SQL ServerからSnowflakeへの移行ガイド¶
Snowflake移行フレームワーク¶
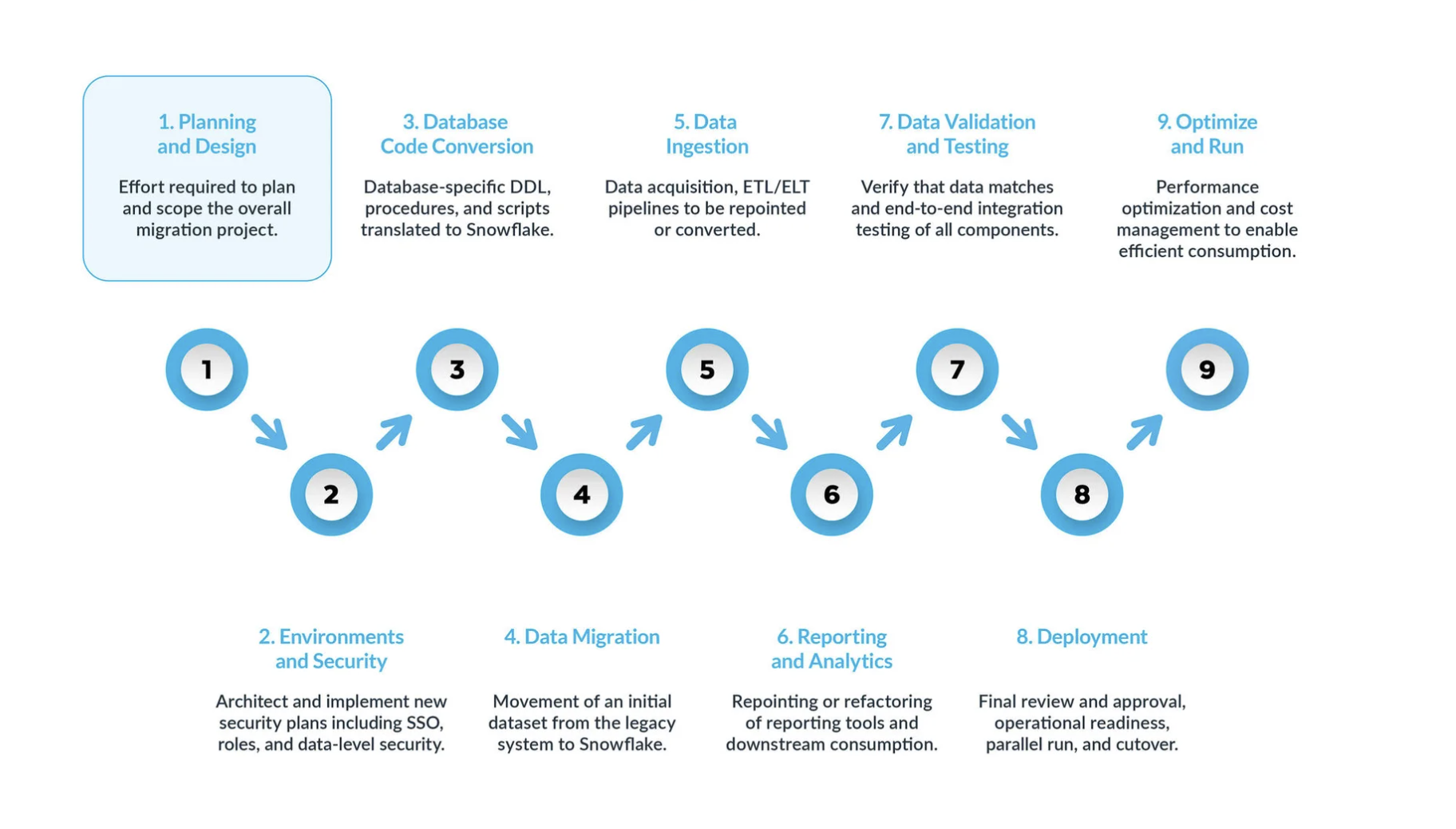
典型的な SQL ServerからSnowflakeへの移行は、9つの主要ステップに分けることができます。
計画と設計 は、移行プロセスにおいて見落とされがちなステップです。その主な理由は、企業は通常、プロジェクトの範囲を完全に理解していない場合であっても、進捗状況を迅速に示したいと考えるからです。だからこそ、このフェーズは移行プロジェクトを理解し、優先順位をつけるために非常に重要なのです。
環境とセキュリティ が、計画、明確なタイムライン、RACI マトリックス、すべての利害関係者の賛同とともに整ったら、いよいよ実行モードに移ります。 可動要素が多いことを考えると、移行を開始するために必要な環境とセキュリティ対策を設定することは、移行フェーズ開始前の非常に重要な工程です。また、移行を進める前にすべてのセットアップが完了していれば、移行プロジェクトへの影響はさらに大きくなります。
データベースコード変換 プロセスでは、テーブル定義、ビュー、ストアドプロシージャ、関数など、ソースシステムのデータベースカタログから直接コードを抽出します。いったん抽出したら、このコードをすべてSnowflakeの同等のデータ定義言語(DDLs)に移行します。このステップには、ビジネスアナリストがレポートやダッシュボードを作成するために使用するデータ操作言語(DML)スクリプトの移行も含まれます。 このコードをすべて移行し、Snowflakeで動くように調整する必要があります。その調整には、命名規則やデータ型のマッピングといった単純な変更から、構文やプラットフォームのセマンティクスなどのより複雑な違いの調整まで、さまざまなものがあります。これを支援するために、Snowflakeでは SnowConvert AI という強力なソリューションを提供し、データベースコード変換プロセスの大部分を自動化しています。
データ移行 には、異なるストレージシステム、フォーマット、またはコンピュータシステム間でデータを転送することが含まれます。SQL ServerからSnowflakeへの移行という文脈では、特に SQL Server環境から新しいSnowflake環境にデータを移動することを指します。
このガイドでは、主に2つのタイプについて説明します。
履歴データ移行: 特定の時点で SQL Serverデータのスナップショットを取得し、Snowflakeに転送します。これは多くの場合、最初の一括転送として行われます。
増分データ移行: 最初に行った履歴データの移行後、継続的に SQL ServerからSnowflakeへ新規または変更データを移行します。これにより、Snowflake環境がソースシステムに対して常に最新の状態に保たれます。
データ取り込み: 履歴データを移行した後、次のステップはデータ取り込みプロセスを移行し、様々なソースからライブデータを取り込むことです。通常、このプロセスは、ビジネスユーザーがデータを利用できるようになる前に、いつ、どこでデータ変換が行われるかによって、抽出、変換、ロード(ETL)、または抽出、ロード、変換(ELT)モデルに従って行われます。
レポーティングとアナリティクス: データベースが履歴データと継続的に新しいデータをインポートするライブパイプラインの両方を備えた今、次のステップは BI を介してこのデータから値を抽出することです。レポーティングは、標準的な BI ツールまたはカスタムクエリを使用して行うことができます。どちらの場合も、データベースに送信される SQL は、Snowflakeの要件を満たすように調整する必要がある場合があります。このような調整には、単純な名前の変更(移行時によくある)から、構文やより複雑な意味の違いまで、さまざまなものがあります。これらすべてを特定し、対処する必要があります。
