複数のアカウント間にわたるデータベースとアカウントオブジェクトの複製¶
このトピックでは、同じ組織内のSnowflakeアカウント間でアカウントオブジェクトとデータを複製し、オブジェクトとデータの同期を維持するために必要なステップについて説明します。アカウント複製は、異なる リージョン のSnowflakeアカウント間および クラウドプラットフォーム 間で発生する可能性があります。
注釈
アカウントをBusiness Critical Edition(またはそれ以上)にアップグレードした場合、フェールオーバー機能が利用可能になるまで最大12時間かかる場合があります。
複製とフェールオーバー/フェールバックのリージョンサポート¶
お客様は、リージョングループ内のリージョン全域で複製できます。異なる リージョングループ のリージョン間で複製するには(例:Snowflake商用リージョンからSnowflake政府リージョンへ)、 Snowflakeサポート に連絡してアクセスを有効にしてください。
データベース複製からグループベース複製への移行¶
ALTER DATABASE を使用して複製が有効になっているデータベースは、複製またはフェールオーバーグループに追加する 前に 複製を無効にする必要があります。
注釈
ACCOUNTADMIN ロールを使用して、このセクションの SQL ステートメントを実行します。
ステップ1:複製が有効なデータベースの複製を無効にする¶
複製またはフェールオーバーグループに追加するために、 SYSTEM$DISABLE_DATABASE_REPLICATION 関数を実行して、プライマリデータベースとそれにリンクされているセカンダリデータベースの複製を無効にします。
プライマリデータベースのソースアカウントから次の SQL ステートメントを実行します。
ステップ2.データベースをプライマリフェールオーバーグループに追加し、セカンダリフェールオーバーグループを作成する¶
データベースの複製を正常に無効にすると、プライマリデータベースをソースアカウントのフェールオーバーグループに追加できます。
次に、ターゲットアカウントにセカンダリフェールオーバーグループを作成します。セカンダリフェールオーバーグループがターゲットアカウントで更新されると、以前のセカンダリデータベースがセカンダリフェールオーバーグループのメンバーとして自動的に追加され、プライマリデータベースからの変更で更新されます。
プライマリおよびセカンダリフェールオーバーグループの作成の詳細については、 ワークフロー をご参照ください。
注釈
以前に複製されたデータベースを複製またはフェールオーバーグループに追加すると、Snowflakeはそのデータベースに対してすでに複製されたデータを再複製 しません。グループが更新されると、最後の更新以降の変更のみが複製されます。
ワークフロー¶
次の SQL ステートメントは、アカウントとデータベースオブジェクトの複製を有効にし、オブジェクトを更新するためのワークフローを示しています。各ステップについては、以下で詳しく説明します。
注釈
次の例では、ソースアカウントとターゲットアカウントに対して複製を有効にする必要があります。詳細については、 前提条件: 組織内のアカウントの複製を有効にする をご参照ください。
例¶
希望するSnowflakeクライアントで次の SQL ステートメントを実行して、アカウントとデータベースオブジェクトの複製とフェールオーバーを有効にし、オブジェクトを更新します。
ソースアカウントでの実行¶
ロールを作成し、それに CREATE FAILOVER GROUP 権限を付与します。このステップは オプション です。
ソースアカウントにフェールオーバーグループを作成し、特定のターゲットアカウントへの複製を有効にします。
注釈
以前に ALTER DATABASE を使用して、データベースの複製とフェールオーバーが有効になっている複製またはフェールオーバーグループに追加するデータベースがある場合は、グループに追加する前に、 データベース複製からグループベース複製への移行 (このトピック内)の手順に従います。
データベースをフェールオーバーグループに追加するには、データベースに対する MONITOR 権限がアクティブなロールに必要です。データベース権限の詳細については、 データベース権限 (別のトピック内)をご参照ください。
ターゲットアカウントでの実行¶
ターゲットアカウントにロールを作成し、それに CREATE FAILOVER GROUP 権限を付与します。このステップは オプション です。
ソースアカウントのフェールオーバーグループのレプリカとして、ターゲットアカウントにフェールオーバーグループを作成します。
注釈
ソースアカウントに存在しないアカウントオブジェクト(ユーザーやロールなど)がターゲットアカウントに存在する場合は、セカンダリグループを作成する前に ユーザーおよびロールの初期複製 を参照してください。
セカンダリフェールオーバーグループを手動で更新します。これは オプション のステップです。複製スケジュールを使用してプライマリフェールオーバーグループが作成されている場合は、セカンダリフェールオーバーグループの作成時に、セカンダリフェールオーバーグループの初期更新が自動的に実行されます。
フェールオーバーグループに対する REPLICATE 権限を持つロールを作成します。このステップは オプション です。
フェールオーバーグループに対する OWNERSHIP 権限を持つロールを使用して、ターゲットアカウントで実行します。
REPLICATE 権限を持つロールを使用して更新ステートメントを実行します。
フェールオーバーグループに対する FAILOVER 権限を持つロールを作成します。このステップは オプション です。
フェールオーバーグループに対する OWNERSHIP 権限を持つロールを使用して、ターゲットアカウントで実行します。
アカウントオブジェクトとデータベースの複製¶
このセクションの手順では、アカウントを複製用に準備する方法、ソースアカウントからターゲットアカウントに特定のオブジェクトを複製できるようにする方法、およびターゲットアカウントのオブジェクトを同期する方法について説明します。
重要
