Compartilhar dados de forma segura entre regiões e plataformas de nuvem¶
Este tópico fornece instruções sobre como usar a replicação para permitir que os provedores de dados compartilhem dados com segurança com consumidores de dados em diferentes regiões e plataformas de nuvem.
Nota
Se você usar listagens para compartilhar dados com contas de consumidor específicas ou usar o Snowflake Marketplace, poderá usar o Preenchimento automático entre nuvens para concluir automaticamente seu produto de dados para outras regiões.
O compartilhamento de dados entre regiões é suportado por contas Snowflake hospedadas em qualquer uma das seguintes plataformas de nuvem:
Amazon Web Services (AWS)
Google Cloud Platform (GCP)
Microsoft Azure (Azure)
Importante
Se você replicar um banco de dados primário para contas em uma região geográfica ou país diferente daquele em que sua conta Snowflake de origem está localizada, deve confirmar que sua organização não tem nenhuma restrição legal ou regulamentar quanto ao local onde seus dados podem ser transferidos ou hospedados.
Considerações sobre o Data Sharing¶
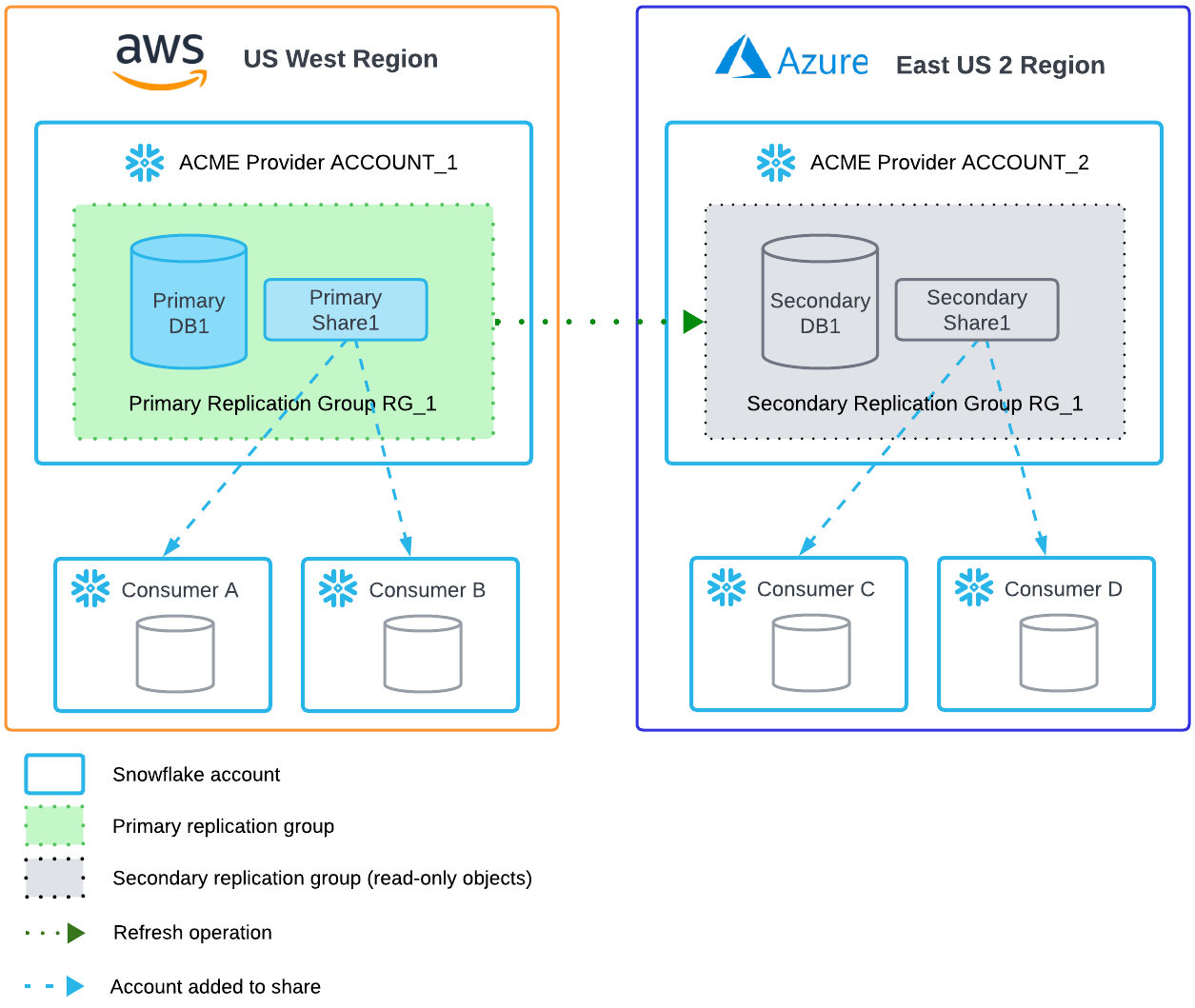
Como o compartilhamento de dados entre regiões utiliza a funcionalidade de replicação de dados do Snowflake, entenda como funciona a replicação no Snowflake como parte de seu processo de planejamento. Para obter mais informações, consulte:
