時系列データの分析¶
この目的のために特別に設計された機能を使用して、Snowflakeで時系列データを分析できます。データベース管理者、データサイエンティスト、アプリケーション開発者は、ビジネスアナリストや他のコンシューマーがデータを利用できるようにする前に、時系列が効率的に保存され、読み込み中であること、多くの場合、完全で一貫性のある形式に要約されていることを確認する必要があります。
時系列データの紹介¶
時系列 は、システム、プロセス、および行動が一定期間にわたってどのように変化するかを捉える連続した観察から構成されます。時系列データは、幅広い業界の各種デバイスから収集されます。一般的な例としては、金融アプリケーションのために収集された株式取引データ、気象観測、スマート工場のセンサーから収集された温度測定値、デジタル広告におけるユーザーのクリックログなどがあります。
時系列における1つの記録は通常、以下のような構成要素を持ちます。
一貫した粒度(ミリ秒、秒、分、時間など)を持つ日付、時刻、またはタイムスタンプ。
通常は数値(データの傾向や異常を明らかにする可能性のある事実)である1つ以上の測定値またはなんらかのメトリクス。
温度測定値の位置や取引銘柄のシンボルなど、測定に関連するディメンション。
例えば、以下の気象観測には、開始と終了のタイムスタンプ、降雨量の測定値(0.32)、および位置情報があります。
工場デバイスから収集された以下のデータには、名前空間(IOT)、タグ(ID)またはセンサー(ID)(3000)、デバイス上の温度読み取り値のタイムスタンプ、温度読み取り値自体(21.1673)、およびデータがその後データブローカーに到着した時である「ブローカータイムスタンプ」があります。例えば、データブローカーはSnowflakeテーブルにデータを取り込むKafkaサーバーかもしれません。
時系列で見ると、何らかの理由で測定値が急激に変化したときにスパイクが発生することがあります。例えば、以下の画像は15秒間隔で測定された一連の温度測定値を示しており、前日まで35℃台で安定していた値が40℃を超えるピークに達しています。
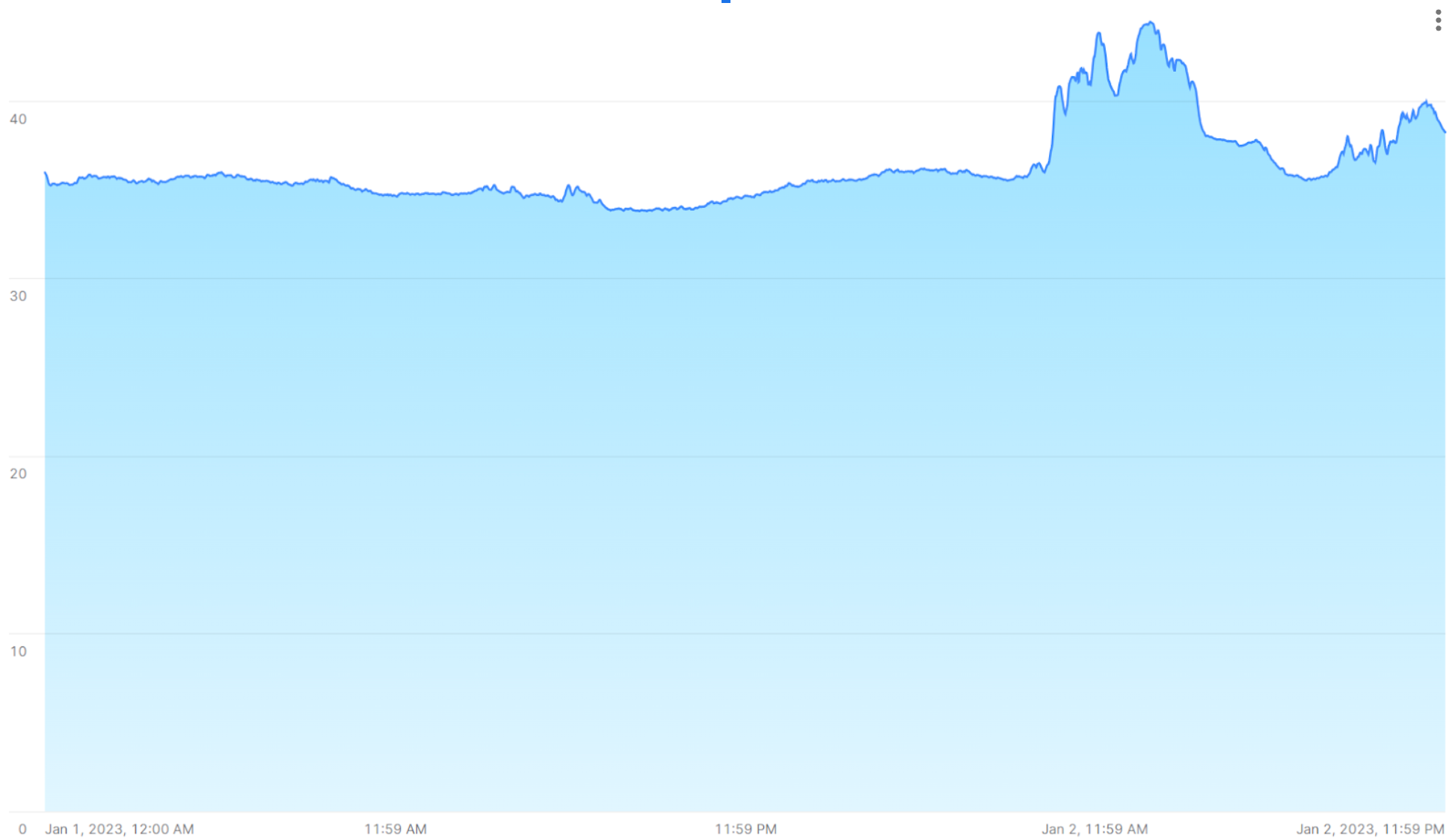
以下のセクションでは、SQL関数と結合を使用して、この種の大量のデータを分析および可視化し、高速かつ正確な結果を得る方法を紹介します。
時系列データの保存方法¶
次の 日次データ型 がサポートされています。
DATE
TIME
TIMESTAMP(およびTIMESTAMP_TZを含むバリエーション)
これらのデータ型を使用するデータのロード、管理、クエリについては、 日付と時刻の値の操作 をご参照ください。
時系列データの保存とクエリの両方に役立つ、よく使われる SQL 関数 が多数用意されています。例えば、 CONVERT_TIMEZONE を使ってタイムスタンプをあるタイムゾーンから別のタイムゾーンに変換することができます。また、 EXTRACT や TIMEADD などの関数を使えば、必要に応じて時間ベースのデータを操作することができます。
注釈
TIMESTAMP_TZ では、指定した値の作成時に、実際のタイムゾーンではなく指定したタイムゾーンのオフセットがSnowflakeに保存されます。
クエリのパフォーマンスを最適化するために、時系列分析に使用されるテーブルは、多くの場合、時間によってクラスタ化されます(場合によっては、センサーIDまたは同様のディメンションによってもクラスタ化されます)。クラスタリングキーとクラスタ化されたテーブル をご参照ください。
時系列データの集計¶
時系列データの管理には、大量のきめ細かい記録をより要約された形に集計することが必要になる場合があります(このプロセスは「ダウンサンプリング」と呼ばれることもあります)。特定の時間ベースの粒度(ミリ秒、秒、分など)を持つレコードの大規模なセットが与えられた場合、これらのレコードをより粗い粒度にロールアップし、効果的に小さなサンプルを作成することができます。
ダウンサンプリングは、データセットのサイズとそのストレージ要件を減少させるので価値のあるものです。粒度を粗くすることで、クエリ実行時に必要な計算リソースも削減できます。ダウンサンプリングを行うもう1つの重要な理由は、分析者の視点から見ると、時系列中の多数の記録が冗長である可能性があることです。例えば、センサーが1秒に1回新しい値を発するが、この測定値が60秒の間隔でほとんど変化しない場合、データを分単位にロールアップして分析することができます。
