Refresh directory tables automatically for Google Cloud Storage¶
Unter diesem Thema finden Sie eine Anleitung zum Auslösen der Aktualisierung der Metadaten von Verzeichnistabellen mithilfe von Google Cloud Pub/Sub-Meldungen für Google Cloud Storage-Ereignisse (GCS).
Bemerkung
Um die unter diesem Thema beschriebenen Schritte ausführen zu können, müssen Sie eine Rolle verwenden, die über die CREATE STAGE-Berechtigung für ein Schema verfügt.
Außerdem benötigen Sie Administratorzugriff auf Google Cloud (GC). Wenn Sie kein GCP-Administrator sind, bitten Sie Ihren GCP-Administrator, die Schritte zur Erfüllung der Voraussetzungen auszuführen.
Beachten Sie, dass nur OBJECT_DELETE- und OBJECT_FINALIZE-Ereignisse die Aktualisierung von Verzeichnistabellen auslösen. Snowflake empfiehlt, nur unterstützte Ereignisse für Verzeichnistabellen zu senden, um Kosten, Ereignisrauschen und Latenz zu reduzieren.
Unterstützung von Cloudplattformen¶
Das Triggern automatischer Aktualisierungen mit GCS Pub/Sub-Ereignisnachrichten wird für Snowflake-Konten unterstützt, die auf einer der unterstützten Cloudplattformen gehostet werden.
Configure secure access to Cloud Storage¶
Bemerkung
Wenn Sie bereits den sicheren Zugriff auf den GCS-Bucket konfiguriert haben, in dem Ihre Datendateien gespeichert sind, können Sie diesen Abschnitt überspringen.
In diesem Abschnitt wird beschrieben, wie Sie ein Speicherintegrationsobjekt konfigurieren, um die Authentifizierungsverantwortung für den Cloudspeicher an eine Snowflake-Entität für die Identitäts- und Zugriffsverwaltung (IAM) zu delegieren.
In diesem Abschnitt wird beschrieben, wie Sie Speicherintegrationen verwenden, damit Snowflake Daten aus einem Google Cloud Storage Bucket lesen und in diesen schreiben kann, auf den in einem externen Stagingbereich (d. h. Cloud Storage) verwiesen wird. Integrationen sind benannte First-Class-Snowflake-Objekte, bei denen keine expliziten Cloudanbieter-Anmeldeinformationen wie geheime Schlüssel oder Zugriffstoken übergeben werden müssen. Stattdessen verweisen Integrationsobjekte auf ein Cloud Storage-Dienstkonto. Ein Administrator in Ihrem Unternehmen gewährt die Dienstkontoberechtigungen im Cloud Storage-Konto.
Administratoren können Benutzer auch auf einen bestimmten Satz von Cloud Storage-Buckets (und optionale Pfade) beschränken, auf die von externen Stagingbereichen zugegriffen wird, die die Integration verwenden.
Bemerkung
Um die Anweisungen in diesem Abschnitt ausführen zu können, müssen Sie als Projekteditor auf Ihr Cloud Storage-Projekt zugreifen können. Wenn Sie kein Projekteditor sind, bitten Sie Ihren Cloud Storage-Administrator, diese Aufgaben auszuführen.
Bestätigen Sie, dass Snowflake die Region von Google Cloud Storage unterstützt, in der Ihr Speicher gehostet wird. Weitere Informationen dazu finden Sie unter Unterstützte Cloudregionen.
