Replicação de bancos de dados e objetos de conta em diversas contas¶
Este tópico descreve as etapas necessárias para replicar dados e objetos de conta em várias contas Snowflake na mesma organização e manter os objetos e os dados sincronizados. A replicação de contas pode ocorrer em contas Snowflake de diferentes regiões e em plataformas de nuvem.
Nota
Ao atualizar uma conta para Business Critical Edition (ou superior), pode levar até 12 horas até que os recursos de failover fiquem disponíveis.
Suporte regional para replicação e failover/failback¶
Os clientes podem replicar em todas as regiões dentro de um grupo de regiões. Para replicar entre regiões em diferentes Grupos de regiões (por exemplo, de uma região comercial de Snowflake para uma região governamental de Snowflake), entre em contato com o suporte Snowflake para permitir o acesso.
Transição da replicação de banco de dados para a replicação baseada em grupos¶
Os bancos de dados que foram habilitados para replicação usando ALTER DATABASE devem ter a replicação desabilitada antes de serem adicionados a um grupo de replicação ou failover.
Nota
Execute as instruções SQL nesta seção usando a função ACCOUNTADMIN.
Etapa 1. Desabilitar a replicação para um banco de dados habilitado para replicação¶
Execute a função SYSTEM$DISABLE_DATABASE_REPLICATION para desativar a replicação de um banco de dados primário, juntamente com bancos de dados secundários ligados a ele, a fim de adicioná-lo a um grupo de replicação ou failover.
Execute a seguinte instrução SQL a partir da conta de origem com o banco de dados primário:
Etapa 2. Adicionar o banco de dados a um grupo de failover primário e criar um grupo de failover secundário¶
Uma vez que você tenha desativado com sucesso a replicação para um banco de dados, você pode adicionar o banco de dados primário a um grupo de failover na conta de origem.
Em seguida, crie um grupo de failover secundário na conta de destino. Quando o grupo secundário de failover é atualizado na conta de destino, o banco de dados secundário anterior será automaticamente adicionado como membro do grupo secundário de failover e atualizado com as alterações do banco de dados primário.
Para obter mais detalhes sobre a criação de grupos primários e secundários de failover, consulte Fluxo de trabalho.
Nota
Quando você adiciona um banco de dados previamente replicado a um grupo de replicação ou failover, o Snowflake não replica os dados que já foram replicados para aquele banco de dados. Somente as alterações desde a última atualização são replicadas quando o grupo é atualizado.
Fluxo de trabalho¶
As seguintes instruções SQL demonstram o fluxo de trabalho para habilitar a replicação de contas e objetos de banco de dados, além de atualizar objetos. Cada etapa é discutida em detalhes abaixo.
Nota
Os exemplos a seguir exigem que a replicação seja habilitada para as contas de origem e destino. Para obter mais detalhes, consulte Pré-requisito: Habilitar a replicação para contas na organização.
Exemplos¶
Execute as seguintes instruções SQL em seu cliente Snowflake preferido para habilitar a replicação e failover de contas e objetos de banco de dados, além da atualização de objetos.
Executado na conta de origem¶
Crie uma função e conceda o privilégio CREATE FAILOVER GROUP. Essa etapa é opcional:
Crie um grupo de failover na conta de origem e habilite a replicação para contas de destino específicas.
Nota
Se você tiver bancos de dados para adicionar a um grupo de replicação ou failover que tenham sido previamente habilitados para failover e replicação de banco de dados usando ALTER DATABASE, siga as instruções Transição da replicação de banco de dados para a replicação baseada em grupos (neste tópico) antes de adicioná-los a um grupo.
Para adicionar um banco de dados a um grupo de failover, a função ativa deve ter o privilégio MONITOR sobre o banco de dados. Para obter mais detalhes sobre privilégios de banco de dados, consulte Privilégios de banco de dados (em um tópico separado).
Executado na conta de destino¶
Crie uma função na conta de destino e conceda o privilégio CREATE FAILOVER GROUP. Essa etapa é opcional:
Crie um grupo de failover na conta de destino como uma réplica do grupo de failover na conta de origem:
Nota
Se existirem objetos de conta (por exemplo, usuários ou funções) na conta de destino que não existam na conta de origem, consulte Replicação inicial de usuários e funções antes de criar um grupo secundário.
Atualize manualmente o grupo de failover secundário. Esta é uma etapa opcional. Se o grupo de failover primário for criado com um cronograma de replicação, a atualização inicial do grupo de failover secundário será executada automaticamente quando o grupo de failover secundário for criado.
Crie uma função com o privilégio REPLICATE no grupo de failover. Esta etapa é opcional.
Execute na conta de destino usando uma função com o privilégio OWNERSHIP no grupo de failover:
Execute a instrução de atualização usando uma função com o privilégio REPLICATE:
Crie uma função com o privilégio FAILOVER no grupo de failover. Esta etapa é opcional.
Execute na conta de destino usando uma função com o privilégio OWNERSHIP no grupo de failover:
Replicação de objetos de conta e bancos de dados¶
As instruções nesta seção explicam como preparar suas contas para replicação, habilitar a replicação de objetos específicos da conta de origem para a conta de destino e sincronizar os objetos na conta de destino.
Importante
As contas de destino não têm conectividade Tri-Secret Secure ou conectividade privada ao serviço Snowflake, como AWS PrivateLink, ativada por padrão. Se você precisar de conectividade Tri-Secret Secure ou conectividade privada para o serviço Snowflake para fins de conformidade, segurança ou outros, é sua responsabilidade configurar e habilitar esses recursos na conta de destino.
Pré-requisito: Habilitar a replicação para contas na organização¶
O administrador da organização deve habilitar a replicação para as contas de origem e destino.
Para ativar a replicação de contas, um administrador da organização usa a função SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER para definir o parâmetro ENABLE_ACCOUNT_DATABASE_REPLICATION como true.
Como um administrador da organização, ative a replicação para cada conta de origem e destino em sua organização.
Embora a função SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER ofereça suporte ao identificador herdado de localizador de contas, ele causa resultados inesperados quando uma organização tem várias contas que compartilham o mesmo localizador (em regiões diferentes).
