Mikropartitionen und Daten-Clustering¶
Herkömmliche Data Warehouses benötigen eine statische Partitionierung großer Tabellen, um eine akzeptable Leistung zu erzielen und eine bessere Skalierung zu ermöglichen. In diesen Systemen ist eine Partition eine Verwaltungseinheit, die unter Verwendung von spezialisierter DDL und Syntax unabhängig manipuliert werden kann. Für die statische Partitionierung gibt es jedoch eine Reihe bekannter Einschränkungen, z. B. Wartungsaufwand und Datenschiefe, die zu Partitionen mit unverhältnismäßig großem Umfang führen können.
Im Gegensatz zu einem Data Warehouse bietet die Snowflake Data Platform eine leistungsstarke und einzigartige Form der Partitionierung, die als Mikropartitionierung bezeichnet wird. Diese bietet alle Vorteile der statischen Partitionierung ohne die bekannten Einschränkungen und bietet darüber hinaus weitere wesentliche Vorteile.
Achtung
Hybridtabellen basieren auf einer Architektur, die einige der in Snowflake-Standardtabellen verfügbaren Features nicht unterstützt, so z. B. Gruppierungsschlüssel.
Was sind Mikropartitionen?¶
Alle Daten in Snowflake-Tabellen werden automatisch in Mikropartitionen unterteilt, bei denen es sich um zusammenhängende Speichereinheiten handelt. Jede Mikropartition enthält zwischen 50 MB und 500 MB unkomprimierte Daten (beachten Sie, dass die tatsächliche Größe in Snowflake geringer ist, da die Daten immer komprimiert gespeichert werden). Gruppen von Zeilen in Tabellen werden einzelnen Mikropartitionen zugeordnet, die spaltenweise organisiert sind. Diese Größe und Struktur ermöglicht ein äußerst granulares Verkürzen sehr großer Tabellen, die aus Millionen oder sogar Hunderten von Millionen von Mikropartitionen bestehen können.
Snowflake speichert Metadaten zu allen Zeilen, die in einer Mikropartition gespeichert sind, einschließlich:
Wertebereich jeder Spalte in der Mikropartition.
Anzahl unterschiedlicher Werte.
Zusätzliche Eigenschaften, die sowohl für die Optimierung als auch für die effiziente Abfrageverarbeitung verwendet werden.
Bemerkung
Die Mikropartitionierung wird automatisch für alle Snowflake-Tabellen durchgeführt. Tabellen werden transparent in der Reihenfolge partitioniert, in der die Daten eingefügt/geladen werden.
Vorteile der Mikropartitionierung¶
Der Snowflake-Ansatz zur Partitionierung von Tabellendaten bietet folgende Vorteile:
Im Gegensatz zur herkömmlichen statischen Partitionierung werden Snowflake-Mikropartitionen automatisch abgeleitet. Sie müssen nicht explizit im Voraus definiert oder von Benutzern verwaltet werden.
Wie der Name vermuten lässt, haben die Mikropartitionen eine geringe Größe (50 bis 500 MB vor der Komprimierung), wodurch äußerst effizientes DML und feinkörniges Verkürzen für schnellere Abfragen ermöglicht wird.
Mikropartitionen können sich in ihrem Wertebereich überlappen, was zusammen mit ihrer einheitlich kleinen Größe dazu beiträgt, eine Datenschiefe zu verhindern.
Spalten werden unabhängig voneinander in Mikropartitionen gespeichert, die häufig auch spaltenweise Speicherung genannt wird. Dies ermöglicht ein effizientes Scannen einzelner Spalten, denn es werden nur die Spalten durchsucht, auf die eine Abfrage verweist.
Spalten werden auch innerhalb von Mikropartitionen individuell komprimiert. Snowflake ermittelt automatisch den effizientesten Komprimierungsalgorithmus für die Spalten jeder Mikropartition.