Die folgende Abbildung zeigt den Integrationsablauf für einen Cloud Storage-Stagingbereich:
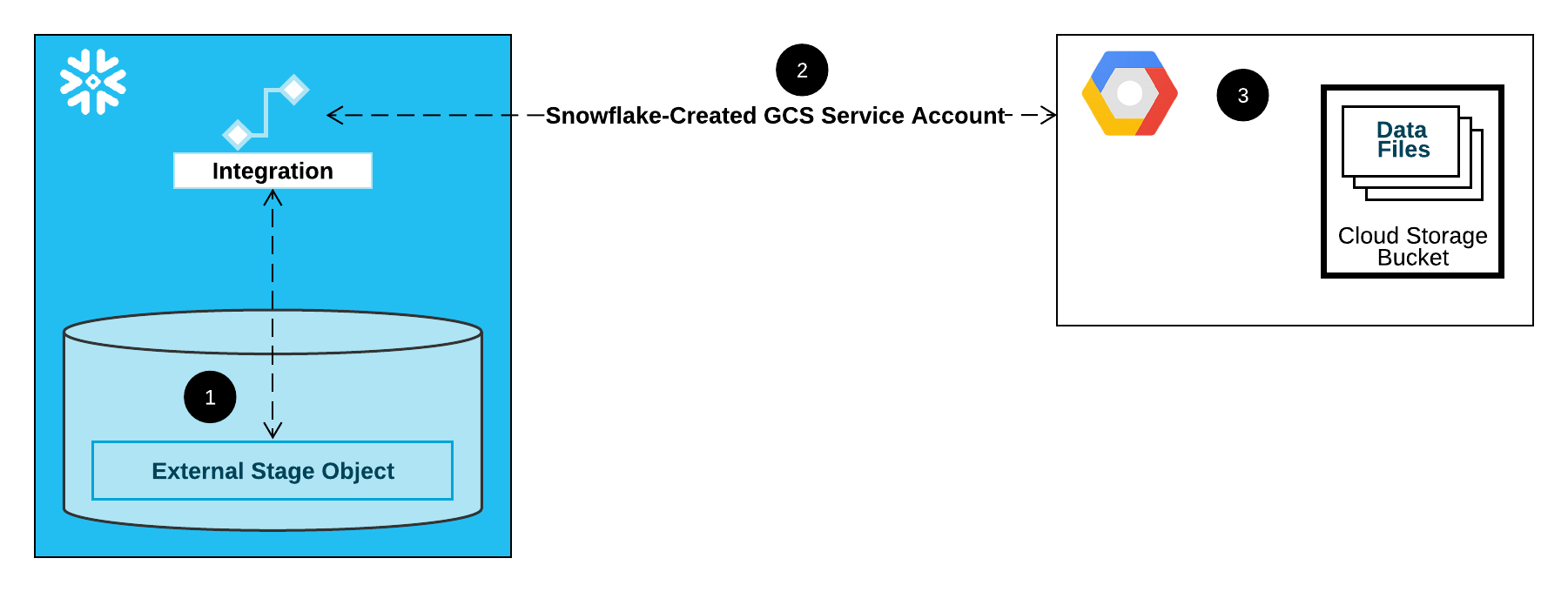
Ein externer Stagingbereich (d. h. Cloud Storage) verweist in seiner Definition auf ein Speicherintegrationsobjekt.
Snowflake ordnet die Speicherintegration automatisch einem für Ihr Konto erstellten Cloud Storage-Dienstkonto zu. Snowflake erstellt ein einzelnes Dienstkonto, auf das von allen GCS-Speicherintegrationen in Ihrem Snowflake-Konto verwiesen wird.
Ein Projekteditor für Ihr Cloud Storage-Projekt gewährt dem Dienstkonto Berechtigungen für den Zugriff auf den in der Stagingbereichsdefinition angegebenen Bucket. Beachten Sie, dass viele externe Stagingobjekte auf unterschiedliche Buckets und Pfade verweisen und dieselbe Integration zur Authentifizierung verwenden können.
Wenn ein Benutzer Daten aus einem Stagingbereich lädt oder in einen Stagingbereich entlädt, überprüft Snowflake die Berechtigungen, die dem Dienstkonto für den Bucket erteilt wurden, bevor Zugriff gewährt oder verweigert wird.