ダウンサンプリングが必要なもう一つのケースは、2つの異なるデータセットを1つのデータとして分析する必要があるが、それらのデータセットの時間粒度が異なる場合です。例えば、工場のセンサーAは15秒ごとにデータを収集しますが、センサーBは30秒ごとに関連データを収集します。この場合、記録を1分のバケットに集計するのが良い解決策かもしれません。IDs各データセットの次元はそのまま保持されますが、数値測定値は共通の時間間隔で合計または平均されます。
ダウンサンプリングの例¶
TIME_SLICE 関数を使用すると、テーブルに格納されているデータセットをダウンサンプリングできます。この関数は、固定幅の「バケット」の開始時刻と終了時刻を計算し、SUMやAVGなどの標準的な集計関数を使用して、個々の記録をグループ化してまとめることができます。
同様に、 DATE_TRUNC 関数は、一連の日付やタイムスタンプの値の一部を切り捨て、その粒度を小さくします。以下のセクションでは、各関数の例を示します。
TIME_SLICEによるダウンサンプリング¶
次の例では、 sensor_data_ts という名前のテーブルをダウンサンプリングします。このテーブルには、2つの工場センサーからの読み取り値が含まれ、530万行が含まれます。これらの測定値は1秒ごとに取り込まれるため、530万行はわずか1ヶ月分のデータに相当し、1センサーあたり250万行強になります。TIME_SLICE関数を使用すると、1分ごと、1時間ごと、1日ごとなどに1行まで集計できます。
この例を実行するには、まず sensor_data_ts テーブルを作成し、ロードします。sensor_data_tsテーブルの作成 をご参照ください。以下は表のデータの一部です。
このクエリで示されるように、このテーブルには、各デバイスについて1分間に60回の測定値が含まれています。
このダウンサンプリングクエリでは、TIME_SLICE関数は1分間のバケットを定義し、各バケットの開始時刻を返します。AVG関数は、デバイスごとにバケットごとの平均温度を計算します。COUNT (*) 関数は、各時間バケットにいくつの行があるかを示すためのものです。
vibration、 motor_rpm 列は含まれませんが、 temperature 列と同じ方法で集計するか、別の集計関数を使用して集計することができます。
重要
この例を自分で実行した場合、 sensor_data_ts テーブルにランダムに生成された値がロードされるため、出力は正確には一致しません。
TIME_SLICE関数を使用すると、分析用に小さな集計表を作成でき、異なるレベル(時間、日、週など)でダウンサンプリングプロセスを適用できます。
DATE_TRUNCによるダウンサンプリング¶
次の例は、 Tasty Bytesサンプルデータベース の raw.pos スキーマの order_header というテーブルからデータを選択します。このテーブルには2億4800万行が含まれています。
order_header テーブルには、 order_ts という TIMESTAMP 列があります。このクエリは、DATE_TRUNC関数の第2引数としてこの列を使用することで、集計された時系列を作成します。最初の引数は、 day 間隔を指定します。つまり、時間/分/秒の粒度を持つ個々の記録が日ごとにロールアップされます。
このクエリは、 truck_id と location_id の2つの次元で記録をグループ化しています。avg_amount 列は、記録された営業日ごとの、フードトラック1台あたりの、1ロケーションあたりの平均注文単価を返します。
このクエリでは、2022年1月1日の最初の25行に限定しています。この日付フィルタと LIMIT 句を削除すると、クエリは元の2億4800万行を約50万行にダウンサンプリングします。
ローリング計算にウィンドウ集約を使用する¶
