Unload into Amazon S3¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths when unloading data from Snowflake tables. This topic describes how to use the COPY command to unload data from a table into an Amazon S3 bucket. You can then download the unloaded data files to your local file system.
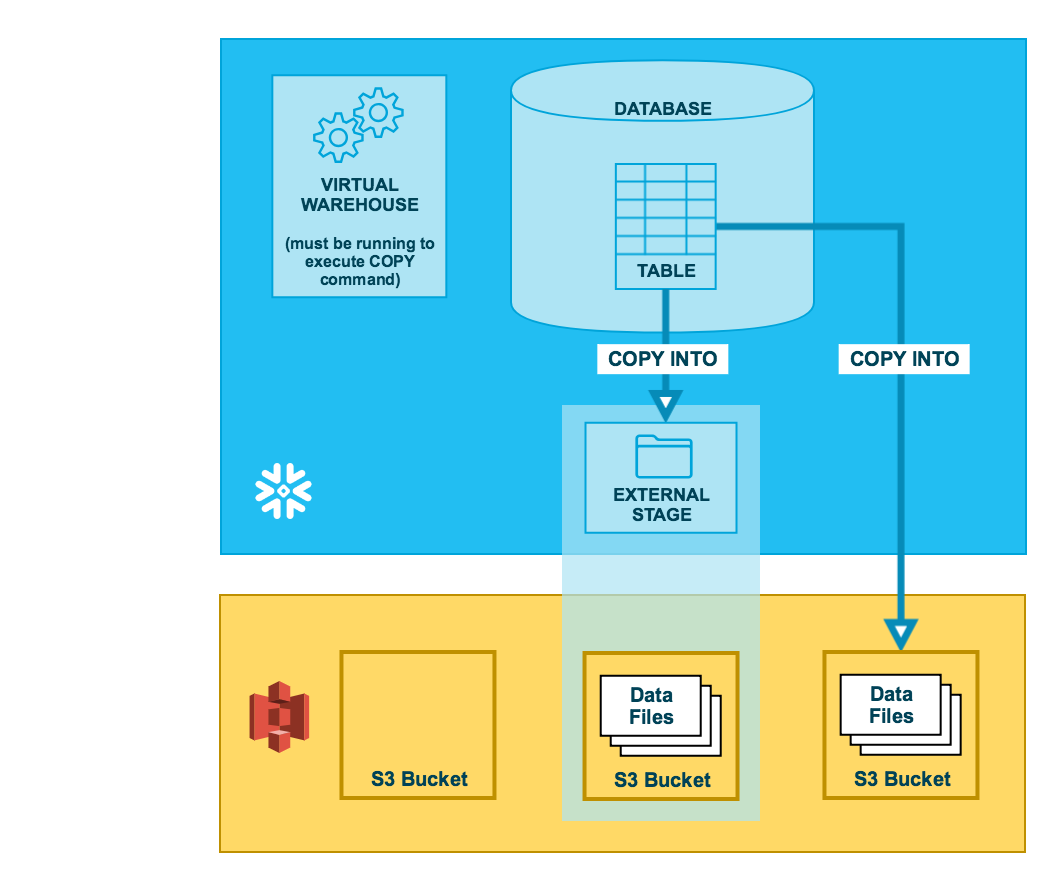
As illustrated in the diagram below, unloading data to an S3 bucket is performed in two steps:
- Step 1:
Use the COPY INTO <location> command to copy the data from the Snowflake database table into one or more files in an S3 bucket. In the command, you specify a named external stage object that references the S3 bucket (recommended) or you can choose to unload directly to the bucket by specifying the URI and either the storage integration or the security credentials (if required) for the bucket.
Regardless of the method you use, this step requires a running, current virtual warehouse for the session if you execute the command manually or within a script. The warehouse provides the compute resources to write rows from the table.
- Step 2:
Use the interfaces/tools provided by Amazon to download the files from the S3 bucket.
Tip
The instructions in this set of topics assume you have read File formats to unload data and have created a named file format, if desired.
Before you begin, you may also want to read Data unloading considerations for best practices, tips, and other guidance.
