Guide de migration de Databricks vers Snowflake¶
Framework de migration Snowflake¶
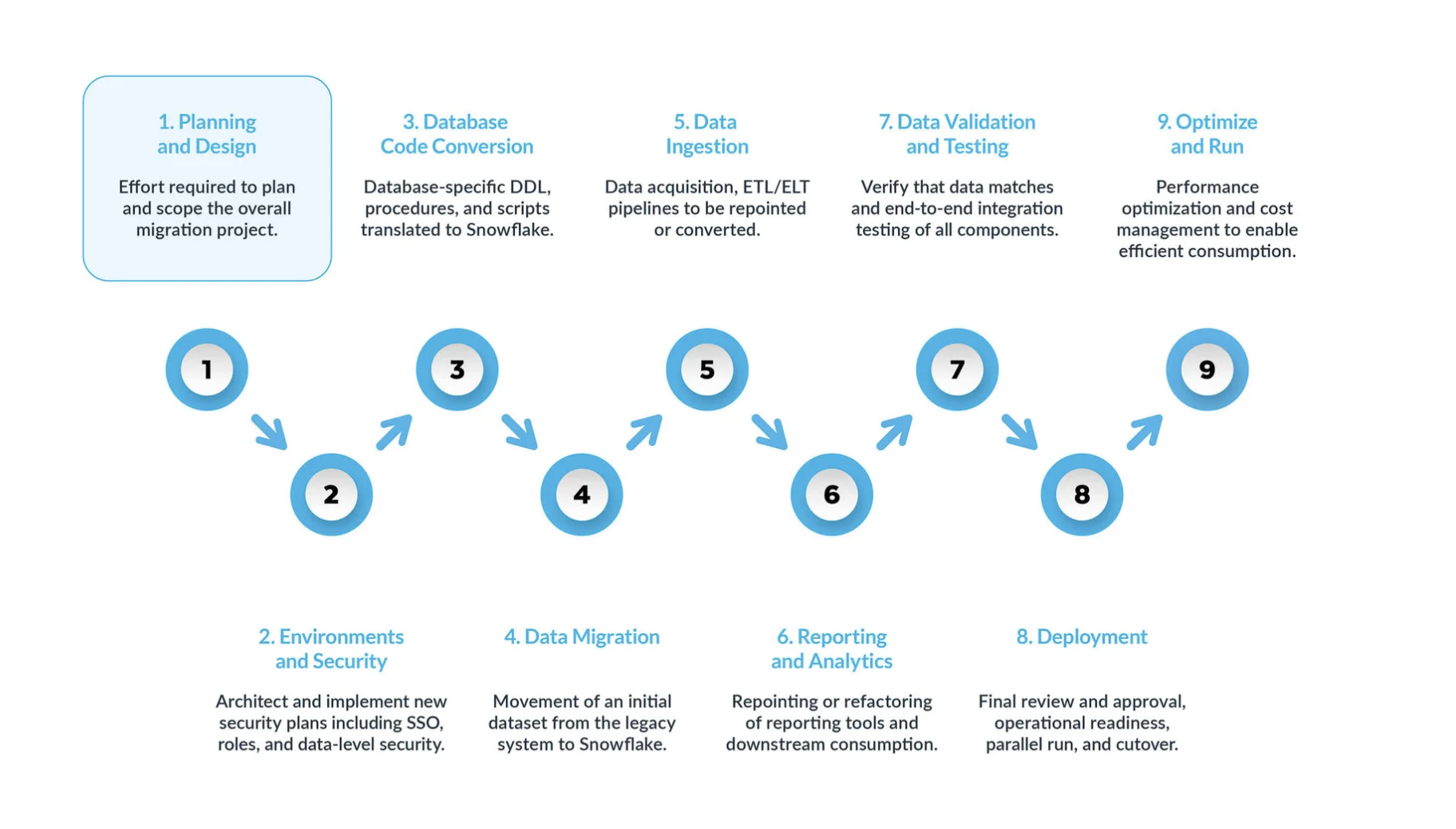
Une migration Databricks vers Snowflake standard peut être divisée en cinq étapes clés :
La planification et la conception sont souvent négligées dans le processus de migration. La principale raison est que les entreprises souhaitent généralement afficher rapidement la progression, même si elles n’ont pas bien compris la portée du projet. C’est pourquoi cette phase est essentielle pour comprendre et hiérarchiser le projet de migration.
