Clés de clustering et tables en cluster¶
En général, Snowflake produit des données bien groupées dans des tables. Toutefois, avec le temps, en particulier parce que le DML intervient sur de très grandes tables (tel que défini par la quantité de données dans la table et non par le nombre de lignes), les données de certaines lignes de la table risquent de ne plus se regrouper de façon optimale selon les dimensions souhaitées.
Pour améliorer le clustering des micro-partitions de la table sous-jacente, vous pouvez toujours trier manuellement les lignes sur les colonnes de la table de clés et les réinsérer dans la table. Cependant, ces tâches peuvent être lourdes et coûteuses.
Au lieu de cela, Snowflake prend en charge l’automatisation de ces tâches en désignant une ou plusieurs colonnes/expressions de table comme une clé de clustering pour la table. Une table avec une clé de clustering définie est considérée comme étant en cluster.
Vous pouvez regrouper en cluster des vues matérialisées, ainsi que des tables. Les règles de clustering de tables et de vues matérialisées sont généralement les mêmes. Pour quelques conseils supplémentaires spécifiques aux vues matérialisées, voir Vues matérialisées et clustering et Meilleures pratiques pour les vues matérialisées.
Attention
Les clés de clustering ne sont pas prévues pour toutes les tables en raison des coûts de clustering initial des données et de maintenance du clustering. Le clustering est optimal à ces deux moments :
Vous avez besoin des temps de réponse les plus rapides possibles, quel que soit le coût.
L’amélioration des performances de vos requêtes compense les crédits nécessaires au regroupement et à la maintenance de la table.
Pour plus d’informations sur le choix des tables à regrouper, voir : Considérations sur le choix du clustering pour une table.
Qu’est-ce qu’une clé de clustering ?¶
Une clé de clustering est un sous-ensemble de colonnes dans une table (ou d’expressions sur une table) qui sont explicitement désignées pour co-localiser les données dans la table dans les mêmes micro-partitions. Ceci est utile pour les très grandes tables pour lesquelles l’ordre n’était pas idéal (au moment où les données ont été insérées/chargées) ou lorsqu’un DML important a causé la dégradation du clustering naturel de la table.
Voici quelques indicateurs généraux qui peuvent aider à déterminer s’il est nécessaire de définir une clé de clustering pour une table :
Les requêtes sur la table s’exécutent plus lentement que prévu ou se sont sensiblement dégradées avec le temps.
La profondeur de clustering de la table est importante.
Une clé de clustering peut être définie lors de la création de la table (à l’aide de la commande CREATE TABLE) ou ultérieurement (à l’aide de la commande ALTER TABLE). La clé de clustering d’une table peut également être modifiée ou supprimée à tout moment.
Attention
Il n’est pas possible de définir de clés de clustering pour des tables hybrides. Dans les tables hybrides, les données sont toujours triées par clé primaire.
Avantages de la définition de clés de clustering (pour les très grandes tables)¶
L’utilisation d’une clé de clustering pour co-localiser des lignes similaires dans les mêmes micro-partitions offre plusieurs avantages pour les très grandes tables, notamment :
Amélioration de l’efficacité de l’analyse des requêtes en ignorant les données qui ne correspondent pas aux prédicats de filtrage.
Meilleure compression des colonnes que dans les tables sans clustering. Ceci est particulièrement vrai lorsque d’autres colonnes sont étroitement liées aux colonnes qui comprennent la clé de clustering.
Une fois qu’une clé a été définie sur une table, aucune administration supplémentaire n’est requise, sauf si vous avez choisi de détruire ou de modifier la clé. Toute la maintenance future sur les lignes de la table (pour assurer un clustering optimal) est effectuée automatiquement par Snowflake.
Bien que le clustering puisse considérablement améliorer les performances et réduire le coût de certaines requêtes, les ressources de calcul utilisées pour effectuer le clustering consomment des crédits. En tant que tel, vous devez réaliser une mise en cluster uniquement lorsque les requêtes bénéficieront considérablement du clustering.
