Leitfaden zur Migration von SQL Server zu Snowflake¶
Snowflake-Migrationsframework¶
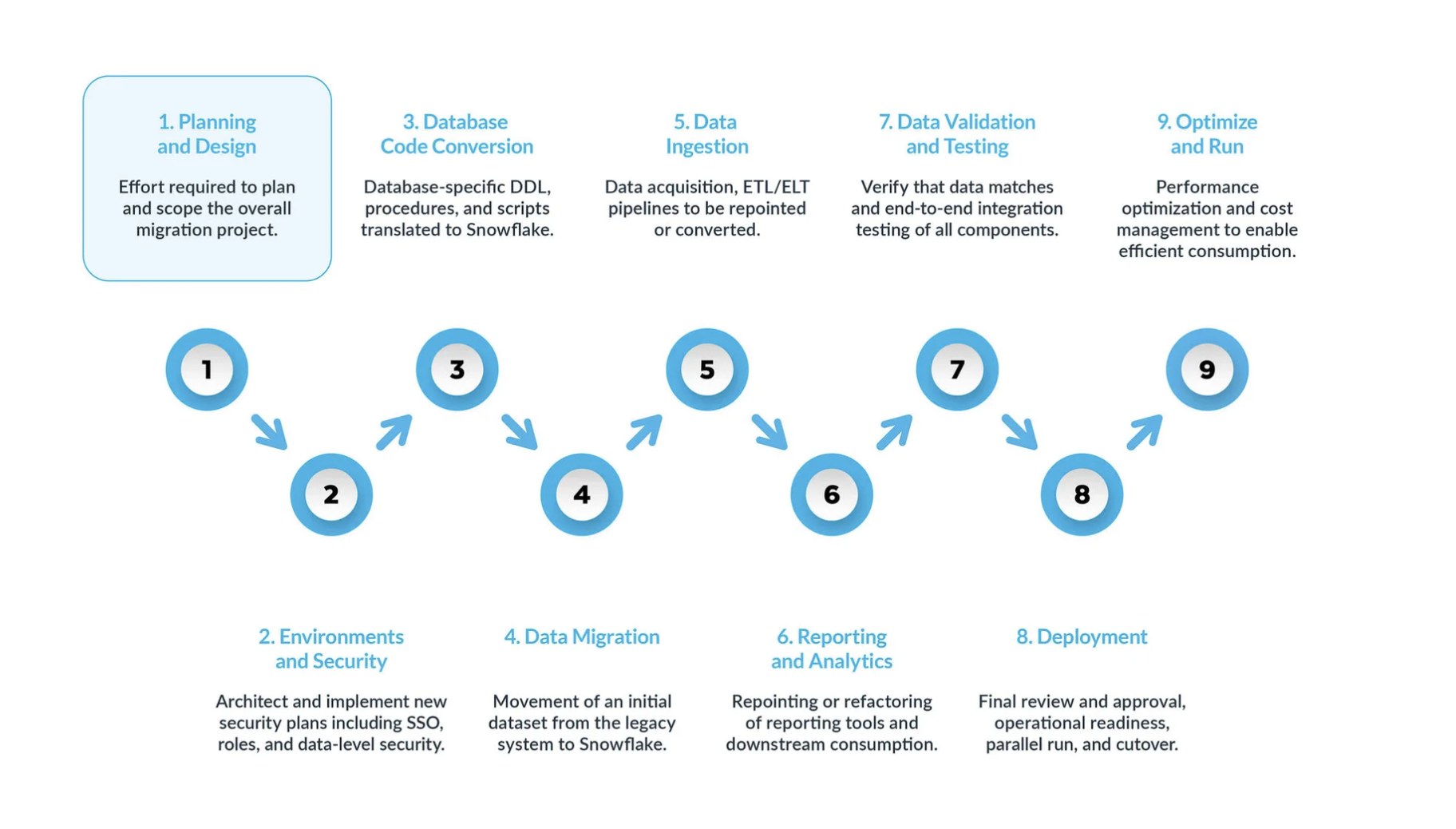
Eine typische SQL Server-zu-Snowflake-Migration kann in neun Hauptschritte unterteilt werden.
Planung und Entwurf sind oft übersehene Schritte im Migrationsprozess. Der Hauptgrund ist, dass Unternehmen in der Regel schnell Fortschritte zeigen möchten, auch wenn sie den Umfang des Projekts nicht vollständig verstanden haben. Daher ist diese Phase entscheidend, um das Migrationsprojekt zu verstehen und zu priorisieren.
