- カテゴリ:
MATCH_RECOGNIZE¶
行のセット内にあるパターンの一致を認識します。 MATCH_RECOGNIZE は、(テーブル、ビュー、サブクエリ、またはその他のソースからの)行のセットを入力として受け入れ、このセット内にある該当する行パターンのすべての一致を返します。パターンは正規表現と同様に定義されます。
句は次のいずれかを返すことができます。
各一致に属するすべての行。
一致ごとに1つの要約行。
MATCH_RECOGNIZE 通常、時系列のイベントを検出するために使用されます。たとえば、 MATCH_RECOGNIZE は、株価履歴テーブルで V (下に続いて上)や W (下、上、下、上)などの形状を検索できます。
MATCH_RECOGNIZE は、 FROM 句のオプションのサブ句です。
注釈
再帰的 共通テーブル式(CTE) でMATCH_RECOGNIZE 句を使用することはできません。
- こちらもご参照ください。
構文¶
必要なサブ句¶
DEFINE: 記号を定義¶
記号(別称「パターン変数」)は、パターンの構成要素です。
記号は式によって定義されます。式が行に対してtrueと評価された場合、記号はその行に割り当てられます。行には複数の記号を割り当てることができます。
DEFINE 句で定義されていないが、パターンで使用されている記号は、常にすべての行に割り当てられます。暗黙的に、これらは次の例と同等です。
パターンは、記号と 演算子 に基づいて定義されます。
PATTERN: 一致するパターンを指定¶
パターンは、一致を表す有効な行のシーケンスを定義します。パターンは正規表現(regex)のように定義され、記号、演算子、および量指定子から構築されます。
たとえば、記号 S1 が stock_price < 55 として定義され、記号 S2 が stock price > 55 として定義されているとします。次のパターンは、株価が55未満から55を超えて上昇した一連の行を指定します。
以下は、パターン定義のより複雑な例です。
次のセクションでは、このパターンの個々のコンポーネントについて詳しく説明します。
注釈
MATCH_RECOGNIZE は、 バックトラッキング を使用してパターンを照合します。他の バックトラッキングを使用する正規表現エンジン の場合と同様に、一致するパターンとデータの組み合わせによっては実行に時間がかかる場合があり、その結果、計算コストが高くなる可能性があります。
パフォーマンスを向上させるには、できるだけ具体的なパターンを定義します。
各行が1つの記号または少数の記号にのみ一致することを確認します。
すべての行に一致する記号の使用は避けてください(例:
DEFINE句にない記号またはtrueとして定義されている記号)量指定子の上限を定義します(例:
*ではなく{,10})。
たとえば、次のパターンでは、一致する行がない場合にコストが増加する可能性があります。
一致させる行数に上限がある場合は、その制限を量指定子で指定してパフォーマンスを向上させることができます。さらに、 symbol1 に続く any_symbol を検索するように指定する代わりに、 symbol1 (この例では not_symbol1)ではない行を検索できます。
通常は、クエリの実行時間をモニターして、クエリに予想よりも時間がかかっていないことを確認する必要があります。
- 記号:
記号は、その記号が割り当てられた行と一致します。次の記号を使用できます。
symbol。たとえば、S1、...、S4これらは、DEFINEサブ句で定義され、行ごとに評価される記号です。(これらには、定義されておらず、すべての行に自動的に割り当てられる記号を含めることも可能。)^(パーティションの開始。)これは、パーティションの開始を示す仮想記号であり、それに関連付けられた行はありません。これを使用して、パーティションの先頭のみで一致を開始するようにリクエストできます。例については、 パーティションの開始または終了に関連する照合パターン をご参照ください。
$(パーティションの終了。)これは、パーティションの終了を示す仮想記号であり、それに関連付けられた行はありません。これを使用して、パーティションの最後のみで一致を終了するようにリクエストできます。例については、 パーティションの開始または終了に関連する照合パターン をご参照ください。
- 量指定子:
量指定子は、記号または演算の後に配置できます。量指定子は、関連する記号または演算の最小および最大発生数を示します。次の量指定子を使用できます。
量指定子
意味
+1以上。例:
( {- S3 -} S4 )+。
*0以上。例:
S2*?。
?0または1。
{n}正確にn。
{n,}n以上。
{,m}0からm。
{n, m}nからm。例:
PERMUTE(S1, S2){1,2}。
デフォルトでは、量指定子は「グリーディモード」になっています。つまり、可能な場合は最大数量に一致させようとします。量指定子を可能な場合に最小数量と一致させようとする、「リラクタントモード」に設定するには、量指定子の後に ? を配置します(例: S2*?)。
- 演算子:
