ウェブインターフェイスを使用したデータのロード¶
Snowsight または Classic Console ウェブインターフェイスからテーブルにデータを追加できます。
これらのインターフェイスから、構造化データ(CSV または TSV 形式を含む)または半構造化データ(JSON、Avro、 ORC、Parquet、 XML 形式を含む)を含むファイルをアップロードできます。
以下の場所からデータをアップロードできます。
ローカルマシン。
既存のステージ。
Snowflake、Amazon S3、Google Cloud Storage、Microsoft Azure上の既存のクラウドストレージで、まだ外部ステージとしてSnowflakeに追加されていないもの(Classic Console のみ)。
一度に250ファイルまでアップロードできます。各ファイルは最大250 MB です。大容量ファイルや多数のファイルをロードするには、Snowflakeクライアントを使用します: SnowSQL。詳細については、 ローカルファイルシステムからの一括ロード をご参照ください。
このトピックの内容:
Snowsight を使用してデータをロードする¶
データをロードする際、 新しいテーブルを作成する か、 既存のテーブルにデータをロードする ことができます。
Snowsight のデータロードセッションの場合、Snowflakeは 明示的トランザクション 内ですべての SQL コマンドを実行します。これらのコマンドは、 ACCOUNT または USER レベルで AUTOCOMMIT にセットした値に関係なくコミットされます。
Snowsight を使用して新しいテーブルを作成する¶
データをロードする際、多くの場合、同時にデータ用の新しいテーブルを作成し、自動的に構成することができます。
注釈
データをロードする際に XML ファイルから新しいテーブルを作成することはサポートされていません。
