여러 계정에 걸쳐 데이터베이스 및 계정 오브젝트 복제하기¶
이 항목에서는 같은 조직의 Snowflake 계정 전체에 걸쳐 계정 오브젝트 및 데이터를 복제하고 오브젝트와 데이터를 동기화된 상태로 유지하는 데 필요한 단계를 설명합니다. 계정 복제는 다양한 리전 의 Snowflake 계정과 클라우드 플랫폼 에서 발생할 수 있습니다.
참고
계정을 Business Critical Edition 이상으로 업그레이드하는 경우 장애 조치 기능을 사용할 수 있게 되기까지 최대 12시간이 걸릴 수 있습니다.
복제 및 장애 조치/장애 복구를 위한 리전 지원¶
고객은 리전 그룹 내의 모든 리전에서 복제할 수 있습니다. 다양한 리전 그룹 에서 리전 간에(예: Snowflake 상업 리전에서 Snowflake 정부 리전으로) 복제하려면 Snowflake 지원 에 문의하여 액세스를 활성화하십시오.
데이터베이스 복제에서 그룹 기반 복제로 전환하기¶
ALTER DATABASE 항목을 사용하여 복제가 활성화된 데이터베이스는 복제 또는 장애 조치 그룹에 추가되기 전에 복제를 비활성화해야 합니다.
참고
ACCOUNTADMIN 역할을 사용하여 이 섹션의 SQL 문을 실행하십시오.
1단계. 복제가 활성화된 데이터베이스에 대한 복제 비활성화하기¶
복제 또는 장애 조치 그룹에 추가하기 위해 기본 데이터베이스와 연결된 보조 데이터베이스에 대한 복제를 비활성화하는 SYSTEM$DISABLE_DATABASE_REPLICATION 함수를 실행합니다.
기본 데이터베이스가 있는 원본 계정에서 다음 SQL 문을 실행합니다.
2단계. 기본 장애 조치 그룹에 데이터베이스를 추가하고 보조 장애 조치 그룹 생성하기¶
데이터베이스에 대한 복제를 성공적으로 비활성화했으면, 원본 계정의 장애 조치 그룹에 기본 데이터베이스를 추가할 수 있습니다.
그런 다음 대상 계정에 보조 장애 조치 그룹을 생성합니다. 보조 장애 조치 그룹이 대상 계정에서 새로 고쳐지면 이전의 보조 데이터베이스가 자동으로 보조 장애 조치 그룹의 구성원으로 추가되고, 기본 데이터베이스의 변경 사항으로 새로 고쳐집니다.
기본 및 보조 장애 조치 그룹 생성에 대한 자세한 내용은 워크플로 섹션을 참조하십시오.
참고
이전에 복제된 데이터베이스를 복제 또는 장애 조치 그룹에 추가하면 Snowflake는 해당 데이터베이스에 대해 이미 복제된 데이터를 다시 복제하지 않습니다. 그룹을 새로 고칠 때 마지막 새로 고침 이후의 변경 사항만 복제됩니다.
워크플로¶
다음 SQL 문은 계정 및 데이터베이스 오브젝트 복제를 활성화하고 오브젝트를 새로 고치는 워크플로를 보여줍니다. 각 단계는 아래에서 자세히 설명합니다.
참고
다음 예제에서는 원본 계정과 대상 계정에 대해 복제를 활성화해야 합니다. 자세한 내용은 전제 조건: 조직의 계정에 대한 복제 활성화 섹션을 참조하십시오.
예¶
선호하는 Snowflake 클라이언트에서 다음 SQL 문을 실행하여 계정 및 데이터베이스 오브젝트 복제 및 장애 조치를 활성화하고 오브젝트를 새로 고칩니다.
원본 계정에서 실행됨¶
역할을 생성하고 CREATE FAILOVER GROUP 권한을 부여합니다. 이 단계는 선택 사항 입니다.
원본 계정에 장애 조치 그룹을 생성하고 특정 대상 계정에 복제를 활성화합니다.
참고
이전에 ALTER DATABASE 항목을 사용하여 데이터베이스 복제 및 장애 조치에 대해 활성화된 복제 또는 장애 조치 그룹에 추가할 데이터베이스가 있는 경우, 그룹에 추가하기 전에 이 항목의 데이터베이스 복제에서 그룹 기반 복제로 전환하기 지침을 따르십시오.
장애 조치 그룹에 데이터베이스를 추가하려면 활성 역할에 데이터베이스에 대한 MONITOR 권한이 있어야 합니다. 데이터베이스 권한에 대한 자세한 내용은 별도 항목의 데이터베이스 권한 섹션을 참조하십시오.
대상 계정에서 실행됨¶
대상 계정에서 역할을 생성하고 CREATE FAILOVER GROUP 권한을 부여합니다. 이 단계는 선택 사항 입니다.
대상 계정에 장애 조치 그룹을 원본 계정에 있는 장애 조치 그룹의 복제본으로서 생성합니다.
참고
대상 계정에 소스 계정에 없는 계정 오브젝트(예: 사용자 또는 역할)가 있는 경우 보조 그룹을 만들기 전에 사용자 및 역할의 초기 복제 섹션을 참조하십시오.
보조 장애 조치 그룹을 수동으로 새로 고칩니다. 이것은 선택적 단계입니다. 기본 장애 조치 그룹이 복제 일정으로 생성된 경우 보조 장애 조치 그룹이 생성될 때 보조 장애 조치 그룹의 초기 새로 고침이 자동으로 실행됩니다.
장애 조치에 대한 REPLICATE 권한이 있는 역할을 만듭니다. 이 단계는 선택 사항 입니다.
장애 조치 그룹에 대한 OWNERSHIP 권한이 있는 역할을 사용하여 대상 계정에서 다음을 실행합니다.
REPLICATE 권한이 있는 역할을 사용하여 다음 새로 고침 문을 실행합니다.
장애 조치에 대한 FAILOVER 권한이 있는 역할을 만듭니다. 이 단계는 선택 사항 입니다.
장애 조치 그룹에 대한 OWNERSHIP 권한이 있는 역할을 사용하여 대상 계정에서 다음을 실행합니다.
계정 오브젝트 및 데이터베이스 복제하기¶
이 섹션의 지침은 복제를 위해 계정을 준비하고, 원본 계정에서 대상 계정으로 특정 오브젝트의 복제를 활성화하고, 대상 계정의 오브젝트를 동기화하는 방법을 설명합니다.
중요
대상 계정에는 기본적으로 활성화된 Tri-Secret Secure 또는 Snowflake 서비스에 대한 비공개 연결(예: AWS PrivateLink)이 없습니다. 규정 준수, 보안 또는 기타 목적을 위해 Snowflake 서비스에 대한 Tri-Secret Secure 또는 비공개 연결이 필요한 경우 대상 계정에서 해당 기능을 구성하고 활성화하는 것은 사용자의 책임입니다.
전제 조건: 조직의 계정에 대한 복제 활성화¶
조직 관리자는 소스 및 대상 계정에 대해 복제를 사용 설정해야 합니다.
