パターンに一致する行のシーケンスを識別する¶
概要¶
場合によっては、パターンに一致するテーブル行のシーケンスを識別する必要があります。たとえば、次のことが必要になる場合があります。
サポートチケットを開いたり、購入を実行したりする前に、ウェブサイトの特定のページとアクションのシーケンスに従ったユーザーを特定します。
一定期間にわたってV形状またはW形状の回復をたどった株価の株式を見つけます。
今後のシステム障害を示す可能性のあるセンサーデータのパターンを探します。
特定のパターンに一致する行のシーケンスを識別するには、 FROM 句の MATCH_RECOGNIZE サブ句を使用します。
注釈
再帰的 共通テーブル式(CTE) でMATCH_RECOGNIZE 句を使用することはできません。
行のシーケンスを識別する簡単な例¶
例として、テーブルに株価に関するデータが含まれているとします。各行には、特定の日における各銘柄記号の終値が含まれています。テーブルには次の列が含まれます。
列名 |
説明 |
|---|---|
|
終値の日付。 |
|
その日の終値。 |
株価が下落してから上昇するパターンを検出して、株価のグラフに「V」形状を作るとします。
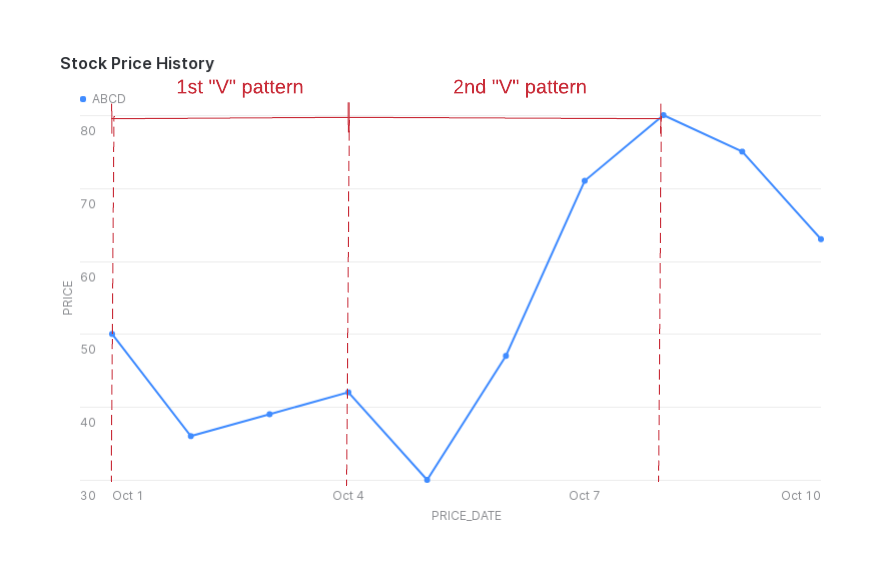
(この例では、株価が日々変化しない場合を考慮しない。)
この例では、特定の銘柄記号について、 price 列の値が増加する前に減少する行のシーケンスを検索する必要があります。
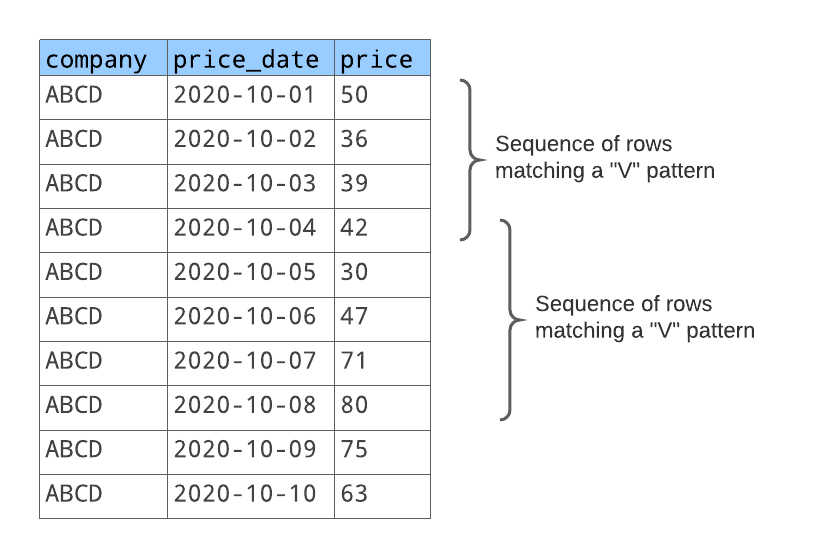
このパターンに一致する行のシーケンスごとに、以下を返します。
シーケンスを識別する番号(最初の照合シーケンス、2番目の照合シーケンスなど)。
株価が下落した前の日。
株価が上昇した最後の日。
「V」パターンの日数。
株価が下落した日数。
株価が上昇した日数。
次の図は、返されたデータがキャプチャする「V」パターン内での株価の下落(NUM_DECREASES)と上昇(NUM_INCREASES)を示しています。 ROWS_IN_SEQUENCE には、 NUM_DECREASES または NUM_INCREASES でカウントされない最初の行が含まれていることに注意してください。
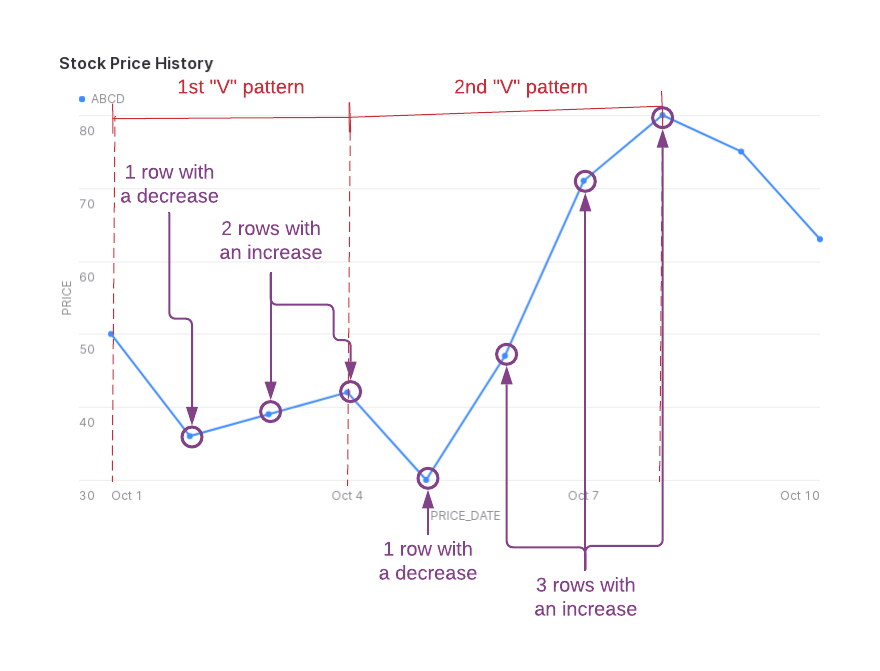
この出力を生成するには、以下に示す MATCH_RECOGNIZE 句を使用します。
上記に示したように、 MATCH_RECOGNIZE 句は多くのサブ句で構成されており、それぞれが異なる目的を果たします(例: 一致するパターンの指定、返すデータの指定など)。
次のセクションでは、この例の各サブ句について説明します。
この例のデータの設定¶
この例で使用されるデータを設定するには、次の SQL ステートメントを実行します。
ステップ1: 行の順序とグループ化を指定する¶
行のシーケンスを識別する最初のステップは、検索する行のグループ化と並べ替え順を定義することです。以下は、会社の株価で「V」パターンを見つける例です。
特定の会社の株価パターンを見つけるために、行を会社ごとにグループ化する必要があります。
行の各グループ(特定の会社の株価)内で、行を日付の昇順で並べ替える必要があります。
MATCH_RECOGNIZE 句では、 PARTITION BY および ORDER BY 句を使用して、行のグループ化と順序を指定します。例:
ステップ2: 一致するパターンを定義する¶
次に、検索する行のシーケンスに一致するパターンを特定します。
このパターンを指定するには、 正規表現 に似たものを使用します。正規表現では、リテラルとメタ文字の組み合わせを使用して、文字列で一致するパターンを指定します。
たとえば、次を含む文字のシーケンスを検索するとします。
任意の1文字に続いて、
1つ以上の大文字に続いて、
1つ以上の小文字とに続いて、
この場合は、次のPerl互換の正規表現を使用します。
条件:
.は、任意の1文字に一致します。[A-Z]+は、1つ以上の大文字に一致します。[a-z]+は、1つ以上の小文字に一致します。
+ は、 量指定子 であり、先行する1つ以上の文字が一致する必要があることを指定します。
たとえば、上記の正規表現は次のような文字のシーケンスに一致します。
1Stock@SFComputing%Fn
