pandas on Snowflake¶
pandas on Snowflake lets you run your pandas code directly on your data in Snowflake. By simply changing the import statement and a few lines of code, you can get the familiar pandas experience to develop robust pipelines, while seamlessly benefiting from Snowflake’s performance and scalability as your pipelines scale.
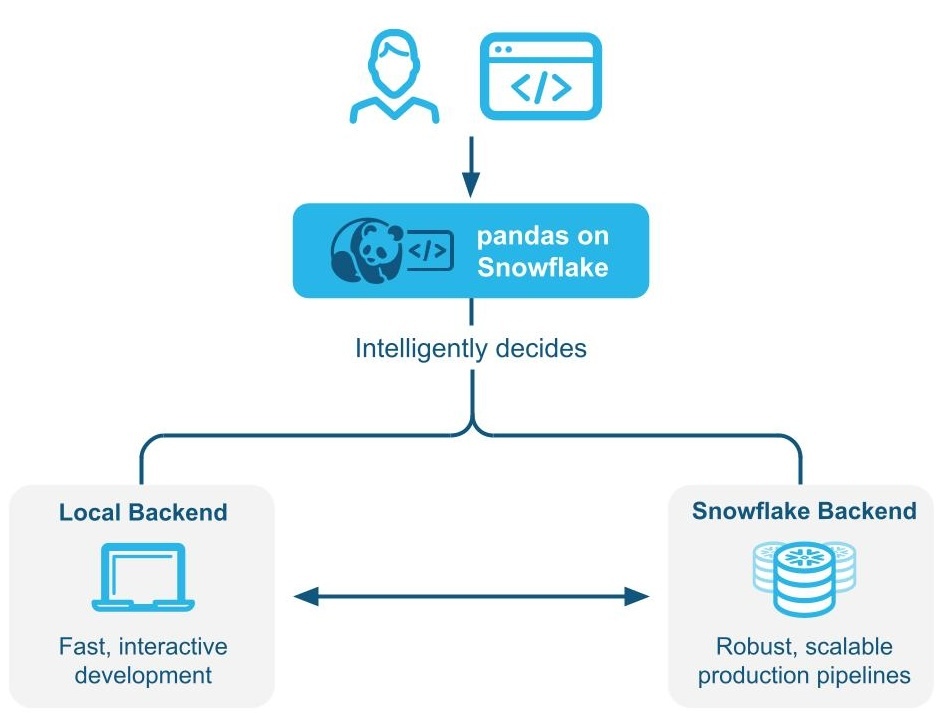
pandas on Snowflake intelligently determines whether to run pandas code locally or use the Snowflake engine to scale and enhance performance through Hybrid execution. When working with large datasets in Snowflake, it runs workloads natively in Snowflake through transpilation to SQL, enabling it to take advantage of parallelization and the data governance and security benefits of Snowflake.
pandas on Snowflake is delivered through the Snowpark pandas API as part of the Snowpark Python library, which enables scalable data processing of Python code within the Snowflake platform.
Benefits of using pandas on Snowflake¶
- Meeting Python developers where they are: pandas on Snowflake offers a familiar interface to Python developers by providing a pandas-compatible layer that can run natively in Snowflake.
- Scalable distributed pandas: pandas on Snowflake bridges the convenience of pandas with the scalability of Snowflake by leveraging existing query optimization techniques in Snowflake. Minimal code rewrites are required, simplifying the migration journey, so you can seamlessly move from prototype to production.
- No additional compute infrastructure to manage and tune: pandas on Snowflake leverages the Snowflake’s powerful compute engine, so you do not need to set up or manage any additional compute infrastructure.
Getting started with pandas on Snowflake¶
Note
For a hands-on example of how to use pandas on Snowflake, check out this Notebook and watch this video.
To install pandas on Snowflake, you can use conda or pip to install the package. For detailed instructions, see Installation.
Once pandas on Snowflake is installed, instead of importing pandas as import pandas as pd, use the following two lines:
Here is an example of how you can start using pandas on Snowflake through the pandas on Snowpark Python library with Modin:
read_snowflake supports reading from Snowflake views, dynamic tables, Iceberg tables, and more. You can also pass in a SQL query directly and get back a pandas on Snowflake DataFrame, making it easy to move seamlessly between SQL and pandas on Snowflake.
