Análise de dados de séries temporais¶
Você pode analisar dados de séries temporais no Snowflake, usando uma funcionalidade projetada especificamente para essa finalidade. Administradores de banco de dados, cientistas de dados e desenvolvedores de aplicativos precisam garantir que as séries temporais sejam armazenadas e carregadas de forma eficiente e, em muitos casos, resumidas em um formato completo e consistente, antes de disponibilizar os dados para analistas de negócios e outros consumidores.
Introdução aos dados de séries temporais¶
Uma série temporal consiste em observações sequenciais que capturam como sistemas, processos e comportamentos mudam ao longo de um período. Dados de séries temporais são coletados de uma ampla gama de dispositivos em uma ampla gama de setores. Exemplos comuns incluem dados de negociação de ações coletados para aplicações financeiras, observações meteorológicas, leituras de temperatura coletadas de sensores em fábricas inteligentes e logs de cliques de usuários em publicidade digital.
Um único registro em uma série temporal normalmente tem os seguintes componentes:
Uma data, hora ou carimbo de data/hora que tenha um nível consistente de granularidade (milissegundos, segundos, minutos, horas etc.).
Uma ou mais medições ou métricas de algum tipo, geralmente numéricas (fatos que podem revelar tendências ou anomalias nos dados).
Dimensões de interesse associadas à medição, como um local para uma leitura de temperatura ou um símbolo de ação para uma determinada negociação.
Por exemplo, a seguinte observação meteorológica tem carimbos de data/hora de início e término, uma medição de precipitação (0.32) e informações de localização:
Os seguintes dados coletados de um dispositivo de fábrica têm um namespace (IOT), uma ID de tag ou ID de sensor (3000), um carimbo de data/hora para a leitura da temperatura no dispositivo, a própria leitura da temperatura (21.1673) e um “carimbo de data/hora do corretor”, que é quando os dados chegaram posteriormente ao corretor de dados. Por exemplo, o corretor de dados pode ser um servidor Kafka que ingere dados em uma tabela Snowflake.
Uma série temporal pode revelar picos quando as leituras mudam drasticamente por algum motivo. Por exemplo, a imagem a seguir mostra uma sequência de leituras de temperatura feitas em intervalos de 15 segundos, com valores atingindo o pico acima de 40 °C após permanecerem estáveis na faixa de 35 °C no dia anterior.
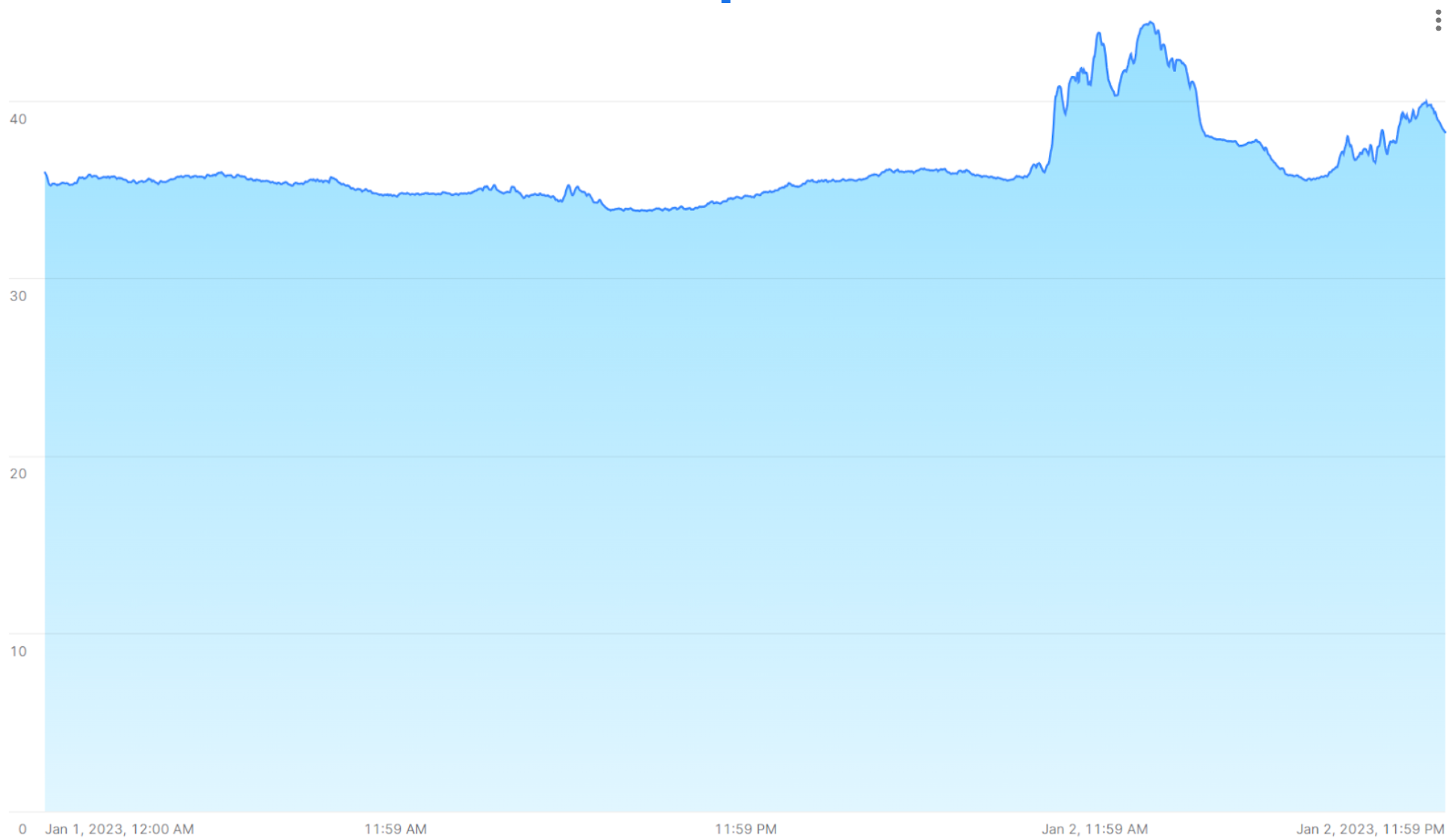
As seções a seguir mostram como analisar e visualizar grandes volumes desse tipo de dados com funções SQL e junções que fornecem resultados rápidos e precisos.