MATCH_RECOGNIZE 句では、同様の式を使用して、一致する行のパターンを指定します。この場合、「V」パターンに一致する行を見つけるには、以下を含む一連の行を見つける必要があります。
株価が下落する前の行に続いて、
株価が下落する1つ以上の行に続いて、
株価が上昇する1行以上
この場合は、次の行パターンとして表すことができます。
行パターンは、 パターン変数、 量指定子 (正規表現で使用されるものと同様)、および 演算子 で構成されます。パターン変数は、行に対して評価される式を定義します。
この行パターンでは、
row_before_decrease、row_with_price_decrease、およびrow_with_price_increaseはパターン変数です。これらのパターン変数の式は、次のように評価する必要があります。任意の行(株価が下落する前の行)
株価が下落する列
株価が上昇する列
row_before_decrease正規表現の.に似ています。次の正規表現では、.はパターンにある最初の大文字の前に表示される、任意の1文字に一致します。同様に、行パターンでは、
row_before_decreaseは、株価が下落した最初の行の前に表示される単一の行と一致します。row_with_price_decreaseとrow_with_price_increaseの後の+量指定子は、これらそれぞれの1つ以上の行が一致する必要があることを指定します。
MATCH_RECOGNIZE 句では、 PATTERN 句を使用して、一致する行パターンを指定します。
パターン変数の式を指定するには、 DEFINE サブ句を使用します。
条件:
row_before_decreaseは、任意の行を評価する必要があるため、ここで定義する必要はありません。row_with_price_decreaseは、株価が下落した行の式として定義されます。row_with_price_increase株価が上昇した行の式として定義されます。
異なる行の株価を比較するには、これらの変数の定義で ナビゲーション関数 LAG() を使用して、前の行の株価を指定します。
以下に示すように、行パターンは2つの行の順序に一致します。

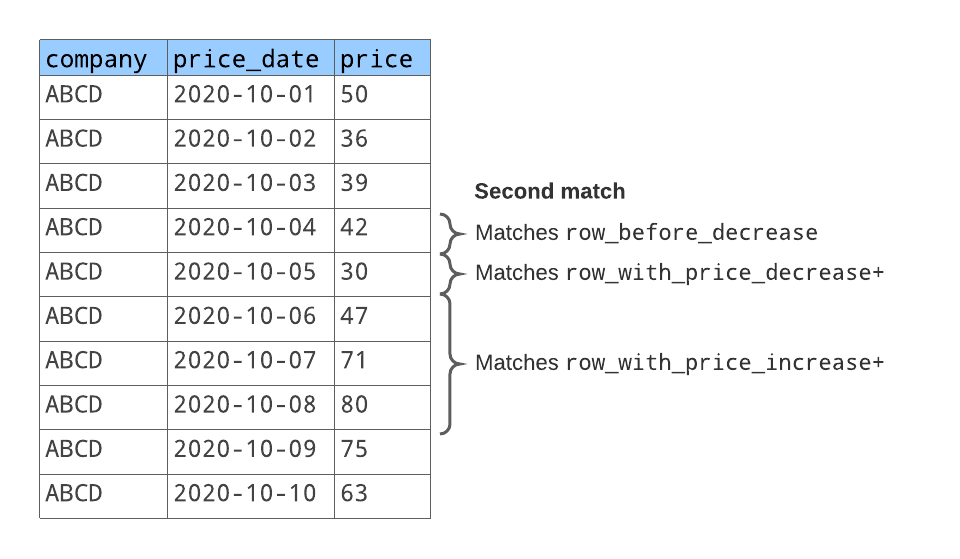
行における最初の照合シーケンスのために、
row_before_decreaseは、行を株価50と一致させます。row_with_price_decreaseは、その次の行を株価36と一致させます。row_with_price_increaseは、その次の2行を株価39および42と一致させます。
行における2番目の照合シーケンスのために、
row_before_decreaseは、行を株価42と一致させます。(これは、最初の照合シーケンスの終わりにあるのと同じ行。)row_with_price_decreaseは、その次の行を株価30と一致させます。row_with_price_increaseは、その次の2行を株価47、71、 および80と一致させます。
ステップ3: 返す行を指定する¶
MATCH_RECOGNIZE は、次のいずれかを返します。
各照合シーケンスを要約する単一の行、または
各照合シーケンス内にある各行
この例では、各照合シーケンスの要約を返します。 ONE ROW PER MATCH サブ句を使用して、照合シーケンスごとに1つの行を返すように指定します。
ステップ4: 選択するメジャーを指定する¶
ONE ROW PER MATCH を使用すると、 MATCH_RECOGNIZE が SELECT * ステートメントに含まれている場合でも、 MATCH_RECOGNIZE はテーブル内のどの列も返しません( PARTITION BY で指定された列を除く)。このステートメントによって返されるデータを指定するには、 メジャー を定義する必要があります。メジャーは、行の照合シーケンスごとに計算されるデータの追加の列です(例: シーケンスの開始日、シーケンスの終了日、シーケンスの日数など)。
MEASURES サブ句を使用して、出力に返すこれらの追加の列を指定します。メジャーを定義するための一般的な形式は次のとおりです。
条件:
expressionは、返すシーケンスに関する情報を指定します。式には、前に定義したテーブル変数とパターン変数の列を持つ関数を使用できます。column_nameは、出力で返される列の名前を指定します。
この例では、次のメジャーを定義できます。
