Snowpark Container Services: サービスの操作¶
:doc:`Snowpark Container Services <overview>`を使用すると、コンテナ化されたアプリケーションをより簡単に展開、管理、スケーリングできるようになります。アプリケーションを作成し、Snowflakeアカウントのリポジトリにアプリケーションイメージをアップロードしたら、アプリケーションコンテナをサービスとして実行できます。
サービスは、疑似マシン (VM) ノードのコレクションである コンピューティングプール 上でコンテナ化されたアプリケーションを実行するSnowflakeを表します。サービスには2つのタイプがあります。
長時間実行サービス。 長時間実行サービスとは、自動的に終了しないウェブサービスのようなものです。サービスを作成した後、Snowflakeは実行中のサービスを管理します。たとえば、何らかの理由でサービスコンテナーが停止した場合、Snowflakeはそのコンテナーを再起動し、サービスが中断されることなく実行されるようにします。
ジョブサービス。 ジョブサービスは、ストアドプロシージャと同じように、コードが終了すると終了します。すべてのコンテナが終了すると、ジョブサービスは完了します。
次の図は、サービスのアーキテクチャを示しています。
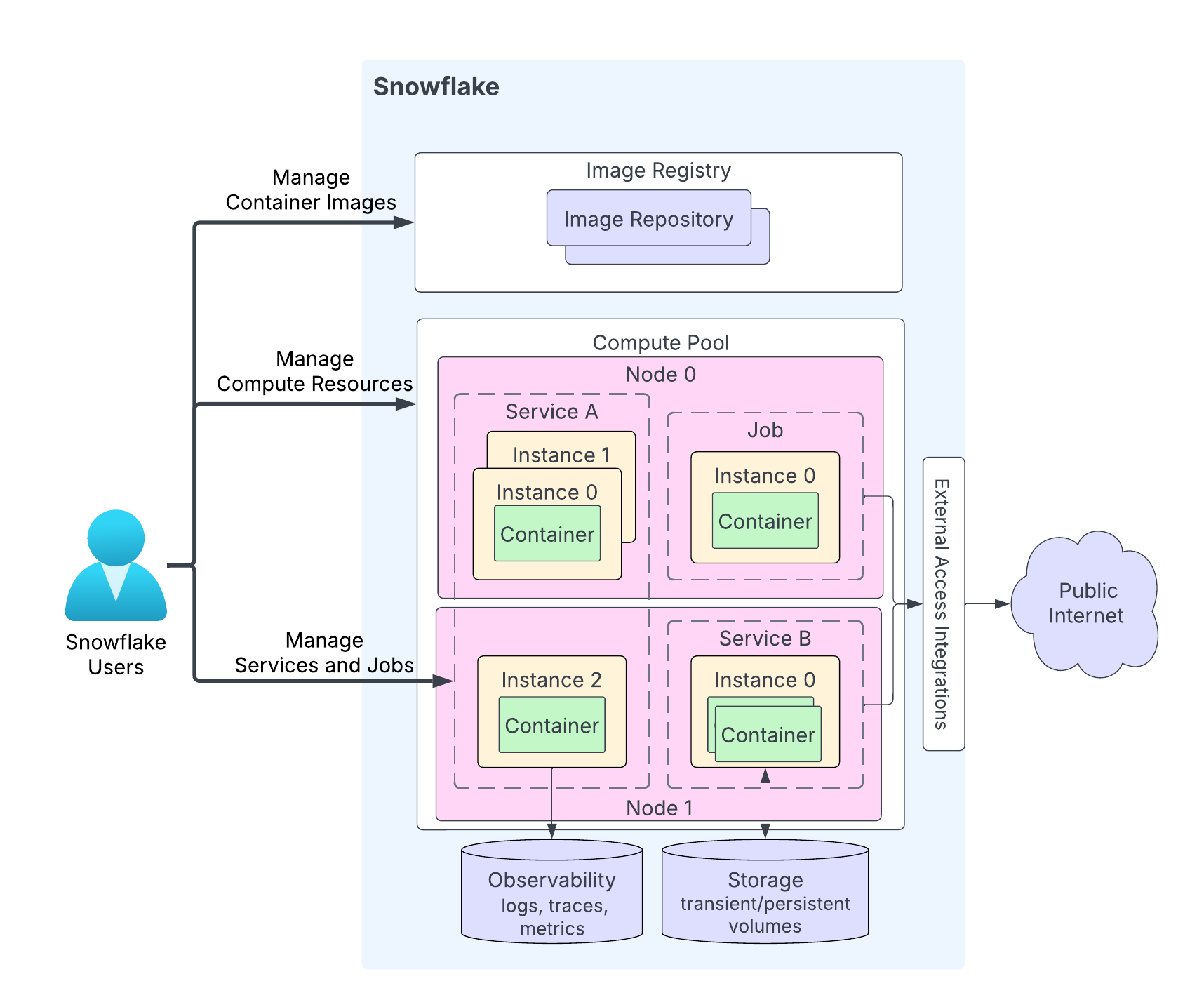
この図のハイライトは以下の通りです。
ユーザーはアプリケーションコードをSnowflakeアカウントのリポジトリにアップロードします。イメージレジストリサービスは、リポジトリに OCI 準拠のイメージを保存するための OCIv2 API を提供します。例えば、Docker API を使ってイメージをリポジトリにアップロードすることができます。サービスを作成する際に、使用するイメージを指定します。
コンピューティングプールは、Snowflakeがサービスを実行する場所です。この図は、2つのコンピュートノード(ノード0とノード1)を持つコンピューティングプールを示しています。Snowflakeはノード上でサービスインスタンスを実行します。複数のサービスインスタンスを実行する場合、リソース要件に応じて、Snowflakeはそれらを同じノードで実行したり、複数のノードに分散して実行したりします。例:
ノード0はサービスA(そのサービスの合計3つのインスタンスのうち2つのインスタンス)とジョブ(1つのインスタンス)を実行しています。
ノード1はサービスAの3番目のインスタンスを実行しており、このノードはサービスBのインスタンスも実行しています。
アプリケーションコードによっては、サービスインスタンスが複数のコンテナーで構成されることもあります。Snowflakeはサービスのインスタンスを複数のコンピューティングプールノードに分散することがありますが、1つのサービスインスタンス内のすべてのコンテナーは常に同じコンピューティングプールノードで実行されます。
サービスは任意でパブリックインターネットと通信することができます。
サービスは一時ストレージ(メモリやローカルディスクなど)や永続ボリューム(ブロックボリュームなど)を含むストレージを使用できます。
Snowflakeは、サービスからのログ、トレース、メトリックをSnowflakeアカウントのイベントテーブルに記録できます。
Snowflakeは、リポジトリ、コンピューティングプール、およびサービスを作成および管理するための APIs を提供します。このトピックでは、サービスの操作について説明します。サービス管理の APIs には以下のものが含まれます。
SQL コマンド:
サービスの作成。 CREATE SERVICE、 EXECUTE JOB SERVICE。
サービスの変更。 ALTER SERVICE、 DROP SERVICE。
サービスに関する情報の取得。 SHOW SERVICES、 DESCRIBE SERVICE、および その他のコマンド。
SQL 以外のインターフェイス: Snowflake Python APIs、 Snowflake REST APIs、および Snowflake CLI。
サービスの開始¶
アプリケーションコードをSnowflakeアカウントの リポジトリ にアップロードしたら、サービスを開始できます。サービスの開始に最低限必要な情報には以下が含まれます。
名前: サービス名。
サービス仕様: この 仕様 は、サービスの実行に必要な情報をSnowflakeに提供します。仕様は YAML ファイルです。
コンピューティングプール: Snowflakeは、指定された コンピューティングプール でサービスを実行します。
長時間実行サービスの作成¶
CREATE SERVICE を使用して長時間実行サービスを作成します。
ほとんどの場合、以下のようにインライン仕様を指定してサービスを作成します。
Snowflakeステージに格納されているサービス仕様を参照してサービスを作成します。実稼働環境にサービスをデプロイする場合、懸念事項の分離という設計原則を適用し、 CREATE SERVICE コマンドでステージ情報を提供して、以下に示すように、仕様をステージにアップロードすることができます。
ジョブサービスの実行¶
EXECUTE JOB SERVICE を使用してジョブサービスを作成します。デフォルトでは、このコマンドは同期的に実行され、ジョブサービスのすべてのコンテナーが終了した後に応答を返します。オプションで ASYNC パラメーターを指定すると、ジョブサービスを非同期に実行できます。
インライン仕様を使用してジョブサービスを実行します。コマンドは、ジョブの実行が完了するまで待機します。
オプションとして、
ASYNCプロパティを使用して、このジョブを非同期に実行することができます。非同期ジョブを実行する場合は、このヘルパー関数 <service_name>!SPCS_WAIT_FOR を使用してジョブが完了するまで待機します。
ステージ情報を使用してジョブサービスを実行します。
ジョブサービスの複数のレプリカの実行(バッチジョブ)¶
デフォルトでは、EXECUTE JOB SERVICE はジョブを実行するために、コンピューティングプール上で単一のジョブサービスインスタンスを実行します。ただし、コンピューティングプールノード間でワークロードを分散するために、複数のジョブサービスレプリカを実行することを選択することもできます。たとえば、10個のレプリカを使用して1,000万行のデータセットを処理すると、それぞれが100万行を処理することになります。
バッチジョブは、作業を独立したタスクに分割できるシナリオをサポートします。ジョブサービスインスタンス(レプリカとも呼ばれます)ごとに1つずつ、同時に実行できる可能性があります。インスタンスを同時に実行するSnowflakeの能力は、コンピューティングプールのサイズに依存します。
複数のインスタンスでバッチジョブを実行するには、次に示すように EXECUTE JOB SERVICE のオプションの REPLICAS パラメーターを使用します。次の例では、10個のインスタンスでジョブサービスを実行します。
REPLICAS パラメーターが EXECUTE JOB SERVICE で指定されている場合、Snowflakeはジョブコンテナで次の2つの環境変数を入力します。