Etapa 1: criar uma função com o privilégio CREATE FAILOVER GROUP na conta de origem — Opcional¶
Crie uma função e conceda o privilégio CREATE FAILOVER GROUP. Essa etapa é opcional. Se você já criou essa função, pule para Etapa 3: crie um grupo de failover primário em uma conta de origem.
Etapa 2: identifique as contas habilitadas para replicação e associação a grupos¶
Antes de criar um grupo de failover primário, identifique as contas habilitadas para replicação e os grupos de failover e replicação existentes.
Exibição de todas as contas habilitadas para replicação¶
Para recuperar a lista de contas em sua organização que estão habilitadas para replicação, use SHOW REPLICATION ACCOUNTS.
Execute a seguinte instrução SQL usando a função ACCOUNTADMIN:
Retorna:
Consulte a lista completa de IDs de região.
Exibição de inscrição de grupo de failover e replicação¶
Conta, banco de dados e objetos compartilhados têm restrições de inscrição em grupos. Antes de criar novos grupos ou adicionar objetos aos grupos existentes, você pode rever a lista de grupos de failover existentes e os objetos em cada grupo.
Nota
Somente um administrador de conta (usuário com a função ACCOUNTADMIN) ou o proprietário do grupo (função com o privilégio OWNERSHIP sobre o grupo) pode executar as instruções SQL nesta seção.
Veja todos os grupos de failover vinculados à conta atual e os tipos de objetos em cada grupo:
Veja todos os bancos de dados no grupo de failover myfg:
Veja todos os compartilhamentos do grupo de failover myfg:
Etapa 3: crie um grupo de failover primário em uma conta de origem¶
Crie um grupo primário de failover e permita a replicação e o failover de objetos específicos da conta atual (origem) para uma ou mais contas de destino na mesma organização.
Você pode criar um grupo de replicação ou failover usando o Snowsight ou SQL.
Nota
Se você tiver bancos de dados para adicionar a um grupo de replicação ou failover que tenham sido previamente habilitados para replicação de banco de dados usando ALTER DATABASE, siga as instruções Transição da replicação de banco de dados para a replicação baseada em grupos (neste tópico) antes de adicioná-los a um grupo.
Criação de um grupo de replicação ou failover usando o Snowsight¶
Nota
Somente administradores de conta podem criar um grupo de replicação ou failover usando Snowsight (consulte Limitações do uso do Snowsight para configuração de replicação).
Você deve estar conectado à conta de destino como um usuário com a função ACCOUNTADMIN. Caso contrário, você será solicitado a fazer login.
Tanto a conta de origem quanto a conta de destino devem usar o mesmo tipo de conexão (Internet pública). Caso contrário, o login na conta de destino falhará.
Conclua as etapas a seguir para criar um novo grupo de replicação ou failover:
Faça login no Snowsight.
No menu de navegação, selecione Admin » Accounts.
Selecione Replication e, em seguida, conclua uma destas ações na guia Groups:
Para contas Business Critical Edition (ou superior), conclua uma destas ações:
Se não houver grupos de replicação ou conexões, selecione Get started para configurar um grupo de replicação e uma conexão. O assistente Setup business continuity é exibido.
Selecione + Group para configurar um grupo de replicação sem configurar uma conexão. O assistente Create a group é exibido.
Para contas Standard Edition e Enterprise Edition, conclua uma destas ações:
Se não houver grupos ou conexões de replicação, selecione Get started para configurar um grupo de replicação. O assistente Setup replication é exibido.
Se houver um ou mais grupos de replicação, selecione + Group para configurar um grupo de replicação. O assistente Create a group é exibido.
Na página Select a target account, selecione uma conta de destino, faça login nela e selecione Next.
Na página Create a group, na caixa Group name, digite um nome para o grupo que atenda aos seguintes requisitos:
Deve começar com um caractere alfabético e não pode conter espaços ou caracteres especiais, a menos que a cadeia de caracteres do identificador esteja entre aspas duplas (por exemplo, «My object»). Os identificadores delimitados por aspas duplas também diferenciam letras maiúsculas de minúsculas.
Para obter mais informações, consulte Requisitos para identificadores.
Deve ser exclusivo nos grupos de failover e replicação em uma conta.
Escolha Edit objects para adicionar objetos de compartilhamento e conta ao seu grupo.
Nota
Os objetos de conta só podem ser adicionados a um grupo de replicação ou failover. Se já existir um grupo de replicação ou failover com algum objeto de conta em sua conta, você não poderá selecionar esses objetos.
Escolha Select databases para adicionar objetos de banco de dados ao seu grupo.
Selecione Replication frequency.
Se a conta for Business Critical Edition ou superior, um grupo de failover será criado por padrão. Você pode optar por criar um grupo de replicação. Para criar um grupo de replicação, selecione Advanced options e desmarque Enable failover.
Conclua uma das seguintes ações:
Para contas Business Critical Edition (ou superior), selecione Next.
Para contas Standard Edition e Enterprise Edition, selecione Start replication para criar o grupo de replicação.
Para contas Business Critical Edition (ou superior), na página Create connection, digite um nome de conexão na caixa Connection name e selecione Start replication.
Se a criação do grupo de replicação não for bem-sucedida, consulte Solução de problemas de criação e edição de grupos de replicação usando Snowsight para erros comuns e como resolvê-los.
Criação de um grupo de failover usando SQL¶
Crie um grupo de failover de contas e objetos de banco de dados especificados na conta de origem e permita a replicação e o failover para uma lista de contas de destino. Consulte CREATE FAILOVER GROUP para sintaxe.
Por exemplo, permita a replicação de usuários, funções, warehouses, monitores de recursos e bancos de dados db1 e db2 da conta de origem para a conta myaccount2 na mesma organização. Defina o cronograma de replicação para atualizar myaccount2 automaticamente a cada 10 minutos.
