Dynamische Tabellen erstellen¶
Unter diesem Thema werden die wichtigsten Konzepte zur Erstellung dynamischer Tabellen erläutert.
Stellen Sie vor Beginn sicher, dass Sie über die Berechtigungen für das Erstellen dynamischer Tabellen verfügen und dass für alle von der Abfrage dynamischer Tabellen verwendeten Objekte die Änderungsverfolgung aktiviert ist.
Für das Erstellen dynamischer Tabellen können einige Einschränkungen gelten. Eine vollständige Liste finden Sie unter Beschränkungen für dynamische Tabellen.
Bemerkung
Eine Anleitung zum Schreiben von Abfragen, die effizient mit einer inkrementellen Aktualisierung arbeiten, finden Sie unter Optimieren von Abfragen für inkrementelle Aktualisierungen.
Änderungsverfolgung aktivieren¶
Wenn beim Erstellen einer dynamischen Tabelle mit inkrementellem Aktualisierungsmodus die Änderungsverfolgung für die abgefragten Tabellen noch nicht aktiviert ist, versucht Snowflake automatisch, die Änderungsverfolgung für sie zu aktivieren. Um inkrementelle Aktualisierungen zu unterstützen, muss die Änderungsverfolgung mit Nicht-Null-Time Travel-Aufbewahrungsfrist für alle zugrunde liegenden Objekte, die von einer dynamischen Tabelle verwendet werden, aktiviert sein.
Wenn sich die Basisobjekte ändern, ändert sich auch die dynamische Tabelle. Wenn Sie ein Basisobjekt neu erstellen, müssen Sie die Änderungsverfolgung wieder aktivieren.
Bemerkung
Snowflake versucht nicht automatisch, die Änderungsverfolgung bei dynamischen Tabellen zu aktivieren, die im Modus der vollständigen Aktualisierung erstellt wurden.
Um die Änderungsverfolgung für ein bestimmtes Datenbankobjekt zu aktivieren, verwenden Sie ALTER TABLE, ALTER VIEW und ähnliche Befehle für dieses Objekt. Der Benutzer, der die dynamische Tabelle erstellt, muss die OWNERSHIP-Berechtigungen haben, um die Änderungsverfolgung für alle zugrunde liegenden Objekte zu aktivieren.
Um zu prüfen, ob die Änderungsverfolgung aktiviert ist, verwenden Sie SHOW VIEWS, SHOW TABLES und ähnliche Befehle für die zugrunde liegenden Objekte, und untersuchen Sie die Spalte change_tracking.
Unterstützte Basisobjekte¶
Dynamische Tabellen unterstützen die folgenden Basisobjekte:
Tabellen
Von Snowflake verwaltete Apache Iceberg™-Tabellen
Extern verwaltete Apache Iceberg™-Tabellen
Beispiel: Erstellen einer einfachen dynamischen Tabelle¶
Angenommen, Sie möchten eine dynamische Tabelle erstellen, die die Spalten product_id und product_name aus der Tabelle staging_table enthält, und Sie haben folgende Ziele:
Sie möchten, dass die Daten in der dynamischen Tabelle höchstens 20 Minuten hinter den Daten in
staging_tablezurückbleiben.Sie möchten die Computeressourcen des Warehouses
mywhfür die Aktualisierung verwenden.Sie möchten, dass der Aktualisierungsmodus automatisch ausgewählt wird.
Snowflake empfiehlt, den automatischen Aktualisierungsmodus nur während der Entwicklungphase zu verwenden. Weitere Informationen dazu finden Sie unter Auswählen eines Aktualisierungsmodus.
Sie möchten, dass die dynamische Tabelle bei der Erstellung synchron aktualisiert wird.
Sie möchten, dass der Aktualisierungstyp automatisch ausgewählt wird und dass die dynamische Tabelle bei der Erstellung synchron aktualisiert wird.
Zum Erstellen der dynamischen Tabelle führen Sie die folgende SQL-Anweisung CREATE DYNAMIC TABLE aus:
Eine vollständige Liste der Parameter und der Syntaxvarianten finden Sie unter CREATE DYNAMIC TABLE.
