Guia de migração do SQL Server para o Snowflake¶
Estrutura de migração do Snowflake¶
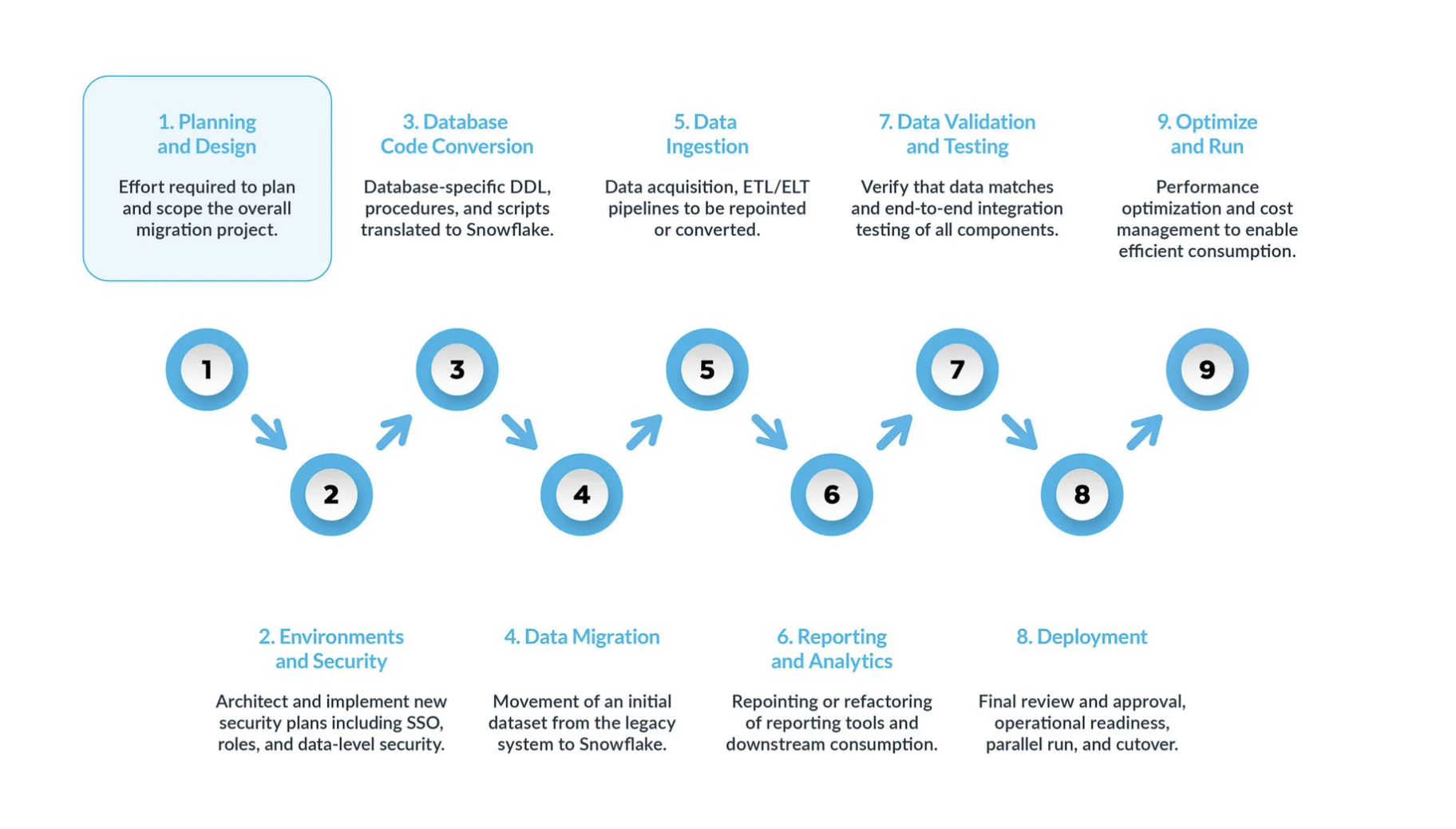
Uma migração típica do SQL Server para o Snowflake pode ser dividida em nove etapas principais:
Planejamento e design são etapas muitas vezes negligenciadas no processo de migração. O principal motivo é que as empresas geralmente querem mostrar progresso rapidamente, mesmo que não tenham compreendido totalmente o escopo do projeto. Por isso, esta fase é crucial para entender e priorizar o projeto de migração.
