Guide de migration du serveur SQL vers Snowflake¶
Framework de migration Snowflake¶
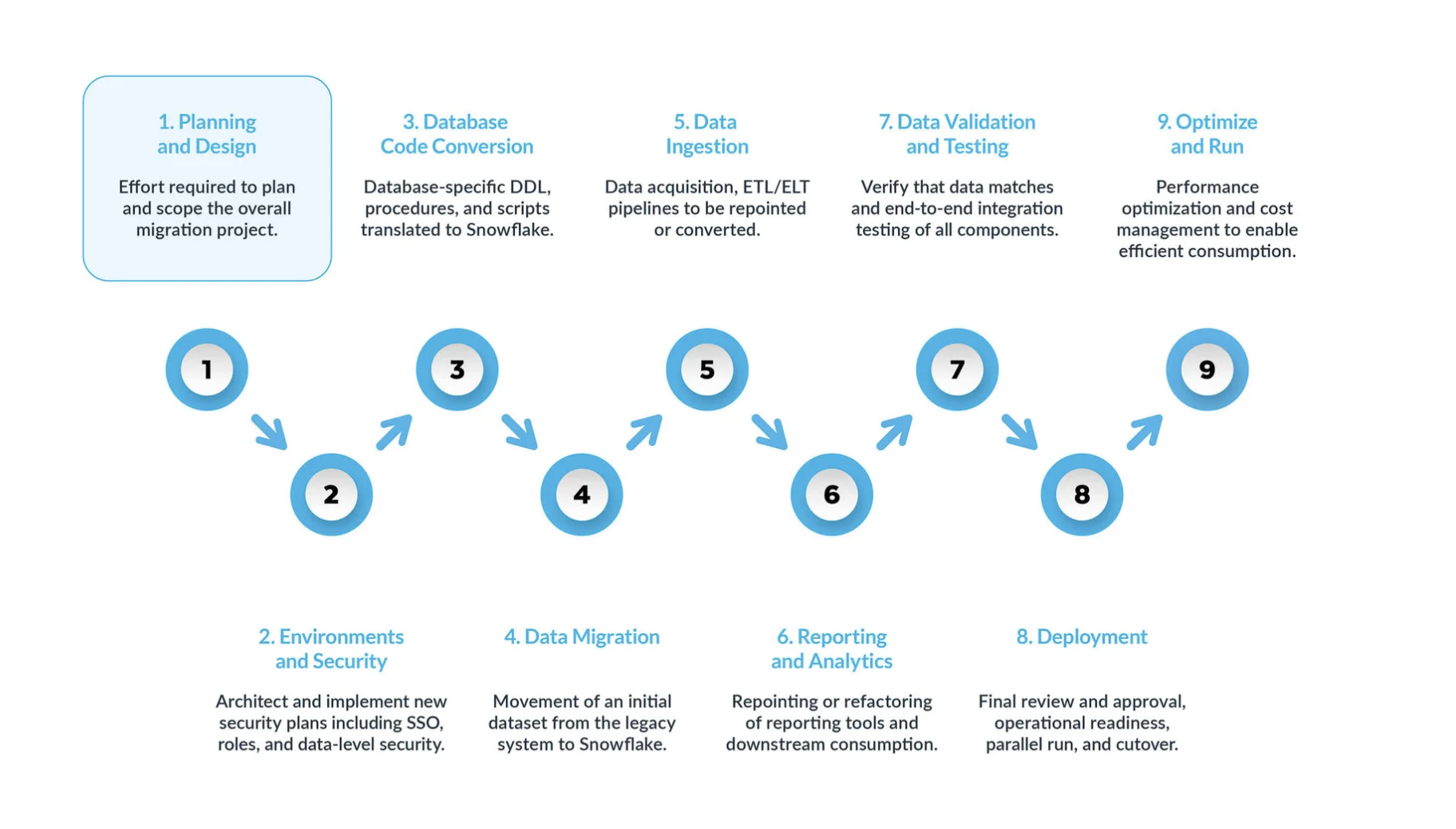
Une migration serveur SQL vers Snowflake typique peut être divisée en 9 étapes clés :
La planification et la conception sont souvent négligées dans le processus de migration. La principale raison est que les entreprises souhaitent généralement afficher rapidement la progression, même si elles n’ont pas bien compris la portée du projet. C’est pourquoi cette phase est essentielle pour comprendre et hiérarchiser le projet de migration.
