Automatisieren von Snowpipe für Amazon S3¶
Unter diesem Thema finden Sie Anleitungen zum automatischen Auslösen des Ladens von Snowpipe-Daten aus externen Stagingbereichen auf S3 mit Amazon SQS (Simple Queue Service)-Benachrichtigungen für einen S3-Bucket.
Snowflake empfiehlt, nur unterstützte Ereignisse für Snowpipe zu senden, um Kosten, Ereignisrauschen und Latenz zu reduzieren.
Unterstützung von Cloudplattformen¶
Das Auslösen automatisierter Snowpipe-Datenladevorgänge unter Verwendung von S3-Ereignismeldungen wird von Snowflake-Konten unterstützt, die auf unterstützten Cloudplattformen gehostet werden.
Netzwerkdatenverkehr¶
Hinweis für Kunden von Virtual Private Snowflake (VPS) und AWS PrivateLink:
Die Automatisierung von Snowpipe mithilfe von Amazon SQS-Nachrichten funktioniert gut. Doch obwohl AWS-Cloudspeicher innerhalb einer VPC (einschließlich VPS) mit seinen eigenen Messaging-Diensten (Amazon SQS, Amazon Simple Notification Service) kommunizieren kann, fließt dieser Datenverkehr zwischen Servern im sicheren Netzwerk von Amazon außerhalb der VPC. Daher ist dieser Datenverkehr nicht durch die VPC geschützt.
Konfigurieren des sicheren Zugriffs auf Cloudspeicher¶
Bemerkung
Wenn Sie bereits den sicheren Zugriff auf den S3-Bucket konfiguriert haben, in dem Ihre Datendateien gespeichert sind, können Sie diesen Abschnitt überspringen.
In diesem Abschnitt wird beschrieben, wie Sie mit Speicherintegrationen dafür sorgen können, dass Snowflake Daten aus einem Amazon S3-Bucket lesen und in einen S3-Bucket schreiben kann, auf den in einem externen (d. h. S3) Stagingbereich verwiesen wird. Integrationen sind benannte First-Class-Snowflake-Objekte, bei denen keine expliziten Cloudanbieter-Anmeldeinformationen wie geheime Schlüssel oder Zugriffstoken übergeben werden müssen. Integrationsobjekte speichern eine AWS Identity and Access Management (IAM)-Benutzer-ID. Ein Administrator in Ihrem Unternehmen gewährt die Integrationsberechtigungen für IAM-Benutzer im AWS-Konto.
Eine Integration kann auch Buckets (und optionale Pfade) auflisten, um so die Speicherorte zu beschränken, die von Benutzern beim Erstellen der von der Integration verwendeten externen Stagingbereiche angeben werden können.
Bemerkung
Zum Ausführen der Anweisungen unter diesem Thema sind Berechtigungen in AWS zum Erstellen und Verwalten von IAM-Richtlinien und -Rollen erforderlich. Wenn Sie kein AWS-Administrator sind, bitten Sie Ihren AWS-Administrator, diese Aufgaben auszuführen.
Beachten Sie, dass derzeit der Zugriff auf S3-Speicher in Regionen für Regierungsbehörden über eine Speicherintegration auf Snowflake-Konten beschränkt ist, die auf AWS in derselben Region gehostet werden. Der Zugriff auf Ihren S3-Speicher von einem Konto, das außerhalb der Region der Regierungsbehörden gehostet wird, wird unter Verwendung direkter Anmeldeinformationen aber unterstützt.
Die folgende Abbildung zeigt den Integrationsablauf für einen S3-Stagingbereich:
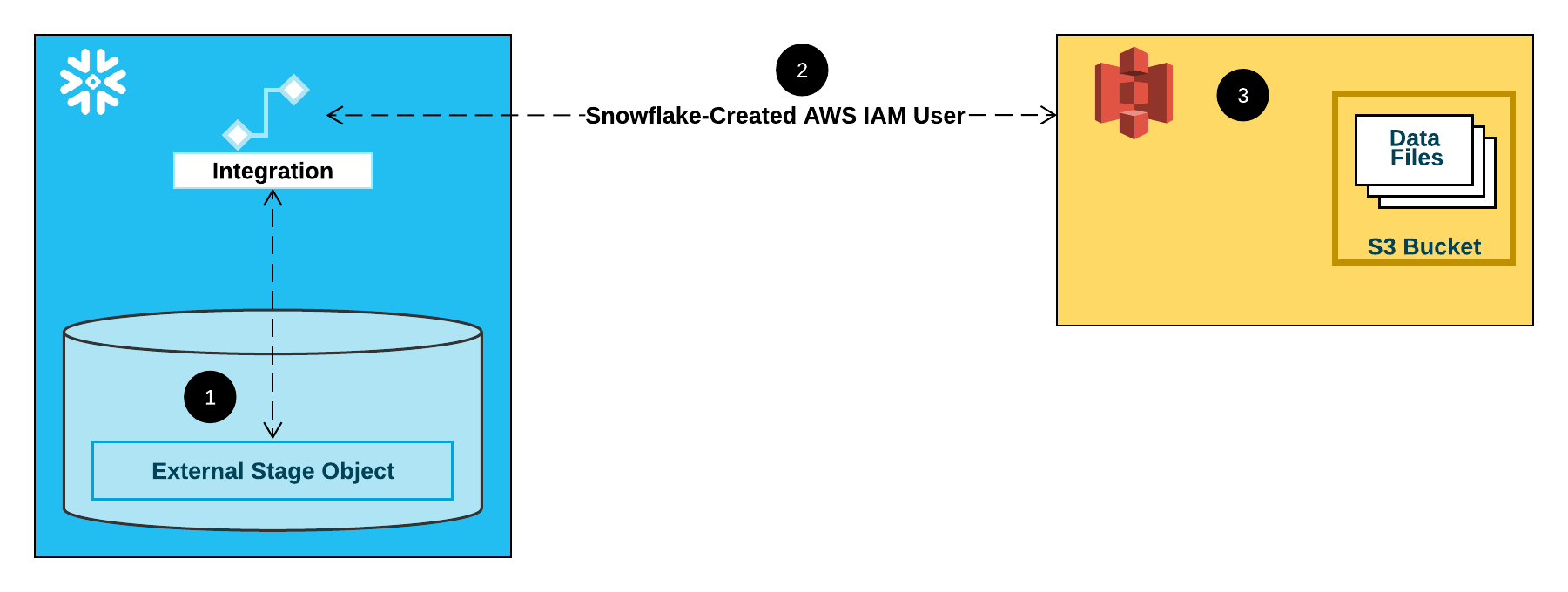
Ein externer (d. h. S3) Stagingbereich verweist in seiner Definition auf ein Speicherintegrationsobjekt.
Snowflake ordnet die Speicherintegration automatisch einem für Ihr Konto erstellten S3-IAM-Benutzer zu. Snowflake erstellt einen einzelnen IAM-Benutzer, auf den von allen S3-Speicherintegrationen in Ihrem Snowflake-Konto verwiesen wird.
