Classification (Snowflake ML Functions)¶
Classification uses machine learning algorithms to sort data into different classes using patterns detected in training data. Binary classification (two classes) and multi-class classification (more than two classes) are supported. Common use cases of classification include customer churn prediction, credit card fraud detection, and spam detection.
Note
Classification is part of Snowflake’s suite of business analysis tools powered by machine learning.
Classification involves creating a classification model object, passing in a reference to the training data. The model is fitted to the provided training data. You then use the resulting schema-level classification model object to classify new data points and to understand the model’s accuracy through its evaluation APIs.
About the Classification Model¶
The classification function is powered by a gradient boosting machine. For binary classification, the model is trained using an area-under-the-curve loss function. For multi-class classification, the model is trained using a logistic loss function.
Suitable training datasets for use with classification include a target column representing the labeled class of each data point and at least one feature column.
The classification model supports numeric, Boolean, and string data types for features and labels.
- Numeric features are treated as continuous. To treat numeric features as categorical, cast them to strings.
- String features are treated as categorical. The classification function supports high-cardinality features (for example, job titles or fruits). It does not support full free text, like sentences or paragraphs.
- Boolean features are treated as categorical.
- Timestamps must be TIMESTAMP_NTZ type. The model creates additional
time-based features (epoch, day, week, month), which are used in training and classification. These features appear in
SHOW_FEATURE_IMPORTANCE results as
derived_features. - The cardinality of the label (target) column must be greater than one and less than the number of rows in the dataset.
Inference data must have the same feature names and types as training data. It is not an error for a categorical feature to have a value that is not present in the training dataset. Columns in the inference data that were not present in the training dataset are ignored.
Classification models can be evaluated for quality of prediction. In the evaluation process, an additional model is trained on the original data but with some data points withheld. The withheld data points are then used for inference, and the predicted classes are compared to the actual classes.
Current Limitations¶
- Training and inference data must be numeric, TIMESTAMP_NTZ, Boolean, or string. Other types must be cast to one of these types.
- You cannot choose or modify the classification algorithm.
- Model parameters cannot be manually specified or adjusted.
- In tests, training on a Medium Snowpark-optimized warehouse has succeeded with up to 1,000 columns and 600 million rows. It is possible, but unlikely, to run out of memory below this limit.
- Your target column must contain no more than 255 distinct classes.
- SNOWFLAKE.ML.CLASSIFICATION instances cannot be cloned. When you clone or replicate a database containing a classification model, the model is currently skipped.
Preparing for Classification¶
Before you can use classification, you must:
- Select a virtual warehouse in which to train and run your models.
- Grant the privileges required to create classification models.
You might also want to modify your search path to include the SNOWFLAKE.ML schema.
Selecting a Virtual Warehouse¶
A Snowflake virtual warehouse provides the compute resources for training and using classification machine learning models. This section provides general guidance on selecting the best type and size of warehouse for classification, focusing on the training step, the most time-consuming and memory-intensive part of the process.
You should choose the warehouse type based on the size of your training data. Standard warehouses are subject to a lower Snowpark memory limit, and are appropriate for prototyping with fewer rows or features. Memory limits of standard warehouses do not increase with warehouse size.
As the number of rows or features increases, consider using a Snowpark-optimized warehouse to ensure training can succeed. Memory limits of Snowpark-optimized warehouses do not increase above Medium.
For best performance, train your models using a dedicated warehouse without other concurrent workloads.
To minimize costs, we recommend using an X-Small standard warehouse for prototyping. For larger datasets and production workloads, use a Medium Snowpark-optimized warehouse.
Granting Privileges to Create Classification Models¶
Training a classification model results in a schema-level object. Therefore, the role you use to create models must have the CREATE SNOWFLAKE.ML.CLASSIFICATION privilege on the schema where the model will be created, allowing the model to be stored there. This privilege is similar to other schema privileges like CREATE TABLE or CREATE VIEW.
Snowflake recommends that you create a role named analyst to be used by people who need to create classification
models.
In the following example, the admin role is the owner of the schema admin_db.admin_schema. The
analyst role needs to create models in this schema.
To use this schema, a user assumes the role analyst:
If the analyst role has CREATE SCHEMA privileges in database analyst_db, the role can create a new schema
analyst_db.analyst_schema and create classification models in that schema:
To revoke a role’s model creation privilege on the schema, use REVOKE <privileges> … FROM ROLE:
Training, Using, Viewing, Deleting, and Updating Models¶
Note
SNOWFLAKE.ML.CLASSIFICATION runs using limited privileges, so by default, it does not have access to your data. You must therefore pass tables and views as references, which pass along the caller’s privileges. You can also provide a query reference instead of a reference to a table or a view.
See the CLASSIFICATION reference for information about training, inference, and evaluation APIs.
Use CREATE SNOWFLAKE.ML.CLASSIFICATION to create and train a model.
To run inference (prediction) on a dataset, use the model’s PREDICT method.
To evaluate a model, call the provided evaluation methods.
To show a model’s feature importance ranking, call its SHOW_FEATURE_IMPORTANCE method.