Os provedores de dados só precisam criar uma cópia do conjunto de dados por região; e não uma cópia por consumidor.
Ao compartilhar uma exibição que faz referência a objetos em múltiplos bancos de dados, cada um desses outros bancos de dados deve ser incluído no grupo de replicação. O compartilhamento de dados de mais de um banco de dados exige etapas adicionais. Para obter instruções, consulte Compartilhamento de dados de vários bancos de dados.
Para obter informações relacionadas ao uso de Virtual Private Snowflake (VPS) com compartilhamento de dados, consulte Sobre colaboração em ambientes VPS.
Exemplo 1: compartilhar dados¶
Um provedor de dados, Acme, quer compartilhar dados com consumidores em uma região diferente.
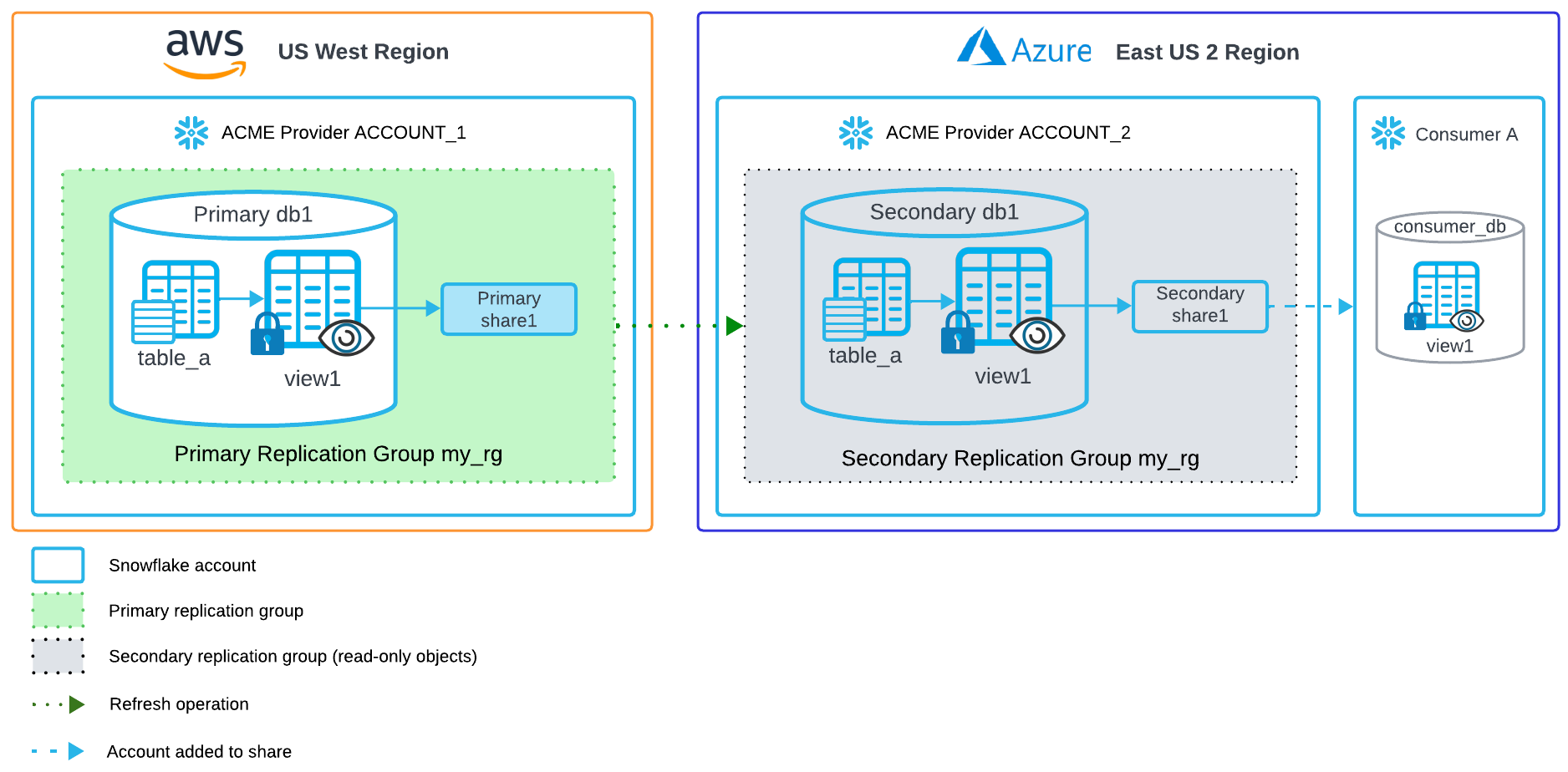
Executar a partir da conta de origem¶
Para criar um grupo de replicação que contenha os bancos de dados e os compartilhamentos para replicar em outra região, execute a instrução SQL a seguir.
Nota
Se você tiver habilitado anteriormente a replicação para um banco de dados individual, deverá desabilitar a replicação do banco de dados antes de adicioná-lo a um grupo de replicação. Para obter mais detalhes, consulte Transição da replicação de banco de dados para a replicação baseada em grupos.