SNOWFLAKE_JOBS_COUNT:EXECUTE JOB SERVICE で指定された REPLICAS プロパティの値。SNOWFLAKE_JOB_INDEX:0から始まる、そのジョブサービスインスタンスの ID。レプリカが3つある場合は、インスタンス IDs は0、1、2になります。
これらの環境変数が提供されることで、ジョブコンテナは入力を分割し、各インスタンスに処理するための特定のパーティションを割り当てることができます。たとえば、10個のジョブレプリカで1,000万行を処理する場合、ジョブインデックス0のインスタンスは1から100万の行を処理し、ジョブインデックス1のインスタンスは100万から200万の行を処理するという具合になります。
SHOW SERVICE INSTANCES IN SERVICE コマンドを使用して、各ジョブサービスインスタンスのステータスを検索します。
DESCRIBE SERVICE コマンドを使用して、ジョブサービスの全体的なステータスを取得します。Snowflakeはジョブサービスの全体なステータスを次のように計算します。
いずれかのインスタンスが失敗すると、ジョブのステータスは FAILED になります。
すべてのインスタンスが正常に完了すると、ジョブのステータスは DONE になります。
現在実行中のインスタンスがある場合、ジョブのステータスは RUNNING になります。
それ以外の場合、ジョブサービスのステータスは PENDING です。
仕様テンプレートの使用¶
同じ仕様で複数のサービスを作成したいが、構成が異なる場合があります。たとえば、サービス仕様で 環境変数 を定義し、同じ仕様で環境変数の値が異なる複数のサービスを作成したいとします。
仕様テンプレートのサポートにより、仕様内でフィールド値の変数を定義することができます。サービスを作成するときに、これらの変数に値を指定します。
仕様テンプレートでは、さまざまな仕様フィールドの値として変数を指定します。これらの変数を指定するには、 {{ variable_name }} 構文を使用します。次に、 CREATE SERVICE コマンドで、 USING パラメーターを指定して、これらの変数の値をセットします。
例えば、次の CREATE SERVICE コマンドのインライン仕様テンプレートでは、イメージタグ名に tag_name という変数を使っています。この変数を使って、サービスごとに異なるイメージタグを指定することができます。この例では、 USING パラメーターは、 tag_name 変数を値 latest にセットします。
仕様テンプレートをアカウント内のSnowflakeステージに保存することを選択した場合、 CREATE SERVICE コマンドでテンプレートの場所を指定できます。
仕様で変数を定義するためのガイドライン¶
仕様でフィールド値として変数を定義するには、
{{ variable_name }}構文を使用します。これらの変数はデフォルト値を持つことができます。デフォルト値を指定するには、変数宣言で
default関数を使用します。たとえば、以下の仕様では2つの変数(character_nameとendpoint_name)をデフォルト値で定義しています。default関数にオプションのブール値パラメーターを指定すると、変数に空白値が渡されたときにデフォルト値を使用するかどうかを指定できます。次の仕様を検討します。仕様で、
変数
character_nameの場合、ブール値パラメーターはfalseに設定されます。したがって、このパラメータに空の文字列値('')が設定されている場合、値は空白のままであり、デフォルト値("Bob")は使用されません。変数
echo_endpointの場合、ブール値パラメーターはtrueに設定されます。したがって、このパラメーターに空白値を渡すと、デフォルト値(「echo-endpoint」)が使用されます。
デフォルトでは、
default関数のブール値パラメーターはfalseです。
仕様変数に値を渡す際のガイドライン¶
CREATE SERVICE コマンドで USING パラメーターを指定して、変数の値を提供します。USING の一般的な構文は次のとおりです。
where
var_nameは大文字小文字を区別し、有効なSnowflake識別子でなければなりません(識別子の要件 を参照)。var_valueには英数字か有効な JSON 値を指定します。例:
CREATE SERVICE の USING パラメーターは、仕様変数(仕様がデフォルト値を提供する変数を除く)の値を提供しなければなりません。それ以外の場合、エラーが返されます。
例¶
次の例は、仕様テンプレートを使用してサービスを作成する方法を示しています。これらの例の CREATE SERVICE コマンドはインライン仕様を使っています。
例1: 単純な値を提供する¶
チュートリアル1 では、インライン仕様を提供してサービスを作成します。以下の例は同じものを修正したバージョンで、 image_url と SERVER_PORT の2つの変数を定義します。変数 SERVER_PORT が3箇所で繰り返されていることに注意してください。これは、同じ値を持つことが期待されるすべてのフィールドが同じ値を持つことを保証する変数を使用することの利点です。
この CREATE SERVICE コマンドでは、 USING パラメーターが2つの仕様変数の値を提供します。1つの image_url 値にはスラッシュとコロンが含まれます。英数字ではありません。そのため、この例では値を二重引用符で囲み、有効な JSON 文字列値にしています。テンプレート仕様は以下の仕様を拡張したものです。
例2: JSON 値を提供する¶
チュートリアル1では、以下のように2つの環境変数(SERVER_PORT と CHARACTER_NAME)を定義しています。
この指定をテンプレート化するには、 env フィールドに変数を使用します。これにより、環境変数の値を変えて複数のサービスを作ることができます。以下の CREATE SERVICE コマンドは、envフィールドに変数(env_values)を使用しています。
CREATE SERVICE の USING パラメーターは、 env_values 変数の値を提供します。値は JSON マップで、両方の環境変数の値を提供します。
例3: 変数値としてリストを提供する¶
チュートリアル2 では、仕様に2つの引数を含む args フィールドが含まれています。
仕様書のテンプレートバージョンでは、以下のように、これらの引数を JSON リストとして提供することができます:
サービスのスケーリング¶
デフォルトでは、Snowflakeは指定したコンピューティングプールでサービスのインスタンスを1つ実行します。重いワークロードを管理するには、 MIN_INSTANCES と MAX_INSTANCES プロパティを設定して、複数のサービスインスタンスを実行できます。このプロパティは、サービスの最小インスタンス数から開始し、必要に応じてSnowflakeがスケールできる最大インスタンス数を指定します。
例
複数のサービスインスタンスが実行されている場合、Snowflakeは自動的にロードバランサーを提供し、受信するリクエストを分散します。
