Build a data processing pipeline using a directory table¶
Bauen Sie eine Datenverarbeitungspipeline auf, indem Sie eine Verzeichnistabelle, die Metadaten auf Dateiebene in einem Stagingbereich verfolgt und speichert, mit anderen Snowflake-Objekten wie Streams und Aufgaben kombinieren.
Ein Stream erfasst Änderungen, die mit Data Manipulation Language (DML) an einer Verzeichnistabelle, einer Tabelle, einer externen Tabelle oder an den zugrunde liegenden Tabellen einer Ansicht vorgenommen wurden. Eine Aufgabe führt eine einzelne Aktion aus, die ein SQL-Befehl oder eine umfangreiche benutzerdefinierte Funktion (UDF) sein kann. Sie können eine Aufgabe so planen, dass sie in regelmäßigen Abständen ausgeführt wird, oder eine Aufgabe bei Bedarf ausführen.
Beispiel: Erstellen einer einfachen Pipeline zur Verarbeitung von PDFs¶
In diesem Beispiel wird eine einfache Datenverarbeitungs-Pipeline erstellt, die folgende Aufgaben ausführt:
Erkennen von PDF-Dateien, die zu einem Stagingbereich hinzugefügt wurden
Abrufen der Daten aus den Dateien
Einfügen der Daten in eine Snowflake-Tabelle
Die Pipeline verwendet einen Stream, um Änderungen an einer Verzeichnistabelle im Stagingbereich zu erkennen, und eine Aufgabe, die eine UDF ausführt, um Daten aus den Dateien zu extrahieren.
In der folgende Abbildung ist zusammengefasst, wie die Beispiel-Pipeline funktioniert:
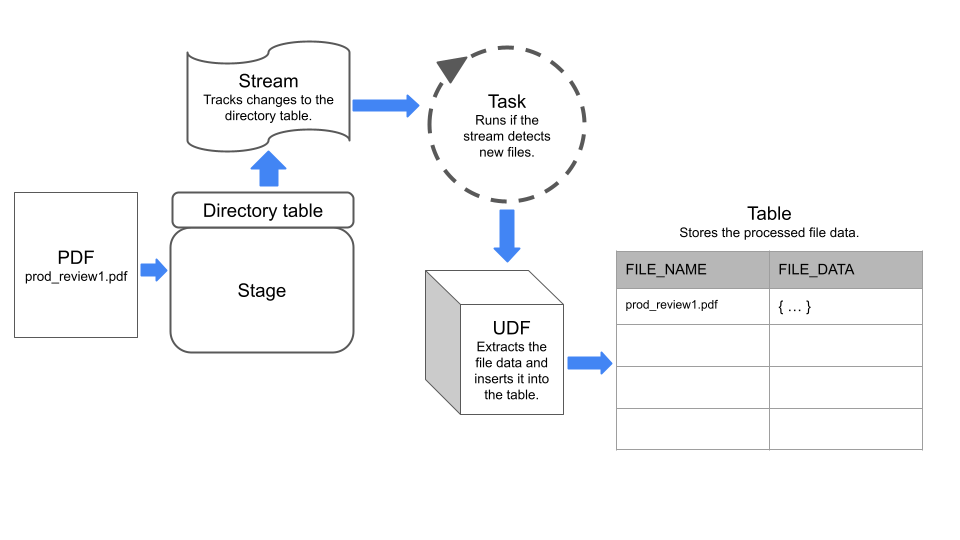
Schritt 1: Stagingbereich mit einer aktivierten Verzeichnistabelle erstellen¶
Erstellen Sie einen internen Stagingbereich, der eine aktivierte Verzeichnistabelle enthält. In der Beispielanweisung wird für ENCRYPTION der Typ SNOWFLAKE_SSE eingestellt, um den Zugriff auf unstrukturierten Daten im Stagingbereich zu aktivieren.