Unter diesem Thema:
Schritt 1: Eine Cloud Storage-Integration in Snowflake erstellen¶
Erstellen Sie mit dem Befehl CREATE STORAGE INTEGRATION eine Integration. Eine Integration ist ein Snowflake-Objekt, das die Authentifizierungsverantwortung für externen Cloud-Speicher an eine von Snowflake generierte Entität (d. h. ein Cloud Storage-Dienstkonto) delegiert. Für den Zugriff auf Cloud Storage-Buckets erstellt Snowflake ein Dienstkonto, dem Berechtigungen für den Zugriff auf die Buckets erteilt werden können, in denen sich Ihre Datendateien befinden.
Eine einzige Speicherintegration kann mehrere externe Stagingbereiche (d. h. GCS) unterstützen. Die URL in der Stagingbereichsdefinition muss mit den für den Parameter STORAGE_ALLOWED_LOCATIONS angegebenen GCS-Buckets (und optionalen Pfaden) übereinstimmen.
Bemerkung
Dieser SQL-Befehl kann nur von Kontoadministratoren (Benutzer mit der Rolle ACCOUNTADMIN) oder von Rollen mit der globalen Berechtigung CREATE INTEGRATION ausgeführt werden.
Wobei:
integration_nameist der Name der neuen Integration.bucketist der Name eines Cloud Storage-Buckets, in dem Ihre Datendateien gespeichert sind (z. B.mybucket). Die erforderlichen Parameter STORAGE_ALLOWED_LOCATIONS und STORAGE_BLOCKED_LOCATIONS beschränken bzw. blockieren den Zugriff auf diese Buckets, wenn Stagingbereiche, die auf diese Integration verweisen, erstellt oder geändert werden.pathist ein optionaler Pfad, mit dem Sie Objekte im Bucket genauer steuern können.
Im folgenden Beispiel wird eine Integration erstellt, die externe Stagingbereiche, die die Integration nutzen, explizit darauf beschränkt, auf einen von zwei Buckets und Pfaden zu verweisen: In einem späteren Schritt werden wir einen externen Stagingbereich erstellen, der auf einen dieser Buckets und Pfade verweist.
Zusätzliche externe Stagingbereiche, die diese Integration ebenfalls verwenden, können auf die zulässigen Buckets und Pfade verweisen:
Schritt 2: Cloud Storage-Dienstkonto für Ihr Snowflake-Konto abrufen¶
Führen Sie den Befehl DESCRIBE INTEGRATION aus, um die ID für das Cloud Storage-Dienstkonto abzurufen, das automatisch für Ihr Snowflake-Konto erstellt wurde:
Wobei:
integration_nameist der Name der Integration, die Sie in Schritt 1: Eine Cloud Storage-Integration in Snowflake erstellen (unter diesem Thema) erstellt haben.
Beispiel:
Die Eigenschaft STORAGE_GCP_SERVICE_ACCOUNT in der Ausgabe zeigt das Konto des Cloud Storage-Dienstes, das für Ihr Snowflake Konto erstellt wurde (d. h. service-account-id@project1-123456.iam.gserviceaccount.com). Wir stellen ein einziges Cloud Storage-Dienstkonto für Ihr gesamtes Snowflake-Konto bereit. Alle Cloud Storage-Integrationen verwenden dieses Dienstkonto.
Schritt 3: Dienstkontoberechtigungen für den Zugriff auf Bucket-Objekte erteilen¶
Die folgende Schritt-für-Schritt-Anweisung beschreibt, wie Sie IAM-Zugriffsberechtigungen für Snowflake in Ihrer Google Cloud console konfigurieren, damit Sie ein Cloud Storage Bucket zum Laden und Entladen von Daten verwenden können:
Create a custom IAM role¶
Erstellen Sie eine kundenspezifische Rolle, die über die erforderlichen Berechtigungen verfügt, um auf den Bucket zuzugreifen und Objekte abzurufen.
Melden Sie sich bei Google Cloud console als Projektbearbeiter an.
Wählen Sie im Startseiten-Dashboard die Option IAM & Admin » Roles aus.
Wählen Sie Create Role aus.
