Dynamic tables¶
Dynamic tables are tables that automatically refresh based on a defined query and target freshness, simplifying data transformation and pipeline management without requiring manual updates or custom scheduling.
When creating a dynamic table, you define a query that specifies how data should be transformed from base objects. Snowflake then handles the refresh schedule of the dynamic table, automatically updating it with changes made to the base objects based on the query.
How dynamic tables work¶
Dynamic tables are updated through an automated refresh process that executes the transformation query on a regular basis. This process computes the changes made to the base objects and merges them into the dynamic table using compute resources associated with the table.
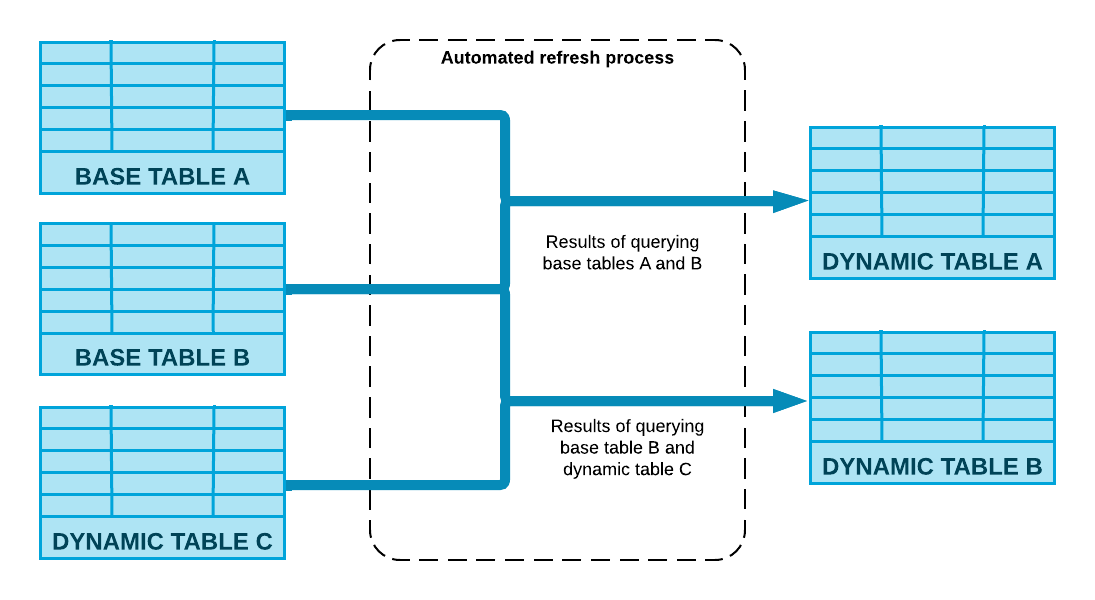
The refresh frequency and freshness of the data are determined by the target lag specified during the creation of the dynamic table, which defines how up-to-date the data should be. The refresh process uses the specified target lag to schedule updates. For example, a target lag of five minutes ensures that the data in the dynamic table is no more than five minutes behind updates to the base table.
Longer target lags can be used to reduce costs when near real-time data updates are not necessary. For example, if your dynamic table’s data just needs to be at most one hour behind the updates to the base tables, you can specify a target freshness of one hour (instead of five minutes) to reduce costs.
For more information, see Understanding dynamic table target lag and Understanding dynamic table initialization and refresh.
When to use dynamic tables¶
Dynamic tables are ideal for scenarios where:
You want to avoid manually tracking data dependencies and managing refresh schedules.
You need to materialize query results from multiple base tables without writing custom code.
You need to build multiple tables for data transformations in a pipeline.
You don’t need fine-grained control over refresh schedules, and you only need to specify a target freshness for the pipeline.
You want to use a dynamic table as the source of a stream.
Example use cases¶
Slowly changing dimensions (SCDs): Dynamic tables can be used to implement Type 1 and Type 2 SCDs by reading from a change stream and using window functions over per-record keys ordered by a change timestamp. This method handles insertions, deletions, and updates that occur out of order, simplifying the creation of SCDs. For more information, see Slowly Changing Dimensions with Dynamic Tables.
Batch to streaming transitions: Dynamic tables support seamless transitions from batch to streaming with a single ALTER DYNAMIC TABLE command. You can control the refresh frequency in your pipeline to balance cost and data freshness.
Key considerations¶
Declarative SQL: Dynamic tables enable you to define pipeline outcomes declaratively, without managing transformation steps manually.
Automated refresh: Snowflake handles the orchestration of data refreshes, including scheduling and execution, based on your target freshness requirements.
Performance optimization: Dynamic tables use incremental processing for workloads that support it, which can improve performance by updating only the data that has changed, rather than performing a full refresh.