ウィンドウ集計関数を使用して、メトリックの経時変化を観察することで、時系列の傾向を分析することができます。ウィンドウ集計は、より大きなデータセットの定義されたサブセット(「ウィンドウ」)内のデータを分析するのに便利です。データセットの各行について、現在の行の前後または周辺の行のグループを考慮したローリング計算(移動平均や合計など)を行うことができます。この種の分析は、データセット全体を要約する通常の集計とは対照的です。
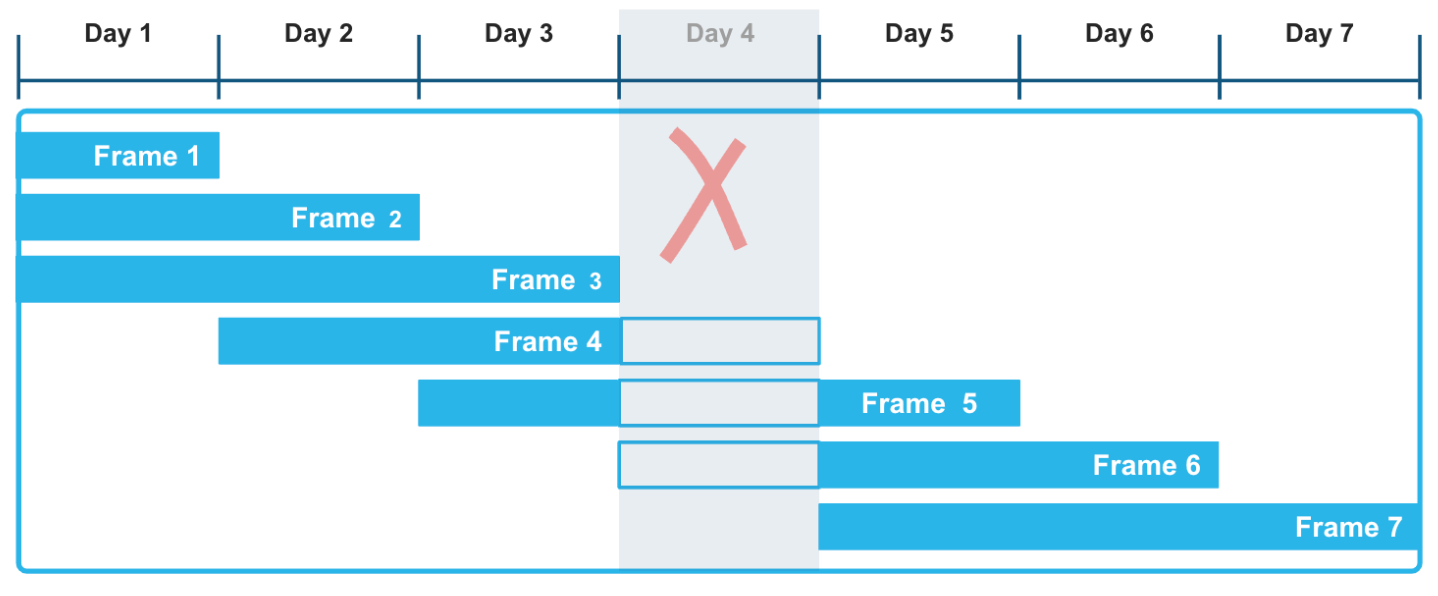
明示的なオフセットを持つ範囲ベースのウィンドウフレームを使用することにより、これらのローリング集計を計算するために非常に柔軟なアプローチを適用することができます。RANGE BETWEEN ウィンドウフレームは、タイムスタンプか数値のどちらかで並べられ、時系列データで発生する可能性のあるギャップによって中断されることはありません。例えば、次の図では、 Day 4 のデータが一連の記録で欠落していても、3日間の移動ウィンドウにおける集計関数の計算には影響しません。特にフレーム3、4、5は、 Day 4 のデータが未知であることを考慮に入れて、正しく計算されています。
次の例では、さまざまな都市や郡の毎時の降水量を記録した気象データの移動和を計算しています。この種のクエリを実行することで、センサーやその他の IoT デバイスなど、さまざまな時系列データセットの傾向を評価することができます。特に、これらのデータセットにギャップがあることが分かっている、または予想される場合です。
ウィンドウ関数は、現在の降水量の読み取り値と、 現在の読み取り値より前の指定された時間間隔内にあるすべての読み取り値をフレームに含めます。 ローリング計算は、正確な行 数 ではなく、この柔軟で論理的な行の 範囲 に基づいています。各都市の最初の行は、 precip と moving_sum_precip の値が一致しています。その後、フレーム内の後続の行ごとに合計が再計算されます。生の値は大きく変動しますが、移動和には強い平滑化効果があります。
この例を実行するには、まず以下の指示に従ってください。heavy_weatherテーブルの作成とロード この非常に小さな表は、1時間ごとの散発的な気象観測を含み、欠落した日を含む多くのギャップがあります。このクエリは、 start_time 列で並べられた降水量の値の移動和を返します。ウィンドウフレームは、現在の行の12時間前から現在の行までの範囲を定義します。したがって、フレームは現在の行と、現在の行の ORDER BY タイムスタンプより12時間前までのタイムスタンプを持つ行のみで構成されます。
Big Bear Cityの3つの moving_sum_precip 値は次のように計算されます。
0.42 = 0.42(前行なし)
0.42 + 0.09 = 0.51(最初の2行は12時間ウィンドウ内)
0.07 = 0.07(12時間ウィンドウ以内の前行なし)
例えば、South Lake Tahoeの行にはこのような計算が含まれています。
0.56 + 0.38 + 0.28 + 0.80 = 2.02(2024年12月23日の4行はすべて12時間以内)
0.80 + 0.17 = 0.97(1つ前の行は12時間ウィンドウ内)
LEAD、 LAG ランキング関数など、その他のウィンドウ関数も時系列分析でよく使われます。現在のデータポイントから相対的に、時系列の次のデータポイントを見つけるには、LEADウィンドウ関数を使用し、前のデータポイントを見つけるには、LAG関数を使用します。
Snowsightでクエリ結果を視覚化する¶
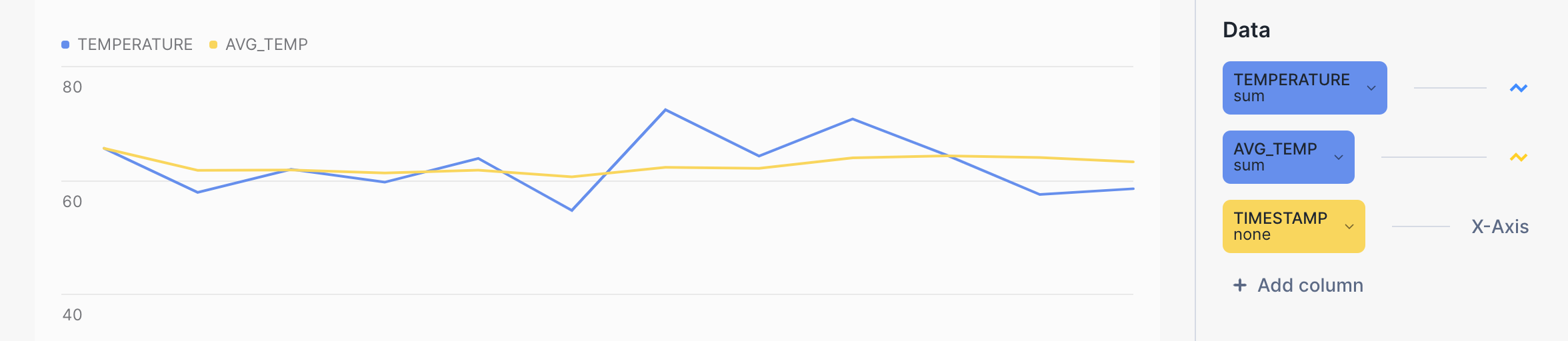
Snowsight を使って集計クエリの結果を視覚化し、スライディングウィンドウフレームを使った計算のスムージング効果をより実感することができます。クエリワークシートで、 Results の横にある Chart ボタンをクリックします。
例えば、次の棒グラフの黄色い線は、生の気温の青い線に対して、平均気温のはるかに滑らかな傾向を示しています。クエリそのものは次のようになります。
MIN_BYおよびMAX_BY集計関数の使用¶