Geben Sie unter Title einen Titel und optional unter Description eine Beschreibung für die benutzerdefinierte Rolle ein.
Wählen Sie Add Permissions aus.
Filtern Sie die Liste der Berechtigungen, und fügen Sie Folgendes aus der Liste hinzu:
Aktionen
Erforderliche Berechtigungen
Nur Laden von Daten
storage.buckets.getstorage.objects.getstorage.objects.list
Laden von Daten mit Bereinigungsoption, Ausführen des Befehls REMOVE im Stagingbereich
storage.buckets.getstorage.objects.deletestorage.objects.getstorage.objects.list
Laden und Entladen von Daten
storage.buckets.get(zur Berechnung der Datentransferkosten)storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Nur Entladen von Daten
storage.buckets.getstorage.objects.createstorage.objects.deletestorage.objects.list
Verwenden von COPY FILES zum Kopieren von Dateien in einen externen Stagingbereich
Sie müssen über die folgenden zusätzlichen Berechtigungen verfügen:
storage.multipartUploads.abortstorage.multipartUploads.createstorage.multipartUploads.liststorage.multipartUploads.listParts
Wählen Sie Add aus.
Wählen Sie Create aus.
Assign the custom role to the Cloud Storage Service Account¶
Melden Sie sich bei Google Cloud console als Projektbearbeiter an.
Wählen Sie im Startseiten-Dashboard die Option Cloud Storage » Buckets aus.
Filtern Sie die Liste der Buckets, und wählen Sie den Bucket, den Sie beim Erstellen Ihrer Speicherintegration angegeben haben.
Wählen Sie Permissions » View by principals und dann Grant access aus.
Fügen Sie unter Add principals den Namen des Dienstkontos ein, den Sie aus der Ausgabe des Befehls DESC STORAGE INTEGRATION abgerufen haben.
Wählen Sie unter Assign roles die benutzerdefinierte IAM-Rolle aus, die Sie zuvor erstellt haben, und wählen Sie dann Save aus.
Wichtig
Wenn Ihre Google Cloud-Organisation am oder nach dem 3. Mai 2024 erstellt wurde, erzwingt Google Cloud in den Richtlinien für Projektorganisationen die Einschränkung domain. Die Standardeinschränkung listet Ihre Domain als einzigen zulässigen Wert auf.
Um dem Snowflake-Dienstkonto Zugriff auf Ihren Speicher zu gewähren, müssen Sie die Domänenbeschränkung aktualisieren.
Grant the Cloud Storage service account permissions on the Cloud Key Management Service cryptographic keys¶
Bemerkung
Dieser Schritt ist nur erforderlich, wenn Ihr GCS-Bucket mit einem in Google Cloud Key Management Service (Cloud KMS) gespeicherten Schlüssel verschlüsselt ist.
Melden Sie sich bei Google Cloud console als Projektbearbeiter an.
Wählen Sie auf dem Home-Dashboard Security » Key Management aus.
Wählen Sie den Schlüsselring aus, der Ihrem GCS-Bucket zugewiesen ist.
Klicken Sie oben rechts auf SHOW INFO PANEL. Der Informationsbereich für den Schlüsselring wird erweitert.
Klicken Sie auf die Schaltfläche ADD PRINCIPAL.
Suchen Sie im Feld New principals nach dem Namen des Dienstkontos aus der DESCRIBEINTEGRATION Ausgabe in Schritt 2: Das Cloud Storage-Dienstkonto für Ihr Snowflake-Konto abrufen (unter diesem Thema).
Wählen Sie in der Dropdown-Liste Select a role die Rolle
Cloud KMS CrytoKey Encryptor/Decryptoraus.Klicken Sie auf die Schaltfläche Save. Der Name des Dienstkontos wird der Dropdown-Liste Cloud KMS CrytoKey Encryptor/Decryptor im Informationsbereich hinzugefügt.
Bemerkung
Sie können die Funktion SYSTEM$VALIDATE_STORAGE_INTEGRATION verwenden, um die Konfiguration für Ihre Speicherintegration zu überprüfen.