シーケンスを識別する番号(最初の照合シーケンス、2番目の照合シーケンスなど)。
このメジャーには、一致する番号を返す
MATCH_NUMBER()関数を使用します。行の パーティション の最初に一致する番号は1で始まります。複数のパーティションがある場合、番号は各パーティションの1で始まります。株価が下落した前の日。
このメジャーには、
FIRST()関数を使用します。この関数は、照合シーケンスにある最初の行のために、式の値を返します。この例では、FIRST(price_date)は、各照合シーケンスにある最初の行のために、price_date列の値を返します。これは、株価が下落する前の日付です。株価が上昇した最後の日。
このメジャーには、
LAST()関数を使用します。この関数は、照合シーケンスにある最後の行のために、式の値を返します。「V」パターンの日数。
このメジャーには、
COUNT(*)を使用します。メジャーの定義でCOUNT(*)を指定しているため、アスタリスク(*)は、照合シーケンスですべての行をカウントすることを指定します(テーブルのすべての行ではない)。株価が下落した日数。
このメジャーには、
COUNT(row_with_price_decrease.*)を使用します。アスタリスク(.*)が後に続くピリオドは、パターン変数row_with_price_decreaseに一致する照合シーケンス内のすべての行をカウントすることを指定します。株価が上昇した日数。
このメジャーには、
COUNT(row_with_price_increase.*)を使用します。
以下は、上記のメジャーを定義する MEASURES サブ句です。
以下に、選択したメジャーを使用した出力の例を示します。
前述のように、出力に company 列が含まれるのは、 PARTITION BY 句でその列が指定されているためです。
ステップ5: その次の一致を検索し続ける場所を指定する¶
行の照合シーケンスを見つけた後、 MATCH_RECOGNIZE は、その次の照合シーケンスを検索し続けます。 MATCH_RECOGNIZE が、その次の照合シーケンスの検索を開始する場所は、指定できます。
照合シーケンスの図 に示すように、行は複数の照合シーケンスの一部にすることができます。この例では、 2020-10-04 の行は、2つの「V」パターンの一部です。
この例では、その次の照合シーケンスを見つけるために、株価が上昇した行から開始できます。 MATCH_RECOGNIZE 句でこれを指定するには、 AFTER MATCH SKIP を使用します。
ここで、 TO LAST row_with_price_increase は、 価格が上昇した最後の行 から検索を開始することを指定します。
行のパーティション分割と並べ替え¶
行全体のパターンを識別する最初のステップは、パターンが見つけられる順序で行を配置することです。たとえば、各会社における株価の経時変化のパターンを見つけたい場合は、次のようにします。
各会社の株価全般を検索できるように、行を会社ごとにパーティションします。
各パーティション内の行を日付で並べ替えて、会社の株価の経時変化を見つけられるようにします。
データをパーティションして行の順序を指定するには、 MATCH_RECOGNIZE の PARTITION BY および ORDER BY サブ句を使用します。例:
(MATCH_RECOGNIZE の PARTITION BY 句は、 ウィンドウ関数 の PARTITION BY 句と同じように機能。)
パーティション分割の利点としてはさらに、並列処理が利用できることが挙げられます。
一致する行のパターンを定義する¶
MATCH_RECOGNIZE を使用すると、パターンに一致する一連の行を見つけることができます。特定の条件に一致する行に関して、このパターンを指定します。
さまざまな会社の日々株価の表における例で、次の3行のシーケンスを検索するとします。
特定の日に、45.00未満の会社の株価。
その翌日、少なくとも10%下落する株価。
さらにその翌日、少なくとも3%上昇する株価。
このシーケンスを見つけるには、次の条件で3つの行に一致するパターンを指定します。
シーケンスの最初の行で、
price列の値は45.00未満である必要があります。2行目で、
price列の値は、前にある行の値の90%以下である必要があります。3行目で、
price列の値は、前にある行の値の105%以上である必要があります。