ターゲットアカウントでは、 Tri-Secret Secure またはSnowflakeサービスへのプライベート接続(AWS PrivateLink など)がデフォルトで有効になっていません。コンプライアンス、セキュリティ、またはその他の目的でSnowflakeサービスへの Tri-Secret Secure またはプライベート接続が必要な場合、ターゲットアカウントでこれらの機能を構成して有効にするのはユーザーの責任です。
前提条件: 組織内のアカウントの複製を有効にする¶
組織管理者は、ソースアカウントとターゲットアカウントの複製を有効にする必要があります。
アカウントの複製を有効にするには、 組織管理者 が SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER 関数を使用して ENABLE_ACCOUNT_DATABASE_REPLICATION パラメーターを true に設定します。
組織管理者として、組織内の各ソースおよびターゲットアカウントに対して複製を有効にします。
SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER 関数は従来の アカウントロケーター 識別子をサポートしていますが、組織が同じロケーターを共有する複数のアカウントを(異なるリージョンで)持つ場合は、予期しない結果が生じます。
ステップ1: ソースアカウントに CREATE FAILOVER GROUP 権限を持つロールを作成する --- オプション¶
ロールを作成し、それに CREATE FAILOVER GROUP 権限を付与します。このステップはオプションです。このロールをすでに作成している場合は、 ステップ3: ソースアカウントでプライマリのフェールオーバーグループを作成する にスキップします。
ステップ2: 複製とグループメンバーシップが有効になっているアカウントを特定する¶
プライマリフェールオーバーグループを作成する前に、複製が有効になっているアカウント、既存のフェールオーバーグループと複製グループを特定しておきます。
複製が有効になっているすべてのアカウントを表示する¶
複製が有効になっている組織内のアカウントのリストを取得するには、 SHOW REPLICATION ACCOUNTS を使用します。
ACCOUNTADMIN ロールを使用して次の SQL ステートメントを実行します。
戻り値:
地域 IDs の包括的なリストをご参照ください。
フェールオーバーと複製グループのメンバーシップを表示する¶
アカウント、データベース、および共有オブジェクトには、 グループメンバーシップの制約 があります。新しいグループを作成したり、既存のグループにオブジェクトを追加したりする前に、既存のフェールオーバーグループと各グループのオブジェクトのリストを確認できます。
注釈
このセクションの SQL ステートメントを実行できるのは、アカウント管理者(ACCOUNTADMIN ロールを持つユーザー)またはグループ所有者(グループに対する OWNERSHIP 権限を持つロール)のみです。
現在のアカウントにリンクされているすべてのフェールオーバーグループと、各グループのオブジェクト型を表示します。
フェールオーバーグループ myfg 内のすべてのデータベースを表示します。
フェールオーバーグループ myfg 内のすべての共有を表示します。
ステップ3: ソースアカウントでプライマリのフェールオーバーグループを作成する¶
プライマリフェールオーバーグループを作成し、現在の(ソース)アカウントから同じ組織内にある1つ以上のターゲットアカウントに、特定のオブジェクトを複製およびフェールオーバーできるようにします。
複製グループやフェイルオーバーグループは、 Snowsight または SQL を使用して作成できます。
注釈
以前に ALTER DATABASE を使用してデータベース複製が有効になっている複製またはフェールオーバーグループに追加するデータベースがある場合は、グループに追加する前に、 データベース複製からグループベース複製への移行 (このトピック内)の手順に従います。
Snowsightを使用した複製グループまたはフェールオーバーグループを作成する¶
注釈
Snowsight を使用して複製グループまたはフェイルオーバーグループを作成できるのは、アカウント管理者のみです (複製設定にSnowsightを使用する場合の制限事項 を参照)。
ACCOUNTADMIN ロールを持つユーザーとしてターゲットアカウントにサインインする必要があります。そうでない場合は、サインインするよう促されます。
ソースアカウントとターゲットアカウントは、両方とも同じ接続タイプ(パブリックインターネット)を使用する必要があります。それ以外の場合、ターゲットアカウントへのサインインは失敗します。
新しい複製グループまたはフェイルオーバーグループを作成するには、次のステップを完了します。
Snowsight にサインインします。
ナビゲーションメニューで Admin » Accounts を選択します。
Replication を選択し、 Groups タブで以下のいずれかのアクションを完了します。
Business Critical Edition(またはそれ以上)のアカウントの場合は、以下のいずれかのアクションを完了します。
複製グループや接続がない場合は、 Get started を選択して複製グループと接続を設定します。Setup business continuity ウィザードが表示されます。
接続を設定せずに複製グループを設定する場合は、 + Group を選択します。Create a group ウィザードが表示されます。
Standard EditionおよびEnterprise Editionのアカウントの場合は、以下のいずれかのアクションを完了します。
複製グループまたは接続がない場合は、 Get started を選択して複製グループを設定します。Setup replication ウィザードが表示されます。
複製グループが1つまたはそれ以上存在する場合は、 + Group を選択して複製グループを設定します。Create a group ウィザードが表示されます。
Select a target account ページでターゲットアカウントを選択してサインインしてから、 Next を選択します。
Create a group ページの Group name ボックスに、以下の条件を満たすグループ名を入力します。