データの検証とテスト: このフェーズに入る前に、データを可能な限りクリーンにしておくことが目標です。 各組織には独自のテスト方法とデータを実稼働環境に移行するための要件があります。これらはプロジェクト開始当初から十分に理解されている必要があります。
デプロイ: このステージで、データが検証され、同等のシステムがセットアップされます。すべての ETLs が移行済みで、レポートは検証済みです。これで実稼働の準備は万全でしょうか。 焦ってはいけません。最終的に実稼働へと進める前に、まだいくつかの重要な検討事項があります。まず、従前のアプリケーションは複数のコンポーネントやサービスで構成されている可能性があります。理想的には、これらのアプリケーションを1つずつ移行し(並行移行も可能ですが)、同じ順番で実稼働環境に移行する必要があります。このプロセスでは、ビジネスユーザーがSnowflakeと従前のシステムの両方をクエリする必要がないように、ブリッジング戦略を確実に実施します。まだ移行されていないアプリケーションのデータ同期は、このブリッジングのメカニズムを通じて舞台裏で行われる必要があります。そうしなければ、ビジネスユーザーはハイブリッド環境で仕事をしなければならなくなり、このセットアップの意味を理解しておく必要が生じます。
最適化と実行: システムがSnowflakeに移行されると、通常のメンテナンスモードに入ります。すべてのソフトウェアシステムは、継続的なメンテナンスを必要とする生きた存在です。移行後のこのフェーズは、最適化と実行と呼ばれるもので、移行自体には含まれません。
主なフェーズ¶
SQL ServerからSnowflakeへの移行を成功させることは、明確に定義された一連のフェーズにわたって展開されるモダナイゼーションプロジェクトです。この構造化された9段階のアプローチに従うことで、初期戦略から長期的なオペレーショナルエクセレンスまでのすべてに対応する、包括的かつ体系的な移行が実現します。
フェーズ1:計画と設計¶
この最初のフェーズは、正確なスコーピング、現実的なタイムライン、利害関係者の調整などの基礎を築くため、移行プロジェクト全体の成功にとって最も重要です。計画フェーズを急いだり不完全なまま進めたりすると、予算超過、納期遅れ、プロジェクト失敗の主な原因となります。目的は、単に既存のシステムのカタログを作ることではなく、どの資産が新しいプラットフォームに移行するのに十分な価値があるかを戦略的に決定することです。「すべてをリフトアンドシフト」するアプローチでは、長年蓄積された技術的負債を移行し、初日からクラウドのコストを膨れ上がらせてしまいます。
主要活動:
包括的なインベントリの作成: 最初のステップは、移行の範囲内にあるすべての資産の詳細かつ網羅的なマニフェストを作成することです。このインベントリは、自動検出ツール、システムカタログクエリ、およびアプリケーション所有者へのインタビューを組み合わせて作成する必要があります。インベントリには、以下のものが含まれてる必要があります。
データベースオブジェクト: すべてのデータベース、スキーマ、テーブル、ビュー。テーブルについては、行数と生データサイズを記録します。
プロシージャコード: すべてのストアドプロシージャ、ユーザー定義関数(UDFs)、トリガー、およびカーソルを使用するロジック。
自動化と ETL: すべての SQL Serverエージェントのジョブ、そのスケジュール、およびそれらの依存関係。SQL Server Integration Services(SSIS)パッケージの完全なカタログは、特に重要です。
下流コンシューマー: SSRS レポート、Power BI ダッシュボード、Tableauワークブックなど、データベースに接続するすべてのアプリケーションと BI ツール。
セキュリティプリンシパル: すべてのユーザー、ロール、およびきめ細かな権限。
システムデータベースの除外: SQL Serverの内部システムデータベース(
master、msdb、tempdb、model)の移行を試みるのは重大な間違いです。これらは、SQL Serverインスタンスには不可欠ですが、Snowflakeでは機能または同等のものはなく、すべての移行計画から明示的に除外する必要があります。