2行目と3行目には、異なる行の列値の比較を必要とする条件があります。1つの行の値を前の行または次の行の値と比較するには、関数 LAG() または LEAD() を使用します。
LAG(column)は、前の行にあるcolumnの値を返します。LEAD(column)は、次の行にあるcolumnの値を返します。
この例では、3つの行の条件を次のように指定できます。
シーケンスの最初の行には
price < 45.00が必要です。2行目には
LAG(price) * 0.90 >= priceが必要です。3行目には
LAG(price) * 1.05 <= priceが必要です。
これら3つの行におけるシーケンスのパターンを指定するときは、条件が異なる行ごとにパターン変数を使用します。 DEFINE サブ句を使用して、指定された条件を満たす必要がある行として各パターン変数を定義します。次の例では、3つの行に3つのパターン変数を定義します。
パターン自体を定義するには、 PATTERN サブ句を使用します。このサブ句では、正規表現を使用して、一致するパターンを指定します。式の構成要素には、定義したパターン変数を使用します。たとえば、次のパターンは3行のシーケンスを検索します。
以下の SQL ステートメントでは、上記の DEFINE および PATTERN サブ句を使用します。
次のセクションでは、特定の数の行と、パーティションの最初または最後に表示される行に一致するパターンを定義する方法について説明します。
注釈
MATCH_RECOGNIZE は、 バックトラッキング を使用してパターンを照合します。他の バックトラッキングを使用する正規表現エンジン の場合と同様に、一致するパターンとデータの組み合わせによっては実行に時間がかかる場合があり、その結果、計算コストが高くなる可能性があります。
パフォーマンスを向上させるには、できるだけ具体的なパターンを定義します。
各行が1つの記号または少数の記号にのみ一致することを確認します。
すべての行に一致する記号の使用は避けてください(例:
DEFINE句にない記号またはtrueとして定義されている記号)量指定子の上限を定義します(例:
*ではなく{,10})。
たとえば、次のパターンでは、一致する行がない場合にコストが増加する可能性があります。
一致させる行数に上限がある場合は、その制限を量指定子で指定してパフォーマンスを向上させることができます。さらに、 symbol1 に続く any_symbol を検索するように指定する代わりに、 symbol1 (この例では not_symbol1)ではない行を検索できます。
通常は、クエリの実行時間をモニターして、クエリに予想よりも時間がかかっていないことを確認する必要があります。
パターン変数での量指定子の使用¶
PATTERN サブ句で正規表現を使用して、一致する行のパターンを指定します。パターン変数を使用して、特定の条件を満たすシーケンス内の行を識別します。
特定の条件を満たす複数の行を一致させる必要がある場合は、 正規表現 の場合と同様に、 量指定子 を使用します。
たとえば、量指定子 + を使用して、パターンに株価が10%下落する1つ以上の行と、その後、株価が5%上昇する1つ以上の行を含める必要があることを指定できます。
パーティションの開始または終了に関連する照合パターン¶
パーティションの開始または終了に関連する行のシーケンスを見つけるには、 PATTERN サブ句で、メタ文字 ^ および $ を使用します。行パターンのこれらのメタ文字は、 正規表現にある同じメタ文字 と同様の目的を持っています。
^パーティションの開始を表します。$パーティションの終了を表します。
次のパターンは、パーティションの開始時に株価が75.00より大きい株式と一致します。
^ と $ は位置を指定しており、それらの位置の行を表してはいないことに注意してください(正規表現の ^ と $ は位置を指定しており、それらの位置の文字を指定してはいないことに類似)。 PATTERN (^ GT75) では、最初の行(2行目ではない)の株価は75.00より大きい必要があります。 PATTERN (GT75 $) では、最後の行(最後から2番目の行ではない)は75.00より大きい必要があります。
これは ^ の包括的な例です。このパーティションの複数の行で XYZ の株価が60.00より高い場合でも、パーティションの先頭の行のみが一致と見なされることに注意してください。