識別子文字列が二重引用符で囲まれていない限り(例えば、"My object")、アルファベット文字で始まる必要があり、スペースや特殊文字を含めることはできません。二重引用符で囲まれた識別子も大文字と小文字が区別されます。
詳細については、 識別子の要件 をご参照ください。
アカウント内のフェイルオーバーグループおよび複製グループ間で一意である必要があります。
共有オブジェクトとアカウントオブジェクトをグループに追加するには、 Edit objects を選択します。
注釈
アカウントオブジェクトは、1つの複製グループまたはフェールオーバーグループにのみ追加できます。アカウントオブジェクトを持つ複製グループまたはフェイルオーバーグループがアカウントに既に存在する場合、それらのオブジェクトを選択することはできません。
Select databases を選択して、データベースオブジェクトをグループに追加します。
Replication frequency を選択します。
アカウントがBusiness Critical Edition以上の場合、デフォルトでフェイルオーバーグループが作成されます。代わりに複製グループを作成することもできます。複製グループを作成するには、 Advanced options を選択し、 Enable failover の選択を解除します。
以下のいずれかのアクションを完了します。
Business Critical Edition(またはそれ以上)のアカウントの場合は、 Next を選択します。
Standard EditionおよびEnterprise Editionのアカウントの場合は、 Start replication を選択して複製グループを作成します。
Business Critical Edition(またはそれ以上)のアカウントの場合は、 Create connection ページで Connection name ボックスに接続名を入力してから Start replication を選択します。
複製グループの作成に失敗した場合は、一般的なエラーとその解決方法について Snowsightを使用した複製グループの作成と編集に関する問題のトラブルシューティング を参照してください。
SQL を使用してフェールオーバーグループを作成する¶
ソースアカウントに指定されたアカウントとデータベースオブジェクトのフェールオーバーグループを作成し、ターゲットアカウントのリストへの複製とフェールオーバーを有効にします。構文については、 CREATE FAILOVER GROUP をご参照ください。
たとえば、同じ組織内のソースアカウントから myaccount2 アカウントへのユーザー、ロール、ウェアハウス、リソースモニター、およびデータベース db1 および db2 の複製を有効にします。10分ごとに myaccount2 を自動的に更新するように複製スケジュールを設定します。
ソースアカウントで次のステートメントを実行します。
ステップ4: ターゲットアカウントでCREATE FAILOVER GROUP権限を持つロールを作成する --- オプション¶
ターゲットアカウントにロールを作成し、それに CREATE FAILOVER GROUP 権限を付与します。このステップはオプションです。このロールをすでに作成している場合は、 ステップ5: ターゲットアカウントでセカンダリのフェールオーバーグループを作成する にスキップします。
ステップ5: ターゲットアカウントでセカンダリのフェールオーバーグループを作成する¶
注釈
ソースアカウントに存在しないアカウントオブジェクト(ユーザーやロールなど)がターゲットアカウントに存在する場合は、セカンダリグループを作成する前に ユーザーおよびロールの初期複製 を参照してください。
ソースアカウントにあるプライマリフェールオーバーグループのレプリカとして、ターゲットアカウントにセカンダリフェールオーバーグループを作成します。
ステップ3: ソースアカウントでプライマリのフェールオーバーグループを作成する (このトピック内)で複製を有効にした各ターゲットアカウントで、 CREATE FAILOVER GROUP...AS REPLICA OF ステートメントを実行します。
各ターゲットアカウントから実行:
ステップ6: ターゲットアカウントでセカンダリのフェールオーバーグループを手動で更新する --- オプション¶
ターゲットアカウント内のオブジェクトを手動で更新するには、 ALTER FAILOVER GROUP...REFRESH コマンドを実行します。
ベストプラクティスとして、 CREATE FAILOVER GROUP または ALTER FAILOVER GROUP を使用して REPLICATION_SCHEDULE パラメーターを設定することにより、セカンダリの更新をスケジュールするようにお勧めします。
注釈
ターゲットアカウントで関数を呼び出したユーザーがソースアカウントでドロップされた場合は、更新操作に失敗します。
フェールオーバーグループの REPLICATE 権限をロールに付与する --- オプション¶
コマンドを実行してターゲットアカウントのセカンダリ複製またはフェールオーバーグループを更新するには、フェールオーバーグループに対する REPLICATE 権限を持つロールを使用する必要があります。現在、 REPLICATE 権限は複製 されない ため、ソースアカウントとターゲットアカウントの両方のフェールオーバー(または複製)グループで付与する必要があります。
グループに対する OWNERSHIP 権限を持つロールを使用して、このステートメントをソースアカウントから実行します。
グループに対する OWNERSHIP の権限を持つロールを使用して、このステートメントをターゲットアカウントから実行します。
セカンダリフェールオーバーグループを手動で更新する¶
たとえば、フェールオーバーグループ myfg 内のオブジェクトを更新するには、ターゲットアカウントから次のステートメントを実行します。
ステップ7。フェールオーバーグループのFAILOVER権限をロールに付与する --- オプション¶
コマンドを実行してターゲットアカウントのセカンダリフェールオーバーグループをフェールオーバーするには、フェールオーバーグループに対する FAILOVER 権限 を持つロールを使用する必要があります。FAILOVER 権限は現在複製 されず、ソースとターゲットの各アカウントで付与する必要があります。
詳細については、 ロールと付与の複製 をご参照ください。