移行の目標、範囲、成功を判断するメトリックの定義: 完全なインベントリを使うことで、チームはビジネス成果に結びついた明確で測定可能な目標を定義することができます。例は次のとおりです。
目標: 月末財務レポートのパフォーマンスを改善する。
メトリック: 「MonthEnd_Consolidation」レポートスイートの実行時間を50%削減する。
目標: データウェアハウスの総所有コスト(TCO)を削減する。
メトリック: 年間 TCO を前年比で30%削減する。
利害関係者の調整と移行チームの招集(RACI): データプラットフォームの移行はビジネストランスフォーメーションです。すべての利害関係者と早期から継続的に関わることが重要です。移行チームには、ビジネスユーザー、データエンジニアリング、財務、セキュリティ、法務の代表者を含める必要があります。Responsible(実行責任者)、Accountable(説明責任者)、Consulted(相談先)、Informed(報告先)を表す RACI マトリックスを確立し、役割と責任を公式化する必要があります。
FinOps の導入: Snowflakeの消費ベースのコストモデルへの移行は、当初から計画される必要があります。移行チームは、財務部門と調整し、価格設定モデルを理解し、予算を設定し、コストをどのように追跡して帰属させるかを定義する必要があります(多くの場合、Snowflakeのオブジェクトのタグ付け機能を使用します)。
初期評価とトリアージ: インベントリは、重要なトリアージプロセスに必要なデータを提供します。チームは使用ログを分析し、冗長なデータや古いデータ、未使用のオブジェクト、移行せずに廃止またはアーカイブする仮ステージのデータなどを特定します。
フェーズ2:環境とセキュリティ¶
戦略的プランが整ったところで、このフェーズでは基盤となるSnowflake環境を構築します。これは、従前のセキュリティモデルを単純に1対1でマッピングするのではなく、第一原理からクリーンでセキュアで統治可能なデータプラットフォームを設計する「グリーンフィールド」の機会です。ほとんどの成熟した SQL Server環境は、過度に広範なアクセスや一貫性のないロールのような「セキュリティ負債」に悩まされていますが、これを解決することがこのフェーズの目的です。
主要活動:
Snowflakeアカウント構造の設計 ほとんどの企業では、データとメタデータを完全に分離するために、マルチアカウント戦略が推奨されます。これには通常、次の個別アカウントが含まれます。
実稼働アカウント: 厳格なセキュリティ管理のもと、すべての実稼働データとワークロードを収容します。
開発/QA アカウント: すべての開発およびテスト活動のための独立したアカウント。
サンドボックスアカウント(オプション): データサイエンティストやアナリストによる実験的作業用のアカウント。
強固なセキュリティモデルの実装: セキュリティは階層的に実装される必要があります。
ネットワークポリシー: 防御の第一線として、ネットワークポリシーを作成し、Snowflakeアカウントへのアクセスを、信頼できる IP アドレスのホワイトリストに制限します。
認証: 全ユーザーに多要素認証(MFA)を強制します。シームレスでセキュアなユーザーエクスペリエンスを実現するには、SnowflakeをAzure Active Directory(Azure AD)やOktaのような企業のシングルサインオン(SSO)プロバイダーと統合します。
ロールベースのアクセス制御(RBAC)階層の設計: これはSnowflakeセキュリティの礎石です。オブジェクトのすべての権限はロールにのみ与えられ、次にロールがユーザーに付与されます。ベストプラクティスの階層構造では、明確なタイプのロールを作成します。
システム定義のロール:
ACCOUNTADMINやSYSADMINなどで、管理業務のみに使用されます。機能的ロール: ビジネス機能にマッピングされるカスタムロール(例:
FINANCE_ADMINやMARKETING_ANALYSTなど)。アクセスロール: 特定の権限を定義する粒度の細かいロール(例:
READ_ONLYやWRITE_ACCESSなど)。これらのロールは、管理を簡素化するために階層的に付与されます。
リソースモニターとコストコントロールの設定: リソースモニターは、Snowflake内でコストコントロールを実施するための主要なツールです。アカウントレベルとウェアハウスレベルの両方でクレジット消費を追跡するために、初期環境設定の一部として設定される必要があります。各モニターについて、予算超過を防ぐために、通知と停止のトリガーを設定します(例えば、クォータの75%でメールを送信し、100%でウェアハウスを一時停止するなど)。
フェーズ3:データベースコード変換¶
このフェーズでは、データベースの物理構造と手続きロジックを SQL Serverの T-SQL からSnowflakeの ANSI 準拠 SQL へ技術的に変換することに重点を置きます。これは多くの場合、移行の中で最も複雑で時間のかかる部分です。このプロセスは、データ処理ロジックをモダナイズするきっかけとなり、命令型のステートフルなロジックから、宣言型のセットベースの処理への根本的なシフトを余儀なくされます。
主要活動:
データ定義言語(DDL)の翻訳: これには
CREATE TABLEとCREATE VIEWステートメントの抽出と変換が含まれます。構文の違いとデータ型のマッピングを処理しながら、T-SQL DDL を解析し、同等のSnowflake SQL を生成するために、Snowflakeの SnowConvert AI のような自動コード変換ツールが強く推奨されます。データ型マッピング: 正確なデータ型マッピングは基盤です。多くの型が直接マッピングされますが(例えば
INTからNUMBER)、いくつかの重要な違いには注意が必要で、特に日付/時刻型についてはなおさらです。SQL ServerのDATETIMEとDATETIME2はタイムゾーン非対応であるため、SnowflakeのTIMESTAMP_NTZにマッピングする必要があります。逆に、DATETIMEOFFSETはタイムゾーンオフセットを含んでおり、この情報を保持するためにTIMESTAMP_TZにマッピングされる必要があります。制約の扱い(強制か非強制か): これは概念の大きな転換を意味します。SQL Serverでは、主キーや外部キーのような制約がデータベースエンジンによって 強制 されます。Snowflakeでは、これらの制約は定義できますが 強制はされません 。それらは純粋にメタデータとして存在している。データの完全性を維持する責任は、データベースからデータパイプライン(ETL/ELT プロセス)に完全に移行します。
ストアドプロシージャとT-SQL の変換: T-SQL ストアドプロシージャの移行は、重要な仕事です。
SQL 方言の不一致: 数多くのT-SQL 関数と構文構造には変換が必要です(たとえば、
GETDATE()はCURRENT_TIMESTAMP()に、ISNULL()はCOALESCE()になる)。ロジックのリファクタリング: SQL ベースの手続き型言語であるSnowflakeスクリプトを使用して、T-SQL 手続きを書き換えるのが望ましい方法です。包括的な目標は、(カーソルのような)行ごとの処理を排除し、可能な限りセットベースの SQL ステートメントを使用することです。
カーソルとトリガーの置き換え: カーソルはSnowflakeにおける深刻なパフォーマンスのアンチパターンであり、排除する必要があります。Snowflakeはトリガーをサポートしていません。トリガーの機能は、ストリームがテーブルの変更をキャプチャし、スケジュールされたタスクがそれらの変更を使用してビジネスロジックを適用する ストリームとタスク というクラウドネイティブなパターンを使用して再実装する必要があります。
フェーズ4:データ移行¶