Snowflakeは、少なくとも2つのインスタンスが利用可能になるまで、サービスを READY だと考えません。サービスが準備できていない間は、Snowflakeはそのサービスへのアクセスをブロックします。つまり、準備完了が確認されるまで、関連するサービス機能やイングレス・リクエストは拒否されます。
場合によっては、利用可能なインスタンスが指定した最小数に満たない場合でも、Snowflakeにサービスの準備ができたと判断させたい(受信リクエストを転送させたい)場合があります。これは、 MIN_READY_INSTANCES プロパティを設定することで実現できます。
このシナリオを考えてみましょう。メンテナンス中またはサービスのローリングアップグレード中に、Snowflakeは1つまたは複数のサービスインスタンスを終了する可能性があります。これにより、指定された MIN_INSTANCES よりも利用可能なインスタンスが少なくなる可能性があり、サービスが READY の状態になるのを防ぎます。このような場合、 MIN_READY_INSTANCES を MIN_INSTANCES より小さい値にセットすることで、サービスがリクエストの受け付けを継続できるようになります。
例
詳細については、 CREATE SERVICE をご参照ください。
オートスケールの有効化¶
実行中のサービスインスタンス数を自動スケールするようにSnowflakeを構成するには、 CREATE SERVICE コマンドの MIN_INSTANCES および MAX_INSTANCES パラメーターを設定します。また、 ALTER SERVICE を使用してこれらの値を変更することもできます。オートスケーリングは、指定された MAX_INSTANCES が MIN_INSTANCES より大きい場合に発生します。
Snowflakeは、指定されたコンピューティングプール上に最小数のサービスインスタンスを作成することから開始します。その後、Snowflakeは80% CPU のリソースリクエストに基づいて、サービスインスタンス数をスケールアップまたはスケールダウンします。Snowflakeは、現在実行中のすべてのサービスインスタンスの使用データを集約し、コンピュートプール内の CPU 使用率を継続的に監視します。
Snowflakeは、(すべてのサービスインスタンスを合計した) CPU の使用率が80%を超えると、コンピュートプール内に追加のサービスインスタンスをデプロイします。CPU の使用率が 80% を下回ると、Snowflake は実行中のサービスインスタンスを削除してスケールダウンします。Snowflakeは5分間の安定化ウィンドウを使用して、頻繁なスケーリングを防止します。target_instances サービスプロパティは、Snowflakeがスケールしているサービスインスタンスのターゲット数を報告します。
以下のスケーリング動作に注意してください。
サービスインスタンスのスケーリングは、サービス用に構成された MIN_INSTANCES と MAX_INSTANCES パラメーターによって制約されます。
スケールアップが必要で、コンピューティングプールノードが別のサービスインスタンスを起動するために必要なリソース容量が不足している場合は、コンピューティングプールの自動スケールをトリガーできます。詳細については、 コンピューティングプールノードの自動スケーリング をご参照ください。
サービスの作成時に MAX_INSTANCES と MIN_INSTANCES パラメーターを指定しても、サービス仕様ファイルでサービスインスタンスのメモリと CPU 要件を指定しない場合は、自動スケーリングは実行されません。Snowflakeは MIN_INSTANCES パラメーターで指定されたインスタンスの数で開始され、数は自動スケーリングされません。
サービスの中断¶
長時間稼働しているサービスは、コンピューティングプールのリソースを消費し、コストを発生させますが、意味のある作業を行っていない場合には、サービスを中断することができます。どのコンピューティングプールノードでもサービスやジョブがアクティブでない場合、Snowflakeのコンピューティングプール自動中断メカニズムがプールを中断し、コストを削減します。
サービスを中断するには、 ALTER SERVICE ... SUSPEND を明示的に呼び出してサービスを中断するか、 CREATE SERVICE または ALTER SERVICE を使用して AUTO_SUSPEND_SECS プロパティをセットし、Snowflakeが自動的にサービスを中断するまでのアイドル時間を定義します。
![]() プレビュー機能 --- オープン
プレビュー機能 --- オープン
AUTO_SUSPEND_SECS プロパティを使用したSnowpark Container Servicesサービスの自動一時停止の構成は、 プレビュー機能 です。
AUTO_SUSPEND_SECS プロパティがセットされている場合、Snowflakeはサービスがまだ中断されておらず、アイドル状態が AUTO_SUSPEND_SECS 秒以上続くと、自動的にサービスを中断します。以下の両方が当てはまる場合、サービスはアイドル状態になります。
現在、そのサービスへの サービス関数 呼び出しを含むクエリは実行されていません。
サービスステータスは RUNNING です。
注意
自動中断では、サービス関数の呼び出しによって開始されたデータ処理は追跡されません。サービス関数が返された後も処理は継続されます。現在の実装では、自動中断はイングレスとサービス間通信も追跡しません。そのため、このような機能を提供するサービスでは、自動中断を有効にすべきではありません。潜在的に進行中のプロセスを中断する可能性があるからです。
Snowflakeがサービスを中断すると、コンピューティングプール上のすべてのサービスインスタンスがシャットダウンされます。コンピューティングプール上で他のサービスが実行されておらず、コンピューティングプールに対して自動中断が構成されている場合、Snowflakeはコンピューティングプールノードも中断します。そのため、非アクティブなコンピューティングプールのために費用を支払う必要がなくなります。
また、次のことにも注意してください。
ジョブサービスの自動中断はサポートされていません。
Snowflakeは現在、サービスのアイドル状態を判断する際に、サービス関数のトラフィックのみを追跡し、イングレスのトラフィックは追跡しないため、パブリックエンドポイントを持つサービスでは自動中断はサポートされません。
サービスの変更とドロップ¶
サービスまたはジョブサービスを作成した後、以下のアクションを実行できます。
DROP SERVICE コマンドを使用してスキーマからサービスを削除します。Snowflakeはすべてのサービスコンテナを終了します。
<service_name>!SPCS_CANCEL_JOB 関数を呼び出してジョブサービスをキャンセルします。ジョブをキャンセルすると、Snowflakeはジョブの実行を停止し、ジョブの実行に割り当てられたリソースを削除します。