Umgebung und Sicherheit – mit einem Plan, einem klaren Zeitplan, einer RACI-Matrix und der Zustimmung aller Beteiligten ist es nun an der Zeit, in die Umsetzungsphase überzugehen. Die Einrichtung der erforderlichen Umgebungen und Sicherheitsmaßnahmen vor Beginn der Migrationsphase ist äußerst wichtig, da viele Komponenten ineinandergreifen. Das Migrationsprojekt wird deutlich erfolgreicher verlaufen, wenn alle Vorbereitungen abgeschlossen sind, bevor es weitergeht.
Der Prozess der Datenbankcode-Konvertierung umfasst das Extrahieren von Code direkt aus dem Datenbankkatalog der Quellsysteme, wie z. B. Tabellendefinitionen, Ansichten, gespeicherten Prozeduren und Funktionen. Sobald Sie diesen Code extrahiert haben, migrieren Sie diesen Code in entsprechende Datendefinitionssprachen (DDLs) in Snowflake. Dieser Schritt umfasst auch die Migration von Data Manipulation Language (DML)-Skripten, die von Business-Analysten zur Erstellung von Berichten oder Dashboards verwendet werden können. Der gesamte Code muss migriert und angepasst werden, damit er in Snowflake funktioniert. Die Anpassungen können von einfachen Änderungen, wie Namenskonventionen und Zuordnungen von Datentypen, bis hin zu komplexeren Unterschieden in der Syntax, der Semantik der Plattformen und anderen Faktoren reichen. Um dies zu unterstützen, bietet Snowflake eine leistungsstarke Lösung namens SnowConvert AI, die einen großen Teil des Konvertierungsprozesses von Datenbankcode automatisiert.
Datenmigration Bei der Datenmigration werden Daten zwischen verschiedenen Speichersystemen, Formaten oder Computersystemen übertragen. Im Zusammenhang mit einer Migration von SQL-Server nach Snowflake bezieht sich der Begriff speziell auf das Verschieben von Daten aus Ihrer SQL-Server-Umgebung in Ihre neue Snowflake-Umgebung.
Es gibt zwei Haupttypen, die in diesem Leitfaden behandelt werden:
Migration historischer Daten: Erstellen eines Snapshots von SQL-Server-Daten zu einem bestimmten Zeitpunkt und Übertragen dieser Daten auf Snowflake. Dies erfolgt oft als erste Massenübertragung.
Inkrementelle Datenmigration: Laufende Übertragung neuer oder geänderter Daten von SQL-Server nach Snowflake nach der anfänglichen historischen Migration. Dadurch wird sichergestellt, dass Ihre Snowflake-Umgebung mit Ihren Quellsystemen auf dem neuesten Stand bleibt.
Datenaufnahme: Nach der Migration der historischen Daten besteht der nächste Schritt in der Migration des Datenaufnahmeprozesses, bei dem Live-Daten aus verschiedenen Quellen eingelesen werden. Typischerweise folgt dieser Prozess einem Extract, Transform, Load (ETL)- oder Extract, Load, Transform (ELT)-Modell – je nachdem, wann und wo die Datenumwandlung erfolgt, bevor die Daten den Business-Usern zur Verfügung stehen.
Berichterstellung und Analysen: Da die Datenbank nun sowohl historische Daten als auch laufende Pipelines enthält, die kontinuierlich neue Daten importieren, besteht der nächste Schritt darin, aus diesen Daten durch BI Wert zu schöpfen. Die Berichterstellung kann mit Standard-BI-Tools oder benutzerdefinierten Abfragen erfolgen. In beiden Fällen muss das an die Datenbank gesendete SQL möglicherweise angepasst werden, um den Anforderungen von Snowflake zu entsprechen. Diese Anpassung kann von einfachen Namensänderungen (häufig während der Migration) bis hin zur Syntax und komplexeren semantischen Unterschieden reichen. Sie alle müssen identifiziert und erledigt werden.
Datenvalidierung und -tests: Das Ziel besteht darin, die Daten so sauber wie möglich zu haben, bevor diese Phase beginnt. Jedes Unternehmen hat seine eigenen Testmethoden und Anforderungen, um Daten in die Produktion zu verschieben. Diese müssen von Beginn des Projekts an vollständig verstanden werden.