En règle générale, les requêtes tirent parti du clustering lorsque celles-ci effectuent un filtrage ou un tri sur la clé de clustering de la table. Le tri est généralement effectué pour les opérations ORDER BY, pour les opérations GROUP BY et pour certaines jointures. Par exemple, la jointure suivante provoquerait probablement une opération de tri par Snowflake :
Dans ce pseudo-exemple, Snowflake est susceptible de trier les valeurs dans my_materialized_view.col1 ou my_table.col1. Par exemple, si les valeurs de my_table.col1 sont triées, alors que la vue matérialisée est en cours d’analyse, Snowflake peut rapidement trouver la ligne correspondante dans my_table.
Plus une table est interrogée fréquemment, plus vous tirez de bénéfices du clustering. Cependant, plus une table change fréquemment, plus il sera coûteux de la garder en cluster. Par conséquent, le clustering est généralement la solution la plus rentable pour les tables interrogées fréquemment et ne changeant pas fréquemment.
Note
Une fois que vous avez défini la clé de clustering pour une table, les lignes ne sont pas nécessairement mises à jour immédiatement. Snowflake n’effectue une maintenance automatisée que si la table bénéficie de l’opération. Pour plus de détails, voir Reclustering (dans ce chapitre) et Clustering automatique.
Considérations sur le choix du clustering pour une table¶
Que vous souhaitiez des temps de réponse plus rapides ou des coûts globaux plus faibles, le clustering est la meilleure solution pour une table qui répond à tous les critères suivants :
La table contient un grand nombre de micro-partitions. En général, cela signifie que la table contient plusieurs téraoctets (TB) de données.
Les requêtes peuvent tirer parti du clustering. En général, cela signifie que l’une des deux conditions suivantes, ou les deux, sont remplies :
Les requêtes sont sélectives. En d’autres termes, les requêtes ne doivent lire qu’un petit pourcentage de lignes (et donc généralement un petit pourcentage de micro-partitions) dans la table.
Les requêtes trient les données. (Par exemple, la requête contient une clause ORDER BY sur la table).
Un pourcentage élevé de requêtes peut bénéficier de la ou des mêmes clés de clustering. En d’autres termes, la plupart des requêtes sélectionnent ou trient sur les mêmes colonnes.
Si votre objectif est principalement de réduire les coûts globaux, chaque table clusterisée doit avoir un ratio élevé de requêtes par rapport aux opérations DML (INSERT/UPDATE/DELETE). Cela signifie généralement que la table est interrogée fréquemment et mise à jour peu fréquemment. Si vous voulez regrouper une table qui connaît beaucoup de DML, envisagez de regrouper les instructions DML en lots importants et peu fréquents.
De plus, avant de choisir de mettre en cluster une table, Snowflake recommande vivement de tester un ensemble représentatif de requêtes sur la table pour établir quelques lignes de base de performances.
Stratégies de sélection des clés de clustering¶
Une seule clé de clustering peut contenir une ou plusieurs colonnes ou expressions. Pour la plupart des tables, Snowflake recommande un maximum de 3 ou 4 colonnes (ou expressions) par clé. L’ajout de plus de 3-4 colonnes a tendance à augmenter les coûts plus que les avantages.
Sélectionner les colonnes/expressions adaptées pour une clé de clustering peut avoir un effet important sur les performances de requête. Analyser votre charge de travail permettra généralement de trouver des clés de clustering idéales.
Snowflake recommande de hiérarchiser les clés dans l’ordre suivant :
Colonnes de cluster les plus activement utilisées dans les filtres sélectifs. Pour de nombreuses tables de faits impliquées dans des requêtes par date (par exemple, « WHERE facture_date > x AND date de facturation < = y »), il est judicieux de choisir la colonne de date. Pour les tables d’événements, le type d’événement peut constituer un bon choix s’il existe un grand nombre de types d’événements différents. (Si votre table ne contient qu’un petit nombre de types d’événements différents, reportez-vous aux commentaires sur la cardinalité ci-dessous avant de choisir une colonne d’événements comme clé de clustering.)