Environnement et sécurité avec un plan, un calendrier clair, une matrice RACI, et l’adhésion de toutes les parties prenantes. Il est temps de passer en mode exécution. La mise en place des environnements et des mesures de sécurité nécessaires pour commencer la migration est très importante avant de démarrer la phase de migration, étant donné qu’il y a de nombreuses parties mobiles, et cela aura plus d’impact pour le projet de migration si toutes vos configurations sont prêtes avant d’aller plus loin.
Le processus de conversion du code de la base de données implique l’extraction du code directement depuis le catalogue de la base de données des systèmes sources, tels que les définitions de table, les vues, les procédures stockées et les fonctions. Une fois extrait, vous migrez l’ensemble de ce code vers des langages de définition de données équivalents (DDLs) dans Snowflake. Cette étape comprend également la migration des scripts du langage de manipulation des données (DML), qui peuvent être utilisés par les analystes commerciaux pour créer des rapports ou des tableaux de bord. Tout ce code doit être migré et ajusté pour fonctionner dans Snowflake. Les ajustements peuvent aller de changements simples, tels que les conventions de dénomination et les mappages de types de données, à des différences plus complexes dans la syntaxe, la sémantique de plateforme et d’autres facteurs. Pour y remédier, Snowflake propose une solution puissante appelée SnowConvert AI, qui automatise une grande partie du processus de conversion du code de la base de données.
Migration de données La migration de données implique le transfert de données entre différents systèmes de stockage, formats ou systèmes informatiques. Dans le contexte d’une migration de Databricks vers Snowflake, il s’agit spécifiquement du déplacement de données de votre environnement Databricks vers votre nouvel environnement Snowflake.
Ce guide présente deux principaux types de :
Migration des données historiques : instantané de vos données Databricks à un moment précis et transfert vers Snowflake. Il s’agit souvent d’un transfert initial en masse.
Migration des données incrémentielles : déplacement continu de données nouvelles ou modifiées de Databricks vers Snowflake après la migration historique initiale. Cela garantit que votre environnement Snowflake reste à jour avec vos systèmes sources.
Ingestion des données : après la migration des données historiques, l’étape suivante consiste à migrer le processus d’ingestion de données, en intégrant des données dynamiques provenant de diverses sources. En règle générale, ce processus suit un modèle d’extraction, transformation, chargement (ETL) ou d’extraction, changement, transformation (ELT), en fonction du moment et de l’endroit où la transformation des données se produit avant qu’elle ne soit disponible pour les utilisateurs professionnels.
Rapports et analyses : maintenant que la base de données contient à la fois des données historiques et des pipelines dynamiques qui importent continuellement de nouvelles données, l’étape suivante consiste à extraire de la valeur de ces données via BI. Les rapports peuvent être effectués à l’aide des outils BI standard ou de requêtes personnalisées. Dans les deux cas, le SQL envoyé à la base de données peut devoir être ajusté pour répondre aux exigences de Snowflake. Ces ajustements peuvent aller de simples modifications de nom (communes lors de la migration) à des différences de syntaxe et sémantiques plus complexes. Tous ces problèmes doivent être identifiés et traités.
Validation et test des données : l’objectif consiste à ce que les données soient aussi propres que possible avant d’entamer cette phase. Chaque organisation possède ses propres méthodologies de test et ses propres exigences pour passer des données en production. Celles-ci doivent être bien comprises dès le début du projet.
Déploiement : à ce stade, les données sont validées, un système équivalent est mis en place, tous les ETLs ont été migrés et les rapports ont été vérifiés. Prêt pour la mise en production ? Encore un peu de patience - il y a encore quelques considérations critiques avant la mise en production finale. Tout d’abord, votre application existante peut consister en plusieurs composants ou services. Idéalement, vous devriez migrer ces applications une par une (bien que la migration parallèle soit possible) et les passer en production dans le même ordre. Au cours de ce processus, assurez-vous que votre stratégie de « pont » est en place afin que les utilisateurs professionnels n’aient pas à interroger à la fois Snowflake et le système existant. La synchronisation des données pour les applications qui n’ont pas encore été migrées doit se faire en arrière-plan via le mécanisme de pont. Si cela n’est pas fait, les utilisateurs professionnels devront travailler dans un environnement hybride, et ils doivent comprendre les implications de cette configuration.