Ein AWS-Administrator in Ihrem Unternehmen gewährt dem IAM-Benutzer die Berechtigung, auf den in der Stagingbereichsdefinition angegebenen Bucket zuzugreifen. Beachten Sie, dass viele externe Stagingbereichsobjekte auf unterschiedliche Buckets und Pfade verweisen und dieselbe Speicherintegration zur Authentifizierung verwenden können.
Wenn ein Benutzer Daten aus einem oder in einen Stagingbereich lädt, überprüft Snowflake erst die Berechtigungen, die dem IAM-Benutzer für den Bucket erteilt wurden, bevor Zugriff gewährt oder verweigert wird.
Bemerkung
Diese Option wird dringend empfohlen, um beim Zugriff auf Cloudspeicher keine IAM-Anmeldeinformationen angeben zu müssen. Weitere Speicherzugriffsoptionen finden Sie unter Konfigurieren des sicheren Zugriffs auf Amazon S3.
Schritt 1: Zugriffsberechtigungen für den S3-Bucket konfigurieren¶
Anforderungen an die AWS-Zugriffssteuerung¶
Snowflake benötigt die folgenden Berechtigungen für einen S3-Bucket und -Ordner, um auf Dateien im Ordner (und in Unterordnern) zugreifen zu können:
s3:GetBucketLocations3:GetObjects3:GetObjectVersions3:ListBucket
Als Best Practice empfiehlt Snowflake für den Zugriff von Snowflake auf den S3-Bucket die Erstellung einer IAM-Richtlinie. Sie können dann die Richtlinie an die Rolle anhängen und die von AWS für die Rolle generierten Sicherheitsanmeldeinformationen verwenden, um auf Dateien im Bucket zuzugreifen.
Erstellen einer IAM-Richtlinie¶
Die folgende schrittweise Anleitung beschreibt, wie Sie über Ihre AWS-Managementkonsole die Zugriffsberechtigungen für Snowflake für den Zugriff auf einen S3-Bucket konfigurieren.
Anmelden bei der AWS-Managementkonsole.
Suchen Sie auf dem Home-Dashboard nach IAM, und wählen Sie es aus.
Wählen Sie im linken Navigationsbereich Account settings aus.
Unter Security Token Service (STS) in der Liste Endpoints finden Sie die Snowflake-Region, in der sich Ihr Konto befindet. Wenn STS status inaktiv ist, stellen Sie den Umschalter auf Active.
Wählen Sie im linken Navigationsbereich Policies aus.
Wählen Sie Create Policy aus.
Wählen Sie unter Policy editor die Option JSON aus.
Fügen Sie ein Richtliniendokument hinzu, das Snowflake den Zugriff auf den S3-Bucket und -Ordner ermöglicht.
Die folgende Richtlinie (im JSON-Format) gibt Snowflake die erforderlichen Berechtigungen zum Laden oder Entladen von Daten über einen einzigen Bucket- und Ordnerpfad.
Kopieren Sie den Text, und fügen Sie ihn in den Richtlinieneditor ein:
Bemerkung
Stellen Sie sicher, dass
bucketundprefixdurch Ihren tatsächlichen Bucket-Namen bzw. Ihr Ordnerpfad-Präfix ersetzt wurden.Die Amazon Resource Names (ARN) für Buckets in Regionen für Regierungsbehörden haben das Präfix
arn:aws-us-gov:s3:::.
Bemerkung
Durch Setzen der Bedingung
"s3:prefix":auf entweder["*"]oder["<Pfad>/*"]wird Zugriff auf alle Präfixe im angegebenen Bucket bzw. Pfad im Bucket gewährt.Beachten Sie, dass AWS-Richtlinien eine Vielzahl von unterschiedlichen Sicherheitsanwendungsfällen unterstützen.
Wählen Sie Next aus.
Geben Sie unter Policy name den Namen der Richtlinie (z. B.
snowflake_access) und unter Description eine optionale Beschreibung ein.Wählen Sie Create policy aus.
Schritt 2: Diie IAM-Rolle in AWS erstellen¶
Um die Zugriffsberechtigungen für Snowflake in der AWS-Managementkonsole zu konfigurieren, gehen Sie wie folgt vor:
Wählen Sie im linken Navigationsbereich des Identity and Access Management (IAM)-Dashboards die Option Roles aus.
Wählen Sie Create role aus.
Wählen Sie AWS account als Typ der vertrauenswürdigen Entität aus.
Wählen Sie Another AWS account aus.
Geben Sie im Feld Account ID vorläufig Ihre eigene AWS-Konto-ID ein. Später werden Sie die Vertrauensstellung ändern und Snowflake Zugriff gewähren.
Wählen Sie die Option Require external ID aus. Eine externe ID wird verwendet, um einer dritten Partei wie Snowflake Zugriff auf Ihre AWS-Ressourcen (wie S3-Buckets) zu gewähren.
Geben Sie eine Platzhalter-ID ein, z. B.
0000. In einem späteren Schritt werden Sie die Vertrauensstellung für Ihre IAM-Rolle ändern und die externe ID Ihrer Speicherintegration angeben.Wählen Sie Next aus.
Wählen Sie die Richtlinie aus, die Sie in Schritt 1: Zugriffsberechtigungen für den S3-Bucket konfigurieren (unter diesem Thema) erstellt haben.
Wählen Sie Next aus.
Geben Sie einen Namen und eine Beschreibung für die Rolle ein, und wählen Sie Create role aus.
Sie haben nun eine IAM-Richtlinie für einen Bucket erstellt, eine IAM-Rolle erstellt und die Richtlinie an die Rolle angehängt.
Notieren Sie den Wert von Role ARN, der auf der Übersichtsseite der Rolle angegeben ist. Im nächsten Schritt erstellen Sie eine Snowflake-Integration, die auf diese Rolle verweist.
Bemerkung
Snowflake speichert die temporären Anmeldedaten für einen Zeitraum, der die 60-minütige Ablaufzeit nicht überschreiten darf. Wenn Sie den Zugriff von Snowflake widerrufen, sind Benutzer vor Ablauf des Cache möglicherweise in der Lage, die am Cloudspeicherort befindlichen Dateien aufzulisten und auf die Daten zuzugreifen.
Schritt 3: Eine Cloud Storage-Integration in Snowflake erstellen¶
Erstellen Sie mit dem Befehl CREATE STORAGE INTEGRATION eine Speicherintegration. Eine Speicherintegration ist ein Snowflake-Objekt, das einen generierten Benutzer für das Identitäts- und Zugriffsmanagement (IAM) für Ihren S3-Cloud-Speicher speichert, zusammen mit einem optionalen Satz von erlaubten oder gesperrten Speicherorten (d. h. Buckets). Cloudanbieter-Administratoren in Ihrer Organisation erteilen dem generierten Benutzer Berechtigungen für die Speicherorte. Dank dieser Option müssen Benutzer beim Erstellen von Stagingbereichen oder beim Laden von Daten keine Anmeldeinformationen eingeben.
Eine einzige Speicherintegration kann mehrere externe (d. h. S3) Stagingbereiche unterstützen. Die URL in der Stagingbereichsdefinition muss mit den für den Parameter STORAGE_ALLOWED_LOCATIONS angegebenen S3-Buckets (und optionalen Pfaden) übereinstimmen.