Execute a seguinte instrução na conta de origem:
Etapa 4: crie uma função com o privilégio CREATE FAILOVER GROUP na conta de destino – opcional¶
Crie uma função na conta de destino e conceda o privilégio CREATE FAILOVER GROUP. Essa etapa é opcional. Se você já criou essa função, pule para Etapa 5: crie um grupo de failover secundário na conta de destino.
Etapa 5: crie um grupo de failover secundário na conta de destino¶
Nota
Se existirem objetos de conta (por exemplo, usuários ou funções) na conta de destino que não existam na conta de origem, consulte Replicação inicial de usuários e funções antes de criar um grupo secundário.
Crie um grupo secundário de failover na conta de destino como uma réplica do grupo primário de failover na conta de origem.
Execute uma instrução CREATE FAILOVER GROUP … AS REPLICA OF em cada conta de destino para a qual você habilitou a replicação em Etapa 3: crie um grupo de failover primário em uma conta de origem (neste tópico).
Executado a partir de cada conta de destino:
Etapa 6. Atualize manualmente um grupo de failover secundário na conta de destino – opcional¶
Para atualizar manualmente os objetos em uma conta de destino, execute o comando ALTER FAILOVER GROUP … REFRESH.
Como prática recomendada, indicamos programar suas atualizações secundárias definindo o parâmetro REPLICATION_SCHEDULE usando CREATE FAILOVER GROUP ou ALTER FAILOVER GROUP.
Nota
Se o usuário que chama a função na conta de destino foi descartado na conta de origem, a operação de atualização falha.
Concessão do privilégio REPLICATE em um grupo de failover a uma função — Opcional¶
Para executar o comando de atualização de um grupo de failover ou replicação secundária na conta de destino, você deve usar uma função com o privilégio REPLICATE no grupo de failover. O privilégio REPLICATE atualmente não é replicado e deve ser concedido sobre um grupo de failover (ou replicação) tanto na conta de origem quanto na conta de destino.
Execute esta instrução da conta de origem usando uma função com o privilégio OWNERSHIP no grupo:
Execute esta instrução da conta de destino usando uma função com o privilégio OWNERSHIP no grupo:
Atualização manual de um grupo secundário de failover¶
Por exemplo, para atualizar os objetos do grupo de failover myfg, execute a seguinte instrução a partir da conta de destino:
Etapa 7. Conceda o privilégio FAILOVER no grupo de failover à função – opcional¶
Para executar o comando de failover de um grupo de failover secundário em uma conta de destino, você deve usar uma função com o privilégio FAILOVER no grupo de failover. O privilégio FAILOVER atualmente não é replicado e deve ser concedido em cada conta de origem e destino.
Para obter mais informações, consulte Replicação de funções e concessões.
Por exemplo, para conceder o privilégio FAILOVER à função my_failover_role no grupo de failover my_fg, execute a seguinte instrução na conta de destino usando uma função com o privilégio OWNERSHIP no grupo:
Para instruções sobre como criar uma função personalizada com um conjunto específico de privilégios, consulte Criação de funções personalizadas.
Para informações gerais sobre concessões de funções e privilégios para executar ações de SQL em objetos protegíveis, consulte Visão geral do controle de acesso.
Replicação em nível de esquema para grupos de failover¶
Para bancos de dados em grupos de failover, você pode configurar opcionalmente o parâmetro REPLICABLE_WITH_FAILOVER_GROUPS no banco de dados e/ou esquemas individuais no banco de dados para especificar um subconjunto de esquemas para replicação.
Esse recurso permite que você controle os esquemas em um grupo de failover que são replicados, o que é útil se apenas um subconjunto de dados em um banco de dados precisar da proteção adicional de recuperação de desastres fornecida pelo failover.
Como esse parâmetro é ativado por padrão para todos os bancos de dados e os esquemas que eles contêm, você ajusta a granularidade da replicação escolhendo quais bancos de dados e/ou esquemas devem ser omitidos da replicação. Você pode ajustar ainda mais as configurações de replicação, permitindo que determinados esquemas sejam replicados, mesmo que o banco de dados que os contém não seja replicado.
Especifique os esquemas a serem replicados ou ignorados¶
Você pode especificar explicitamente os esquemas a serem replicados ou ignorados em um banco de dados em um grupo de failover usando o parâmetro opcional REPLICABLE_WITH_FAILOVER_GROUPS.
Parâmetro REPLICABLE_WITH_FAILOVER_GROUPS¶
O parâmetro REPLICABLE_WITH_FAILOVER_GROUPS especifica se um esquema que pertence a um banco de dados em um grupo de failover é replicado. Esse parâmetro pode ser definido em um banco de dados e em qualquer/todos os esquemas do banco de dados. Se o parâmetro for definido para um banco de dados, todos os esquemas do banco de dados herdarão o valor, a menos que um valor diferente seja explicitamente definido para um determinado esquema.
O parâmetro aceita dois valores, 'YES' ou 'NO' (não diferencia maiúsculas de minúsculas), e é opcional:
Se REPLICABLE_WITH_FAILOVER_GROUPS não estiver explicitamente definido em um banco de dados (ou não estiver explicitamente definido), o banco de dados seguirá o comportamento de replicação padrão, o que equivale a definir o parâmetro como
'YES'.Se REPLICABLE_WITH_FAILOVER_GROUPS não estiver explicitamente definido em um esquema (ou não estiver definido explicitamente), o comportamento de replicação será herdado do banco de dados pai.
Exigências de segurança¶
Para definir ou cancelar a definição desse parâmetro em um banco de dados ou em um esquema, são necessários os seguintes privilégios:
REPLICATE (privilégio em nível de conta). Antes do recurso de replicação em nível de esquema, esse privilégio era apenas um privilégio em nível de objeto em grupos de replicação e grupos de failover. Os usuários com a função ACCOUNTADMIN podem conceder esse privilégio a outras funções.
USAGE (privilégio do banco de dados e do esquema) ou qualquer privilégio semelhante que permita realizar ações no banco de dados e no esquema.