例えば、フェールオーバーグループ my_fg 上のロール my_failover_role に FAILOVER 権限を付与するには、 ターゲットアカウント で、グループ上の OWNERSHIP 権限を持つロールを使用して、以下のステートメントを実行します。
指定された権限のセットを使用してカスタムロールを作成する手順については、 カスタムロールの作成 をご参照ください。
セキュリティ保護可能なオブジェクト に対して SQL アクションを実行するためのロールと権限付与に関する一般的な情報については、 アクセス制御の概要 をご参照ください。
フェールオーバーグループのスキーマレベルの複製¶
フェールオーバーグループ内のデータベースに対して、オプションでREPLICABLE_WITH_FAILOVER_GROUPSパラメーターをデータベースまたはデータベース内の個々のスキーマに設定して、複製するスキーマのサブセットを指定することができます。
この機能により、複製されるフェールオーバーグループ内のスキーマを制御できるようになります。データベース内の任意のデータサブセットに対してのみフェールオーバーで提供される追加のディザスタリカバリ保護を必要とする場合に便利です。
このパラメーターはデフォルトですべてのデータベースとそのデータベースに含まれるスキーマに対して有効になっているため、複製から除外するデータベースやスキーマを選択することで複製の設定を細かく調整できます。スキーマを含んでいるデータベースが複製されない設定であっても、その特定のスキーマは複製するよう複製の設定値をさらに細かく調整できます。
複製または省略するスキーマの指定¶
オプション のREPLICABLE_WITH_FAILOVER_GROUPSパラメーターを使用して、フェールオーバーグループ内の任意のデータベースで複製または省略するスキーマを明示的に指定できます。
REPLICABLE_WITH_FAILOVER_GROUPS パラメーター¶
REPLICABLE_WITH_FAILOVER_GROUPSパラメーターは、フェールオーバーグループ内のデータベースに属するスキーマを複製するかどうかを指定します。このパラメーターはデータベースおよびデータベース内のすべてのスキーマに設定できます。このパラメーターをデータベースに設定した場合、いずれかのスキーマに異なる値が明示的に設定されていない限り、データベース内のすべてのスキーマがその値を継承します。
パラメーターには、 'YES' または 'NO' の2つの値(大文字と小文字を区別しない)を指定できます(オプション)。
データベースでREPLICABLE_WITH_FAILOVER_GROUPSが明示的に設定されていない(または明示的に設定が解除されている)場合、データベースは標準の複製動作に従います。これは、パラメーターを
'YES'に設定することと同じです。スキーマにREPLICABLE_WITH_FAILOVER_GROUPSが明示的に設定されていない(あるいは明示的に設定が解除されている)場合、複製動作は親データベースから継承されます。
セキュリティ要件¶
このパラメーターをデータベースまたはスキーマに設定する、または設定解除するには、以下の権限が必要です。
REPLICATE(アカウントレベルの権限)。スキーマレベルの複製機能より以前では、この権限は複製グループとフェールオーバーグループに対するオブジェクトレベルの権限でしかありませんでした。ACCOUNTADMINロールを持つユーザーは、この権限を他のロールに付与することができます。
USAGE(データベース と スキーマ の権限)またはデータベースとスキーマでアクションを起こすことができる類似の権限。
例¶
既存のロールに必要な権限を付与する、 replicationadmin:
1つのスキーマ( sch1 )を db1 データベースで複製する:
1つのスキーマ( sch2 )を除きすべてのスキーマを db2 データベースで複製する:
REPLICABLE_WITH_FAILOVER_GROUPSがターゲットアカウントで設定されているスキーマの更新¶
データベースの更新時:
REPLICABLE_WITH_FAILOVER_GROUPSが
'YES'に設定されているスキーマは、ソースアカウントからターゲットアカウントに複製されます。REPLICABLE_WITH_FAILOVER_GROUPSが
'NO'に設定されているスキーマは複製されません(以下の2つの状況を除く):ターゲットスキーマがソースアカウントのスキーマの複製になる場合。この場合、ターゲットスキーマは常にそのソーススキーマと同期が行われます。
ターゲットスキーマ名がソースアカウントのスキーマ名と競合している場合。この場合、名前の競合が原因で複製のジョブは失敗します。
アカウントにREPLICABLE_WITH_FAILOVER_GROUPSが設定されているデータベースとスキーマのリスト¶
ACCOUNT_USAGEおよびINFORMATION_SCHEMAビューをクエリすることで、現在のアカウントのREPLICABLE_WITH_FAILOVER_GROUPSパラメーターに設定された値をリストすることができます。
Tip
ACCOUNT_USAGE、INFORMATION_SCHEMAの各ビューを使用する理由については、 Account UsageとInformation Schemaの違い をご覧ください。
例¶
これらの例では、INFORMATION_SCHEMAビューを使用します。そうすることで、変更後すぐに設定を確認することができます。
既存の replicationadmin ロールを使用すると、2つのデータベースを持つアカウントのすべてのパラメーター値が返されます。
db1データベース、明示的にNOに設定されデータベース内のsch1スキーマは明示的にYESに設定されています。複製対象となるのは、データベース内のこの1つのスキーマのみです。db2データベース、明示的にYESに設定されデータベース内のsch2スキーマは明示的にNOに設定されています。このスキーマを除いて、データベース内のすべてのスキーマが複製対象になります。
ターゲットアカウントのスクリプトによって作成されたオブジェクトにグローバル IDs を適用する¶
複製 以外の 方法(スクリプトを使用するなど)でターゲットアカウントにアカウントオブジェクト(ユーザーやロールなど)を作成した場合、これらのユーザーやロールには既定のグローバル識別子がありません。更新操作は、グローバル識別子を使用して、これらのオブジェクトをソースアカウント内の同じオブジェクトに同期します。