これは $ の包括的な例です。このパーティションの複数の行で ABCD の株価が50.00より高い場合でも、パーティションの最後の行のみが一致と見なされることに注意してください。
出力行の指定¶
MATCH_RECOGNIZE を使用するステートメントでは、出力する行を選択できます。
一致ごとに1行を生成と、一致ごとにすべての行を生成の比較¶
MATCH_RECOGNIZE では、一致を見つけると、出力は、一致全体に対して1つの要約行、またはパターン内の各データポイントに対して1つの行のいずれかになります。
ALL ROWS PER MATCHは、出力に一致するすべての行が含まれることを指定します。ONE ROW PER MATCHは、各パーティションの一致ごとに1行のみが出力に含まれることを指定します。SELECT ステートメントの射影句では、
MATCH_RECOGNIZEの出力のみを使用できます。事実上これは、 SELECT ステートメントが、次に挙げるMATCH_RECOGNIZEのサブ句の列のみが使用できることを意味します。PARTITION BYサブ句。一致するすべての行は同じパーティションからのものであるため、
PARTITION BYサブ句の式の値は同じです。MEASURES句。MATCH_RECOGNIZE ... ONE ROW PER MATCHを使用すると、MEASURESサブ句は、一致するすべての行に対して同じ値を返す式(例:MATCH_NUMBER())だけでなく、一致する行ごとに異なる値を返すことができる式(例:MATCH_SEQUENCE_NUMBER())を生成します。一致する行ごとに異なる値を返すことができる式を使用する場合、出力は確定的ではありません。
集計関数と
GROUP BYに精通している場合は、次の類推がONE ROW PER MATCHの理解に役立つ可能性があります。MATCH_RECOGNIZEのPARTITION BY句は、GROUP BYがSELECTのデータをグループ化するのと同じようにデータをグループ化します。MATCH_RECOGNIZE ... ONE ROW PER MATCHのMEASURES句を使用すると、MATCH_NUMBER()と同様に、一致する各行に同じ値を返すCOUNT()などの集計関数を使用できます。
一致する各行に、同じ値を返す集計関数と式のみを使用する場合、
... ONE ROW PER MATCHはGROUP BYと集計関数と同様に動作します。
デフォルトは ONE ROW PER MATCH です。
次の例は、 ONE ROW PER MATCH と ALL ROWS PER MATCH の出力の違いを示しています。これら2つのコード例は、 ...ROW(S) PER MATCH 句を除いてほとんど同じです。(通常の使用法では、 ONE ROW PER MATCH を含む SQL ステートメントには、 ALL ROWS PER MATCH を含む SQL ステートメントとは異なる MEASURES サブ句があります。)
出力からの行の除外¶
一部のクエリでは、パターンの一部のみを出力に含めることができます。たとえば、株価が何日も連続して上昇するパターンを見つけたいが、ピークといくつかの要約情報(たとえば、各ピークの前に価格が上昇する日数)のみを表示したい場合があります。
パターンで 除外構文 を使用して、 MATCH_RECOGNIZE に特定のパターン変数を検索するが、出力には含めないように指示します。検索するパターンの一部としてパターン変数を含めるが、出力の一部には含めない場合は、 {- <パターン変数> -} 表記を使用します。
これは、除外構文を使用する場合と、使用しない場合の違いを示す簡単な例です。この例には2つのクエリが含まれており、それぞれが$45未満で始まり、その後下落してから上昇した株価を検索します。最初のクエリは使用除外構文を使用しないため、すべての行が表示されます。2番目のクエリは除外構文を使用しており、株価が下落した日は表示されません。
次の例は、より現実的です。株価が1日以上連続して上昇し、その後1日以上連続して下落するパターンを検索します。出力が非常に大きくなる可能性があるため、ここでは除外を使用して、株価が上昇した最初の日(連続して1日以上上昇した場合)と、下落した最初の日(連続して1日以上下落した場合)のみを表示します。パターンを以下に示します。
