DatabricksからSnowflakeへの移行ガイド¶
Snowflake移行フレームワーク¶
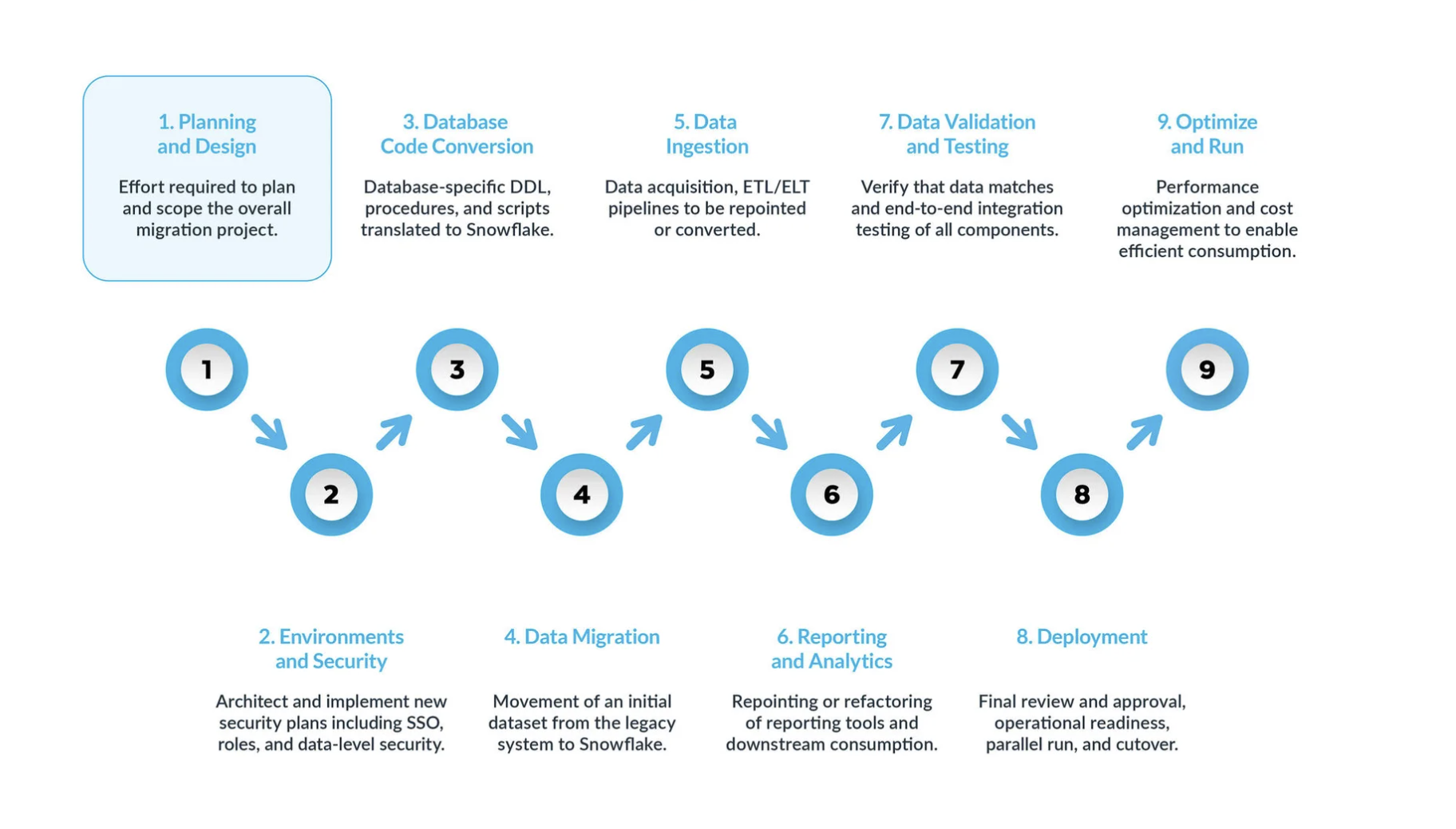
典型的なDatabricksからSnowflakeへの移行は、5つの主要ステップに分けることができます。
計画と設計 は、移行プロセスにおいて見落とされがちなステップです。その主な理由は、企業は通常、プロジェクトの範囲を完全に理解していない場合であっても、進捗状況を迅速に示したいと考えるからです。だからこそ、このフェーズは移行プロジェクトを理解し、優先順位をつけるために非常に重要なのです。
環境とセキュリティ が、計画、明確なタイムライン、 RACI マトリックス、すべての利害関係者の賛同とともに整ったら、いよいよ実行モードに移ります。 可動要素が多いことを考えると、移行を開始するために必要な環境とセキュリティ対策を設定することは、移行フェーズ開始前の非常に重要な工程です。また、移行を進める前にすべてのセットアップが完了していれば、移行プロジェクトへの影響はさらに大きくなります。
データベースコード変換 プロセスでは、テーブル定義、ビュー、ストアドプロシージャ、関数など、ソースシステムのデータベースカタログから直接コードを抽出します。いったん抽出したら、このコードをすべてSnowflakeの同等のデータ定義言語( DDLs )に移行します。このステップには、ビジネスアナリストがレポートやダッシュボードを作成するために使用するデータ操作言語( DML )スクリプトの移行も含まれます。 このコードをすべて移行し、Snowflakeで動くように調整する必要があります。その調整には、命名規則やデータ型のマッピングといった単純な変更から、構文やプラットフォームのセマンティクスなどのより複雑な違いの調整まで、さまざまなものがあります。これを支援するために、Snowflakeでは SnowConvert AI という強力なソリューションを提供し、データベースコード変換プロセスの大部分を自動化しています。
データ移行 には、異なるストレージシステム、フォーマット、またはコンピュータシステム間でデータを転送することが含まれます。DatabricksからSnowflakeへの移行という文脈では、特にDatabricks環境から新しいSnowflake環境にデータを移動することを指します。
このガイドでは、主に2つのタイプについて説明します。
過去のデータ移行: 特定の時点でDatabricksデータのスナップショットを取得し、Snowflakeに転送します。これは多くの場合、最初の一括転送として行われます。
増分データ移行: 最初に行った過去データの移行後、継続的にDatabricksからSnowflakeへ新規または変更データを移行します。これにより、Snowflake環境がソースシステムに対して常に最新の状態に保たれます。
データ取り込み: 過去データを移行した後、次のステップはデータ取り込みプロセスを移行し、様々なソースからライブデータを取り込むことです。通常、このプロセスは、ビジネスユーザーがデータを利用できるようになる前に、いつ、どこでデータ変換が行われるかによって、抽出、変換、ロード( ETL )、または抽出、ロード、変換( ELT )モデルに従って行われます。