ALTER SERVICE コマンドを使用してサービスを変更します。たとえば、サービスを一時停止または再開し、実行中のインスタンス数を変更し、新しいサービス仕様を使用することでサービスを再展開するようにSnowflakeに指示します。
注釈
ジョブサービスを変更することはできません。
サービスの終了¶
サービスを一時停止 (ALTERSERVICE... SUSPEND) またはサービスを停止 (DROP SERVICE) すると、Snowflake はすべてのサービスインスタンスを終了します。同様に、サービスコードをアップグレードする場合(ALTER SERVICE...<fromSpecification> )、Snowflake は、一度に 1 つのサービスインスタンスを終了して再デプロイすることで、 ローリングアップグレード を適用します。
サービスインスタンスを終了する際、Snowflakeはまず各サービスコンテナに SIGTERM シグナルを送信します。コンテナーには、シグナルを処理し、30秒のウィンドウで優雅にシャットダウンするオプションがあります。そうでない場合は、猶予期間の後、Snowflake はコンテナー内のすべてのプロセスを終了します。
サービスコードの更新とサービスの更新¶
サービス作成後、 ALTER SERVICE...<fromSpecification> コマンドを使用してサービスコードを更新し、サービスを再デプロイします。
まず、変更したアプリケーションコードをイメージリポジトリにアップロードします。次に、 ALTER SERVICE コマンドを実行し、サービス仕様をインラインで提供するか、Snowflakeステージ内の仕様ファイルへのパスを指定します。例:
リクエストを受信すると、Snowflakeは新しいコードを使用してサービスを再展開します。
注釈
CREATE SERVICE ... <fromSpecification>コマンドを実行すると、Snowflakeは提供されたイメージの特定のバージョンを記録します。Snowflakeは、リポジトリ内のイメージが更新された場合でも、以下のシナリオで同じイメージバージョンをデプロイします。
中断されたサービスが再開された場合(ALTERSERVICE... RESUMEを使用)。
オートスケールがさらにサービス・インスタンスを追加する場合。
クラスタメンテナンス中にサービスインスタンスが再起動された場合。
しかし、 ALTER SERVICE ... <fromSpecification>を呼び出すと、Snowflakeはそのイメージのリポジトリの最新バージョンを使用します。
あなたがサービス・オーナーである場合、 DESCRIBE SERVICE コマンドの出力にはサービス仕様が含まれ、下図のようにイメージ・ダイジェスト(仕様の sha256 フィールドの値)が含まれます。
ALTER SERVICE は、サービスとの通信( サービスの使用 を参照)に影響を与える可能性があります。
ALTER SERVICE...<fromSpecification> でエンドポイントが削除されたり、エンドポイントを使用するために必要な関連するパーミッションが削除されたりした場合(仕様リファレンスの serviceRoles を参照)、サービスへのアクセスは失敗します。詳しくは、 Using Service をご参照ください。
アップグレード中は、新しい接続が新しいバージョンにルーティングされる可能性があります。新しいサービス・バージョンに後方互換性がない場合、有効なサービス利用は中断されます。例えば、サービス・ファンクションを使った継続的なクエリは失敗するかもしれません。
注釈
ネイティブアプリの一部であるサービスコードをコンテナで更新する場合、 SYSTEM$WAIT_FOR_SERVICES システム機能を使用してネイティブアプリのセットアップスクリプトを一時停止し、サービスを完全にアップグレードできるようにします。詳細については、 アプリ(レガシー)をアップグレードする をご参照ください。
ローリングアップデートの監視¶
複数のサービスインスタンスが実行されている場合、Snowflakeはサービスインスタンスの ID に基づいて降順にローリングアップデートを実行します。サービスのアップデートを監視するには、以下のコマンドを使用します。
DESCRIBE SERVICE および SHOW SERVICES:
サービスがアップグレードされている場合、出力の
is_upgrading列の表示は TRUE です。出力の
spec_digest列は、現在のサービス仕様の仕様ダイジェストを表します。このコマンドは定期的に実行することができます。;spec_digestの値が変化した場合は、サービスのアップグレードがトリガーされたことを示しています。spec_digestが使用されるのは、is_upgradingが FALSE になってからです。それ以外の場合、サービスのアップグレードはまだ進行中です。SHOW SERVICE INSTANCES IN SERVICE コマンドを使用して、以下の説明に従って、すべてのインスタンスが最新バージョンにアップデートされているかどうかを確認します。
SHOW SERVICE INSTANCES IN SERVICE:
出力の
status列は、ローリングアップグレードの進行中に、個々のサービスインスタンスのステータスを提供します。アップグレード中、 TERMINATING から PENDING 、 PENDING から READY のように、各サービス・インスタンスの移行ステータスが表示されます。サービスのアップグレード中、このコマンドの出力の
spec_digest列は、常に最新のスペックダイジェストを返す SHOW SERVICES とは異なる値を示すかもしれません。 この違いは、単にサービスのアップグレードが進行中であり、サービスインスタンスがまだ古いバージョンのサービスを実行していることを示しています。
サービスについての情報の取得¶
これらのコマンドを使うことができます。
サービスのプロパティとステータスを取得するには、 DESCRIBE SERVICE コマンドを使用します。出力はすべてのサービスプロパティを返します。
SHOW SERVICES コマンドを使用して、あなたが権限を持っている現在のサービス(ジョブサービスを含む)をリストアップします。出力は、これらのサービスのプロパティとステータスの一部を提供します。
デフォルトでは、現在のデータベースとスキーマのサービスが出力されます。また、以下のスコープを指定することもできます。例:
特定のデータベース、または特定のスキーマでアカウントのサービスをリストする: 例えば、 IN ACCOUNT フィルタを使用して、サービスがどのデータベースまたはスキーマに属しているかに関係なく、Snowflake アカウントのサービスを一覧表示します。これは、アカウント内の複数のデータベースとスキーマにSnowflakeサービスが作成されている場合に便利です。他のコマンドと同様に、 SHOW SERVICES IN ACCOUNTS は権限によって制限され、使用しているロールが表示権限を持っているサービスのみを返します。
IN DATABASE または IN SCHEMA を指定して、現在の(または指定した)データベースまたはスキーマのサービスを一覧表示することもできます。