계정에 복제를 사용하도록 설정하려면 조직 관리자 가 SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER 함수를 사용하여 ENABLE_ACCOUNT_DATABASE_REPLICATION 매개 변수를 true 로 설정합니다.
조직 관리자로 조직의 각 소스 및 대상 계정에 대해 복제를 사용 설정합니다.
SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER 함수는 레거시 계정 로케이터 식별자를 지원하지만, 조직에 (다양한 리전에서) 같은 로케이터를 공유하는 계정이 여러 개 있을 때 예기치 않은 결과를 초래합니다.
1단계: 원본 계정에서 CREATE FAILOVER GROUP 권한이 있는 역할 만들기 — 선택 사항¶
역할을 생성하고 CREATE FAILOVER GROUP 권한을 부여합니다. 이 단계는 선택 사항입니다. 이 역할을 이미 만든 경우 3단계: 원본 계정에서 기본 장애 조치 그룹 생성하기 항목으로 건너뛰십시오.
2단계: 복제 및 그룹 멤버십이 활성화된 계정 식별자 확인¶
기본 장애 조치 그룹을 만들기 전에 복제에 사용할 수 있는 계정과 기존 장애 조치 및 복제 그룹을 식별합니다.
복제가 활성화된 모든 계정 보기¶
복제가 활성화된 조직의 계정 목록을 검색하려면 SHOW REPLICATION ACCOUNTS 항목을 사용하십시오.
ACCOUNTADMIN 역할을 사용하여 다음 SQL 문을 실행합니다.
반환 결과:
리전 IDs 전체 목록을 살펴봅니다.
장애 조치 및 복제 그룹 구성원 보기¶
계정, 데이터베이스, 공유 오브젝트에는 그룹 구성원 자격에 대한 제약 이 있습니다. 새 그룹을 생성하거나 기존 그룹에 오브젝트를 추가하기 전에 기존 장애 조치 그룹 및 각 그룹의 오브젝트 목록을 검토할 수 있습니다.
참고
계정 관리자(ACCOUNTADMIN 역할이 있는 사용자) 또는 그룹 소유자(그룹에 대한 OWNERSHIP 권한이 있는 역할)만 이 섹션의 SQL 문을 실행할 수 있습니다.
현재 계정에 연결된 모든 장애 조치 그룹, 그리고 각 그룹의 오브젝트 유형을 봅니다.
장애 조치 그룹 myfg 의 모든 데이터베이스 보기:
장애 조치 그룹 myfg 의 모든 공유 보기:
3단계: 원본 계정에서 기본 장애 조치 그룹 생성하기¶
기본 장애 조치 그룹을 생성하고 현재(원본) 계정에서 동일 조직의 하나 이상의 대상 계정으로 특정 오브젝트의 복제 및 장애 조치를 활성화합니다.
Snowsight 또는 SQL 을 사용하여 복제 또는 장애 조치 그룹을 만들 수 있습니다.
참고
이전에 ALTER DATABASE 항목을 사용하여 데이터베이스 복제에 대해 활성화된 복제 또는 장애 조치 그룹에 추가할 데이터베이스가 있는 경우, 그룹에 추가하기 전에 이 항목의 데이터베이스 복제에서 그룹 기반 복제로 전환하기 지침을 따르십시오.
Snowsight를 사용하여 복제 또는 장애 조치 그룹 만들기¶
참고
계정 관리자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 생성할 수 있습니다(복제 구성에 Snowsight 사용 시 제한 사항 참조).
대상 계정에 ACCOUNTADMIN 역할을 가진 사용자로 로그인한 상태여야 합니다. 그렇지 않으면 로그인하라는 메시지가 표시됩니다.
원본 계정과 대상 계정 모두 동일한 연결 유형(공용 인터넷)을 사용해야 합니다. 그렇지 않으면 대상 계정에 로그인할 수 없습니다.
새 복제 또는 장애 조치 그룹을 생성하려면 다음 단계를 완료하십시오.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Admin » Accounts 를 선택합니다.
Replication 을 선택한 다음 Groups 탭에서 다음 작업 중 하나를 완료합니다.
Business Critical Edition(또는 그 이상) 계정의 경우 다음 작업 중 하나를 완료합니다.
복제 그룹이나 연결이 없는 경우 Get started 를 선택하여 복제 그룹과 연결을 구성합니다. Setup business continuity 마법사가 나타납니다.
연결을 구성하지 않고 복제 그룹을 구성하려면 + Group 을 선택합니다. Create a group 마법사가 나타납니다.
Standard Edition 및 Enterprise Edition 계정의 경우 다음 작업 중 하나를 완료합니다.
복제 그룹이나 연결이 없는 경우 Get started 를 선택하여 복제 그룹을 구성합니다. Setup replication 마법사가 나타납니다.
복제 그룹이 1개 이상 있는 경우 + Group 을 선택하여 복제 그룹을 구성합니다. Create a group 마법사가 나타납니다.
Select a target account 페이지에서 대상 계정을 선택하고 로그인한 다음 Next 을 선택합니다.
Create a group 페이지의 Group name 상자에 다음 요구 사항을 충족하는 그룹 이름을 입력합니다.
알파벳 문자로 시작해야 하며 식별자 문자열을 큰따옴표로 묶지 않는 한 공백이나 특수 문자를 포함할 수 없습니다(예: “내 오브젝트”). 큰따옴표로 묶인 식별자도 대/소문자를 구분합니다.
자세한 내용은 식별자 요구 사항 섹션을 참조하십시오.
계정의 장애 조치 및 복제 그룹 전체에서 고유해야 합니다.
Edit objects 를 선택하여 그룹에 공유 및 계정 오브젝트를 추가합니다.
참고
계정 오브젝트는 하나의 복제 또는 장애 조치 그룹에만 추가할 수 있습니다. 계정 오브젝트가 포함된 복제 또는 장애 조치 그룹이 계정에 이미 존재하는 경우 해당 오브젝트를 선택할 수 없습니다.
Select databases 를 선택하여 그룹에 데이터베이스 오브젝트를 추가합니다.
Replication frequency 를 선택합니다.
계정이 Business Critical Edition 이상인 경우 기본적으로 장애 조치 그룹이 생성됩니다. 대신 복제 그룹을 생성하도록 선택할 수 있습니다. 복제 그룹을 생성하려면 Advanced options 를 선택한 다음 Enable failover 를 선택 취소하십시오.
다음 작업 중 하나를 완료합니다.
Business Critical Edition(또는 그 이상) 계정의 경우 Next 을 선택합니다.
Standard Edition 및 Enterprise Edition 계정의 경우 Start replication 을 선택하여 복제 그룹을 생성합니다.
Business Critical Edition(또는 그 이상) 계정의 경우 Create connection 페이지의 Connection name 상자에 연결 이름을 입력한 다음 Start replication 을 선택합니다.
복제 그룹 생성에 실패한 경우 일반적인 오류와 해결 방법은 Snowsight를 사용한 복제 그룹 생성 및 편집 관련 문제 해결하기 섹션을 참조하십시오.