演算子は、有効な一致を形成するために、行のシーケンスで記号またはその他の操作を実行する順序を指定します。次の演算子を使用できます。
演算子
意味
... ...(スペース)連結。記号または操作が別のものに続く必要があることを指定します。たとえば、
S1 S2は、S2に定義された条件がS1に定義された条件の後に発生する必要があることを意味します。
{- ... -}除外。含まれている記号または操作を出力から除外します。たとえば、
{- S3 -}は演算子S3を出力から除外します。除外された行は出力に表示されませんが、MEASURES式の評価には含まれます。
( ... )グループ化。演算子の優先順位を上書きするため、またはグループ内の記号または操作に同じ量指定子を適用するために使用されます。この例では、量指定子
+は、S4だけでなく、シーケンス{- S3 -} S4にも適用されます。
PERMUTE(..., ...)順列。指定されたパターンの任意の順列に一致させます。たとえば、
PERMUTE(S1, S2)はS1 S2またはS2 S1のいずれかに一致させます。PERMUTE()は無制限の数の引数を取ります。
... | ...代替候補。最初の記号または操作、あるいはその他のいずれかが発生することを指定します。例:
( S3 S4 ) | PERMUTE(S1, S2)。代替演算子は、連結演算子よりも優先されます。
オプションのサブ句¶
ORDER BY: 照合する前に行を並べ替え¶
{}条件:
ウィンドウ関数 の場合と同じように、行の順序を定義します。これは、各パーティションの個々の行が
MATCH_RECOGNIZE演算子に渡される順序です。詳細については、 行のパーティション分割と並べ替え をご参照ください。
PARTITION BY: 行をウィンドウにパーティション分割¶
{}ウィンドウ関数 の場合と同じように、行の入力セットを分割します。
MATCH_RECOGNIZEは、結果のパーティションごとに照合を個別に実行します。パーティション分割は、相互に関連する行をグループ化するだけでなく、個別のパーティションを並行して処理できるため、Snowflakeの分散データ処理機能を活用します。
パーティション分割の詳細については、 行のパーティション分割と並べ替え をご参照ください。
MEASURES: 追加の出力列を指定¶
「メジャー」は、 MATCH_RECOGNIZE 演算子の出力に追加されるオプションの追加列です。 MEASURES サブ句の式には、 DEFINE サブ句の式と同じ機能があります。詳細については、 記号 をご参照ください。
MEASURES サブ句内では、 MATCH_RECOGNIZE に固有の次の関数を使用できます。
MATCH_NUMBER()は、一致する連番を返します。MATCH_NUMBER は1から始まり、一致するたびに増加されます。MATCH_SEQUENCE_NUMBER()は、一致内の行番号を返します。MATCH_SEQUENCE_NUMBER は連続しており、1から始まります。CLASSIFIER()は、それぞれの行が一致した記号を含む TEXT 値を返します。たとえば、行が記号GT75と一致した場合、CLASSIFIER関数は文字列「GT75」を返します。
注釈
メジャーを指定するときは、 DEFINE および MEASURES で使用されるウィンドウ関数の制限 セクションに記載されている制限に注意してください。
ROW(S) PER MATCH: 返す行を指定¶
一致が成功した場合に返される行を指定します。サブ句はオプションです。
ALL ROWS PER MATCH: 一致するすべての行を返します。ONE ROW PER MATCH: 一致する行数に関係なく、一致ごとに1つの要約行を返します。これがデフォルトです。
次の特殊なケースに注意してください。
空の一致: パターンがゼロ行と一致できる場合、空の一致が発生します。たとえば、パターンが
A*として定義され、照合試行の開始時における最初の行が記号Bに割り当てられている場合、その行のみを含む空の一致が生成されます。これは、A*パターンにある*量指定子が、Aの0発生を一致として扱うことができるからです。MEASURES式は、この行に対して異なる方法で評価されます。CLASSIFIER 関数は NULL を返します。
ウィンドウ関数は NULL を返します。
COUNT 関数は0を返します。
一致しない行: 行がパターンと一致しなかった場合、それは不一致行と呼ばれます。
MATCH_RECOGNIZEは、不一致行を返すように構成することもできます。不一致行の場合、MEASURESサブ句の式は NULL を返します。
除外
パターン定義の除外構文
({- ... -})を使用すると、ユーザーは出力から特定の行を除外できます。パターン内の一致するすべての記号が除外された場合、ALL ROWS PER MATCHが指定されていれば、その一致に対して行は生成されません。いずれにせよ、 MATCH_NUMBER が増加されることに注意してください。除外された行は結果の一部ではありませんが、MEASURES式の評価には含まれます。除外構文を使用する場合、 ROWS PER MATCH サブ句は次のように指定できます。