How hybrid execution works¶
Note
Starting with Snowpark Python version 1.40.0, hybrid execution is enabled by default when using pandas on Snowflake.
pandas on Snowflake uses hybrid execution to determine whether to run pandas code locally or use the Snowflake engine to scale and enhance performance. This allows you to continue writing familiar pandas code to develop robust pipelines, without having to think about the most optimal and efficient way to run your code, while seamlessly benefiting from Snowflake’s performance and scalability as their pipelines scale.
Example 1: Create a small, 11-row DataFrame inline. With hybrid execution, Snowflake selects local, in-memory pandas backend for executing the operation:
Example 2: Seed a table with 10 million rows of transactions
You can see that the table leverages Snowflake as the backend since this is a large table that resides in Snowflake.
Example 3: Filter data and perform a groupby aggregation resulting in 7 rows of data.
When data is filtered, Snowflake implicitly recognizes the backend choice of engine changes from Snowflake to pandas, since the output is only 7 rows of data.
Notes and limitations¶
-
The DataFrame type will always be
modin.pandas.DataFrame/Series/etceven when the backend changes, to ensure interoperability/compatibility with downstream code. -
To determine what backend to use, Snowflake sometimes uses an estimate of the row size instead of computing the exact length of the DataFrame at each step. This means that Snowflake may not always switch to the optimal backend immediately after an operation when the dataset gets larger/smaller (e.g. filter, aggregation).
-
When there is an operation that combines two or more DataFrames across different backends, Snowflake determines where to move the data based on the lowest data transfer cost.
-
Filter operations may not result in the movement of data, because Snowflake may not be able to estimate the size of the underlying filtered data.
-
Any DataFrames comprised of in-memory Python data will use the pandas backend, such as the following:
-
DataFrames will automatically move from the Snowflake engine to the pandas engine on a limited set of operations. These operations include
df.apply,df.plot,df.iterrows,df.itertuples,series.items, and in reduction operations where the size of data is guaranteed to be smaller. Not all operations are supported points where data migration can occur. -
Hybrid execution does not automatically move a DataFrame from the pandas engine back to Snowflake, except in cases where an operation like
pd.concatacts on multiple DataFrames. -
Snowflake does not automatically move a DataFrame from the pandas engine back to Snowflake unless an operation like
pd.concatacts on multiple DataFrames.
When you should use pandas on Snowflake¶
You should use pandas on Snowflake if any of the following is true:
- You are familiar with the pandas API and the broader PyData ecosystem.
- You work on a team with others who are familiar with pandas and want to collaborate on the same codebase.
- You have existing code written in pandas.
- You prefer more accurate code completion from AI-based copilot tools.
For more information, see Snowpark DataFrames vs Snowpark pandas DataFrame: Which should I choose?
Using pandas on Snowflake with Snowpark DataFrames¶
The pandas on Snowflake and DataFrame API is highly interoperable, so you can build a pipeline that leverages both APIs. For more information, see Snowpark DataFrames vs Snowpark pandas DataFrame: Which should I choose?
You can use the following operations to do conversions between Snowpark DataFrames and Snowpark pandas DataFrames:
| Operation | Input | Output |
|---|---|---|
| to_snowpark_pandas | Snowpark DataFrame | Snowpark pandas DataFrame |
| to_snowpark | Snowpark pandas DataFrame or Snowpark pandas Series | Snowpark DataFrame |
How pandas on Snowflake compares to native pandas¶
pandas on Snowflake and native pandas have similar DataFrame APIs with matching signatures and similar semantics. pandas on Snowflake provides the same API signature as native pandas and provides scalable computation with Snowflake. pandas on Snowflake respects the semantics described in the native pandas documentation as much as possible, but it uses the Snowflake computation and type system. However, when native pandas executes on a client machine, it uses the Python computation and type system. For information about the type mapping between pandas on Snowflake and Snowflake, see Data types.