Environnement et sécurité avec un plan, un calendrier clair, une matrice RACI, et l’adhésion de toutes les parties prenantes. Il est temps de passer en mode exécution. La mise en place des environnements et des mesures de sécurité nécessaires pour commencer la migration est très importante avant de démarrer la phase de migration, étant donné qu’il y a de nombreuses parties mobiles, et cela aura plus d’impact pour le projet de migration si toutes vos configurations sont prêtes avant d’aller plus loin.
Le processus de conversion du code de la base de données implique l’extraction du code directement depuis le catalogue de la base de données des systèmes sources, tels que les définitions de table, les vues, les procédures stockées et les fonctions. Une fois extrait, vous migrez l’ensemble de ce code vers des langages de définition de données équivalents (DDLs) dans Snowflake. Cette étape comprend également la migration des scripts du langage de manipulation des données (DML), qui peuvent être utilisés par les analystes commerciaux pour créer des rapports ou des tableaux de bord. Tout ce code doit être migré et ajusté pour fonctionner dans Snowflake. Les ajustements peuvent aller de changements simples, tels que les conventions de dénomination et les mappages de types de données, à des différences plus complexes dans la syntaxe, la sémantique de plateforme et d’autres facteurs. Pour y remédier, Snowflake propose une solution puissante appelée SnowConvert AI, qui automatise une grande partie du processus de conversion du code de la base de données.
Migration de données La migration de données implique le transfert de données entre différents systèmes de stockage, formats ou systèmes informatiques. Dans le contexte d’une migration de serveur SQL vers Snowflake, il s’agit spécifiquement du déplacement de données de votre environnement de serveur SQL vers votre nouvel environnement Snowflake.
Ce guide présente deux principaux types de :
Migration des données historiques : instantané des données de votre serveur SQL à un moment précis et transfert de ces données vers Snowflake. Il s’agit souvent d’un transfert initial en masse.
Migration des données incrémentielles : déplacement continu de données nouvelles ou modifiées du serveur SQL vers Snowflake après la migration historique initiale. Cela garantit que votre environnement Snowflake reste à jour avec vos systèmes sources.
Ingestion des données : après la migration des données historiques, l’étape suivante consiste à migrer le processus d’ingestion de données, en intégrant des données dynamiques provenant de diverses sources. En règle générale, ce processus suit un modèle d’extraction, transformation, chargement (ETL) ou d’extraction, changement, transformation (ELT), en fonction du moment et de l’endroit où la transformation des données se produit avant qu’elle ne soit disponible pour les utilisateurs professionnels.
Rapports et analyses : maintenant que la base de données contient à la fois des données historiques et des pipelines dynamiques qui importent continuellement de nouvelles données, l’étape suivante consiste à extraire de la valeur de ces données via BI. Les rapports peuvent être effectués à l’aide des outils BI standard ou de requêtes personnalisées. Dans les deux cas, le SQL envoyé à la base de données peut devoir être ajusté pour répondre aux exigences de Snowflake. Ces ajustements peuvent aller de simples modifications de nom (communes lors de la migration) à des différences de syntaxe et sémantiques plus complexes. Tous ces problèmes doivent être identifiés et traités.
Validation et test des données : l’objectif consiste à ce que les données soient aussi propres que possible avant d’entamer cette phase. Chaque organisation possède ses propres méthodologies de test et ses propres exigences pour passer des données en production. Celles-ci doivent être bien comprises dès le début du projet.