大半の場合、ターゲットアカウントがソースアカウントからリフレッシュされると、リフレッシュ操作により、グローバル識別子を持たないターゲットアカウント内の OBJECT_TYPES リストにあるすべてのアカウントオブジェクト型が ドロップ されます。ただし、ターゲットアカウントへのユーザーとロールの最初の複製では、初期のリフレッシュ操作に失敗する可能性があります。この動作に関する詳細については、 ユーザーおよびロールの初期複製 をご参照ください。
SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME() を使用してグローバル IDs を適用する¶
ソースアカウントとターゲットアカウントで同名の一致するオブジェクトをリンクすると、一部のオブジェクト型の欠落を防ぐことができます。SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 関数は、グローバル識別子をターゲットのアカウントオブジェクトに追加します。
注釈
グローバル識別子は、次のオブジェクト型の複製またはフェールオーバーグループに含まれるアカウントオブジェクトにのみ追加されます。
RESOURCE_MONITORROLEUSERWAREHOUSE
グローバル識別子を、フェールオーバーグループ myfg の object_types リストに含まれる型のターゲットアカウント内にあるアカウントオブジェクトに適用します。
ACCOUNTADMIN ロールを使用して次の SQL ステートメントを実行します。
ユーザーおよびロールの初期複製¶
USERS および ROLES オブジェクト型の初期リフレッシュ操作の動作は、ターゲットアカウントに同名の一致するオブジェクトがあるかどうかによって異なる場合があります。
注釈
このセクションで説明する動作は、これらのオブジェクト型がターゲットアカウントに複製される 最初 の回にのみ適用されます。
以下のシナリオでは、 USERS の複製について説明します。ROLES の複製も同様です。
ソースアカウントにあるユーザーと同名のユーザーがターゲットアカウントに存在する場合は、初期リフレッシュ操作に失敗し、継続するために必要なオプション2つが説明されます。
リフレッシュ操作を強制し、ターゲットアカウントにある既存ユーザーのドロップを許可します。ソースアカウントにあるユーザーが、ターゲットアカウントに複製されます。
グループを強制的にリフレッシュするには、リフレッシュコマンドの FORCE パラメーターを使用します。たとえば、フェールオーバーグループを強制的にリフレッシュするには、以下のコマンドを実行します。
名前でアカウントオブジェクトをリンクします。SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 関数は、ターゲットアカウントとソースアカウントで同じ名前を持つユーザーをリンクします。リンクされているターゲットアカウントのユーザーは削除されません。
アカウントオブジェクトを名前でリンクするには、次のコマンドを実行します。
注釈
ソースアカウントに一致する名前の ない ターゲットアカウントのユーザーは、すべて ドロップ されます。
ソースアカウントにあるユーザーと同名のユーザーがターゲットアカウントに存在 しない 場合は、ターゲットアカウントでの初期リフレッシュ操作によりすべてのユーザーがドロップされます。これにより、データやメタデータが失われる可能性があります。
複製またはフェールオーバーグループの OBJECT_TYPES リストに USERS が含まれている場合は、
ワークシートが失われます。
クエリの履歴が失われます。
OBJECT_TYPES に USERS は含まれるが、 ROLES は含まれない場合は、
ユーザーへの権限付与が失われます。
OBJECT_TYPES に ROLES が含まれる場合は、
オブジェクトを共有するための権限付与は失われます。
ターゲットアカウントでユーザーまたはロールのドロップを回避するには、
初期複製の前に、ターゲットアカウントに のみ 存在するユーザーまたはロールを手動でソースアカウントに再作成します。
SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME 関数を使用して、両方のアカウントで同じ名前を持つオブジェクトをターゲットアカウントでリンクします。
セカンダリストレージ統合のためにクラウドストレージアクセスを構成する¶
ストレージ統合複製を有効にしている場合は、ストレージ統合がターゲットアカウントに複製された後に追加の手順を実行する必要があります。複製された統合には、プライマリ統合のIDおよび IAM エンティティとは異なる独自のIDおよびアクセス管理(IAM)エンティティがあります。したがって、クラウドプロバイダーの権限を更新して、複製された統合にクラウドストレージへのアクセス権を付与する必要があります。
この信頼関係の構成は、ターゲットアカウントに対して1回のみ行う必要があります。
このプロセスは、ソースアカウントでアクセスを許可するのと似ています。詳細については、次のページをご参照ください。
セカンダリステージでディレクトリテーブルの自動リフレッシュを構成する¶
外部ステージをディレクトリテーブルで複製し、ソースディレクトリテーブルに自動リフレッシュを構成した場合、セカンダリディレクトリテーブルに 自動リフレッシュ を構成する手順を実行する必要があります。
このプロセスは、ソースアカウントで自動リフレッシュを設定するのと似ています。詳細については、次をご参照ください。
Amazon S3: 構成プロセスは、イベント通知の設定方法に応じて異なります。
Amazon Simple Queue Service(SQS)でAmazon S3イベント通知を使用している場合は ステップ2: イベント通知を構成する の手順に従ってください。SQS から SNS に移行することもできます。詳細については、 Amazon Simple Notification Service(SNS)への移行 をご参照ください。
Amazon Simple Notification Service(SNS)を使用している場合は、 Snowflake SQS キューを SNS トピックにサブスクライブする をご参照ください。