Schritt 2: Stream auf der Verzeichnistabelle erstellen¶
Erstellen Sie einen Stream auf der Verzeichnistabelle, indem Sie den Stagingbereich angeben, zu dem die Verzeichnistabelle gehört. Der Stream verfolgt die Änderungen an der Verzeichnistabelle. In Schritt 5 dieses Beispiels wird dieser Stream dann verwendet, um eine Aufgabe zu konstruieren.
Schritt 3: Benutzerdefinierte Funktion zum Parsen der PDFs erstellen¶
Erstellen Sie eine UDF, die Daten aus PDF-Dateien extrahiert. Die Aufgabe, die Sie in einem späteren Schritt erstellen, wird diese UDF aufrufen, um neu hinzugefügte Dateien im Stagingbereich zu verarbeiten.
Die folgende Beispielanweisung erstellt eine Python UDF mit dem Namen PDF_PARSE, die PDF-Dateien mit Produktprüfungsdaten verarbeitet. Die UDF extrahiert Formularfelddaten unter Verwendung der PyPDF2-Bibliothek. Sie gibt ein Wörterbuch zurück, das die Formularnamen und -werte als Schlüssel-Wert-Paare enthält.
Bemerkung
Die UDF liest dynamisch spezifizierte Dateien mithilfe der Klasse SnowflakeFile aus. Weitere Informationen zu SnowflakeFile finden Sie unter Lesen einer mit SnowflakeFile dynamisch spezifizierten Datei.
Schritt 4: Tabelle zum Speichern der Dateiinhalte erstellen¶
Als Nächstes erstellen Sie eine Tabelle, in der in jeder Zeile in den Spalten file_name und file_data Informationen zu einer Datei des Stagingbereichs gespeichert werden. Die Aufgabe, die Sie in einem späteren Schritt erstellen, lädt die Daten in diese Tabelle.
Schritt 5: Aufgabe erstellen¶
Erstellen Sie eine geplante Aufgabe, die den Stream auf neue Dateien im Stagingbereich überprüft und die Daten in diesen Dateien in die Tabelle prod_reviews einfügt.
Die folgende Anweisung erstellt eine geplante Aufgabe unter Verwendung des zuvor erstellten Streams. Die Aufgabe verwendet die Funktion SYSTEM$STREAM_HAS_DATA, um zu prüfen, ob der Stream CDC-Datensätze (Change Data Capture, Datenänderungserfassung) enthält.
Schritt 6: Aufgabe zum Testen der Pipeline ausführen¶
Um zu prüfen, ob die Pipeline funktioniert, können Sie dem Stagingbereich Dateien hinzufügen, die Aufgabe manuell ausführen und dann die Tabelle product_reviews abfragen.
Fügen Sie zunächst einige PDF-Dateien zum Stagingbereich my_pdf_stage hinzu, und aktualisieren Sie dann den Stagingbereich.
Bemerkung
Dieses Beispiel verwendet PUT-Befehle, die Sie nicht von einem Arbeitsblatt in der Snowflake-Weboberfläche aus ausführen können. Weitere Informationen zum Hochladen von Dateien mit Snowsight finden Sie unter Dateien in einen benannten internen Stagingbereich hochladen.
Sie können den Stream abfragen, um zu überprüfen, ob dieser die beiden PDF-Dateien erfasst hat, die wir dem Stagingbereich hinzugefügt hatten.
Führen Sie nun die Aufgabe aus, um die PDF-Dateien zu verarbeiten und die Tabelle product_reviews zu aktualisieren.
Fragen Sie die Tabelle product_reviews ab, um zu prüfen, ob die Aufgabe für jede PDF-Datei eine Zeile hinzugefügt hat.
Schließlich können Sie eine Ansicht erstellen, die die Objekte in der Spalte FILE_DATA in einzelne Spalten aufteilt. Sie können dann die Ansicht abfragen, um die Dateiinhalte zu analysieren und weiterzuverwenden.