Bereitstellung. In dieser Phase werden die Daten validiert, ein entsprechendes System eingerichtet, alle ETLs wurden migriert und die Berichte wurden verifiziert. Sind Sie bereit, live zu gehen? Nicht so schnell – es gibt noch einige kritische Überlegungen, bevor es endgültig in die Produktion gehen kann. Erstens kann Ihre Legacy-Anwendung aus mehreren Komponenten oder Services bestehen. Idealerweise sollten Sie diese Anwendungen eine nach der anderen migrieren (obwohl eine parallele Migration möglich ist) und sie in der gleichen Reihenfolge in die Produktion überführen. Stellen Sie während dieses Prozesses sicher, dass Ihre Bridging-Strategie implementiert ist, damit Business-User nicht sowohl Snowflake als auch das Altsystem abfragen müssen. Die Datensynchronisierung für Anwendungen, die noch nicht migriert wurden, sollte im Hintergrund durch den Bridging-Mechanismus erfolgen. Wenn dies nicht geschieht, müssen die Benutzer in einer hybriden Umgebung arbeiten und die Auswirkungen dieses Setups verstehen.
Optimieren und ausführen – sobald ein System auf Snowflake migriert wurde, wechselt es in den normalen Wartungsmodus. Alle Softwaresysteme sind lebende Organismen, die eine laufende Wartung erfordern. Diese Phase nach der Migration wird als „Optimieren und Ausführen“ bezeichnet und ist nicht Teil der Migration selbst.
Wichtige Phasen¶
Eine erfolgreiche Migration von SQL Server zu Snowflake ist ein Modernisierungsprojekt, das sich über eine Reihe klar definierter Phasen erstreckt. Die Anwendung dieses strukturierten Neun-Phasen-Ansatzes gewährleistet einen umfassenden und methodischen Übergang – von der anfänglichen Strategie bis hin zur langfristigen operativen Exzellenz.
Phase 1: Planung und Entwurf¶
Diese erste Phase ist entscheidend für den Erfolg des gesamten Migrationsprojekts, da sie die Grundlage für eine präzise Umfangsbestimmung, realistische Zeitpläne und die Abstimmung aller Beteiligten schafft. Eine übersprungene oder unvollständige Planungsphase ist die häufigste Ursache für Budgetüberschreitungen, verstrichene Fristen und Projektfehler. Das Ziel ist es nicht nur, das bestehende System zu katalogisieren, sondern auch strategisch zu entscheiden, welche Ressourcen wertvoll genug sind, um auf die neue Plattform migriert zu werden. Ein pauschaler „Lift-and-Shift“-Ansatz führt meist dazu, dass Altlasten einfach mitgenommen werden – und die Cloud-Kosten schon am ersten Tag unnötig steigen.
Wichtige Aktivitäten:
Umfassende Bestandsaufnahme durchführen: Der erste Schritt besteht darin, ein detailliertes und vollständiges Verzeichnis aller Assets zu erstellen, die in den Umfang der Migration fallen. Diese Bestandsaufnahme sollte mithilfe einer Kombination aus automatisierten Erkennungstools, Systemkatalogabfragen und Interviews mit den Anwendungsverantwortlichen erstellt werden. Bestände müssen Folgendes enthalten:
Datenbankobjekte: Alle Datenbanken, Schemas, Tabellen und Ansichten. Für Tabellen, Dokumentzeilenzahl und Rohdatengröße.
Prozeduraler Code: Alle gespeicherten Prozeduren, benutzerdefinierten Funktionen (UDFs), Trigger und jegliche Logik, die Cursors verwendet.
Automatisierung und ETL: Alle Jobs von SQL Server Agent, deren Zeitpläne und deren Abhängigkeiten. Ein vollständiges Verzeichnis der SQL Server Integration Services (SSIS)-Pakete ist besonders wichtig.
Downstream-Verbraucher: Alle Anwendungen und BI-Tools, die eine Verbindung zur Datenbank herstellen, wie z. B. SSRS-Berichte, Power BI Dashboards und Tableau-Arbeitsmappen.
Sicherheitsprinzipale: Alle Benutzer, Rollen und detaillierten Berechtigungen.
Ausschluss von Systemdatenbanken: Es ist ein schwerwiegender Fehler, zu versuchen, die internen Systemdatenbanken von SQL Server (
master,msdb,tempdb,model) zu migrieren. Diese sind integraler Bestandteil einer SQL Server-Instanz, haben jedoch keine Funktion oder Entsprechung in Snowflake und müssen ausdrücklich aus allen Migrationsplänen ausgeschlossen werden.
Festlegung von Migrationszielen, Umfang und Erfolgskriterien: Mit einer vollständigen Bestandsaufnahme kann das Team klare und messbare Ziele definieren, die an geschäftliche Ergebnisse gekoppelt sind. Diese Beispiele sind:
Ziel: Verbesserung der Performance der Finanzberichterstattung zum Monatsende.