Ambiente e segurança: com um plano, um cronograma claro, uma matriz RACI e a aprovação de todas as partes interessadas, é hora de passar para o modo de execução. Configurar os ambientes e as medidas de segurança necessárias para iniciar a migração é muito importante antes de começar a fase de migração, visto que há muitas partes envolvidas, e será mais impactante para o projeto de migração se toda a sua configuração estiver pronta antes de prosseguir.
O processo de conversão do código do banco de dados envolve a extração do código diretamente do catálogo do banco de dados dos sistemas de origem, como definições de tabelas, exibições, procedimentos armazenados e funções. Depois da extração, você migra todo esse código para linguagens de definição de dados (DDLs) equivalentes no Snowflake. Esta etapa também inclui a migração de scripts de linguagem de manipulação de dados (DML), que podem ser utilizados por analistas de negócios para criar relatórios ou painéis. Todo esse código precisa ser migrado e ajustado para funcionar no Snowflake. Os ajustes podem variar de mudanças simples, como convenções de nomenclatura e mapeamentos de tipos de dados, a diferenças mais complexas em sintaxe, semântica da plataforma e outros fatores. Para auxiliar nesse processo, o Snowflake oferece uma solução poderosa chamada SnowConvert AI, que automatiza grande parte do processo de conversão do código do banco de dados.
Migração de dados: a migração de dados envolve a transferência de dados entre diferentes sistemas de armazenamento, formatos ou sistemas de computador. No contexto de uma migração do SQL Server para o Snowflake, ela se refere especificamente à movimentação de dados do seu ambiente SQL Server para o seu novo ambiente Snowflake.
Há dois tipos principais discutidos neste guia:
Migração histórica de dados: tirar um instantâneo dos seus dados do seu SQL Server em um ponto específico no tempo e transferi-lo para o Snowflake. Isso geralmente é feito como uma transferência inicial em massa.
Migração incremental de dados: mover dados novos ou alterados do SQL Server para o Snowflake de maneira contínua após a migração histórica inicial. Isso garante que seu ambiente Snowflake permaneça atualizado com seus sistemas de origem.
Ingestão de dados: depois de você migrar os dados históricos, a próxima etapa é migrar o processo de ingestão de dados, apresentando dados em tempo real de várias fontes. Normalmente, esse processo segue um modelo de extração, transformação e carregamento (ETL) ou extração, carregamento e transformação (ELT), dependendo de quando e onde a transformação de dados ocorre antes de ficar disponível para os usuários de negócios.
Relatórios e análises, agora que o banco de dados tem dados históricos e pipelines ativos que importam continuamente novos dados, a próxima etapa é extrair valor desses dados por meio de BI. É possível fazer os relatórios usando ferramentas BI padrão ou consultas personalizadas. Em ambos os casos, o SQL enviado para o banco de dados pode precisar ser ajustado para atender aos requisitos do Snowflake. Esses ajustes podem variar de simples alterações de nome (comuns durante a migração) a diferenças de sintaxe e semânticas mais complexas. Tudo isso precisa ser identificado e abordado.
Validação e testes de dados: o objetivo é ter a maior limpeza de dados possível antes de entrar nesta fase. Cada organização tem suas próprias metodologias e requisitos de teste para mover dados para produção. Eles devem ficar totalmente compreendidos desde o início do projeto.
Implantação: nesta etapa, os dados são validados, um sistema equivalente é configurado, todos os ETLs foram migrados e os relatórios foram verificados. Tudo pronto para entrar em produção? Espere um pouco; ainda há algumas considerações críticas antes da promoção final para produção. Primeiro, seu aplicativo legado pode consistir em vários componentes ou serviços. O ideal é migrar esses aplicativos um por um (embora a migração paralela seja possível) e promovê-los para produção na mesma ordem. Durante esse processo, certifique-se de que sua estratégia de transição esteja em vigor para que os usuários comerciais não tenham que consultar o Snowflake e o sistema legado. A sincronização de dados para aplicativos que ainda não foram migrados deve ocorrer em segundo plano por meio do mecanismo de transição. Se isso não for feito, os usuários empresariais terão que trabalhar em um ambiente híbrido e devem entender as implicações dessa configuração.