このパターンは、次のイベントを順番に検索します。
45未満の開始株価。
UP。出力に含まれないその他が、直後に続く可能性があります。
DOWN。出力に含まれないその他が、直後に続く可能性があります。
除外なし、および除外ありの前述のパターンにおけるバージョンのコードと出力は次のとおりです。
一致に関する情報を返す¶
基本的な一致情報¶
多くの場合、クエリには、データを含むテーブルの情報だけでなく、見つかったパターンに関する情報もリストする必要があります。一致自体に関する情報が必要な場合は、 MEASURES 句でその情報を指定します。
MEASURES 句には、 MATCH_RECOGNIZE に固有の次の関数を含めることができます。
MATCH_NUMBER(): 一致するものが見つかるたびに、1から始まる一致した連番が割り当てられます。この関数は、その一致番号を返します。MATCH_SEQUENCE_NUMBER(): パターンには通常、複数のデータポイントが含まれるため、テーブルの各値に関連付けられているデータポイントを知りたい場合があります。この関数は、一致内のデータポイントの連番を返します。CLASSIFIER(): 分類子は、行が一致したパターン変数の名前です。
以下のクエリには、一致番号、一致シーケンス番号、および分類子を含む MEASURES 句が含まれています。
MEASURES サブ句は、これよりもはるかに多くの情報を生成できます。詳細については、 MATCH_RECOGNIZE 参照ドキュメント をご参照ください。
ウィンドウ、ウィンドウフレーム、およびナビゲーション関数¶
MATCH_RECOGNIZE 句は、行の「ウィンドウ」で機能します。 MATCH_RECOGNIZE に PARTITION サブ句が含まれている場合、各 パーティション は1つのウィンドウです。 PARTITION サブ句がない場合は、入力全体が1つのウィンドウになります。
MATCH_RECOGNIZE の PATTERN サブ句は、左から右への順に記号を指定します。例:
データを左から右に昇順で行のシーケンスとして描く場合、 MATCH_RECOGNIZE は右に移動し(たとえば、株価の例の最も早い日付から最も遅い日付に)、各ウィンドウ内の行にあるパターンを検索すると考えることができます。
MATCH_RECOGNIZE は、ウィンドウの最初の行から開始し、その行と後続の行がパターンに一致するかどうかを確認します。
最も単純なケースでは、ウィンドウの最初の行からパターンの一致があるかどうかを判断した後、 MATCH_RECOGNIZE は右に1行移動してプロセスを繰り返し、2番目の行がパターンの出現の始まりであるかどうかを確認します。 MATCH_RECOGNIZE は、ウィンドウの終わりに達するまで右方向に移動し続けます。
(MATCH_RECOGNIZE は、複数行で右方向に移動できます。たとえば、現在のパターンの終了後に次のパターンの検索を開始するよう、 MATCH_RECOGNIZE に指示できます。)
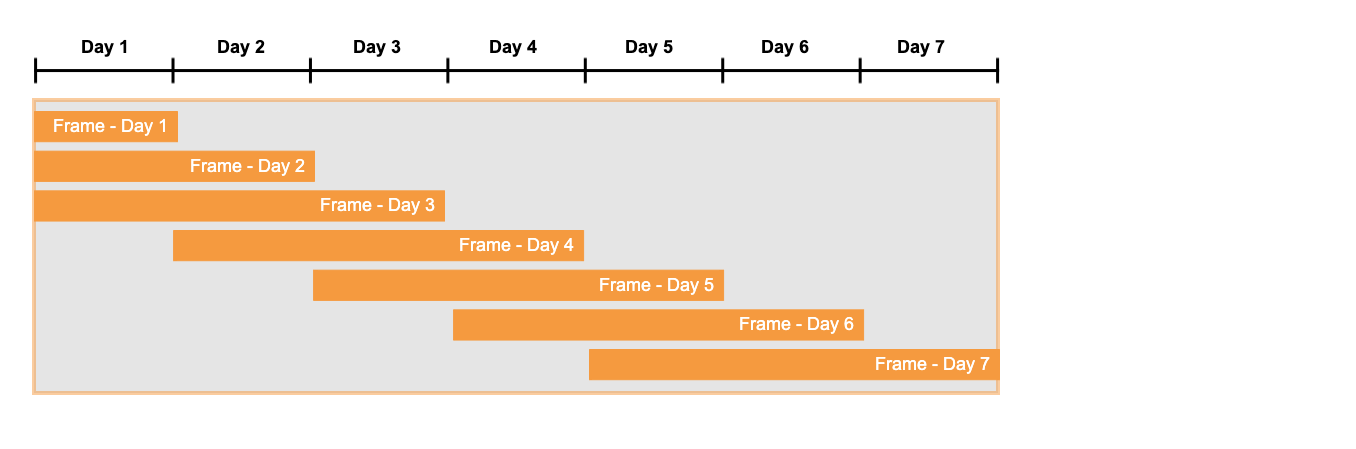
これは、まるで「フレーム」がウィンドウの中で右に動いているかのように、大まかに想像することができます。そのフレームの左端は、現在一致がチェックされている行のセットにある最初の行にあります。フレームの右端は、一致するものが見つかるまで定義されません。一致が見つかると、フレームの右端が一致の最後の行になります。たとえば、検索パターンが pattern (start down up) の場合、 up に一致する行が、フレームの右端の前にある最後の行です。
(一致するものが見つからない場合、フレームの右端は定義されず、参照されることもありません。)
単純なケースでは、以下に示すようにスライディングウィンドウフレームを描くことができます。
DEFINE サブ句(例: DEFINE down_10_percent as LAG(price) * 0.9 >= price)の式で使用される、 LAG() などの ナビゲーション関数 はすでに見たとおりです。次のクエリは、ナビゲーション関数が MEASURES サブ句でも使用できることを示しています。この例では、ナビゲーション関数は、現在の一致を含むウィンドウフレームの端(したがってサイズ)を表示します。