コンピューティングプールで実行されているサービスをリストする: 例えば、 IN COMPUTE POOL フィルターを使用して、コンピューティングプールで実行されているサービスをリストします。
プレフィックスで始まる、またはパターンに一致するサービスをリストする: LIKE と STARTS WITH フィルタを適用して、名前でサービスをフィルタリングすることができます。
ジョブ・サービスのみをリストアップする、またはジョブ・サービスをリストから除外する: SHOW JOB SERVICES または SHOW SERVICES EXCLUDE JOBS を使用します。
これらのオプションを組み合わせて、 SHOW SERVICES 出力をカスタマイズすることもできます。
サービス・インスタンスのプロパティを取得するには、 SHOW SERVICE INSTANCES IN SERVICE コマンドを使用します。
サービスインスタンスのプロパティとステータスを取得するには、 SHOW SERVICE CONTAINERS IN SERVICE コマンドを使用します。
GET_JOB_HISTORY 関数を呼び出して、特定の時間範囲内に実行されていたジョブのジョブ履歴を取得します。
<service_name>!SPCS_WAIT_FOR 関数を呼び出して、待機して特定の時間後にジョブサービスの状態を含むサービスのステータスを取得します。
サービスのモニタリング¶
Snowpark Container Servicesは、アカウント内のコンピューティングプールとその上で実行されているサービスを監視するためのツールを提供します。詳細については、 Snowpark Container Services:Monitoring Services をご参照ください。
サービスの使用¶
サービスを作成すると、同じアカウント(サービスを作成したアカウント)のユーザーはそのサービスを利用することができます。サービスを利用するには、図のように3つの方法があります。ユーザーは必要な権限を持つロールにアクセスする必要があります。
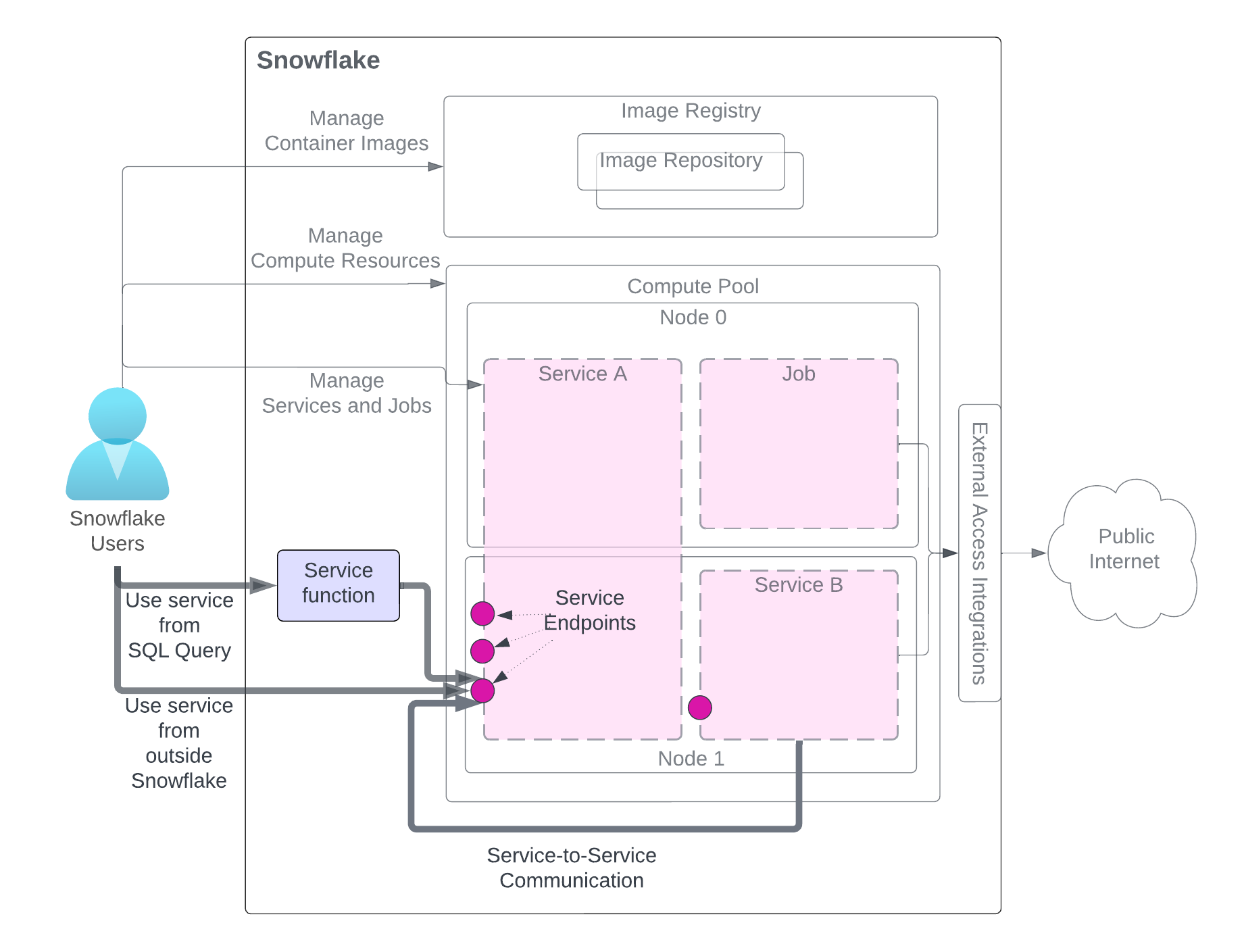
この図では、サービスを使用するためのメソッドが強調表示され、その他のサービス関連コンポーネントはわかりやすくするために灰色で表示されています。サービスコンポーネントの詳細な説明については、このページ冒頭の図を参照してください。
SQL クエリからサービスを使用する (サービス関数): サービスに関連付けられたユーザー定義関数(UDF)であるサービス関数を作成し、それを SQL クエリで使用して、サービスが提供するカスタムデータ処理を活用します。例については、 チュートリアル1 をご参照ください。
Snowflakeの外部からサービスを使用する (Ingress):1つまたは複数のサービスエンドポイントをパブリックとして宣言し、サービスへのネットワークイングレスアクセスを許可することができます。これを使用して、Snowflakeデータ上にWebアプリや公開 APIs を構築できます。例については、 チュートリアル1 をご参照ください。
**別のサービスからのサービスを使用する**( サービス間通信 ): サービス間通信のためにSnowflakeが割り当てたサービス DNS 名を使用して、サービス間で通信することができます。例については、 チュートリアル4 を参照してください。
図が示すように、これらのメソッドを使用してサービスと通信する場合、サービスが公開するエンドポイントにリクエストを送信し、結果を取得します。
注釈
サービス関数は、ジョブサービスとの通信には使用できません。
以下のセクションで詳細を説明します。
サービス関数: SQL クエリからのサービスの使用¶
サービス関数とは、 CREATE FUNCTION (Snowpark Container Services) を使用して作成するユーザー定義関数(UDF)のことです。しかし、 UDF のコードを直接記述する代わりに、 UDF をサービスエンドポイントに関連付けます。サービス関数は、 HTTP プロトコルをサポートするサービスエンドポイントにのみ関連付けることができることに注意してください(spec.endpoints フィールド(オプション) を参照してください)。
たとえば、 チュートリアル1 では、サービス仕様で定義された1つのエンドポイント(echoendoint)を公開する echo_service という名前のサービスを作成します。
echoendpoint は、対応するポート(8080)を表す分かりやすいエンドポイント名です。このサービスエンドポイントと通信するには、次に示すように SERVICE と ENDPOINT パラメーターを指定してサービス関数を作成します。
AS パラメーターは、サービスコードへの HTTP パスを提供します。このパス値はサービスコードから取得します(例: チュートリアル 1 のservice.pyを参照)。例えば、以下のコード行は チュートリアル 1 の service.py にあります。
次のような SELECT ステートメントでサービス関数を呼び出します。
Snowflakeはリクエストを関連するサービスエンドポイントとパスに誘導します。
注釈
サービス関数は、ジョブとではなく、サービスと通信するために使用されます。つまり、サービスのみ(ジョブではなく)をサービス関数に関連付けることができます。
データ交換形式¶
サービス関数とコンテナー間のデータ交換では、Snowflakeは外部関数が使用するのと同じ形式に従います( データ形式 を参照)。たとえば、テーブル(input_table)にデータ行が格納されているとします。
このデータをサービスに送信するには、これらの行をパラメーターとして渡してサービス関数を呼び出します。
Snowflakeは、一連のリクエストをリクエスト本文のデータ行のバッチと合わせて次の形式でコンテナーに送信します。
そして、コンテナーは次の形式で出力を返します。
上記の出力例では、行(「a」、「b」)を持つ1列のテーブルを想定しています。
バッチ処理の構成¶
CREATE FUNCTION と ALTER FUNCTION コマンドは、Snowflakeがサービスによって処理されるデータのバッチをどのように処理するかを構成するパラメーターをサポートします。
バッチサイズの構成
MAX_BATCH_ROWS パラメーターを使用して、バッチサイズ、つまりSnowflakeが1回のリクエストでサービスに送信する行の最大数を制限することができます。これにより、データ転送量をコントロールすることができます。また、サービスが複数のインスタンスや同時リクエストをサポートしている場合は、より小さなバッチを並行して処理することになります。
エラーの処理
これらのパラメーターはバッチエラー処理に使用できます:
ON_BATCH_FAILURE、MAX_BATCH_RETRIES、およびBATCH_TIMEOUT_SECS。
例えば、次の ALTER FUNCTION コマンドは、 my_echo_udf サービス関数の MAX_BATCH_ROWS と MAX_BATCH_RETRIES パラメーターを構成します。
サービス関数の作成および管理に必要な権限¶
サービス関数を作成して管理するには、ロールに以下の権限が必要です。