SQL을 사용하여 장애 조치 그룹 만들기¶
원본 계정에 지정된 계정 및 데이터베이스 오브젝트의 장애 조치 그룹을 생성하고 대상 계정 목록에 대한 복제 및 장애 조치를 활성화합니다. 구문은 CREATE FAILOVER GROUP 섹션을 참조하십시오.
예를 들어 원본 계정에서 동일 조직의 myaccount2 계정으로 사용자, 역할, 웨어하우스, 리소스 모니터, db1 및 db2 데이터베이스를 복제할 수 있습니다. 10분마다 자동으로 myaccount2 를 새로 고치도록 복제 일정을 설정합니다.
원본 계정에서 다음 문을 실행합니다.
4단계: 대상 계정에서 CREATE FAILOVER GROUP 권한으로 역할 만들기 — 선택 사항¶
대상 계정에서 역할을 생성하고 CREATE FAILOVER GROUP 권한을 부여합니다. 이 단계는 선택 사항입니다. 이 역할을 이미 만든 경우 5단계: 대상 계정에 보조 장애 조치 그룹 생성하기 항목으로 건너뛰십시오.
5단계: 대상 계정에 보조 장애 조치 그룹 생성하기¶
참고
대상 계정에 소스 계정에 없는 계정 오브젝트(예: 사용자 또는 역할)가 있는 경우 보조 그룹을 만들기 전에 사용자 및 역할의 초기 복제 섹션을 참조하십시오.
원본 계정의 기본 장애 조치 그룹의 복제본으로서 대상 계정에 보조 장애 조치 그룹을 생성합니다.
이 항목의 3단계: 원본 계정에서 기본 장애 조치 그룹 생성하기 에서 복제를 활성화한 각 대상 계정에서 CREATE FAILOVER GROUP … AS REPLICA OF 문을 실행합니다.
각 대상 계정에서 실행됨:
6단계. 대상 계정의 보조 장애 조치 그룹을 수동으로 새로 고침 — 선택 사항¶
대상 계정의 오브젝트를 수동으로 새로 고치려면 ALTER FAILOVER GROUP … REFRESH 명령을 실행합니다.
모범 사례로서 CREATE FAILOVER GROUP 또는 ALTER FAILOVER GROUP 항목을 사용하여 REPLICATION_SCHEDULE 매개 변수를 설정해 보조 새로 고침을 예약하는 것이 좋습니다.
참고
대상 계정에서 함수를 호출한 사용자가 원본 계정에서 삭제된 경우 새로 고침 작업이 실패합니다.
역할에 장애 조치 그룹에 대한 REPLICATE 권한 부여하기 — 선택 사항¶
대상 계정에서 보조 복제 또는 장애 조치 그룹을 새로 고치는 명령을 실행하려면 장애 조치 그룹에 대한 REPLICATE 권한이 있는 역할을 사용해야 합니다. REPLICATE 권한은 현재 복제되지 않으며 원본 계정 및 대상 계정 둘 다의 장애 조치(또는 복제) 그룹에 부여되어야 합니다.
그룹에 대한 OWNERSHIP 권한이 있는 역할을 사용하여 원본 계정에서 다음 문을 실행합니다.
그룹에 대한 OWNERSHIP 권한이 있는 역할을 사용하여 대상 계정에서 다음 문을 실행합니다.
수동으로 보조 장애 조치 그룹 새로 고치기¶
예를 들어 장애 조치 그룹 myfg 의 오브젝트를 새로 고치려면 대상 계정에서 다음 문을 실행합니다.
7단계. 역할에 장애 조치 그룹에 대한 FAILOVER 권한 부여 — 선택 사항¶
대상 계정에서 보조 복제 또는 장애 조치 그룹에서 장애 조치를 수행하는 명령을 실행하려면, 장애 조치 그룹에 대한 FAILOVER 권한 이 있는 역할을 사용해야 합니다. FAILOVER 권한은 현재 복제되지 않으며 각 소스 및 대상 계정에서 부여해야 합니다.
자세한 내용은 역할 및 권한 부여 복제 섹션을 참조하십시오.
예를 들어, 장애 조치 그룹 my_fg 의 역할 my_failover_role 에 FAILOVER 권한을 부여하려면 그룹에서 OWNERSHIP 권한이 있는 역할을 사용하여 대상 계정 에서 다음 문을 실행합니다
지정된 권한 세트로 사용자 지정 역할을 만드는 방법에 대한 지침은 사용자 지정 역할 만들기 섹션을 참조하십시오.
보안 오브젝트 에 대해 SQL 작업을 수행하기 위한 역할과 권한 부여에 대한 일반적인 정보는 액세스 제어의 개요 섹션을 참조하십시오.
장애 조치 그룹을 위한 스키마 수준 복제¶
장애 조치 그룹의 데이터베이스의 경우 데이터베이스 및/또는 데이터베이스의 개별 스키마에서 REPLICABLE_WITH_FAILOVER_GROUPS 매개 변수를 선택적으로 구성하여 복제를 위한 스키마의 하위 집합을 지정할 수 있습니다.
이 기능을 사용하면 복제되는 장애 조치 그룹의 스키마를 제어할 수 있으므로 데이터베이스의 데이터 하위 집합에만 장애 조치로 제공되는 추가 재해 복구 보호가 필요한 경우에 유용합니다.
이 매개 변수는 기본적으로 모든 데이터베이스 및 해당 데이터베이스에 포함된 스키마에 대해 활성화되어 있으므로 복제에서 생략할 데이터베이스 및/또는 스키마를 선택하여 복제 세부 수준을 조정할 수 있습니다. 특정 스키마가 포함된 데이터베이스가 복제되지 않더라도 해당 스키마가 복제되도록 허용하여 복제 설정을 더욱 세밀하게 조정할 수 있습니다.
복제하거나 건너뛸 스키마 지정¶
선택 사항 REPLICABLE_WITH_FAILOVER_GROUPS 매개 변수를 사용하여 장애 조치 그룹의 데이터베이스에서 복제하거나 건너뛸 스키마를 명시적으로 지정할 수 있습니다.
REPLICABLE_WITH_FAILOVER_GROUPS 매개 변수¶
REPLICABLE_WITH_FAILOVER_GROUPS 매개 변수는 장애 조치 그룹의 데이터베이스에 속하는 스키마가 복제되는지 여부를 지정합니다. 이 매개 변수는 데이터베이스 및 데이터베이스의 모든/모든 스키마에 설정할 수 있습니다. 데이터베이스에 매개 변수가 설정되어 있으면 특정 스키마에 대해 다른 값을 명시적으로 설정하지 않는 한 데이터베이스의 모든 스키마가 이 값을 상속합니다.
이 매개 변수는 'YES' 또는 'NO' (대/소문자 구분 안 함)의 두 가지 값을 사용할 수 있으며 선택 사항입니다.
REPLICABLE_WITH_FAILOVER_GROUPS 이 데이터베이스에 명시적으로 설정되지 않았거나 명시적으로 설정되지 않은 경우 데이터베이스는 표준 복제 동작을 따르며, 이는 매개 변수를
'YES'로 설정하는 것과 동일합니다.스키마에 REPLICABLE_WITH_FAILOVER_GROUPS 이 명시적으로 설정되어 있지 않거나 명시적으로 설정되지 않은 경우 상위 항목의 데이터베이스에서 복제 동작이 상속됩니다.