Como armazenar dados de séries temporais¶
Os seguintes tipos de dados datetime têm suporte:
DATE
TIME
TIMESTAMP (e variações, incluindo TIMESTAMP_TZ)
Para obter mais informações sobre como carregar, gerenciar e consultar dados que usam esses tipos de dados, consulte Como trabalhar com valores de data e hora.
Uma série de funções SQL comumente usadas estão disponíveis para ajudar tanto no armazenamento quanto na consulta de dados de séries temporais. Por exemplo, você pode usar CONVERT_TIMEZONE para converter carimbos de data/hora de um fuso horário para outro, e você pode usar funções como EXTRACT e TIMEADD para manipular dados baseados em tempo conforme necessário.
Nota
Para dados TIMESTAMP_TZ, o Snowflake armazena o deslocamento de um determinado fuso horário, e não o fuso horário real, no momento da criação de um valor específico.
Para otimizar o desempenho da consulta, as tabelas usadas para análises de séries temporais geralmente são clusterizadas por tempo (e às vezes também por ID de sensor ou uma dimensão similar). Consulte Chaves de clustering e tabelas clusterizadas.
Agregação de dados de séries temporais¶
O gerenciamento de dados de séries temporais pode exigir a agregação de grandes volumes de registros detalhados em um formato mais resumido (um processo às vezes chamado de “redução de amostragem”). Dado um grande conjunto de registros com uma granularidade específica baseada em tempo (milissegundos, segundos, minutos etc.), você pode agrupar esses registros para uma granularidade menos precisa, produzindo efetivamente uma amostra menor.
A redução de amostragem é valiosa porque diminui o tamanho de um conjunto de dados e seus requisitos de armazenamento. Um nível menos preciso de granularidade também reduz os requisitos de recursos de computação durante a execução da consulta. Outro motivo importante para a redução de amostragem é que um grande número de registros em uma série temporal pode ser redundante do ponto de vista de um analista. Por exemplo, se um sensor emite um novo valor uma vez a cada segundo, mas essa medição raramente muda dentro de intervalos de 60 segundos, os dados podem ser acumulados até o nível de minuto para análise.
Outro caso de redução de amostragem ocorre quando dois conjuntos de dados diferentes precisam ser analisados como um, mas eles têm granularidades de tempo diferentes. Por exemplo, o sensor A em uma fábrica coleta dados a cada 15 segundos, mas o sensor B coleta dados relacionados a cada 30 segundos. Nesse caso, agregar os registros em intervalos de 1 minuto pode ser uma boa solução. Os IDs e as dimensões em cada conjunto de dados são mantidos como estão, mas as medições numéricas são somadas ou calculadas em média por um intervalo de tempo comum.
Exemplos de redução de amostragem¶
Você pode reduzir a amostragem de um conjunto de dados armazenado em uma tabela usando a função TIME_SLICE. Essa função calcula os horários de início e término de “buckets” de largura fixa para que registros individuais possam ser agrupados e resumidos, usando funções de agregação padrão, como SUM e AVG.
Da mesma forma, a função DATE_TRUNC trunca parte de uma série de valores de data ou carimbo de data/hora, reduzindo sua granularidade. As seções a seguir mostram exemplos de cada função.
Redução de amostragem com TIME_SLICE¶
O exemplo a seguir reduz a amostragem de uma tabela nomeada sensor_data_ts, que contém leituras de dois sensores de fábrica e contém 5,3 milhões de linhas. Essas leituras foram ingeridas por segundo, então 5,3 milhões de linhas representam apenas um mês de dados, com pouco mais de 2,5 milhões de linhas por sensor. Você pode usar a função TIME_SLICE para agregar até uma única linha por minuto, por hora ou por dia, por exemplo.
Para executar este exemplo, primeiro crie e carregue a tabela sensor_data_ts; consulte Criação da tabela sensor_data_ts. Aqui está uma pequena amostra dos dados na tabela:
A tabela contém 60 leituras como essas por minuto para cada dispositivo, conforme mostrado por esta consulta:
Nessa consulta de redução de amostragem, a função TIME_SLICE define intervalos de um minuto e retorna o horário de início de cada intervalo. A função AVG calcula a temperatura média para cada bucket por dispositivo. A função COUNT (*) é incluída para referência, apenas para mostrar quantas linhas caem em cada intervalo de tempo.
As colunas vibration e motor_rpm não estão inclusas, mas podem ser agregadas da mesma forma que a coluna temperature ou usando diferentes funções de agregação.
Importante
Se você executar este exemplo sozinho, sua saída não corresponderá exatamente porque a tabela sensor_data_ts é carregada com valores gerados aleatoriamente.
Ao usar a função TIME_SLICE, você pode criar tabelas menores e agregadas para fins de análise e pode aplicar o processo de redução de amostragem em diferentes níveis (hora, dia, semana e assim por diante).