Google Cloud Storage:Pub/Subトピックに新しいサブスクリプションを作成し、ターゲットアカウントに新しい通知統合を作成します。次に、SnowflakeにPub/Subサブスクリプションへのアクセス権を付与します。手順については、 Configure automation using GCS Pub/Sub をご参照ください。
Azure Blob Storage: 新しいEvent Gridサブスクリプションとストレージキューを作成します。次に、ターゲットアカウントで新しい通知統合を作成し、Snowflakeにストレージキューへのアクセス権を付与します。手順については、 Azure Event Gridを使用した自動化の構成 をご参照ください。
重要
ターゲットアカウントでこれらの構成手順を完了した後、ディレクトリテーブルの完全なリフレッシュを実行し、通知漏れがないことを確認する必要があります。
Google Cloud StorageとAzure Blob Storageの場合、各ターゲットアカウントの通知統合名は、ソースアカウントの通知統合名と一致する必要があります。
セカンダリ自動インジェストパイプの通知を構成する¶
フェールオーバーの前に、セカンダリ自動インジェストパイプのクラウド通知を構成するための追加の手順を実行する必要があります。このセクションでは、この追加構成が必要な理由と、サポートされている各クラウドプロバイダーで構成を完了する方法について説明します。
Amazon S3¶
構成プロセスは、イベント通知の設定方法に応じて異なります。たとえば、Snowflakeステージの場所に関するメッセージを公開するためにAmazon Simple Notification Service(SNS)トピックに依存する自動インジェストパイプがあるとします。
パイプをターゲットアカウントに複製すると、Snowflakeは自動的に新しいAmazon Simple Queue Service(SQS)キューを作成します。ステージの場所に関する通知を受け取るには、ターゲットアカウントのこの SQS キューを SNS トピックにサブスクライブする必要があります。
Amazon Simple Queue Service(SQS)でAmazon S3イベント通知を使用している場合は ステップ4: イベント通知を構成する の手順に従ってください。
重要
パイプが通知を見逃していないことを確認するために、新しい SQS キューに切り替えた後、パイプをリフレッシュする必要があります。
SQS から SNS に移行することもできます。詳細については、 Amazon Simple Notification Service(SNS)への移行 をご参照ください。
Amazon Simple Notification Service(SNS)を使用している場合は、 Snowflake SQS キューを SNS トピックにサブスクライブする をご参照ください。
Amazon EventBridgeを使用している場合は、 オプション3: Snowpipeを自動化するためにAmazon EventBridge を設定する をご参照ください。
Microsoft Azure Blob Storage¶
Microsoft Azure Blob Storageのステージにあるファイルからデータを自動的にロードするパイプには、Event Gridサブスクリプション、ストレージキュー、ストレージキューにバインドされた通知統合が必要です。ターゲットアカウントのセカンダリパイプには、個別のEvent Grid、ストレージキュー、ストレージキューにバインドされた通知統合が必要です。ソースアカウントとターゲットアカウントの両方のEvent Gridが、同じAzure Storageソースのエンドポイントとして構成されている必要があります。
構成の詳細については、下図を参照してください。
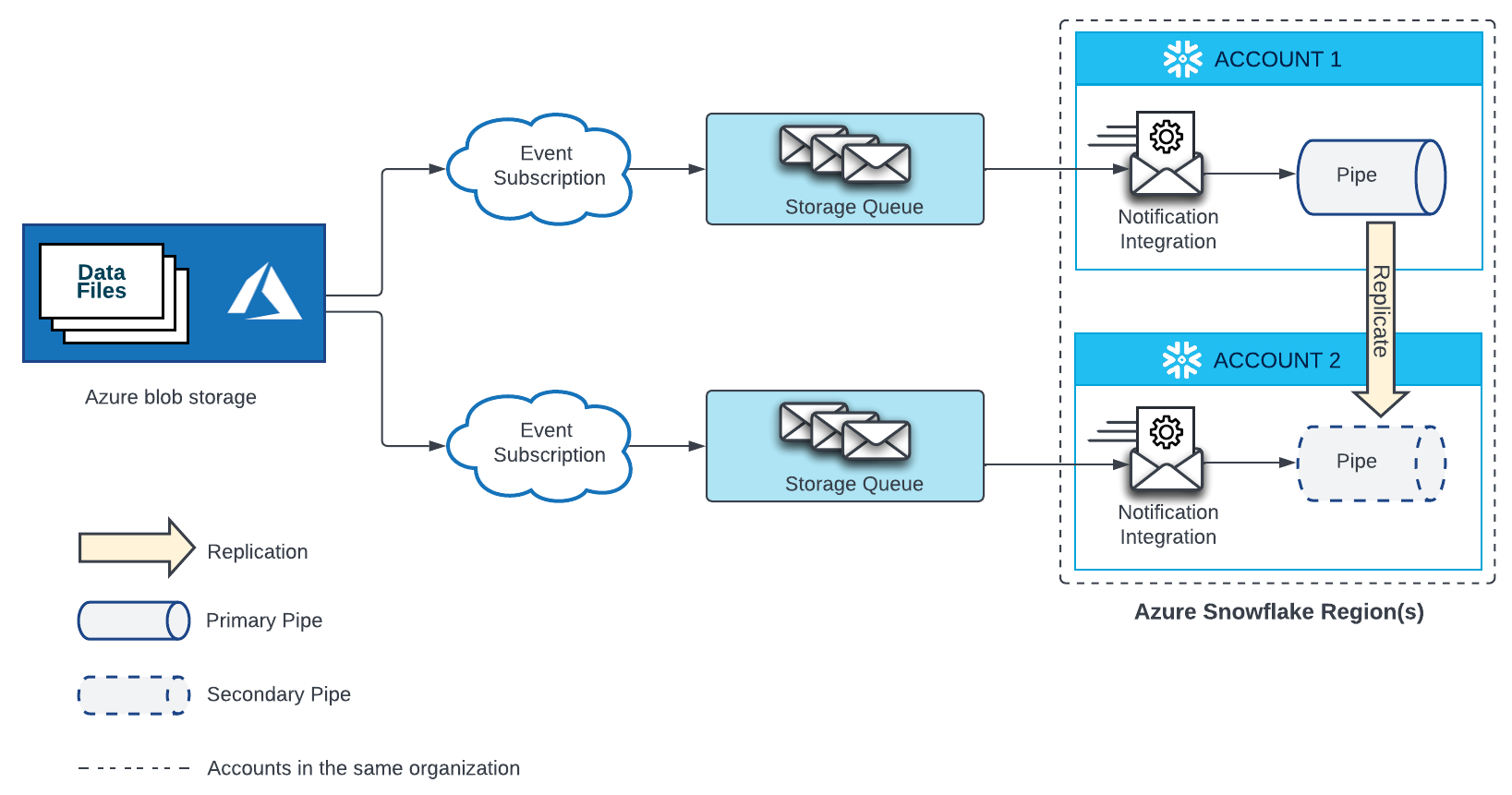
新しいEvent Gridサブスクリプションとストレージキューを作成します。次に、ターゲットアカウントで新しい通知統合を作成し、Snowflakeにストレージキューへのアクセス権を付与します。手順については、 Azure Event Gridを使用した自動化の構成 をご参照ください。
重要
各ターゲットアカウントの通知統合の名前は、ソースアカウントの通知統合の名前と 一致する必要があります。
Google Cloud Storageの外部ステージ¶
Google Cloud Storageにあるファイルからデータを自動的にロードするパイプには、Google Pub/Subサブスクリプションと、そのサブスクリプションを参照する通知統合が必要です。ターゲットアカウントの複製された各パイプには、Google Pub/Subサブスクリプションと、そのサブスクリプションを参照する通知統合も必要です。各ソースおよびターゲットアカウントのPub/Subサブスクリプションは、Google Cloud Storageソースからの通知を受信する同じPub/Subトピックにサブスクライブする必要があります。
構成の詳細については、下図を参照してください。
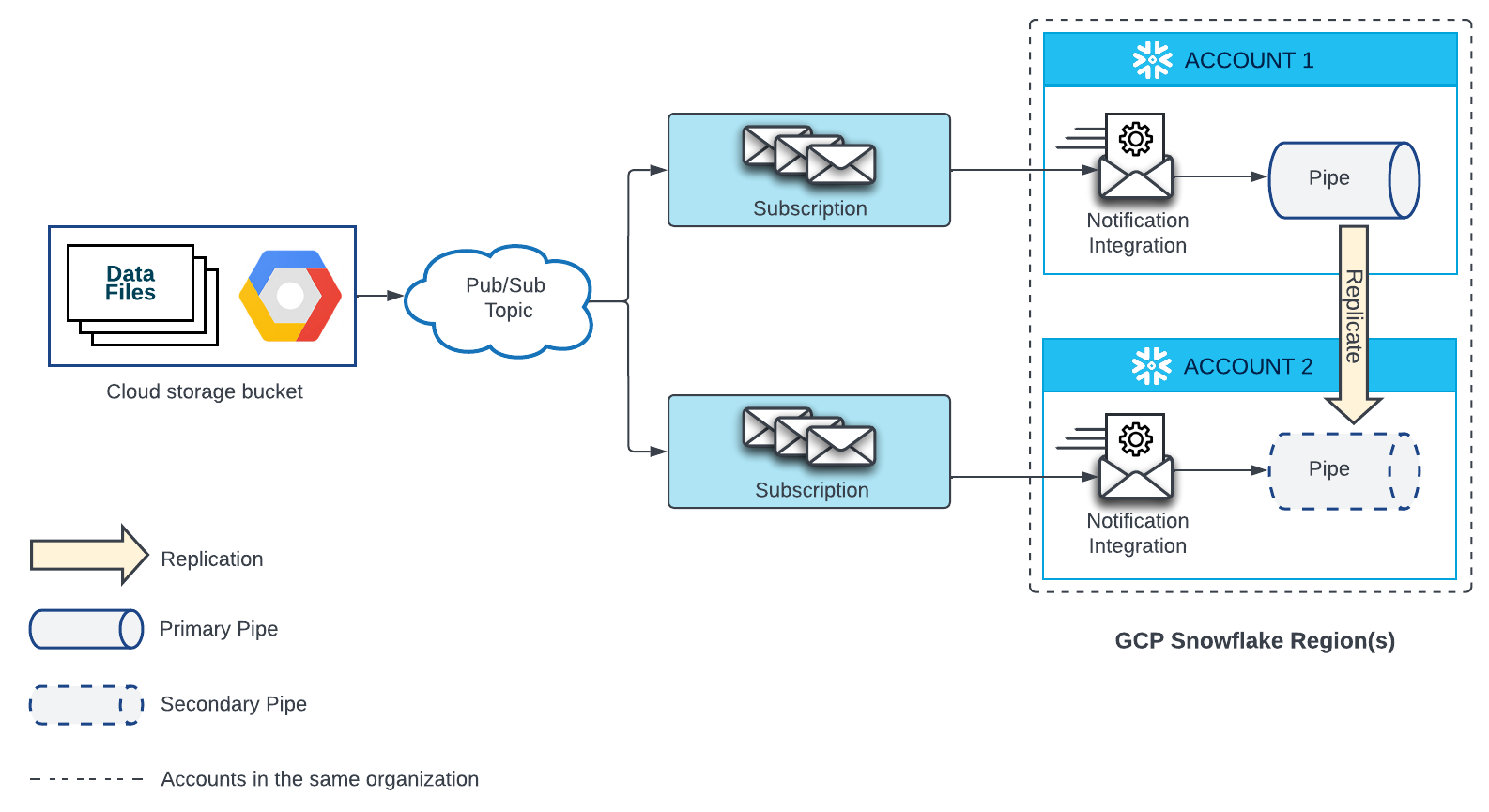
- Pub/Subトピックに新しいサブスクリプションを作成し、ターゲットアカウントに新しい通知統合を作成します。
次に、SnowflakeにPub/Subサブスクリプションへのアクセス権を付与します。手順については、 GCS Pub/Subを使用した自動化の構成 をご参照ください。
重要
各ターゲットアカウントの通知統合の名前は、ソースアカウントの通知統合の名前と 一致する必要があります。
API 統合のリモートサービスの更新¶
API 統合複製を有効にしている場合は、 API 統合がターゲットアカウントに複製された後で追加のステップが必要です。複製された統合には、プライマリ統合のIDおよび IAM エンティティとは異なる独自のIDおよびアクセス管理(IAM)エンティティがあります。したがって、複製された関数へのアクセスを許可するには、リモートサービスの権限を更新する必要があります。このプロセスは、プライマリアカウントの関数へのアクセスを許可するのと似ています。詳細については、以下のリンクをご参照ください。
Amazon Web Services Snowflakeと新しい IAM ロールの間における信頼関係の設定。