Otimizar e executar: após a migração de um sistema para o Snowflake, ele entra no modo de manutenção normal. Todos os sistemas de software são organismos vivos que exigem manutenção contínua. Essa fase, após a migração, é chamada de otimização e execução e não faz parte da migração em si.
Fases principais¶
Uma migração bem-sucedida do SQL Server para o Snowflake é um projeto de modernização que se desenrola em uma sequência de fases bem definidas. Seguir essa abordagem estruturada de nove fases garante uma transição abrangente e metódica, abordando tudo, desde a estratégia inicial até a excelência operacional de longo prazo.
Fase 1: Planejamento e projeto¶
Esta fase inicial é a mais crítica para o sucesso de todo o projeto de migração, pois estabelece as bases para um escopo preciso, cronogramas realistas e alinhamento das partes interessadas. Uma fase de planejamento apressada ou incompleta é a principal causa de estouros de orçamento, prazos perdidos e falha do projeto. O objetivo não é apenas catalogar o sistema existente, mas decidir estrategicamente quais ativos são valiosos o suficiente para serem migrados para a nova plataforma. Uma abordagem que migra tudo sem planejamento prévio é uma receita para migrar anos de dívida técnica acumulada e inflar os custos da nuvem desde o primeiro dia.
Atividades principais:
Realização de um inventário abrangente: o primeiro passo é criar um manifesto detalhado e exaustivo de todos os ativos dentro do escopo da migração. Esse inventário deve ser criado usando uma combinação de ferramentas de descoberta automatizadas, consultas ao catálogo do sistema e entrevistas com os proprietários dos aplicativos. O inventário deve incluir:
Objetos de banco de dados: todos os bancos de dados, esquemas, tabelas e exibições. Para tabelas, contagem de linhas de documentos e tamanho dos dados brutos.
Código procedimental: todos os procedimentos armazenados, funções definidas pelo usuário (UDFs), acionadores e qualquer lógica que utilize cursores.
Automação e ETL: todos os trabalhos do agente do SQL Server, com agendamentos e dependências deles. Um catálogo completo dos pacotes do SQL Server Integration Services (SSIS) é especialmente crítico.
Consumidores downstream: todos os aplicativos e ferramentas de BI que se conectam ao banco de dados, como relatórios SSRS, painéis do Power BI e pastas de trabalho do Tableau.
Entidades de segurança: todos os usuários, funções e permissões granulares.
Exclusão de bancos de dados do sistema: é um erro crítico tentar migrar os bancos de dados internos do sistema do SQL Server (
master,msdb,tempdb,model). Eles são parte integrante de uma instância do SQL Server, mas não têm função ou equivalente no Snowflake e devem ser explicitamente excluídos de todos os planos de migração.
Definição de objetivos, escopo e métricas de sucesso da migração:** com um inventário completo, a equipe pode definir metas claras e mensuráveis vinculadas aos resultados de negócios. Alguns exemplos incluem:
Objetivo: melhorar o desempenho dos relatórios financeiros de fechamento mensal.
Métrica:** reduzir o tempo de execução do conjunto de relatórios «MonthEnd_Consolidation» em 50%.
Objetivo:** reduzir o custo total de propriedade do data warehousing (TCO).
Métrica: reduzir o TCO anual em 30% em comparação com os custos do ano anterior.
Alinhamento das partes interessadas e montagem da equipe de migração (RACI): uma migração de plataforma de dados é uma transformação de negócios. O envolvimento precoce e contínuo de todas as partes interessadas é fundamental. A equipe de migração deve incluir representantes de usuários empresariais, engenharia de dados, finanças, segurança e jurídico. Uma matriz RACI (responsável, prestador de contas, consultado, informado) deve ser estabelecida para formalizar funções e responsabilidades.
Introdução ao FinOps:** a transição para o modelo de custo baseado em consumo do Snowflake deve ser planejada desde o início. A equipe de migração deve coordenar-se com o departamento financeiro para entender o modelo de precificação, estabelecer orçamentos e definir como os custos serão acompanhados e atribuídos, geralmente usando os recursos de marcação de objetos do Snowflake.