Redução de amostragem com DATE_TRUNC¶
O exemplo a seguir seleciona dados de uma tabela nomeada order_header no esquema raw.pos do Banco de dados de amostra Tasty Bytes. Esta tabela contém 248 milhões de linhas.
A tabela order_header tem uma coluna TIMESTAMP nomeada order_ts. A consulta cria uma série temporal agregada usando esta coluna como o segundo argumento para a função DATE_TRUNC. O primeiro argumento especifica um intervalo de day. Isso significa que os registros individuais, que têm uma granularidade de horas/minutos/segundos, são agrupados por dia.
A consulta agrupa os registros por duas dimensões: truck_id e location_id. A coluna avg_amount retorna o preço médio por pedido, por food truck e por local para cada dia útil registrado.
A consulta mostrada aqui limita os resultados às primeiras 25 linhas de 1º de janeiro de 2022. Se você remover este filtro de data e a cláusula LIMIT, a consulta reduz a amostragem das 248 milhões de linhas originais para cerca de 500 mil linhas.
Usar agregações em janela para cálculos contínuos¶
Ao usar funções de agregação em janela para observar como uma métrica muda ao longo do tempo, você pode analisar uma série temporal em busca de tendências. Agregações em janelas são úteis para analisar dados dentro de subconjuntos definidos (“janelas”) de um conjunto de dados maior. Você pode fazer cálculos contínuos (como médias e somas móveis) para cada linha em um conjunto de dados, levando em consideração um grupo de linhas antes, depois ou ao redor da linha atual. Esse tipo de análise contrasta com agregações regulares, que resumem todo o conjunto de dados.
Ao usar quadros de janela baseados em intervalo com offsets explícitos, você pode aplicar uma abordagem muito flexível ao cálculo dessas agregações contínuas. O quadro de janela RANGE BETWEEN, ordenado por carimbos de data/hora ou números, não é interrompido por lacunas que podem ocorrer em dados de séries temporais. Por exemplo, na ilustração a seguir, o fato de faltarem dados do Day 4 na série de registros não afeta o cálculo de funções agregadas em uma janela móvel de três dias. Em particular, os quadros 3, 4 e 5 são calculados corretamente, levando em conta que os dados do Day 4 são desconhecidos.
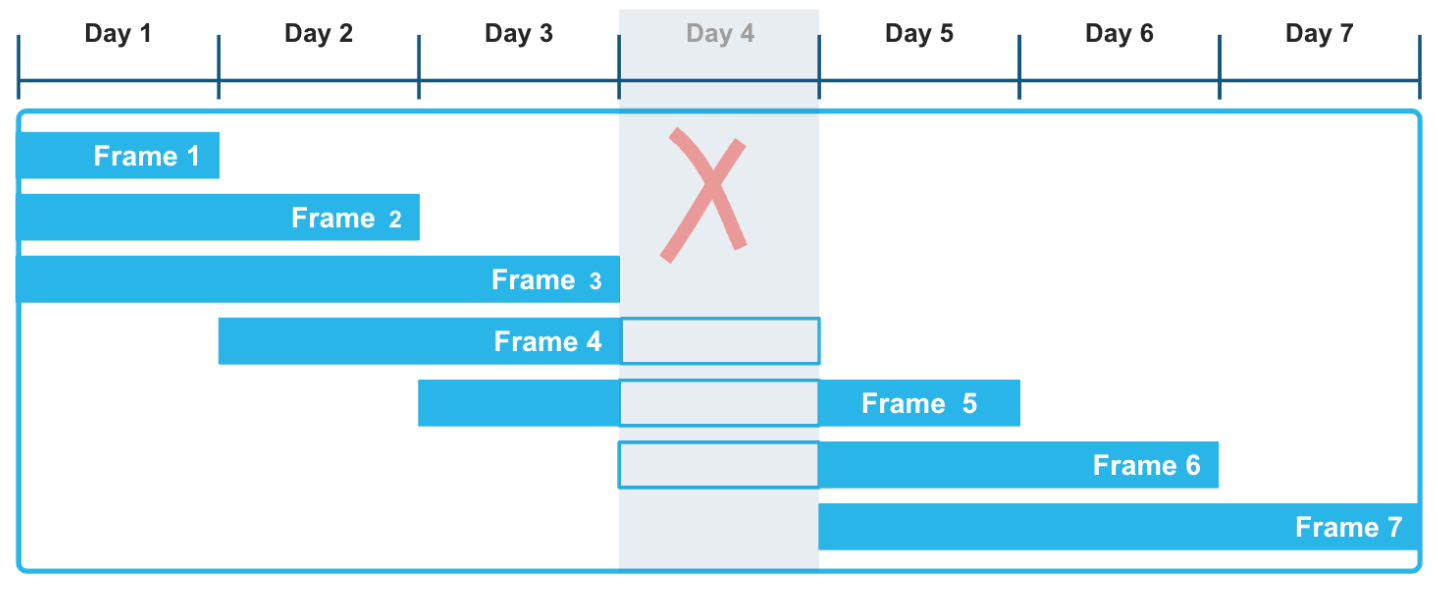
O exemplo a seguir calcula uma soma móvel sobre dados meteorológicos que registram leituras de precipitação por hora em diferentes cidades e municípios. Você pode executar esse tipo de consulta para avaliar tendências em vários conjuntos de dados de séries temporais, como sensores e outros dispositivos IoT, especialmente quando esses conjuntos de dados são previstos ou conhecidos por ter lacunas.