Starting with Snowpark Python 1.40.0, pandas on Snowflake is best used with data which is already in Snowflake. To convert between native pandas and pandas on Snowflake type, use the following operations:
| Operation | Input | Output |
|---|---|---|
| to_pandas | Snowpark pandas DataFrame | Native pandas DataFrame - Materialize all data to the local environment. If the dataset is large, this may result in an out-of-memory error. |
| pd.DataFrame(…) | Native pandas DataFrame, raw data, Snowpark pandas object | Snowpark pandas DataFrame |
Execution environment¶
pandas: Operates on a single machine and processes in-memory data.pandas on Snowflake: Integrates with Snowflake, which allows for distributed computing across a cluster of machines for large datasets, while leveraging in memory pandas for processing small datasets. This integration enables handling of much larger datasets that exceed the memory capacity of a single machine. Note that using the Snowpark pandas API requires a connection to Snowflake.
Lazy versus eager evaluation¶
-
pandas: Executes operations immediately and materializes results fully in memory after each operation. This eager evaluation of operations might lead to increased memory pressure because data must be moved extensively within a machine. -
pandas on Snowflake: Provides the same API experience as pandas. It mimics the eager evaluation model of pandas, but internally builds a lazily-evaluated query graph to enable optimization across operations.Fusing and transpiling operations through a query graph enables additional optimization opportunities for the underlying distributed Snowflake compute engine, which decreases both cost and end-to-end pipeline runtime compared to running pandas directly within Snowflake.
Note
I/O-related APIs and APIs whose return value is not a Snowpark pandas object (that is,
DataFrame,SeriesorIndex) always evaluate eagerly. For example:read_snowflaketo_snowflaketo_pandasto_dictto_list__repr__- The dunder method,
__array__which can be called automatically by some third-party libraries such as scikit-learn. Calls to this method will materialize results to the local machine.
Data source and storage¶
pandas: Supports the various readers and writers listed in the pandas documentation in IO tools (text, CSV, HDF5, …).pandas on Snowflake: Can read and write from Snowflake tables and read local or staged CSV, JSON, or Parquet files. For more information, see IO (Read and Write).
Data types¶
pandas: Has a rich set of data types, such as integers, floats, strings,datetimetypes, and categorical types. It also supports user-defined data types. Data types in pandas are typically derived from the underlying data and are enforced strictly.pandas on Snowflake: Is constrained by Snowflake type system, which maps pandas objects to SQL by translating the pandas data types to the SQL types in Snowflake. A majority of pandas types have a natural equivalent in Snowflake, but the mapping is not always one to one. In some cases, multiple pandas types are mapped to the same SQL type.
The following table lists the type mappings between pandas and Snowflake SQL:
| pandas type | Snowflake type |
|---|---|
| All signed/unsigned integer types, including pandas extended integer types | NUMBER(38, 0) |
| All float types, including pandas extended float data types | FLOAT |
bool, BooleanDtype | BOOLEAN |
str, StringDtype | STRING |
datetime.time | TIME |
datetime.date | DATE |
All timezone-naive datetime types | TIMESTAMP_NTZ |
All timezone-aware datetime types | TIMESTAMP_TZ |
list, tuple, array | ARRAY |
dict, json | MAP |
| Object column with mixed data types | VARIANT |
| Timedelta64[ns] | NUMBER(38, 0) |
Note
Categorical, period, interval, sparse, and user-defined data types are not supported. Timedelta is only supported on the pandas on Snowpark client today. When writing Timedelta back to Snowflake, it will be stored as Number type.
The following table provides the mapping of Snowflake SQL types back to pandas on Snowflake types using df.dtypes:
| Snowflake type | pandas on Snowflake type (df.dtypes) |
|---|---|
NUMBER (scale = 0) | int64 |
NUMBER (scale > 0), REAL | float64 |
| BOOLEAN | bool |
| STRING, TEXT | object (str) |
| VARIANT, BINARY, GEOMETRY, GEOGRAPHY | object |
| ARRAY | object (list) |
| OBJECT | object (dict) |
| TIME | object (datetime.time) |
| TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ | datetime64[ns] |
| DATE | object (datetime.date) |
When you convert from the Snowpark pandas DataFrame to the native pandas DataFrame with to_pandas(), the native pandas DataFrame will
have refined data types compared to the pandas on Snowflake types, which are compatible with the SQL-Python Data Type Mappings for
functions and procedures.