보안 요구 사항¶
데이터베이스 또는 스키마에서 이 매개 변수를 설정하거나 설정 해제하려면 다음 권한이 필요합니다.
예¶
기존 역할에 필요한 권한을 부여합니다(replicationadmin):
db1 데이터베이스에서 1개의 스키마 sch1 만 복제합니다.
db2 데이터베이스에서 1개의 스키마 sch2 를 제외한 모든 스키마를 복제합니다.
대상 계정에 REPLICABLE_WITH_FAILOVER_GROUPS 이 설정된 스키마 새로 고침¶
데이터베이스 새로 고침 중:
REPLICABLE_WITH_FAILOVER_GROUPS 이
'YES'로 설정된 스키마는 소스 계정에서 대상 계정으로 복제됩니다.REPLICABLE_WITH_FAILOVER_GROUPS 이
'NO'로 설정된 스키마는 다음 두 가지 시나리오를 제외하고 복제되지 않습니다.대상 스키마는 소스 계정 스키마의 복제본입니다. 이 경우 대상 스키마는 항상 소스 스키마와 동기화됩니다.
대상 스키마가 소스 계정 스키마와 이름이 충돌합니다. 이 경우 이름 충돌로 인해 복제 작업이 실패합니다.
계정에 REPLICABLE_WITH_FAILOVER_GROUPS 으로 설정된 데이터베이스 및 스키마 목록 만들기¶
ACCOUNT_USAGE 및 INFORMATION_SCHEMA 뷰를 쿼리하여 현재 계정의 REPLICABLE_WITH_FAILOVER_GROUPS 매개 변수에 설정된 값을 나열할 수 있습니다.
팁
ACCOUNT_USAGE 또는 INFORMATION_SCHEMA 뷰를 사용하는 이유를 잘 모르는 경우 Account Usage와 Information Schema의 차이점 섹션을 참조하십시오.
예¶
이 예제에서는 INFORMATION_SCHEMA 뷰를 사용합니다. 이렇게 하면 설정을 변경한 후 즉시 설정을 확인할 수 있습니다.
기존 replicationadmin 역할을 사용하여 2개의 데이터베이스를 가진 계정에 대한 모든 매개 변수 값을 반환합니다.
db1데이터베이스는 명시적으로NO로 설정되었으며 데이터베이스의sch1스키마는 명시적으로YES로 설정되어 있습니다. 데이터베이스의 해당 스키마 하나만 복제할 수 있습니다.db2데이터베이스는 명시적으로YES로 설정되었으며 데이터베이스의sch2스키마는 명시적으로NO로 설정되어 있습니다. 데이터베이스의 모든 스키마는 해당 스키마 하나를 제외하고 복제할 수 있습니다.
대상 계정의 스크립트에 의해 생성된 오브젝트에 전역 ID 적용하기¶
복제가 아닌 다른 방법(예: 스크립트 사용)으로 대상 계정에 사용자 및 역할과 같은 계정 오브젝트를 생성한 경우 이러한 사용자 및 역할에는 기본적으로 전역 식별자가 없습니다. 새로 고침 작업은 전역 식별자를 사용하여 이러한 오브젝트를 원본 계정의 동일 오브젝트에 동기화합니다.
대부분의 경우에는 대상 계정이 원본 계정에서 새로 고쳐지면 새로 고침 작업은 전역 식별자가 없는 대상 계정에 있는 OBJECT_TYPES 목록에서 유형의 모든 계정 오브젝트를 삭제 합니다. 그러나 대상 계정에 대한 사용자 및 역할의 초기 복제로 인해 첫 번째 새로 고침 작업이 실패할 수 있습니다. 이 동작에 대한 자세한 내용은 사용자 및 역할의 초기 복제 섹션을 참조하십시오.
SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME()을 사용하여 전역 ID 적용하기¶
원본 계정과 대상 계정에서 동일한 이름을 가진 일치하는 오브젝트를 연결하면 일부 오브젝트 유형의 손실을 방지할 수 있습니다. SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 함수는 대상 계정의 계정 오브젝트에 전역 식별자를 추가합니다.
참고
전역 식별자는 다음 오브젝트 유형에 대한 복제 또는 장애 조치 그룹에 포함된 계정 오브젝트에만 추가됩니다.
RESOURCE_MONITORROLEUSERWAREHOUSE
장애 조치 그룹 myfg 의 object_types 목록에 포함된 유형의 대상 계정에 있는 계정 오브젝트에 전역 식별자를 적용합니다.
ACCOUNTADMIN 역할을 사용하여 다음 SQL 문을 실행합니다.
사용자 및 역할의 초기 복제¶
USERS 및 ROLES 오브젝트 유형에 대한 초기 새로 고침 작업의 동작은 대상 계정에 동일한 이름을 가진 일치하는 오브젝트가 있는지 여부에 따라 달라질 수 있습니다.
참고
이 섹션에서 설명하는 동작은 이러한 오브젝트 유형이 대상 계정에 처음 복제될 때만 적용됩니다.
아래 시나리오에서는 USERS의 복제를 설명합니다. ROLES 복제에도 동일하게 적용됩니다.
대상 계정에 원본 계정의 사용자와 같은 이름을 가진 기존 사용자가 있는 경우 초기 새로 고침 작업이 실패하고 계속해야 하는 두 가지 옵션을 설명합니다.
새로 고침 작업을 강제로 실행하고 대상 계정의 기존 사용자를 삭제하도록 허용합니다. 원본 계정의 사용자가 대상 계정에 복제됩니다.
그룹을 강제로 새로 고치려면 새로 고침 명령에 FORCE 매개 변수를 사용하십시오. 예를 들어 장애 조치 그룹을 강제로 새로 고치려면 다음 명령을 실행하십시오.
계정 오브젝트를 이름별로 연결합니다. SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 함수는 대상 계정과 원본 계정에서 모두 같은 이름을 가진 사용자를 연결합니다. 연결된 대상 계정의 사용자는 삭제되지 않습니다.
계정 오브젝트를 이름별로 연결하려면 다음 문을 실행하십시오.
참고
이름이 같은 원본 계정에 일치하는 사용자가 없는 대상 계정의 모든 사용자는 삭제됩니다.
원본 계정의 사용자와 이름이 일치하는 대상 계정의 사용자가 없는 경우 대상 계정의 초기 새로 고침 작업에서 모든 사용자가 삭제됩니다. 이로 인해 다음과 같은 데이터와 메타데이터가 손실될 수 있습니다.
복제 또는 장애 조치 그룹의 OBJECT_TYPES 목록에 USERS가 포함된 경우:
워크시트가 손실됩니다.
쿼리 기록이 손실됩니다.
USERS가 OBJECT_TYPES 목록에 포함되지만 ROLES는 포함되지 않는 경우:
사용자에게 부여된 권한이 손실됩니다.