A função de janela inclui em seu quadro a leitura atual de precipitação e todas as leituras que ocorrem dentro do intervalo de tempo especificado antes da leitura atual. O cálculo contínuo é baseado nesse intervalo flexível e lógico de linhas, em vez de um número exato de linhas. A primeira linha para cada cidade tem valores precip e moving_sum_precip correspondentes. Depois disso, a soma é recalculada para cada linha subsequente no quadro. Os valores brutos flutuam significativamente, mas as somas móveis têm um forte efeito de suavização.
Para executar esse exemplo, siga estas instruções primeiro: Criação e carregamento da tabela heavy_weather. Essa tabela muito pequena contém observações meteorológicas esporádicas de hora em hora, com muitas lacunas, incluindo um dia ausente. A consulta retorna a soma móvel dos valores de precipitação ordenados pela coluna start_time. O quadro de janela define um intervalo entre 12 horas antes da linha atual e a linha atual. Portanto, o quadro consiste na linha atual mais apenas aquelas linhas que têm registros de data e hora até 12 horas antes do carimbo de data/hora ORDER BY da linha atual.
Os três valores moving_sum_precip para Big Bear City são calculados da seguinte forma:
0,42 = 0,42 (sem linhas anteriores)
0,42 + 0,09 = 0,51 (as duas primeiras linhas estão dentro da janela de 12 horas)
0,07 = 0,07 (nenhuma linha anterior está dentro da janela de 12 horas)
As linhas de South Lake Tahoe incluem esses cálculos, por exemplo:
0,56 + 0,38 + 0,28 + 0,80 = 2,02 (todas as quatro linhas para 2024-12-23 estão dentro de 12 horas uma da outra)
0,80 + 0,17 = 0,97 (uma linha anterior está dentro da janela de 12 horas)
Outras funções de janela, como as funções de classificação LEAD e LAG também são comumente usadas em análises de séries temporais. Use função de janela LEAD para encontrar o próximo ponto de dados na série temporal, em relação ao ponto de dados atual, e a função LAG para encontrar o ponto de dados anterior.
Visualizar resultados de consulta no Snowsight¶
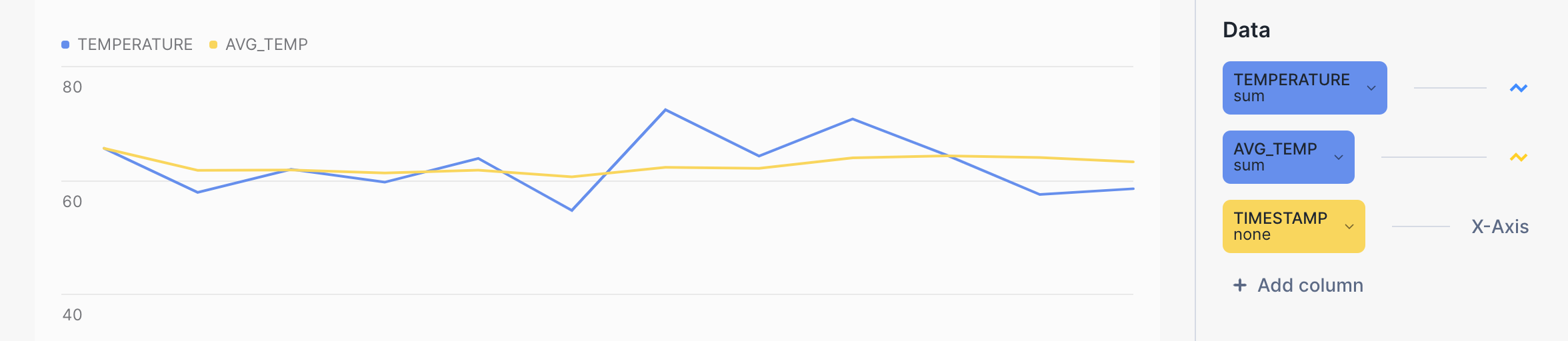
Você pode usar Snowsight para visualizar os resultados de consultas de agregação e ter uma noção melhor do efeito de suavização dos cálculos com quadros de janela deslizantes. Na planilha de consulta, clique no botão Chart ao lado de Results.
Por exemplo, a linha amarela no gráfico de barras a seguir mostra uma tendência muito mais suave para a temperatura média em comparação com a linha azul para a temperatura bruta. A consulta em si é semelhante a:
Usando funções de agregação MIN_BY e MAX_BY¶
A capacidade de selecionar uma coluna com base no valor mínimo ou máximo de outra coluna na mesma linha é um requisito comum para desenvolvedores SQL que trabalham com dados de séries temporais. MIN_BY e MAX_BY são funções de conveniência que retornam os valores inicial e final (ou maior e menor, ou primeiro e último) em uma tabela, quando os dados são classificados por alguma outra coluna, como um carimbo de data/hora.
O primeiro exemplo simplesmente encontra o último (mais recente) valor precip em toda a tabela. A função MAX_BY classifica todas as linhas por seu valor start_time e retorna o valor precip para o tempo de início “máximo”.
Para criar e carregar a tabela usada nos exemplos a seguir, consulte Criação da tabela heavy_weather.
Você pode verificar esse resultado (e obter mais informações sobre ele) executando esta consulta:
Você pode adicionar uma cláusula GROUP BY para fazer perguntas mais interessantes sobre esses dados. Por exemplo, a consulta a seguir encontra o último valor de precipitação observado para cada cidade na Califórnia, ordenado pelos valores precip (do maior para o menor). Os resultados são agrupados por city para retornar o último valor precip para cada cidade diferente.
