Desenvolvimento e execução de código nos Snowflake Notebooks¶
Este tópico descreve como escrever e executar códigos SQL, Python e Markdown em Snowflake Notebooks.
Noções básicas sobre células de notebooks¶
Esta seção apresenta algumas operações básicas de células. Quando você cria um notebook, três células de exemplo são exibidas. Você pode modificar essas células ou adicionar novas.
Crie uma nova célula:¶
Snowflake Notebooks oferecem suporte a três tipos de células: SQL, Python e Markdown. Para criar uma nova célula, você pode passar o mouse sobre uma célula existente ou rolar até a parte inferior do notebook e selecionar um dos botões para o tipo de célula que deseja adicionar.

Altere o idioma de uma célula existente usando um dos métodos a seguir:
Selecione o menu suspenso de idiomas e escolha um idioma diferente.
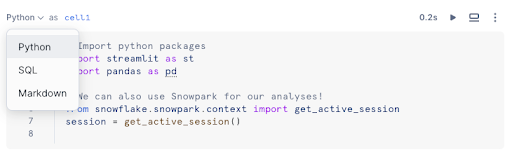
Use os atalhos de teclado.
Editar uma célula¶
Para evitar conflitos de edição, somente um usuário pode editar uma célula de cada vez. Se outro usuário tentar editar uma célula ativa, será exibida uma notificação. A célula ficará disponível para edição após 60 segundos de inatividade.
Como mover células¶
É possível mover uma célula arrastando e soltando a célula com o mouse ou usando o menu de ações:
(Opção 1) Passe o mouse sobre a célula existente que deseja mover. Selecione o ícone
 (arrastar e soltar) no lado esquerdo da célula e mova a célula para seu novo local.
(arrastar e soltar) no lado esquerdo da célula e mova a célula para seu novo local.(Opção 2) Selecione o menu de reticências verticais
 (ações). Em seguida, selecione a ação apropriada.
(ações). Em seguida, selecione a ação apropriada.
Nota
Para mover o foco entre as células, use as setas para cima e para baixo.
Como excluir uma célula¶
Para excluir uma célula, siga estas etapas em um notebook:
Selecione o menu de reticências verticais
(mais ações).Selecione Delete.
Selecione Delete novamente para confirmar.
Você também pode usar o atalho de teclado para excluir uma célula.
Para considerações ao usar Python e células SQL, consulte Considerações para execução de notebooks.
Execute as células em Snowflake Notebooks¶
Para executar células Python e SQL nos Snowflake Notebooks, você pode:
Executar uma única célula: escolha esta opção ao fazer atualizações de código frequentes.
Pressione CMD + Return em um teclado Mac, ou CTRL + Enter em um teclado Windows.
Selecione
 ou Run this cell only.
ou Run this cell only.
Executar todas as células de um notebook em ordem sequencial: escolha essa opção antes de apresentar ou compartilhar um notebook para garantir que os destinatários vejam as informações mais atualizadas. Essa opção executa todas as células de código SQL e Python no notebook, de cima para baixo. Se ocorrer um erro em qualquer célula, a execução será interrompida e as células subsequentes não serão executadas. Esse comportamento também se aplica aos notebooks agendados. Por exemplo, se você executar um notebook com 10 células e na célula 2 houver um erro de sintaxe SQL, o notebook deixará de ser executado após a célula 2.