このクエリの各出力行には、その行の LAG()、 LEAD()、 FIRST()、および LAST() ナビゲーション関数の値が含まれています。ウィンドウフレームのサイズは、最初と最後の行自体を含む、 FIRST() から LAST() までの行数です。
以下のクエリの DEFINE 句と PATTERN 句は、3行のグループを選択します(10月1日から3日、10月2日から4日、10月3日から5日など)。
このクエリの出力は、 LAG() 関数と LEAD() 関数が、一致グループの外側(つまり、 ウィンドウフレーム の外側)の行を参照しようとする式に対して、 NULL を返すことも示しています。
DEFINE 句のナビゲーション関数のルールは、 MEASURES 句のナビゲーション関数のルールとは少し異なります。たとえば、 PREV() 関数は MEASURES 句で使用できますが、現在、 DEFINE 句では使用できません。その代わりに、 DEFINE 句で LAG() を使用することができます。 MATCH_RECOGNIZE の参照ドキュメントには、各 ナビゲーション関数 に対応するルールが記載されています。
MEASURES サブ句には、次のものを含めることもできます。
集計関数。たとえば、パターンがさまざまな行数に一致するときに(例: 1つ以上の株価の下落に一致する場合)、一致する行の総数を知りたい場合があります。その場合は、
COUNT(*)を使用してこれを表示できます。一致の各行の値を操作する一般式。これらは、数式、論理式などです。たとえば、行の値を調べて、「ABOVE AVERAGE」などのテキスト記述子を出力できます。
行(
ONE ROW PER MATCH)をグループ化し、グループ内の行ごとに列の値が異なる場合は、その一致のその列に選択された値は非確定的であり、その値に基づく式も非確定的になる可能性が高いことに注意してください。
MEASURES サブ句の詳細については、 MATCH_RECOGNIZE の参照ドキュメント をご参照ください。
次の一致を検索する場所の指定¶
デフォルトでは、 MATCH_RECOGNIZE は一致を見つけると、最新の一致が終了した直後に次の一致の検索を開始します。たとえば、 MATCH_RECOGNIZE が行2、3、および4で一致を見つけた場合、 MATCH_RECOGNIZE は行5で次の一致の検索を開始します。これにより、一致の重複が防止されます。
ただし、別の開始点を選択できます。
次のデータを検討してください。
データで W パターン(下、上、下)を検索するとします。3つの W 形状があります。
月: 1、2、3、4、および5。
月: 3、4、5、6、および7。
月: 5、6、7、8、および9。
SKIP 句を使用して、すべてのパターンが必要か、重複しないパターンのみが必要かを指定できます。 SKIP 句は他のオプションもサポートします。 SKIP 句については、 MATCH_RECOGNIZE で詳しく文書化されています。
ベストプラクティス¶
MATCH_RECOGNIZE句に ORDER BY 句を含めます。この ORDER BY は、
MATCH_RECOGNIZE句内のみで適用されることに注意してください。クエリ全体で特定の順序で結果を返す場合は、クエリの最も外側のレベルで追加のORDER BY句を使用します。
パターン変数名:
意味のあるパターン変数名を使用して、パターンの理解とデバッグを容易にします。
PATTERN句とDEFINE句の両方でパターン変数名の誤植を確認します。
デフォルトのあるサブ句にデフォルトを使用することは避けます。選択を明確にします。
包括的なデータセットにスケールアップする前に、少量のデータサンプルでパターンをテストします。
MATCH_NUMBER()、MATCH_SEQUENCE_NUMBER()、およびCLASSIFIER()は、デバッグに非常に役立ちます。クエリの最も外側のレベルで
ORDER BY句を使用して、MATCH_NUMBER()とMATCH_SEQUENCE_NUMBER()を使用することによる、出力の強制的順序付けを検討してください。出力データの順序が異なる場合は、出力がパターンと一致していないように見える場合があります。
分析エラーの回避¶
相関関係と因果関係¶
相関関係は因果関係を保証するものではありません。 MATCH_RECOGNIZE は、「偽陽性」を返す可能性があります(パターンが見られる場合があるが、それは単なる偶然)。