Optimisation et exécution une fois qu’un système a été migré vers Snowflake, il passe en mode de maintenance normale. Tous les systèmes logiciels sont des organismes vivants qui nécessitent une maintenance continue. Cette phase, après la migration, est appelée optimisation et exécution, et elle ne fait pas partie de la migration elle-même.
¶
** Phases clés **¶
Une migration Databricks vers Snowflake typique peut être décomposée en plusieurs phases clés, chacune ayant des objectifs et des considérations distinctes. Suivre ces phases vous garantit une transition structurée et réussie.
Phase 1 : Planification et conception¶
Cette phase initiale est cruciale pour une migration réussie. Elle pose les bases en définissant la portée, les objectifs et les exigences de votre projet. Cela implique une compréhension profonde de votre environnement Databricks actuel et une vision claire de l’état futur dans Snowflake.
Vos étapes exploitables :¶
** Réalisez une évaluation complète de votre environnement Databricks :** Cela implique plus qu’un simple inventaire technique. Il s’agit d’un exercice stratégique pour identifier la « dette technique » et découvrir les possibilités de rationalisation et de simplification du domaine des données.
Inventaire des données existantes : identifiez et documentez de manière approfondie toutes les ressources Databricks, y compris les bases de données, les tables (en particulier les tables Delta Lake), les vues, les notebooks (catégorisés par langage : Python, Scala, SQL), les tâches, les workflows,les fonctions définies par l’utilisateur (UDFs), et les intégrations externes.
Analyse des charges de travail des requêtes : utilisez les outils de surveillance et les journaux de Databricks pour identifier les requêtes fréquemment exécutées et gourmandes en ressources. Ces requêtes seront essentielles pour la validation des performances après la migration.
Classification des actifs de données : faites la distinction entre les données de production et de non-production, identifiez les objets actifs par rapport aux objets obsolètes, et identifiez les actifs redondants qui peuvent être exclus de la migration. Cela réduit considérablement le volume de données et de code à migrer, ce qui permet de réduire les efforts, le temps et les coûts.
Évaluation des exigences de sécurité et de conformité : identifiez les données sensibles, les obligations réglementaires (par exemple GDPR, HIPAA), et les vulnérabilités potentielles dans l’environnement Databricks existant. Ces informations sont essentielles pour concevoir une configuration de sécurité robuste dans Snowflake.
Définition d’objectifs de migration et de métriques de réussite clairs : ne pas définir clairement ces objectifs peut conduire à des « objectifs mouvants » et à l’échec du projet.
Articulation des facteurs stratégiques : indiquez clairement les moteurs stratégiques (par exemple, la réduction des coûts, l’amélioration des performances de BI, la simplification des opérations, l’amélioration de la gouvernance) et les objectifs techniques pour migrer vers Snowflake.
Établissement de paramètres de réussite mesurables : Définissez des métriques quantifiables pour suivre les progrès réalisés et démontrer le ROI, comme l’amélioration des performances des requêtes (par exemple, la latence moyenne des requêtes a été réduite de X), les économies quantifiables (par exemple, la réduction de Y % des dépenses mensuelles de Cloud), une diminution mesurable des incidents opérationnels, l’augmentation des scores de confiance des utilisateurs et l’exactitude des données vérifiée.
** Choix de votre approche de la migration : Migration par phase ou complète (Big Bang) :** la sélection d’une stratégie de migration est fondamentalement une décision de gestion des risques.
Migration par phase : cette approche implique le déplacement des données et des charges de travail dans des segments plus petits et plus faciles à gérer (par domaine, Datamart, unité commerciale ou application). Elle est vivement recommandée pour bénéficier d’un temps d’arrêt nul ou minimal, permettant des tests continus, un apprentissage itératif et un déplacement graduel de la charge de travail. Cette approche facilite les exécutions parallèles pour une validation approfondie.
Migration complète (Big Bang) : cette approche implique la migration de l’ensemble des données et charges de travail en une seule fois, suivie d’un changement immédiat. Bien que potentiellement plus rapide pour les systèmes très simples, elle comporte un risque élevé de problèmes imprévus et est généralement moins sûre pour ne subir aucun temps d’arrêt.
Établissement d’un cadre solide de préparation à la migration : la participation précoce et continue de toutes les parties prenantes est essentielle.
Conduite d’une évaluation officielles de la préparation à la migration (MRA) : impliquez une équipe interfonctionnelle d’experts (conversion de code, migration de données, ingestion de données, validation des données, rapports et analyse) et de représentants commerciaux et techniques.