このフェーズでは、ソースである SQL ServerシステムからターゲットであるSnowflake環境への履歴データの最初の一括転送に焦点を当てます。Snowflakeにデータをロードするための基本的なアーキテクチャは、 ソース -> ステージ -> ターゲット の「スリーボックス」モデルです。データはソースからターゲットに直接移動されるのではなく、まず中間のクラウドオブジェクトストレージの場所(ステージ)に置かれます。
主要活動:
SQL Serverからのデータ抽出: 履歴データの初期移行には、SQL Serverのネイティブ Bulk Copy Program(BCP) コマンドラインユーティリティが非常に効率的です。大きなテーブルをフラットファイル(例: CSV)に高速でエクスポートできます。これらのファイルは、クラウドステージ(Amazon S3やAzure Blob Storageなど)にアップロードすることができます。
ステージからSnowflakeへのデータのロード: データファイルがクラウドステージに存在するようになった後、取り込みの主なメカニズムは
COPY INTO <table>コマンドです。これは、高パフォーマンスの一括データロードを行うための主力 SQL コマンドです。超並列方式で動作するように設計されています。最適なパフォーマンスを得るためには、大きなデータセットを適度なサイズ(100~250MB が一般的な推奨値)の複数のファイルに分割し、この並列性を最大化するのがベストプラクティスです。
フェーズ5:データの取り込み¶
履歴データを移行した後のこのフェーズでは、さまざまなソースからライブの増分データをSnowflakeに取り込むための、継続的なデータ取り込みプロセスの移行に焦点を当てます。これには通常、SSIS のようなレガシー ETL ツールからのロジックの移行と、SQL Serverエージェントからのスケジューリングが含まれます。
主要活動:
増分データの複製: 最初にロードした後の継続的な変更を複製するには、SQL Serverのネイティブな Change Data Capture (CDC) 機能が好ましいメソッドです。CDC は、データベースのトランザクションログを読み込んで、
INSERT操作、UPDATE操作、DELETE操作のすべてを発生時にキャプチャすることで機能し、影響の少ないほぼリアルタイムの変更ストリームを提供します。Snowpipeによる継続的な取り込み: Snowpipe はSnowflakeの継続的なデータインジェスションサービスで、ストリーミングやマイクロバッチのユースケース向けに設計されています。ここでは、ステージをサブスクライブする
PIPEオブジェクトを作成します。CDC プロセスで生成された新しい変更ファイルがステージに到着すると、Snowpipeが自動的にトリガーされ、データがロードされます。MERGE による変更の適用: 変更データが(Snowpipe経由で)Snowflakeの仮ステージングテーブルにロードされた後、
MERGEコマンドを使用して、これらの変更を最終的な実稼働テーブルに適用します。挿入、更新、削除を単一のアトミックステートメントで処理できます。SSIS およびSQL Serverエージェントジョブのモダナイゼーション:
SSIS の移行: ただ既存の SSIS パッケージをSnowflakeに移すというのは、有望な戦略ではありません。推奨されるアプローチは、 抽出(Extract)、ロード(Load)、転換(Transform)の ELT パターンを取り入れながら、クラウドネイティブツールを使って SSIS ロジック を再構築することです。これには、SSIS を廃止し、ビジネスロジックを再構築する必要があります。ウェアハウス内での変換に dbt(データビルドツール) のようなツールを使い、オーケストレーションの管理を Apache Airflow のようなツールで行うなどします。