To investigate logs generated during training, use the SHOW_TRAINING_LOGS method. If no training logs are available, this call returns NULL.
Tip
For examples of using these methods, see Examples.
To view all classification models, use the SHOW command.
To delete a classification model, use the DROP command.
Models are immutable and cannot be updated in place. To update a model, drop the existing model and train a new one. The CREATE OR REPLACE variant of the CREATE command is useful for this purpose.
Examples¶
Setting Up the Data for the Examples¶
The examples in this topic uses two tables. The first table, training_purchase_data, has two feature columns: a
binary label column and a multi-class label column. The second table is called
prediction_purchase_data and has two feature columns. Use the SQL below to create these
tables.
Training and Using a Binary Classifier¶
First, create a view containing binary data for training.
The SELECT statement returns results in the following form.
Using this view, create and train a binary classification model.
After you’ve created the model, use its PREDICT method to infer labels for the unlabeled purchase data. You can use wildcard expansion in an object literal to create key-value pairs of features for the INPUT_DATA argument.
The model returns output in the following format. The prediction object includes predicted probabilities for each class and the predicted class based on the maximum predicted probability. The predictions are returned in the same order as the original features were provided.
To zip together features and predictions, use a query like the following.
Training and Using a Multi-Class Classifier¶
Create a view containing binary data for training.
This SELECT statement returns results in the following form.
Now create a multi-class classification model from this view.
After you’ve created the model, use its PREDICT method to infer labels for the unlabeled purchase data. Use wildcard expansion in an object literal to automatically create key-value pairs for the INPUT_DATA argument.
The model returns output in the following format. The prediction object includes predicted probabilities for each class and the predicted class based on the maximum predicted probability. The predictions are returned in the same order as the original features provided and can be joined in the same query.
Saving Results to a Table and Exploring Predictions¶
Results of the calls to models’ PREDICT method can be read directly into a query, but saving the results to a table allows you to conveniently explore predictions.
The key and prediction columns can then be explored in further queries. The query below explores predictions.
The query above returns results in the following form.
Using Evaluation Functions¶
By default, evaluation is enabled on all instances. However, evaluation can be manually enabled or disabled using the config object argument. If the key ‘evaluate’ is specified with the value FALSE, evaluation is not available.
When evaluation is enabled, evaluation metrics can be obtained using the evaluation APIs shown here.
See Understanding Evaluation Metrics for a description of the returned metrics.
The evaluation metrics of our multiclass model are as follows..
Note
For information on threshold metrics, see SHOW_THRESHOLD_METRICS.
We can also review feature importance.
Model Roles and Usage Privileges¶
Each classification model instance includes two model roles, mladmin and mlconsumer. These roles are scoped to the
model itself: model!mladmin and model!mlconsumer. The owner of the model object (initially, its creator) is
automatically granted the model!mladmin and model!mlconsumer roles, and can grant these roles to account roles
and database roles.
The mladmin role permits usage of all APIs invocable from the model object, including but not limited to prediction
methods and evaluation methods. The mlconsumer role permits usage only on prediction APIs, not other exploratory
APIs.
The following SQL example illustrates the grant of classification model roles to other roles. The role r1 can create
a classification model, and grants the role r2 the mlconsumer privilege so that the r2 can call that model’s
PREDICT method. Then r1 grants the mladmin role to another role, r3, so r3 can call all methods of the
model.
First, role r1 creates a model object, making r1 the owner of the model model.
You can see by executing the statements below that the role r2 cannot call the model’s PREDICT method.
Next, r1 grants r2 the mlconsumer instance role, after which r2 can call the model’s PREDICT method.
Similarly, role r3 cannot see the model’s evaluation metrics without the mladmin instance role.
Role r1 grants the required role to r3, and r3 can then call the model’s SHOW_EVALUATION_METRICS method.
You can revoke the privileges as follows.
Use the following commands to see which account roles and database roles have been granted each of these instance roles.
Understanding Evaluation Metrics¶
Metrics measure how accurately a model predicts new data. The Snowflake classification currently evaluates models by selecting a
random sample from the entire dataset. A new model is trained without these rows, and then the rows are used as inference input.
The random sample portion can be configured using the test_fraction key in the EVALUATION_CONFIG object.
Metrics in show_evaluation_metrics¶
show_evaluation_metrics calculates the following values for each class. See
SHOW_EVALUATION_METRICS.
- Positive Instances: Instances of data (rows) that belong to the class of interest or the class being predicted.
- Negative Instances: Instances of data (rows) that do not belong to the class of interest or are the opposite of what is being predicted.
- True Positives (TP): Correct predictions of positive instances.
- True Negatives (TN): Correct predictions of negative instances,
- False Positives (FP): Incorrect predictions of positive instances
- False Negatives (FN): Incorrect predictions of negative instances.
Using the values above, the following metrics are reported for each class. For each metric, a higher value indicates a more predictive model.
- Precision: The ratio of true positives to the total predicted positives. It measures how many of the predicted positive instances are actually positive.
- Recall (Sensitivity): The ratio of true positives to the total actual positives. It measures how many of the actual positive instances were correctly predicted.