同じ行の別の列の最小値または最大値に基づいて、ある列を選択する機能は、時系列データを扱う SQL 開発者にとって一般的な要件です。MIN_BY と MAX_BY は、データがタイムスタンプなどの他の列でソートされている場合に、テーブルの開始値と終了値(または最高値と最低値、最初の値と最後の値)を返す便利な関数です。
最初の例は、単純にテーブル全体の最後の(最新の) precip 値を見つけます。MAX_BY 関数は、すべての行を start_time の値でソートし、次に「最大」開始時刻の precip の値を返します。
以下の例で使用するテーブルを作成し、ロードするには、 heavy_weatherテーブルの作成 をご参照ください。
このクエリを実行することで、この結果を確認することができます。
GROUPBY句を追加して、このデータについてより興味深い質問をすることができます。例えば、次のクエリは、カリフォルニア州の各都市で観測された最後の降水量を precip の値(多い順から少ない順)で検索します。結果は city でグループ化され、各都市の最後の precip の値が返されます。
前回観測されたアルタ市の precip の値は 0.89 で、前回観測されたサウスレイクタホ市、ビッグベアシティ市、モンタギュー市、レベック市の precip の値は4か所とも 0.07 です。(クエリでは、これらの観測がいつ行われたかはわかりません。)
MIN_BY 関数を使用すると、「正反対」の結果セット(最も古い precip の記録と最新の記録)を返すことができます。
時系列データの結合¶
時系列データを含むテーブルを結合するには、 ASOF JOIN 構文を使用します。ASOF JOIN クエリは複雑な SQL や他の型の結合、ウィンドウ関数を使用することでエミュレートできますが、 ASOF JOIN 構文を使用すると、これらのクエリの作成が簡単になります(最適化もされます)。
ASOFジョインの一般的な用途は、金融取引データの分析です。たとえば、取引コスト分析では、株式の購入を決定した時点での気配値と、取引が実行および記録された時点で実際に支払われた価格との差を測定する「スリッページ」計算が必要です。ASOF JOIN はこの種の分析を迅速化できます。この結合方法の主な機能は、ある時系列を別の時系列と比較して分析することであるため、ASOF JOINは、本質的に履歴的なデータセットを分析するのに役立つ可能性があります。これらのユースケースの多くでは、異なるデバイスから読み取られたタイムスタンプが完全に同じではない場合に、データを関連付けるためにASOF JOINが使用できます。
分析が必要な時系列データが2つのテーブルに存在し、各テーブルの各行にタイムスタンプがあることが前提となります。このタイムスタンプは、記録されたイベントの正確な「その時点」の日付と時刻を表します。最初(または左側)のテーブルの各行に対して、結合では、指定した比較演算子を持つ「一致条件」を使用して、タイムスタンプ値が次のいずれかである2番目(または右側)のテーブル内の単一の行を検索します。
左側のテーブルのタイムスタンプ値以下。
左側のテーブルのタイムスタンプ値以上。
左側のテーブルのタイムスタンプ値より小さい。
左側のテーブルのタイムスタンプ値より大きい。
右側の条件に該当する行はもっとも近い一致であり、指定された比較演算子に応じて、時間的に等しい、時間的に早い、または時間的に遅い可能性があります。
ASOF JOIN の結果のカーディナリティは常に左側のテーブルのカーディナリティと等しくなります。左側のテーブルに4,000万行が含まれている場合、 ASOF JOIN は4,000万行を返します。したがって、左側のテーブルは「保存」テーブル、右側のテーブルは「参照」テーブルと考えることができます。
2つのテーブルを最も近い一致で結合(アライメント)¶
たとえば、財務アプリケーションで、 quotes という名前のテーブルと trades という名前のテーブルがあるとします。1つのテーブルには株式購入の入札履歴が記録され、もう1つのテーブルには実際の取引履歴が記録されます。株式購入の入札は取引の前に行われます(記録された時間の粒度に応じて、「同時に」行われる場合もあります)。どちらのテーブルにもタイムスタンプがあり、比較対象として使用するその他の列も両方にあります。単純なASOF JOINクエリは、各取引の前にもっとも近い気配値(時間的に)を返します。言い換えると、クエリは次のように尋ねます。「取引を行った時点での株価はいくらでしたか」