Pressione CMD + Shift + Return em um teclado Mac, ou CTRL + Shift + Enter em um teclado Windows.
Selecione Run all.
Executar uma célula e avançar para a próxima célula: escolha esta opção para executar uma célula e avançar para a próxima célula mais rapidamente.
Pressione Shift + Return em um teclado Mac, ou Shift + Enter em um teclado Windows.
Selecione o menu de reticências verticais
(mais ações) para uma célula e escolha Run cell and advance.
Executar tudo acima: escolha esta opção ao executar uma célula que faça referência aos resultados de células anteriores.
Selecione o menu de reticências verticais
(mais ações) para uma célula e escolha Run all above.
Executar tudo abaixo: escolha esta opção ao executar uma célula da qual células posteriores dependem. Esta opção executa a célula atual e todas as células seguintes.
Selecione o menu de reticências verticais
(mais ações) para uma célula e escolha Run all below.
Quando uma célula está em execução, outras solicitações de execução são enfileiradas e serão executadas assim que a célula em execução ativa terminar.
Recolher e expandir células¶
Você pode controlar a parte visível do notebook selecionando uma das opções de exibição de células na parte superior do notebook:
Selecione o menu de reticências verticais
(mais ações).Selecione Show/hide all e escolha a opção apropriada:
Mostrar tudo: exibe o código e os resultados de cada célula.
Mostrar apenas o código: oculta os resultados e exibe apenas as células de código.
Mostrar apenas resultados: oculta o código e exibe apenas a saída.
Ocultar tudo: recolhe o código e os resultados de todas as células.
Essas opções são úteis quando:
Você quer se concentrar na leitura do código ou na análise dos resultados.
Você está apresentando ou compartilhando seu notebook.
Você precisa explorar notebooks grandes com mais eficiência.
Duplicar células¶
A duplicação de uma célula pode ajudar com o seguinte:
Testar variações de uma consulta ou função.
Depurar sem sobrescrever a versão em funcionamento.
Comparar diferentes saídas lado a lado.
Reutilizar código ou modificar uma célula existente sem perder o original.
Para duplicar uma célula do notebook:
Na célula a ser duplicada, selecione o menu de reticências verticais
(mais ações).Selecione Duplicate.
Uma cópia da célula aparece imediatamente abaixo da original.
Minimapa de células¶
O minimapa de células aparece na barra lateral direita do notebook e fornece uma lista compacta de todas as células do notebook e que pode ser arrastada. Cada entrada no minimapa corresponde a um código ou célula de texto e reflete a ordem em que as células aparecem.
Célula atual: a célula selecionada é destacada no minimapa.
Reordenação: arraste e solte itens no minimapa para alterar rapidamente a ordem das células no notebook.
Navegação: clique no nome de uma célula no minimapa para ir diretamente para essa célula.
Esse recurso é útil para explorar notebooks grandes e reorganizar o conteúdo com mais eficiência.
Execução de notebooks com parâmetros¶