Sie können Clustering für bestimmte Tabellen aktivieren, indem Sie für jede dieser Tabellen einen Gruppierungsschlüssel angeben. Weitere Informationen zum Angeben eines Gruppierungsschlüssel finden Sie unter:
Weitere Informationen zum Clustering, einschließlich Strategien zur Auswahl der zu clusternden Tabellen, finden Sie unter:
Auswirkungen von Mikropartitionen¶
DML¶
Alle DML-Operationen (z. B. DELETE, UPDATE, MERGE) nutzen die zugrunde liegenden Metadaten der Mikropartitionen, um die Tabellenwartung zu vereinfachen. Einige Operationen, beispielsweise das Löschen aller Zeilen aus einer Tabelle, sind reine Metadaten-Operationen.
Löschen einer Spalte in einer Tabelle¶
Wenn eine Spalte in einer Tabelle gelöscht wird, werden die Mikropartitionen, die die Daten für die gelöschte Spalte enthalten, bei Ausführung der Löschanweisung nicht neu geschrieben. Die Daten in der gelöschten Spalte bleiben im Speicher. Weitere Informationen dazu finden Sie in den Nutzungshinweisen für ALTER TABLE.
Abfrageverkürzung¶
Die von Snowflake verwalteten Mikropartitions-Metadaten ermöglichen ein präzises Verkürzen von Spalten in Mikropartitionen zur Laufzeit der Abfrage, einschließlich Spalten, die semistrukturierte Daten enthalten. Mit anderen Worten, eine Abfrage, die ein Filterprädikat für einen Wertebereich angibt, der auf 10 % der Werte im Bereich zugreift, sollte im Idealfall nur 10 % des Inhalts der Mikropartitionen scannen.
Angenommen, eine große Tabelle enthält historische Daten eines ganzen Jahres mit Datums- und Stundenspalten. Unter der Annahme einer gleichmäßigen Verteilung der Daten würde eine Abfrage, die auf eine bestimmte Stunde abzielt, idealerweise 1/8760 der Mikropartitionen der Tabelle scannen und dann nur den Teil der Mikropartition, der die Daten für die Stundenspalte enthält. Snowflake scannt die Partitionen spaltenweise, sodass bei einer Abfrage, die nur nach einer Spalte filtert, nicht die gesamte Partition durchsucht wird.
Mit anderen Worten, je näher das Verhältnis von gescannten Mikropartitionen und spaltenweisen Daten dem Verhältnis der tatsächlich ausgewählten Daten ist, desto effizienter ist die auf der Tabelle ausgeführte Verkürzung.
Bei Zeitreihendaten ermöglicht diese Verkürzung potenziell Antwortzeiten von unter einer Sekunde auf Abfragen innerhalb von Bereichen (d. h. „Slices“) mit einer Genauigkeit von einer Stunde oder weniger.
Nicht alle Prädikatausdrücke können zum Abtrennen verwendet werden. Beispielsweise führt Snowflake kein Abtrennen bei Mikropartitionen auf Basis eines Prädikats mit einer Unterabfrage aus, selbst wenn die Unterabfrage zu einer Konstanten führt.
Was ist Daten-Clustering?¶
Normalerweise werden Daten, die in Tabellen gespeichert sind, nach natürlichen Dimensionen (z. B. Datum und/oder geografische Regionen) sortiert. Dieses „Clustering“ ist ein Schlüsselfaktor für Abfragen, da Tabellendaten, die nicht oder nur teilweise sortiert sind, die Abfrageleistung insbesondere bei sehr großen Tabellen beeinflussen können.
In Snowflake werden beim Einfügen/Laden von Daten in eine Tabelle Clustering-Metadaten für jede während des Prozesses erstellte Mikropartition erfasst. Snowflake nutzt dann diese Clustering-Informationen, um bei Abfragen das Scannen von Mikropartitionen zu vermeiden und die Leistung von Abfragen, die auf diese Spalten verweisen, erheblich zu beschleunigen.