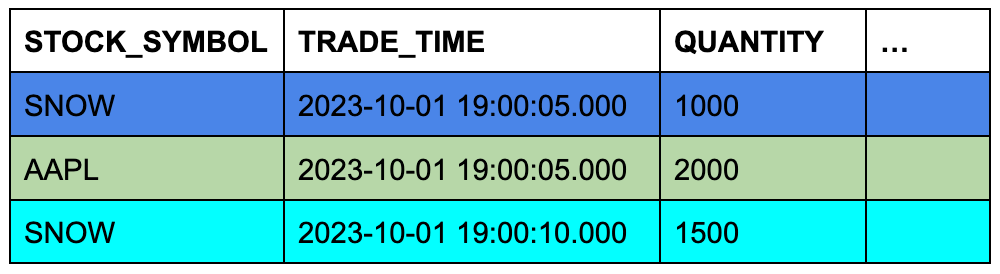
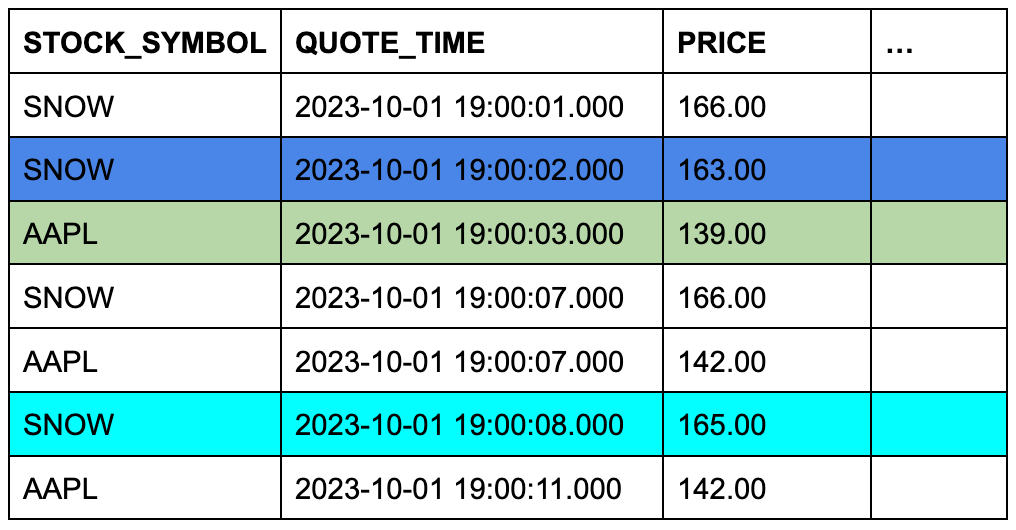
trades テーブルには3つの行が含まれ、 quotes テーブルには7つの行が含まれるとします。セルの背景色は、一致する銘柄シンボルで行を結合し、そのタイムスタンプ列を比較したときに、 quotes のどの3行が ASOF JOIN の対象となるかを示しています。
TRADES テーブル(左側または「保存」テーブル)
QUOTESテーブル(右側または「参照」テーブル)
この概念的な例を具体的なクエリ(ASOFJOIN)にするのは簡単です。
ON 条件は、一致した行を株式シンボルでグループ化します。
この例を実行するには、以下のようにテーブルを作成し、読み込みます。
ASOF JOIN クエリの例については、 例 をご参照ください。
時系列データのギャップを埋める¶
時系列分析では、多くの場合、データにすべての間隔の記録と一貫性のある粒度が必要ですが、実際のデータは不規則な間隔で到着するか、ギャップが含まれることがよくあります。たとえば、既に主に1時間ごとのデータセットがあるが、ダウンストリーム分析に合わせて30分のエントリを生成する必要がある場合や、既に一貫した解像度があるが、系列にギャップがある場合などです。Snowflakeのギャップ埋め機能は、時系列データに一定の間隔を適用し、ギャップを埋める効率的な方法を提供します。
たとえば、2025年3月15日のカリフォルニア州にある2つの都市の気象観測を行っている次の8つの記録について考えます。
これらの記録はやや一貫性のあるレベルの粒度(日、時間、分)を持っていますが、行間の間隔は一貫性がなく、1分から15分の間で変動しています。5分間隔でデータを収集することが目標である場合、いくつかの行が欠落しています。
RESAMPLE 句の使用¶
特定の時間間隔に「アップサンプリング」することで、行のセットの粒度を変更し、一貫性を向上させることができます。このような変更を行うには、SELECTステートメントのFROM句で定義する:ref:`label-resample_clause`句を使用します。再サンプリングされたデータセットの結果は、既存の入力行のすべてを保持し、時系列のギャップを埋める値を持つ新しい行をいくつか生成する、*より大きな*データセットになります。(RESAMPLE句を使用して、行をより小さく、より粒度の細かい結果セットに「ダウンサンプリング」することもできることに注意してください。)
定義上、時系列には常に日付または時刻を表す、日付、タイムスタンプ、または数値のシーケンスが含まれる列があります。ソーステーブルのこのような列には、再サンプリングが機能し、必要な粒度を``5 minutes``、30 minutes、``1 hour``などのINTERVAL値で指定する必要があります。
通常、間隔ごとに1つの新しいタイムスタンプを生成するだけではなく、特定のディメンションに時系列行を作成するパーティションも定義します。
RESAMPLEクエリの構造は次のようになります。
生成された行の列は、USINGおよびPARTITION BY句で指定された列を除き、NULLに設定されます。指定された日付、時刻、または数値列と、パーティショニング列には意味のある値が生成されます。
注釈
特定の値(たとえば、特定のデバイス ID または場所)で再サンプリングされたデータをフィルタリングする場合、 PARTITION BY 句にそれらの列を含めます。これにより、生成される行には NULL 値ではなく、これらの列の実際の値が含まれるようになります。PARTITION BY 句にない列の WHERE 句でフィルタリングした場合、 WHERE 句は NULL 値を含むため、それらの列の生成されたすべての行を除外します。
前述の8つの記録を使用する簡単な例を実行するには、次のテーブルを作成してロードすることから始めます。
次に、``5 minutes``の間隔を使用して、そのテーブルからアップサンプルされた行を選択します。