Casting and type inference¶
pandas: Relies on NumPy and by default follows the NumPy and Python type system for implicit type casting and inference. For example, it treats booleans as integer types, so1 + Truereturns2.pandas on Snowflake: Maps NumPy and Python types to Snowflake types according to the preceding table, and uses the underlying Snowflake type system for implicit type casting and inference. For example, in accordance with the Logical data types, it does not implicitly convert booleans to integer types, so1 + Trueresults in a type conversion error.
Null value handling¶
pandas: In pandas versions 1.x, pandas was flexible when handling missing data, so it treated all of PythonNone,np.nan,pd.NaN,pd.NA, andpd.NaTas missing values. In later versions of pandas (2.2.x) these values are treated as different values.pandas on Snowflake: Adopts a similar approach to earlier pandas versions that treats all of the preceding values listed as missing values. Snowpark reusesNaN,NA, andNaTfrom pandas. But note that all these missing values are treated interchangeably and stored as SQL NULL in the Snowflake table.
Offset/frequency aliases¶
pandas: Date offsets in pandas changed in version 2.2.1. The single-letter aliases'M','Q','Y', and others have been deprecated in favor of two-letter offsets.pandas on Snowflake: Exclusively uses the new offsets described in the pandas time series documentation.
Install the pandas on Snowflake library¶
Prerequisites
The following package versions are required:
- Python 3.9 (deprecated), 3.10, 3.11, 3.12 or 3.13
- Modin version 0.32.0
- pandas version 2.2.*
Tip
To use pandas on Snowflake in Snowflake Notebooks, see the setup instructions in pandas on Snowflake in notebooks.
To install pandas on Snowflake in your development environment, follow these steps:
-
Change to your project directory and activate your Python virtual environment.
Note
The API is under active development, so we recommend installing it in a Python virtual environment instead of system-wide. This practice allows each project you create to use a specific version, which insulates you from changes in future versions.
You can create a Python virtual environment for a particular Python version by using tools like Anaconda, Miniconda, or virtualenv.
For example, to use conda to create a Python 3.12 virtual environment, run these commands:
Note
If you previously installed an older version of pandas on Snowflake using Python 3.9 and pandas 1.5.3, you will need to upgrade your Python and pandas versions as described above. Follow the steps to create a new environment with Python 3.10 to 3.13.
-
Install the Snowpark Python library with Modin:
or
Note
Confirm that
snowflake-snowpark-pythonversion 1.17.0 or later is installed.
Authenticating to Snowflake¶
Before using pandas on Snowflake, you must establish a session with the Snowflake database. You can use a config file to choose the connection parameters for your session, or you can enumerate them in your code. For more information, see Creating a Session for Snowpark Python. If a unique active Snowpark Python session exists, pandas on Snowflake will automatically use it. For example:
The pd.session is a Snowpark session, so you can do anything with it that you can do with any other Snowpark session. For example, you can use it to execute an arbitrary SQL query,
which results in a Snowpark DataFrame as per the Session API, but note that
the result is a Snowpark DataFrame, not a Snowpark pandas DataFrame.
Alternatively, you can configure your Snowpark connection parameters in a configuration file. This eliminates the need to enumerate connection parameters in your code, which allows you to write your pandas on Snowflake code almost as you would normally write pandas code.
-
Create a configuration file located at
~/.snowflake/connections.tomlthat looks something like this: -
To create a session using these credentials, use
snowflake.snowpark.Session.builder.create():
You can also create multiple Snowpark sessions, then assign one of them to pandas on Snowflake. pandas on Snowflake only uses one session, so you have to explicitly assign one
of the sessions to pandas on Snowflake with pd.session = pandas_session:
The following example shows that trying to use pandas on Snowflake when there is no active Snowpark session will raise a SnowparkSessionException with an
error like “pandas on Snowflake requires an active snowpark session, but there is none.” After you create a session, you can use pandas on Snowflake. For example:
The following example shows that trying to use pandas on Snowflake when there are multiple active Snowpark sessions will cause
a SnowparkSessionException with a message like, “There are multiple active snowpark sessions, but you need to choose one for pandas on Snowflake.”