Exemplos¶
Conceda os privilégios necessários em uma função pré-existente, replicationadmin:
Replique apenas um esquema, sch1, no banco de dados db1:
Replique todos os esquemas, exceto um esquema, sch2, no banco de dados db2:
Atualização de esquemas com REPLICABLE_WITH_FAILOVER_GROUPS definido em contas de destino¶
Durante uma atualização do banco de dados:
Os esquemas com REPLICABLE_WITH_FAILOVER_GROUPS definido como
'YES'são replicados da conta de origem para a conta de destino.Os esquemas com REPLICABLE_WITH_FAILOVER_GROUPS definido como
'NO'não são replicados, exceto nos dois cenários a seguir:O esquema de destino é uma réplica do esquema da conta de origem. Nesse caso, o esquema de destino é sempre sincronizado com o esquema de origem.
O esquema de destino tem um conflito de nome com o esquema de conta de origem. Nessa situação, o trabalho de replicação falha devido ao conflito de nomes.
Liste os bancos de dados e esquemas com REPLICABLE_WITH_FAILOVER_GROUPS definido em sua conta¶
Você pode listar os valores definidos para o parâmetro REPLICABLE_WITH_FAILOVER_GROUPS na conta atual consultando as exibições ACCOUNT_USAGE e INFORMATION_SCHEMA.
Dica
Se você estiver familiarizado com os motivos para usar as exibições ACCOUNT_USAGE ou INFORMATION_SCHEMA, consulte Diferenças entre Account Usage e Information Schema.
Exemplos¶
Para estes exemplos, usaremos as exibições INFORMATION_SCHEMA. Dessa forma, você pode ver as configurações imediatamente após fazer qualquer alteração.
Usando a função pré-existente replicationadmin, retorne todos os valores de parâmetros de conta, que tem dois bancos de dados:
db1explicitamente definido comoNOe o esquemasch1no banco de dados explicitamente definido comoYES. Somente esse esquema no banco de dados é elegível para replicação.db2explicitamente definido comoYESe o esquemasch2no banco de dados explicitamente definido comoNO. Todos os esquemas do banco de dados são elegíveis para replicação, exceto esse esquema.
Aplicação de IDs globais a objetos criados por scripts em contas de destino¶
Se você criou objetos de conta, por exemplo, usuários e funções, na conta de destino por qualquer meio que não seja via replicação (por exemplo, usando scripts), esses usuários e funções não têm identificador global por padrão. A operação de atualização utiliza identificadores globais para sincronizar esses objetos com os mesmos objetos na conta de origem.
Na maioria dos casos, quando uma conta de destino é atualizada a partir da conta de origem, a operação de atualização descarta qualquer objeto de conta dos tipos na lista OBJECT_TYPES na conta de destino que não tenha um identificador global. No entanto, a replicação inicial de usuários e funções para uma conta de destino pode causar falha na primeira operação de atualização. Para obter detalhes sobre esse comportamento, consulte Replicação inicial de usuários e funções.
Uso de SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME() para aplicar IDs globais¶
Você pode evitar a perda de alguns tipos de objetos vinculando objetos correspondentes com o mesmo nome nas contas de origem e de destino. A função SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME adiciona um identificador global aos objetos de conta na conta de destino.
Nota
Os identificadores globais são adicionados apenas aos objetos de conta que estão incluídos em um grupo de replicação ou failover para os seguintes tipos de objetos:
RESOURCE_MONITORROLEUSERWAREHOUSE
Aplique identificadores globais aos objetos de conta na conta de destino dos tipos incluídos na lista object_types para o grupo de failover myfg:
Execute a seguinte instrução SQL usando a função ACCOUNTADMIN:
Replicação inicial de usuários e funções¶
O comportamento da operação de atualização inicial para os tipos de objeto USERS e ROLES pode variar dependendo da existência ou não de objetos correspondentes com o mesmo nome na conta de destino.
Nota
O comportamento descrito nesta seção se aplica apenas à primeira vez que esses tipos de objeto são replicados para a conta de destino.
Os cenários abaixo descrevem a replicação de USERS. O mesmo se aplica à replicação de ROLES.
Se houver usuários na conta de destino com o mesmo nome dos usuários na conta de origem, a operação de atualização inicial falhará e descreverá as duas opções que você terá para continuar:
Forçar a operação de atualização e permitir que quaisquer na conta de destino sejam descartados. Os usuários da conta de origem serão replicados para a conta de destino.
Para forçar uma atualização para um grupo, use o parâmetro FORCE para o comando de atualização. Por exemplo, para forçar a atualização de um grupo de failover, execute o seguinte comando:
Vincule os objetos de conta por nome. A função SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME vincula usuários com o mesmo nome na conta de destino e na conta de origem. Os usuários vinculados na conta de destino não são excluídos.
Para vincular objetos de conta por nome, execute o seguinte comando:
Nota
Qualquer usuário na conta de destino que não tenha um usuário correspondente na conta de origem com o mesmo nome será descartado.
Se não houver nenhum usuário na conta de destino com nomes correspondentes aos usuários da conta de origem, a operação de atualização inicial na conta de destino descartará todos os usuários. Isso pode resultar na seguinte perda de dados e metadados:
Se USERS estiverem incluídos na lista OBJECT_TYPES para um grupo de replicação ou failover:
As planilhas são perdidas.
O histórico de consultas é perdido.
Se USERS estiverem incluídos na lista OBJECT_TYPES, mas ROLES não:
As concessões de privilégios aos usuários são perdidas.
Se ROLES estiverem incluídos na lista OBJECT_TYPES:
Concessões de privilégio para compartilhar objetos são perdidas.
Para evitar descartar usuários ou funções na conta de destino:
Na conta de origem, recrie manualmente quaisquer usuários ou funções que existam somente na conta de destino antes da replicação inicial.
Na conta de destino, vincule objetos correspondentes com o mesmo nome em ambas as contas usando a função SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME.
Configuração do acesso ao armazenamento em nuvem para integrações de armazenamento secundárias¶
Se você ativar a replicação da integração de armazenamento, deverá executar etapas adicionais depois que a integração de armazenamento for replicada para contas de destino. A integração replicada tem sua própria identidade e entidade de gerenciamento de acesso (IAM) que são diferentes da identidade e entidade IAM da integração primária. Portanto, você deve atualizar as permissões do seu provedor de nuvem para conceder à integração replicada acesso ao seu armazenamento em nuvem.