S’il y a de la place pour des clés de cluster supplémentaires, considérez les colonnes fréquemment utilisées dans les prédicats de jointure, par exemple « FROM table1 JOIN table2 ON table2 .colonne_A = table1 .colonne_B ».
Si vous filtrez généralement les requêtes en fonction de deux dimensions (colonnes application_id et user_status, par exemple), alors le clustering sur les deux colonnes peut améliorer les performances.
Le nombre de valeurs distinctes (c’est-à-dire la cardinalité) dans une colonne/expression est un aspect essentiel de la sélection d’une clé de clustering. Il est important de choisir une clé de clustering qui a :
Un nombre suffisant de valeurs distinctes pour permettre un nettoyage efficace sur la table.
Un nombre de valeurs distinctes suffisamment restreint pour permettre à Snowflake de regrouper efficacement les lignes dans les mêmes micro-partitions.
Une colonne dont la cardinalité est très faible peut ne donner lieu qu’à un nettoyage minimal, comme une colonne nommée IS_NEW_CUSTOMER qui ne contient que des valeurs booléennes. À l’opposé, une colonne avec une cardinalité très élevée n’est généralement pas un bon candidat à utiliser directement comme clé de clustering. Par exemple, une colonne contenant des valeurs d’horodatage à la nanoseconde ne constituerait pas une bonne clé de clustering.
Astuce
En général, si une colonne (ou une expression) a une cardinalité plus élevée, le maintien du clustering sur cette colonne est plus coûteux.
Le coût du clustering sur une clé unique peut aller au-delà des avantages du clustering sur cette clé, en particulier si les recherches ponctuelles ne constituent pas le principal cas d’utilisation de cette table.
Si vous voulez utiliser une colonne avec une cardinalité très élevée comme clé de clustering, Snowflake recommande de définir la clé comme une expression sur la colonne, plutôt que directement sur la colonne, pour réduire le nombre de valeurs distinctes. L’expression doit conserver l’ordre d’origine de la colonne afin que les valeurs minimale et maximale de chaque partition permettent toujours le nettoyage.
Par exemple, si une table de faits possède une colonne TIMESTAMP c_timestamp contenant de nombreuses valeurs discrètes (beaucoup plus que le nombre de micro-partitions dans la table), alors une clé de clustering pourrait être définie sur la colonne en convertissant les valeurs en dates au lieu d’horodatages (p. ex. to_date(c_timestamp)). Cela réduirait la cardinalité au nombre total de jours, ce qui donne généralement de bien meilleurs résultats de nettoyage.
Comme autre exemple, vous pouvez tronquer un nombre pour obtenir moins de chiffres significatifs en utilisant les fonctions TRUNC et une valeur négative pour l’échelle (par exemple, TRUNC(123456789, -5)).
Astuce
Si vous définissez une clé de clustering multi-colonnes pour une table, l’ordre dans lequel les colonnes sont spécifiées dans la clause CLUSTER BY est important. En règle générale, Snowflake recommande de classer les colonnes de cardinalité minimale à cardinalité maximale. Placer une colonne de cardinalité supérieure avant une colonne de cardinalité inférieure réduira généralement l’efficacité du clustering sur cette dernière colonne.
Astuce
Lors d’un clustering sur un champ de texte, les métadonnées de la clé du cluster ne suivent que les premiers octets (généralement 5 ou 6 octets). Notez que pour les jeux de caractères multi-octets, cela peut être inférieur à 5 caractères.
Dans certains cas, le clustering des colonnes utilisées dans les clauses GROUP BY ou ORDER BY peut être utile. Toutefois, le clustering sur ces colonnes est généralement moins utile que le clustering sur des colonnes fortement utilisées dans les opérations de filtrage ou JOIN. Si vous avez des colonnes fortement utilisées dans les opérations de filtrage/jointure et différentes colonnes utilisées dans des opérations ORDER BY ou GROUP BY, privilégiez les colonnes utilisées dans les opérations de filtrage et de jointure.