Metrik: Reduzieren Sie die Laufzeit der „MonthEnd_Consolidation“-Report Suite um 50 %.
Ziel: Reduzieren der Gesamtbetriebskosten für das Data Warehousing (TCO).
Metrik: Verringern des jährlichen TCO um 30 % im Vergleich zu den Kosten des Vorjahres.
Abstimmung der Interessengruppen und Berücksichtigung des Migrationsteams (RACI): Eine Datenplattform-Migration ist eine Geschäftstransformation. Eine frühzeitige und kontinuierliche Einbeziehung aller Interessengruppen ist entscheidend. Das Migrationsteam sollte Verantwortliche aus den Bereichen Geschäftsanwender, Data Engineering, Finanzen, Sicherheit und Recht umfassen. Eine RACI-Matrix (Responsible, Accountable, Consulted, Informed) sollte erstellt werden, um Rollen und Verantwortlichkeiten klar festzulegen.
Einführung von FinOps: Die Umstellung auf das verbrauchsabhängige Kostenmodell von Snowflake muss von Anfang an geplant werden. Das Migrationsteam muss sich mit der Finanzabteilung abstimmen, um das Preismodell zu verstehen, Budgets aufzustellen und festzulegen, wie die Kosten verfolgt und zugeordnet werden sollen, wobei häufig die Features des Objekt-Taggings von Snowflake verwendet werden.
Erstmalige Bewertung und Triage: Die Bestandsliste liefert die Daten, die für einen kritischen Triage-Prozess benötigt werden. Das Team sollte die Nutzungsprotokolle analysieren, um redundante oder veraltete Daten, nicht verwendete Objekte und temporäre Stagingdaten zu identifizieren, die dekomprimiert oder archiviert statt migriert werden können.
Phase 2: Umgebung und Sicherheit¶
Nach einem Strategieplan wird in dieser Phase die grundlegende Snowflake-Umgebung aufgebaut. Dies ist eine „Greenfield“-Gelegenheit, eine saubere, sichere und gut steuerbare Datenplattform von Grund auf neu zu entwerfen – anstatt das Altsystem-Sicherheitsmodell einfach 1:1 zu übernehmen. Die meisten gewachsenen SQL Server-Umgebungen leiden unter „Security Debt“, also Problemen wie zu weit gefasstem Zugriff und uneinheitlichen Rollen – genau diese sollen in dieser Phase behoben werden.
Wichtige Aktivitäten:
Architektur der Snowflake-Kontostruktur: Für die meisten Unternehmen wird eine Multi-Account-Strategie empfohlen, um eine vollständige Trennung von Daten und Metadaten sicherzustellen. Dies beinhaltet in der Regel separate Konten für:
Produktionskonto: Enthält alle Produktionsdaten und -Workloads mit strengsten Sicherheitskontrollen.
Entwicklung/QA-Konto: Ein separates Konto für alle Entwicklungs- und Testaktivitäten.
Sandbox-Konto (optional): Ein Konto für experimentelle Arbeiten von Datenwissenschaftlern oder -Analysten.
Implementierung eines robusten Sicherheitsmodells: Sicherheit sollte in Ebenen implementiert werden:
Netzwerkrichtlinien: Als erste Verteidigungslinie sollten Netzwerkrichtlinien erstellt werden, um den Zugriff auf das Snowflake-Konto auf eine Whitelist vertrauenswürdiger IP-Adressen zu beschränken.
Authentifizierung: Mehrstufige Authentifizierung (MFA) für alle Benutzer erzwingen. Für eine nahtlose und sichere Benutzererfahrung integrieren Sie Snowflake mit einem unternehmensweiten Single-Sign-On-(SSO)-Anbieter wie Azure Active Directory (Azure AD) oder Okta.
Role-Based Access Control (RBAC)-Hierarchie entwerfen: Dies ist der Grundpfeiler der Snowflake-Sicherheit. Alle Berechtigungen für Objekte werden ausschließlich Rollen erteilt, die dann den Benutzern zugewiesen werden. Eine bewährte Hierarchie besteht darin, unterschiedliche Typen von Rollen zu erstellen:
Systemdefinierte Rollen:
ACCOUNTADMIN,SYSADMINusw., die ausschließlich für administrative Aufgaben verwendet werden.Funktionale Rollen: Benutzerdefinierte Rollen, die Geschäftsfunktionen zugeordnet sind (z. B.
FINANCE_ADMIN,MARKETING_ANALYST).Zugriffsrollen: Granulare Rollen, die bestimmte Berechtigungen definieren (z. B.