Você só precisa configurar essa relação de confiança nas contas de destino uma vez.
O processo é semelhante à concessão de acesso na conta de origem. Para obter mais informações, consulte as seguintes páginas:
Configuração de atualização automatizada para tabelas de diretório em estágios secundários¶
Se você replicar um estágio externo com uma tabela de diretórios e tiver configurado a atualização automática para a tabela de diretórios de origem, deverá seguir etapas para configurar a atualização automática para a tabela de diretórios secundária.
O processo é semelhante à configuração da atualização automática na sua conta de origem. Consulte o seguinte para obter mais informações:
Amazon S3: o processo de configuração depende de como você configura as notificações de eventos.
Se você usar o Amazon S3 Event Notifications com o Amazon Simple Queue Service (SQS), siga as instruções em Etapa 2: configurar notificações de eventos. Você também pode migrar de SQS para SNS. Para obter mais informações, consulte Migração para Amazon Simple Notification Service (SNS).
Se você usar o Amazon Simple Notification Service (SNS), consulte Inscrição na fila Snowflake SQS em seu tópico SNS.
Google Cloud Storage: crie uma nova assinatura para seu tópico do Pub/Sub e uma nova integração de notificação em sua conta de destino. Depois, conceda acesso do Snowflake à assinatura Pub/Sub. Para obter instruções, consulte Configure automation using GCS Pub/Sub.
Armazenamento de blobs Azure: crie uma nova assinatura do Event Grid e uma fila de armazenamento. Em seguida, crie uma nova integração de notificação na conta de destino e conceda ao Snowflake acesso à sua fila de armazenamento. Para obter instruções, consulte Configuração da automação com o Azure Event Grid.
Importante
Depois de concluir essas etapas de configuração em sua conta de destino, você deverá realizar uma atualização completa da tabela de diretórios para garantir que nenhuma notificação tenha sido perdida.
Para o Google Cloud Storage e o Azure Blob Storage, o nome da integração de notificação em cada conta de destino deve corresponder ao nome da integração de notificação na conta de origem.
Configuração de notificações para canais de ingestão automática secundária¶
Você deve executar etapas adicionais para configurar notificações de nuvem para canais de ingestão automática secundários antes do failover. Esta seção aborda por que essa configuração adicional é necessária e como concluí-la para cada provedor de nuvem compatível.
Amazon S3¶
O processo de configuração depende de como você configura as notificações de eventos. Por exemplo, suponha que você tenha um canal de ingestão automática que depende de um tópico do Amazon Simple Notification Service (SNS) para publicar mensagens sobre o local do estágio Snowflake.
Quando você replica o canal para uma conta de destino, o Snowflake cria automaticamente uma nova fila do Amazon Simple Queue Service (SQS). Você deve inscrever esta fila SQS da sua conta de destino no tópico SNS para receber notificações sobre o local do estágio.
Se você usar o Amazon S3 Event Notifications com o Amazon Simple Queue Service (SQS), siga as instruções em Etapa 4: configurar notificações de eventos.
Importante
Para garantir que o canal não tenha perdido nenhuma notificação, você deve atualizá-lo após mudar para a nova fila SQS.
Você também pode migrar de SQS para SNS. Para obter mais informações, consulte Migração para Amazon Simple Notification Service (SNS).
Se você usar o Amazon Simple Notification Service (SNS), consulte Inscrição na fila Snowflake SQS em seu tópico SNS.
Se você usar Amazon EventBridge, consulte Opção 3: configuração do Amazon EventBridge para automatizar o Snowpipe.
Armazenamento de Blobs do Microsoft Azure¶
Um canal que carrega automaticamente dados de arquivos localizados em um estágio no armazenamento de blobs do Microsoft Azure requer uma assinatura de Event Grid, uma fila de armazenamento e uma integração de notificação vinculada à fila de armazenamento. Um canal secundário em uma conta de destino precisa de um Event Grid separado, uma fila de armazenamento e uma integração de notificação vinculada à fila de armazenamento. O Event Grid nas contas de origem e de destino deve ser configurado como pontos de extremidade para a mesma fonte de armazenamento do Azure.