A última vez que uma observação foi feita para a cidade de Alta, o valor precip era 0.89, e a última vez que uma observação foi feita para as cidades de South Lake Tahoe, Big Bear City, Montague e Lebec, o valor precip era 0.07 para os quatro locais. (Observe que a consulta não informa quando essas observações foram feitas.)
Você pode retornar o conjunto de resultados “oposto” (o registro precip mais antigo versus o mais recente) usando a função MIN_BY.
Junção de dados de série temporal¶
Você pode usar o construtor ASOF JOIN para unir tabelas que contêm dados de série temporal. Embora consultas ASOF JOIN possam ser emuladas através do uso de SQL complexo, outros tipos de junções e funções de janela, essas consultas são mais fáceis de escrever (e otimizadas) se você usar a sintaxe ASOF JOIN.
Um uso comum para junções ASOF é a análise de dados de negociação financeira. A análise dos custos de transação, por exemplo, requer cálculos de “slippage”, que medem a diferença entre o preço cotado no momento da decisão de comprar ações e o preço efetivamente pago quando a negociação foi executada e registrada. O ASOF JOIN pode agilizar esse tipo de análise. Dado que a principal capacidade deste método de junção é a análise de uma série temporal em relação a outra, ASOF JOIN pode ser útil para analisar qualquer conjunto de dados de natureza histórica. Em muitos desses casos de uso, ASOF JOIN pode ser usado para associar dados quando leituras de diferentes dispositivos possuem carimbos de data/hora que não são exatamente iguais.
A suposição é que os dados de série temporal que você precisa analisar existem em duas tabelas e há um carimbo de data/hora para cada linha em cada tabela. Este carimbo de data/hora representa a data e hora “a partir de” de um evento registrado. Para cada linha na primeira tabela (ou à esquerda), a junção usa uma “condição de correspondência” com um operador de comparação especificado para localizar uma única linha na segunda tabela (ou à direita) em que o valor do carimbo de data/hora é um dos seguintes:
Menor ou igual ao valor do carimbo de data/hora na tabela à esquerda.
Maior ou igual ao valor do carimbo de data/hora na tabela à esquerda.
Menor que o valor do carimbo de data/hora na tabela à esquerda.
Maior que o valor do carimbo de data/hora na tabela à esquerda.
A linha de qualificação no lado direito é a correspondência mais próxima, que pode ser igual no tempo, mais cedo ou mais tarde, dependendo do operador de comparação especificado.
A cardinalidade do resultado de ASOF JOIN é sempre igual à cardinalidade da tabela esquerda. Se a tabela esquerda contiver 40 milhões de linhas, ASOF JOIN retornará 40 milhões de linhas. Portanto, a tabela à esquerda pode ser considerada a tabela “de preservação” e a tabela à direita como a tabela “referenciada”.
União de duas tabelas na correspondência mais próxima (alinhamento)¶
Por exemplo, em um aplicativo financeiro, você pode ter uma tabela chamada quotes e uma tabela chamada trades. Uma tabela registra o histórico de ofertas de compra de ações e a outra registra o histórico de negociações reais. Uma oferta de compra de ações acontece antes da negociação (ou possivelmente no “mesmo” momento, dependendo da granularidade do tempo registrado). Ambas as tabelas possuem carimbos de data/hora e outras colunas de interesse que você pode querer comparar. Uma simples consulta ASOF JOIN retornará a cotação mais próxima (no tempo) antes de cada negociação. Em outras palavras, a consulta pergunta: qual era o preço de uma determinada ação no momento em que fiz a negociação?
Suponha que a tabela trades contenha três linhas e a tabela quotes contenha sete linhas. A cor de fundo das células mostra quais três linhas de quotes se qualificarão para ASOF JOIN quando as linhas forem unidas em símbolos de ações correspondentes e suas colunas de carimbo de data/hora forem comparadas.
Tabela TRADES (tabela esquerda ou “de preservação”)
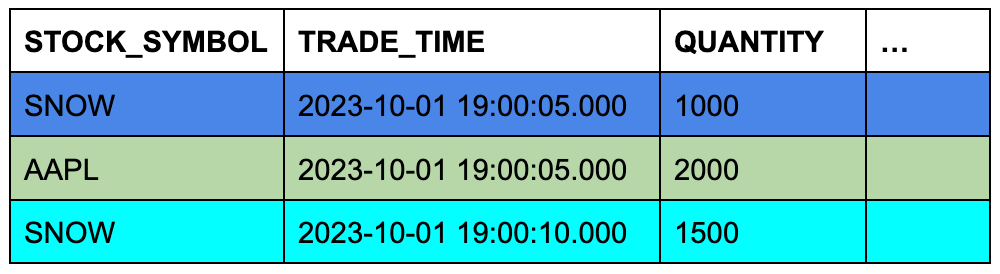
Tabela QUOTES (tabela direita ou “referenciada”)
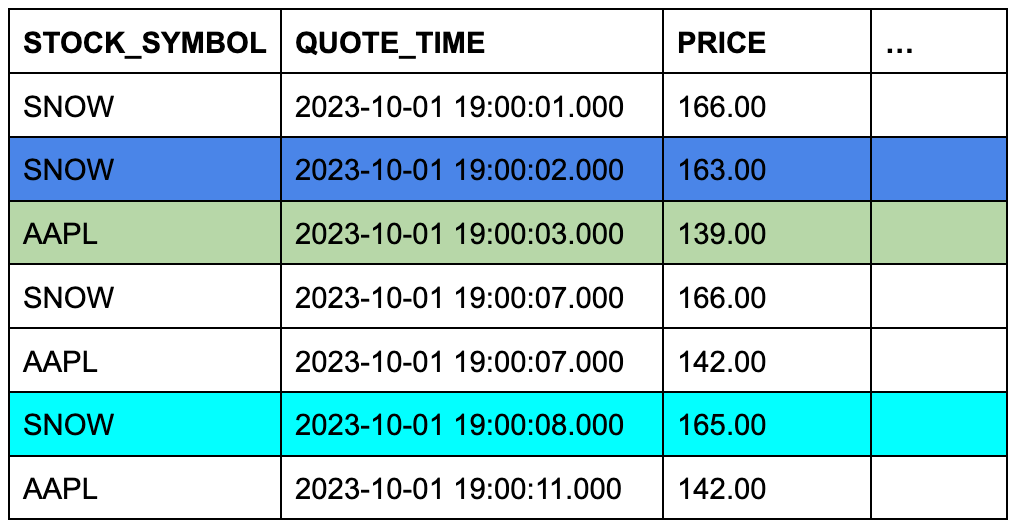
Este exemplo conceitual é fácil de transformar em uma consulta ASOF JOIN específica:
A condição ON agrupa as linhas correspondentes por seus símbolos de ações.