Bemerkung
Dieser SQL-Befehl kann nur von Kontoadministratoren (Benutzer mit der Rolle ACCOUNTADMIN) oder von Rollen mit der globalen Berechtigung CREATE INTEGRATION ausgeführt werden.
Wobei:
integration_nameist der Name der neuen Integration.iam_roleist der Amazon Resource Name (ARN) der Rolle, die Sie in Schritt 2: Die IAM-Rolle in AWS erstellen (unter diesem Thema) erstellt haben.protocolist eine der folgenden Optionen:s3bezieht sich auf S3-Speicher in öffentlichen AWS-Regionen außerhalb Chinas.s3chinabezieht sich auf S3-Speicher in öffentlichen AWS-Regionen in China.s3govbezieht sich auf S3-Speicher in Regionen für Regierungsbehörden.
bucketist der Name eines S3-Buckets, in dem Ihre Datendateien gespeichert sind (z. B.mybucket). Die erforderlichen Parameter STORAGE_ALLOWED_LOCATIONS und STORAGE_BLOCKED_LOCATIONS beschränken bzw. blockieren den Zugriff auf diese Buckets, wenn Stagingbereiche, die auf diese Integration verweisen, erstellt oder geändert werden.pathist ein optionaler Pfad, mit dem Sie Objekte im Bucket genauer steuern können.
Das folgende Beispiel erstellt eine Integration, die den Zugriff auf alle Buckets im Konto erlaubt, aber den Zugriff auf die definierten sensitivedata-Ordner blockiert.
Zusätzliche externe Stagingbereiche, die diese Integration ebenfalls verwenden, können auf die zulässigen Buckets und Pfade verweisen:
Bemerkung
Optional können Sie den Parameter STORAGE_AWS_EXTERNAL_ID verwenden, um Ihre eigene externe ID anzugeben. Sie können diese Option wählen, um dieselbe externe ID für mehrere externe Volumes und/oder Speicherintegrationen zu verwenden.
Schritt 4: Den AWSIAM-Benutzer für Ihr Snowflake-Konto abrufen¶
Um den ARN des IAM-Benutzers abzurufen, der für Ihr Snowflake-Konto automatisch erstellt wurde, verwenden Sie den Befehl DESCRIBE INTEGRATION.
Wobei:
integration_nameist der Name der Integration, die Sie in Schritt 3: Cloud Storage-Integration in Snowflake erstellen (unter diesem Thema) erstellt haben.
Beispiel:
Notieren Sie sich die Werte der folgenden Eigenschaften:
Eigenschaft
Beschreibung
STORAGE_AWS_IAM_USER_ARNDer AWS-IAM-Benutzer, der für Ihr Snowflake-Konto erstellt wurde, in diesem Beispiel
arn:aws:iam::123456789001:user/abc1-b-self1234. Snowflake stellt genau einen IAM-Benutzer für Ihr gesamtes Snowflake-Konto bereit. Alle S3-Speicherintegrationen in Ihrem Konto verwenden diesen IAM-Benutzer.STORAGE_AWS_EXTERNAL_IDDie externe ID, die Snowflake verwendet, um eine Vertrauensstellung mit AWS einzurichten. Wenn Sie beim Erstellen der Speicherintegration keine externe ID (
STORAGE_AWS_EXTERNAL_ID) angegeben haben, generiert Snowflake eine ID, die Sie verwenden können.Diese Werte geben Sie im nächsten Abschnitt an.
Schritt 5: IAM-Benutzerberechtigungen für den Zugriff auf Bucket-Objekte erteilen¶
Die folgende schrittweise Anleitung beschreibt, wie Sie die IAM-Zugriffsberechtigungen für Snowflake über Ihre AWS Management Console so konfigurieren, dass Sie einen S3-Bucket zum Laden und Entladen von Daten verwenden können:
Melden Sie sich bei der AWS-Managementkonsole an.
Wählen Sie IAM aus.
Wählen Sie im linken Navigationsbereich Roles aus.
Wählen Sie die Rolle aus, die Sie in Schritt 2: Die IAM-Rolle in AWS erstellen (unter diesem Thema) erstellt haben.
Wählen Sie die Registerkarte Trust relationships aus.
Wählen Sie Edit trust policy aus.
Ändern Sie das Richtliniendokument mit den Ausgabewerten der DESCSTORAGEINTEGRATION, die Sie in Schritt 4: AWSIAM Benutzer für Ihr Snowflake-Konto abrufen (unter diesem Thema) erfasst haben.
Richtliniendokument für die IAM-Rolle
Wobei:
snowflake_user_arnist der von Ihnen notierte STORAGE_AWS_IAM_USER_ARN-Wert.snowflake_external_idist der von Ihnen notierte STORAGE_AWS_EXTERNAL_ID-Wert.In diesem Beispiel hat
snowflake_external_idden WertMYACCOUNT_SFCRole=2_a123456/s0aBCDEfGHIJklmNoPq=.Bemerkung
Wenn Sie aus Sicherheitsgründen eine neue Speicherintegration erstellen (oder eine bestehende Speicherintegration mit der CREATE OR REPLACE STORAGE INTEGRATION-Syntax neu erstellen) und dabei keine externe ID angeben, hat die neue Speicherintegration eine andere externe ID und kann daher die Vertrauensstellung nicht auflösen, es sei denn, Sie aktualisieren die Vertrauensrichtlinie.
Wählen Sie Update policy aus, um Ihre Änderungen zu speichern.
Bemerkung
Snowflake speichert die temporären Anmeldedaten für einen Zeitraum, der die 60-minütige Ablaufzeit nicht überschreiten darf. Wenn Sie den Zugriff von Snowflake widerrufen, sind Benutzer vor Ablauf des Cache möglicherweise in der Lage, Dateien auflisten und Daten vom Cloudspeicherort zu laden.
Bemerkung
Sie können die Funktion SYSTEM$VALIDATE_STORAGE_INTEGRATION verwenden, um die Konfiguration für Ihre Speicherintegration zu überprüfen.
Bestimmen der korrekten Option¶
Ermitteln Sie vor dem Fortfahren, ob für den Zielpfad (oder in AWS-Terminologie das „Präfix“) in dem S3-Bucket, in dem sich Ihre Datendateien befinden, eine S3-Ereignisbenachrichtigung vorhanden ist. AWS-Regeln verbieten das Erstellen widersprüchlicher Benachrichtigungen für denselben Pfad.
Folgende Optionen zum Automatisieren von Snowpipe mit Amazon SQS werden unterstützt:
Option 1: Neue S3-Ereignisbenachrichtigung: Erstellen Sie eine Ereignisbenachrichtigung für den Zielpfad in Ihrem S3-Bucket. Die Ereignisbenachrichtigung informiert Snowpipe über eine SQS-Warteschlange, wenn Dateien ladebereit sind.
Wichtig
Wenn für Ihren S3-Bucket eine widersprüchliche Ereignisbenachrichtigung vorliegt, verwenden Sie stattdessen Option 2.