Crie um grupo de replicação my_rg que inclua o banco de dados db1 e compartilhamento share1 para replicar para a conta account_2 na organização acme.
USE ROLE ACCOUNTADMIN;
CREATE REPLICATION GROUP my_rg
OBJECT_TYPES = databases, shares
ALLOWED_DATABASES = db1
ALLOWED_SHARES = share1
ALLOWED_ACCOUNTS = acme.account_2;
Executar a partir da conta de destino¶
Da conta de destino na outra região, execute as seguintes instruções SQL. Qualquer conta que você adicionar ao compartilhamento deverá ser local à região da conta de destino. Após alterar o compartilhamento para definir uma lista de contas (destinos), as contas adicionadas não serão substituídas na próxima atualização.
Crie um grupo secundário de replicação em
account_2:USE ROLE ACCOUNTADMIN; CREATE REPLICATION GROUP my_rg AS REPLICA OF acme.account1.my_rg;
Atualize manualmente o grupo de replicação para replicar os bancos de dados e compartilhamentos para
account_2:ALTER REPLICATION GROUP my_rg REFRESH;
Adicione uma ou mais contas de consumidor a
share1:ALTER SHARE share1 ADD ACCOUNTS = consumer_org.consumer_account_name;
Você pode automatizar operações de atualização definindo o parâmetro REPLICATION_SCHEDULE para o grupo de replicação primário usando o comando ALTER REPLICATION GROUP na conta de origem. Para obter mais informações, consulte Cronograma de replicação.