ROLES가 OBJECT_TYPES 목록에 포함된 경우:
오브젝트를 공유하기 위해 부여된 권한이 손실됩니다.
대상 계정에서 사용자나 역할을 삭제하지 않으려면 다음을 수행하십시오.
원본 계정에서 초기 복제 전에 오직 대상 계정에만 존재하는 사용자나 역할을 전부 수동으로 다시 생성합니다.
대상 계정에서 SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 함수를 사용하여 두 계정에서 모두 동일한 이름을 가진 일치하는 오브젝트를 연결합니다.
보조 저장소 통합을 위한 클라우드 저장소 액세스 구성하기¶
저장소 통합 복제를 활성화할 경우 저장소 통합이 대상 계정에 복제된 후 추가 단계를 수행해야 합니다. 복제된 통합에는 기본 통합의 ID 및 IAM 엔티티와는 다른 고유한 ID 및 액세스 관리(IAM) 엔티티가 있습니다. 따라서 복제된 통합에 클라우드 저장소에 대한 액세스 권한을 부여하려면 클라우드 공급자 권한을 업데이트해야 합니다.
대상 계정에서 이 신뢰 관계를 한 번만 구성하면 됩니다.
이 프로세스는 원본 계정에 액세스 권한을 부여하는 것과 유사합니다. 자세한 내용은 다음 페이지를 참조하십시오.
보조 스테이지에서 디렉터리 테이블에 대한 자동 새로 고침 구성하기¶
디렉터리 테이블이 있는 외부 스테이지를 복제하고 원본 디렉터리 테이블에 대해 자동 새로 고침을 구성한 경우 보조 디렉터리 테이블에 대해 자동 새로 고침 을 구성하는 단계를 수행해야 합니다.
이 프로세스는 원본 계정에서 자동 새로 고침을 설정하는 것과 유사합니다. 자세한 내용은 다음을 참조하십시오.
Amazon S3: 구성 프로세스는 이벤트 알림 설정 방법에 따라 다릅니다.
Amazon SQS(Simple Queue Service)와 함께 Amazon S3 Event Notifications를 사용하는 경우 2단계: 이벤트 알림 구성 의 지침을 따르십시오. SQS에서 SNS로 마이그레이션할 수도 있습니다. 자세한 내용은 Amazon SNS(Simple Notification Service)로 마이그레이션하기 섹션을 참조하십시오.
Amazon SNS(Simple Notification Service)를 사용하는 경우 Snowflake SQS 큐에서 SNS 항목 구독하기 를 참조하십시오.
Google Cloud Storage: 대상 계정에서 Pub/Sub 항목에 대한 새 구독과 새 알림 통합을 만듭니다. 그런 다음, Pub/Sub 구독에 Snowflake 액세스 권한을 부여합니다. 자세한 지침은 Configure automation using GCS Pub/Sub 섹션을 참조하십시오.
Azure Blob Storage: 새 Event Grid 구독 및 저장소 큐를 만듭니다. 그런 다음, 대상 계정에서 새 알림 통합을 생성하고 저장소 큐에 Snowflake 액세스 권한을 부여합니다. 자세한 지침은 Azure Event Grid를 사용한 자동화 구성 섹션을 참조하십시오.
중요
대상 계정에서 이러한 구성 단계를 완료한 후 디렉터리 테이블을 완전히 새로 고쳐 놓치는 알림이 없도록 해야 합니다.
Google Cloud Storage 및 Azure Blob Storage의 경우 각 대상 계정의 알림 통합 이름이 원본 계정의 알림 통합 이름과 일치해야 합니다.
보조 자동 수집 파이프에 대한 알림 구성하기¶
장애 조치 전에 보조 자동 수집 파이프에 대한 클라우드 알림을 구성하려면 추가 단계를 수행해야 합니다. 이 섹션에서는 이 추가 구성이 필요한 이유와 지원되는 각 클라우드 공급자에 대해 구성을 완료하는 방법을 설명합니다.
Amazon S3¶
구성 프로세스는 이벤트 알림 설정 방법에 따라 다릅니다. 예를 들어 Snowflake 스테이지 위치에 대한 메시지를 게시하기 위해 Amazon SNS(Simple Notification Service) 항목에 의존하는 자동 수집 파이프가 있다고 가정해 보겠습니다.
파이프를 대상 계정에 복제하면 Snowflake가 새로운 Amazon SQS(Simple Queue Service) 큐를 자동으로 생성합니다. 스테이지 위치에 대한 알림을 받으려면 SNS 항목에 대해 대상 계정의 이 SQS 큐를 구독해야 합니다.
Amazon SQS(Simple Queue Service)와 함께 Amazon S3 Event Notifications를 사용하는 경우 4단계: 이벤트 알림 구성 의 지침을 따르십시오.
중요
파이프가 알림을 놓치지 않았는지 확인하려면 새 SQS 큐로 전환한 후 파이프를 새로 고쳐야 합니다.
SQS에서 SNS로 마이그레이션할 수도 있습니다. 자세한 내용은 Amazon SNS(Simple Notification Service)로 마이그레이션하기 섹션을 참조하십시오.
Amazon SNS(Simple Notification Service)를 사용하는 경우 Snowflake SQS 큐에서 SNS 항목 구독하기 를 참조하십시오.
Amazon EventBridge을 사용하는 경우 옵션 3: Snowpipe를 자동화하도록 Amazon EventBridge 설정 섹션을 참조하십시오.
Microsoft Azure Blob 저장소¶
Microsoft Azure Blob 저장소의 스테이지에 있는 파일에서 데이터를 자동으로 로드하는 파이프에는 Event Grid 구독, 저장소 큐, 저장소 큐에 바인딩된 알림 통합이 필요합니다. 대상 계정의 보조 파이프에는 별도의 Event Grid, 저장소 큐, 저장소 큐에 바인딩된 알림 통합이 필요합니다. 원본 계정과 대상 계정 모두의 Event Grid는 동일한 Azure Storage 원본의 엔드포인트로 구성해야 합니다.
구성 세부 정보는 아래 다이어그램을 참조하십시오.