Option 2: Bestehende Ereignisbenachrichtigung: Konfigurieren Sie Amazon Simple Notification Service (SNS) als Broadcaster, um Benachrichtigungen für einen bestimmten Pfad mit mehreren Endpunkten (oder „Abonnenten“, z. B. SQS-Warteschlangen oder AWS Lambda-Workloads) freizugeben, einschließlich der Snowflake SQS-Warteschlange zur Snowpipe-Automatisierung. Eine von SNS veröffentlichte S3-Ereignisbenachrichtigung informiert Snowpipe über eine SQS-Warteschlange, wenn Dateien ladebereit sind.
Bemerkung
Wir empfehlen diese Option, wenn Sie Replikation von Stagingbereichen, Pipes und des Ladeverlaufs verwenden möchten. Sie können auch von Option 1 zu Option 2 migrieren, nachdem Sie eine Replikations- oder Failover-Gruppe erstellt haben. Weitere Informationen dazu finden Sie unter Migration zu Amazon Simple Notification Service (SNS).
Option 3: Einrichten von Amazon EventBridge für das Automatisieren von Snowpipe: Ähnlich wie bei Option 2 können Sie auch Amazon EventBridge für S3-Buckets aktivieren und Regeln zum Senden von Benachrichtigungen an SNS-Themen erstellen.
Option 1: Erstellen einer neuen S3-Ereignisbenachrichtigung zum Automatisieren von Snowpipe¶
In diesem Abschnitt wird die am häufigsten verwendete Option zum automatischen Auslösen von Snowpipe-Datenladevorgängen mithilfe von Amazon SQS (Simple Queue Service)-Benachrichtigungen für einen S3-Bucket beschrieben. In den Schritten wird erläutert, wie Sie eine Ereignisbenachrichtigung für den Zielpfad (oder in AWS-Terminologie das „Präfix“) in dem S3-Bucket erstellen, in dem Ihre Datendateien gespeichert sind.
Wichtig
Wenn für Ihren S3-Bucket eine Benachrichtigung über widersprüchliche Ereignisse vorhanden ist, verwenden Sie stattdessen Option 2: Konfigurieren von Amazon SNS zum Automatisieren der Snowpipe mithilfe von SQS-Benachrichtigungen (unter diesem Thema). AWS-Regeln verbieten das Erstellen widersprüchlicher Benachrichtigungen für denselben Zielpfad.
Die folgende Abbildung veranschaulicht den Prozessablauf der automatischen Erfassung mit Snowpipe:
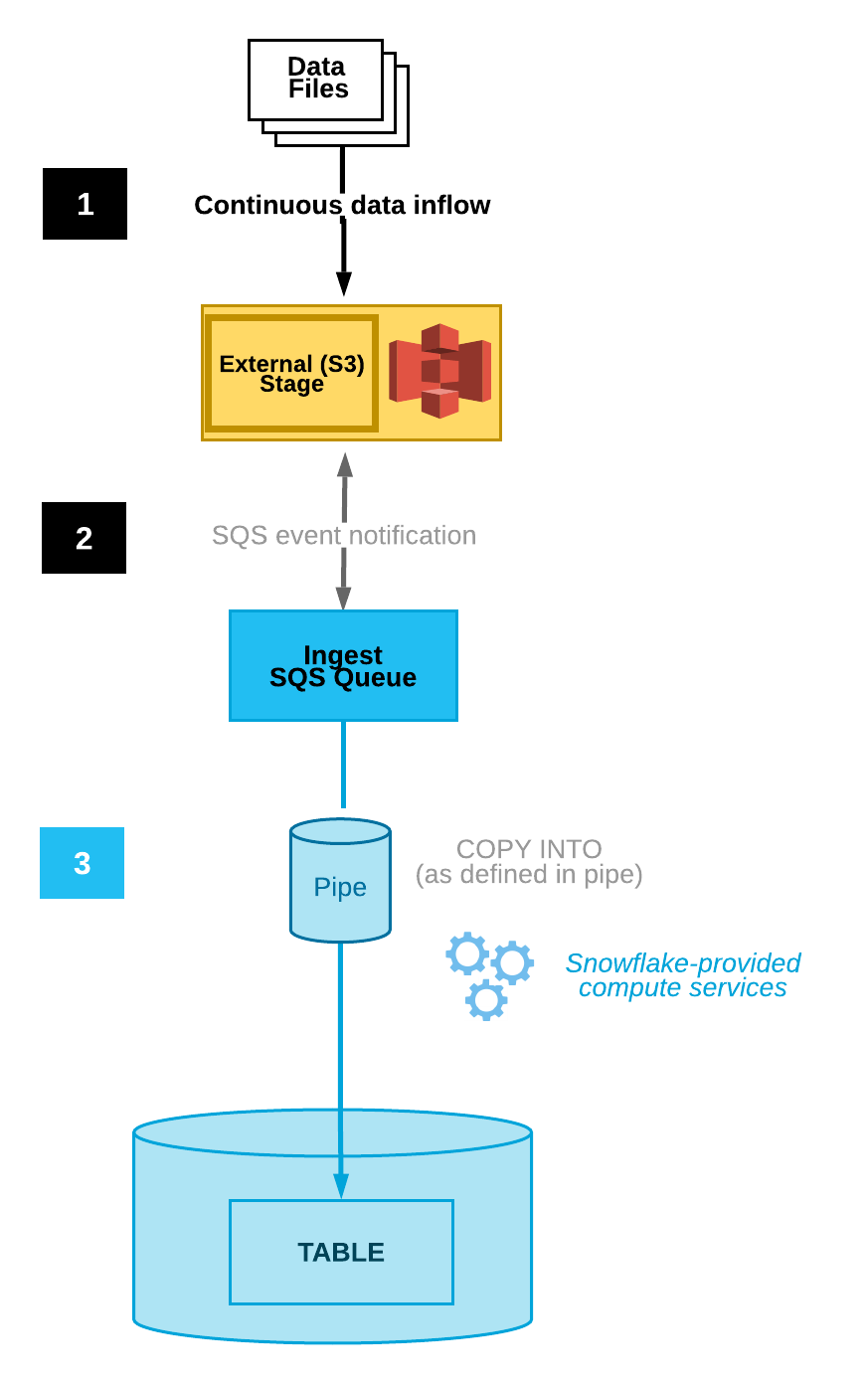
Datendateien werden in einen Stagingbereich geladen.
Eine S3-Ereignisbenachrichtigung informiert Snowpipe über eine SQS-Warteschlange, dass Dateien ladebereit sind. Snowpipe kopiert die Dateien in eine Warteschlange.
Ein von Snowflake bereitgestelltes virtuelles Warehouse lädt Daten aus den Warteschlangendateien in die Zieltabelle, basierend auf den in der angegebenen Pipe definierten Parametern.
Bemerkung
Die Anweisungen unter diesem Thema setzen voraus, dass in der Snowflake-Datenbank, in die Ihre Daten geladen werden, bereits eine Zieltabelle vorhanden ist.