READ_ONLY,WRITE_ACCESS). Diese Rollen werden dann in einer Hierarchie zugewiesen, um die Verwaltung zu vereinfachen.
Ressourcenmonitore und Kostenkontrollen konfigurieren: Ressourcenmonitore sind das primäre Tool in Snowflake zur Implementierung von Kostenkontrollen. Sie sollten als Teil der erstmaligen Einrichtung der Umgebung konfiguriert werden, um den Credit-Verbrauch sowohl auf Konto- als auch auf Warehouse-Ebene zu verfolgen. Legen Sie für jeden Monitor Benachrichtigungs- und Sperr-Schwellen fest (z. B. E-Mail bei 75 % des Kontingents, Warehouse bei 100 % aussetzen), um Budgetüberschreitungen zu verhindern.
Phase 3: Konvertierung von Datenbankcode¶
Diese Phase konzentriert sich auf die technische Übersetzung der physischen Datenbankstruktur und der prozeduralen Logik von SQL Server T-SQL zu Snowflakes ANSI-SQL-kompatiblem Dialekt. Dies ist oft der komplexeste und zeitaufwändigste Teil der Migration. Dieser Prozess dient als Katalysator zur Modernisierung der Datenverarbeitungslogik und erzwingt einen grundlegenden Wandel weg von imperativer, zustandsbehafteter Logik hin zu deklarativer, mengenbasierter Verarbeitung.
Wichtige Aktivitäten:
Data Definition Language (DDL) übersetzen: Dies umfasst das Extrahieren und Konvertieren von
CREATE TABLE- undCREATE VIEW-Anweisungen. Automatisierte Code-Konvertierungstools wie Snowflake SnowConvert AI werden dringend empfohlen, um T-SQL DDL zu analysieren und das entsprechende Snowflake-SQL zu generieren, wobei Syntaxunterschiede und Datentypzuordnungen berücksichtigt werden.Datentypen zuordnen: Eine genaue Zuordnung von Datentypen ist unerlässlich. Während viele Typen direkt zuordnen (z. B.
INTzuNUMBER), erfordern mehrere wichtige Unterschiede große Aufmerksamkeit, insbesondere bei Datums-/Uhrzeittypen. Die Datentypen von SQL ServerDATETIMEundDATETIME2sind nicht zeitzonenbewusst und müssen auf SnowflakesTIMESTAMP_NTZabgebildet werden. Umgekehrt enthältDATETIMEOFFSETeinen Zeitzonenoffset und muss aufTIMESTAMP_TZabgebildet werden, um diese Information beizubehalten.Einschränkungen (erzwungene vs. nicht erzwungene) handhaben: Dies stellt eine erhebliche konzeptionelle Veränderung dar. In SQL Server- werden Einschränkungen wie Primärschlüssel und Fremdschlüssel von der Datenbank-Engine erzwungen. In Snowflake können diese Einschränkungen definiert werden. Sie werden aber nicht erzwungen. Sie existieren nur als Metadaten. Die Verantwortung für die Aufrechterhaltung der Datenintegrität verlagert sich vollständig von der Datenbank auf die Datenpipeline (ETL/ELT-Prozess).
Gespeicherte Prozeduren und T-SQL-Konvertierung: Die Migration von T-SQL-gespeicherten Prozeduren ist ein bedeutendes Unterfangen.
SQL-Dialekt-Diskrepanzen: Zahlreiche T-SQL-Funktionen und -Syntaxkonstrukte erfordern eine Konvertierung (z. B. wird
GETDATE()zuCURRENT_TIMESTAMP()undISNULL()wird zuCOALESCE()).**Logik überarbeiten: Der bevorzugte Ansatz besteht darin, T-SQL-Prozeduren mithilfe von Snowflake Scripting neu zu schreiben – einer SQL-basierten prozeduralen Sprache. Das übergeordnete Ziel besteht darin, die zeilenweise Verarbeitung (wie Cursors) zugunsten von satzbasierten SQL-Anweisungen zu eliminieren, wo immer dies möglich ist.
Cursor und Trigger ersetzen: Cursor sind in Snowflake ein schwerwiegendes Anti-Muster für die Performance und müssen eliminiert werden. Snowflake unterstützt keine Trigger; ihre Funktion muss mithilfe eines cloudnativen Musters aus Streams und Tasks neu implementiert werden, wobei ein Stream Tabellenänderungen erfasst und eine geplante Task diese Änderungen verarbeitet, um die Geschäftslogik anzuwenden.