Avaliação inicial e triagem: o inventário fornece os dados necessários para um processo crítico de triagem. A equipe deve analisar os logs de uso para identificar dados redundantes ou obsoletos, objetos não utilizados e dados temporários de preparação que podem ser desativados ou arquivados em vez de migrados.
Fase 2: Ambiente e segurança¶
Com um plano estratégico definido, esta fase envolve a construção do ambiente Snowflake fundamental. Essa é uma oportunidade «do zero» para projetar uma plataforma de dados limpa, segura e governável a partir de princípios básicos, em vez de simplesmente replicar o modelo de segurança legado. A maioria dos ambientes SQL Server maduros sofre de «dívida de segurança», como acesso excessivamente amplo e funções inconsistentes, que esta fase visa resolver.
Atividades principais:
Arquitetura da estrutura de suas contas Snowflake: para a maioria das empresas, recomenda-se uma estratégia de múltiplas contas para garantir o isolamento completo de dados e metadados. Isso normalmente inclui contas separadas para:
Conta de produção: abriga todos os dados e cargas de trabalho de produção com os controles de segurança mais rigorosos.
Conta de desenvolvimento/QA: uma conta separada para todas as atividades de desenvolvimento e teste.
Conta Snowbox (opcional): uma conta para trabalho experimental de cientistas ou analistas de dados.
Implementação de um modelo de segurança robusto: a segurança deve ser implementada em camadas:
Políticas de rede: como primeira linha de defesa, crie políticas de rede para restringir o acesso à conta Snowflake a uma lista de permissões de endereços IP confiáveis.
Autenticação: imponha a autenticação multifator (MFA) para todos os usuários. Para garantir uma experiência de usuário tranquila e segura, integre o Snowflake a um provedor de login único (SSO) corporativo, como o Azure Active Directory (Azure AD) ou o Okta.
Criação de uma hierarquia de controle de acesso baseado em funções (RBAC) : esta é a base da segurança do Snowflake. Todos os privilégios sobre os objetos são concedidos exclusivamente a funções, que são então concedidas aos usuários. Uma hierarquia de práticas recomendadas envolve a criação de tipos distintos de funções:
Funções definidas pelo sistema:
ACCOUNTADMIN,SYSADMIN, etc., utilizadas apenas para tarefas administrativas.Funções funcionais: funções personalizadas que correspondem a funções de negócio (por exemplo,
FINANCE_ADMIN,MARKETING_ANALYST).Funções de acesso: funções granulares que definem permissões específicas (por exemplo,
READ_ONLY,WRITE_ACCESS). Essas funções são concedidas em uma hierarquia para simplificar a administração.
Configuração de monitores de recursos e controles de custos: os monitores de recursos são a principal ferramenta do Snowflake para implementar controles de custo. Eles devem ser configurados como parte da configuração inicial do ambiente para acompanhar o consumo de crédito nos níveis de conta e de warehouse. Para cada monitor, defina acionadores de notificação e suspensão (por exemplo, enviar um e-mail quando a cota atingir 75%, suspender o warehouse quando atingir 100%) para evitar estouros de orçamento.
Fase 3: Conversão do código do banco de dados¶
Esta fase concentra-se na tradução técnica da estrutura física e da lógica procedural do banco de dados, do T-SQL do SQL Server para o SQL compatível com ANSI do Snowflake. Esta é geralmente a parte mais complexa e demorada da migração. O processo é um catalisador para a modernização da lógica de processamento de dados, forçando uma mudança fundamental da lógica imperativa e com estado para o processamento declarativo baseado em conjuntos.
Atividades principais:
Tradução da linguagem de definição de dados (DDL): envolve a extração e conversão de instruções
CREATE TABLEeCREATE VIEW. Ferramentas automatizadas de conversão de código, como o SnowConvert AI do Snowflake, são altamente recomendadas para analisar o DDL do T-SQL e gerar o equivalente no Snowflake SQL, lidando com as diferenças de sintaxe e o mapeamento de tipos de dados.Mapeamento de tipos de dados: o mapeamento preciso de tipos de dados é fundamental. Embora muitos tipos sejam mapeados diretamente (por exemplo,
INTparaNUMBER), várias diferenças importantes exigem atenção cuidadosa, especialmente com os tipos de data/hora. Os tiposDATETIMEeDATETIME2do SQL Server não levam em consideração o fuso horário e devem ser mapeados paraTIMESTAMP_NTZdo Snowflake. Por outro lado,DATETIMEOFFSETcontém um deslocamento de fuso horário e deve ser mapeado paraTIMESTAMP_TZpara preservar essa informação.Tratamento de restrições (impostas e não impostas): isso representa uma mudança conceitual significativa. No SQL Server, restrições como chaves primárias e chaves estrangeiras são impostas pelo mecanismo do banco de dados. No Snowflake, essas restrições podem ser definidas, mas não são impostas. Eles existem puramente como metadados. A responsabilidade pela manutenção da integridade dos dados passa inteiramente do banco de dados para o pipeline de dados (processo ETL/ELT).
