Das PIPE-Objekt¶
Das PIPE-Objekt ist die serverseitige Verarbeitungsschicht für Snowpipe Streaming. Jede Streaming-Datenaufnahme erfolgt durch eine Pipe, die die Schemavalidierung, optionale Datentransformationen und optional das Pre-Clustering durchführt, bevor die Daten in die Zieltabelle übertragen werden.
Das PIPE-Objekt bietet die folgenden Funktionen:
Transformationen während der Ausführung: Filtern von Zeilen, Anordnen von Spalten, Umwandeln von Typen und Anwenden von Ausdrücken während der Erfassung mit Syntax für die Transformation von COPY-Befehlen. Dies ermöglicht eine Bereinigung und Umformung von Daten zum Zeitpunkt der Datenaufnahme, ohne dass ein separater ETL-Schritt erforderlich ist.
Pre-Pre-Clustering: Sortieren von Daten während der Datenaufnahme auf der Grundlage von Gruppierungsschlüsseln für Tabellen zur Optimierung der Abfrageleistung.
Serverseitige Schemavalidierung: Überprüfen Sie die eingehenden Daten vor dem Commit anhand des in der Pipe definierten Schemas.
Unterstützung von Tabellen-Features: Verarbeiten der Datenaufnahme in Tabellen mit definierten Clustering-Schlüsseln, Spalten mit dem Wert DEFAULT und AUTOINCREMENT- (oder IDENTITY-)Spalten.
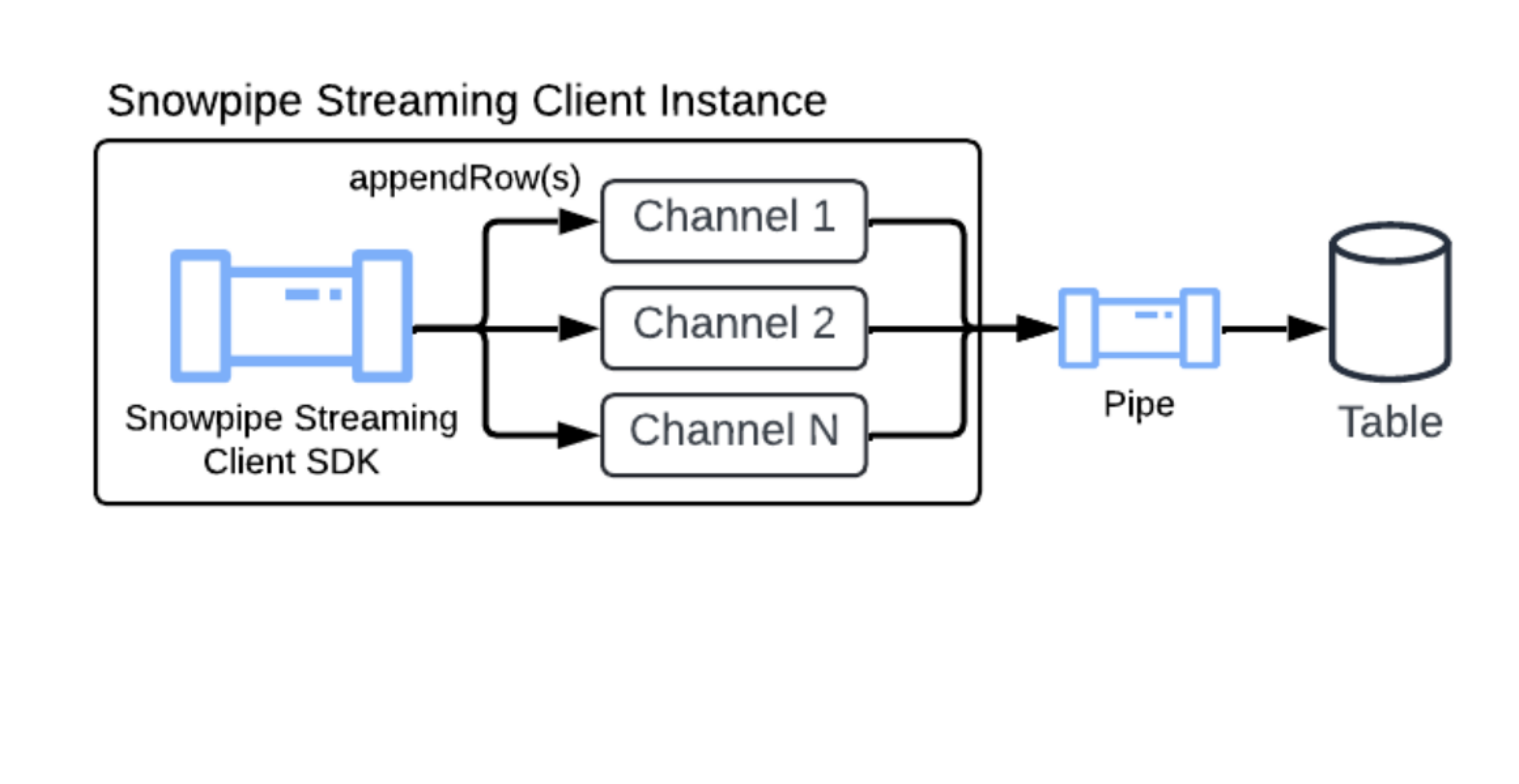
Für eine schnelle Einrichtung erstellt Snowflake automatisch eine Standard-Pipe für jede Tabelle. Die Standard-Pipe verarbeitet die Datenaufnahme, ohne dass eine manuelleDDL erforderlich ist. Für fortgeschrittene Anwendungsfälle, die Transformationen oder Pre-Clustering erfordern, können Sie eine kundenspezifische benannte Pipe erstellen. Weitere Informationen dazu finden Sie unter CREATE PIPE.