データをロードする際に新しい Apache Iceberg™ テーブルを作成することはサポートされていません。
このような状況では、新しい空のテーブルを作成し、 既存のテーブルにデータをロードする 手順を使用します。
Snowsight にサインインします。
左下隅にある名前 » Switch role を選択してから、次の権限を含むロールを選択します。
オブジェクト
権限
注意
データベース
USAGE
スキーマ
CREATE TABLE
ステージ
USAGE
テーブル
OWNERSHIP
ナビゲーションメニューの上部で、|add-tile|(:ui:`Create`)|raa| Table » From File を選択します。
Load Data into Table ダイアログが表示されます。
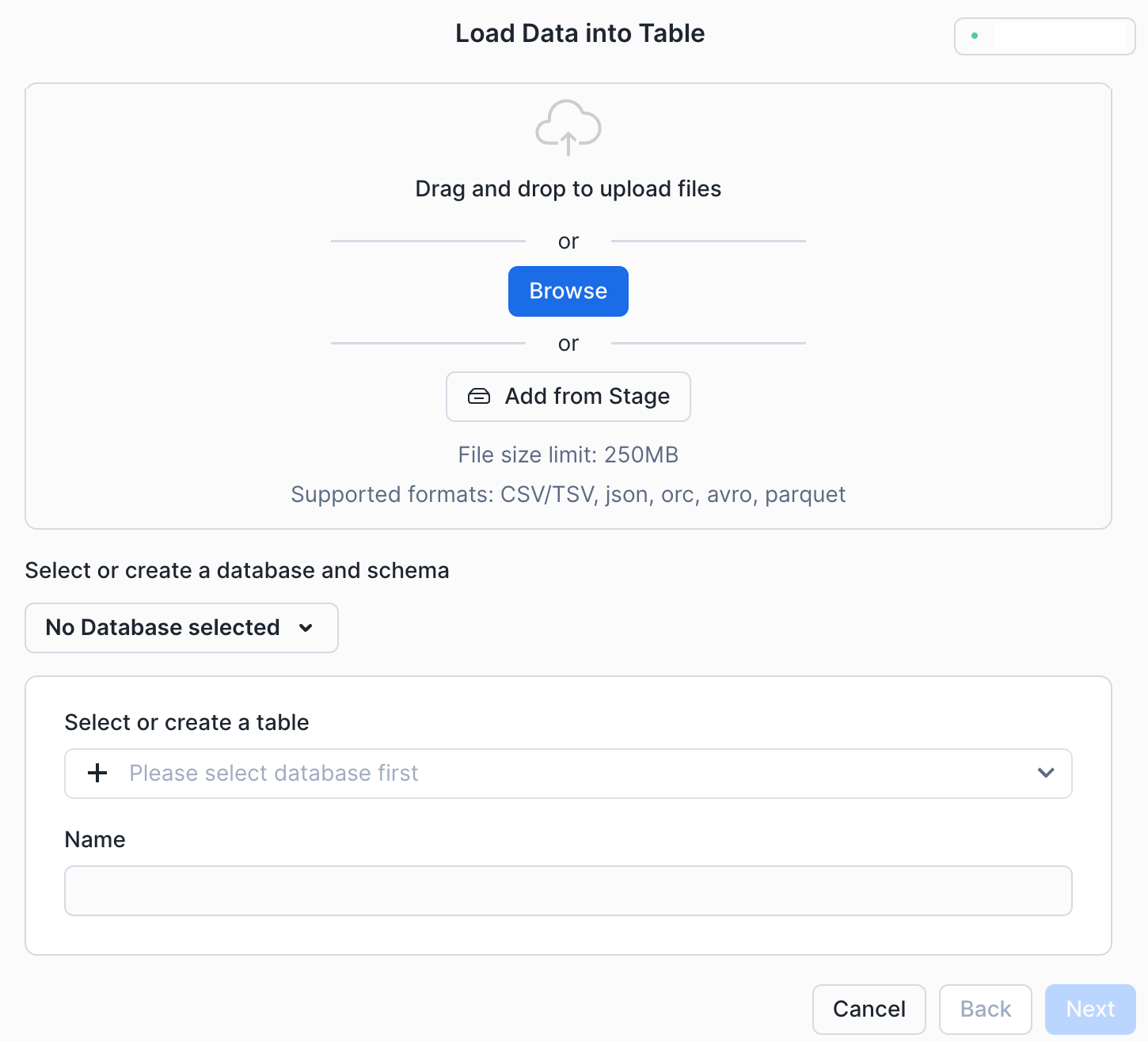
テーブルを作成するデータベースとスキーマを選択または作成します。
これらの方法のいずれかを使用して、データを含むファイルを選択します。
ローカルシステムから直接 Drag and drop to upload files する。
ローカルシステムのファイルに Browse する。
Add from stage。
Add from stage を選択すると、ステージエクスプローラーが表示されます。
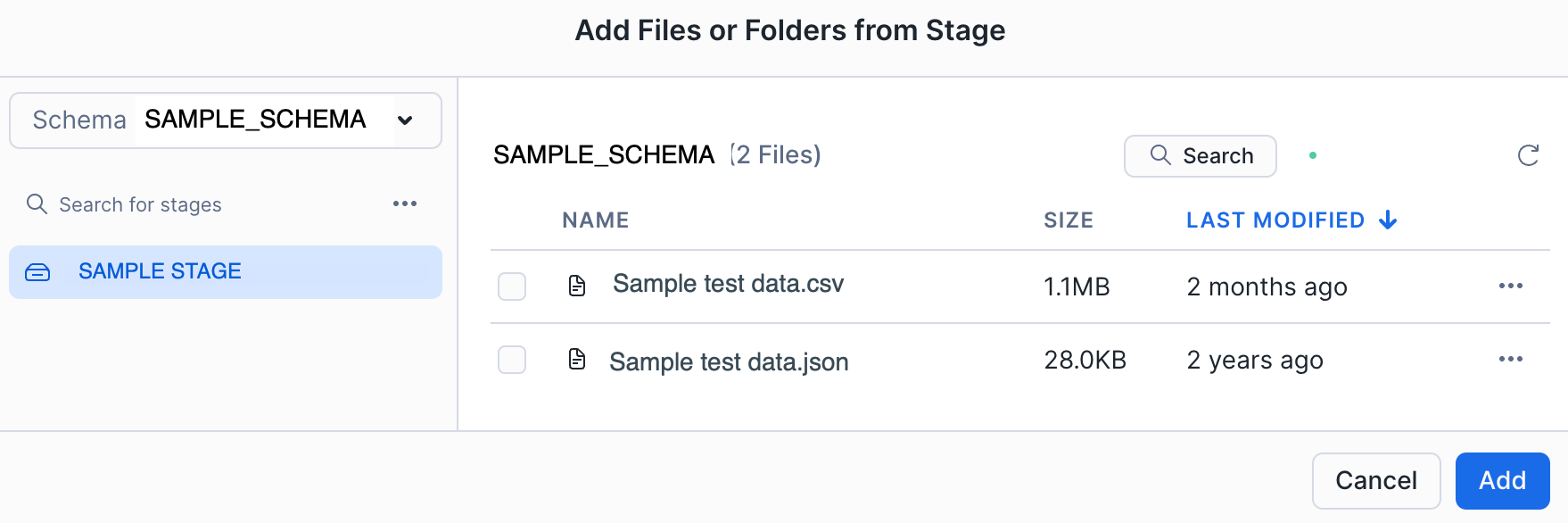
ステージエクスプローラーからステージやサブフォルダーに移動し、ステージから特定のフォルダーやファイルを選択することができます。
ステージ上の特定のファイルを選択せずに Add を選択すると、ステージ上のすべてのファイルとフォルダを含むルートステージが追加されます。
ステージフォルダに表示できるファイル数の上限は250です。
新しいテーブルの名前を入力し、 Next を選択します。テーブルスキーマのダイアログが表示されます。
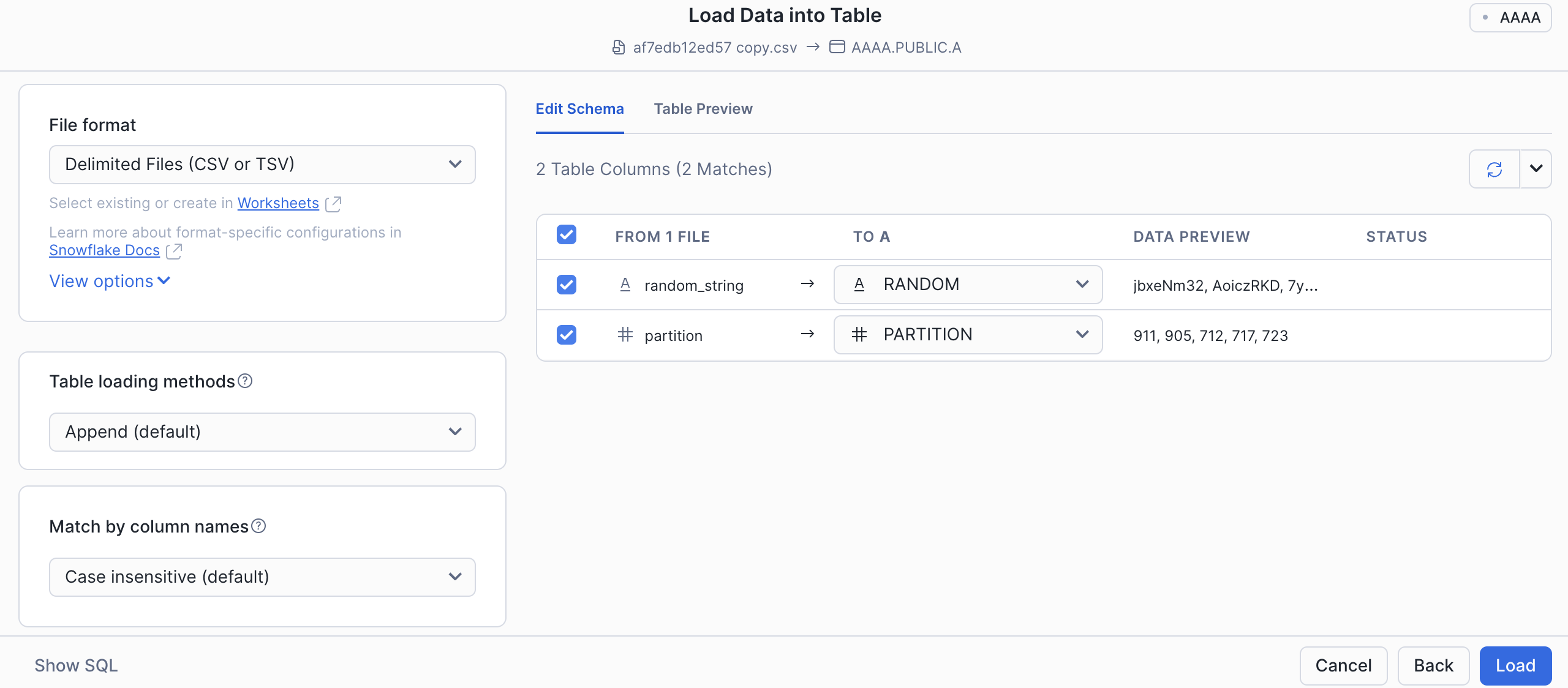