Conversão do T-SQL e procedimentos armazenados: migrar procedimentos armazenados do T-SQL é uma tarefa significativa.
Discrepâncias de dialetos SQL: inúmeras funções e construções de sintaxe T-SQL exigem conversão (por exemplo,
GETDATE()torna-seCURRENT_TIMESTAMP(),ISNULL()torna-seCOALESCE()).Refatoração da lógica: o caminho preferencial é reescrever os procedimentos do T-SQL usando o Snowflake Scripting, uma linguagem procedural baseada em SQL. O objetivo principal é eliminar o processamento linha por linha (como cursores) em favor de instruções SQL baseadas em conjuntos sempre que possível.
Substituição de cursores e acionadores: cursores são um grave antipadrão de desempenho no Snowflake e devem ser eliminados. O Snowflake não é compatível com acionadores; a funcionalidade deles precisa ser reimplementada usando um padrão nativo da nuvem de fluxos e tarefas, em que um fluxo captura as alterações da tabela e uma tarefa agendada consome essas alterações para aplicar lógica de negócios.
Fase 4: Migração de dados¶
Esta fase concentra-se na transferência inicial e única de dados históricos do sistema do SQL Server de origem para o ambiente Snowflake de destino. A arquitetura fundamental para carregar dados no Snowflake é um modelo de «três caixas»: Origem -> Área de preparação -> Destino Os dados não são movidos diretamente da origem para o destino, mas primeiro são armazenados em um local intermediário de armazenamento de objetos na nuvem (a área de preparação).
Atividades principais:
Extração de dados do SQL Server: para a migração inicial de dados históricos, Bulk Copy Program (BCP), o utilitário de linha de comando nativo do SQL Server, é uma opção altamente eficiente. Ele pode exportar tabelas grandes para arquivos simples (por exemplo, CSV) em alta velocidade. Esses arquivos podem então ser carregados para a área de preparação na nuvem (por exemplo, Amazon S3, Azure Blob Storage).
Carregamento de dados no Snowflake a partir da área de preparação: assim que os arquivos de dados estiverem presentes na área de preparação da nuvem, o principal mecanismo de ingestão é o comando
COPY INTO <table>. Este é o comando SQL principal para carregamento de dados em massa de alto desempenho. Ele foi projetado para funcionar de forma massivamente paralela. Para ter um desempenho ideal, é uma prática recomendada dividir grandes conjuntos de dados em vários arquivos de tamanho moderado (100-250MB é uma recomendação comum) para maximizar esse paralelismo.
Fase 5: Ingestão de dados¶
Após a migração dos dados históricos, esta fase se concentra na migração dos processos contínuos de ingestão de dados para levar dados incrementais e em tempo real de várias fontes para o Snowflake. Isso normalmente envolve a migração da lógica de ferramentas ETL legadas como SSIS e o agendamento do SQL Server Agent.