Quando você usa o comando EXECUTE NOTEBOOK para executar um notebook, é possível passar argumentos para o notebook. Em uma célula Python no notebook, você pode acessar esses argumentos usando a variável sys.argv, que é uma lista integrada do Python que contém argumentos de linha de comando.
Passar argumentos para notebooks permite que você personalize o comportamento do notebook. Você pode:
Personalizar ou adaptar a execução do notebook.
Reutilizar o mesmo notebook para várias entradas.
Oferecer suporte à automação ou ao cronograma de tarefas.
Exemplos¶
Em uma célula Python no notebook, você pode acessar os argumentos usando a variável sys.argv.
Visualização de todos os argumentos passados para o notebook¶
Imprima a lista completa de argumentos passados para o notebook.
Se o notebook for executado com este comando:
A saída será:
Impressão de cada argumento¶
Faça loop e imprima cada argumento individualmente.
A saída será:
Acesso a um argumento específico¶
Acesse o segundo argumento.
A saída será:
Análise de um argumento contendo valores separados por vírgula¶
Se um argumento contiver uma lista de valores separados por vírgula, você poderá dividi-la em valores individuais.
A saída será:
Você também pode fazer loop dos valores:
Extração de um argumento contendo um par chave-valor¶
Se um argumento incluir um par chave-valor (por exemplo, key=value), extraia o valor.
A saída será:
Sintaxe alternativa para uma única cadeia de caracteres¶
Você pode definir uma variável de sessão como o valor de um argumento e passá-la para o notebook.
Visualização de resultados de uma execução parametrizada¶
Para visualizar o resultado de uma execução de notebook que foi acionada usando EXECUTE NOTEBOOK:
Faça login na Snowsight.
No menu de navegação, selecione Projects » Notebooks.
Selecione o ícone Calendar.
Selecione View run history.
Encontre a execução do notebook e abra o resultado.
Um notebook somente leitura é aberto contendo o resultado dessa execução.
Notas¶
sys.argvcontém apenas as cadeias de caracteres passadas por EXECUTE NOTEBOOK.Há suporte apenas para cadeias de caracteres. Se outro tipo de dados (como um número inteiro) for passado, ele será interpretado como NULL. Para obter mais informações, consulte EXECUTE NOTEBOOK.
Como inspecionar o status de uma célula¶
O status de execução da célula é indicado pelas cores exibidas pela célula. Essa cor de status é exibida em dois lugares: na parede à esquerda da célula e no mapa de navegação da célula à direita.
Cor do status da célula:
Ponto azul: a célula foi modificada, mas ainda não foi executada.
Vermelho: a célula foi executada na sessão atual e ocorreu um erro.
Verde: a célula foi executada na sessão atual sem erros.
Verde em movimento: a célula está em execução no momento.
Cinza: a célula foi executada em uma sessão anterior e os resultados mostrados são da sessão anterior. Os resultados da célula da sessão interativa anterior são mantidos por 7 dias. Sessão interativa significa que o usuário executa o notebook de forma interativa na Snowsight, e não aqueles executados por um cronograma ou pelo comando :doc:`/sql-reference/sql/execute-notebook`SQL.