Google Cloud Platform: プロキシサービスの GCP セキュリティポリシーを作成する。
Microsoft Azure:
ステップ1:Azureの API 統合をリンクする
ステップ2: JWT 検証ポリシーを作成する
プライマリデータベースとセカンダリデータベースのデータセットの比較¶
Snowflakeは、各複製のリフレッシュ操作の一環として、自動検証チェックを実行します。検証に失敗すると、リフレッシュは失敗します。したがって、複製されたデータを手動で確認する必要はありません。コンプライアンス上の理由で追加の検証が必要な場合は、リフレッシュ操作の終了後に手動検証ステップを実行できます。
Snowflakeによる自動検証¶
Snowflakeは現在、各リフレッシュ操作の後に、プライマリアカウントとセカンダリアカウントの間で次のチェックを実行します。
Snowflakeは、複製されたすべてのファイルについて、プライマリアカウントとセカンダリアカウント間のハッシュ値を比較します。
各テーブルについて、Snowflakeはプライマリアカウントとセカンダリアカウントの間で次の値を比較します。
ファイルカウント。
行カウント。
バイトカウント。
手動検証¶
データベースオブジェクトが複製グループまたはフェールオーバーグループで複製される場合は、 HASH_AGG 関数を使用して、プライマリデータベースとセカンダリデータベースにある一部またはすべてのテーブルの行を比較し、データの一貫性を確認できます。HASH_AGG 関数は、入力行のセットの署名付き64ビットハッシュ値の集合を返します。ハッシュ値は、入力行の順序に関係なく同じです。
セカンダリアカウントとプライマリアカウントの両方で、すべてのテーブル、またはテーブルのランダムなサブセットでこの関数をクエリします。プライマリアカウントで、AT | BEFORE 句を使用して、関連するデータベースの最新リフレッシュ時刻を指定します。両方のアカウントでのクエリ間の出力を比較します。
リフレッシュ後にデータを手動検証する例¶
次の例では、データベース mydb はフェールオーバーグループ myfg に含まれています。テーブル mydb を含んでいるデータベース myschema.mytable。
ターゲットアカウントで実行するコマンド¶
REPLICATION_GROUP_REFRESH_PROGRESS テーブル関数(Snowflake Information Schema 内)をクエリします。
primarySnapshotTimestampフェーズのDETAILS列にあるPRIMARY_UPLOADING_METADATAに注意してください。これは、プライマリアカウントにあるそのデータベースの最新更新のタイムスタンプです。セカンダリアカウントにある指定されたテーブルの HASH_AGG 関数をクエリします。次のクエリは、
myschema.mytableテーブル内にあるすべての行のハッシュ値を返します。
ソースアカウントで実行するコマンド¶
プライマリアカウントにある同じテーブルの HASH_AGG 関数をクエリします。Time Travelを使用して、セカンダリデータベースの最新の更新が実行されたときのタイムスタンプを指定します。
2つのクエリの結果を比較します。出力は同一である必要があります。
ソースアカウントの複製グループまたはフェールオーバーグループの変更¶
Snowsight または SQL を使用して、ソースアカウントの複製グループまたはフェールオーバーグループの名前、包含オブジェクト、および複製スケジュールを編集できます。
注釈
複製グループをフェールオーバーグループに変更する、またはその逆を行うことはできません。フェールオーバーを有効または無効にするには、グループを削除し、正しいフェールオーバー設定でグループを再作成します。
Snowsightを使用した、ソースアカウントの複製グループまたはフェールオーバーグループの変更¶
注釈
アカウント管理者のみが、 Snowsight を使用して複製グループまたはフェイルオーバーグループを編集できます (複製設定にSnowsightを使用する場合の制限事項 を参照)。
これらのアクションを実行するには、ソースアカウントにサインインしている必要があります。サインインしていない場合、 Status 列にはリフレッシュステータスの代わりにサインインメッセージが表示されます。
Snowsight にサインインします。
ナビゲーションメニューで Admin » Accounts を選択します。
Replication を選択してから、 Groups を選択します。
編集する複製グループまたはフェールオーバーグループを探し、行の最後の列にある More メニュー(...)を選択します。
Edit を選択します。
グループ名を変更するには、 Group name ボックスに以下の条件を満たす新しい名前を入力します。
識別子文字列が二重引用符で囲まれていない限り(例えば、"My object")、アルファベット文字で始まる必要があり、スペースや特殊文字を含めることはできません。二重引用符で囲まれた識別子も大文字と小文字が区別されます。
詳細については、 識別子の要件 をご参照ください。
アカウント内のフェールオーバーグループと複製グループの名前は一意にする必要があります。
共有オブジェクトとアカウントオブジェクトを追加または削除するには、 Edit objects を選択します。
注釈
アカウントオブジェクトは、1つの複製グループまたはフェールオーバーグループにのみ追加できます。いずれかのアカウントオブジェクトを持つ複製グループまたはフェールオーバーグループがアカウントに既に存在する場合、それらのオブジェクトを選択することはできません。
データベースオブジェクトを追加または削除するには、 Select databases を選択します。
グループの複製スケジュールを変更するには、 Replication frequency を選択します。
Save を選択してグループを更新します。
グループへの変更の保存に失敗した場合は、よくあるエラーとその解決方法について Snowsightを使用した複製グループの作成と編集に関する問題のトラブルシューティング を参照してください。
SQL を使用した、ソースアカウントの複製グループまたはフェールオーバーグループの変更¶