Déploiement : à ce stade, les données sont validées, un système équivalent est mis en place, tous les ETLs ont été migrés et les rapports ont été vérifiés. Prêt pour la mise en production ? Encore un peu de patience - il y a encore quelques considérations critiques avant la mise en production finale. Tout d’abord, votre application existante peut consister en plusieurs composants ou services. Idéalement, vous devriez migrer ces applications une par une (bien que la migration parallèle soit possible) et les passer en production dans le même ordre. Au cours de ce processus, assurez-vous que votre stratégie de « pont » est en place afin que les utilisateurs professionnels n’aient pas à interroger à la fois Snowflake et le système existant. La synchronisation des données pour les applications qui n’ont pas encore été migrées doit se faire en arrière-plan via le mécanisme de pont. Si cela n’est pas fait, les utilisateurs professionnels devront travailler dans un environnement hybride, et ils doivent comprendre les implications de cette configuration.
Optimisation et exécution une fois qu’un système a été migré vers Snowflake, il passe en mode de maintenance normale. Tous les systèmes logiciels sont des organismes vivants qui nécessitent une maintenance continue. Cette phase, après la migration, est appelée optimisation et exécution, et elle ne fait pas partie de la migration elle-même.
** Phases clés **¶
Une migration réussie du serveur SQL vers Snowflake est un projet de modernisation qui se déroule sur une séquence de phases bien définies. Le suivi de cette approche structurée en neuf phases garantit une transition complète et méthodique, en abordant l’ensemble des points, de la stratégie initiale à l’exigence opérationnelle à long terme.
Phase 1 : Planification et conception¶
Cette phase initiale est la plus essentielle pour la réussite de l’ensemble du projet de migration, car elle pose les bases d’une définition précise, de calendriers réalistes et de l’alignement des parties prenantes. Une phase de planification accélérée ou incomplète est la principale cause de dépassement de budget, de dépassement de délais et d’échec des projets. L’objectif n’est pas simplement de cataloguer le système existant, mais de décider stratégiquement quelles ressources sont suffisamment précieuses pour passer à la nouvelle plateforme. Une approche entièrement « Lift and Shift » est une recette pour migrer des années de dette technique accumulée et augmenter les coûts du Cloud dès le premier jour.
Activités clés :
Exécution d’un inventaire complet : la première étape consiste à créer un manifeste détaillé et exhaustif de chaque actif dans le champ d’application de la migration. Cet inventaire doit être créé à l’aide d’une combinaison d’outils de découverte automatisés, de requêtes dans le catalogue système et d’entretiens avec les propriétaires d’applications. L’inventaire doit comprendre :
Objets de la base de données : l’ensemble des bases de données, schémas, tables et vues. Pour les tables, le nombre de lignes de document et la taille des données brutes.
Code procédural : toutes les procédures stockées, les fonctions définies par l’utilisateur (UDFs), les déclencheurs et toute logique à l’aide de curseurs.
Automatisation et ETL: toutes les tâches d’agent de serveur SQL, leurs planifications et leurs dépendances. Un catalogue complet de services d’intégration de serveur SQL (SSIS) est particulièrement important.
Consommateurs en aval : toutes les applications et outils de BI qui se connectent à la base de données, tels que les rapports SSRS, les tableaux de bord Power BI et les notebooks Tableau.
Principaux de sécurité : tous les utilisateurs, rôles et autorisations granulaires.
Exclusion des bases de données système : Tenter de migrer les bases de données du système interne du serveur SQL est une erreur critique (
master,msdb,tempdb,model). Celles-ci font partie intégrante d’une instance de serveur SQL, mais n’ont pas de fonction ou d’équivalent dans Snowflake, et doivent être explicitement exclues de tous les plans de migration.