Atividades principais:
Replicação incremental de dados: para replicar alterações em andamento após o carregamento inicial, o recurso nativo Captura de dados de alterações (CDC) do SQL Server é o método preferido. O CDC funciona lendo o log de transações do banco de dados para capturar todas as operações
INSERT,UPDATEeDELETEà medida que elas ocorrem, fornecendo um fluxo de alterações de baixo impacto e quase em tempo real.Ingestão contínua com o Snowpipe: Snowpipe é o serviço de ingestão de dados contínuo do Snowflake, projetado para casos de uso de streaming e microlotes. Você cria um objeto
PIPEque «se inscreve» em uma área de preparação. Quando novos arquivos de alteração gerados por um processo CDC chegam à área de preparação, o Snowpipe é acionado automaticamente para carregar os dados.Aplicação de alterações com MERGE: após os dados de alteração serem carregados em uma tabela de preparação temporária no Snowflake (via Snowpipe), o comando
MERGEé utilizado para aplicar essas alterações à tabela de produção final. Ele pode lidar com inserções, atualizações e exclusões em uma única instrução atômica.Modernização de trabalhos do SSIS e SQL Server Agent:
Migração do SSIS: simplesmente apontar um pacote do SSIS existente para o Snowflake não é uma estratégia viável. A abordagem recomendada é reestruturar a lógica do SSIS com ferramentas nativas da nuvem, adotando o padrão ELT (extrair, carregar, transformar). Isso envolve desativar o SSIS e recriar a lógica de negócios usando ferramentas como dbt (ferramenta de construção de dados) para transformações no data warehouse, com orquestração gerenciada por uma ferramenta como o Apache Airflow.
Migração do SQL Server Agent: a funcionalidade de agendamento do SQL Server Agent deve ser migrada. Trabalhos simples e não dependentes podem ser agendados usando tarefas Snowflake nativas. Fluxos de trabalho complexos com dependências exigem um orquestrador externo mais robusto, como o Apache Airflow ou o Azure Data Factory.
Fase 6: Relatórios e análises¶
Uma migração de data warehouse só é considerada concluída quando os usuários finais estão utilizando a nova plataforma com sucesso por meio de suas ferramentas de análise preferidas. Essa última parte do projeto muitas vezes é subestimada e requer um planejamento meticuloso para gerenciar a aceitação do usuário, o desempenho e o custo.
Atividades principais:
Conexão de ferramentas de BI (Tableau, Power BI): tanto o Tableau quanto o Power BI são ferramentas essenciais no ecossistema Snowflake e oferecem conectores nativos de alto desempenho. Para ambas as ferramentas, uma decisão crítica deve ser tomada para cada painel individualmente entre uma conexão ao vivo (por exemplo, Tableau Live, Power BI DirectQuery) e um modelo importado/extraído.
Live/DirectQuery: fornece dados em tempo real, mas envia consultas diretamente para o Snowflake a cada interação do usuário, o que pode levar a custos computacionais significativos.
Extrair/importar: oferece excelente desempenho, atendendo às consultas a partir de uma cópia dos dados na memória, mas os dados são atualizados apenas até a última atualização.
O desafio e a substituição do SSRS:** conectar o SQL Server Reporting Services (SSRS) ao Snowflake é notoriamente desafiador e não é uma estratégia de longo prazo recomendada. A migração para o Snowflake deve servir como catalisador para um plano estratégico de desativação do SSRS. Os relatórios críticos do SSRS devem ser avaliados e reconstruídos em uma plataforma de BI moderna e nativa da nuvem, como o Power BI ou o Tableau.
Isolamento de carga de trabalho: para controlar o desempenho e o impacto nos custos dessas ferramentas de BI, é uma prática recomendada criar data warehouses virtuais dedicados e com tamanho adequado no Snowflake especificamente para cargas de trabalho de BI. Isso isola as consultas de BI de outras cargas de trabalho, como ETL.
Fase 7: Validação e testes de dados¶
Esta fase é onde a plataforma Snowflake recém-construída é testada e validada com rigor em relação ao sistema legado para construir confiança comercial e garantir uma implantação bem-sucedida. A validação de dados não pode ser deixada para depois e deve ir muito além da simples contagem de linhas.
Atividades principais:
Uma estratégia de validação de dados em várias camadas:
Nível 1: Validação de arquivos e objetos: use checksums ou funções hash para verificar se os arquivos de dados transferidos do sistema de origem para o ambiente na nuvem não foram corrompidos em trânsito.
Nível 2: Reconciliação e validação de agregados: execute consultas tanto no banco de dados do SQL Server de origem quanto nas tabelas do Snowflake de destino para comparar métricas importantes, como contagem de linhas e funções de agregação (
SUM,AVG,MIN,MAX) para todas as colunas numéricas principais.Nível 3: Validação em nível de célula (diferença de dados): para as tabelas mais críticas para os negócios, é necessária uma comparação mais granular, célula por célula, de uma amostra estatisticamente significativa de linhas para detectar erros sutis de conversão de tipo de dados ou bugs na lógica de transformação.
