind keine Änderungsverfolgungsmetadaten für das Objekt verfügbar.
Required access privileges¶
Das Abfragen eines Streams erfordert eine Rolle mit mindestens den folgenden Rollenberechtigungen:
Objekt |
Berechtigung |
Anmerkungen |
|---|---|---|
Datenbank |
USAGE |
|
Schema |
USAGE |
|
Stream |
SELECT |
|
Tabelle |
SELECT |
Nur Streams auf Tabellen. |
Ansicht |
SELECT |
Nur Streams on Views. |
Externer Stagingbereich |
USAGE |
Nur Streams auf Verzeichnistabellen (in externen Stagingbereichen) |
Interner Stagingbereich |
READ |
Nur Streams auf Verzeichnistabellen (in internen Stagingbereichen) |
Billing for streams¶
Wie unter Datenaufbewahrungsfrist und Veraltung (unter diesem Thema) beschrieben, verlängert Snowflake vorübergehend die Datenaufbewahrungsfrist für die Quelltabelle bzw. die zugrunde liegenden Tabellen der Quellansicht, wenn ein Stream nicht regelmäßig verarbeitet wird. Wenn die Datenaufbewahrungsfrist der Tabelle weniger als 14 Tage beträgt, wird der Zeitraum unabhängig von der Snowflake-Edition Ihres Kontos automatisch auf den kleineren Transaktionsoffset des Streams oder auf 14 Tage (wenn die Datenaufbewahrungsfrist der Tabelle kleiner als 14 Tage ist) verlängert.
Beachten Sie, dass eine erweiterte Datenaufbewahrungsfrist zusätzlichen Speicherplatz erfordert, was sich in Ihren monatlichen Speicherkosten widerspiegelt.
Die mit einem Stream verbundenen Hauptkosten entstehen durch die Verarbeitungszeit, die ein virtuelles Warehouse für die Abfrage des Streams benötigt. Diese Gebühren sind auf der Rechnung als übliche Snowflake-Credits ausgewiesen.
Einschränkungen¶
Für Streams gelten die folgenden Beschränkungen:
Sie können keine Standard- oder Nur-Anfügen-Streams für Apache Iceberg™-Tabellen verwenden, die einen externen Katalog verwenden. (Nur Nur-Einfügen-Streams werden unterstützt.)
Sie können Änderungen in einer Ansicht mit GROUP BY-Klauseln nicht nachverfolgen.
Nach dem Hinzufügen oder Ändern einer Spalte, die NOT NULL sein soll, können Abfragen auf Streams fehlschlagen, wenn der Stream Zeilen mit unzulässigen NULL-Werten ausgibt. Dies geschieht, weil das Schema des Streams die aktuelle Einschränkung NOT NULL erzwingt, die nicht mit den vom Stream zurückgegebenen historischen Daten übereinstimmt.
Wenn eine von Streams auf Ansichten eine Aufgabe getriggert wird, dann werden alle Änderungen an Tabellen, auf die die Abfrage von Streams auf Ansichten verweist, auch die Aufgabe triggern, unabhängig von allen Verknüpfungen, Aggregationen oder Filtern in der Abfrage.
Streams werden bei partitionierten externen Tabellen oder partitionierten Apache Iceberg™-Tabellen, die von einem externen Katalog verwaltet werden, nicht unterstützt.