Configure automation using GCS Pub/Sub¶
Voraussetzungen¶
In den Anweisungen unter diesem Thema wird davon ausgegangen, dass die folgenden Elemente erstellt und konfiguriert wurden:
- GCP-Konto:
Pub/Sub topic that receives event messages from the GCS bucket. For more information, see Create the Pub/Sub topic (in this topic).
Subscription that receives event messages from the Pub/Sub topic. For more information, see Create the Pub/Sub subscription (in this topic).
Eine Anleitung dazu finden Sie unter Pub/Sub-Dokumentation.
- Snowflake:
Zieltabelle der Snowflake-Datenbank, in die Ihre Daten geladen werden.
Create the Pub/Sub topic¶
Erstellen Sie ein Pub/Sub-Thema mit Cloud Shell oder Cloud SDK.
Führen Sie den folgenden Befehl aus, um das Thema zu erstellen und zu aktivieren, damit es im angegebenen GCS-Bucket auf Aktivitäten wartet:
Wobei:
<Thema>ist der Name für das Thema.<Bucket-Name>ist der Name Ihres GCS-Buckets.
Wenn das Thema bereits vorhanden ist, wird es vom Befehl verwendet. Andernfalls wird ein neues Thema erstellt.
Weitere Informationen finden Sie unter Verwenden von Pub/Sub-Benachrichtigungen für Cloudspeicher in der Pub/Sub-Dokumentation.
Create the Pub/Sub subscription¶
Erstellen Sie ein Abonnement mit Pull-Bereitstellung für das Pub/Sub-Thema über die Cloud Console, das Befehlszeilentool gcloud oder die Cloud Pub/Sub-API. Anweisungen finden Sie unter Verwalten von Themen und Abonnements in der Pub/Sub-Dokumentation.
Bemerkung
Von Snowflake werden nur Pub/Sub-Abonnements unterstützt, die die Standard-Pull-Bereitstellung verwenden. Push-Bereitstellung wird nicht unterstützt.
Retrieve the Pub/Sub subscription ID¶
Die Pub/Sub-Themenabonnement-ID wird in dieser Anleitung verwendet, um Snowflake den Zugriff auf Ereignismeldungen zu ermöglichen.
Melden Sie sich bei der Google Cloud Platform Console als Projekteditor an.
Wählen Sie im Startseiten-Dashboard die Option Big Data » Pub/Sub » Subscriptions aus.
Kopieren Sie die ID in die Spalte Subscription ID des Themenabonnements.
Step 1: Create a notification integration in Snowflake¶
Erstellen Sie eine Benachrichtigungsintegration mit dem Befehl CREATE NOTIFICATION INTEGRATION.
Die Benachrichtigungsintegration verweist auf Ihr Pub/Sub-Abonnement. Snowflake verknüpft die Benachrichtigungsintegration mit einem GCS-Dienstkonto, das für Ihr Konto erstellt wurde. Snowflake erstellt ein einziges Dienstkonto, auf das von allen GCS-Speicherintegrationen in Ihrem Snowflake-Konto verwiesen wird.
Bemerkung
Dieser SQL-Befehl kann nur von Kontoadministratoren (Benutzer mit der Rolle ACCOUNTADMIN) oder von Rollen mit der globalen Berechtigung CREATE INTEGRATION ausgeführt werden.
Das GCS-Dienstkonto für Benachrichtigungsintegrationen unterscheidet sich von dem Dienstkonto, das für Speicherintegrationen erstellt wird.
Eine einzelne Benachrichtigungsintegration unterstützt genau ein Google Cloud Pub/Sub-Abonnement. Wenn mehrere Benachrichtigungsintegrationen auf dasselbe Pub/Sub-Abonnement verweisen, kann dies zu fehlenden Daten in den Zieltabellen führen, da Ereignisbenachrichtigungen zwischen Benachrichtigungsintegrationen aufgeteilt werden.
