Python user-defined aggregate functions¶
User-defined aggregate functions (UDAFs) take one or more rows as input and produce a single row of output. They operate on values across multiple rows to perform mathematical calculations such as sum, average, counting, finding minimum or maximum values, standard deviation, and estimation, as well as some non-mathematical operations.
Python UDAFs provide a way for you to write your own aggregate functions that are similar to the Snowflake system-defined SQL aggregate functions.
You can also create your own UDAFs using Snowpark APIs as described in Creating User-Defined Aggregate Functions (UDAFs) for DataFrames in Python.
Limitations¶
- The
aggregate_statehas a maximum size of 64 MB in a serialized version, so try to control the size of the aggregate state. - You can’t call a UDAF as a window function (in other words, with an OVER clause).
- IMMUTABLE is not supported on an aggregate function (when you use the AGGREGATE parameter). Therefore, all aggregate functions are VOLATILE by default.
- User-defined aggregate functions cannot be used in conjunction with the WITHIN GROUP clause. Queries will fail to execute.
Interface for aggregate function handler¶
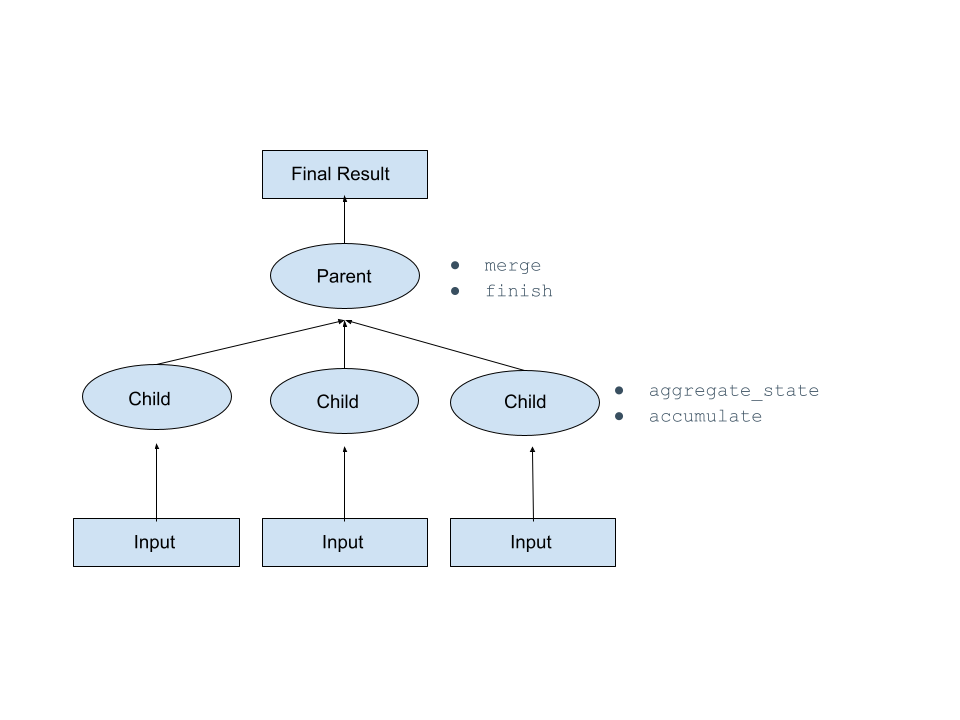
An aggregate function aggregates state in child nodes and then, eventually, those aggregate states are serialized and sent to the parent node where they get merged and the final result is calculated.
To define an aggregate function, you must define a Python class (which is the function’s handler) that includes methods that Snowflake invokes at run time. Those methods are described in the table below. See examples elsewhere in this topic.
| Method | Requirement | Description |
|---|---|---|
__init__ | Required | Initializes the internal state of an aggregate. |
aggregate_state | Required | Returns the current state of an aggregate.
|
accumulate | Required | Accumulates the state of the aggregate based on the new input row. |
merge | Required | Combines two intermediate aggregated states. |
finish | Required | Produces the final result based on the aggregated state. |
Example: Calculate a sum¶
Code in the following example defines a python_sum user-defined aggregate function (UDAF) to return the sum of the numeric values.
-
Create the UDAF.
-
Create a table of test data.
-
Call the
python_sumUDAF. -
Compare results with the output of the Snowflake system-defined SQL function, SUM, and see that the result is the same.
-
Group by sum values by the item type in the sales table.
Example: Calculate an average¶
Code in the following example defines a python_avg user-defined aggregate function to return the average of the numeric values.
-
Create the function.
-
Create a table of test data.
-
Call the
python_avguser-defined function. -
Compare results with the output of the Snowflake system-defined SQL function, AVG, and see that the result is the same.
-
Group average values by the item type in the sales table.
Example: Return only unique values¶
Code in the following example takes an array and returns an array containing only the unique values.
Example: Return a count of strings¶
Code in the following example returns counts of all instances of strings in an object.
Example: Return top k largest values¶
Code in the following example returns a list of the top largest values for k. The code accumulates negated input values on a min
heap, then returns the top k largest values.