SQL Serverエージェントの移行: SQL Serverエージェントのスケジューリング機能を移行する必要があります。シンプルで依存関係のないジョブは、ネイティブの Snowflakeタスク を使用してスケジュールできます。依存関係を持つ複雑なワークフローには、Apache AirflowやAzure Data Factoryのような、より強力な外部オーケストレーターが必要です。
フェーズ6:レポートと分析¶
データウェアハウスの移行が真に完了するのは、エンドユーザーが好みの分析ツールを使って新しいプラットフォームをうまく利用できるようになってからです。このプロジェクトの「ラストワンマイル」は過小評価されがちで、ユーザーの受け入れ、パフォーマンス、コストを管理するための綿密な計画が必要となります。
主要活動:
BI ツール(Tableau、Power BI)の接続: Tableau と Power BI はどちらもSnowflakeエコシステムの第一級市民であり、ネイティブな高性能コネクタを提供しています。両ツールとも、 ライブ接続 (例: Tableau Live、Power BI DirectQuery)と インポート/抽出モデル との間で、ダッシュボードごとに重要な決定を下さなければなりません。
Live/DirectQuery: リアルタイムのデータを提供するが、ユーザーとのインタラクションごとにクエリを直接Snowflakeに送信するため、多大なコンピューティングコストが発生する可能性があります。
抽出/インポート: データのインメモリコピーからクエリを提供することによって優れたパフォーマンスを提供しますが、データの新鮮度は最終更新と同じでしかありません。
SSRS の課題と代替: SQL Server Reporting Services(SSRS)のSnowflakeへの接続は、難題としてよく知られており、長期的な戦略としては推奨されません。Snowflakeへの移行は、 SSRS を廃止する 戦略的計画のきっかけとなるはずです。重要な SSRS レポートは、Power BI やTableauのような最新のクラウドネイティブ BI プラットフォームで評価し、再構築する必要があります。
ワークロードの分離: これらの BI ツールのパフォーマンスとコストへの影響を管理するためのベストプラクティスは、BI ワークロード専用の適切なサイズの仮想ウェアハウスをSnowflakeに作成することです。これにより、BI クエリを ETL のような他のワークロードから分離することができます。
フェーズ7:データ検証とテスト¶
このフェーズでは、新たに構築されたSnowflakeプラットフォームをレガシーシステムに対して厳格にテスト、検証することで、ビジネスの信頼を構築し、導入の成功を確実なものにします。データ検証は後回しにすることはできず、単純な行数のカウントをはるかに超えるものでなければなりません。
主要活動:
多層的なデータ検証戦略:
レベル1:ファイルおよびオブジェクトの検証: チェックサムまたはハッシュ関数を使用して、ソースシステムからクラウドステージに転送されたデータファイルが転送中に破損していないことを検証します。
レベル2:照合と集約の検証: ソースの SQL ServerデータベースとターゲットのSnowflakeテーブルの両方でクエリを実行し、行数やすべての主要な数値列の集計関数(
SUM、AVG、MIN、MAX)などの主要なメトリックを比較します。レベル3:セルレベルの検証(Data Diff): 最もビジネスクリティカルなテーブルでは、微妙なデータ型の変換エラーや変換ロジックのバグを検出するために、統計的に有意な行のサンプルをセル単位でより詳細に比較する必要があります。
パフォーマンステストとユーザー受け入れテスト(UAT):
パフォーマンステスト: 移行された ETL/ELT パイプラインおよび BI レポートは、計画段階で定義済みのパフォーマンス SLAs に対してテストされる必要があります。