Para executar este exemplo, crie e carregue as tabelas da seguinte forma:
Para mais exemplos de consultas ASOF JOIN, consulte Exemplos.
Preenchimento de lacunas em dados de séries temporais¶
A análise de séries temporais geralmente exige que os dados tenham uma granularidade consistente com registros para cada intervalo, mas os dados do mundo real geralmente chegam em intervalos irregulares ou contêm lacunas. Por exemplo, você pode ter um conjunto de dados principalmente por hora, mas precisa gerar entradas de meia hora para alinhá-lo com a análise downstream , ou pode já ter uma resolução consistente, mas descobrir lacunas na série. A funcionalidade de preenchimento de lacunas do Snowflake oferece maneiras eficientes de aplicar um intervalo uniforme a dados de séries temporais e preencher quaisquer lacunas.
Por exemplo, considere os oito registros a seguir, que capturam observações meteorológicas para duas cidades da Califórnia em 15 de março de 2025.
Embora esses registros tenham um nível um tanto consistente de granularidade (dia, hora, minuto), os intervalos entre as linhas são inconsistentes, variando entre 1 e 15 minutos. Se o objetivo é coletar dados em intervalos de cinco minutos, várias linhas estão faltando.
Como usar a cláusula RESAMPLE¶
Você pode modificar a granularidade e melhorar a consistência de um conjunto de linhas aumentando a amostragem para um intervalo de tempo específico. Para fazer esse tipo de alteração, use a cláusula RESAMPLE, que você define dentro da cláusula FROM de uma instrução SELECT. O resultado de um conjunto de dados reamostrados é um conjunto de dados maior que preserva todas as linhas de entrada existentes e gera algum número de novas linhas com valores que preenchem lacunas na série temporal. (Note que você também pode usar a cláusula RESAMPLE para “reduzir amostragem” de linhas em um conjunto de resultados menor e com granulação ampla).
Por definição, uma série temporal sempre tem uma coluna que contém uma sequência de datas, carimbos de data/hora ou valores numéricos que representam datas ou horas. A reamostragem opera em tal coluna na tabela de origem, e a granularidade necessária deve ser especificada com um valor INTERVAL, como 5 minutes, 30 minutes ou 1 hour.
Normalmente, você também define partições que criam linhas de séries temporais em determinadas dimensões, em vez de apenas gerar um novo carimbo de data/hora por intervalo.
A estrutura de uma consulta RESAMPLE fica assim:
As colunas nas linhas que são geradas são definidas como NULL, salvo pelas colunas especificadas nas cláusulas USING e PARTITION BY. A data, hora ou coluna numérica especificada e as colunas de particionamento têm valores gerados significativos.
Nota
Se você planeja filtrar seus dados reamostrados com base em valores específicos (por exemplo, um ID de dispositivo ou local específico), inclua essas colunas na cláusula PARTITION BY. Isso garante que as linhas geradas tenham valores reais para essas colunas em vez de valores NULL. Se você filtrar com uma cláusula WHERE em colunas que não estão na cláusula PARTITION BY, a cláusula WHERE filtra todas as linhas geradas para essas colunas porque elas contêm valores NULL.
Para executar um exemplo simples que usa os oito registros mostrados anteriormente, comece criando e carregando a seguinte tabela:
Agora selecione as linhas com amostragem aumentada dessa tabela, usando um intervalo de 5 minutes:
Essa consulta preserva as oito linhas originais e gera três novas linhas, preenchendo lacunas por três intervalos de tempo, às 09:45, 10:00 e 10:05. Valores NULL são inseridos nas colunas temperature, city e county.
O ponto de partida para a série temporal é 2025-03-15 09:45:00.000 porque está dentro de 5 minutos do carimbo de data/hora mais antigo no conjunto de dados de entrada (2025-03-15 09:49:00.000).
Se você quiser remover linhas que não ocorrem em intervalos uniformes (09:49 e 10:18 neste caso), consulte Exemplo de RESAMPLE que usa BUCKET_START() para filtrar linhas não uniformes.
Agora adicione uma cláusula PARTITION BY para a consulta:
Os resultados particionados são diferentes de duas maneiras:
São geradas sete linhas, para um total de 15 linhas. Agora existe uma linha para cada intervalo de 5 minutos para cada partição.
As colunas de particionamento geraram corretamente os valores
cityecounty. A única coluna que tem valores NULL nas linhas geradas étemperature.