Reclustering¶
Étant donné que les opérations DML (INSERT, UPDATE, DELETE, MERGE, COPY) sont effectuées sur une table groupée, les données de la table pourraient devenir moins groupées. Un reclustering périodique/régulier de la table est nécessaire pour maintenir un clustering optimal.
Lors du reclustering, Snowflake utilise une clé de clustering de la table mise en cluster pour réorganiser les données des colonnes, de sorte que les enregistrements liés soient déplacés vers la même micro-partition. Cette opération DML supprime les enregistrements concernés et les réinsère, regroupés en fonction de la clé de clustering.
Note
Le reclustering dans Snowflake est automatique ; aucune maintenance n’est nécessaire. Pour plus de détails, voir Clustering automatique.
Cependant, pour certains comptes, le reclustering manuel a été retiré, mais il est toujours autorisé. Pour plus de détails, voir Reclustering manuel.
Conséquences du reclustering sur les crédits et le stockage¶
Semblable à toutes les opérations DML dans Snowflake, le reclustering consomme des crédits. Le nombre de crédits consommés dépend de la taille de la table et de la quantité de données à regrouper de nouveau en cluster.
Le reclustering entraîne également des coûts de stockage. Chaque fois que des données sont regroupées en cluster, les lignes sont physiquement regroupées en fonction de la clé de clustering pour la table, ce qui fait que Snowflake génère de nouvelles micro-partitions pour la table. L’ajout d’un petit nombre de lignes à une table peut recréer toutes les micro-partitions qui contiennent ces valeurs.
Ce processus peut créer une rotation importante des données, car les micro-partitions d’origine sont marquées comme supprimées, mais conservées dans le système pour activer les fonctions Time Travel et Fail-safe. Les micro-partitions originales ne sont purgées qu’après l’expiration de la période de conservation Time Travel et de la période Fail-safe