Exemplo 2: compartilhar um subconjunto de dados de um banco de dados¶
Um provedor de dados, Acme, quer compartilhar um subconjunto de dados com consumidores em uma região diferente. Para reduzir os custos de replicação, ele gostaria de replicar apenas as linhas relevantes de sua tabela mestre. Como a replicação é feita no nível do banco de dados, este exemplo descreve como a Acme pode usar fluxos e tarefas para copiar as linhas desejadas do banco de dados principal para um novo banco de dados, criar um compartilhamento e conceder privilégios na exibição e replicar ambos em um grupo de replicação para uma conta em uma região diferente para acesso do consumidor. Neste cenário, o novo banco de dados e o compartilhamento são designados como objetos primários para replicação de dados.
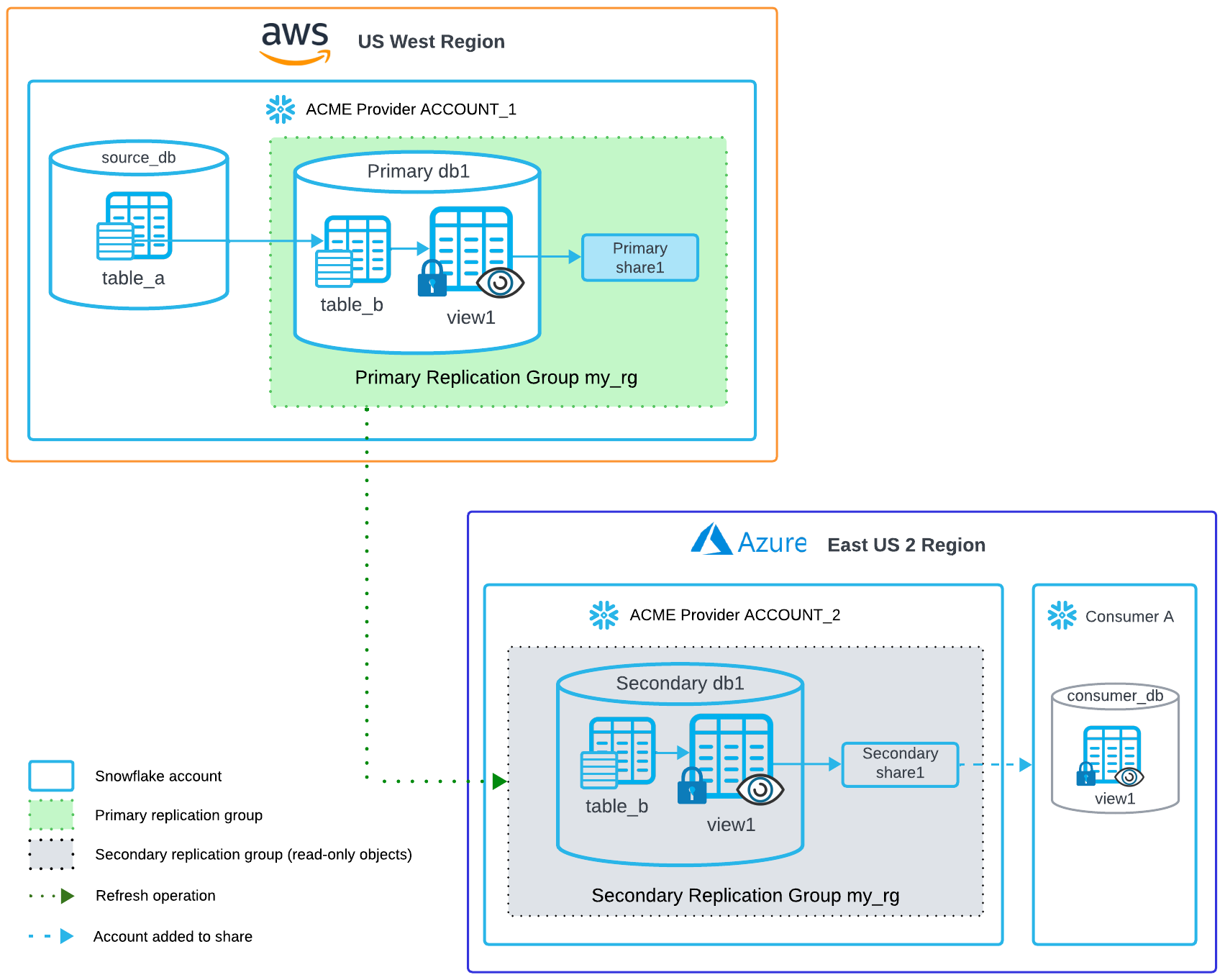
Executar a partir da conta de origem¶
Use os seguintes comandos SQL para criar um novo banco de dados na conta de origem e permitir a replicação.