Schritt 1: Stagingbereich erstellen (falls erforderlich)¶
Erstellen Sie mit dem Befehl CREATE STAGE einen externen Stagingbereich, der auf Ihren S3-Bucket verweist. Snowpipe ruft Ihre Datendateien aus dem Stagingbereich ab und stellt sie vorübergehend in die Warteschlange, bevor sie in die Zieltabelle geladen werden. Alternativ können Sie einen vorhandenen externen Stagingbereich verwenden.
Bemerkung
Informationen zum Konfigurieren des sicheren Zugriffs auf den Speicherort in der Cloud finden Sie unter Konfigurieren des sicheren Zugriffs auf Cloudspeicher (unter diesem Thema).
Um in der CREATE STAGE-Anweisung auf eine Speicherintegration zu verweisen, muss die Rolle über USAGE-Berechtigung für das Speicherintegrationsobjekt verfügen.
Im folgenden Beispiel wird im aktiven Schema der Benutzersitzung ein Stagingbereich mit dem Namen mystage erstellt. Die Cloudspeicher-URL enthält den Pfad files. Der Stagingbereich verweist auf eine Speicherintegration mit dem Namen my_storage_int:
Schritt 2: Pipe mit aktivierter automatischer Datenaufnahme erstellen¶
Erstellen Sie mit dem Befehl CREATE PIPE eine Pipe. Die Pipe definiert die COPY INTO <Tabelle>-Anweisung, mit der Snowpipe Daten aus der Erfassungswarteschlange in die Zieltabelle lädt.
Im folgenden Beispiel wird im aktiven Schema der Benutzersitzung eine Pipe mit dem Namen mypipe erstellt. Die Pipe lädt die Daten aus den im Stagingbereich mystage bereitgestellten Dateien in die Tabelle mytable:
Der Parameter AUTO_INGEST = TRUE gibt an, dass die von einem S3-Bucket an eine SQS-Warteschlange gesendeten Ereignisbenachrichtigungen gelesen werden, sobald neue Daten ladebereit sind.
Wichtig
Vergleichen Sie die Stagingbereichsreferenz in der Pipedefinition mit den vorhandenen Pipes. Stellen Sie sicher, dass sich die Verzeichnispfade für denselben S3-Bucket nicht überschneiden. Andernfalls könnten verschiedene Pipes denselben Satz von Datendateien mehrmals in eine oder mehrere Zieltabellen laden. Dies kann beispielsweise der Fall sein, wenn mehrere Stagingbereiche auf denselben S3-Bucket verweisen, aber mit unterschiedlicher Granularität, z. B. s3://mybucket/path1 und s3://mybucket/path1/path2. In diesem Anwendungsfall würden beim Staging von Dateien in s3://mybucket/path1/path2 die Pipes für beide Stagingbereiche eine Kopie der Dateien laden.
Dies unterscheidet sich von der manuellen Snowpipe-Einrichtung (mit deaktivierter automatischer Erfassung), bei der Benutzer einen benannten Satz von Dateien an eine REST-API senden müssen, um die Dateien zum Laden in die Warteschlange zu stellen. Bei aktivierter automatischer Erfassung erhält jede Pipe eine generierte Dateiliste aus den S3-Ereignisbenachrichtigungen. Zusätzliche Sorgfalt ist erforderlich, um Datenduplikate zu vermeiden.
Schritt 3: Sicherheit konfigurieren¶
Vergeben Sie für jeden Benutzer, der kontinuierliches Laden von Daten mit Snowpipe durchführt, ausreichende Zugriffssteuerungsrechte an den Objekten für das Laden von Daten (d. h. Zieldatenbank, Schema und Tabelle; Stagingobjekt und Pipe).
Bemerkung
Um dem allgemeinen Prinzip der geringsten Berechtigungen zu folgen, empfehlen wir, einen separaten Benutzer und eine eigene Rolle für die Erfassung von Dateien über eine Pipe zu erstellen. Der Benutzer sollte mit dieser Rolle als Standardrolle erstellt werden.
Die Verwendung von Snowpipe erfordert eine Rolle mit den folgenden Berechtigungen:
Objekt |
Berechtigung |
Anmerkungen |
|---|---|---|
Benannte Pipe |
OWNERSHIP |
|
Benannter Stagingbereich |
USAGE , READ |
|
Benanntes Dateiformat |
USAGE |
Optional; nur erforderlich, wenn der in Schritt 1: Stagingbereich erstellen (falls erforderlich) erstellte Stagingbereich auf ein benanntes Dateiformat verweist. |
Zieldatenbank |
USAGE |
|
Zielschema |
USAGE |
|
Zieltabelle |
INSERT , SELECT |
Verwenden Sie den Befehl GRANT <Berechtigungen> … TO ROLE, um der Rolle Berechtigungen zu erteilen.
Bemerkung
Nur Sicherheitsadministratoren (d. h. Benutzer mit der Rolle SECURITYADMIN oder höher) oder mit einer anderen Rolle, die sowohl die Berechtigung CREATE ROLE für das Konto als auch die globale Berechtigung MANAGE GRANTS besitzt, können Rollen erstellen und Berechtigungen erteilen.
Erstellen Sie beispielsweise eine Rolle mit dem Namen snowpipe_role, die auf einen Satz von snowpipe_db.public-Datenbankobjekten sowie auf eine Pipe mit dem Namen mypipe zugreifen kann. Weisen Sie die Rolle anschließend einem Benutzer zu:
Schritt 4: Ereignisbenachrichtigungen konfigurieren¶
Konfigurieren Sie Ereignisbenachrichtigungen für Ihren S3-Bucket, um Snowpipe zu benachrichtigen, sobald neue Daten zum Laden verfügbar sind. Das Feature zur automatischen Erfassung stützt sich auf SQS-Warteschlangen, um Ereignisbenachrichtigungen von S3 an Snowpipe zu übermitteln.
Zur Vereinfachung der Verwendung werden Snowpipe SQS-Warteschlangen von Snowflake angelegt und verwaltet. Die Ausgabe des Befehls SHOW PIPES zeigt den Amazon Resource Name (ARN) Ihrer SQS-Warteschlange an.
Führen Sie den Befehl SHOW PIPES aus:
Beachten Sie den ARN der SQS-Warteschlange für den Stagingbereich in der Spalte
notification_channel. Kopieren Sie den ARN an einen geeigneten Speicherort.Bemerkung
Gemäß den Richtlinien von AWS legt Snowflake nicht mehr als eine SQS-Warteschlange pro AWS-S3-Region fest. Eine SQS-Warteschlange kann von mehreren Buckets in derselben Region von demselben AWS-Konto gemeinsam genutzt werden. Die SQS-Warteschlange koordiniert Benachrichtigungen für alle Pipes, die die externen Stagingbereiche für die S3-Buckets mit den Zieltabellen verbinden. Wenn eine Datendatei in den Bucket hochgeladen wird, führen alle Pipes, die mit dem Verzeichnispfad des Stagingbereichs übereinstimmen, ein einmaliges Laden der Datei in die entsprechenden Zieltabellen durch.