Você também pode especificar o parâmetro METADATA_COLUMNS na sintaxe RESAMPLE para adicionar as seguintes colunas ao resultado:
A coluna de metadados
is_generatedidentifica as linhas que foram geradas pela operação RESAMPLE e as linhas que já estavam presentes.A coluna de metadados
bucket_startretorna o valor que marca o início do bucket ou intervalo atual que a operação RESAMPLE produz. Você pode usar esta coluna para identificar a qual intervalo uma determinada linha pertence após a reamostragem, e você pode usá-la para executar consultas agregadas em dados reamostrados. Consulte Exemplo de RESAMPLE que usa BUCKET_START() para agregar linhas reamostradas.
Para a sintaxe RESAMPLE completa, consulte RESAMPLE.
Para armazenar os resultados de uma consulta RESAMPLE, use uma Instrução CTAS que seleciona e insere os dados em uma nova tabela:
Interpolação de valores ou «preenchimento de lacunas» em uma série temporal¶
Embora você possa usar a sintaxe RESAMPLE e funções de interpolação independentemente, elas são mais comumente usadas juntas para preencher lacunas com dados de séries temporais no escopo de uma consulta única. Depois de reamostrar seu conjunto de dados, você pode chamar uma função de interpolação para atualizar as outras colunas de interesse nas linhas recém-geradas. O processo de interpolação atualiza colunas que foram anteriormente NULL, como medições numéricas, fornecendo valores significativos com base nos valores encontrados nas linhas anteriores ou seguintes.
Você pode interpolar valores chamando as funções de janela INTERPOLATE_FFILL, INTERPOLATE_BFILL e INTERPOLATE_LINEAR. Por exemplo, a função INTERPOLATE_FFILL encontra o valor anterior (último) na série temporal para a coluna em questão:
A primeira linha retorna NULL para a coluna ffill_temp porque não há uma linha anterior para a função INTERPOLATE_FFILL a ser usada.
Para obter mais informações sobre essas funções de janela, consulte INTERPOLATE_BFILL, INTERPOLATE_FFILL, INTERPOLATE_LINEAR.
Aumento de amostragem, preenchimento de lacunas e armazenamento dos resultados em uma única operação¶
Para simplificar todo o processo de preenchimento de lacunas em um conjunto de dados, você pode aumentar a amostragem de dados e interpolar valores em uma única consulta e salvar os resultados usando uma operação CTAS. Por exemplo, a seguinte instrução CTAS cria uma nova tabela que interpola as medições em um conjunto de dados com amostragem aumentada:
Nota
Quando você usa funções INTERPOLATE com reamostragem, as colunas especificadas na cláusula OVER (PARTITION BY) para funções de janela normalmente correspondem às colunas na cláusula RESAMPLE (PARTITION BY). Essa abordagem garante que a interpolação ocorra dentro das mesmas partições lógicas que foram criadas durante a reamostragem. No exemplo anterior, a reamostragem é particionada por city e county, enquanto o particionamento de funções INTERPOLATE é feita apenas por city. Este exemplo funciona porque a interpolação está acontecendo em uma granularidade menos precisa, mas você deve sempre se certificar de que a estratégia de particionamento esteja alinhada com seus requisitos de dados.
Preenchimento de lacunas com ASOF JOIN¶
Nota
Para utilizar a abordagem recomendada para preenchimento de lacunas e interpolação, consulte Preenchimento de lacunas em dados de séries temporais. O constructo RESAMPLE e as funções INTERPOLATE são recursos de versão preliminar e a abordagem ASOF JOIN do preenchimento de lacunas é incluída apenas como uma possível solução alternativa.
Além de alinhar os dados em duas tabelas encontrando correspondências não exatas em colunas baseadas em tempo, ASOF JOIN é útil para preencher lacunas em uma série temporal quando sua tabela de dados brutos não tem linhas para datas ou carimbos de data/hora específicos. Por exemplo, quando as linhas estão ausentes porque o equipamento tem um defeito ou uma falha de energia resulta em leituras de sensor ignoradas, você pode usar ASOF JOIN para interpolar valores de uma série temporal gerada na tabela. As linhas ausentes são preenchidas com o último valor conhecido para as leituras ausentes. Este valor também é conhecido como “última observação transferida” (LOCF). A consulta ASOF JOIN retorna um conjunto completo de linhas em ordem cronológica e contíguas.
Para usar ASOF JOIN para interpolação, siga estes passos:
Identifique as lacunas na sua tabela executando uma consulta simples.
Gere uma série temporal completa, com a granularidade apropriada, para o período que você precisa cobrir. Por exemplo, sua série temporal pode ser uma sequência simples de datas para um ano específico ou uma sequência muito mais granular de carimbos de data/hora por segundo para um determinado número de dias. Você pode usar SQL ou um aplicativo de planilha para gerar a lista de valores.
A série temporal também precisará de uma dimensão ou ID significativo para cada linha que você irá especificar posteriormente na condição ASOF JOIN ON.
Escreva uma consulta ASOF JOIN que interpole valores nas linhas ausentes. A série temporal gerada será a tabela de preservação e a tabela de dados brutos será a tabela referenciada.
O exemplo a seguir requer a tabela sensor_data_ts. Se você ainda não a criou e carregou, consulte Criação da tabela sensor_data_ts. Para simular a necessidade de uma operação de preenchimento de lacunas, exclua algumas linhas da tabela da seguinte forma:
O resultado é uma tabela em que faltam cinco linhas para DEVICE2 em 7 de março (1h16 à 1h20).
Agora siga estes passos para completar o exercício de preenchimento de lacunas.
Nota
Se você executar este exemplo sozinho, sua saída não corresponderá exatamente porque a tabela sensor_data_ts é carregada com valores gerados aleatoriamente.