このクエリは、元の8つの行を保持し、09:45、10:00、10:05``に3つの新しい行を生成し、3つの時間間隔のギャップを埋めます。NULL値が``temperature、city、``county``列に挿入されます。
時系列の開始点は、入力データセットの最も早いタイムスタンプ(2025-03-15 09:49:00.000)から5分以内であるため、``2025-03-15 09:45:00.000``です。
一定の間隔で発生しない行を削除する場合(この場合は``09:49``および``10:18``)、:ref:`label-resample_example_with_filter`をご参照ください。
次に、クエリにPARTITION BY句を追加します。
パーティション化された結果は、2つの点で異なります。
7つの行、合計15の行が生成されます。パーティションごとに5分間隔で行が存在するようになりました。
パーティション列は、``city``および``county``値を正しく生成しました。生成された行のうちNULLを持つ唯一の列は、``temperature``です。
また、RESAMPLE構文にMETADATA_COLUMNSパラメーターを指定して、結果に次の列を追加することもできます。
``is_generated``メタデータ列は、RESAMPLE操作とすでに存在していた行によって生成された行を識別します。
``bucket_start``メタデータ列は、現在のバケットまたはRESAMPLE操作で生成された間隔の開始を示す値を返します。この列を使用して、再サンプリング後に特定の行がどの間隔に属するかを識別することができます。また、再サンプリングされたデータに対して集計クエリを実行するために使用できます。BUCKET_START() を使用してリサンプリングされた行を集計する RESAMPLE の例 をご参照ください。
完全なRESAMPLE構文の詳細については、:ref:`label-resample_clause`をご参照ください。
RESAMPLEクエリの結果を保存するには、データを選択し新しいテーブルに挿入する:ref:`CTASステートメント<label-CTAS_syntax>`を使用してください。
時系列への値の補間または「ギャップ埋め」¶
RESAMPLE構文と補間関数を独立して使うことはできますが、これらは、:ref:`単一クエリ<label-resample_in_one_op>`のスコープの時系列データのギャップを埋めるために一緒に使用されるのが最も一般的です。データセットを再サンプリングすると、補間関数を呼び出して、新しく生成された行の関心のある他の列を更新できます。補間プロセスは、数値測定値などの以前はNULLであった列を更新し、前後の行にある値に基づいて意味のある値を与えます。
INTERPOLATE_FFILL、INTERPOLATE_BFILL、INTERPOLATE_LINEARウィンドウ関数を呼び出すことで値を補間できます。たとえば、INTERPOLATE_FFILL関数は、対象の列の時系列における以前(最後の)値を検索します。
最初の行は``ffill_temp``列にNULLを返します。INTERPOLATE_FFILL関数が使用する前の行がないためです。
これらのウィンドウ関数の詳細については、:ref:`label-interpolation_functions`をご参照ください。
1つの操作によるアップサンプリング、ギャップ埋め、結果の格納¶
データセットのギャップを埋めるプロセス全体を簡素化するために、CTAS操作を使用することで単一のクエリ内でデータをアップサンプリングし、値を補間し、結果を保存することができます。たとえば、次のCTASステートメントは、測定値をアップサンプリングされたデータセットに補間する、新しいテーブルを作成します。
注釈
INTERPOLATE 関数と再サンプリングを使用した場合、ウィンドウ関数の OVER ( PARTITION BY )句で指定する列は通常、 RESAMPLE ( PARTITION BY )句の列と一致します。このアプローチにより、再サンプリング中に作成されたのと同じ論理パーティション内で補間が行われます。前述の例では、再サンプリングは city および county によってパーティション化され、 INTERPOLATE 関数は city のみでパーティション化されます。この例は、補間がより粗い粒度で行われるため機能しますが、常にパーティショニング戦略がデータ要件と一致していることを確認する必要があります。