Wobei:
integration_nameist der Name der neuen Integration.subscription_idis the subscription name you recorded in Retrieve the Pub/Sub subscription ID.
Beispiel:
Step 2: Grant Snowflake access to the Pub/Sub subscription¶
Führen Sie den Befehl DESCRIBE INTEGRATION aus, um die Snowflake-Dienstkonto-ID abzurufen:
Wobei:
integration_nameist der Name der Integration, die Sie in Schritt 1: Benachrichtigungsintegration in Snowflake erstellen erstellt haben.
Beispiel:
Notieren Sie den Namen des Dienstkontos in der Spalte GCP_PUBSUB_SERVICE_ACCOUNT, die das folgende Format hat:
Melden Sie sich bei der Google Cloud Platform Console als Projekteditor an.
Wählen Sie im Startseiten-Dashboard die Option Big Data » Pub/Sub » Subscriptions aus.
Wählen Sie das Abonnement aus, das für den Zugriff konfiguriert werden soll.
Klicken Sie oben rechts auf SHOW INFO PANEL. Der Informationsbereich für das Abonnement wird erweitert.
Klicken Sie auf die Schaltfläche ADD PRINCIPAL.
Suchen Sie im Feld New principals nach dem Dienstkontonamen, den Sie sich in Schritt 2 notiert haben.
Wählen Sie in der Dropdown-Liste Select a role die Option Pub/Sub Subscriber aus.
Klicken Sie auf die Schaltfläche Save. Der Name des Dienstkontos wird der Dropdown-Liste Pub/Sub Subscriber im Informationsbereich hinzugefügt.
Navigieren Sie zur Seite Dashboard in der Cloud Console, und wählen Sie in der Dropdown-Liste Ihr Projekt aus.
Klicken Sie auf die Schaltfläche ADD PEOPLE TO THIS PROJECT.
Fügen Sie den Namen des Dienstkontos hinzu, den Sie sich notiert haben.
Wählen Sie in der Dropdown-Liste Select a role die Option Monitoring Viewer aus.
Klicken Sie auf die Schaltfläche Save. Der Name des Dienstkontos wird der Rolle Monitoring Viewer hinzugefügt.
Step 3: Create a stage with an included directory table¶
Erstellen Sie mit dem Befehl CREATE STAGE einen externen Stagingbereich, der auf Ihren GCS-Bucket verweist. Snowflake liest Ihre Staging-Datendateien in die Metadaten der externen Tabelle. Alternativ können Sie einen vorhandenen externen Stagingbereich verwenden.
Bemerkung
To configure secure access to the cloud storage location, see Configure secure access to Cloud Storage (in this topic).
Um in der CREATE STAGE-Anweisung auf eine Speicherintegration zu verweisen, muss die Rolle über USAGE-Berechtigung für das Speicherintegrationsobjekt verfügen.
Wobei:
Parameter der Verzeichnistabelle (directoryTable)¶
ENABLE = TRUE | FALSEGibt an, ob eine Verzeichnistabelle zum Stagingbereich hinzugefügt werden soll. Wenn der Wert TRUE ist, wird beim Erstellen des Stagingbereichs auch eine Verzeichnistabelle erstellt.
Standard:
FALSEAUTO_REFRESH = TRUE | FALSEGibt an, ob Snowflake das Auslösen einer automatischen Aktualisierung der Metadaten der Verzeichnistabelle aktivieren soll, wenn in dem benannten externen Stagingbereich, der in dem URL-Wert angegebenen ist, neue oder aktualisierte Datendateien verfügbar sind.
TRUESnowflake ermöglicht das Auslösen automatischer Aktualisierungen von Metadaten externer Tabellen.
FALSESnowflake ermöglicht nicht das Auslösen automatischer Aktualisierungen von Metadaten externer Tabellen. Sie müssen die Metadaten der Verzeichnistabelle manuell mit ALTER STAGE … REFRESH aktualisieren, um die Metadaten mit der aktuellen Liste der Dateien im Stagingbereichspfad zu synchronisieren.