ONE ROW PER MATCH (デフォルト)
一致が成功するたびに正確に1行を返します。
MEASURESサブ句にあるウィンドウ関数のデフォルトのウィンドウ関数セマンティクスはFINALです。MATCH_RECOGNIZE演算子の出力列は、PARTITION BYサブ句で指定されたすべての式とすべてのMEASURES式です。結果として得られる一致のすべての行は、すべてのメジャーに対してANY_VALUE集計関数を使用して、PARTITION BYサブ句とMATCH_NUMBERで指定された式によってグループ化されます。したがってメジャーが、同じ一致の異なる行に対して異なる値に評価される場合、出力は非確定的です。PARTITION BYおよびMEASURESサブ句を省略すると、結果に列が含まれていないことを示すエラーが発生します。空の一致の場合、行が生成されます。不一致行は出力の一部ではありません。
ALL ROWS PER MATCH除外 のマークが付けられたパターンの一部に一致した行を除き、一致の一部である各行に対して行を返します。
除外された行は、
MEASURESサブ句の計算で引き続き考慮されます。AFTER MATCH SKIP TOサブ句に基づいて一致が重複する可能性があるため、同じ行が出力に複数回表示される可能性があります。MEASURESサブ句にあるウィンドウ関数のデフォルトのウィンドウ関数セマンティクスはRUNNINGです。MATCH_RECOGNIZE演算子の出力列は、入力されている行のセットの列とMEASURESサブ句で定義されている列です。ALL ROWS PER MATCHでは次のオプションを使用できます。SHOW EMPTY MATCHES (default)は、空の一致を出力に追加します。不一致行は出力されません。OMIT EMPTY MATCHESは、空の一致も不一致の行も出力されません。ただし、 MATCH_NUMBER は、空の一致によって引き続き増加されます。WITH UNMATCHED ROWSは、空の一致および不一致の行を出力に追加します。この句を使用する場合、パターンに除外を含めることはできません。
除外を使用して無関係な出力を減らす例については、 隣接していない行のパターンを検索する をご参照ください。
AFTER MATCH SKIP: 一致後に続行する場所を指定¶
このサブ句は、正の一致が見つかった後、どこで照合を続行するかを指定します。
PAST LAST ROW (default)現在一致する最後の行の後で、照合を続行します。
これにより、重複する行を含む一致が防止されます。たとえば、行に3つの
V形状を含む株価パターンがある場合、PAST LAST ROWは、2つではなく1つのWパターンを検索します。TO NEXT ROW現在一致する最初の行の後で、照合を続行します。
これにより、重複する行を含む一致が可能になります。たとえば、行に3つの
V形状を含む株価パターンがある場合、TO NEXT ROWは、2つのWパターンを検索します(最初のパターンは、最初の2つのV形状に基づいており、2番目のW形状は、2番目と3番目のV形状に基づいているため、両方のパターンに同じVが含まれている)。TO [ { FIRST | LAST } ] <記号>指定された記号に一致した最初または最後の(デフォルト)行で、照合を続行します。
少なくとも1つの行を指定された記号にマップする必要があります。そうしないと、エラーが発生します。
これが現在一致する最初の行をスキップしない場合は、エラーが発生します。
使用上の注意¶
DEFINE および MEASURES 句の式¶
DEFINE 句と MEASURES 句で式を使用できます。これらの式は複雑にすることができ、 ウィンドウ関数 と特別なナビゲーション関数(ウィンドウ関数の一種)を含めることができます。
ほとんどの点で、 DEFINE および MEASURES の式は、Snowflake SQL 構文の他の場所における式の規則に従います。ただし、以下に説明するいくつかの違いがあります。
- ウィンドウ関数:
-
PREV( expr [ , offset [, default ] ] )MEASURES サブ句の現在のマッチ内にある前の行に移動します。この関数は現在、 DEFINE サブ句では利用できません。その代わりに、 LAG を使用することができます。これにより、現在の ウィンドウフレーム 内にある前の行に移動します。
NEXT( expr [ , offset [ , default ] ] )現在の ウィンドウフレーム 内にある次の行に移動します。この関数は LEAD と同等です。FIRST( expr )MEASURES サブ句の現在のマッチ内にある最初の行に移動します。この関数は現在、 DEFINE サブ句では利用できません。 FIRST_VALUE 現在の ウィンドウフレーム にある最初の行に移動します。
LAST( expr )現在の ウィンドウフレーム にある最後の行に移動します。この関数は LAST_VALUE に似ていますが、 LAST の場合、ウィンドウフレームは、 DEFINE サブ句内で LAST が使用されている時における、現在の照合試行の現在行に限定されます。