Développement d’un calendrier de projet détaillé et d’une matrice RACI : veillez à définir les rôles et les responsabilités pour toutes les tâches de migration.
** Adhésion explicite :** obtenez l’adhésion de toutes les principales parties prenantes, y compris les cadres supérieurs et les utilisateurs professionnels. Une migration techniquement sans faille peut toujours échouer si les utilisateurs professionnels ne sont pas correctement préparés, formés ou impliqués.
Phase 2 : Environnement et sécurité¶
La configuration des environnements et des mesures de sécurité nécessaires est une étape précoce essentielle avant de commencer la migration. Snowflake fonctionne selon un modèle de sécurité partagé entre la plateforme et les administrateurs.
Vos étapes exploitables :
Configuration des environnements : décidez du nombre de comptes Snowflake nécessaires. Au minimum, configurez un environnement de production et de développement. En fonction de votre stratégie, envisagez des environnements supplémentaires pour différentes zones de préparation de test.
Mise en œuvre des mesures de sécurité :
commencez par des politiques réseau pour garantir que seuls les utilisateurs autorisés dans votre VPN peuvent accéder au système Snowflake.
Définissez des rôles en fonction des besoins de l’entreprise, car le contrôle d’accès des utilisateurs de Snowflake est basé sur les rôles.
Créez des comptes utilisateur et appliquez l’authentification multifactorielle (MFA) et/ou la connexion unique (SSO) pour tous les utilisateurs.
Configurez des comptes de service sans vous fier à l’authentification traditionnelle par nom d’utilisateur/mot de passe.
Définition des rôles pendant la migration : définissez des rôles spécifiques pour votre équipe de migration. Même dans les environnements de non-production, où l’équipe peut avoir une plus grande liberté, n’oubliez pas que vous traiterez avec des données réelles, afin de maintenir une sécurité solide.
Réflexion sur votre modèle d’accès : utilisez cette migration pour nettoyer et optimiser votre hiérarchie d’accès, en veillant à ce que seuls les utilisateurs nécessaires aient accès à des ressources spécifiques.
Coordination avec les finances : collaborez avec votre équipe financière pour suivre l’utilisation de Snowflake par département, en utilisant le modèle de tarification basé sur la consommation de Snowflake et le balisage des objets pour l’attribution des coûts.
Phase 3 : Conversion du code de base de données¶
Cette phase se concentre sur la conversion du code de votre base de données Databricks (DDL, SQL, Spark code) vers un SQL compatible avec Snowflake et Snowpark.
Vos étapes exploitables :
Mappage des types de données Databricks Spark sur des types de données Snowflake :
identifiez et mappez soigneusement les types de données Databricks (Spark) sur les équivalents Snowflake les plus appropriés. Soyez attentif à la précision, à l’échelle et aux fuseaux horaires pour les types complexes (par exemple TimestampType en TIMESTAMP_NTZ, TIMESTAMP_LTZ, ou TIMESTAMP_TZ).
Notez que ByteType effectue un mappage sur un INTEGER de Snowflake, et que LongType (64 bits) vers INTEGER (32 bits) peut nécessiter des contrôles de plage pour éviter toute troncation.
ArrayType et MapType sont généralement mappés sur le type de données VARIANT de Snowflake.
Traduction du langage de définition de données (DDL) pour les tables et les vues :
extrayez des scripts DDL existants de votre environnement Databricks, généralement de tables Delta Lake.
Ajustez le DDL extrait pour une compatibilité complète avec le dialecte SQL de Snowflake, en supprimant ou en recréant des fonctionnalités spécifiques à Databricks (par exemple, propriétés de la table Delta Lake, schémas de partitionnement spécifiques au-delà des clés de clustering).
Considérez les possibilités de réorganisation des schémas, comme la division de grands schémas en plusieurs bases de données ou schémas Snowflake pour une meilleure séparation logique et un meilleur contrôle d’accès.
Conversion du SQL Databricks et du Spark Code en SQL Snowflake et Snowpark :
SQL Databricks en SQL Snowflake : L’AI Snowconvert prend désormais en charge l’évaluation et la traduction du SQL Spark et du SQL Databricks pour les TABLES et les VIEWS.