Cinza piscante: a célula está esperando para ser executada depois que você selecionar Run All.
Nota
As células Markdown não mostram nenhum status.
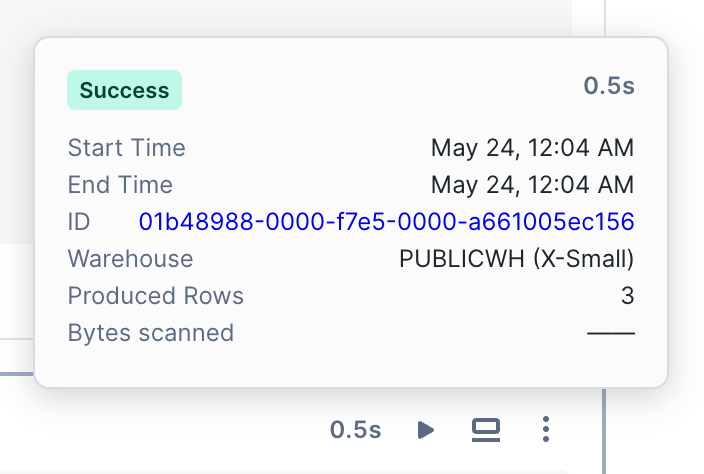
Depois que uma célula termina de ser executada, o tempo que levou para ser executada é exibido na parte superior da célula. Selecione esse texto para visualizar os detalhes da execução, incluindo os horários de início e término e o tempo total decorrido.
As células SQL contêm informações adicionais, como o warehouse usado para executar a consulta, as linhas retornadas e um hiperlink para a página do ID da consulta.
Como parar uma célula em execução¶
Para interromper a execução de qualquer célula de código que esteja em execução no momento, selecione Stop no canto superior direito da célula. Você também pode selecionar Stop no canto superior direito da página Notebooks. Enquanto as células estão funcionando, Run all se torna Stop.
Isso interrompe a execução da célula sendo executada no momento e de todas as células subsequentes que foram programadas para serem executadas.
Atalhos do teclado¶
Os Snowflake Notebooks oferecem suporte a vários atalhos de teclado para ajudar a acelerar seu processo de desenvolvimento.
Você também pode ver a lista de atalhos de teclado selecionando o ícone do teclado no canto inferior direito e, em seguida, selecionando Keyboard shortcuts.
Tarefa |
MacOS |
Windows |
|---|---|---|
Executar todas as células |
CMD + Shift + Return |
CTRL + Shift + Enter |
Executar a célula selecionada |
CMD + Return |
CTRL + Enter |
Executar a célula selecionada e avançar para a próxima célula |
Shift + Return |
Shift + Enter |
Mover entre células |
Setas para cima e para baixo |
Setas para cima e para baixo |
Parar todas as células |
ii |
ii |
Encontrar dentro da célula |
CMD + f |
CTRL + f |
Mover a célula para cima |
CMD + SHIFT + Seta para cima |
CTRL + SHIFT + Seta para cima |
Mover célula para baixo |
CMD + SHIFT + Seta para baixo |
CTRL + SHIFT + Seta para baixo |
Adicionar uma célula acima da célula atualmente selecionada |
a |
a |
Adicionar uma célula abaixo da célula atualmente selecionada |
b |
b |
Excluir a célula atualmente selecionada |
dd ou DELETE |
dd ou DELETE |
Converter uma célula SQL ou Python em uma célula Markdown |
m |
m |
Converter uma célula em uma célula de código:
|
y |
y |
Mostrar atalhos de teclado |
Shift + ? |
Shift + ? |
Além disso, você pode usar os mesmos atalhos de teclado que usa para planilhas. Consulte Executar tarefas com atalhos de teclado.
Como formatar texto com Markdown¶
Para incluir Markdown em seu notebook, adicione uma célula Markdown:
Use um atalho de teclado e selecione Markdown ou + Markdown.
Selecione o ícone de lápis Edit markdown ou clique duas vezes na célula e comece a escrever Markdown.
Você pode digitar Markdown válido para formatar uma célula de texto. À medida que você digita, o texto formatado aparece abaixo da sintaxe Markdown.
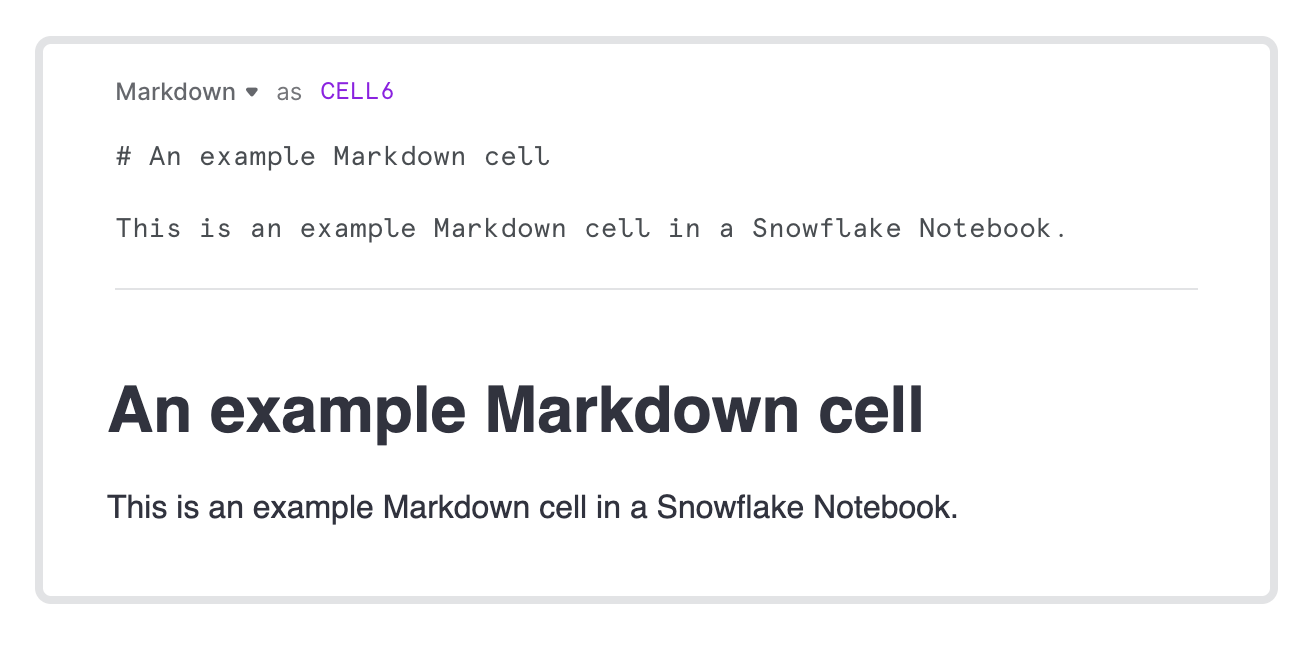
Para exibir apenas o texto formatado, selecione o ícone de marca de seleção Done editing.