Teste de desempenho e teste de aceitação do usuário (UAT):
Teste de desempenho: os pipelines ETL/ELT e os relatórios de BI migrados devem ser testados em relação aos SLAs de desempenho definidos na fase de planejamento.
Teste de aceitação do usuário (UAT): é aqui que os usuários empresariais interagem com o novo sistema. Eles devem ter tempo e recursos para executar os relatórios, as consultas e validar se o sistema migrado atende aos requisitos funcionais que eles têm e produz os mesmos resultados que o sistema legado. O UAT é a etapa final antes da implantação da produção.
Fase 8: Implantação¶
Esta fase é a concretização de todos os esforços anteriores, em que o sistema validado é promovido para produção e ocorre a mudança formal, ou «transição», do sistema legado do SQL Server para o Snowflake. A estratégia deve ser escolhida para minimizar riscos e interrupções nos negócios.
Atividades principais:
Desenvolvimento de um plano de transição: em vez de uma migração única e abrupta, recomenda-se uma abordagem em fases para limitar o impacto de problemas potenciais.
Implantação em fases (recomendada):** migre aplicativos, relatórios ou unidades de negócios um a um ao longo de um período.
Execução paralela: por um período, execute o sistema legado do SQL Server e o novo sistema Snowflake em paralelo, alimentando ambos com dados e comparando as saídas para garantir 100% de consistência antes de desativar o sistema legado.
Estratégia de transição: durante uma implantação em fases ou uma execução paralela, é fundamental implementar uma estratégia de transição para que os usuários não precisem consultar dois sistemas diferentes. O objetivo é apresentar uma visão única e unificada para a empresa.
Lista de verificação de implantação final e assinatura das partes interessadas: antes da transição final, a equipe deve realizar uma revisão final de prontidão. Isso inclui verificar todas as permissões e funções, garantir que todas as contas de serviço estejam configuradas e confirmar se o monitoramento e os alertas estão ativos. Obtenha a aprovação formal e por escrito de todas as principais partes interessadas, tanto da área de negócios quanto da área técnica, antes de entrar em operação.
Fase 9: Otimizar e executar¶
A conclusão da transição marca o fim do projeto de migração, mas o início da vida operacional da plataforma. Uma plataforma de dados é um sistema vivo que requer manutenção, governança e otimização contínuas. No paradigma do Snowflake, o ajuste de desempenho e a otimização de custos são duas faces da mesma moeda: aplicar a quantidade certa de computação, pelo tempo certo, para atender a um SLA de negócios com o menor custo possível.
Atividades principais:
Ajuste de desempenho:
Dimensionamento e gerenciamento do warehouse virtual: este é o fator primordial que impacta tanto o desempenho quanto o custo. Monitore e dimensione continuamente os warehouses, crie warehouses separados para diferentes cargas de trabalho (isolamento de carga de trabalho) e assegure que todos os warehouses tenham uma política agressiva de suspensão automática.
Otimização de consultas: use a ferramenta Perfil de consulta do Snowflake para analisar visualmente e depurar consultas de execução lenta.
Chaves de clustering: para tabelas muito grandes (normalmente acima de um terabyte), definir uma chave de clustering pode melhorar significativamente o desempenho da consulta ao colocalizar fisicamente os dados relacionados.
Implementação de FinOps de longo prazo:
Monitoramento contínuo: revise regularmente os dados de custo e uso do esquema
ACCOUNT_USAGE.Showback e chargeback: implemente um modelo para atribuir custos às unidades de negócios ou projetos que os incorrem, a fim de promover a responsabilização.
Marcação de objetos: use o recurso de marcação do Snowflake para aplicar tags de metadados aos objetos e simplificar a alocação e a governança de custos.
Estabelecimento de segurança e governança de dados:
Aprimoramento de RBAC: Atualize continuamente a hierarquia RBAC e realize auditorias regulares para remover funções não utilizadas ou permissões excessivas.
Recursos de segurança avançados: para dados altamente sensíveis, implemente os recursos avançados de governança de dados do Snowflake, como Mascaramento dinâmico de dados e Políticas de acesso a linhas.