現在のロールは、 CREATE FUNCTION または ALTER FUNCTION コマンドで参照されるエンドポイントに対して付与されたサービスロールを持っている必要があります。
SQL クエリでサービス関数を使用するには、現在のセッションがサービス関数の使用権限を持つロールを持ち、サービス関数の所有者ロールが関連するサービスエンドポイントのサービスロールを付与されている必要があります。
次のスクリプト例では、サービス関数の作成と使用に対する権限の付与方法を示します。
イングレス:Snowflake外部からのサービスの使用¶
サービス仕様の中で1つ以上のエンドポイントをパブリックとして宣言することで、ユーザーがパブリックからサービスを利用できるようになります。ユーザーは、サービスを作成したのと同じSnowflakeアカウントのSnowflakeユーザーでなければならないことに注意してください。
イングレスは HTTP エンドポイントでのみ許可されていることに注意してください(spec.endpoints フィールド(オプション) を参照してください)。
イングレス認証¶
ユーザーがパブリックエンドポイントにアクセスできるのは、そのエンドポイントへのアクセスを許可するサービスロールが付与されている場合です。(サービスエンドポイントへのアクセスに必要な権限(サービスロール) を参照してください)。
その後、ユーザーはブラウザーやプログラムを使ってパブリックエンドポイントにアクセスできます。
ブラウザーの使用によるパブリックエンドポイントへのアクセス: ブラウザーを使用してパブリックエンドポイントにアクセスすると、Snowflakeは自動的にサインインページにリダイレクトします。ユーザーは、サインインするためにSnowflakeの認証情報を提供する必要があります。サインインに成功すると、ユーザーはエンドポイントにアクセスできます。裏側では、ユーザーがサインインするとSnowflakeから OAuth トークンが生成されます。そして、 OAuth トークンを使用してサービスエンドポイントにリクエストが送信されます。
例については、 チュートリアル1 をご参照ください。
プログラムによるパブリックエンドポイントへのアクセス: プログラムクライアントがエンドポイントにアクセスする方法は3つあります。
プログラムによるアクセストークン( PAT ) の使用:アプリケーションは、そのIDを表すため、リクエストの
Authorizationヘッダー内のトークンをエンドポイントに渡します。キーペア認証 の使用: アプリケーションはキーペアを使用して JWT を生成し、 JWT をSnowflakeと交換して OAuth トークンを取得し、次にリクエストの
Authorizationヘッダー内の OAuth トークンをエンドポイントに渡してそのIDを表します。Pythonコネクタ の使用:アプリケーションはPythonコネクタを使用してセッショントークンを生成し、次にリクエストの
Authorizationヘッダー内のセッショントークンをエンドポイントに渡してそのIDを表します。
関連する例については、 チュートリアル8 をご参照ください。
イングレスリクエストのユーザー固有ヘッダー¶
Snowflakeは、パブリックエンドポイントのリクエストを受信すると、自動的に HTTP リクエストとともに以下のヘッダーをコンテナーに渡します。
コンテナコードにより、オプションでこれらのヘッダーを読み取り、呼び出し元が誰であるかを把握し、異なるユーザーに対してコンテキスト固有のカスタマイズを適用することができます。さらに、Snowflakeではオプションで Sf-Context-Current-User-Email ヘッダーを含めることができます。このヘッダーを含めるには、 Snowflakeサポート までご連絡ください。
サービス間通信¶
サービスインスタンスは、 TCP (HTTP を含む)を介して相互に直接通信することができます。これは、同じサービスに属するインスタンスにも、異なるサービスに属するインスタンスにも当てはまります。
インスタンスは、サービス仕様で宣言された エンドポイント でのみ通信(リクエスト)を受信できます。クライアント(リクエストを送信するサービス)は、そのエンドポイントに接続するために必要なロールと付与を持っていなければなりません(サービスエンドポイントへのアクセスに必要な権限(サービスロール) を参照してください)。
デフォルトでは、サービスインスタンスは宣言されたエンドポイントで同じサービスの他のインスタンスに接続できます。広い意味では、サービスの 所有者ロール は、同じオーナーロールを持つサービスのエンドポイントに接続する権限を持っています。
クライアントサービスが異なる所有者ロールを持つサービスのエンドポイントに接続するには、クライアントサービスの所有者ロールが、そのエンドポイントを呼び出すために、別のサービスのエンドポイントへのアクセスを付与する サービスロール が必要です。詳細については、 サービスエンドポイントへのアクセスに必要な権限(サービスロール) をご参照ください。
サービス同士が通信できないようにする場合(セキュリティなどの理由により)は、異なるSnowflakeロールを使用してこれらのサービスを作成します。
サービス・インスタンスには、サービス・アドレス(IP)またはサービス・インスタンス・アドレス(IP)のいずれかを使用してアクセスできます。
サービス IP アドレスを使ったリクエストはロードバランサーにルーティングされ、ロードバランサーはランダムに選ばれたサービスインスタンスにリクエストをルーティングします。
サービスインスタンス IP アドレスを使用したリクエストは、特定のサービスインスタンスに直接ルーティングされます。
portRangeフィールドを使用して定義されたエンドポイントに接続する場合は、サービスインスタンス IP を使用する必要があります( spec.endpoints フィールド(オプション) を参照)。
どちらの IP アドレスも、Snowflake が各サービスに自動的に割り当てる DNS 名を使用して検出可能です。なお、 DNS を使って特定のインスタンスに接続することはできません。例えば、サービスインスタンス DNS 名を使用して URL を構築することは意味がありません。なぜなら、サービスインスタンス DNS 名を使用して特定のサービスインスタンスをリファレンスする方法がないからです。
2025_01 動作変更バンドル が有効な場合、 SHOW SERVICE INSTANCES IN SERVICE コマンドの出力にサービスインスタンス IP アドレスが表示されます。
サービス間通信の例については、 チュートリアル4 をご参照ください。
サービス間の通信を可能にするためだけにサービスエンドポイントを作成する場合は、 TCP プロトコルを使用する必要があることに注意してください(spec.endpoints フィールド(オプション) を参照)。
サービス DNS 名¶
DNS 名形式は以下のとおりです。
サービスの DNS 名を取得するには、 SHOW SERVICES (または DESCRIBE SERVICE )を使用します。直前の DNS 名は完全修飾名です。同じスキーマで作成されたサービスでは、 <サービス名> を使用するだけで通信できます。異なるスキーマまたはデータベースにあるサービスは、 <service-name>.<hash> のようにハッシュを提供するか、完全修飾名 (<service-name>.<hash>.svc.spcs.internal) を提供する必要があります。