Définition des objectifs, de la portée et des métriques de réussite de la migration : avec un inventaire complet, l’équipe peut définir des objectifs clairs et mesurables liés aux résultats commerciaux. Les exemples incluent :
Objectif : améliorer les performances des rapports financiers de fin de mois.
Métrique : réduire la durée d’exécution de la suite de rapport « MonthEnd_Consolidation » de 50 %.
Objectif : réduire le coût total de possession (TCO) de l’entrepôt de données.
Métrique : diminuer le TCO annuel de 30 % par rapport aux coûts de l’année précédente.
Alignement des parties prenantes et assemblage de l’équipe de migration (RACI) : la migration de plateforme de données est une transformation commerciale. Un engagement précoce et continu de toutes les parties prenantes est essentiel. L’équipe de migration doit comprendre des représentants des utilisateurs professionnels, de l’ingénierie des données, des finances, de la sécurité et des services juridiques. Une matrice RACI (Responsible, Accountable, Consulted, Informed) doit être établie pour formaliser les rôles et les responsabilités.
** Présentation de FinOps :** le passage au modèle de coûts basé sur la consommation de Snowflake doit être planifié depuis le début. L’équipe de migration doit se coordonner avec le service financier pour comprendre le modèle de tarification, établir des budgets et définir comment les coûts seront suivis et attribués, souvent en utilisant les fonctionnalités de balisage d’objets de Snowflake.
Évaluation initiale et tri : l’inventaire fournit les données nécessaires à un processus de tri critique. L’équipe doit analyser les journaux d’utilisation pour identifier les données redondantes ou obsolètes, les objets inutilisés et les données de mise en zone de préparation temporaire qui peuvent être désactivés ou archivés au lieu d’être migrés.
Phase 2 : Environnement et sécurité¶
Avec un plan stratégique en place, cette phase implique la construction de l’environnement Snowflake de base. C’est l’occasion de concevoir depuis le début une plateforme de données propre, sécurisée et gouvernable à partir des principes fondamentaux, plutôt que de reproduire à l’identique le modèle de sécurité hérité 1:1. Les environnements de serveur SQL les plus matures subissent une « dette de sécurité » comme un accès trop large et des rôles incohérents, que cette phase vise à résoudre.
Activités clés :
Architecture de votre structure de compte Snowflake : pour la plupart des entreprises, une stratégie multi-comptes est recommandée afin de garantir une isolation complète des données et des métadonnées. Ceci inclut généralement des comptes séparés pour :
Compte de production : héberge toutes les données et les charges de travail de production avec les contrôles de sécurité les plus stricts.
Compte Développement/QA : un compte distinct pour toutes les activités de développement et de test.
Compte sandbox (facultatif) : compte pour les travaux expérimentaux des scientifiques ou des analystes des données.
Implémentation d’un modèle de sécurité robuste : la sécurité doit être mise en œuvre en couches :
Politiques réseau : comme première ligne de défense, créez des politiques réseau pour restreindre l’accès au compte Snowflake à une liste blanche d’adresses IP de confiance.
Authentification : renforcer l’authentification multifactorielle (MFA) pour tous les utilisateurs. Pour une expérience utilisateur transparente et sécurisée, intégrez Snowflake à un fournisseur d’authentification unique (SSO) d’entreprise comme Azure Active Directory (Azure AD) ou Okta.
Conception d’une hiérarchie de contrôle d’accès basé sur les rôles (RBAC) : il s’agit de la base de la sécurité de Snowflake. Tous les privilèges sur les objets sont accordés exclusivement aux rôles, qui sont ensuite accordés aux utilisateurs. Une hiérarchie des meilleures pratiques implique la création de types de rôles distincts :
Rôles définis par le système :
ACCOUNTADMIN,SYSADMIN, etc., utilisés uniquement pour les tâches administratives.Rôles fonctionnels : rôles personnalisés correspondant à des fonctions métier (par exemple,
FINANCE_ADMIN,MARKETING_ANALYST).Rôles d’accès : rôles granulaires qui définissent des autorisations spécifiques (par exemple,
READ_ONLY,WRITE_ACCESS). Ces rôles sont ensuite attribués dans une hiérarchie pour simplifier l’administration.