Standard:
FALSENOTIFICATION_INTEGRATION = '<Name_der_Benachrichtigungsintegration>'Gibt den Namen der Benachrichtigungsintegration an, die zur automatischen Aktualisierung der Metadaten der Verzeichnistabelle unter Verwendung von Pub/Sub-Benachrichtigungen verwendet wird. Eine Benachrichtigungsintegration ist ein Snowflake-Objekt, das als Schnittstelle zwischen Snowflake und Cloud-Meldungswarteschlangendiensten von Drittanbietern dient.
Der Integrationsname muss komplett in Großbuchstaben angegeben werden.
Im folgenden Beispiel wird im aktiven Schema der Benutzersitzung ein Stagingbereich mit dem Namen mystage erstellt. Die Cloudspeicher-URL enthält den Pfad files. Der Stagingbereich verweist auf eine Speicherintegration mit dem Namen my_storage_int.
Der NOTIFICATION_INTEGRATION-Parameter verweist auf die my_notification_int-Integration, die Sie in Schritt 1: Benachrichtigungsintegration in Snowflake erstellen erstellt haben.
Bemerkung
Der Speicherort im URL-Wert muss mit einem Schrägstrich (
/) enden.Der Integrationsname muss komplett in Großbuchstaben angegeben werden.
Wenn neue oder aktualisierte Datendateien zum S3-Bucket hinzugefügt werden, weist die Ereignisbenachrichtigung Snowflake an, sie in die Metadaten der externen Tabelle zu scannen.
Step 4: Manually refresh the directory table metadata¶
Aktualisieren Sie die Metadaten in einer Verzeichnistabelle manuell mit dem Befehl ALTER STAGE.
Syntax¶
Wobei:
REFRESHGreift auf die Staging-Datendateien zu, auf die in der Definition der Verzeichnistabelle verwiesen wird, und aktualisiert die Tabellenmetadaten:
Neue Dateien im Pfad werden zu den Tabellenmetadaten hinzugefügt.
Änderungen an Dateien im Pfad werden in den Tabellenmetadaten aktualisiert.
Dateien, die sich nicht mehr im Pfad befinden, werden aus den Tabellenmetadaten entfernt.
Derzeit muss dieser Befehl jedes Mal ausgeführt werden, wenn Dateien zum Stagingbereich hinzugefügt, aktualisiert oder gelöscht werden. Dieser Schritt synchronisiert die Metadaten mit dem neuesten Satz zugeordneter Dateien im Stagingbereich und Pfad in der externen Tabellendefinition.
SUBPATH = '<relative-path>'Geben Sie optional einen relativen Pfad an, um die Metadaten für eine bestimmte Teilmenge der Datendateien zu aktualisieren.
Beispiele¶
Aktualisieren Sie manuell die Metadaten der Verzeichnistabelle eines Stagingbereichs namens mystage:
Wichtig
Wenn dieser Schritt nicht mindestens einmal nach der Erstellung der Verzeichnistabelle erfolgreich abgeschlossen wird, liefert die Abfrage der Verzeichnistabelle keine Ergebnisse, bis ein Benachrichtigungsereignis die automatische Aktualisierung der Verzeichnistabellen-Metadaten zum ersten Mal auslöst.
Step 5: Configure security¶
Erteilen Sie mit GRANT <Berechtigungen> … TO ROLE für jede zusätzliche Rolle, die zum Abfragen der Verzeichnistabelle verwendet wird, ausreichende Zugriffssteuerungsrechte für die verschiedenen Objekte (d. h. Datenbanken, Schemas, und Stagingbereiche):
Objekt |
Berechtigung |
Anmerkungen |
|---|---|---|
Datenbank |
USAGE |
|
Schema |
USAGE |
|
Benannter Stagingbereich |
USAGE , READ |
|
Benanntes Dateiformat |
USAGE |
Optional; nur erforderlich, wenn der von Ihnen erstellte Stagingbereich auf ein benanntes Dateiformat verweist. |