SYSTEM$GET_SERVICE_DNS_DOMAIN 関数を使用して、指定されたスキーマの DNS ドメインを検索します。DNS ハッシュ・ドメインは、スキーマの現在のバージョンに固有のものです。次の点に注意してください。
スキーマやそのデータベースの名前が変わっても、ハッシュは変わりません。
スキーマが削除され、(例えば CREATE OR REPLACE SCHEMA を使って)再作成された場合、新しいスキーマは新しいハッシュを持つことになります。 スキーマを UNDROP しても、ハッシュは変わりません。
DNS 名には以下の制限があります。
サービス名は有効な DNS ラベルでなければなりません。(https://www.ietf.org/rfc/rfc1035.html#section-2.3.1 もご参照ください)。それ以外の場合は、サービスの作成に失敗します。
Snowflakeは、サービス名のアンダースコア(_)を DNS のダッシュ(-)に置き換えます。
DNS 名は、同じアカウントで実行されているサービス間のSnowflake内部での通信にのみ使用されます。インターネットからはアクセスできません。
サービスインスタンス DNS 名¶
サービスインスタンス DNS 名の形式は以下の通りです。
これは、サービスのインスタンスごとに1つずつ、サービスインスタンス IP アドレスのリストに解決されます。DNS が返す IP アドレスのリストには順番が保証されていないことに注意してください。この DNS 名は DNS APIs でのみ使用し、 URL のホスト名としては使用しないでください。アプリケーションはこのホスト名を DNS APIs によって、サービスインスタンス IPs のセットを収集し、それらのインスタンス IPs にプログラムで直接接続することを想定しています。
この IP アドレスのリストは、特定のサービスインスタンス間で直接通信するためのメッシュネットワークの作成を可能にします。
どの DNS 名を選ぶべきか¶
サービス間通信でサービスに接続する際に、どの DNS 名を使用するかを選択する際には、以下の点を考慮する必要があります。
以下のいずれかに該当する場合は、サービス名(DNS)を使用してください。
特定の宛先ポートにできるだけ簡単な方法でアクセスする必要があります。
各リクエストがランダムに選択されたサービスインスタンスに送られるようにします。
アプリケーションフレームワークがどのようにパフォーマンスし、 DNS レスポンスをキャッシュしているかはわかりません。
以下のいずれかに該当する場合は、サービスインスタンス DNS 名またはサービスインスタンス IP を使用します。
すべてのサービス・インスタンスの IP アドレスを発見したいとします。
中間のロードバランサーをスキップしたい場合。
RayやCassandraなど、IDとしてサービスインスタンス IP アドレスを使用する分散フレームワークやデータベースを使用しています。
アカウントで許可されているサービスの種類を管理¶
Snowflakeは、アカウントで作成できるさまざまなタイプのサービス(ワークロードタイプ)をサポートしています。これには、サービスやジョブなどのユーザーが展開するワークロードだけでなく、ノートブック、使用中のモデル、 ML ジョブなど、Snowflakeによって管理されるファーストパーティのワークロードも含まれます。ワークロードの種類のリストについては、 ALLOWED_SPCS_WORKLOAD_TYPES をご参照ください。
SHOW SERVICES を使用してアカウントのサービスを一覧表示する場合、特定のワークロードタイプのみをリストするフィルターを含めることができます。例えば、ユーザーがデプロイしたサービスのみを表示します。
アカウントレベルのパラメーター ALLOWED_SPCS_WORKLOAD_TYPES および DISALLOWED_SPCS_WORKLOAD_TYPES を使用して、Snowflakeアカウントで許可されるワークロードの型を制限できます。たとえば、 NOTEBOOK ワークロードのみを許可するには、次のステートメントを実行します。
注釈
DISALLOWED_SPCS_WORKLOAD_TYPES で指定されているワークロードタイプはデプロイできません。ALLOWED_SPCS_WORKLOAD_TYPES および DISALLOWED_SPCS_WORKLOAD_TYPES の両方を構成する場合、許可されていないリストが優先されます。たとえば、両方のパラメーターが NOTEBOOK ワークロードタイプを指定する場合、 NOTEBOOK ワークロードはSnowpark Container Services上で実行できません。
これらのアカウントレベルのパラメーターを構成する前に作成されたサービスは引き続き実行されます。ただし、ワークロードタイプが許可されていないサービスを一時停止すると、再起動できません。
許可されていないタイプの以前に作成したサービスをすべて削除するには、 ALTER COMPUTE POOL ... STOP ALL OF TYPE コマンドを実行します。
Snowflakeシークレットを使用してコンテナーに認証情報を引き渡す¶
Snowflake が管理する認証情報をコンテナーに渡したい理由は多数あります。サービスが外部エンドポイント(Snowflakeの外部)と通信する場合は、アプリケーションコードが使用できるように、コンテナー内に認証情報を提供する必要があります。
認証情報を提供するには、まず認証情報を Snowflake secret オブジェクトに格納します。次に、サービス仕様の中で、 containers.secrets 、どのシークレットオブジェクトを使用し、コンテナー内のどこに配置するかを指定します。これらの認証情報をコンテナー内の環境変数に渡すか、コンテナー内のローカルファイルで利用できるようにします。
Snowflakeのシークレットを指定する¶
Snowflakeのシークレットを名前または参照で指定します(参照はNative Applicationシナリオでのみ適用可能です)。
Snowflake のシークレットを名前で渡す:
snowflakeSecretフィールドの値としてシークレット名を渡すことができます。なお、
snowflakeSecretの値として、<secret-name>を直接指定することもできます。Snowflakeシークレットをリファレンスで渡す: Snowpark Container Services を使用してNative App(コンテナー付きアプリ)を作成する場合、アプリのプロデューサーとコンシューマーは異なる Snowflake アカウントを使用します。場合によっては、インストールされた Snowflake Native Appは、 APPLICATION オブジェクトの外部に存在するコンシューマーカウントの既存のオブジェクトにアクセスする必要があります。この場合、開発者は「secrets by reference(参照によるシークレット)」指定構文を使用して、図のように認証情報を扱うことができます。