Die folgende Abbildung zeigt eine Snowflake-Tabelle t1 mit vier nach Datum sortierten Spalten:
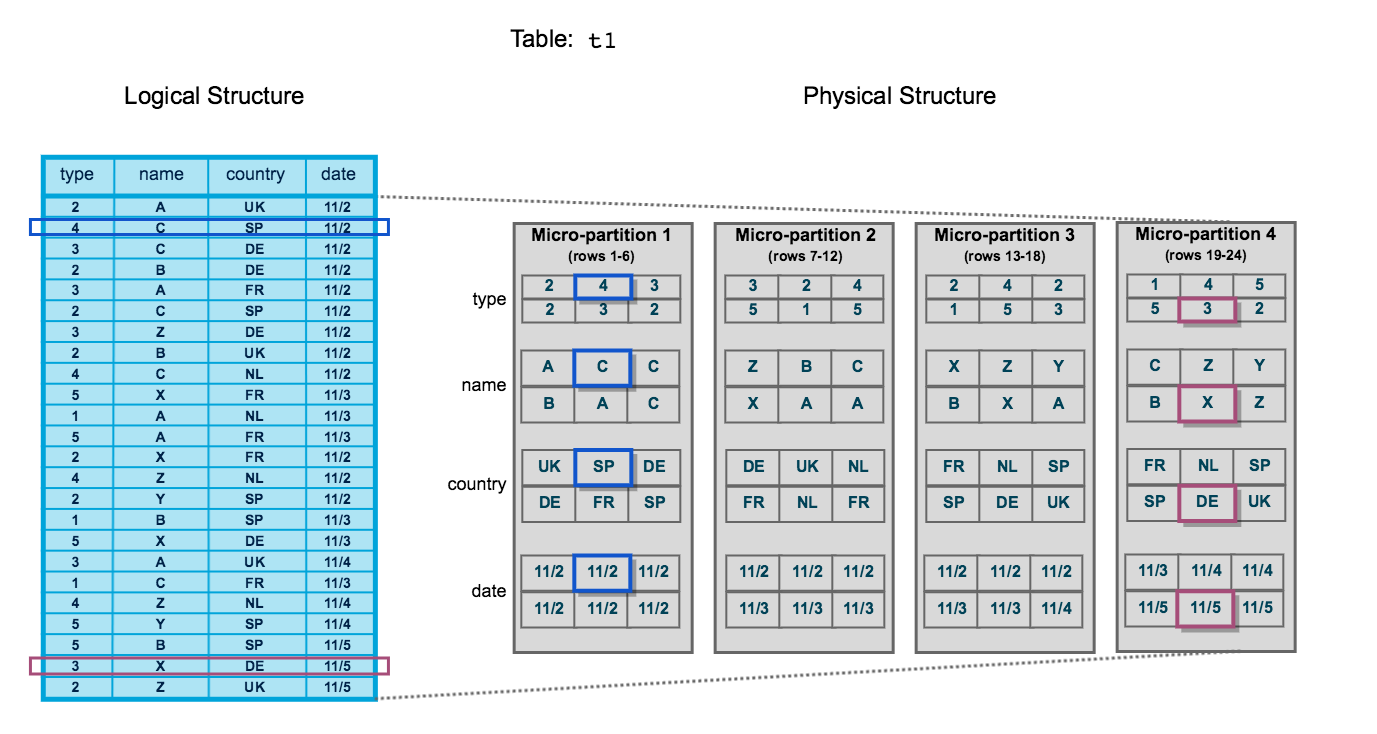
Die Tabelle besteht aus 24 Zeilen, die in 4 Mikropartitionen gespeichert sind, wobei die Zeilen zwischen den einzelnen Mikropartitionen gleich verteilt sind. Innerhalb jeder Mikropartition werden die Daten nach Spalte sortiert und gespeichert, sodass Snowflake die folgenden Aktionen für Abfragen in der Tabelle ausführen kann:
Ersten: Abtrennen der Mikropartitionen, die für die Abfrage nicht benötigt werden.