Melden Sie sich bei der Amazon S3-Konsole an.
Konfigurieren Sie anhand der Anweisungen in der Amazon S3-Dokumentation eine Ereignisbenachrichtigung für Ihren S3-Bucket. Füllen Sie die Felder wie folgt aus:
Name: Name der Ereignisbenachrichtigung (z. B.
Auto-ingest Snowflake).Events: Wählen Sie die Option ObjectCreate (All) aus.
Send to: Wählen Sie SQS Queue in der Dropdown-Liste aus.
SQS: Wählen Sie Add SQS queue ARN in der Dropdown-Liste aus.
SQS queue ARN: Fügen Sie den SQS-Warteschlangennamen aus der SHOW PIPES-Ausgabe ein.
Bemerkung
Mit diesen Anweisungen wird eine einzelne Ereignisbenachrichtigung erstellt, die die Aktivität für den gesamten S3-Bucket überwacht. Dies ist der einfachste Ansatz. Diese Benachrichtigung gilt für alle Pipes, die im S3-Bucket-Verzeichnis auf einer granulareren Ebene konfiguriert wurden. Snowpipe lädt nur Datendateien, die in Pipe-Definitionen angegeben sind. Beachten Sie jedoch, dass sich eine große Anzahl von Benachrichtigungen für Aktivitäten außerhalb einer Pipe-Definition negativ auf die Rate auswirken kann, mit der Snowpipe Benachrichtigungen filtert und Maßnahmen ergreift.
Alternativ können Sie in den obigen Schritten einen oder mehrere Pfade und/oder Dateierweiterungen (bzw. Präfixe und Suffixe in der AWS-Terminologie) konfigurieren, um Ereignisaktivitäten zu filtern. Anweisungen dazu finden Sie in den Informationen zum Filtern von Objektschlüsselnamen im entsprechenden AWS-Dokumentationsthema. Wiederholen Sie diese Schritte für jeden weiteren Pfad oder jede weitere Dateierweiterung, den bzw. die die Benachrichtigung überwachen soll.
Beachten Sie, dass AWS die Anzahl dieser Benachrichtigungs-Warteschlangenkonfigurationen auf maximal 100 pro S3-Bucket begrenzt.
Beachten Sie auch, dass AWS für denselben S3-Bucket keine überlappenden Warteschlangenkonfigurationen (über Ereignisbenachrichtigungen hinweg) zulässt. Wenn beispielsweise eine vorhandene Benachrichtigung für s3://mybucket/load/path1 konfiguriert ist, können Sie keine weitere Benachrichtigung auf einer höheren Ebene erstellen (z. B. s3://mybucket/load) oder umgekehrt.
Snowpipe mit automatischer Erfassung ist nun konfiguriert!
Wenn dem S3-Bucket neue Datendateien hinzugefügt werden, weist die Ereignisbenachrichtigung Snowpipe an, diese in die in der Pipe definierte Zieltabelle zu laden.
Schritt 5: Historische Dateien laden¶
Informationen zum Laden aller Backlogs mit Datendateien, die vor der Konfiguration von SQS-Benachrichtigungen im externen Stagingbereich vorhanden waren, finden Sie unter Laden historischer Daten.
Schritt 6: Stagingdateien löschen¶
Löschen Sie die Stagingdateien, nachdem Sie die Daten erfolgreich geladen haben und die Dateien nicht mehr benötigen. Eine Anleitung dazu finden Sie unter Löschen von Stagingdateien, nachdem Snowpipe die Daten geladen hat.
Option 2: Konfigurieren von Amazon SNS zum Automatisieren von Snowpipe mithilfe von SQS-Benachrichtigungen¶
In diesem Abschnitt wird beschrieben, wie das automatische Laden von Snowpipe-Daten mithilfe von Amazon SQS (Simple Queue Service)-Benachrichtigungen für einen S3-Bucket ausgelöst wird. In den Schritten wird erläutert, wie Sie Amazon Simple Notification Service (SNS) als Broadcaster konfigurieren, um Ereignisbenachrichtigungen für Ihren S3-Bucket für mehrere Abonnenten zu veröffentlichen (z. B. SQS-Warteschlangen oder AWS-Lambda-Workloads), einschließlich der Snowflake-SQS-Warteschlange für die Snowpipe-Automatisierung.
Bemerkung
Diese Anweisungen setzen voraus, dass für den Zielpfad in Ihrem S3-Bucket, in dem sich Ihre Datendateien befinden, eine Ereignisbenachrichtigung vorhanden ist. Wenn keine Ereignisbenachrichtigung vorhanden ist, gehen Sie wie folgt vor:
Führen Sie stattdessen Option 1: Erstellen einer neuen S3-Ereignisbenachrichtigung zum Automatisieren von Snowpipe aus (unter diesem Thema).
Erstellen Sie eine Ereignisbenachrichtigung für Ihren S3-Bucket, und fahren Sie dann mit den Anweisungen unter diesem Thema fort. Weitere Informationen dazu finden Sie in der Amazon S3-Dokumentation.
Die folgende Abbildung veranschaulicht den Prozessablauf für die automatische Erfassung mit Snowpipe und Amazon SNS:
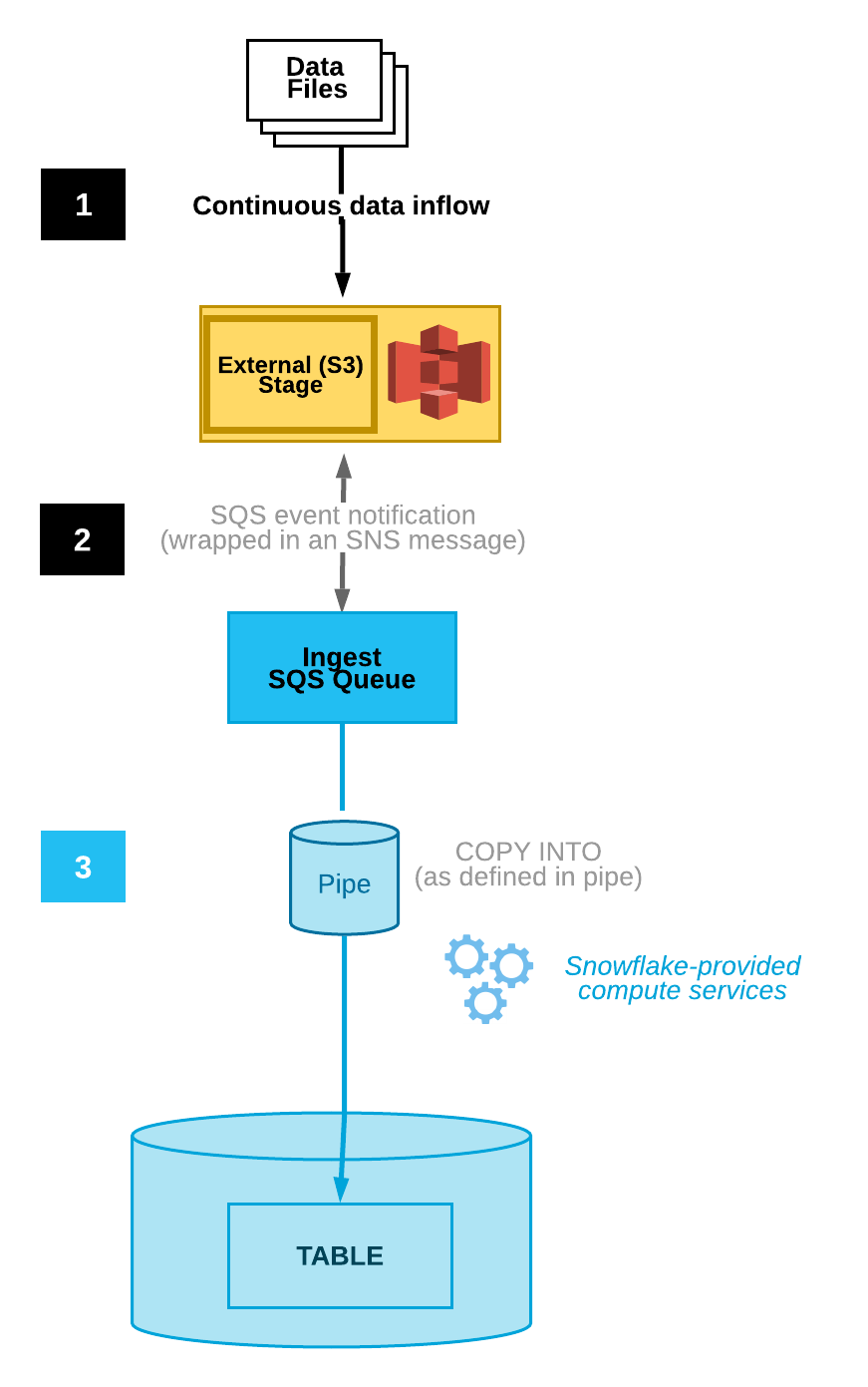
Datendateien werden in einen Stagingbereich geladen.