Erstellen dynamischer Tabellen, die aus von Snowflake verwalteten oder extern verwalteten Apache Iceberg™-Tabellen lesen¶
Das Erstellen einer dynamischen Tabelle aus einer Iceberg-Tabelle ist ähnlich wie das Erstellen einer dynamischen Tabelle aus einer regulären Tabelle. Führen Sie die CREATE DYNAMIC TABLE SQL-Anweisung wie bei einer normalen Tabelle aus, wobei entweder eine von Snowflake verwaltete Tabelle oder eine von einem externen Katalog verwaltete Tabelle als Basisobjekt verwendet wird.
Dynamische Tabellen, die aus einer von Snowflake verwalteten Iceberg-Tabelle als Basistabelle lesen, sind nützlich, wenn Sie möchten, dass Ihre Pipelines Daten in einer Snowflake-verwalteten Iceberg-Tabelle verarbeiten oder wenn Sie möchten, dass Ihre Pipelines Iceberg-Tabellen verarbeiteten, die von anderen Engines geschrieben wurden. Beachten Sie, dass externe Engines nicht in von Snowflake verwaltete Iceberg-Tabellen schreiben können. Sie haben Lese- und Schreibberechtigungen für Snowflake, sind für externe Engines jedoch schreibgeschützt.
Dynamische Tabellen, die aus Iceberg-Tabellen lesen, die von externen (nicht Snowflake) Katalogen, z. B. AWS Glue, verwaltet werden und von Engines wie Apache Spark geschrieben wurden, eignen sich für die Verarbeitung von Daten aus externen Data Lakes. Sie können dynamische Tabellen auf der Grundlage extern verwalteter Daten erstellen und diese kontinuierlich in Snowflake verarbeiten, ohne die Daten zu duplizieren oder aufzunehmen.
Einschränkungen und Hinweise zur Verwendung von Iceberg-Tabellen¶
Alle Einschränkungen für reguläre dynamische Tabellen und dynamische Iceberg-Tabellen gelten weiterhin.
Außerdem:
Alle Einschränkungen für Iceberg-Basistabellen gelten. Weitere Informationen dazu finden Sie unter Hinweise und Einschränkungen.
Sie können eine dynamische Tabelle erstellen, die aus nativen Snowflake-Tabellen, aus Snowflake verwalteten Iceberg-Tabellen und aus extern verwalteten Iceberg-Tabellen liest.
Dynamische Tabellen verfolgen Änderungen auf Dateiebene für extern verwaltete Iceberg-Basistabellen, im Gegensatz zu anderen Basistabellen, die Änderungen auf Zeilenebene verfolgen. Häufige Kopieren-auf-Schreiben-Operationen (z. B. Aktualisierungen oder Löschungen) auf extern verwalteten Iceberg-Tabellen können sich auf die Leistung von inkrementellen Aktualisierungen auswirken.
Erstellen dynamischer Tabellen mit Unveränderlichkeit und Backfill¶
Mit Unveränderlichkeitseinschränkungen können Sie Teile einer dynamischen Tabelle als statisch markieren. Wenn Sie eine IMMUTABLE WHERE-Klausel definieren, überspringt Snowflake diese Zeilen bei der Aktualisierung, was die Leistung verbessert, insbesondere bei Tabellen, die große Mengen historischer Daten enthalten.
Backfill erweitert die Unveränderlichkeitseinschränkungen, indem Sie vorhandene Daten in eine dynamische Tabelle kopieren können, ohne diese berechnen zu müssen. Durch diesen Vorgang sind historische Daten sofort verfügbar, während Sie eine kundenspezifische Aktualisierungsabfrage für zukünftige Aktualisierungen definieren.
Weitere Informationen und Beispiele dazu finden Sie unter Verwenden von Unveränderlichkeitseinschränkungen.
Best Practices für das Erstellen dynamischer Tabellen¶
Pipelines dynamischer Tabellen verketten¶
Wenn Sie eine neue dynamische Tabelle definieren, sollten Sie keine große dynamische Tabelle mit vielen verschachtelten Anweisungen definieren, sondern stattdessen kleine dynamische Tabellen mit Pipelines verwenden.