パターン照合は、「偽陰性」を引き起こす可能性もあります(実世界にパターンが存在するが、そのパターンがデータサンプルには表示されない場合)。
ほとんどの場合、一致するものを見つけること(たとえば、保険金詐欺を示唆するパターンを見つけること)は、分析の最初のステップにすぎません。
通常、次の要因により偽陽性の数が増加します。
データセットが大きい。
多数のパターンを検索している。
短いパターンまたは単純なパターンを検索している。
通常、次の要因により偽陰性の数が増加します。
データセットが小さい。
考えられるすべての関連パターンを検索していない。
必要以上に複雑なパターンを検索している。
順序に依存しないパターン¶
ほとんどのパターン照合では、データが順序付けられている必要(たとえば、時間ごとに)がありますが、例外があります。たとえば、人が自動車事故と住居侵入窃盗の両方で保険金詐欺を犯した場合、詐欺がどの順序で発生したかは関係ありません。
探しているパターンが順序に依存しない場合は、「代替」(|)や PERMUTE などの演算子を使用して、検索の順序依存度合いを低減することができます。
例¶
このセクションには追加の例が含まれています。
MATCH_RECOGNIZE にはさらに多くの例があります。
複数日の株価上昇を見つける¶
次のクエリは、会社 ABCD の株価が2日連続で上昇したすべてのパターンを検索します。
PERMUTE 演算子のデモ¶
この例は、パターンの PERMUTE 演算子を示しています。上昇する株価の数を2つに制限するチャートで、すべての上昇と下落のスパイクを検索します。
SKIP TO NEXT ROW オプションのデモ¶
この例は、 SKIP TO NEXT ROW オプションを示しています。このクエリは、各社のチャートでW形状の曲線を検索します。一致は重なり合う可能性があります。
除外構文¶
この例は、パターンの除外構文を示しています。このパターン(前のパターンと同様)は W 形状を検索しますが、このクエリの出力では株価の下落は除外されます。このクエリでは、一致の最後の行を超えて照合が継続されることに注意してください。
隣接していない行のパターンを検索する¶
状況によっては、連続していない行のパターンを探したい場合があります。たとえば、ログファイルを分析している時に、致命的なエラーの前に特定の一連の警告が表示されたすべてのパターンを検索したい場合があります。関連するすべてのメッセージ(行)が単一のウィンドウに表示されて隣接するように、自然な方法で行のパーティションおよび並べ替えができない場合があります。そのような状況では、特定のイベントを検索するパターンが必要になる場合がありますが、イベントがデータ内で連続している必要はありません。
以下は、パターンに適合する、連続または非連続の行を認識する DEFINE および PATTERN 句の例です。記号 ANY_ROW は TRUE として定義されます(したがって、任意の行に一致)。 ANY_ROW が発生するたびに * は、最初の警告と2番目の警告の間、および2番目の警告と致命的なエラーログメッセージの間に、0以上の ANY_ROW の発生を許可することを示します。したがって、パターン全体では、 WARNING1、任意の数の行、 WARNING2、任意の数の行、 FATAL_ERROR の順に検索するように指示します。関係のない行を出力から除外するために、クエリでは 除外 構文({- および -})を使用します。
トラブルシューティング¶
ONE ROW PER MATCH を使用し、Select句で列を指定するときのエラー¶
ONE ROW PER MATCH 句は、集計関数と同様に機能します。これにより、使用できる出力列が制限されます。たとえば、 ONE ROW PER MATCH を使用し、各一致に日付の異なる3つの行が含まれている場合は、3つの行すべてに対して正しい単一の日付がないため、 SELECT 句の出力列として日付列を指定することはできません。
予期しない結果¶
PATTERN句とDEFINE句にある誤植を確認します。PATTERN句で使用されているパターン変数名がDEFINE句で定義されていない場合(例: 名前がPATTERN句またはDEFINE句で間違って入力されている場合)は、エラーが報告されません。代わりに、パターン変数名は各行でtrueであると単純に見なされます。重複するパターンを含めたり除外したりするなど、
SKIP句を見直して、適切であることを確認します。