Configuration des moniteurs de ressources et des contrôles de coûts : les moniteurs de ressources sont l’outil principal de Snowflake pour la mise en œuvre du contrôle de coûts. Ils doivent être configurés dans le cadre de la configuration initiale de l’environnement pour suivre la consommation de crédit au niveau du compte et de l’entrepôt. Pour chaque moniteur, définissez des déclencheurs de notification et de suspension (par exemple, envoyer un e-mail à 75 % du quota, suspendre l’entrepôt à 100 %) pour éviter les dépassements de budget.
Phase 3 : Conversion du code de base de données¶
Cette phase se concentre sur la traduction technique de la structure physique et de la logique procédurale de la base de données depuis le T-SQL du serveur SQL vers le SQL conforme à l’ANSI de Snowflake. Il s’agit souvent de la partie la plus complexe et la plus longue de la migration. Ce processus est un catalyseur pour la modernisation de la logique de traitement des données, imposant un changement fondamental qui s’éloigne de la logique impérative et étatique pour se diriger vers un traitement déclaratif et basé sur des ensembles.
Activités clés :
Traduction du langage de définition des données (DDL) : implique l’extraction et la conversion des instructions
CREATE TABLEetCREATE VIEW. Les outils de conversion de code automatiques commeSnowConvert AI de Snowflake sont vivement recommandés pour analyser des DDL de T-SQL et génèrent l’équivalent du SQL Snowflake, la gestion des différences de syntaxe et le mappage des types de données.Mappage des types de données : le mappage précis des types de données est fondamental. Alors que de nombreux types sont mappés directement (par exemple,
INTsurNUMBER), plusieurs différences clés requièrent une attention particulière, en particulier avec les types date/heure. LesDATETIMEetDATETIME2du serveur SQL ne sont pas sensibles au fuseau horaire et doivent être mappés surTIMESTAMP_NTZde Snowflake. À l’inverse,DATETIMEOFFSETcontient un décalage de fuseau horaire et doit être mappé surTIMESTAMP_TZpour préserver ces informations.Traitement des contraintes (appliquées ou non appliquées) : cela représente un changement conceptuel important. Sur le serveur SQL, les contraintes telles que les clés primaires et les clés étrangères sont appliquées par le moteur de base de données. Dans Snowflake, ces contraintes peuvent être définies mais ne sont pas appliquées. Elles existent uniquement en tant que métadonnées. La responsabilité du maintien de l’intégrité des données passe entièrement de la base de données au pipeline de données (ETL/processus ELT).
Conversion des procédures stockées et du T-SQL : la migration des procédures stockées du T-SQL est une entreprise importante.
Différences de dialecte SQL : de nombreuses fonctions et constructions de syntaxe T-SQL nécessitent une conversion (par exemple,
GETDATE()devientCURRENT_TIMESTAMP(),ISNULL()devientCOALESCE()).Logique de refactorisation : le chemin préféré est la réécriture des procédures T-SQL à l’aide de l’exécution de scripts Snowflake, un langage procédural basé sur SQL. L’objectif global consiste à éliminer le traitement ligne par ligne (comme les curseurs) en faveur des instructions SQL basées sur les ensembles partout où c’est possible.
Remplacement des curseurs et des déclencheurs : les curseurs constituent un anti-modèle de performance grave dans Snowflake et doivent être supprimés. Snowflake ne prend pas en charge les déclencheurs. Leurs fonctionnalités doivent être réimplémentées à l’aide d’un modèle natif Cloud de flux et de tâches, où un flux capture les modifications de table et une tâche planifiée consomme ces modifications pour appliquer une logique métier.