Code Spark (PySpark/Scala) en Snowpark : conversion du code PySpark ou Scala des notebooks et des tâches Databricks en API Snowpark de Snowflake (Python, Java, Scala). Les DataFrames Snowpark offrent des fonctionnalités similaires aux DataFrames Spark (filtrer, sélectionner, joindre, grouper par, agréger), visant à apporter la logique de traitement directement aux données dans Snowflake.
Fonctions définies par l’utilisateur (UDFs) : réimplémentez les UDFs Databricks (Python, Scala) comme les UDFs Snowflake (SQL, JavaScript, Python, Java, Scala). Les UDFs Spark peuvent nécessiter une réingénierie importante pour tirer parti efficacement de Snowpark.
Logique d’orchestration : recréation et réimplémentation de la logique d’orchestration des tâches Databricks, des workflows et des tables Delta Live Tables (DLT) dans Snowflake en utilisant des fonctionnalités natives telles que les flux et les tâches pour les transformations incrémentielles et la planification. Vous pouvez également rediriger des orchestrateurs externes (par exemple, Airflow) vers Snowflake, en réécrivant tout code intégré spécifique à Databricks.
Phase 4 : Migration des données¶
La migration des données est le processus de transfert d’ensembles de données existants de l’environnement Databricks vers Snowflake. Cette phase implique généralement à la fois le transfert de données historiques en masse et l’ingestion de données incrémentielles en continu.
Vos étapes exploitables :
Extraction des données de Databricks :
pour les tables Delta Lake Tables, générez des fichiers manifestes en utilisant Apache Spark, qui pointent vers les fichiers de données Parquet sous-jacents que Snowflake peut lire directement.
Pour les grandes tables, partitionnez les exportations de données pour un traitement parallèle efficace.
Tirez parti du connecteur Snowflake natif de Databricks pour lire directement les données de Databricks et les écrire dans un stockage Cloud (par exemple AWS S3, Azure Blob Storage) comme zone de mise en zone de préparation pour Snowflake.
Ajoutez une colonne d’horodatage pour l’heure de l’ingestion et une colonne de nom du système source pour maintenir la traçabilité et le contrôle dans Snowflake.
Chargement de données dans Snowflake :
utilisez la commande COPY INTO de Snowflake pour le chargement en masse de données à partir de zones de préparation externes (emplacements de stockage Cloud) dans des tables Snowflake.
Pour des performances optimales avec les fichiers Parquet, utilisez le scanner vectorisé de Snowflake (définissez USE_VECTORIZED_SCANNER dans la commande COPY, ou attendez-vous à ce qu’elle soit la commande par défaut à l’avenir).
Les meilleures pratiques de chargement :
Optimisation de la taille des fichiers : créez des fichiers dans la plage de 100-250MB avec compression (par exemple, Snappy pour Parquet) pour un débit optimal.
Purge des fichiers en zone de préparation : utilisez PURGE=TRUE dans la commande COPY pour supprimer les fichiers de la zone de préparation après un chargement réussi, en optimisant les performances et en gérant les coûts de stockage.
Traitement des erreurs : utilisez ON_ERROR=”CONTINUE” dans la commande COPY pour les fichiers volumineux contenant des données potentiellement négatives, permettant à de bonnes données de se charger tout en ignorant les lignes problématiques.
Zones de préparation internes : envisagez d’utiliser les zones de préparation internes de Snowflake pour un chargement plus rapide par rapport aux zones de préparation externes, mais comparez les coûts de stockage.
Pour le chargement de données incrémentiel, implémentez les pipelines Change Data Capture (CDC) pour répliquer des pipelines nouveaux ou modifiés de Databricks vers Snowflake. Des outils tels que Fivetran ou Matillion peuvent automatiser ces synchronisations.
Phase 5 : ingestion des données¶
Cette phase se concentre sur la migration des processus d’ingestion de données en cours et les pipelines ETL/ELT de Databricks vers Snowflake, garantissant un flux continu de données dynamiques.
Vos étapes exploitables :
Réingénierie des workflows ETL/ELT Databricks :
effectuez une réingénierie des workflows ETL/ELT Databricks (souvent construits à l’aide de PySpark, Scala ou SQL avec des tables Delta Live Tables (DLT) ou des tâches Databricks) pour Snowflake.
Pour les ETL/ELT complexes, convertissez le code Spark en DataFrames et UDFs Snowpark (comme discuté dans la phase 1). Pour les transformations basées sur du SQL, pensez à utiliser dbt (outil de construction de données) pour les transformations au sein de Snowflake.