ナビゲーション関数を使用する例については、 一致に関する情報を返す をご参照ください。
一般に、ウィンドウ関数が
MATCH_RECOGNIZE句内で使用される場合、ウィンドウ関数は独自のOVER (PARTITION BY ... ORDER BY ...)句を必要としません。ウィンドウは、MATCH_RECOGNIZE句のPARTITION BYとORDER BYによって暗黙的に決定されます。(ただし、一部の例外については DEFINE および MEASURES で使用されるウィンドウ関数の制限 を参照。)一般に、 ウィンドウフレーム も、ウィンドウ関数が使用されている現在のコンテキストから暗黙的に導出されます。フレームの下限は、以下のように定義されます。
DEFINEサブ句で、フレームは、
LAG、LEAD、FIRST_VALUE、およびLAST_VALUEを使用する場合を除いて、現在の照合試行の開始時に開始されます。MEASURESサブ句で、フレームは、見つかった一致の開始時に開始されます。
ウィンドウフレームのエッジは、
RUNNINGまたはFINALセマンティクスのいずれかを使用して指定できます。RUNNING:通常、フレームは現在の行で終了します。ただし、次の例外があります。
DEFINEサブ句では、LAG、LEAD、FIRST_VALUE、LAST_VALUE、およびNEXTの場合、フレームはウィンドウの最後の行で終了します。MEASURESサブ句では、PREV、NEXT、LAG、およびLEADの場合、フレームはウィンドウの最後の行で終了します。
DEFINEサブ句では、RUNNINGがデフォルトの(そして唯一許可されている)セマンティクスです。MEASURESサブ句では、ALL ROWS PER MATCHサブ句が使用されている場合、RUNNINGがデフォルトです。FINAL:フレームは一致の最後の行で終了します。
FINALMEASURESは、サブ句内のみで許可されます。ONE ROW PER MATCHが適用される場合は、これがデフォルトです。 - 記号による述語:
DEFINEおよびMEASURESサブ句内の式では、列参照の述語として記号を使用できます。<記号>は一致した行を示し、<列>はその行内の特定の列を識別します。述語化された列参照とは、周囲のウィンドウ関数が、指定された記号に最終的にマップされた行のみを参照することを意味します。
述語化された列参照は、ウィンドウ関数の外側と内側で使用できます。ウィンドウ関数の外部で使用する場合、
<symbol>.<column>はLAST(<記号>.<列>)と同じです。ウィンドウ関数内では、すべての列参照が同じ記号で述語化されているか、すべて非述語である必要があります。以下に、ナビゲーション関連の関数が、述語化された列参照でどのように動作するかを説明します。
{}は、最終的に指定された<記号>にマップされた最初の行に対して、現在の行を含む現在の行(またはFINALセマンティックの場合は最後の行)から開始して、ウィンドウフレームを逆方向に検索します。それから、<オフセット>(デフォルトは1)行を逆方向に移動し、それらの行がマップされた記号を無視します。フレームの検索された部分で<記号>にマップされた行が含まれていないか、検索がフレームの端を超える場合は、 NULL が返されます。{}は、最終的に指定された<記号>にマップされた最初の行に対し、現在の行を含む現在の行(またはFINALセマンティックの場合は最後の行)から開始して、ウィンドウフレームを逆方向に検索します。また、<オフセット>(デフォルトは1)行を順方向に移動し、それらの行がマップされた記号を無視します。フレームの検索された部分で<記号>にマップされた行が含まれていないか、検索がフレームの端を超える場合は、 NULL が返されます。{}は、最終的に指定された<記号>にマップされた最初の行に対し、最初の行を含む最初の行から開始して、現在の行を含む現在の行(または、FINALセマンティックの場合は最後の行)まで、ウィンドウフレームを順方向に検索します。フレームの検索された部分において<記号>にマップされた行が含まれていない場合は、 NULL が返されます。{}は、最終的に指定された<記号>にマップされた最初の行に対して、現在の行を含む現在の行(または、FINALセマンティックの場合は最後の行)から開始して、ウィンドウフレームを逆方向に検索します。フレームの検索された部分において<記号>にマップされた行が含まれていない場合は、 NULL が返されます。
注釈
ウィンドウ関数の制限は、 DEFINE および MEASURES で使用されるウィンドウ関数の制限 セクションに記載されています。
DEFINE および MEASURES で使用されるウィンドウ関数の制限¶
DEFINE および MEASURES サブ句の式には、ウィンドウ関数を含めることができます。ただし、これらのサブ句でウィンドウ関数を使用するにはいくつかの制限があります。これらの制限を次のテーブルに示します。
関数
DEFINE (実行中)[列/記号.列]
MEASURES (実行中)[列/記号.列]
MEASURES (最終)[列/記号.列]
列
✔ / ❌
✔ / ❌
✔ / ✔
PREV(...)