Eine von SNS veröffentlichte S3-Ereignisbenachrichtigung informiert Snowpipe via SQS-Warteschlange, dass Dateien ladebereit sind. Snowpipe kopiert die Dateien in eine Warteschlange.
Ein von Snowflake bereitgestelltes virtuelles Warehouse lädt Daten aus den Warteschlangendateien in die Zieltabelle, basierend auf den in der angegebenen Pipe definierten Parametern.
Bemerkung
Die Anweisungen setzen voraus, dass bereits eine Zieltabelle in der Snowflake-Datenbank vorhanden ist, in die Ihre Daten geladen werden.
Die automatische Snowpipe-Datenerfassung unterstützt AWS KMS-verschlüsselte SNS-Themen. Weitere Informationen dazu finden Sie unter Verschlüsselung im Ruhezustand.
Vorbereitung: Amazon-SNS-Thema und Abonnement erstellen.¶
Erstellen Sie ein SNS-Thema in Ihrem AWS-Konto, um alle Nachrichten für den Snowflake-Stagingbereich in Ihrem S3-Bucket zu verwalten.
Abonnieren Sie Ihre Zieldestinationen für die S3-Ereignisbenachrichtigungen (z. B. andere SQS-Warteschlangen oder AWS-Lambda-Workloads) zu diesem Thema. SNS veröffentlicht Ereignisbenachrichtigungen für Ihren Bucket an alle Abonnenten des Themas.
Anweisungen dazu finden Sie in der SNS-Dokumentation.
Schritt 1: Snowflake-SQS-Warteschlange zum SNS-Thema abonnieren¶
Melden Sie sich bei der AWS-Managementkonsole an.
Wählen Sie auf dem Startseiten-Dashboard die Option Simple Notification Service (SNS) aus.
Wählen Sie im linken Navigationsbereich Topics aus.
Suchen Sie das Thema für Ihren S3-Bucket. Beachten Sie das Thema ARN.
Fragen Sie mithilfe eines Snowflake-Clients die SYSTEM$GET_AWS_SNS_IAM_POLICY-Systemfunktion mit Ihrem SNS-Thema ARN ab:
Die Funktion gibt eine IAM-Richtlinie zurück, die einer Snowflake-SQS-Warteschlange die Berechtigung zum Abonnieren des SNS-Themas erteilt.
Beispiel:
Kehren Sie zur AWS Management Console zurück. Wählen Sie im linken Navigationsbereich Topics aus.
Wählen Sie das Thema für Ihren S3-Bucket aus, und klicken Sie auf die Schaltfläche Edit. Die Seite Edit wird angezeigt.
Klicken Sie auf Access policy - Optional, um diesen Bereich der Seite zu erweitern.
Fügen Sie den IAM-Richtlinienzusatz aus den SYSTEM$GET_AWS_SNS_IAM_POLICY-Funktionsergebnissen in das JSON-Dokument ein.
Beispiel:
Ursprüngliche IAM-Richtlinie (abgekürzt):
Zusammengeführte IAM-Richtlinie:
Fügen Sie eine zusätzliche Richtlinienberechtigung hinzu, damit S3 Ereignisbenachrichtigungen für den Bucket im SNS-Thema veröffentlichen kann.
Beispiel (unter Verwendung des in diesen Anweisungen verwendeten SNS-Thema-ARN und S3-Bucket):
Zusammengeführte IAM-Richtlinie:
Klicken Sie auf Save changes.
Schritt 2: Stagingbereich erstellen (falls erforderlich)¶
Erstellen Sie mit dem Befehl CREATE STAGE einen externen Stagingbereich, der auf Ihren S3-Bucket verweist. Snowpipe ruft Ihre Datendateien aus dem Stagingbereich ab und stellt sie vorübergehend in die Warteschlange, bevor sie in die Zieltabelle geladen werden.
Alternativ können Sie einen vorhandenen externen Stagingbereich verwenden.
Bemerkung
Informationen zum Konfigurieren des sicheren Zugriffs auf den Speicherort in der Cloud finden Sie unter Konfigurieren des sicheren Zugriffs auf Cloudspeicher (unter diesem Thema).
Im folgenden Beispiel wird im aktiven Schema der Benutzersitzung ein Stagingbereich mit dem Namen mystage erstellt. Die Cloudspeicher-URL enthält den Pfad files. Der Stagingbereich verweist auf eine Speicherintegration mit dem Namen my_storage_int:
Schritt 3: Pipe mit aktivierter automatischer Datenaufnahme erstellen¶
Erstellen Sie mit dem Befehl CREATE PIPE eine Pipe. Die Pipe definiert die COPY INTO <Tabelle>-Anweisung, mit der Snowpipe Daten aus der Erfassungswarteschlange in die Zieltabelle lädt. Identifizieren Sie in der COPY-Anweisung den SNS-Thema-ARN aus Voraussetzung: Amazon-SNS-Thema und Abonnement erstellen.
Im folgenden Beispiel wird im aktiven Schema der Benutzersitzung eine Pipe mit dem Namen mypipe erstellt. Die Pipe lädt die Daten aus den im Stagingbereich mystage bereitgestellten Dateien in die Tabelle mytable:
Wobei:
AUTO_INGEST = TRUEGibt an, dass die von einem S3-Bucket an eine SQS-Warteschlange gesendeten Ereignisbenachrichtigungen gelesen werden, sobald neue Daten ladebereit sind.