Phase 4: Datenmigration¶
Diese Phase konzentriert sich auf die erste, einmalige Massenübertragung von historischen Daten aus der Quelle SQL Serversystem für die Snowflake-Zielumgebung. Die grundlegende Architektur zum Laden von Daten in Snowflake ist ein „Drei-Felder“-Modell: Quelle -> Stagingbereich -> Ziel. Die Daten werden nicht direkt von der Quelle zum Ziel verschoben, sondern zunächst in einem Zwischenspeicherort von Cloudobjekten (dem Stagingbereich) gespeichert.
Wichtige Aktivitäten:
Datenextraktion aus SQL Server: Für die anfängliche Migration historischer Daten ist das native Befehlszeilenprogramm Bulk Copy Program (BCP) von SQL Server eine sehr effiziente Option. Es kann große Tabellen mit hoher Geschwindigkeit in Flatfiles exportieren (z. B. CSV). Diese Dateien können dann in den Cloud-Stagingbereich (z. B. Amazon S3, Azure Blob Storage) hochgeladen werden.
Laden von Daten aus dem Stagingbereich in Snowflake: Sobald Datendateien im Cloud-Stagingbereich vorhanden sind, ist der primäre Mechanismus für die Aufnahme der Befehl -
COPY INTO <table>. Dies ist der zentrale SQL-Befehl für leistungsstarkes Laden großer Datenmengen. Er ist so konzipiert, dass er massiv parallel funktioniert. Für eine optimale Performance ist es eine bewährte Praxis, große Datensets in mehrere Dateien einer mittleren Größe (100-250MB ist eine allgemeine Empfehlung) aufzuteilen, um diese Parallelität zu maximieren.
Phase 5: Datenaufnahme¶
Nach der Migration der historischen Daten konzentriert sich diese Phase auf die Migration der laufenden Datenaufnahmeprozesse, um inkrementelle Live-Daten aus verschiedenen Quellen in Snowflake zu übertragen. Dies beinhaltet in der Regel die Migration der Logik von älteren ETL-Tools wie SSIS und die Planung von SQL Server Agent.
Wichtige Aktivitäten:
Inkrementelle Datenreplikation: Für die Replikation fortlaufender Änderungen nach dem initialen Ladevorgang ist die native Change Data Capture (CDC)-Funktion von SQL Server die bevorzugte Methode. CDC liest das Transaktionslog der Datenbank aus, um alle
INSERT,UPDATEundDELETE-Operationen bei deren Auftreten zu erfassen und so einen ressourcenschonenden, nahezu Echtzeit-Datenstrom bereitzustellen.Kontinuierliche Datenaufnahme mit Snowpipe: Snowpipe ist der kontinuierliche Datenerfassungsservice von Snowflake, der für Streaming- und Microbatch-Anwendungsfälle entwickelt wurde. Sie erstellen ein
PIPE-Objekt, das einen Stagingbereich „abonniert“. Wenn neue Änderungsdateien, die durch einen CDC-Prozess erzeugt wurden, in der Stage ankommen, wird Snowpipe automatisch ausgelöst, um die Daten zu laden.Änderungen mit MERGE anwenden: Nachdem die Änderungsdaten über Snowpipe in eine temporäre Staging-Tabelle in Snowflake geladen wurden, wird der
MERGE-Befehl verwendet, um diese Änderungen auf die endgültige Produktionstabelle anzuwenden. Er kann Inserts, Updates und Deletes in einer einzigen atomaren Anweisung verarbeiten.SSIS und SQL Server Agent Jobs:
SSIS-Migration: Einfaches Verweisen auf ein bestehendes SSIS-Paket bei Snowflake ist keine tragfähige Strategie. Der empfohlene Ansatz besteht darin, die SSIS-Logik mithilfe cloudnativer Tools neu zu gestalten und dabei das ELT-Muster (Extract, Load, Transform) zu übernehmen. Dies beinhaltet die Außerbetriebnahme von SSIS und den Wiederaufbau der Geschäftslogik mithilfe von Tools wie dbt (Data Build Tool) für In-Warehouse-Transformationen, wobei die Orchestrierung durch ein Tool wie Apache Airflow gesteuert wird.
SQL Server Agent-Migration: Die Planungsfunktionen des SQL Server Agent müssen migriert werden. Einfache, nicht abhängige Jobs können mithilfe der nativen Snowflake-Aufgaben geplant werden. Komplexe Workflows mit Abhängigkeiten erfordern einen leistungsfähigeren externen Orchestrator wie Apache Airflow oder Azure Data Factory.