Zweitens: Abtrennen nach Spalte in den verbleibenden Mikropartitionen.
Beachten Sie, dass dieses Abbildung nur eine kleine konzeptuelle Darstellung des natürlichen Daten-Clusterings ist, das Snowflake in Mikropartitionen verwendet. Eine typische Snowflake-Tabelle kann aus Tausenden, sogar Millionen von Mikropartitionen bestehen.
Für Mikropartitionen gewartete Clustering-Informationen¶
Snowflake verwaltet Clustering-Metadaten für die Mikropartitionen in einer Tabelle, einschließlich:
Die Gesamtanzahl der Mikropartitionen, aus denen die Tabelle besteht.
Die Anzahl der Mikropartitionen, die Werte enthalten, die sich überlappen (in einer angegebenen Teilmenge von Tabellenspalten).
Die Tiefe der sich überlappenden Mikropartitionen.
Clustering-Tiefe¶
Mit der Clustering-Tiefe einer ausgefüllten Tabelle wird die durchschnittliche Tiefe (1 oder größer) der sich überlappenden Mikropartitionen für angegebene Spalten einer Tabelle gemessen. Je kleiner die durchschnittliche Tiefe ist, desto besser ist die Tabelle in Bezug auf die angegebenen Spalten geclustert.
Die Clustering-Tiefe kann für verschiedene Zwecke verwendet werden, darunter:
Überwachen des Clustering-Zustands einer großen Tabelle, insbesondere im Laufe der Zeit, wenn auf der Tabelle DML ausgeführt wird.
Bestimmen, ob eine große Tabelle vom expliziten Definieren der Gruppierungsschlüssel profitieren würde.
Eine Tabelle ohne Mikropartitionen (d. h. eine nicht ausgefüllte/leere Tabelle) hat eine Clustering-Tiefe von 0.
Bemerkung
Die Clustering-Tiefe einer Tabelle ist kein absolutes oder genaues Maß dafür, ob die Tabelle gut geclustert ist. Letztendlich ist die Abfrageleistung der beste Indikator dafür, wie gut eine Tabelle geclustert ist:
Wenn Abfragen für eine Tabelle wie gefordert oder erwartet ausgeführt werden, ist die Tabelle wahrscheinlich gut geclustert.
Wenn sich die Abfrageleistung im Laufe der Zeit verschlechtert, ist die Tabelle wahrscheinlich nicht mehr gut geclustert und würde von einem Clustering profitieren.
Beispiel für die Clustering-Tiefe¶
Die folgende Abbildung zeigt ein Konzeptbeispiel für eine Tabelle, die aus fünf Mikropartitionen mit Werten zwischen A und Z besteht, und veranschaulicht, wie sich die Überlappung auf die Clustering-Tiefe auswirkt:
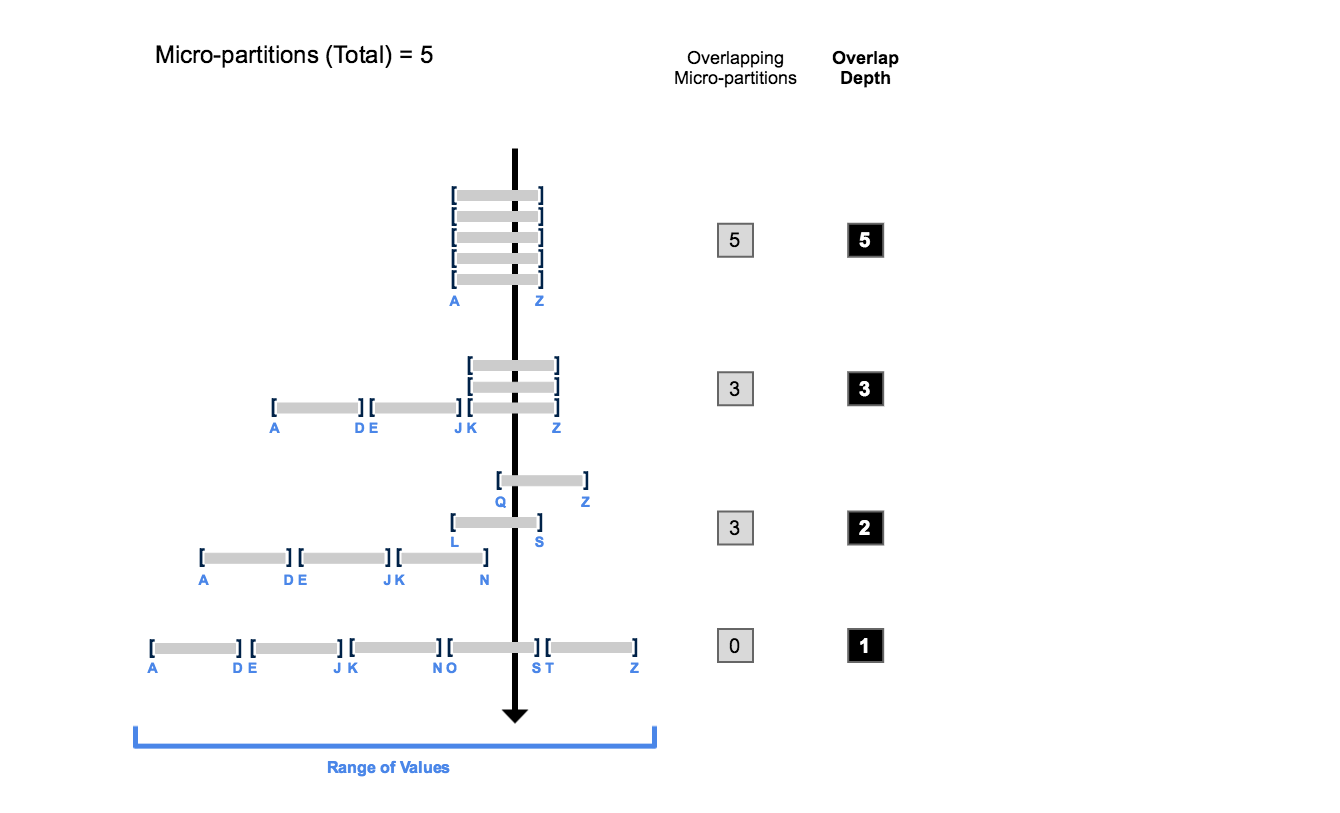
Die Abbildung zeigt Folgendes:
Zu Beginn überlappen sich die Wertebereiche in allen Mikropartitionen.
Wenn die Zahl der sich überlappenden Mikropartitionen abnimmt, verringert sich die Überlappungstiefe.
Wenn sich der Wertebereich über alle Mikropartitionen hinweg nicht überschneidet, wird davon ausgegangen, dass sich die Mikropartitionen in einem konstanten Zustand befinden (d. h. sie können durch Clustering nicht verbessert werden).
Die Abbildung soll keine reale Tabelle darstellen. In einer realen Tabelle, in der Daten in einer großen Anzahl von Mikropartitionen enthalten sind, ist es weder wahrscheinlich noch erforderlich, zur Verbesserung der Abfrageleistung über alle Mikropartitionen hinweg einen konstanten Zustand zu erreichen.
Überwachen von Clustering-Informationen für Tabellen¶
Um die Clustering-Metadaten für eine Tabelle anzuzeigen und zu überwachen, bietet Snowflake die folgenden Systemfunktionen:
SYSTEM$CLUSTERING_INFORMATION (einschließlich Clustering-Tiefe)
Weitere Details zur Verwendung von Clustering-Metadaten durch diese Funktionen finden Sie unter Beispiel für Clustering-Tiefe (unter diesem Thema).