ASOF JOINによるギャップ埋め¶
注釈
ギャップ埋めと補間で推奨されるアプローチを使用するには、:ref:`label-gap_filling_with_resample_interpolate`をご参照ください。RESAMPLEコンストラクトおよびINTERPOLATE関数はプレビュー機能であり、次のASOF JOINギャップ埋めのアプローチは、潜在的な回避策としてのみ含まれています。
ASOF JOINは、時間ベースの列の非正確な一致を発見することによって2つのテーブルのデータを整列させることに加え、生のデータテーブルに特定の日付やタイムスタンプの行がない場合に、時系列のギャップを埋めるのに便利です。たとえば、機器の故障や停電のためにセンサーの読み取り値がスキップされ、行が欠落している場合は、ASOF JOINを使用して、生成された時系列からテーブルに値を補間することができます。欠落した行は、欠落している測定値の最後の既知の値で埋められます。この値は「前回の観察繰越」(LOCF)とも呼ばれます。ASOFJOINクエリは、時系列で連続した行の完全なセットを返します。
補間にASOFJOINを使用するには、以下の手順に従います。
簡単なクエリを実行して、テーブルのギャップを識別子します。
必要な期間について、適切な粒度で完全な時系列を作成します。例えば、時系列は特定の年の単純な日付の列かもしれませんし、ある日数の1秒あたりのタイムスタンプのもっと細かい列かもしれません。値のリストを生成するには、SQLまたは表計算アプリケーションを使用できます。
時系列には、後でASOFJOINON条件で指定する、各行に意味のあるIDまたはディメンションも必要です。
欠落している行に値を補間するASOFJOINクエリを記述します。生成された時系列は保存テーブルとなり、生データテーブルは参照テーブルとなります。
次の例では、 sensor_data_ts テーブルが必要です。まだ作成およびロードしていない場合は、 sensor_data_tsテーブルの作成 をご参照ください。ギャップを埋める作業の必要性をシミュレートするために、以下のようにテーブルからいくつかの行を削除します。
その結果、3月7日の DEVICE2 (1:16~1:20)の5行が欠落した表が出来上がりました。
では、以下の手順に従って、ギャップを埋める練習をしてください。
注釈
この例を自分で実行した場合、 sensor_data_ts テーブルにランダムに生成された値がロードされるため、出力は正確には一致しません。
ステップ1:テーブルにギャップがあることを確認します。¶
以下のクエリを実行して、ギャップを識別します。
このクエリは、 DEVICE2 に対して2つの行を返します。ギャップ前の最後の行とギャップ後の最初の行です。
ステップ2:既知のギャップをカバーする完全な時系列の生成¶
sensor_data_ts テーブルのギャップに対して細かい粒度(1秒につき1行)で時系列を生成するには、生成されたタイムスタンプを含む以下のテーブルを作成します。
この SQL ステートメントでは、 5 はギャップをカバーするために必要な秒数です。デバイスの ID 値(DEVICE2)は、生成された行に含まれることに注意してください。
以下のクエリは、生成された5つの行を返します。
ステップ3:ASOFJOINを使って値を補間する¶
これで、 continuous_timestamps を sensor_data_ts に結合し、 DEVICE2 の欠損行の値を補間する、 ASOF JOIN クエリを実行できます。一致条件は、欠落している各行に対して時間的に最も近い行を見つけ、ON条件は、一致するデバイスIDsで補間が行われることを保証します。
この例で示されているように、 >= が一致条件に指定されている場合、欠落行に最も近い行は、 2024-03-07 00:01:16.000 のタイムスタンプを持つ行です。
この INSERT 文は、 ASOF JOIN 操作から5行を選択し、 sensor_data_ts テーブルに挿入します。