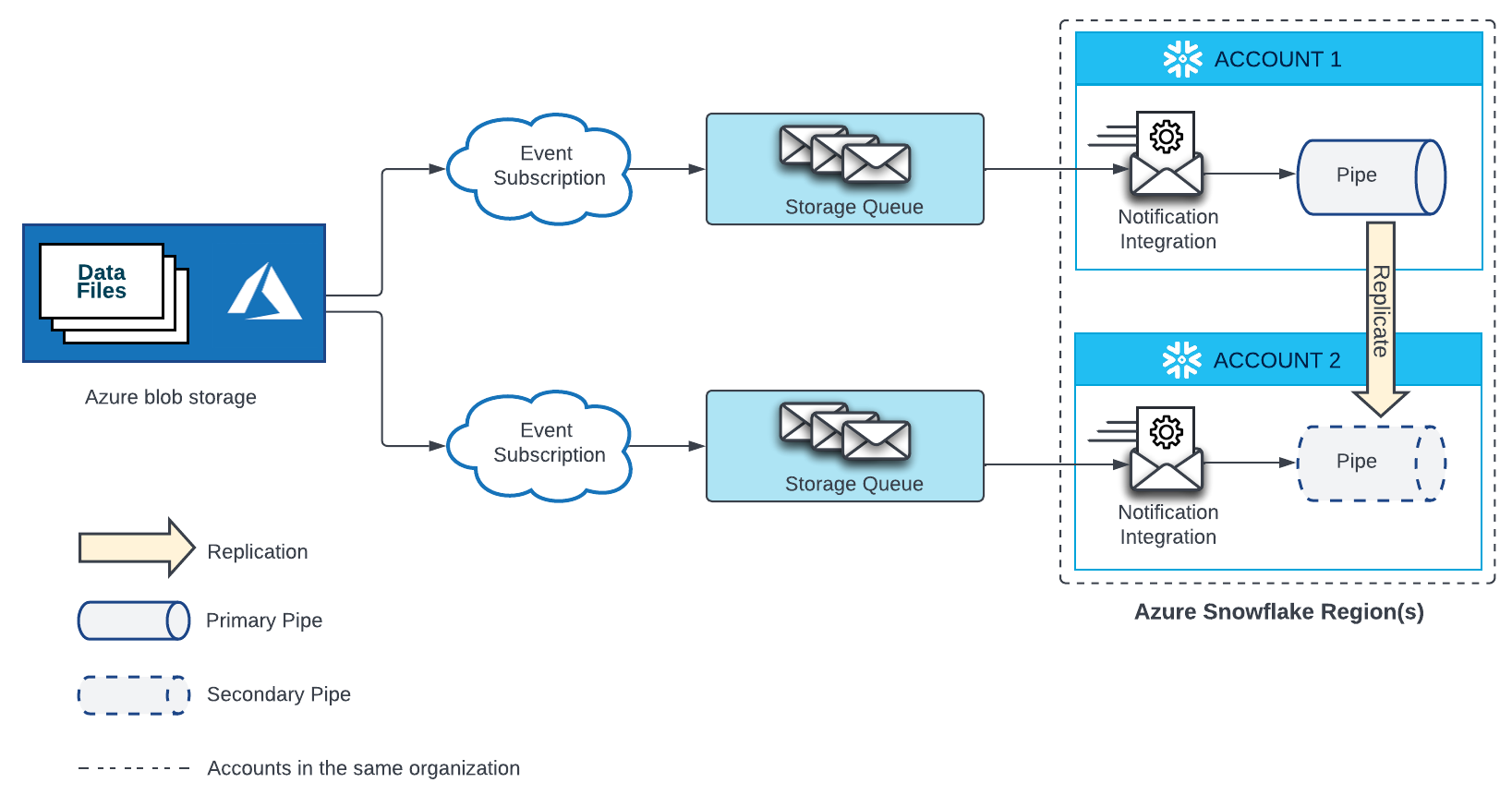
새 Event Grid 구독 및 저장소 큐를 만듭니다. 그런 다음, 대상 계정에서 새 알림 통합을 생성하고 저장소 큐에 Snowflake 액세스 권한을 부여합니다. 자세한 지침은 Azure Event Grid를 사용한 자동화 구성하기 섹션을 참조하십시오.
중요
각 대상 계정의 알림 통합 이름은 원본 계정의 알림 통합 이름과 일치해야 합니다.
Google Cloud Storage의 외부 스테이지¶
Google Cloud Storage에 있는 파일에서 데이터를 자동으로 로드하는 파이프에는 Google Pub/Sub 구독과 해당 구독을 참조하는 알림 통합이 필요합니다. 대상 계정에서 복제된 각 파이프에는 Google Pub/Sub 구독과 해당 구독을 참조하는 알림 통합도 필요합니다. 각 원본 및 대상 계정의 Pub/Sub 구독은 Google Cloud Storage 원본에서 알림을 받는 동일한 Pub/Sub 항목을 구독해야 합니다.
구성 세부 정보는 아래 다이어그램을 참조하십시오.
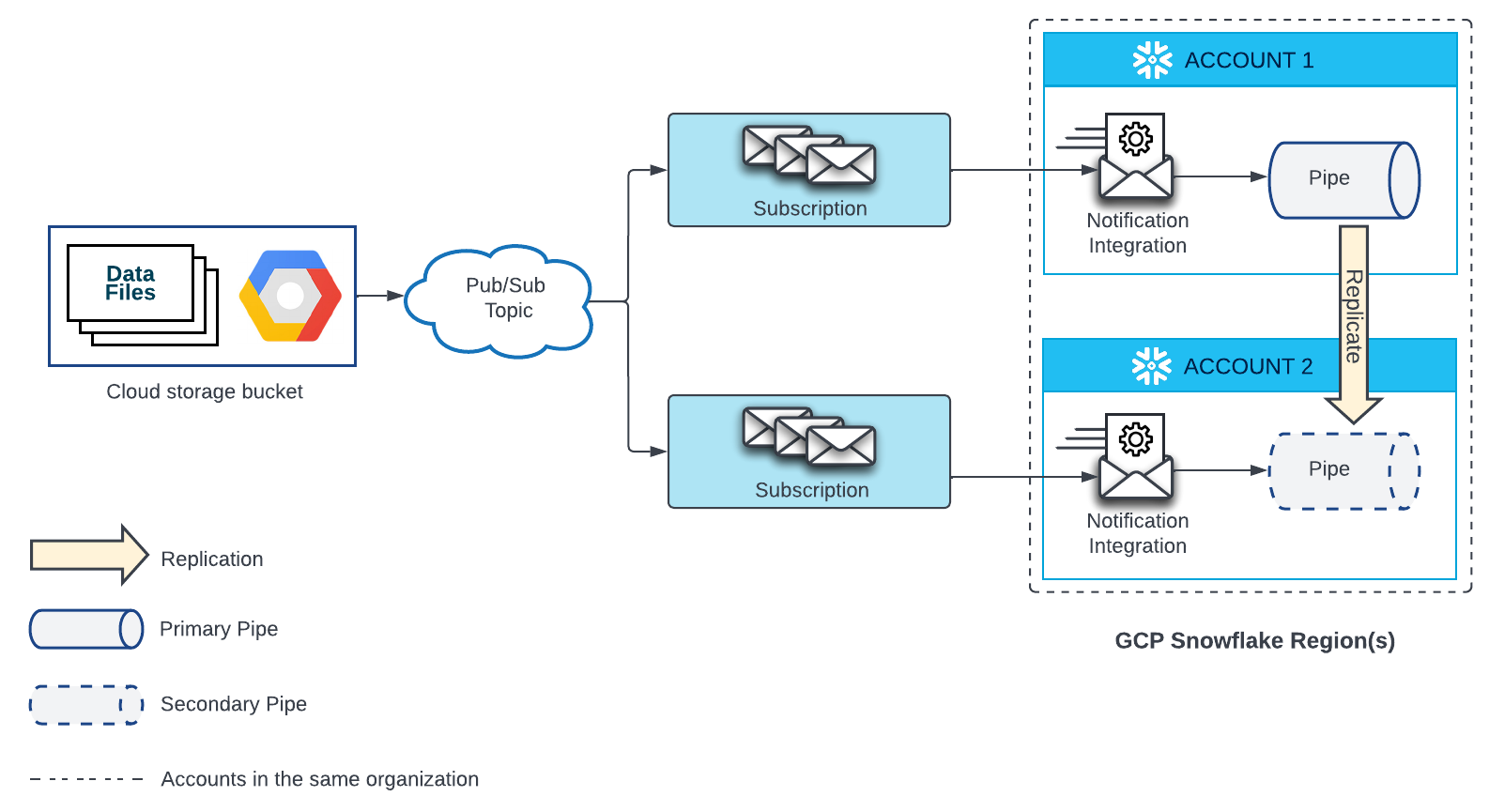
- 대상 계정에서 Pub/Sub 항목에 대한 새 구독과 새 알림 통합을 만듭니다.