Etapa 1: Verifique se a tabela tem lacunas¶
Execute a seguinte consulta para identificar as lacunas:
Esta consulta retorna duas linhas para DEVICE2: a última linha antes do espaço e a primeira linha depois do espaço.
Etapa 2: Gere uma série temporal completa para cobrir as lacunas conhecidas¶
Para gerar uma série temporal com granulação fina (uma linha por segundo) para a lacuna na tabela sensor_data_ts, crie a seguinte tabela com os carimbos de data/hora gerados:
Nesta instrução SQL, 5 é o número de segundos que você precisa para cobrir a lacuna. Observe que o valor de ID do dispositivo (DEVICE2) está incluso nas linhas geradas.
A consulta a seguir retorna as cinco linhas geradas.
Etapa 3: interpole valores usando ASOF JOIN¶
Agora você pode executar uma consulta ASOF JOIN que une continuous_timestamps para sensor_data_ts e interpola valores para linhas ausentes para DEVICE2. A condição de correspondência encontra a linha mais próxima no tempo para cada linha ausente e a condição ON garante que a interpolação ocorra nos IDs de dispositivo correspondente.
A linha mais próxima das linhas ausentes é a linha com o carimbo de data/hora 2024-03-07 00:01:16.000, assumindo que >= é especificado na condição de correspondência, conforme mostrado neste exemplo.
Essa instrução INSERT seleciona cinco linhas da operação ASOF JOIN e os insere na tabela sensor_data_ts.
Para verificar os resultados da interpolação, selecione essas cinco linhas e as duas linhas que as precedem e seguem diretamente, a partir da tabela sensor_data_ts. Observe que as cinco linhas interpoladas pegaram os mesmos valores para as colunas temperature, vibration e motor_rpm registradas na linha 2024-03-07 00:01:15.000. A interpolação foi bem-sucedida.
Aplicação de funções baseadas em ML em dados de séries temporais¶
Você pode treinar um modelo com funções de ML para fazer análise preditiva em dados de séries temporais:
A previsão usa dados de séries temporais históricas para fazer previsões sobre dados futuros. Dada uma série temporal registrada com valores reais observados para datas e horas no passado, o modelo de ML prevê quais podem ser os valores observados para datas e horas no futuro.
A detecção de anomalias identifica valores discrepantes, que são pontos de dados que se desviam de um intervalo esperado. No contexto de uma série temporal, um outlier é uma medida que é muito maior ou menor do que outras medidas em um intervalo de tempo semelhante. Para encontrar outliers, a função de ML produz uma previsão para o mesmo período que está sendo verificado quanto a anomalias e, em seguida, compara os resultados da previsão com os dados reais.
O Top Insights encontra as dimensões mais importantes em um conjunto de dados, cria segmentos a partir dessas dimensões e detecta quais desses segmentos influenciaram uma métrica.
Nota
Para fins de aprendizado de máquina, os carimbos de data/hora em sua série temporal devem representar intervalos de tempo fixos. Se necessário, você pode usar a função DATE_TRUNC ou TIME_SLICE em colunas TIMESTAMP para remover irregularidades ao treinar o modelo de previsão.
Um exemplo de detecção de anomalias em uma série temporal¶
O exemplo a seguir usa uma exibição com apenas 30 linhas para treinar um modelo de detecção de anomalias. Comece gerando dados em uma tabela e depois crie uma exibição na tabela. A exibição não é obrigatória (você pode usar uma tabela para treinar um modelo), mas a opção de exibição oferece alguma flexibilidade para treinar modelos iterativamente, com diferentes contagens de linha, sem atualizar os dados de origem.
Nota
Se você executar este exemplo sozinho, sua saída não corresponderá exatamente porque a tabela sensor_data_30_rows é carregada com valores gerados aleatoriamente.
Agora crie o modelo:
Quando o modelo for desenvolvido com sucesso, chame o método <nome_do_modelo>!DETECT_ANOMALIES para detectar outliers no conjunto de dados de teste especificado. Os carimbos de data/hora nos dados de teste devem seguir cronologicamente os carimbos de data/hora nos dados de treinamento, mas não deve haver um intervalo de tempo muito grande entre os dados de treinamento e os dados de teste. Por exemplo, se você tiver carimbos de data/hora para cada segundo, não use dados de teste que estejam milhões de segundos à frente dos dados de treinamento.
Este exemplo usa outra tabela como dados de teste, com apenas três linhas. Essas linhas têm carimbos de data/hora que seguem de perto aqueles nos dados de treinamento.
Quando a chamada de detecção de anomalias termina, ela retorna uma saída semelhante à seguinte:
As colunas TS e Y retornam os carimbos de data/hora e os valores de temperatura dos dados de teste. Neste caso de teste muito pequeno, a função encontrou uma anomalia (IS_ANOMALY=True). Para obter mais informações sobre as colunas de saída, consulte a seção “Retornos” na descrição da função.
Criação da tabela sensor_data_ts¶
Se quiser testar os exemplos nesta seção que consultam a tabela sensor_data_ts, você pode criar e carregar uma cópia desta tabela executando o seguinte script em SQL. O script gera um mês de dados sintéticos para leituras de sensor chamando as funções UNIFORM, RANDOM e GENERATOR; portanto, sua cópia da tabela não retornará resultados idênticos. As leituras estarão no mesmo intervalo, mas não serão iguais.
Criação da tabela heavy_weather¶
O script a seguir cria e carrega a tabela heavy_weather, que é usada nos exemplos para as funções MAX_BY. A tabela contém 55 linhas de registros de precipitação de neve em cidades da Califórnia durante a última semana de 2021.