複製グループまたはフェイルオーバーグループのプロパティは、 ALTER REPLICATION GROUP または ALTER FAILOVER GROUP コマンドを使用して変更できます。
ターゲットアカウントでの複製スケジュールの一時停止または再開¶
Snowsight または SQL を使用して、ターゲットアカウントの複製スケジュールを一時停止(中断)または再開できます。
Snowsightを使用したターゲットアカウントでの複製スケジュールの一時停止または再開¶
注釈
アカウント管理者のみが、 Snowsight を使用して複製グループまたはフェイルオーバーグループを編集できます (複製設定にSnowsightを使用する場合の制限事項 を参照)。
複製スケジュールを一時停止または再開するには、ターゲットアカウントにサインインしている必要があります。
Snowsight にサインインします。
ナビゲーションメニューで Admin » Accounts を選択します。
Replication を選択してから、 Groups を選択します。
編集する複製グループまたはフェールオーバーグループを探し、行の最後の列にある More メニュー(...)を選択します。
Pause または Resume を選択します。
SQL を使用したターゲットアカウントでの複製スケジュールの一時停止または再開¶
ALTER REPLICATION GROUP または ALTER FAILOVER GROUP コマンドを使用して、ターゲットアカウントの複製スケジュールを一時停止または再開できます。一時停止するには、 SUSPEND パラメーターを指定します。再開するには、 RESUME パラメーターを指定します。
セカンダリ複製またはフェールオーバーグループのドロップ¶
DROP REPLICATION GROUP または DROP FAILOVER GROUP コマンドを使用して、セカンダリ複製またはフェールオーバーをドロップできます。グループをドロップできるのは、複製グループまたはフェールオーバーグループの所有者(つまり、グループに対して OWNERSHIP 権限を持つロール)のみです。
Snowsight を使用してセカンダリ複製グループまたはフェイルオーバーグループを削除するには、ソースアカウントでグループを削除する必要があります。Snowsightを使用した複製グループまたはフェールオーバーグループのドロップ をご参照ください。
プライマリ複製またはフェールオーバーグループのドロップ¶
Snowsight または SQL を使用して、プライマリ複製グループまたはフェイルオーバーグループを削除できます。SQL を使用してプライマリグループを削除する場合は、まずすべてのセカンダリグループを削除する必要があります。セカンダリ複製またはフェールオーバーグループのドロップ をご参照ください。
SQL を使用したプライマリ複製グループまたはフェールオーバーグループのドロップ¶
プライマリ複製またはフェールオーバーグループは、グループのすべてのレプリカ(つまり、セカンダリ複製またはフェールオーバーグループ)がドロップされた後にのみドロップできます。または、セカンダリフェールオーバーグループを昇格してプライマリフェールオーバーグループとして機能させてから、以前のプライマリフェールオーバーグループをドロップすることもできます。
グループ所有者のみがグループをドロップできることに注意してください。
Snowsightを使用した複製グループまたはフェールオーバーグループのドロップ¶
注釈
アカウント管理者のみが、 Snowsight を使用して複製グループまたはフェイルオーバーグループを削除できます (複製設定にSnowsightを使用する場合の制限事項 を参照)。
プライマリ複製グループまたはフェイルオーバーグループと、リンクされているセカンダリグループを削除できます。
Snowsight にサインインします。
ナビゲーションメニューで Admin » Accounts を選択します。
Replication を選択してから、 Groups を選択します。
削除する複製グループまたはフェイルオーバーグループを探します。行の最後の列で More メニュー (...) を選択します。
Drop を選択してから、 Drop group を選択します。
Snowsightを使用した複製グループの作成と編集に関する問題のトラブルシューティング¶
次のシナリオは、 Snowsight を使用して複製グループまたはフェイルオーバーグループを作成または編集する際に発生する可能性のある問題のトラブルシューティングに役立ちます。
データベースをグループに追加することはできません¶
エラー |
|
|---|---|
原因 |
データベースは、1つの複製グループまたはフェイルオーバーグループにのみ追加できます。グループに選択したデータベースの1つが、すでに別の複製グループまたはフェイルオーバーグループに含まれています。 |
解決策 |
Select Databases を選択し、他のグループに既に含まれているデータベースの選択を解除します。 |
エラー |
|
|---|---|
原因 |
複製グループまたはフェイルオーバーグループに追加するデータベースは、以前にデータベース複製用に構成されていました。 |
解決策 |
そのデータベースのデータベース複製を無効にします。データベース複製からグループベース複製への移行 をご参照ください。 |
複製設定にSnowsightを使用する場合の制限事項¶
Snowsight を使用して複製グループまたはフェイルオーバーグループを作成できるのは、 ACCOUNTADMIN ロールを持つユーザーだけです。CREATE REPLICATION GROUP または CREATE FAILOVER GROUP 権限を持つロールを持つユーザーは、それぞれの SQL コマンドを使用してグループを作成できます。
ACCOUNTADMIN ロールを持つユーザーだけが、 Snowsight を使用して、複製グループまたはフェイルオーバーグループを編集または削除できます。複製グループまたはフェイルオーバーグループの OWNERSHIP 権限を持つロールを持つユーザーは、それぞれの SQL コマンドを使用してグループを編集および削除できます。
アカウントでプライベート接続を使用している場合、 Snowsight を使用したグループの作成、変更、削除を行うことはできません。SQLを使用すると、これらのアクションを完了できます。