❌ / ❌
✔ / ❌
✔ / ❌
NEXT(...)
✔ / ❌
✔ / ❌
✔ / ❌
FIRST(...)
❌ / ❌
✔ / ❌
✔ / ✔
LAST(...)
✔ / ❌
✔ / ❌
✔ / ✔
LAG()
✔ / ❌
✔ / ❌
✔ / ❌
LEAD()
✔ / ❌
✔ / ❌
✔ / ❌
FIRST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
LAST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
集計 [1]
✔ / ❌
✔ / ✔
✔ / ✔
その他のウィンドウ関数 [1]
✔ / ❌
✔ / ❌
✔ / ❌
MATCH_RECOGNIZE 固有の関数 MATCH_NUMBER()、 MATCH_SEQUENCE_NUMBER()、および CLASSIFIER() は、現在 DEFINE サブ句では使用できません。
トラブルシューティング¶
エラーメッセージ: ONE ROW PER MATCH を使用すると、「SELECT with no columns」というエラーメッセージが表示される¶
ONE ROW PER MATCH 句を使用する場合、 SELECT の射影句では、 PARTITION BY および MEASURES のサブ句の列と式のみが許可されます。 PARTITION BY 句または MEASURES 句を指定せずに MATCH_RECOGNIZE を使用しようとすると、 SELECT with no columns と類似のエラーが発生します。
ONE ROW PER MATCH と ALL ROWS PER MATCH の詳細については、 一致ごとに1行を生成と、一致ごとにすべての行を生成の比較 をご参照ください。
例¶
トピック パターンに一致する行のシーケンスを識別する には、ここにあるほとんどの例よりも単純な例を含め、多くの例が含まれています。 MATCH_RECOGNIZE にまだ慣れていない場合は、最初にそれらの例を読むことをお勧めします。
以下の例のいくつかでは、次のテーブルとデータを使用します。
次のグラフは、曲線の形状を示しています。
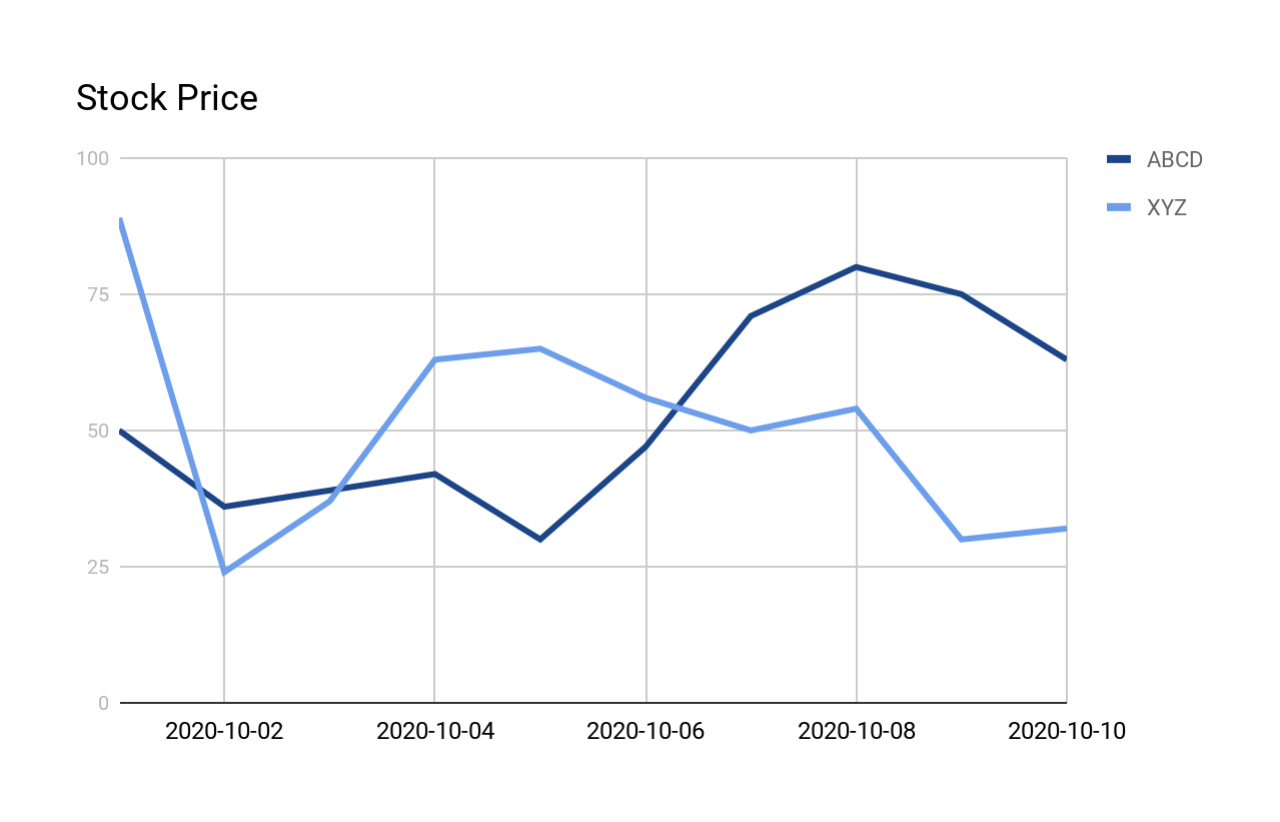
V 形状ごとに1つの要約行をレポートする¶
次のクエリは、以前に提示されたstock_price_history内のすべての V 形状を検索します。この出力については、クエリと出力の後で詳しく説明します。