Phase 6: Berichterstattung und Analyse¶
Eine Data Warehouse-Migration ist erst dann wirklich abgeschlossen, wenn die Endbenutzer die neue Plattform mit ihren bevorzugten Analysetools erfolgreich nutzen. Diese „letzte Metrik“ des Projekts wird oft unterschätzt und erfordert eine sorgfältige Planung, um die Akzeptanz der Benutzer, die Performance und die Kosten zu verwalten.
Wichtige Aktivitäten:
BI-Tools (Tableau, Power BI) verbinden: Sowohl Tableau als auch Power BI sind erstklassige Mitglieder im Snowflake-Ökosystem und bieten native, leistungsstarke Konnektoren. Für beide Tools muss für jedes Dashboard eine wichtige Entscheidung getroffen werden – zwischen einer Live-Verbindung (z. B. Tableau Live, Power BI DirectQuery) und einem importierten bzw. extrahierten Modell.
Live/DirectQuery: Stellt Echtzeitdaten bereit, sendet aber bei jeder Benutzerinteraktion-Abfragen direkt an Snowflake, was zu erheblichen Rechenkosten führen kann.
Extrahieren/Importieren: Bietet eine hervorragende Performance, indem Abfragen mit einer speicherinternen Kopie der Daten bereitgestellt werden. Die Daten sind jedoch nur so aktuell wie die letzte Aktualisierung.
Die SSRS-Herausforderung und Ersetzung: Verbinden mit SQL Server Reporting Services (SSRS) für Snowflake ist bekanntermaßen eine Herausforderung und keine empfohlene langfristige Strategie. Die Migration zu Snowflake sollte als Katalog für einen Strategieplan zur Stilllegung von SSRS dienen. Kritische SSRS-Berichte sollten bewertet und in einer modernen, cloudnativen BI-Plattform wie Power BI oder Tableau neu aufgebaut werden.
**Workload-Isolierung: Um die Leistungs- und Kostenwirkung dieser BI-Tools zu steuern, ist es Best Practice, in Snowflake dedizierte, passend dimensionierte virtuelle Warehouses speziell für BI-Workloads einzurichten. Dies isoliert BI-Abfragen von anderen Workloads wie ETL.
Phase 7: Datenvalidierung und Testen¶
In dieser Phase wird die neu aufgebaute Snowflake-Plattform gründlich getestet und mit dem Altsystem verglichen, um das Vertrauen des Unternehmens zu stärken und eine erfolgreiche Inbetriebnahme sicherzustellen. Die Datenvalidierung darf nicht nachträglich sein und muss weit über das Zählen von Zeilen hinausgehen.
Wichtige Aktivitäten:
Eine mehrstufige Datenvalidierungsstrategie:
Level 1: Datei- und Objektvalidierung: Verwenden Sie Prüfsummen oder Hashfunktionen, um sicherzustellen, dass die vom Quellsystem in die Cloud-Stage übertragenen Datendateien während der Übertragung nicht beschädigt wurden.
Level 2: Abgleich und Aggregatvalidierung: Führen Sie Abfragen sowohl auf der SQL Server-Quelldatenbank als auch auf den Snowflake-Zieltabellen aus, um Metriken wie Zeilenanzahlen und Aggregatfunktionen (
SUM,AVG,MIN,MAX) für alle wichtigen numerischen Spalten zu vergleichen.Level 3: Validierung auf Zellenebene (Data Diff): Für die geschäftskritischsten Tabellen ist ein detaillierter, zellweiser Vergleich einer statistisch signifikanten Stichprobe von Zeilen erforderlich, um subtile Fehler bei der Datentypkonvertierung oder in der Transformationslogik zu erkennen.
Performance-Tests und Benutzerakzeptanztests (UAT):
Performance-Tests: Die migrierten ETL-/ELT-Pipelines und BI-Berichte müssen anhand der in der Planungsphase definierten SLAs getestet werden.
Benutzerakzeptanztests (UAT): Hier machen sich die Benutzer mit dem neuen System vertraut. Sie müssen die Zeit und Ressourcen erhalten, um ihre Berichte auszuführen, ihre Abfragen zu testen und zu bestätigen, dass das migrierte System ihre funktionalen Anforderungen erfüllt und die gleichen Ergebnisse liefert wie das Altsystem. Die Benutzerakzeptanzprüfung (UAT) ist die letzte Hürde vor dem Übergang in den Produktivbetrieb.
Phase 8: Bereitstellung¶
Diese Phase ist der Höhepunkt aller vorherigen Arbeiten: Das validierte System wird in den Produktivbetrieb überführt, und der formale Wechsel – die Umstellung vom alten SQL-Server-System zu Snowflake findet statt. Die Strategie sollte gewählt werden, um Risiken und Geschäftsunterbrechungen zu minimieren.