그런 다음, Pub/Sub 구독에 Snowflake 액세스 권한을 부여합니다. 자세한 지침은 GCS Pub/Sub를 사용하여 자동화 구성하기 섹션을 참조하십시오.
중요
각 대상 계정의 알림 통합 이름은 원본 계정의 알림 통합 이름과 일치해야 합니다.
API 통합을 위해 원격 서비스 업데이트하기¶
API 통합 복제를 활성화한 경우 API 통합이 대상 계정에 복제된 후 추가 단계가 필요합니다. 복제된 통합에는 기본 통합의 ID 및 IAM 엔티티와는 다른 고유한 ID 및 액세스 관리(IAM) 엔티티가 있습니다. 따라서 복제된 함수에 대한 액세스 권한을 부여하려면 원격 서비스에 대한 권한을 업데이트해야 합니다. 이 프로세스는 기본 계정의 함수에 대한 액세스 권한을 부여하는 것과 유사합니다. 자세한 내용은 아래 링크를 참조하십시오.
Amazon Web Services Snowflake와 새 IAM 역할 사이의 트러스트 관계 설정하기.
Google Cloud Platform: 프록시 서비스에 대한 GCP 보안 정책 생성.
Microsoft Azure:
1단계. Azure용 API 통합 연결
2단계. JWT 유효성 검사 정책 생성하기
기본 및 보조 데이터베이스의 데이터 세트 비교하기¶
Snowflake는 복제 새로 고침 작업을 수행할 때마다 자동 확인 검사를 수행합니다. 확인에 실패하면 새로 고침이 실패합니다. 따라서 복제된 데이터를 수동으로 확인할 필요가 없습니다. 규정 준수를 위해 추가 확인이 필요한 경우 새로 고침 작업이 완료된 후 수동 확인 단계를 수행할 수 있습니다.
Snowflake를 통한 자동 확인¶
Snowflake는 현재 각 새로 고침 작업 후 기본 계정과 보조 계정 간에 다음 검사를 수행합니다.
Snowflake는 복제된 모든 파일에 대해 기본 계정과 보조 계정 간의 해시 값을 비교합니다.
Snowflake는 각 테이블에 대해 기본 계정과 보조 계정 간의 다음 값을 비교합니다.
파일 수.
행 수.
바이트 수.
수동 확인¶
데이터베이스 오브젝트가 복제 또는 장애 조치 그룹에서 복제되는 경우 HASH_AGG 함수를 통해 기본 데이터베이스와 보조 데이터베이스의 일부 또는 모든 테이블에 있는 행을 비교하여 데이터 일관성을 확인할 수 있습니다. HASH_AGG 함수는 입력 행 세트에 대해 부호 있는 집계 64비트 해시 값을 반환합니다. 해시 값은 입력 행의 순서와 관계없이 동일합니다.
보조 계정과 기본 계정 모두에서 모든 테이블 또는 테이블의 임의 하위 세트에 대해 이 함수를 쿼리합니다. 기본 계정에서 AT | BEFORE 절을 사용하여 연결된 데이터베이스의 최신 새로 고침 시점을 지정합니다. 두 계정에서 쿼리 간의 출력을 비교합니다.
새로 고침 후 데이터를 수동으로 확인하는 예¶
다음 예에서 데이터베이스 ``mydb``는 장애 조치 그룹 ``myfg``에 포함되어 있습니다. 데이터베이스 ``mydb``에는 테이블 ``myschema.mytable``이 있습니다.
대상 계정에서 실행할 명령¶
(/sql-reference/info-schema`의) :doc:`REPLICATION_GROUP_REFRESH_PROGRESS 테이블 함수를 쿼리합니다.
PRIMARY_UPLOADING_METADATA단계에 대한DETAILS열에서 ``primarySnapshotTimestamp``를 기록합니다. 이는 기본 계정에서 해당 데이터베이스의 최신 스냅샷에 대한 타임스탬프입니다.보조 계정에서 지정된 테이블에 대해 HASH_AGG 함수를 쿼리합니다. 다음 쿼리는
myschema.mytable테이블의 모든 행에 대한 해시 값을 반환합니다.
소스 계정에서 실행할 명령¶
기본 계정에서 동일한 테이블에 대해 HASH_AGG 함수를 쿼리합니다. Time Travel을 사용하여 보조 데이터베이스에 대한 최신 스냅샷이 생성된 타임스탬프를 지정합니다.
두 쿼리의 결과를 비교합니다. 출력은 동일해야 합니다.
소스 계정에서 복제 또는 장애 조치 그룹 수정하기¶
Snowsight 또는 SQL 을 사용하여 소스 계정에서 복제 또는 장애 조치 그룹의 이름, 포함된 오브젝트, 복제 예약을 편집할 수 있습니다.
참고
복제 그룹을 장애 조치 그룹으로 변경하거나 그 반대로 변경할 수 없습니다. 장애 조치를 사용하거나 사용하지 않으려면 그룹을 삭제하고 올바른 장애 조치 설정으로 그룹을 다시 생성합니다.
Snowsight를 사용하여 소스 계정에서 복제 또는 장애 조치 그룹 수정¶
참고
계정 관리자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 편집할 수 있습니다(복제 구성에 Snowsight 사용 시 제한 사항 참조).
이러한 작업을 수행하려면 소스 계정에 로그인해야 합니다. 로그인한 상태가 아니라면 Status 열에 새로 고침 상태 대신 로그인 메시지가 표시됩니다.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Admin » Accounts 를 선택합니다.
Replication 를 선택한 다음 Groups 을 선택합니다.
편집하려는 복제 또는 장애 조치 그룹의 위치를 찾고 행의 마지막 열에 있는 More 메뉴(…)를 선택합니다.
Edit 를 선택합니다.
그룹 이름을 변경하려면 다음 요구 사항을 충족하는 Group name 상자에 새 이름을 입력하십시오.
알파벳 문자로 시작해야 하며 식별자 문자열을 큰따옴표로 묶지 않는 한 공백이나 특수 문자를 포함할 수 없습니다(예: “내 오브젝트”). 큰따옴표로 묶인 식별자도 대/소문자를 구분합니다.
자세한 내용은 식별자 요구 사항 섹션을 참조하십시오.