Nota
Se você tiver habilitado anteriormente a replicação para um banco de dados individual, deverá desabilitar a replicação do banco de dados antes de adicioná-lo a um grupo de replicação. Para obter mais detalhes, consulte Transição da replicação de banco de dados para a replicação baseada em grupos.
Na sua conta local, crie um banco de dados
db1com um subconjunto de dados do banco de dados com os dados de origem:USE ROLE ACCOUNTADMIN; CREATE DATABASE db1; CREATE SCHEMA db1.sch; CREATE TABLE db1.sch.table_b AS SELECT customerid, user_order_count, total_spent FROM source_db.sch.table_a WHERE REGION='azure_eastus2';
Crie uma exibição segura com os dados a serem compartilhados:
CREATE SECURE VIEW db1.sch.view1 AS SELECT customerid, user_order_count, total_spent FROM db1.sch.table_b;
Crie um fluxo para registrar as alterações feitas na tabela de origem:
CREATE STREAM mystream ON TABLE source_db.sch.table_a APPEND_ONLY = TRUE;
Crie uma tarefa para inserir dados na tabela em
db1com alterações dos dados de origem:CREATE TASK mytask1 WAREHOUSE = mywh SCHEDULE = '5 minute' WHEN SYSTEM$STREAM_HAS_DATA('mystream') AS INSERT INTO table_b(CUSTOMERID, USER_ORDER_COUNT, TOTAL_SPENT) SELECT customerid, user_order_count, total_spent FROM mystream WHERE region='azure_eastus2' AND METADATA$ACTION = 'INSERT';
Inicie a tarefa para atualizar os dados:
ALTER TASK mytask1 RESUME;
Crie um compartilhamento e conceda privilégios ao compartilhamento:
CREATE SHARE share1; GRANT USAGE ON DATABASE db1 TO SHARE share1; GRANT USAGE ON SCHEMA db1.sch TO SHARE share1; GRANT SELECT ON VIEW db1.sch.view1 TO SHARE share1;
Crie um grupo de replicação primário com o banco de dados e compartilhamento:
CREATE REPLICATION GROUP my_rg OBJECT_TYPES = DATABASES, SHARES ALLOWED_DATABASES = db1 ALLOWED_SHARES = share1 ALLOWED_ACCOUNTS = acme_org.account_2;
Executar a partir da conta de destino¶
Execute os seguintes comandos SQL a partir da conta de destino na outra região.
Crie um grupo de replicação secundário para replicar os bancos de dados e compartilhamentos da conta de origem:
USE ROLE ACCOUNTADMIN; CREATE REPLICATION GROUP my_rg AS REPLICA OF acme_org.account_1.my_rg;
Atualize manualmente o grupo para replicar objetos para a conta atual:
ALTER REPLICATION GROUP my_rg REFRESH;
Adicione uma ou mais contas de consumidor ao compartilhamento:
ALTER SHARE share1 ADD ACCOUNTS = consumer_org.consumer_account_name;
Você pode automatizar operações de atualização definindo o parâmetro REPLICATION_SCHEDULE para o grupo de replicação primário usando o comando ALTER REPLICATION GROUP na conta de origem. Para obter mais informações, consulte Cronograma de replicação.