Phase 4 : Migration des données¶
Cette phase se concentre sur le transfert en masse initial et unique des données historiques depuis le système de serveur SQL source vers l’environnement cible de Snowflake. L’architecture fondamentale pour le chargement des données dans Snowflake est un modèle à « trois compartiments » : Source -> Zone de préparation -> cible. Les données ne sont pas déplacées directement de la source vers la cible, mais atterrissent d’abord dans un emplacement intermédiaire de stockage d’objets dans le Cloud (la zone de préparation).
Activités clés :
Extraction de données à partir du serveur SQL : pour la migration initiale des données historiques, l’utilitaire de ligne de commande native Bulk Copy Program (BCP) du serveur SQL est une option très efficace. Il peut exporter de grandes tables vers des fichiers plats (par ex., CSV) à grande vitesse. Ces fichiers peuvent ensuite être chargés vers la zone de préparation Cloud (par exemple, Amazon S3, Azure Blob Storage).
Chargement des données dans Snowflake à partir de la zone de préparation : une fois les fichiers de données présents dans la zone de préparation Cloud, le principal mécanisme d’ingestion est la commande
COPY INTO <table>. Il s’agit de la commande SQL principale pour le chargement de données en masse de haute performance. Il est conçu pour fonctionner de manière massivement parallèle. Pour des performances optimales, il est recommandé de diviser de grands ensembles de données en plusieurs fichiers de taille moyenne (100-250MB est une recommandation courante) pour optimiser ce parallélisme.
Phase 5 : ingestion des données¶
Après la migration des données historiques, cette phase se concentre sur la migration des processus d’ingestion de données en cours afin d’intégrer des données incrémentielles dynamiques de différentes sources dans Snowflake. Cela implique généralement la migration de la logique depuis les outils ETL existants comme SSIS et la planification depuis l’agent du serveur SQL.
Activités clés :
Réplication de données incrémentielle : pour répliquer les modifications en cours après le chargement initial, la fonctionnalité Capture des données de changement (CDC) native du serveur SQL est la méthode préférée. CDC fonctionne en lisant le journal des transactions de la base de données pour capturer toutes les opérations
INSERT,UPDATE, etDELETEà mesure qu’elles se produisent, fournissant un flux de changements à faible impact quasiment en temps réel.Alimentation continue à Snowpipe : Snowpipe est le service d’alimentation continue de données de Snowflake, conçu pour les cas d’utilisation en continu et en micro-lots. Vous créez un objet
PIPEqui « s’abonne » à une zone de préparation. Lorsque de nouveaux fichiers de modification générés par un processus CDC arrivent dans la zone de préparation, Snowpipe est automatiquement déclenché pour charger les données.** Application de modifications avec MERGE :** une fois que les données de modification ont été chargées dans une table de zone de préparation temporaire dans Snowflake (via Snowpipe), la commande
MERGEest utilisée pour appliquer ces modifications à la table de production finale. Elle peut gérer les insertions, les mises à jour et les suppressions dans une seule instruction atomique.Modernisation des tâches SSIS et de l’agent du serveur SQL :
Migration de SSIS : pointer simplement un package SSIS existant sur Snowflake n’est pas une stratégie valide. L’approche recommandée consiste à réarchitecturer la logique SSIS avec des outils Cloud natifs, en intégrant le modèle ELT (Extraire, Charger, Transformer). Cela implique la désactivation de SSIS et la reconstruction de la logique métier à l’aide d’outils tels que dbt (outil de construction de données) pour les transformations en entrepôt, avec une orchestration gérée par un outil tel que Apache Airflow.
Migration de l’agent du serveur SQL : la fonctionnalité de planification de l’agent du serveur SQL doit être migrée. Les tâches simples et non dépendantes peuvent être planifiées à l’aide de tâches Snowflake natives. Les workflows complexes avec des dépendances nécessitent un orchestrateur externe plus puissant comme Apache Airflow ou Azure Data Factory.