- F1 Score: The harmonic mean of precision and recall. It provides a balance between precision and recall, especially when there is an uneven class distribution.
Metrics in show_global_evaluation_metrics¶
show_global_evaluation_metrics calculates overall (global) metrics for all classes predicted by the model by averaging the per-class metrics
calculated by show_evaluation_metrics. See
SHOW_GLOBAL_EVALUATION_METRICS.
Currently, macro and weighted averaging is used for the metrics Precision, Recall, F1, AUC.
Logistic Loss (LogLoss) is calculated for the model as a whole. The objective of prediction is to minimize the loss function.
Metrics in show_threshold_metrics¶
show_threshold_metrics provides raw counts and metrics for a specific threshold for each class. This can be used to
plot ROC and PR curves or do threshold tuning if desired. The threshold varies from 0 to 1 for each specific class; a
predicted probability is assigned. See SHOW_THRESHOLD_METRICS.
The sample is classified as belonging to a class if the predicted probability of being in that class exceeds the specified threshold. The true and false positives and negatives are computed considering the negative class as every instance that does not belong to the class being considered. The following metrics are then computed.
- True positive rate (TPR): The proportion of actual positive instances that the model correctly identifies (equivalent to Recall).
- False positive rate (FPR): The proportion of actual negative instances that were incorrectly predicted as positive.
- Accuracy: The ratio of correct predictions (both true positives and true negatives) to the total number of predictions, an overall measure of how well the model is performing. This metric can be misleading in unbalanced cases.
- Support: The number of actual occurrences of a class in the specified dataset. Higher support values indicate a larger representation of a class in the dataset. Support is not itself a metric of the model but a characteristic of the dataset.
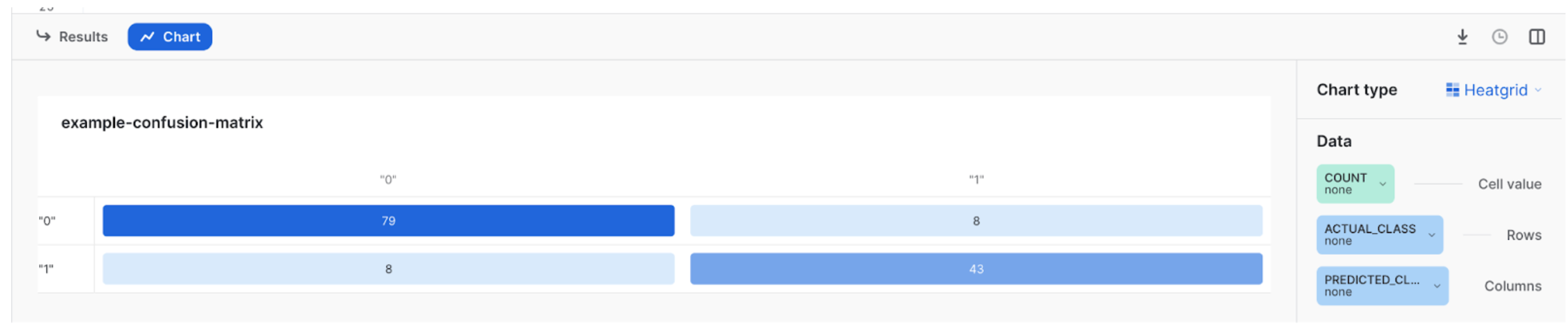
Confusion Matrix in show_confusion_matrix¶
The confusion matrix is a table used to assess the performance of a model by comparing predicted and actual values and evaluating its ability to correctly identify positive and negative instances. The objective is to maximize the number of instances on the diagonal of the matrix while minimizing the number of off-diagonal instances. See SHOW_CONFUSION_MATRIX.
You can visualize the confusion matrix in Snowsight as follows.
The results look like the following.
To visualize the confusion matrix, click on Chart, then Chart Type, then Heatgrid. Under Data, for Cell values select NONE, for Rows select PREDICTED_CLASS, and for Columns select ACTUAL_CLASS. The result appears similar to the figure below.
Understanding Feature Importance¶
A classification model can explain the relative importance of all features used in the model, This information is useful in understanding what factors are really influencing your data.
The SHOW_FEATURE_IMPORTANCE method counts the number of times the model’s trees used each feature to make a decision. These feature importance scores are then normalized to values between 0 and 1 so that their sum is 1. The resulting scores represent an approximate ranking of the features in your trained model.
Features that are close in score have similar importance. Using multiple features that are very similar to each other may result in reduced importance scores for those features.
Limitations¶
- You cannot choose the technique used to calculate feature importance.
- Feature importance scores can be helpful for gaining intuition about which features are important to your model’s accuracy, but the actual values should be considered estimates.
Example¶
Cost Considerations¶
Training and using classification models incurs compute and storage costs.
Using any APIs from the Classification feature (training a model, predicting with the model, retrieving metrics) all require an active warehouse. The compute cost of using Classification functions is charged to the warehouse. See Understanding Compute Cost for general information on Snowflake compute costs.
For details on costs for using ML functions in general, see Cost Considerations in the ML functions overview.