계정의 장애 조치 그룹 및 복제 그룹에 대한 이름은 고유해야 합니다.
Edit objects 를 선택하여 공유 및 계정 오브젝트를 추가하거나 제거합니다.
참고
계정 오브젝트는 하나의 복제 또는 장애 조치 그룹에만 추가할 수 있습니다. 계정에 이미 계정 오브젝트가 있는 복제 또는 장애 조치 그룹이 있는 경우에는 해당 오브젝트를 선택할 수 없습니다.
Select databases 를 선택하여 데이터베이스 오브젝트를 추가하거나 제거합니다.
Replication frequency 를 선택하여 그룹의 복제 일정을 변경합니다.
Save 를 선택하여 그룹을 업데이트합니다.
변경 사항을 그룹에 저장하지 못한 경우 일반적인 오류와 해결 방법은 Snowsight를 사용한 복제 그룹 생성 및 편집 관련 문제 해결하기 섹션을 참조하십시오.
SQL 을 사용하여 소스 계정에서 복제 또는 장애 조치 그룹을 수정¶
ALTER REPLICATION GROUP 또는 ALTER FAILOVER GROUP 명령을 사용하여 복제 또는 장애 조치 그룹 속성을 수정할 수 있습니다.
대상 계정에서 복제 예약 일시 중지 또는 다시 시작¶
Snowsight 또는 SQL 을 사용하여 대상 계정의 복제 예약을 일시 중지(일시 중단)하거나 다시 시작할 수 있습니다.
Snowsight를 사용하여 대상 계정에서 복제 예약 일시 중지 또는 다시 시작¶
참고
계정 관리자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 편집할 수 있습니다(복제 구성에 Snowsight 사용 시 제한 사항 참조).
복제 예약을 일시 중지하거나 다시 시작하려면 대상 계정에 로그인해야 합니다.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Admin » Accounts 를 선택합니다.
Replication 를 선택한 다음 Groups 을 선택합니다.
편집하려는 복제 또는 장애 조치 그룹의 위치를 찾고 행의 마지막 열에 있는 More 메뉴(…)를 선택합니다.
Pause 또는 Resume 를 선택합니다.
SQL 을 사용하여 대상 계정의 복제 예약을 일시 중지하거나 다시 시작¶
ALTER REPLICATION GROUP 또는 ALTER FAILOVER GROUP 명령을 사용하여 대상 계정의 복제 예약을 일시 중지하거나 다시 시작할 수 있습니다. 일시 중지하려면 SUSPEND 매개 변수를 지정합니다. 다시 시작하려면 RESUME 매개 변수를 지정합니다.
보조 복제 또는 장애 조치 그룹 삭제하기¶
DROP REPLICATION GROUP 또는 DROP FAILOVER GROUP 명령을 사용하여 보조 복제 또는 장애 조치를 삭제할 수 있습니다. 복제 또는 장애 조치 그룹 소유자(즉, 그룹에 대한 OWNERSHIP 권한이 있는 역할)만 그룹을 삭제할 수 있습니다.
Snowsight 를 사용하여 보조 복제 또는 장애 조치 그룹을 삭제하려면 원본 계정의 그룹을 삭제해야 합니다. Snowsight를 사용하여 복제 또는 장애 조치 그룹 삭제하기 섹션을 참조하십시오.
기본 복제 또는 장애 조치 그룹 삭제하기¶
Snowsight 또는 SQL을 사용하여 기본 복제 또는 장애 조치 그룹을 삭제할 수 있습니다. SQL을 사용하여 기본 그룹을 삭제하려는 경우 먼저 모든 보조 그룹을 삭제해야 합니다. 보조 복제 또는 장애 조치 그룹 삭제하기 섹션을 참조하십시오.
SQL을 사용하여 기본 복제 또는 장애 조치 그룹 삭제하기¶
그룹의 모든 복제본(즉, 보조 복제 또는 장애 조치 그룹)이 삭제된 후에만 기본 복제 또는 장애 조치 그룹을 삭제할 수 있습니다. 또는 기본 장애 조치 그룹의 역할을 하도록 보조 장애 조치 그룹을 승격한 다음, 이전의 기본 장애 조치 그룹을 삭제할 수 있습니다.
그룹 소유자만 그룹을 삭제할 수 있음에 유의하십시오.
Snowsight를 사용하여 복제 또는 장애 조치 그룹 삭제하기¶
참고
계정 관리자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 삭제할 수 있습니다(복제 구성에 Snowsight 사용 시 제한 사항 참조).
기본 복제 또는 장애 조치 그룹과 연결된 모든 보조 그룹을 삭제할 수 있습니다.
Snowsight 에 로그인합니다.
탐색 메뉴에서 Admin » Accounts 를 선택합니다.
Replication 을 선택한 다음 Groups 를 선택합니다.
삭제하려는 복제 또는 장애 조치 그룹을 찾습니다. 행의 마지막 열에서 More 메뉴(…)를 선택합니다.
Drop 를 선택한 다음 Drop group 을 선택합니다.
Snowsight를 사용한 복제 그룹 생성 및 편집 관련 문제 해결하기¶
다음 시나리오는 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 생성하거나 편집할 때 발생할 수 있는 일반적인 문제를 해결하는 데 도움이 될 수 있습니다.
그룹에 데이터베이스를 추가할 수 없음¶
오류 |
|
|---|---|
원인 |
데이터베이스는 하나의 복제 또는 장애 조치 그룹에만 있을 수 있습니다. 그룹에 대해 선택한 데이터베이스 중 하나가 다른 복제 또는 장애 조치 그룹에 이미 포함되어 있습니다. |
해결책 |
Select Databases 를 선택하고 다른 그룹에 이미 포함된 데이터베이스를 모두 선택 취소합니다. |
오류 |
|
|---|---|
원인 |
복제 또는 장애 조치 그룹에 추가하려는 데이터베이스가 이전에 데이터베이스 복제용으로 구성되었습니다. |
해결책 |
데이터베이스에 대한 데이터베이스 복제를 비활성화합니다. 데이터베이스 복제에서 그룹 기반 복제로 전환하기 섹션을 참조하십시오. |
복제 구성에 Snowsight 사용 시 제한 사항¶
ACCOUNTADMIN 역할을 가진 사용자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 생성할 수 있습니다. CREATE REPLICATION GROUP 또는 CREATE FAILOVER GROUP 권한이 부여된 역할이 있는 사용자는 해당 SQL 명령을 사용하여 그룹을 만들 수 있습니다.
ACCOUNTADMIN 역할이 있는 사용자만 Snowsight 를 사용하여 복제 또는 장애 조치 그룹을 편집하거나 삭제할 수 있습니다. 복제 또는 장애 조치 그룹에 대한 OWNERSHIP 권한이 부여된 역할이 있는 사용자는 해당 SQL 명령을 사용하여 그룹을 편집하고 삭제할 수 있습니다.
계정이 비공개 연결을 사용하는 경우 Snowsight 를 사용하여 그룹을 만들거나 수정하거나 삭제할 수 없습니다. SQL 을 사용하여 이러한 작업을 완료할 수 있습니다.