Phase 6 : Rapports et analyses¶
La migration d’un entrepôt de données n’est pas vraiment terminée tant que les utilisateurs finaux n’utilisent pas correctement la nouvelle plateforme via leurs outils d’analyse préféré. Ce « dernier kilomètre » du projet est souvent sous-estimé et nécessite une planification pointue pour gérer l’acceptation des utilisateurs, les performances et les coûts.
Activités clés :
Connexion des outils de BI (Tableau, Power BI) : Tableau et Power BI sont des éléments incontournables de l’écosystème Snowflake et fournissent des connecteurs natifs et hautes performances. Pour les deux outils, une décision critique doit être prise sur la base du tableau de bord entre une connexion en direct (par exemple, Tableau Live, Power BI DirectQuery) et un modèle importé/extrait.
Live/DirectQuery : fournit des données en temps réel, mais envoie des requêtes directement à Snowflake pour chaque interaction utilisateur, ce qui peut entraîner des coûts de calcul importants.
Extraction/Importation : offre d’excellentes performances en servant des requêtes à partir d’une copie en mémoire des données, mais les données ne seront pas plus récentes que la dernière actualisation.
Difficultés et remplacement du SSRS : connecter les services de rapports du serveur SQL (SSRS) à Snowflake est très difficile et n’est pas une stratégie à long terme recommandée. La migration vers Snowflake doit servir de déclencheur à un plan stratégique de désactivation du SSRS. Les rapports SSRS critiques doivent être évalués et reconstruits sur une plateforme BI Cloud moderne native comme Power BI ou Tableau.
** Isolation de la charge de travail : ** pour gérer les performances et l’impact des coûts de ces outils de BI, il est recommandé de créer des entrepôts virtuels dédiés et de taille appropriée dans Snowflake spécifiquement pour les charges de travail BI. Cela isole les requêtes BI des autres charges de travail telles que ETL.
Phase 7 : validation et test des données¶
Cette phase est l’endroit où la nouvelle plateforme Snowflake est rigoureusement testée et validée par rapport au système existant pour établir la confiance des entreprises et garantir un déploiement réussi. La validation des données ne peut pas être une réflexion après coup et doit aller bien au-delà du simple comptage des lignes.
Activités clés :
Une stratégie de validation des données à plusieurs niveaux :
Niveau 1 : Validation des fichiers et des objets : utilisez des sommes de contrôle ou des fonctions de hachage pour vérifier que les fichiers de données transférés du système source vers la zone de préparation Cloud n’ont pas été corrompus pendant le transit.
Niveau 2 : Rapprochement et validation de l’agrégation : exécutez des requêtes sur la base de données du serveur SQL source et sur les tables cibles Snowflake pour comparer les métriques clés telles que le nombre de lignes et les fonctions d’agrégation (
SUM,AVG,MIN,MAX) pour toutes les principales colonnes numériques.Niveau 3 : Validation au niveau de la cellule (différence de données) : pour les tables les plus critiques, une comparaison plus granulaire, cellule par cellule, d’un échantillon de lignes statistiquement significatif est nécessaire pour détecter les erreurs subtiles de conversion de type de données ou les bugs de logique de transformation.
Tests de performance et d’acceptation par l’utilisateur (UAT) :
Tests de performance : les ETL/pipelines ELT et rapports BI migrés doivent être testés par rapport aux SLAs de performances définis dans la phase de planification.
Test d’acceptation par l’utilisateur (UAT) : c’est ici que les utilisateurs professionnels se familiarisent avec le nouveau système. Ils doivent disposer du temps et des ressources nécessaires pour exécuter leurs rapports, exécuter leurs requêtes et confirmer que le système migré répond à leurs exigences fonctionnelles et produit les mêmes résultats que le système hérité. L’UAT est la dernière étape avant le déploiement en production.