Note
You must set the session used for a new pandas on Snowflake DataFrame or Series via modin.pandas.session.
However, joining or merging DataFrames created with different sessions is not supported, so you should avoid repeatedly setting different sessions
and creating DataFrames with different sessions in a workflow.
API reference¶
See the pandas on Snowflake API reference for the full list of currently implemented APIs and methods available.
For a full list of supported operations, see the following tables in pandas on Snowflake reference:
- pandas general utilities supported APIs
- Series supported APIs
- DataFrame supported APIs
- Index supported APIs
- Windows supported APIs
- GroupBy supported APIs
- Resampler supported APIs
- DatetimeProperties supported APIs
- StringMethods supported APIs
APIs and configuration parameter for hybrid execution¶
Hybrid execution uses a combination of the dataset size estimate and the operations being applied to the DataFrame to determine the choice of backend. In general, datasets under 100k rows will tend to use local pandas; those over 100k rows will tend to use Snowflake, unless the dataset is loaded from local files.
Configuring transfer costs¶
To change the default switching threshold to another row limit value, you can modify the environment variable before initializing a DataFrame:
Setting this value will penalize transferring rows out of Snowflake.
Configuring local execution limits¶
Once a DataFrame is local it will generally stay local unless there is a need to move it back to Snowflake for a merge, but there is an upper bound considered for the maximum size of data than can be processed locally. Currently this boundary is 10M rows.
Checking and setting backend¶
To check the current backend of choice, you can use the df.getbackend() command, which returns Pandas for local execution, or Snowflake for pushdown execution.
To set the current backend of choice with either set_backend or its alias move_to:
You can also set the backend in place:
To inspect and display information about why data was moved:
Manual override backend selection by pinning backend¶
By default, Snowflake automatically chooses the best backend for a given DataFrame and operation. If you would like to override the automatic engine selection, you can disable automatic switching on an object and all resulting data produced by it, using the pin_backend() method:
To re-enable automatic backend switching, call unpin_backend():
Using Snowpark pandas in Snowflake notebooks¶
To use pandas on Snowflake in Snowflake notebooks, see pandas on Snowflake in notebooks.
Using Snowpark pandas in Python Worksheets¶
To use Snowpark pandas, you need to install Modin by selecting modin from Packages in the Python Worksheet environment.
You can select the Return type of the Python function under Settings > Return type. By default, this is set as a Snowpark table. To display the Snowpark pandas DataFrame as a result, you can convert a Snowpark pandas DataFrame to a Snowpark DataFrame by calling to_snowpark(). No I/O cost will be incurred in this conversion.
Here is an example of using Snowpark pandas with Python Worksheets:
Using pandas on Snowflake in stored procedures¶
You can use pandas on Snowflake in a stored procedure to build a data pipeline and schedule the execution of the stored procedure with tasks.
Here is how you can create a stored procedure using SQL:
Here is how you can create a stored procedure using the Snowflake Python API:
To call the stored procedure, you can run dt_pipeline_sproc() in Python or CALL run_data_transformation_pipeline_sp() in SQL.
Using pandas on Snowflake with third-party libraries¶
pandas is commonly used with third-party library APIs for visualization and machine learning applications. pandas on Snowflake is interoperable with most of these libraries, so they can be used without converting to pandas DataFrames explicitly. However, note that distributed execution is not often supported in most third-party libraries except in limited use cases. Therefore, this can lead to slower performance on large datasets.
Supported third-party libraries¶
The libraries listed below accept pandas on Snowflake DataFrames as input, but not all their methods have been tested. For an in-depth interoperability status on an API level, see Interoperability with third party libraries.
- Plotly
- Altair
- Seaborn
- Matplotlib
- Numpy
- Scikit-learn
- XGBoost
- NLTK
- Streamlit
pandas on Snowflake currently has limited compatibility for certain NumPy and Matplotlib APIs, such as distributed implementation for np.where and interoperability with df.plot. Converting Snowpark pandas DataFrames via to_pandas() when working with these third-party libraries will avoid multiple I/O calls.