Consulte o diagrama abaixo para detalhes de configuração:
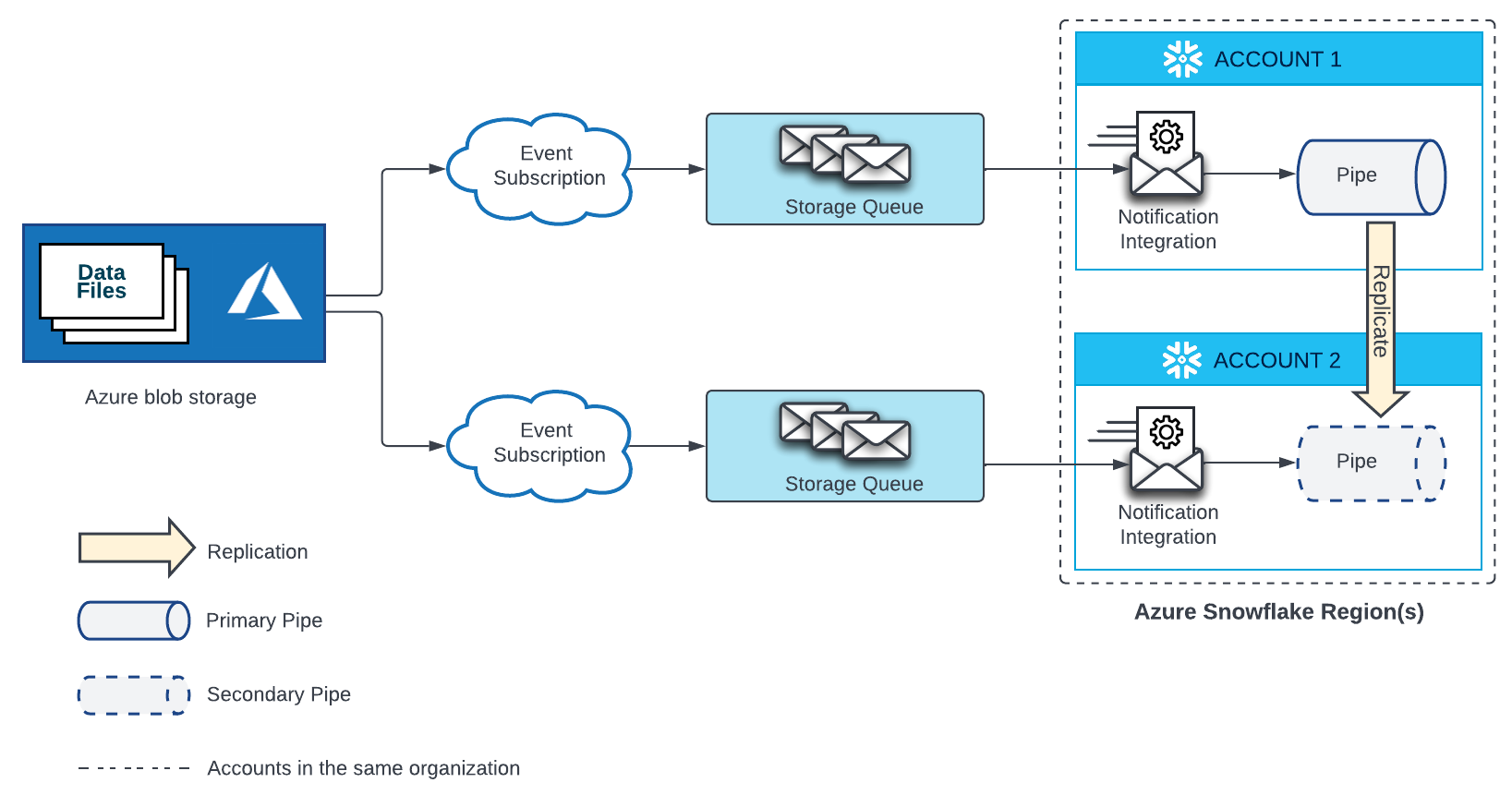
Crie uma nova assinatura do Event Grid e uma fila de armazenamento. Em seguida, crie uma nova integração de notificação na conta de destino e conceda ao Snowflake acesso à sua fila de armazenamento. Para obter instruções, consulte Configuração da automação com a Event Grid do Azure.
Importante
O nome da integração de notificação em cada conta de destino deve corresponder ao nome da integração de notificação na conta de origem.
Estágio externo para Google Cloud Storage¶
Um canal que carrega automaticamente dados de arquivos localizados no Google Cloud Storage requer uma assinatura do Google Pub/Sub e uma integração de notificação que faça referência a essa assinatura. Cada canal replicado em uma conta de destino também requer uma assinatura do Google Pub/Sub e uma integração de notificação que faça referência a essa assinatura. A assinatura do Pub/Sub em cada conta de origem e de destino precisa estar inscrita no mesmo tópico do Pub/Sub que recebe notificações da origem do Google Cloud Storage.
Consulte o diagrama abaixo para detalhes de configuração:
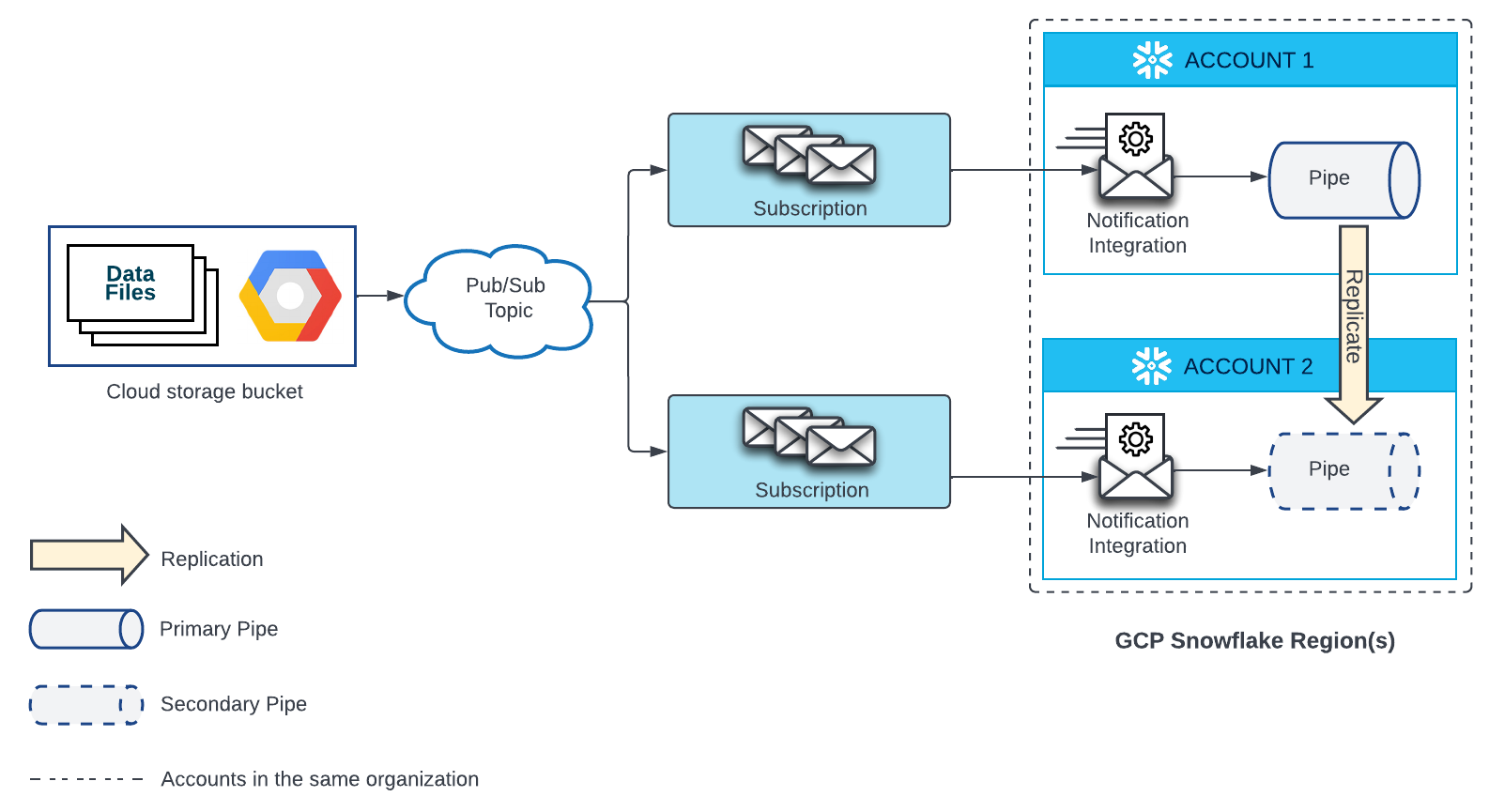
- Crie uma nova assinatura para seu tópico do Pub/Sub e uma nova integração de notificação em sua conta de destino.