Exploitation des fonctionnalités natives Snowflake :
Flux et tâches : utilisez des flux pour enregistrer les modifications de DML pour le traitement incrémentiel et des tâches pour planifier des instructions SQL ou des procédures stockées pour les transformations incrémentielles et l’orchestration directement dans Snowflake.
Snowpipe : pour le chargement continu et en temps réel de nouvelles données, utilisez Snowpipe pour les flux en continu. Pour le chargement par lots, la commande COPY reste une option puissante.
**Snowpipe Streaming :**idéal pour les cas d’utilisation du streaming à faible latence.
Réalignement des sources et des puits de données :
redirigez plusieurs sources de données entrantes qui aboutissent actuellement dans Databricks vers des modèles d’ingestion Snowflake en configurant des connecteurs ou des processus d’ingestion personnalisés pour qu’ils pointent directement vers des zones de préparation ou des tables Snowflake.
Élaborez un plan pour rediriger les systèmes en aval (par ex., outils BI, autres applications) qui effectuent actuellement une lecture de Databricks à Snowflake une fois que les pipelines de données se sont stabilisés et que la validation des données est terminée.
Phase 6 : rapports et transition des analyses¶
Cette phase a pour objectif de s’assurer que les outils de Business Intelligence (BI) et d’analyse continuent de fonctionner correctement et de manière optimale avec Snowflake comme nouvelle source de données.
Vos étapes exploitables :
Ajustement des outils de BI et des requêtes personnalisées :
redirigez ou refactorisez les outils de rapport existants (par exemple, Tableau, Power BI, Looker) et ajustez les requêtes personnalisées qui s’exécutaient précédemment sur Databricks.
Ajustez les requêtes SQL envoyées à la base de données pour les exigences de Snowflake, qui peuvent aller du simple changement de nom à la syntaxe et aux différences sémantiques plus complexes.
** Activation des utilisateurs professionnels et formation : **
incluez les utilisateurs professionnels en tant que parties prenantes clés dans le processus de migration (par exemple, dans la matrice RACI lors de la planification). Leur acceptation est cruciale pour une transition complète hors de la plateforme héritée.
Formez les utilisateurs professionnels au fonctionnement de Snowflake et assurez-vous qu’ils comprennent bien les différences entre les plateformes. Cela leur permettra de modifier leurs requêtes et rapports personnalisés selon leurs besoins.
Envisagez un suivi de formation parallèle pour les utilisateurs professionnels, suivi d’heures de bureau avec des experts en migration, pour aider à répondre aux différences entre les plateformes et guider les utilisateurs à travers les ajustements nécessaires.
Phase 7 : validation et test des données¶
La validation et les tests des données sont souvent sous-estimés dans le processus de planification de la migration, alors qu’ils sont essentiels pour garantir l’intégrité et la précision des données dans le nouvel environnement Snowflake. L’objectif est que les données soient aussi propres que possible avant d’entrer dans cette phase.
Vos étapes exploitables :
Exécution de stratégies de tests complètes : chaque organisation possède ses propres méthodologies et exigences en matière de test pour passer des données en production, qui doivent être pleinement comprises dès le début du projet.
Tests fonctionnels : vérifiez que toutes les applications et fonctionnalités migrées fonctionnent comme prévu dans le nouvel environnement, en garantissant l’intégrité et la précision des données. Cela comprend de vérifier que les ETLs et les rapports migrés produisent des résultats corrects.
Test des performances : évaluez les performances des requêtes, la vitesse de chargement des données et la réactivité globale du système. Cela permet d’identifier et de remédier à tout goulot d’étranglement dans Snowflake, en s’assurant que la nouvelle plateforme répond ou dépasse les attentes en matière de performances.
User Acceptance Testing (Test d’acceptation utilisateur) (UAT : impliquez les utilisateurs finaux dans le processus de test pour vous assurer que le système migré répond à leurs exigences métier et recueillez des commentaires sur les améliorations potentielles. Cette étape est cruciale pour gagner la confiance des utilisateurs et leur adoption.
Techniques de validation des données : comparez le nombre de lignes, calculez les sommes, les maximums, les minimums et les moyennes des colonnes, et hachez les valeurs des lignes pour une association unique entre les systèmes sources (Databricks) et cibles (Snowflake). L’exécution de systèmes parallèles pendant une période permet une comparaison en temps réel.