Snowsight はファイルのメタデータスキーマを検出し、 INFER_SCHEMA 関数で特定されたファイルフォーマットと列定義を返します。
推測されるファイル形式、データ型、列名、列データのサンプルを確認します。すべての情報が正確であることを確認し、必要に応じて更新を行います。
Load を選択します。
Snowsightはファイルをロードし、ファイル用の新しいテーブルを作成します。
Snowsight を使用して既存のテーブルにデータをロードする¶
Snowsight にサインインします。
ユーザーメニュー を開き、少なくとも以下の権限を含むアカウントロールを選択します。
オブジェクト
権限
注意
データベース
USAGE
スキーマ
USAGE
ステージ
USAGE
ステージからファイルを読み込む際に必要です。
ファイル形式
USAGE
という名前のファイル形式 を使用する場合に必要です。
テーブル
INSERT
ナビゲーションメニューで Ingestion » Add Data を選択します。
Load data into a Table を選択します。「テーブルにデータをロード」ダイアログが表示されます。
これらの方法のいずれかを使用して、データを含むファイルを選択します。
ローカルシステムから直接 Drag and drop to upload files する。
ローカルシステムのファイルに Browse する。
Add from stage。
Add from stage を選択すると、ステージエクスプローラーが表示されます。
ステージエクスプローラーからステージやサブフォルダーに移動し、ステージから特定のフォルダーやファイルを選択することができます。
ステージ上の特定のファイルを選択せずに Add を選択すると、ステージ上のすべてのファイルとフォルダを含むルートステージが追加されます。
ステージフォルダに表示できるファイル数の上限は250です。
データのロード先のデータベース、スキーマ、テーブルを選択します。