補間の結果を確認するには、 sensor_data_ts の表から、これらの5行と、その前後の2行を選択します。補間された5つの行は、 2024-03-07 00:01:15.000 の行で記録されたのと同じ値を、 temperature、 vibration、 motor_rpm の列で拾っていることに注意してください。補間は成功しました。
時系列データへのMLベースの関数の適用¶
ML関数でモデルをトレーニングして、時系列データの予測分析を行うことができます。
予測は、過去の時系列データを使って将来のデータを予測します。過去の日時における実際の観測値が記録された時系列が与えられた場合、MLモデルは、将来の日時における観測値がどうなるかを予測します。
異常値検出は、予想される範囲から逸脱したデータポイントである異常値を識別します。時系列の文脈では、外れ値とは、同じような時間間隔の他の測定値よりもはるかに大きいか小さい測定値のことです。異常値を見つけるために、ML関数は異常値をチェックするのと同じ期間の予測を作成し、次に予測結果を実際のデータと比較します。
Top Insightsは、データセットの最も重要なディメンションを見つけ、それらのディメンションからセグメントを構築し、それらのセグメントのどれがメトリックに影響を与えたかを検出します。
注釈
機械学習のためには、時系列のタイムスタンプは一定の時間間隔を表す必要があります。必要であれば、TIMESTAMP列に対してDATE_TRUNCまたはTIME_SLICE関数を使用して、予測モデルのトレーニング時に不規則性を取り除くことができます。
時系列における異常検出の例¶
次の例では、30行しかない表示を使って異常検知モデルを学習します。まずデータをテーブルに生成し、そのテーブルに表示を作成します。表示オプションは必須ではありません(テーブルを使用してモデルをトレーニングすることができます)が、表示オプションを使用することで、ソースデータを更新することなく、行数を変えてモデルを繰り返しトレーニングする柔軟性が得られます。
注釈
この例を自分で実行した場合、 sensor_data_30_rows テーブルにランダムに生成された値がロードされるため、出力は正確には一致しません。
次にモデルを作成します。
モデルが正常に構築されたら、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出して、指定されたテストデータセットの外れ値を検出します。テストデータのタイムスタンプは、トレーニングデータのタイムスタンプに時系列的に追随していなければなりませんが、トレーニングデータとテストデータの間にあまり大きな時間のずれがあってはなりません。例えば、1秒ごとのタイムスタンプがある場合、トレーニングデータより何百万秒も先のテストデータは使用しないでください。
この例では、3行しかない別のテーブルをテストデータとして使用しています。これらの行は、トレーニングデータのタイムスタンプに近いタイムスタンプを持っています。
異常検知コールが終了すると、以下のような出力が返されます。
TS と Y 列は、テストデータからタイムスタンプと温度値を返します。この非常に小さなテストケースで、この関数は異常(IS_ANOMALY=True)を発見しました。出力列の詳細については、 関数の説明 の「戻り値」セクションをご参照ください。
sensor_data_tsテーブルの作成¶
sensor_data_ts テーブルをクエリするこのセクションの例をテストしたい場合は、以下の SQL スクリプトを実行することで、このテーブルのコピーを作成し、ロードすることができます。このスクリプトは、UNIFORM、RANDOM、GENERATOR関数を呼び出すことによって、センサーの測定値の1ヶ月分の合成データを生成します。したがって、テーブルのコピーが同一の結果を返すわけではありません。測定値は同じ範囲になりますが、同じ値にはなりません。
heavy_weatherテーブルの作成¶
以下のスクリプトは、 MAX_BY 関数の例で使用される heavy_weather テーブルを作成し、ロードします。この表には、2021年最後の週のカリフォルニア州各都市の降雪降水量の記録が55行含まれています。