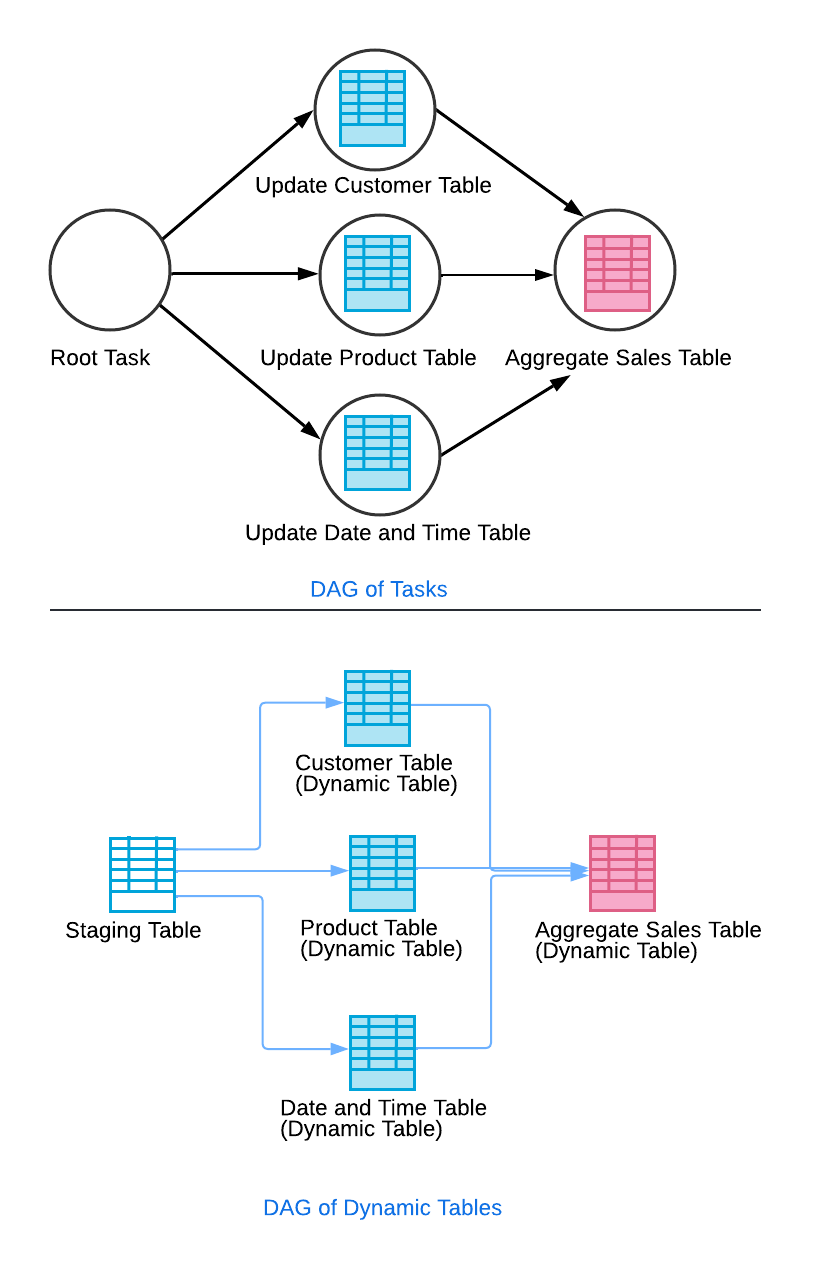
Sie können eine dynamische Tabelle einrichten, um andere dynamische Tabellen abzufragen. Stellen Sie sich zum Beispiel ein Szenario vor, in dem Ihre Datenpipeline Daten aus einer Staging-Tabelle extrahiert, um verschiedene Dimensionstabellen zu aktualisieren (z. B. customer, product, date und time). Außerdem aktualisiert Ihre Pipeline eine aggregierte sales-Tabelle, die auf den Informationen aus diesen Dimensionstabellen basiert. Indem Sie die Dimensionstabellen so konfigurieren, dass sie die Staging-Tabelle abfragen, und die aggregierte sales-Tabelle so, dass sie die Dimensionstabellen abfragt, erzeugen Sie einen Kaskadeneffekt, ähnlich wie bei einem Task-Graphen.