Next を選択します。「テーブルにデータをロード」ダイアログに「スキーマの編集」ページが表示されます。
必要に応じて最終的なカスタマイズを行います。
ファイル形式 を現在のデータベースから選択します。
カスタマイズするファイル型を選択し、データファイルの関連設定を選択します。
注釈
ParquetデータをSnowflake管理のIcebergテーブルにロードするには、 Load as a single variant column? の選択を解除します。SnowflakeはParquetデータをIcebergのテーブル列に直接ロードします。Snowsightを使用してParquetファイルをロードする場合、デフォルトの LOAD_MODE = FULL_INGEST のみがサポートされます。詳細については、 COPY INTO <テーブル> をご参照ください。
(オプション) 形式タイプオプション (例: 日付と時刻の形式を指定する、または無効な文字を置換する)の場合は、 View options を選択します。
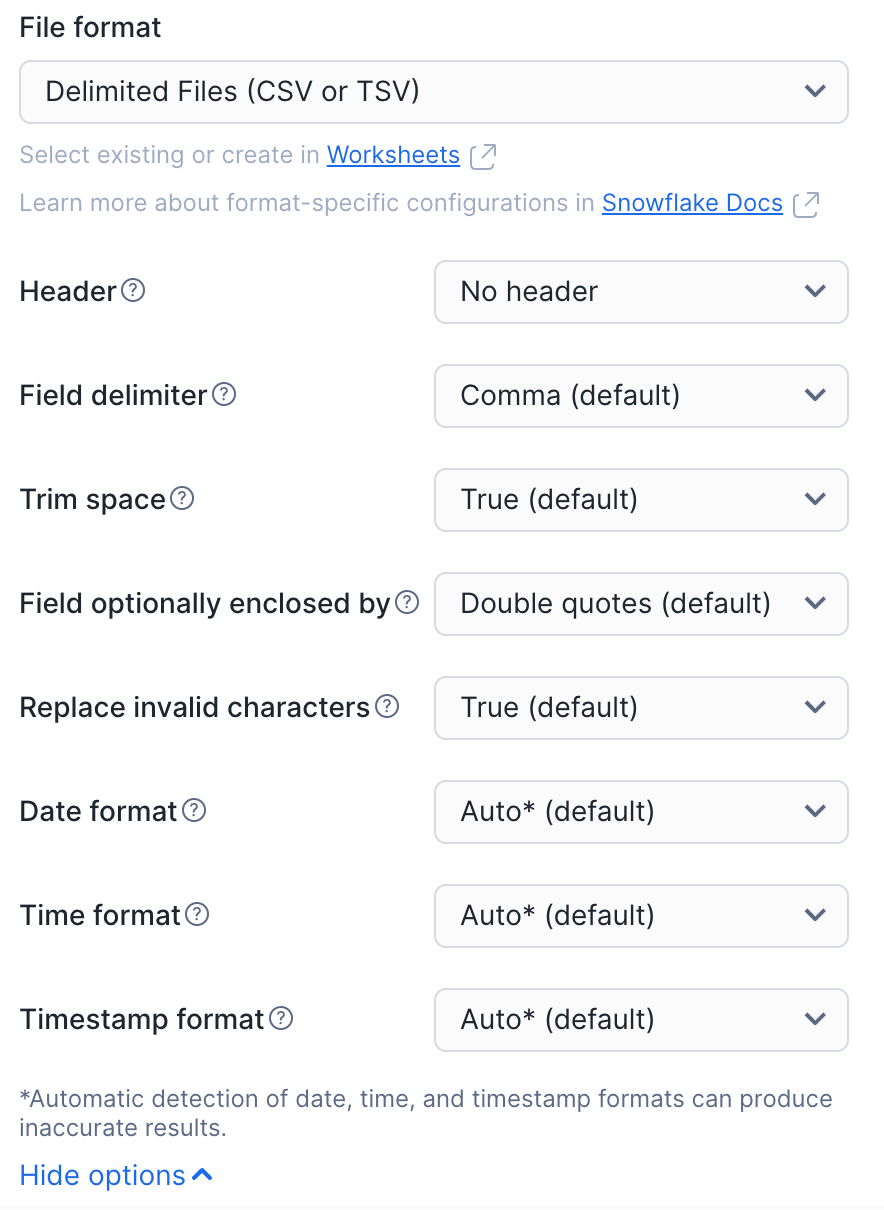
(オプション)ロード中にエラーが発生した場合の処理を選択します。デフォルトでは、データはファイルからロードされません。
Table loading methods の以下のオプションのいずれかを選択してください。デフォルトのオプションは Append です。
Append: データのロード中、既存のテーブルに新しいデータが追加されます。
Replace: 新しいデータはテーブルの既存のデータを置き換えます。
Match by column names オプションのいずれかを選択し、ソースファイルとターゲットテーブルを自動的に一致させます。デフォルトのオプションは case insensitive です。
テーブルスキーマのダイアログの右側にある Edit Schema タブを選択します。ソースファイルとターゲットテーブルの間に不一致がある場合は、必要に応じて調整してください。