Allow the Amazon Virtual Private Cloud IDs¶
If an AWS administrator in your organization has not explicitly granted Snowflake access to your AWS S3 storage account, you can do so now. Follow the steps in Allowing the Virtual Private Cloud IDs in the data loading configuration instructions.
Configure an S3 bucket for unloading data¶
Snowflake requires the following permissions on an S3 bucket and folder to create new files in the folder (and any sub-folders):
s3:DeleteObjects3:PutObject
As a best practice, Snowflake recommends configuring a storage integration object to delegate authentication responsibility for external cloud storage to a Snowflake identity and access management (IAM) entity.
For configuration instructions, see Configuring secure access to Amazon S3.
(Optional) Configure support for Amazon S3 access control lists¶
Snowflake storage integrations support AWS access control lists (ACLs) to grant the bucket owner full control. Files created in Amazon S3 buckets from unloaded table data are owned by an AWS Identity and Access Management (IAM) role. ACLs support the use case where IAM roles in one AWS account are configured to access S3 buckets in one or more other AWS accounts. Without ACL support, users in the bucket-owner accounts could not access the data files unloaded to an external (S3) stage using a storage integration. When users unload Snowflake table data to data files in an external (S3) stage using COPY INTO <location>, the unload operation applies an ACL to the unloaded data files. The data files apply the "s3:x-amz-acl":"bucket-owner-full-control" privilege to the files, granting the S3 bucket owner full control over them.
Enable ACL support in the storage integration for an S3 stage via the optional STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' parameter. A storage integration is a Snowflake object that stores a generated identity and access management (IAM) user for your S3 cloud storage, along with an optional set of allowed or blocked storage locations (that is, S3 buckets). An AWS administrator in your organization adds the generated IAM user to the role to grant Snowflake permissions to access specified S3 buckets. This feature allows users to avoid supplying credentials when creating stages or loading data. An administrator can set the STORAGE_AWS_OBJECT_ACL parameter when creating a storage integration (using CREATE STORAGE INTEGRATION) or later (using ALTER STORAGE INTEGRATION).
Unload data into an external stage¶
External stages are named database objects that provide the greatest degree of flexibility for data unloading. Because they are database objects, privileges for named stages can be granted to any role.
You can create an external named stage using either Snowsight or SQL:
- Snowsight:
In the navigation menu, select Catalog » Database Explorer » <db_name> » Stages » Create
- SQL:
Create a named stage¶
Snowflake uses multipart uploads when uploading to Amazon S3 and Google Cloud Storage. This process might leave incomplete uploads in the storage location for your external stage.
To prevent incomplete uploads from accumulating, we recommend that you set a lifecycle rule. For instructions, see the Amazon S3 or Google Cloud Storage documentation.
The following example creates an external stage named my_ext_unload_stage using an S3 bucket named unload with a
folder path named files. The stage accesses the S3 bucket using an existing storage integration named s3_int.
The stage references a named file format object called my_csv_unload_format. For instructions, see File formats to unload data.
Unload data to the named stage¶
-
Use the COPY INTO <location> command to unload data from a table into an S3 bucket using the external stage.
The following example uses the
my_ext_unload_stagestage to unload all the rows in themytabletable into one or more files into the S3 bucket. Ad1filename prefix is applied to the files: -
Use the S3 console (or equivalent client application) to retrieve the objects (that is, files generated by the command) from the bucket.
Unload data directly into an S3 bucket¶
-
Use the COPY INTO <location> command to unload data from a table directly into a specified S3 bucket. This option works well for ad hoc unloading, when you aren’t planning regular data unloading with the same table and bucket parameters.
You must specify the URI for the S3 bucket and the storage integration or credentials for accessing the bucket in the COPY command.
The following example unloads all the rows in the
mytabletable into one or more files with the folder path prefixunload/in themybucketS3 bucket:Note
In this example, the referenced S3 bucket is accessed using a referenced storage integration named
s3_int. -
Use the S3 console (or equivalent client application) to retrieve the objects (that is, files generated by the command) from the bucket.