ユーザー受け入れテスト(UAT): ここでは、ビジネスユーザーが新システムを実際に使用します。ビジネスユーザーがレポートを実行し、クエリを実行し、移行したシステムが機能要件を満たし、レガシーシステムと同じ結果を出すことを検証するための時間とリソースを与える必要があります。UAT は、実稼働用にデプロイする前の最終関門です。
フェーズ8:デプロイ¶
このフェーズは、それまでのすべての努力の集大成であり、検証されたシステムが実稼働に昇格し、レガシーの SQL ServerシステムからSnowflakeへの正式な切り替え、つまり「カットオーバー」が行われます。その戦略は、リスクと事業の中断を最小限に抑えるように選択される必要があります。
主要活動:
カットオーバー計画の策定: 潜在的な問題の「爆発半径」を限定するために、単発の「ビッグバン」カットオーバーではなく、段階的なアプローチが推奨されます。
段階的ロールアウト(推奨): アプリケーション、レポート、またはビジネスユニットを、一定期間をかけて1つずつ移行します。
並行運用: レガシーシステムを廃止する前に、一定期間、レガシーシステムである SQL Serverと新しいSnowflakeシステムの両方を並行して稼動させ、両方にデータを供給して出力を比較し、100%の一貫性を確保します。
ブリッジング戦略: 段階的ロールアウトや並行運用の際には、ユーザーが2つの異なるシステムにクエリする必要がないように、ブリッジング戦略を取り入れることが重要です。目標は、ビジネスに対して単一の統一されたビューを示すことです。
最終デプロイチェックリストと利害関係者のサインオフ: 最終的なカットオーバーの前に、チームは最終的な準備状況のレビューを行う必要があります。これには、すべての権限とロールの確認、確実にすべてのサービスアカウントが整っていることの確認、モニタリングとアラートが有効であることの確認が含まれます。実際の稼働に入る前に、すべての主要なビジネスと技術の利害関係者から正式な書面による署名を得ます。
フェーズ9:最適化と実行¶
カットオーバーの完了は、移行プロジェクトの終了とプラットフォームの運用開始を意味します。データプラットフォームは、継続的なメンテナンス、ガバナンス、最適化を必要とする生きたシステムです。Snowflakeのパラダイムでは、パフォーマンスチューニングとコスト最適化は同じコインの表裏の関係にあります。つまり、ビジネス SLA を可能な限り低いコストで満たすために、適切な量のコンピュートを適切な時間だけ適用するということです。
主要活動:
パフォーマンスチューニング:
仮想ウェアハウスのサイジングと管理: これはパフォーマンスとコストの両面で重要な役割を果たします。ウェアハウスを継続的に監視し、適切なサイズに設定し、ワークロードごとにウェアハウスを分け(ワークロードの分離)、すべてのウェアハウスに確実に積極的な自動一時停止ポリシーが適用されるようにします。
クエリの最適化: Snowflakeの クエリプロファイル ツールを使用して、実行速度の遅いクエリを視覚的に分析し、デバッグします。
クラスタリングキー: 非常に大きなテーブル(通常1テラバイト以上)の場合、クラスタリングキーを定義することで、関連するデータを物理的に同一の場所に置くことにより、クエリパフォーマンスを大幅に改善させることができます。
長期的 FinOps の実装:
継続的モニタリング:
ACCOUNT_USAGEスキーマからコストと使用量データを定期的に精査します。ショーバックとチャージバック: 説明責任を推進するために、コストを発生源のビジネスユニットやプロジェクトに関連付けし直すモデルを実装します。
オブジェクトのタグ付け: Snowflakeのタグ付け機能を使用して、オブジェクトにメタデータタグを適用し、コスト割り当てとガバナンスを簡素化します。
データガバナンスとセキュリティの確立:
RBAC の改良: RBAC 階層を継続的に更新し、定期的な監査を実施して、未使用のロールや過剰な権限を削除します。
高度なセキュリティ機能: 機密性の高いデータに ダイナミックデータマスキング や 行アクセスポリシー など、Snowflakeの高度なデータガバナンス機能を実装します。