Depois, conceda acesso do Snowflake à assinatura Pub/Sub. Para obter instruções, consulte Configuração da automação usando GCS Pub/Sub.
Importante
O nome da integração de notificação em cada conta de destino deve corresponder ao nome da integração de notificação na conta de origem.
Atualização do serviço remoto para integrações de API¶
Se você tiver ativado a replicação de integração de API, etapas adicionais serão necessárias após a replicação da integração API para a conta de destino. A integração replicada tem sua própria identidade e gerenciamento de acesso (IAM) que são diferentes da identidade e entidade IAM da integração primária. Portanto, você deve atualizar as permissões do serviço remoto para conceder acesso às funções replicadas. O processo é semelhante à concessão de acesso às funções na conta primária. Consulte os links abaixo para obter mais detalhes:
Amazon Web Services Defina a(s) relação(ões) de confiança entre o Snowflake e a nova função IAM.
Google Cloud Platform: criar uma política de segurança do GCP para o serviço de proxy.
Microsoft Azure:
Etapa 2. Criar uma política Validar JWT
Comparação de conjuntos de dados em bancos de dados primários e secundários¶
O Snowflake realiza verificações automáticas como parte de cada operação de atualização de replicação. Se ocorrer uma falha na verificação, a atualização falhará. Portanto, você não precisa verificar manualmente os dados replicados. Se você precisar de verificação adicional por motivos de conformidade, poderá executar etapas de verificação manual após a conclusão da operação de atualização.
Verificação automática pelo Snowflake¶
O Snowflake atualmente realiza as seguintes verificações entre a conta primária e a secundária, após cada operação de atualização:
O Snowflake compara os valores de hash entre a conta primária e a secundária para todos os arquivos que foram replicados.
Para cada tabela, o Snowflake compara os seguintes valores entre a conta primária e a secundária:
Contagem de arquivos.
Contagem de linhas.
Contagem de bytes.
Verificação manual¶
Se os objetos do banco de dados forem replicados em um grupo de replicação ou failover, você poderá usar a função HASH_AGG para comparar as linhas em algumas ou todas as tabelas em um banco de dados primário e secundário para verificar a consistência dos dados. A função HASH_AGG retorna um valor de hash de 64 bits com sinal agregado sobre o conjunto de linhas de entrada. O valor de hash é o mesmo, independentemente da ordem das linhas de entrada.
Consulte essa função em todas as tabelas, ou em um subconjunto aleatório de tabelas, tanto na conta secundária quanto na primária. Na conta primária, use uma cláusula AT | BEFORE para especificar o momento da última atualização do banco de dados associado. Compare a saída entre as consultas em ambas as contas.
Exemplo de verificação manual de dados após uma atualização¶
Nos exemplos a seguir, o banco de dados mydb está incluído no grupo de failover myfg. O banco de dados mydb contém a tabela myschema.mytable.
Comandos a serem executados na conta de destino¶
Consulte a função de tabela REPLICATION_GROUP_REFRESH_PROGRESS (no Snowflake Information Schema). Observe o
primarySnapshotTimestampna colunaDETAILSpara a fasePRIMARY_UPLOADING_METADATA. Esse é o carimbo de data/hora referente à última atualização desse banco de dados na conta primária.Consulte a função HASH_AGG para uma tabela específica da conta secundária. A seguinte consulta retorna um valor de hash para todas as linhas da tabela
myschema.mytable:
Comandos a serem executados na conta de origem¶
Consulte a função HASH_AGG para a mesma tabela da conta primária. Usando o Time Travel, especifique o carimbo de data/hora de quando o último instantâneo do banco de dados secundário foi tirado:
Compare os resultados das duas consultas. A saída deve ser idêntica.
Modificação de um grupo de replicação ou failover em uma conta de origem¶
É possível editar o nome, os objetos inclusos e o cronograma de replicação de um grupo de replicação ou failover em uma conta de origem usando o Snowsight ou SQL.
Nota
Os grupos de replicação não podem ser alterados para grupos de failover ou vice-versa. Para ativar ou desativar o failover, exclua o grupo e recrie-o com a configuração de failover correta.
Modificação de um grupo de replicação ou failover em uma conta de origem usando o Snowsight¶
Nota
Somente administradores de conta podem editar um grupo de replicação ou failover usando Snowsight (consulte Limitações do uso do Snowsight para configuração de replicação).
Para executar essas ações, é necessário estar conectado à conta de origem. Se você não estiver conectado, a coluna Status exibirá uma mensagem de login em vez do status de atualização.
Faça login no Snowsight.
No menu de navegação, selecione Admin » Accounts.
Selecione Replication e depois selecione Groups.
Localize o grupo de replicação ou failover que deseja editar e selecione o menu More (…) na última coluna da linha.
Selecione Edit.