Standard-Pipe¶
Snowflake bietet für jede Zieltabelle eine Standard-Pipe. Die Standard-Pipe wird bei Bedarf erstellt, wenn der erste erfolgreiche Aufruf des Typs „pipe-info“ oder „open-channel“ für die Zieltabelle ausgeführt wurde. So können Sie sofort mit dem Streaming von Daten beginnen, ohne CREATE PIPE DDL-Anweisungen manuell ausführen zu müssen.
Erstellung nach Bedarf: Sie können die Pipe nur anzeigen oder beschreiben (mithilfe von SHOW PIPES oder DESCRIBE PIPE), nachdem sie durch einen dieser Aufrufe instanziiert wurde.
Namenskonvention:
<TABLE_NAME>-STREAMING(z. B.MY_TABLE-STREAMING)Vollständig von Snowflake verwaltet: Sie können CREATE, ALTER oder DROP nicht für die Standard-Pipe ausführen.
Sichtbarkeit: Sie können die Standard-Pipe mit SHOW PIPES, DESCRIBE PIPE überprüfen. Die Standard-Pipe ist auch in den Ansichten ACCOUNT_USAGE.PIPES, ACCOUNT_USAGE.METERING_HISTORY und ORGANIZATION_USAGE.PIPES enthalten.
Die Standard-Pipe weist die folgenden Beschränkungen auf:
Keine Transformationen: Die Standard-Pipe verwendet``MATCH_BY_COLUMN_NAME`` in der zugrunde liegenden Kopieranweisung. Es werden keine bestimmten Datentransformationen unterstützt.
Kein Pre-Clustering: Die Standard-Pipe unterstützt kein Pre-Clustering für die Zieltabelle.
Wenn Ihr Workflow Transformationen oder Pre-Clustering erfordert, erstellen Sie Ihre eigene benannte Pipe. Weitere Informationen dazu finden Sie unter CREATE PIPE.
Bei der Konfiguration des Snowpipe Streaming SDK oder der REST API können Sie in Ihrer Clientkonfiguration auf den Namen der Standard-Pipe verweisen, um mit dem Streaming zu beginnen. Weitere Informationen dazu finden Sie unter Tutorial: Erste Schritte mit der leistungsstarken Snowpipe Streaming-Architektur SDK und Tutorial: Erste Schritte mit der Snowpipe Streaming REST API unter Verwendung von cURL und JWT.
Vorab-Clustering von Daten während der Aufnahme¶
Snowpipe Streaming kann Daten während der Aufnahme clustern, was die Abfrageleistung der Zieltabellen verbessert. Dieses Feature sortiert die Daten direkt während der Aufnahme, bevor die Daten übertragen werden.
Um das Pre-Clustering nutzen zu können, müssen für Ihre Zieltabelle Gruppierungsschlüssel definiert sein. Sie können dieses Feature dann aktivieren, indem Sie den Parameter CLUSTER_AT_INGEST_TIME auf TRUE in der COPY INTO-Anweisung festlegen, wenn Sie die Snowpipe Streaming-Pipe erstellen oder ersetzen.
Weitere Informationen dazu finden Sie unter CLUSTER_AT_INGEST_TIME.
Wichtig
Wenn Sie das Pre-Clustering-Feature verwenden, deaktivieren Sie nicht das Auto-Clustering-Feature für die Zieltabelle. Das Deaktivieren von Auto-Clustering kann im Laufe der Zeit zu einer Beeinträchtigung der Abfrage führen.