ドロップダウンリストから正しい列名を選択し、ソースファイルとターゲットテーブルを一致させます。例えば、以下のスクリーンショットでは、ソースファイルには
buildingという列があり、ターゲットテーブルにはBUILDING_IDという列があります。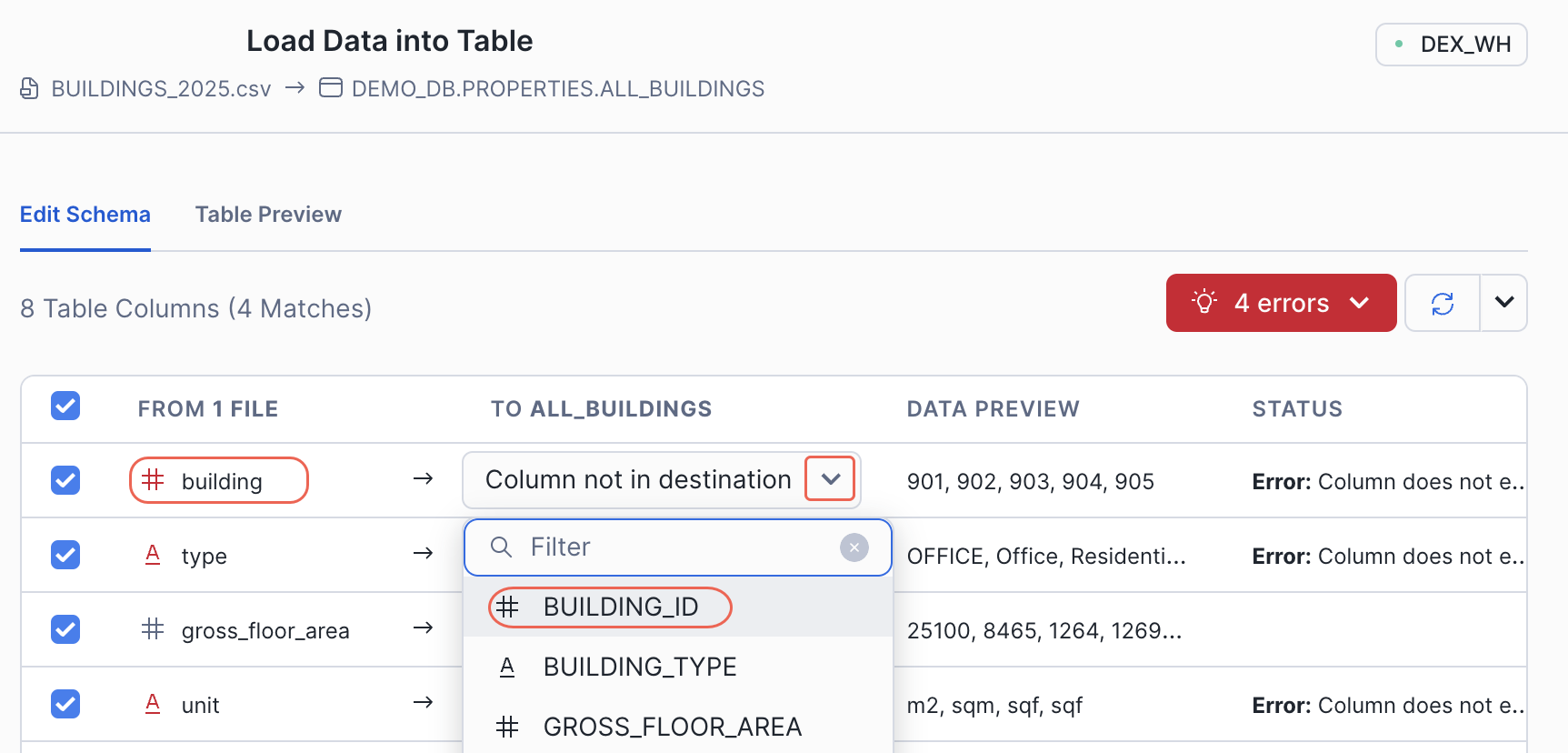
オプション: Table Preview タブを選択し、受信ソースファイルのデータがターゲットテーブルでどのように見えるかをプレビューします。
Load を選択します。
Snowsightはファイルをロードし、テーブルに正常に挿入された行の数を表示します。
従来のコンソールを使用したデータのロード¶
Classic Console は、限られた量のデータを小さなファイルセットからテーブルにロードするためのウィザードを提供します。ウィザードは、 SQL を使用する場合と同じ PUT および COPY 操作を実行しますが、2つのフェーズ(ファイルのステージングとデータのロード)を1つの操作に結合し、ロードの完了後にステージングされたファイルすべてを削除します。
ローカルマシン上のファイル、またはSnowflake、Amazon S3、Google Cloud Storage、Microsoft Azureにある既存のクラウドストレージの場所ですでにステージングされているファイルから、データをロードできます。
ロールを選択¶
適切な権限を持つロールを選択してください。(左下隅にある名前 » Switch role » ACCOUNTADMIN を選択します。)
データをロードするには、データをロードするテーブルが含まれるデータベースおよびスキーマに対する USAGE 権限がロールに必要です。
データのロード時にステージを作成するには、データベーススキーマに対する CREATE STAGE 権限がロールに必要です。