Nota
As células Markdown atualmente não oferecem suporte à renderização de HTML.
Noções básicas de Markdown¶
Esta seção descreve a sintaxe básica do Markdown para introduzir o assunto.
Cabeçalhos
Nível de título |
Sintaxe Markdown |
Exemplo |
|---|---|---|
Nível superior |

|
|
2º nível |

|
|
3º nível |

|
Formatação de texto em linha
Formato de texto |
Sintaxe Markdown |
Exemplo |
|---|---|---|
Itálico |

|
|
Negrito |

|
|
Link |

|
Listas
Tipo de lista |
Sintaxe Markdown |
Exemplo |
|---|---|---|
Lista ordenada |

|
|
Lista não ordenada |

|
Formatação de código
Linguagem |
Sintaxe Markdown |
Exemplo |
|---|---|---|
Python |
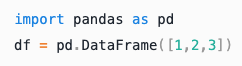
|
|
SQL |

|
Incorporar imagens
Tipo de arquivo |
Sintaxe Markdown |
Exemplo |
|---|---|---|
Imagem |

|
Para um notebook que demonstra esses exemplos de Markdown, consulte a seção Células de Markdown do notebook de histórias de dados visuais.
Compreensão das saídas de células¶
Ao executar uma célula Python, o notebook exibe os seguintes tipos de saída da célula nos resultados:
Quaisquer resultados gravados no console, como logs, erros e avisos e saídas de instruções print().
DataFrames são impressos automaticamente com a exibição de tabela interativa do Streamlit,
st.dataframe().Os tipos de exibição compatíveis com DataFrame incluem pandas DataFrame, Snowpark DataFrames e tabelas Snowpark.
Para o Snowpark, DataFrames impressos são avaliados imediatamente, sem a necessidade de executar o comando
.show(). Se você preferir não avaliar o DataFrame imediatamente, por exemplo, ao executar o notebook no modo não interativo, o Snowflake recomenda remover as instruções de impressão DataFrame para acelerar o tempo de execução geral do código do Snowpark.
As exibições são renderizadas em saídas. Para saber mais sobre como visualizar seus dados, consulte Visualização de dados no Snowflake Notebooks.
Além disso, você pode acessar os resultados de sua consulta SQL em Python e vice-versa. Consulte Células de referência e variáveis nos Snowflake Notebooks.
Limites de saída da célula¶
Apenas 10.000 linhas ou 8 MB da saída do DataFrame são mostrados como resultados de célula, o que for menor. No entanto, todo o DataFrame ainda permanece disponível para uso na sessão do notebook. Por exemplo, mesmo que o DataFrame inteiro não seja renderizado, você ainda pode executar tarefas de transformação de dados.
Para cada célula, são permitidos apenas 20 MB de saída. Se o tamanho da saída da célula exceder 20 MB, a saída será descartada. Se isso acontecer, considere a possibilidade de dividir o conteúdo em várias células.
Células de referência e variáveis nos Snowflake Notebooks¶
Você pode referenciar os resultados das células anteriores em uma célula do notebook. Por exemplo, para referenciar o resultado de uma célula SQL ou o valor de uma variável Python, consulte as seguintes tabelas:
Nota
O nome da célula da referência diferencia maiúsculas de minúsculas e deve corresponder exatamente ao nome da célula referenciada.
Saída de referência SQL em células Python:
Tipo de célula de referência |
Tipo de célula atual |
Sintaxe de referência |
Exemplo |
|---|---|---|---|
SQL |
Python |
|
Converter uma tabela de resultados SQL em um Snowpark DataFrame. Se você tiver o seguinte em uma célula SQL nomeada Você pode referenciar a célula para acessar o resultado SQL: Converta o resultado em um pandas DataFrame: |
Referência de variáveis em código SQL:
Importante
No código SQL, você só pode referenciar variáveis Python do tipo string. Você não pode referenciar um Snowpark DataFrame, pandas DataFrame ou outro formato DataFrame nativo do Python.
Tipo de célula de referência |
Tipo de célula atual |
Sintaxe de referência |
Exemplo |
|---|---|---|---|
SQL |
SQL |
|
Por exemplo, em uma célula SQL nomeada |
Python |
SQL |
|
Por exemplo, em uma célula Python nomeada Como usar a variável Python como um valor É possível fazer referência ao valor da variável Como usar a variável Python como um identificador Se a variável Python representar um identificador SQL, como um nome de coluna ou tabela: Se a variável Python representar um identificador SQL, como o nome de uma coluna ou tabela ( Certifique-se de diferenciar entre variáveis usadas como valores (com aspas) e como identificadores (sem aspas). Observação: a referência ao Python DataFrames não é compatível. |
Considerações para execução de notebooks¶
Os notebooks são executados usando os direitos do chamador. Para considerações adicionais, consulte Alteração do contexto de sessão para um notebook.
Você pode importar bibliotecas Python para usar em um notebook. Para obter mais detalhes, consulte Importação de pacotes Python para uso em notebooks.
Ao referenciar objetos em células SQL, você deve usar os nomes de objetos totalmente qualificados, a menos que esteja referenciando nomes de objetos em um banco de dados ou esquema especificado. Consulte Alteração do contexto de sessão para um notebook.
Os rascunhos do notebook são salvos a cada três segundos.
Você pode usar a integração com o Git para manter versões do notebook.
É possível configurar um tempo limite de inatividade para encerrar automaticamente a sessão do notebook quando essa configuração for atingida. Para obter mais informações, consulte Tempo ocioso e reconexão.
Os resultados das células do notebook são visíveis apenas para o usuário que executou o notebook e são armazenados em cache em todas as sessões. A reabertura de um notebook exibe os resultados anteriores da última vez que o usuário executou o notebook usando o Snowsight.
BEGIN … END (Script Snowflake) não é compatível em células SQL. Em vez disso, use o método Session.sql().collect() em uma célula Python para executar o bloco de script. Encadeie a chamada
sqlcom uma chamada paracollectpara executar imediatamente a consulta SQL.O código a seguir executa um bloco de script Snowflake usando o método
session.sql().collect():