Here is an example with Altair for visualization and scikit-learn for machine learning.
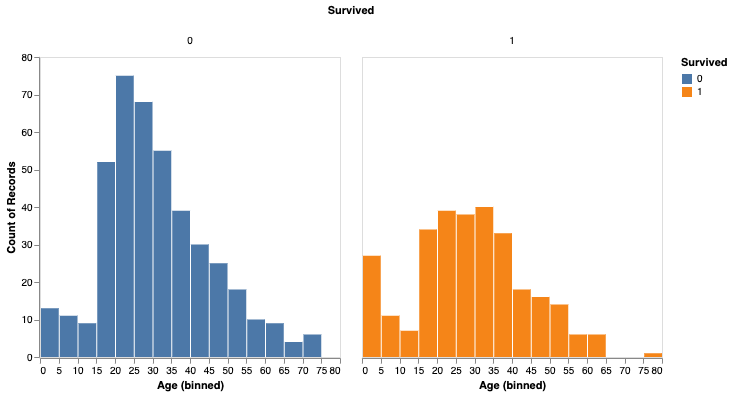
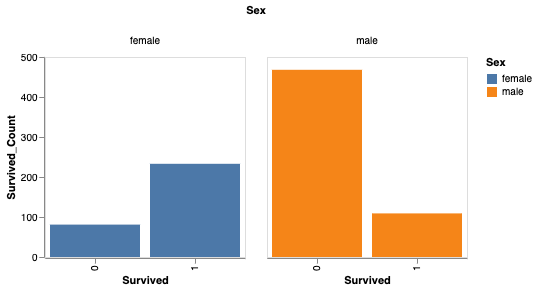
You can also analyze survival based on gender.
You can now use scikit-learn to train a simple model.
Note
For greater performance, we recommend converting to pandas DataFrames via to_pandas(), particularly when using machine learning libraries such as scikit-learn. The to_pandas() function collects all rows, however, so it may be better to reduce the dataframe size first with sample(frac=0.1) or head(10).
Unsupported libraries¶
When using unsupported third-party libraries with a pandas on Snowflake DataFrame, we recommend converting the pandas on Snowflake DataFrame to a pandas DataFrame by calling to_pandas() before passing the DataFrame to the third-party library method.
Note
Calling to_pandas() pulls your data out of Snowflake and into memory, so consider that for large datasets and sensitive use cases.
Using Snowflake Cortex LLM functions with Snowpark pandas¶
You can use Snowflake Cortex LLM functions via the Snowpark pandas apply function.
You apply the function with special keyword arguments. Currently, the following Cortex functions are supported:
The following example uses the TRANSLATE function across multiple records in a Snowpark pandas DataFrame:
Output:
The following example uses the SENTIMENT (SNOWFLAKE.CORTEX) function on a Snowflake table named reviews:
The following example uses the AI_EXTRACT to answer a question:
Output:
Note
The snowflake-ml-python package must be installed to use Cortex LLM functions.
Limitations¶
pandas on Snowflake has the following limitations:
-
pandas on Snowflake provides no guarantee of compatibility with OSS third-party libraries. Starting with version 1.14.0a1, however, Snowpark pandas introduces limited compatibility for NumPy, specifically for
np.whereusage. For more information, see NumPy Interoperability.When you call third-party library APIs with a Snowpark pandas DataFrame, Snowflake recommends that you convert the Snowpark pandas DataFrame to a pandas DataFrame by calling
to_pandas()before passing the DataFrame to the third-party library call. For more information, see Using pandas on Snowflake with third-party libraries. -
pandas on Snowflake is not integrated with Snowpark ML. When you use Snowpark ML, we recommend that you convert the Snowpark pandas DataFrame to a Snowpark DataFrame using to_snowpark() before calling Snowpark ML.
-
Lazy
MultiIndexobjects are not supported. WhenMultiIndexis used, it returns a native pandasMultiIndexobject, which requires pulling all data to the client side. -
Not all pandas APIs have a distributed implementation in pandas on Snowflake, although some are being added. For unsupported APIs,
NotImplementedErroris thrown. For information about supported APIs, see the API reference documentation. -
pandas on Snowflake provides compatibility with any patch version of pandas 2.2.