In diesem Setup wird die Aktualisierung der aggregierten sales-Tabelle erst ausgeführt, nachdem die Aktualisierungen der Dimensionstabellen erfolgreich abgeschlossen wurden. Dies stellt die Konsistenz der Daten und die Einhaltung der Verzögerungsziele sicher. Durch einen automatischen Aktualisierungsprozess lösen alle Änderungen in den Quelltabellen zu den entsprechenden Zeitpunkten Aktualisierungen in allen abhängigen Tabellen aus.
Dynamische „Controller“-Tabelle für komplexe Task-Graphen verwenden¶
Wenn Sie einen komplexen Graphen von dynamischen Tabellen mit vielen Wurzeln und Blättern haben und mit einem einzigen Befehl Operationen (z. B. Änderung der Verzögerung, manuelle Aktualisierung, Aussetzung) am gesamten Task-Graphen ausführen möchten, gehen Sie wie folgt vor:
Setzen Sie den Wert für
TARGET_LAGfür alle Ihre dynamischen Tabellen aufDOWNSTREAM.Erstellen Sie eine dynamische „Controller“-Tabelle, die alle Blätter in Ihrem Task-Graphen ausliest.
Eine dynamische Leaf-Tabelle ist ein Knoten in Ihrem Task-Graphen, der keine nachgelagerten Abhängigkeiten aufweist. Keine anderen dynamischen Tabellen lesen aus der Tabelle, sodass sie keine Abhängigkeit von einer anderen dynamischen Tabelle darstellt.
Ersetzen Sie
<leaf1>,<leaf2>, …,<leafN>durch die eigentlichen dynamischen Leaf-Tabellennamen.Um sicherzustellen, dass dieser Controller keine Ressourcen verbraucht, erstellen Sie eine kartesische Verknüpfung mit
LIMIT 0.
Verwenden Sie den Controller, um den gesamten Task-Graphen zu steuern. Beispiel:
Legen Sie eine neue Zielverzögerung für den Task-Graphen fest.
Aktualisieren Sie den Task-Graphen manuell.
Verwenden Sie transiente dynamische Tabellen, um die Speicherkosten zu reduzieren¶
Transiente dynamische Tabellen halten Daten zuverlässig über die Zeit aufrecht und unterstützen Time Travel innerhalb der Datenaufbewahrungsfrist, bewahren aber keine Daten über die Fail-safe-Frist hinaus auf. Standardmäßig werden die dynamischen Tabellendaten sieben Tage lang im Fail-safe-Speicher aufbewahrt.
Bei dynamischen Tabellen mit hohem Aktualisierungsdurchsatz kann dies den Speicherverbrauch erheblich erhöhen. Daher sollten Sie eine dynamische Tabelle nur dann zu einer transienten Tabelle machen, wenn ihre Daten nicht dasselbe Maß an Datenschutz und Wiederherstellung benötigen, das permanente Tabellen bieten.
Mit der Anweisung CREATE DYNAMIC TABLE können Sie eine transiente dynamische Tabelle erstellen oder bestehende dynamische Tabellen in transiente dynamische Tabellen klonen.
Probleme beim Erstellen dynamischer Tabellen lösen¶
Wenn Sie eine dynamische Tabelle erstellen, erfolgt die anfängliche Aktualisierung entweder nach einem Zeitplan (ON_SCHEDULE) oder sofort bei der Erstellung (ON_CREATE). Die erstmalige Datenbefüllung oder Initialisierung hängt davon ab, wann diese erste Aktualisierung stattfindet. Beispiel: Für ON_CREATE kann die Initialisierung länger dauern, wenn sie Aktualisierungen der vorgelagerten dynamischen Tabellen auslöst.
Die Initialisierung kann einige Zeit dauern, je nachdem, wie viele Daten gescannt werden. Um den Fortschritt zu sehen, gehen Sie wie folgt vor:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Monitoring » Query History aus.
In der Dropdown-Liste Filters geben Sie CREATE DYNAMIC TABLE als SQL Text-Filter und Ihren Warehouse-Namen als Warehouse-Filter ein.
Wählen Sie unter SQL text die Abfrage mit Ihrer dynamischen Tabelle aus, und verwenden Sie die Registerkarten Query Details und Query Profile, um den Fortschritt zu verfolgen.