suivante (c’est-à-dire minimum 8 jours et maximum 97 jours pour le Time Travel étendu si vous utilisez Snowflake Enterprise Edition ou une version supérieure). Cela entraîne généralement une augmentation des coûts de stockage. Pour plus d’informations, voir Time Travel et Fail-safe de Snowflake.
Important
Avant de définir une clé de clustering pour une table, vous devriez prendre en compte les coûts de crédit et de stockage associés.
Exemple de reclustering¶
S’appuyant sur le diagramme de clustering de la rubrique précédente, ce diagramme montre comment le reclustering d’une table peut aider à réduire l’analyse des micro-partitions afin d’améliorer les performances des requêtes :
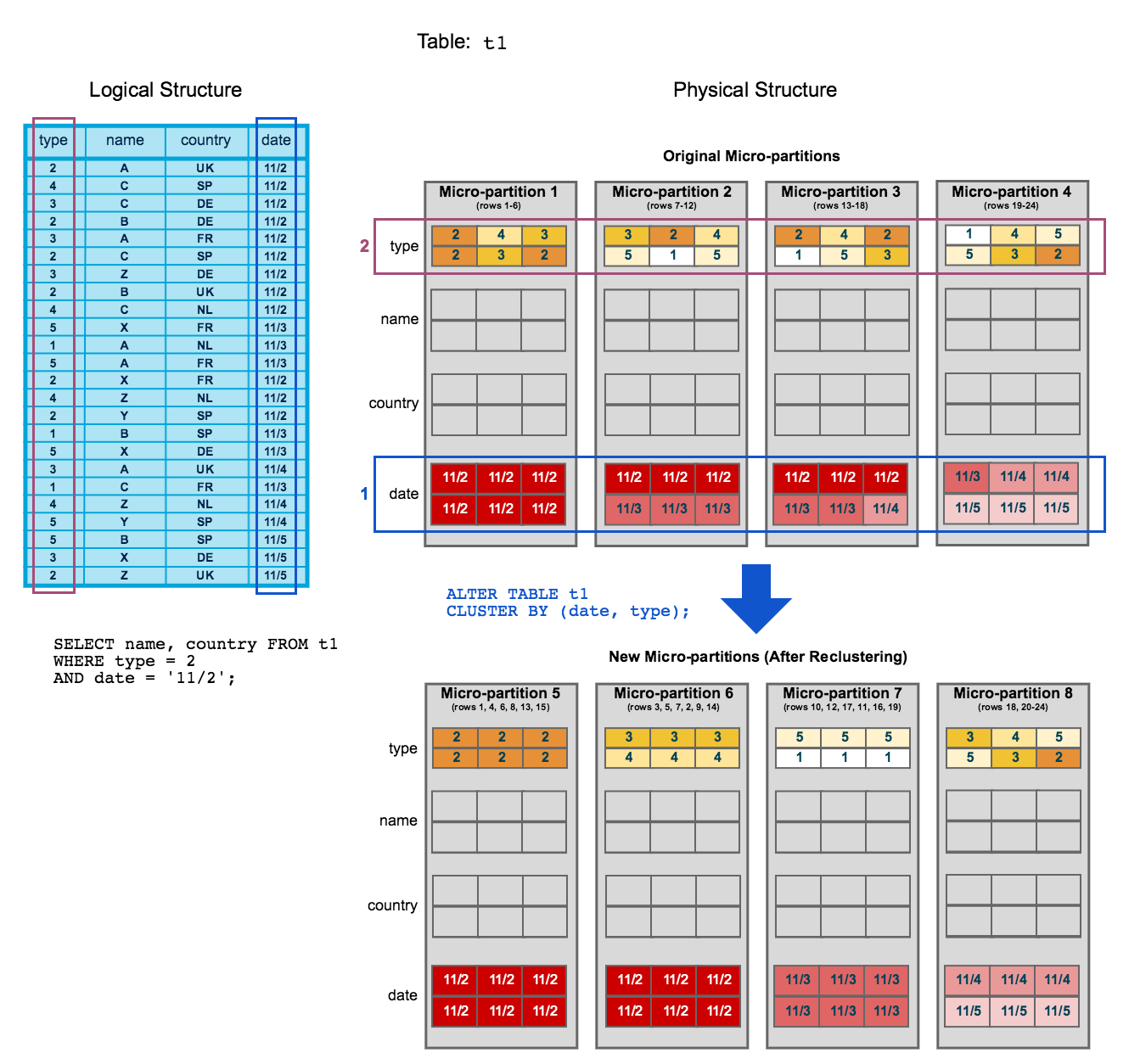
Pour commencer, la table
t1est naturellement regroupée pardateà travers les micro-partitions 1-4.La requête (dans le diagramme) nécessite l’analyse des micro-partitions 1, 2 et 3.
dateettypesont définis en tant que clé de clustering. Lorsque la table est remise en cluster, de nouvelles micro-partitions (5-8) sont créées.Après le reclustering, la même requête analyse uniquement les micro-partitions 5.
En outre, après le reclustering :
La micro-partition 5 a atteint un état constant (c’est-à-dire qu’elle ne peut pas être améliorée par le reclustering) et est donc exclue lors du calcul de la profondeur et du chevauchement pour une future maintenance. Dans une grande table bien regroupée, la plupart des micro-partitions entrent dans cette catégorie.
Les micro-partitions originales (1-4) sont marquées comme supprimées, mais elles ne sont pas purgées du système. Elles sont conservées pour Time Travel et Fail-safe.
Note
Cet exemple illustre les conséquences d’un reclustering à très petite échelle. À l’échelle d’une très grande table (c’est-à-dire composée de millions de micro-partitions), le reclustering peut avoir des conséquences importantes sur l’analyse et, par conséquent, sur la performance des requêtes.