データのロード時にファイル形式を作成するには、データベーススキーマに対する CREATE FILE FORMAT 権限がロールに必要です。
データをロードするテーブルを選択する¶
Databases
 を選択します。
を選択します。特定のデータベースとスキーマを選択します。
Tables タブを選択します。
データをロードするテーブルを見つけます。
次のいずれかを実行して、特定のテーブルにデータのロードを開始します。
テーブルの行を選択し、 Load Data を選択します。
テーブル名を選択してテーブルの詳細ページを開き、 Load Table を選択します。
Load Data ウィザードが開きます。
テーブルにデータをロードするために使用するウェアハウスを選択します。ドロップダウンには、 USAGE 権限のあるウェアハウスが含まれます。
Next を選択します。
ロードするデータを選択する¶
データのロード元として選択した場所に応じて、関連するステップに従います。複数の場所からデータをロードする場合は、 Load Data ウィザードを複数回使用します。
自分のコンピューターからデータをロードするには、
Load files from your computer オプションを選択し、 Select Files を選択してロードするファイルを閲覧します。
1つ以上のローカルデータファイルを選択し、 Open を選択します。
Next を選択します。
既存のステージからデータをロードするには、
Load files from external stage オプションを選択します。
Stage ドロップダウンリストから、既存のステージを選択します。
(オプション)ステージ内のファイルへのパスを指定します。
Next を選択します。
ステージを作成する(例: 外部クラウドストレージからデータをロードする)には、
Load files from external stage オプションを選択します。