Para alterar o nome do grupo, insira um novo nome na caixa Group name que atenda aos seguintes requisitos:
Deve começar com um caractere alfabético e não pode conter espaços ou caracteres especiais, a menos que a cadeia de caracteres do identificador esteja entre aspas duplas (por exemplo, «My object»). Os identificadores delimitados por aspas duplas também diferenciam letras maiúsculas de minúsculas.
Para obter mais informações, consulte Requisitos para identificadores.
Nomes para grupos de failover e grupos de replicação em uma conta devem ser únicos.
Escolha Edit objects para adicionar ou remover objetos de conta e compartilhamento.
Nota
Os objetos de conta só podem ser adicionados a um grupo de replicação ou failover. Se um grupo de replicação ou failover com qualquer objeto de conta já existir em sua conta, você não poderá selecionar esses objetos.
Escolha Select databases para adicionar ou remover objetos de banco de dados.
Selecione Replication frequency para alterar a programação de replicação de um grupo.
Selecione Save para atualizar o grupo.
Se não for possível salvar as alterações no grupo, consulte Solução de problemas de criação e edição de grupos de replicação usando Snowsight para ver erros comuns e como resolvê-los.
Modificação de um grupo de replicação ou failover em uma conta de origem usando SQL¶
Você pode modificar as propriedades de um grupo de replicação ou failover usando o comando ALTER REPLICATION GROUP ou ALTER FAILOVER GROUP.
Como pausar ou retomar um cronograma de replicação em uma conta de destino¶
É possível pausar (suspender) ou retomar um cronograma de replicação em uma conta de destino usando o Snowsight ou SQL.
Como pausar ou retomar um cronograma de replicação em uma conta de destino usando o Snowsight¶
Nota
Somente administradores de conta podem editar um grupo de replicação ou failover usando Snowsight (consulte Limitações do uso do Snowsight para configuração de replicação).
Para pausar ou retomar um cronograma de replicação, é necessário estar conectado à conta de destino.
Faça login no Snowsight.
No menu de navegação, selecione Admin » Accounts.
Selecione Replication e depois selecione Groups.
Localize o grupo de replicação ou failover que deseja editar e selecione o menu More (…) na última coluna da linha.
Selecione Pause ou Resume.
Como pausar ou retomar um cronograma de replicação em uma conta de destino usando SQL¶
É possível pausar ou retomar um cronograma de replicação em uma conta de destino usando o comando ALTER REPLICATION GROUP ou ALTER FAILOVER GROUP. Para pausar, especifique o parâmetro SUSPEND. Para retomar, especifique o parâmetro RESUME.
Descarte de um grupo secundário de replicação ou failover¶
Você pode descartar uma replicação ou failover secundário usando o comando DROP REPLICATION GROUP ou DROP FAILOVER GROUP. Somente o proprietário do grupo de replicação ou failover (ou seja, a função com o privilégio OWNERSHIP no grupo) pode eliminar o grupo.
Para descartar um grupo de failover ou replicação secundária usando Snowsight, você deve descartar o grupo na conta de origem. Consulte Descarte de um grupo de replicação ou failover usando o Snowsight.
Descarte de um grupo primário de replicação ou failover¶
Você pode descartar um grupo de failover ou replicação primária usando Snowsight ou SQL. Se você estiver excluindo um grupo primário usando SQL, primeiro deverá descartar todos os grupos secundários. Consulte Descarte de um grupo secundário de replicação ou failover.
Descarte de um grupo primário de failover ou replicação usando SQL¶
Um grupo primário de replicação ou failover só pode ser descartado depois que todas as réplicas do grupo (ou seja, grupos secundários de replicação ou failover) tiverem sido descartadas. Como alternativa, você pode promover um grupo de failover secundário para servir como o grupo de failover primário e, em seguida, descartar o antigo grupo de failover primário.
Note que somente o proprietário do grupo pode descartar o grupo.
Descarte de um grupo de replicação ou failover usando o Snowsight¶
Nota
Somente administradores de conta podem excluir um grupo de replicação ou failover usando Snowsight (consulte Limitações do uso do Snowsight para configuração de replicação).
Você pode excluir um grupo de replicação primária ou de failover e quaisquer grupos secundários vinculados.
Faça login no Snowsight.
No menu de navegação, selecione Admin » Accounts.
Selecione Replication, selecione Groups.
Localize o grupo de replicação ou failover que você deseja excluir. Selecione o menu More (…) na última coluna da linha.
Selecione Drop e depois selecione Drop group.
Solução de problemas de criação e edição de grupos de replicação usando Snowsight¶
Os cenários a seguir podem ajudar você a solucionar problemas comuns que podem ocorrer ao criar ou editar o grupo de replicação ou failover usando Snowsight.
Você não consegue adicionar um banco de dados a um grupo¶
Erro |
|
|---|---|
Causa |
Um banco de dados só pode estar em um grupo de replicação ou failover. Um dos bancos de dados selecionados para o grupo já está incluído em outro grupo de replicação ou failover. |
Solução |
Escolha Select Databases e desmarque todos os bancos de dados que já estão incluídos em outro grupo. |
Erro |
|
|---|---|
Causa |
O banco de dados que você deseja adicionar a um grupo de replicação ou failover foi configurado anteriormente para replicação de banco de dados. |
Solução |
Desabilite a replicação do banco de dados para o banco de dados. Consulte Transição da replicação de banco de dados para a replicação baseada em grupos. |
Limitações do uso do Snowsight para configuração de replicação¶
Somente um usuário com a função ACCOUNTADMIN pode criar um grupo de replicação ou failover usando Snowsight. Um usuário com uma função com privilégio CREATE REPLICATION GROUP ou CREATE FAILOVER GROUP pode criar um grupo usando os respectivos comandos SQL.
Somente um usuário com a função ACCOUNTADMIN pode editar ou descartar um grupo de replicação ou failover usando Snowsight. Um usuário com uma função com privilégio OWNERSHIP em um grupo de replicação ou failover pode editar e descartar grupos usando os respectivos comandos SQL.
Se sua conta usa conectividade privada, você não pode usar o Snowsight para criar, modificar ou eliminar grupos. Você pode usar SQL para concluir essas ações.