出力には、一致ごとに1つの行が表示されます(一致の一部であった行数に無関係)。
出力には次の列が含まれます。
COMPANY: 会社の銘柄表示記号。
MATCH_NUMBER は、このデータセット内にあった一致を識別する連番です(例: 最初の一致には MATCH_NUMBER 1、2番目の一致には MATCH_NUMBER 2など)。データがパーティション化されている場合、 MATCH_NUMBER はパーティション内の連番です(この例では、各会社/株式に対して)。
START_DATE: このパターンの出現が始まる日付。
END_DATE: このパターンの出現が終わる日付。
ROWS_IN_SEQUENCE: これは一致する行数です。たとえば、最初の一致は4日間(10月1日から10月4日)に測定された株価に基づいているため、 ROWS_IN_SEQUENCE は4です。
NUM_DECREASES: これは、株価が下落した(一致内の)日数です。たとえば、最初の一致では、株価が1日間下落した後、2日間上昇したため、 NUM_DECREASES は1になります。
NUM_INCREASES: これは、株価が上昇した(一致内の)日数です。たとえば、最初の一致では、株価が1日間下落した後、2日間上昇したため、 NUM_INCREASES は2になります。
1つの会社において、すべての一致で、すべての行をレポートする¶
この例では、各一致内のすべての行が返されます(一致ごとに1つの要約行だけではない)。このパターンは、「ABCD」会社の株価の上昇を検索します。
空の一致を省略する¶
これは、会社のチャート全体の平均を超える株価の範囲を検索します。この例では、空の一致を省略しています。ただし、その場合でも空の一致は MATCH_NUMBER を増加することに注意してください。
WITH UNMATCHED ROWS オプションを示す¶
この例は、 WITH UNMATCHED ROWS option オプションを示しています。上記の 空の一致を省略する の例と同様に、この例では、各会社のチャートの平均株価を超える株価範囲を検索します。このクエリの量指定子は + であるのに対し、前のクエリの量指定子は * であることに注意してください。
MEASURES 句でシンボル述語を示す¶
この例は、シンボル述語での <記号>.<列> 表記の使用を示しています。