-
Snowpark pandas cannot be referenced within Snowpark pandas
applyfunction. You can only use native pandas insideapply.- Following is an example:
Troubleshooting¶
This section describes troubleshooting tips for using pandas on Snowflake.
-
When troubleshooting, try running the same operation on a native pandas DataFrame (or a sample) to see whether the same error persists. This approach might provide hints on how to fix your query. For example:
-
If you have a long-running notebook opened, note that by default Snowflake sessions time out after the session is idle for 240 minutes (4 hours). When the session expires, if you run additional pandas on Snowflake queries, the following message appears: “Authentication token has expired. The user must authenticate again.” At this point, you must re-establish the connection to Snowflake. This might cause the loss of any unpersisted session variables. For more information about how to configure the session idle timeout parameter, see Session policies.
Best practices¶
This section describes best practices to follow when using pandas on Snowflake.
- Avoid using iterative code patterns, such as
forloops,iterrows, anditeritems. Iterative code patterns quickly increase the generated query complexity. Let pandas on Snowflake, not the client code, perform the data distribution and computation parallelization. With regard to iterative code patterns, look for operations that can be performed on the whole DataFrame, and use the corresponding operations instead.
-
Avoid calling
apply,applymap, andtransform, which are eventually implemented with UDFs or UDTFs, which might not be as performant as regular SQL queries. If the function applied has an equivalent DataFrame or series operation, use that operation instead. For example, instead ofdf.groupby('col1').apply('sum'), directly calldf.groupby('col1').sum(). -
Call
to_pandas()before passing the DataFrame or series to a third-party library call. pandas on Snowflake does not provide a compatibility guarantee with third-party libraries. -
Use a materialized regular Snowflake table to avoid extra I/O overhead. pandas on Snowflake works on top of a data snapshot that only works for regular tables. For other types, including external tables, views, and Apache Iceberg™ tables, a temporary table is created before the snapshot is taken, which introduces extra materialization overhead.
-
pandas on Snowflake provides fast and zero copy clone capability while creating DataFrames from Snowflake tables using
read_snowflake. -
Double check the result type before proceeding to other operations, and do explicit type casting with
astypeif needed.Due to limited type inference capability, if no type hint is given,
df.applywill return results of object (variant) type even if the result contains all integer values. If other operations require thedtypeto beint, you can do an explicit type casting by calling theastypemethod to correct the column type before you continue. -
Avoid calling APIs that require evaluation and materialization unless necessary.
APIs that don’t return
SeriesorDataframerequire eager evaluation and materialization to produce the result in the correct type. Same for plotting methods. Reduce calls to those APIs to minimize unnecessary evaluations and materialization. -
Avoid calling
np.where(<cond>, <scalar>, n)on large datasets. The<scalar>will be broadcast to a DataFrame the size of<cond>, which may be slow. -
When working with iteratively built queries,
df.cache_resultcan be used to materialize intermediate results to reduce the repeated evaluation and improve the latency and reduce complexity of the overall query. For example:In the example above, the query to produce
df2is expensive to compute and is reused in the creation of bothdf3anddf4. Materializingdf2into a temporary table (making subsequent operations involvingdf2a table scan instead of a pivot) can reduce the overall latency of the code block:
Examples¶
Here is a code example with pandas operations. We start with a Snowpark pandas DataFrame named pandas_test, which contains three
columns: COL_STR, COL_FLOAT, and COL_INT. To view the notebook associated with these examples, see the
pandas on Snowflake examples in the Snowflake-Labs repository.
We save the DataFrame as a Snowflake table named pandas_test, which we will use throughout our examples.
Next, we create a DataFrame from the Snowflake table. We drop the column COL_INT and then
save the result back to Snowflake with a column named row_position.
The result is a new table, pandas_test2, which looks like this:
IO (Read and Write)¶
For more information, see Input/Output.
Indexing¶
Missing values¶
Type conversion¶
Binary operations¶
Aggregation¶
Merge¶
Groupby¶
For more information, see GroupBy.