Wichtige Aktivitäten:
Übergangsplan erstellen: Anstatt alles auf einmal umzustellen, empfiehlt sich ein schrittweises Vorgehen, um das Risiko möglicher Probleme zu begrenzen und die Auswirkungen überschaubar zu halten.
Phasenweise Einführung (empfohlen): Sie migrieren Anwendungen, Berichte oder Geschäftsbereiche nacheinander über einen bestimmten Zeitraum.
Parallele Ausführung: Führen Sie für eine gewisse Zeit sowohl das alte SQL Server-System als auch das neue Snowflake-System parallel aus, speisen Sie Daten in beide Systeme ein und vergleichen Sie die Ergebnisse, um vollständige Übereinstimmung sicherzustellen, bevor das Altsystem außer Betrieb genommen wird.
Überbrückungsstrategie: Während einer schrittweisen Einführung oder einer Parallelphase ist es entscheidend, eine Überbrückungsstrategie umzusetzen, damit die Benutzer nicht auf zwei verschiedene Systeme zugreifen müssen. Ziel ist es, dem Unternehmen eine einzige, einheitliche Ansicht zu präsentieren.
Finale Checkliste für die Bereitstellung und Genehmigung: Vor der endgültigen Umstellung sollte das Team eine letzte Überprüfung der Bereitschaft durchführen. Dazu gehört die Überprüfung aller Berechtigungen und Rollen, die Sicherstellung, dass alle Service-Konten vorhanden sind, und die Bestätigung, dass Überwachung und Alarme aktiv sind. Holen Sie sich eine formelle, schriftliche Genehmigung von allen wichtigen geschäftlichen und technischen Interessensvertretern, bevor Sie live gehen.
Phase 9: Optimieren und ausführen¶
Der Abschluss des Übergangs markiert zwar das Ende des Migrationsprojekts, aber gleichzeitig den Beginn des operativen Lebenszyklus der Plattform. Eine Datenplattform ist ein dynamisches System, das kontinuierliche Wartung, Governance und Optimierung erfordert. Im Snowflake-Paradigma sind Performance- und Kostenoptimierung zwei Seiten derselben Medaille: Es geht darum, die richtige Menge an Rechenleistung für die richtige Dauer einzusetzen, um ein geschäftliches SLA zu den geringstmöglichen Kosten zu erreichen.
Wichtige Aktivitäten:
Performance-Optimierung:
Virtuelle Warehouses dimensionieren und verwalten: Dies hat primären Einfluss sowohl auf die Performance als auch auf die Kosten. Überwachen und optimieren Sie die Größe der Warehouses kontinuierlich, richten Sie separate Warehouses für unterschiedliche Workloads ein (Workload-Isolierung) und stellen Sie sicher, dass alle Warehouses über eine strikte Auto-Suspend-Richtlinie verfügen.
Abfrageoptimierung: Verwenden Sie das Query Profile-Tool von Snowflake, um langsam ausgeführte Abfragen visuell zu analysieren und zu debuggen.
Gruppierungsschlüssel: Bei sehr großen Tabellen (typischerweise über 1 Terabyte) kann das Definieren eines Gruppierungsschlüssels die Abfrageleistung erheblich verbessern, indem zusammengehörige Daten physisch zusammengelegt werden.
Langfristige FinOps implementieren:
Kontinuierliche Überwachung: Überprüfen Sie regelmäßig die Kosten- und Nutzungsdaten des Schemas
ACCOUNT_USAGE.Showback und Chargeback: Implementieren Sie ein Modell, das die entstandenen Kosten den jeweiligen Geschäftsbereichen oder Projekten zuordnet, um Transparenz und Verantwortlichkeit zu fördern.
Objekt-Tagging: Verwenden Sie das Tagging-Feature von Snowflake, um Metadaten-Tags auf Objekte anzuwenden und so die Kostenzuweisung und Governance zu vereinfachen.
Data Governance und Datensicherheit einrichten:
RBAC verbessern: Aktualisieren Sie kontinuierlich die RBAC-Hierarchie und führen Sie regelmäßige Audits durch, um nicht genutzte Rollen oder übermäßige Berechtigungen zu entfernen.
Erweiterte Sicherheitsfeatures: Für hochsensible Daten können Sie erweiterte Data Governance-Features von Snowflake wie Dynamische Datenmaskierung und Zeilenzugriffsrichtlinien implementieren.