Définition de tables en cluster¶
Calcul des informations de clustering pour une table¶
Utilisez la fonction système, SYSTEM$CLUSTERING_INFORMATION, pour calculer les détails de clustering, y compris la profondeur de clustering, pour une table donnée. Cette fonction peut être exécutée sur n’importe quelle colonne de n’importe quelle table, que la table ait une clé de clustering explicite ou non :
Si une table possède une clé de clustering explicite, la fonction ne nécessite aucun argument d’entrée autre que le nom de la table.
Si une table n’a pas de clé de clustering explicite (ou si une table a une clé de clustering, mais que vous voulez calculer le ratio sur d’autres colonnes de la table), la fonction prend la ou les colonnes souhaitées comme argument d’entrée supplémentaire.
Définition d’une clé de clustering pour une table¶
Une clé de clustering peut être définie lors de la création d’une table en ajoutant une clause CLUSTER BY à CREATE TABLE :
Chaque clé de clustering est composée d’une ou de plusieurs colonnes/expressions de table, pouvant être de n’importe quel type de données, sauf GEOGRAPHY, VARIANT, OBJECT ou ARRAY. Une clé de clustering peut contenir l’un des éléments suivants :
Des colonnes de base.
Des expressions sur des colonnes de base.
Expressions sur les chemins dans les colonnes VARIANT.
Par exemple :
Notes importantes sur l’utilisation¶
Pour chaque colonne VARCHAR, l’implémentation actuelle du clustering n’utilise que les cinq premiers octets.
Si les N premiers caractères sont les mêmes pour chaque ligne ou s’ils ne fournissent pas une cardinalité suffisante, il faut alors envisager un clustering sur une sous-chaîne qui commence après les caractères identiques et qui présente une cardinalité optimale. (Pour plus d’informations sur la cardinalité optimale, voir Stratégies de sélection des clés de clustering). Par exemple :
Si vous définissez deux ou plusieurs colonnes/expressions en tant que clé de clustering pour une table, l’ordre a un impact sur la façon dont les données sont regroupées en micro-partitions.
Pour plus de détails, voir Stratégies de sélection des clés de clustering (dans ce chapitre).
Une clé de clustering existante est copiée lorsqu’une table est créée en utilisant CREATE TABLE … CLONE. Cependant, le clustering automatique est suspendu sur pour la table clonée et doit être repris.
Une clé de clustering existante n’est pas prise en charge lorsqu’une table est créée à l’aide de CREATE TABLE … AS SELECT ; cependant, vous pouvez définir une clé de clustering après la création de la table.
La définition d’une clé de clustering directement au-dessus des colonnes VARIANT n’est pas prise en charge. Toutefois, vous pouvez spécifier une colonne VARIANT dans une clé de clustering si vous fournissez une expression composée du chemin et du type de cible.
Modification de la clé de clustering d’une table¶
À tout moment, vous pouvez ajouter une clé de clustering à une table existante ou modifier la clé de clustering existante d’une table en utilisant ALTER TABLE.
Par exemple :
Notes importantes sur l’utilisation¶
Lors de l’ajout d’une clé de clustering à une table déjà remplie de données, toutes les expressions ne sont pas autorisées à être spécifiées en tant que clé de clustering. Vous pouvez vérifier si une fonction spécifique est prise en charge en utilisant SHOW FUNCTIONS :
show functions like 'function_name';La sortie comprend une colonne,
valid_for_clustering, à la fin de la sortie. Cette colonne indique si la fonction peut être utilisée dans une clé de clustering pour une table remplie.La modification de la clé de clustering d’une table n’affecte pas les enregistrements existants de la table jusqu’à ce que la table ait fait l’objet d’un reclustering par Snowflake.
Destruction des clés de clustering d’une table¶
À tout moment, vous pouvez détruire la clé de clustering d’une table en utilisant ALTER TABLE :
Par exemple :