Phase 8 : Déploiement¶
Cette phase est le point final de tous les efforts précédents, où le système validé passe en production et où le changement officiel, ou migration du système de serveur SQL existant vers Snowflake est effectué. La stratégie doit être choisie pour réduire les risques et les interruptions de l’activité.
Activités clés :
Développement d’un plan de migration : au lieu d’une simple migration complète ( ou « big bang »), une approche par étapes est recommandée pour limiter les conséquences de tout problème potentiel.
Déploiement échelonné (recommandé) : migrez les applications, les rapports ou les unités commerciales une par une sur une période donnée.
Exécution en parallèle : pendant une période déterminée, exécutez à la fois le serveur SQL hérité et les nouveaux systèmes Snowflake en parallèle, en alimentant les deux en données et en comparant les sorties pour assurer une cohérence totale avant la désactivation du système existant.
Stratégie de transition : lors d’un déploiement par étapes ou d’une exécution parallèle, il est essentiel de mettre en œuvre une stratégie de transition afin que les utilisateurs n’aient pas à interroger deux systèmes différents. L’objectif consiste à présenter une vue unique et unifiée de l’entreprise.
Liste de contrôle du déploiement final et signature des parties prenantes : avant la migration finale, l’équipe doit procéder à un dernier examen de vérification. Il s’agit notamment de vérifier toutes les autorisations et tous les rôles, de s’assurer que tous les comptes de service sont en place et de confirmer que la surveillance et les alertes sont actives. Obtenez le consentement écrit et signé de la part de toutes les principales parties prenantes commerciales et techniques avant la mise en service.
Phase 9 : Optimisation et exécution¶
La fin du projet de migration marque le début de la vie opérationnelle de la plateforme. Une plateforme de données est un système existant qui nécessite une maintenance, une gouvernance et une optimisation continues. Dans le paradigme Snowflake, le réglage des performances et l’optimisation des coûts sont les deux faces d’une même médaille : appliquer la bonne quantité de calcul, pendant la bonne durée, pour répondre au SLA de l’entreprise au coût le plus bas possible.
Activités clés :
Réglage des performances :
Dimensionnement et gestion de l’entrepôt virtuel : Il s’agit là du principal levier tant pour la performance que pour les coûts. Surveillez et ajustez la taille des entrepôts en permanence, créez des entrepôts distincts pour différentes charges de travail (isolation des charges de travail) et assurez-vous que tous les entrepôts disposent d’une politique de suspension automatique agressive.
Optimisation des requêtes : utilisez l’outil ** Profil de requête** de Snowflake pour analyser et déboguer visuellement les requêtes qui s’exécutent lentement.
Clés de clustering : pour les très grandes tables (généralement plus de 1 téraoctet), la définition d’une clé de clustering peut améliorer considérablement les performances des requêtes en co-localisant physiquement les données associées.
Mise en œuvre du FinOps à long terme :
Surveillance continue : examinez régulièrement les données de coût et d’utilisation du schéma
ACCOUNT_USAGE.Showback (récupération des données de facturation) et chargeback (rétrofacturation) : mettez en place un modèle permettant d’imputer les coûts aux unités opérationnelles ou aux projets qui les engagent afin de renforcer la responsabilité.
Balisage d’objets : utilisez la fonctionnalité de balisage de Snowflake pour appliquer des balises de métadonnées aux objets afin de simplifier l’allocation des coûts et la gouvernance.
Établissement de la gouvernance et de la sécurité des données :
Réglage de la RBAC : mettez à jour en continu la hiérarchie RBAC et effectuez des audits réguliers pour supprimer les rôles inutilisés ou les autorisations excessives.
Fonctionnalités de sécurité avancées : pour les données hautement sensibles, implémentez les fonctionnalités de gouvernance des données avancées de Snowflake comme le masquage dynamique des données et les politiques d’accès aux lignes.