Formation et documentation :
proposez une formation complète aux utilisateurs finaux sur les fonctionnalités et les meilleures pratiques de Snowflake, en abordant des sujets tels que l’accès aux données, l’optimisation des requêtes et la sécurité.
Créez une documentation complète, y compris des schémas d’architecture système, des schémas de flux de données, des procédures opérationnelles, des guides d’utilisateur, des guides de dépannage et des FAQs pour des recherches simples et un support continu.
Phase 8 : Déploiement - Mise en service¶
Cette étape implique des considérations critiques avant la mise en production finale, garantissant une migration fluide et coordonnée.
Vos étapes exploitables :
Planification d’un déploiement échelonné et d’une stratégie de pont :
idéalement, migrez les applications héritées une par une et passez en production dans le même ordre.
Veillez à ce qu’une stratégie de pont soit mise en place afin que les utilisateurs professionnels n’aient pas à interroger à la fois Snowflake et l’ancien système Databricks. La synchronisation des données pour les applications n’ayant pas encore migré devrait se faire en arrière-plan grâce à ce mécanisme.
Adoption des parties prenantes et signatures officielles :
lorsque vous êtes prêt pour la migration, assurez-vous que toutes les parties prenantes sont d’accord avec le fait que Snowflake devienne le système d’enregistrement, et non l’ancienne plateforme Databricks.
Obtenez les signatures finales et officielles de toutes les parties prenantes avant de poursuivre.
Mettez l’accent sur le fait que tous les rapports non migrés sont désormais la responsabilité des utilisateurs professionnels, en soulignant l’importance d’une implication précoce de l’utilisateur.
Vérifiez que toutes les autorisations ont été correctement accordées dans Snowflake, y compris tous les rôles basés sur Active Directory.
Considérations critiques pour la migration :
Clés artificielles : si vous utilisez des clés artificielles, sachez que leur cycle de vie peut varier entre les systèmes existants et les systèmes Snowflake ; ces clés doivent être synchronisées lors de la migration.
Planning de la migration : définissez le planning de migration optimal en fonction de votre secteur d’activité afin de réduire l’impact sur l’entreprise.
Mise hors service de l’ancienne plateforme : planifiez la mise hors service de l’environnement Databricks existant, y compris les considérations relatives aux politiques de licence et de conservation des données de l’ancienne plateforme.
Phase 9 : Optimisation et exécution - Amélioration continue¶
Une fois qu’un système a été migré vers Snowflake, il entre en mode de maintenance normal. Cette phase, appelée « Optimisation et exécution », ne fait pas partie de la migration elle-même, mais se concentre sur l’optimisation en cours et l’amélioration continue.
Vos étapes exploitables :
Attention portée à l’optimisation continue et à la gestion des coûts :
L’équipe est entièrement propriétaire du système dans Snowflake, avec une optimisation pilotée par les modèles d’utilisation.
Bien que les tâches dans Snowflake s’exécutent généralement plus rapidement, si les performances ne répondent pas aux attentes, des optimisations peuvent être nécessaires pour tirer pleinement parti de l’architecture unique de Snowflake.
Utilisez les outils d’analyse de requêtes de Snowflake pour identifier les goulots d’étranglement et optimiser des parties spécifiques du workflow.
Traitez uniquement les problèmes de performances critiques pendant la migration. L’optimisation plus étendue se fera après la migration.
Mise en œuvre de la gestion des coûts continus :
définissez les délais de suspension automatique des entrepôts virtuels à 60 secondes pour réduire considérablement les coûts, car Snowflake facture chaque seconde de fonctionnement de l’entrepôt avec un minimum de 60 secondes par reprise.
Réduisez la taille des entrepôts virtuels en fonction des exigences de charge de travail, car les ressources de calcul et les coûts augmentent de façon exponentielle avec la taille de l’entrepôt.
Surveillez en permanence les modèles d’utilisation et coordonnez-vous avec le service des finances pour suivre l’utilisation du département à des fins de répartition des coûts.
Amélioration de la gouvernance et de la sécurité :
Affinez le contrôle d’accès basé sur les rôles, mettez en œuvre des politiques de masquage dynamique des données et d’accès aux lignes pour les données sensibles, et auditez régulièrement les modèles d’accès.
Repensez le modèle d’accès pour clarifier la hiérarchie des utilisateurs et vous assurer que seuls les utilisateurs nécessaires ont accès à des ressources spécifiques.