AWS_SNS_TOPIC = '<sns_topic_arn>'Gibt den ARN für das SNS-Thema Ihres S3-Buckets an, z. B.
arn:aws:sns:us-west-2:001234567890:s3_mybucketim aktuellen Beispiel. Mit der CREATE PIPE-Anweisung wird die Snowflake-SQS-Warteschlange für das angegebene SNS-Thema abonniert. Beachten Sie, dass die Pipe nur Dateien in die Erfassungswarteschlange kopiert, die durch Ereignisbenachrichtigungen über das SNS-Thema ausgelöst wurden.
Um einen der Parameter aus einer Pipe zu entfernen, muss die Pipe derzeit mit der Syntax CREATE OR REPLACE PIPE neu erstellt werden.
Wichtig
Stellen Sie sicher, dass sich die Speicherortreferenz in der COPY INTO <Tabelle>-Anweisung nicht mit der Referenz in bestehenden Pipes des Kontos überschneidet. Andernfalls könnten mehrere Pipes denselben Satz von Datendateien in die Zieltabellen laden. Diese Situation kann beispielsweise eintreten, wenn mehrere Pipe-Definitionen auf denselben Speicherort mit unterschiedlicher Granularität verweisen, wie <Speicherort>/path1/ und <Speicherort>/path1/path2/. Wenn in diesem Beispiel Dateien in <Speicherort>/path1/path2/ bereitgestellt werden, würden beide Pipes eine Kopie der Dateien laden.
Prüfen Sie die COPY INTO <Tabelle>-Anweisungen in den Definitionen aller Pipes des Kontos durch Ausführen von SHOW PIPES oder durch Abfragen der Ansicht PIPES in Account Usage oder der Ansicht PIPES in Information Schema.
Schritt 4: Sicherheit konfigurieren¶
Vergeben Sie für jeden Benutzer, der kontinuierliches Laden von Daten mit Snowpipe durchführt, ausreichende Zugriffssteuerungsrechte an den Objekten für das Laden von Daten (d. h. Zieldatenbank, Schema und Tabelle; Stagingobjekt und Pipe).
Bemerkung
Um dem allgemeinen Prinzip der geringsten Berechtigungen zu folgen, empfehlen wir, einen separaten Benutzer und eine eigene Rolle für die Erfassung von Dateien über eine Pipe zu erstellen. Der Benutzer sollte mit dieser Rolle als Standardrolle erstellt werden.
Die Verwendung von Snowpipe erfordert eine Rolle mit den folgenden Berechtigungen:
Objekt |
Berechtigung |
Anmerkungen |
|---|---|---|
Benannte Pipe |
OWNERSHIP |
|
Benannte Speicherintegration |
USAGE |
Erforderlich, wenn der in Schritt 2: Stagingbereich erstellen (falls erforderlich) erstellte Stagingbereich auf eine Speicherintegration verweist. |
Benannter Stagingbereich |
USAGE , READ |
|
Benanntes Dateiformat |
USAGE |
Optional; nur erforderlich, wenn der in Schritt 2: Stagingbereich erstellen (falls erforderlich) erstellte Stagingbereich auf ein benanntes Dateiformat verweist. |
Zieldatenbank |
USAGE |
|
Zielschema |
USAGE |
|
Zieltabelle |
INSERT , SELECT |
Verwenden Sie den Befehl GRANT <Berechtigungen> … TO ROLE, um der Rolle Berechtigungen zu erteilen.
Bemerkung
Nur Sicherheitsadministratoren (d. h. Benutzer mit der Rolle SECURITYADMIN oder höher) können Rollen erstellen.
Erstellen Sie beispielsweise eine Rolle mit dem Namen snowpipe_role, die auf einen Satz von snowpipe_db.public-Datenbankobjekten sowie auf eine Pipe mit dem Namen mypipe zugreifen kann. Weisen Sie die Rolle anschließend einem Benutzer zu:
Snowpipe mit automatischer Erfassung ist nun konfiguriert!
Wenn dem S3-Bucket neue Datendateien hinzugefügt werden, weist die Ereignisbenachrichtigung Snowpipe an, diese in die in der Pipe definierte Zieltabelle zu laden.
Schritt 5: Historische Dateien laden¶
Informationen zum Laden aller Backlogs mit Datendateien, die vor der Konfiguration von SQS-Benachrichtigungen im externen Stagingbereich vorhanden waren, finden Sie unter Laden historischer Daten.
Schritt 6: Stagingdateien löschen¶
Löschen Sie die Stagingdateien, nachdem Sie die Daten erfolgreich geladen haben und die Dateien nicht mehr benötigen. Eine Anleitung dazu finden Sie unter Löschen von Stagingdateien, nachdem Snowpipe die Daten geladen hat.
Option 3: Einrichten von Amazon EventBridge zum Automatisieren von Snowpipe¶
Ähnlich wie bei Option 2 können Sie auch Amazon EventBridge zum Automatisieren von Snowpipe einrichten.
Schritt 1: Amazon SNS-Thema erstellen¶
Führen Sie die unter Vorbereitung: Amazon-SNS-Thema und Abonnement erstellen (unter diesem Thema) beschriebenen Schritte aus.
Schritt 2: EventBridge-Regel zum Abonnieren von S3-Buckets und zum Senden von Benachrichtigungen an SNS-Themen erstellen¶
Aktivieren Sie Amazon EventBridge für S3-Buckets.
Erstellen Sie EventBridge-Regeln, die das Senden von Benachrichtigungen an das in Schritt 1 erstellte SNS-Thema steuern.
Option 3: Konfigurieren von Amazon SNS zum Automatisieren von Snowpipe mithilfe von SQS-Benachrichtigungen¶
Führen Sie die unter Option 2: Konfigurieren von Amazon SNS zum Automatisieren von Snowpipe mithilfe von SQS-Benachrichtigungen (unter diesem Thema) beschriebenen Schritte aus.
SYSTEM$PIPE_STATUS-Ausgabe¶
Die Funktion SYSTEM$PIPE_STATUS ruft eine JSON-Darstellung des aktuellen Status einer Pipe ab.
Bei Pipes, bei denen AUTO_INGEST auf TRUE gesetzt ist, gibt die Funktion ein JSON-Objekt zurück, das die folgenden Name/Wert-Paare enthält (falls auf den aktuellen Pipe-Status zutreffend):
{„executionState“:“<Wert>“,“oldestFileTimestamp“:<Wert>,“pendingFileCount“:<Wert>,“notificationChannelName“:“<Wert>“,“numOutstandingMessagesOnChannel“:<Wert>,“lastReceivedMessageTimestamp“:“<Wert>“,“lastForwardedMessageTimestamp“:“<Wert>“,“error“:<Wert>,“fault“:<Wert>}
Weitere Erläuterungen zu den Ausgabewerten finden Sie im Referenzthema zur SQL-Funktion.