Stage ドロップダウンリストの横にある + を選択します。
使用するファイルのある、サポートされているクラウドストレージサービスを選択します。
Next を選択します。
フィールドに入力してステージを説明します。詳細については、 CREATE STAGE をご参照ください。
Finish を選択します。
新しいステージは、 Stage ドロップダウンリストから自動的に選択されます。
(オプション)ステージ内のファイルへのパスを指定します。
Next を選択します。
データのロードを終了する¶
ロードするファイルを選択したら、テーブルへのデータのロードを完了します。
注釈
データのロードが完了したときにウェアハウスが実行されていない場合は、データのロード前にウェアハウスが再開されるまで(最大5分)待つ必要があります。
データのロードを完了するには、次を実行します。
ドロップダウンリストから既存の名前付きファイル形式を選択するか、形式を作成します。
ファイル形式を作成するには、
ドロップダウンリストの横にある + を選択します。
データファイルの形式に合わせて、フィールドに入力します。オプションの説明については、 CREATE FILE FORMAT をご参照ください。
Finish を選択します。
新しい名前付きファイル形式は、ドロップダウンリストから自動的に選択されます。
データのロード時に発生するエラーをどのように処理するかを決定します。
エラーが発生した場合にデータのロードを停止する場合は、 Load を選択します。
エラーを別の方法で処理したい場合は、
Next を選択します。
エラーの処理方法を説明するオプションを選択します。オプションの詳細については、 COPY INTO <テーブル> の
ON_ERRORセクションをご参照ください。Load を選択します。
Snowflakeは、選択したウェアハウスを使用して、選択したテーブルにデータをロードします。
OK を選択して、 Load Data ウィザードを閉じます。