この仕様では、シークレットの参照名を提供するために、
objectNameの代わりにobjectReferenceを使用していることに注意してください。
コンテナー内のシークレットの配置を指定する¶
Snowflakeには、シークレットを環境変数としてコンテナーに配置するか、ローカルコンテナーファイルに書き込むように指示することができます。
シークレットを環境変数として引き渡し¶
Snowflakeのシークレットを環境変数としてコンテナーに渡すには、 containers.secrets フィールドに envVarName を含めます。
secretKeyRef: この値はSnowflakeシークレットの型によって異なります。設定可能な値は以下の通りです。
username、またはSnowflakeシークレットがpassword型の場合はpassword。Snowflakeシークレットが
generic_string型の場合はsecret_string。
サービスが作成された後、Snowflakeは環境変数として渡されたシークレットを更新しないことに注意してください。
例1: パスワード 型のシークレットを環境変数として引き渡し¶
この例では、 password 型の以下のSnowflakeシークレットオブジェクトを作成します。
このSnowflakeシークレットオブジェクトをコンテナー内の環境変数(例: LOGIN_USER や LOGIN_PASSWORD)に提供するには、仕様ファイルに以下の containers.secrets フィールドを追加します。
この例では、 snowflakeSecret の値は完全修飾オブジェクト名です。これは、シークレットは作成されるサービスとは異なるスキーマに格納できるためです。
この例の containers.secrets フィールドは、2つの snowflakeSecret オブジェクトのリストです。
最初のオブジェクトは、Snowflakeシークレットオブジェクトの
usernameをコンテナーの環境変数LOGIN_USERにマップします。2番目のオブジェクトは、Snowflakeシークレットオブジェクトの
passwordをコンテナーの環境変数LOGIN_PASSWORDにマップします。
例¶
この例では、 generic_string 型の以下のSnowflakeシークレットオブジェクトを作成します。
このSnowflakeシークレットオブジェクトをコンテナー内の環境変数(例: GENERIC_SECRET)に提供するには、仕様ファイルに以下の containers.secrets フィールドを追加します。
ローカルコンテナーファイルでのシークレットを記述する¶
ローカルコンテナーファイル内のアプリケーションコンテナーで Snowflake シークレットを利用できるようにするには、 containers.secrets フィールドを含めます。ローカルコンテナーファイル内のアプリケーションコンテナーでSnowflake のシークレットを利用できるようにするには、 containers.secrets に directoryPath を含めます。
Snowflakeは、この指定された directoryPath; secretKeyRef を指定する必要はありません。シークレットタイプに応じて、Snowflakeは指定したディレクトリパスの下のコンテナー内に以下のファイルを作成します。
Snowflakeシークレットが
password型の場合、usernameとpasswordです。Snowflakeシークレットが
generic_string型の場合はsecret_string。Snowflakeシークレットが
oauth2型の場合はaccess_token。
注釈
サービスが作成された後、Snowflakeのシークレットオブジェクトが更新されると、Snowflakeは実行中のコンテナ内の対応するシークレットファイルを更新します。
例1: ローカルコンテナーファイルにおける password 型のシークレットの引き渡し¶
この例では、 password 型の以下のSnowflakeシークレットオブジェクトを作成します。
これらの認証情報をローカルコンテナーファイルで利用できるようにするには、仕様ファイルに以下の containers.secrets フィールドを追加します。
サービスを開始すると、Snowflakeはコンテナー内に /usr/local/creds/username と /usr/local/creds/password の2つのファイルを作成します。そうすると、アプリケーションコードはこれらのファイルを読み取ることができます。
例2: ローカルコンテナーファイルにおける oauth2 型のシークレットを引き渡す¶
この例では、 generic_string 型の以下のSnowflakeシークレットオブジェクトを作成します。
このSnowflakeシークレットオブジェクトをローカルコンテナーファイルで提供するには、仕様ファイルに以下の containers.secrets フィールドを追加します。
サービスを開始すると、Snowflakeはコンテナー内に /usr/local/creds/secret_string のファイルを作成します。
例3: ローカルコンテナーファイルにおける oauth2 型のシークレットを引き渡す¶
この例では、 oauth2 型の以下のSnowflakeシークレットオブジェクトを作成します。
これらの認証情報をローカルコンテナーファイルで利用できるようにするには、仕様ファイルに以下の containers.secrets フィールドを追加します。
Snowflakeは OAuth シークレットオブジェクトからアクセストークンをフェッチし、コンテナーに /usr/local/creds/access_token を作成します。
サービスがoauth2型のシークレットを使用する場合、サービスはインターネット宛先にアクセスするためにそのシークレットを使用することが求められます。oauthシークレットは 外部アクセス統合(EAI) によって許可される必要があります。それ以外の場合、 CREATE SERVICE または EXECUTE JOB SERVICE は失敗します。この追加の EAI 要件は、oauth2型のシークレットにのみ適用され、他の型のシークレットには適用されません。
要約すると、このようなサービスを作る際の典型的なステップは以下のとおりです。
oauth2型のシークレットを作成します(前述のとおり)。
サービスによるシークレットの使用を許可する EAI を作成します。例:
仕様に
containers.secretsフィールドを含むサービスを作成します。また、oauth2シークレットの使用を許可するために、 EXTERNAL_ACCESS_INTEGRATIONS プロパティに EAI を含めるようにオプションで指定します。CREATE SERVICE (インライン仕様を使用)コマンドの例:
エグレスの詳細については、 サービスエグレスの構成 をご参照ください。
ガイドラインと制約¶
詳細については、 SSnowpark Container Services:ガイドラインと制約 をご参照ください。