レポーティングとアナリティクス: データベースが過去データと継続的に新しいデータをインポートするライブパイプラインの両方を備えた今、次のステップは BI を介してこのデータから値を抽出することです。レポーティングは、標準的な BI ツールまたはカスタムクエリを使用して行うことができます。どちらの場合も、データベースに送信される SQL は、Snowflakeの要件を満たすように調整する必要がある場合があります。このような調整には、単純な名前の変更(移行時によくある)から、構文やより複雑な意味の違いまで、さまざまなものがあります。これらすべてを特定し、対処する必要があります。
データの検証とテスト: このフェーズに入る前に、データを可能な限りクリーンにしておくことが目標です。 各組織には独自のテスト方法とデータを実稼働環境に移行するための要件があります。これらはプロジェクト開始当初から十分に理解されている必要があります。
デプロイ: このステージで、データが検証され、同等のシステムがセットアップされます。すべての ETLs が移行済みで、レポートは検証済みです。これで実稼働の準備は万全でしょうか。 焦ってはいけません。最終的に実稼働へと進める前に、まだいくつかの重要な検討事項があります。まず、従前のアプリケーションは複数のコンポーネントやサービスで構成されている可能性があります。理想的には、これらのアプリケーションを1つずつ移行し(並行移行も可能ですが)、同じ順番で実稼働環境に移行する必要があります。このプロセスでは、ビジネスユーザーがSnowflakeと従前のシステムの両方を照会する必要がないように、ブリッジング戦略を確実に実施します。まだ移行されていないアプリケーションのデータ同期は、このブリッジングのメカニズムを通じて舞台裏で行われる必要があります。これを行わないと、ビジネスユーザーはハイブリッド環境で作業する必要があり、この設定の影響を理解しなければならなくなります。
最適化と実行: システムがSnowflakeに移行されると、通常のメンテナンスモードに入ります。すべてのソフトウェアシステムは、継続的なメンテナンスを必要とする生きた存在です。移行後のこのフェーズは、最適化と実行と呼ばれるもので、移行自体には含まれません。
¶
主なフェーズ¶
典型的なDatabricksからSnowflakeへの移行は、いくつかの重要なフェーズに分けることができ、それぞれ明確な目的と考慮事項があります。これらのフェーズに従うことで、体系的な移行を成功に導くことができます。
フェーズ1:計画と設計¶
移行を成功させるためには、この初期フェーズが極めて重要です。プロジェクトの範囲、目的、要件を定義することで、基礎を固めます。ここでは、現在のDatabricks環境を深く理解し、Snowflakeにおける将来の状態について明確なビジョンを描く必要があります。
行動可能なステップ:¶
Databricks環境の徹底的な評価を実施する: これは単なる技術の棚卸しにとどまりません。「技術的負債」を特定し、データ資産の近代化と簡素化の機会を見出すための戦略的な取り組みです。
既存のデータ資産の棚卸しをする: データベース、テーブル(特にDelta Lakeテーブル)、ビュー、ノートブック(言語別カテゴリ:Python、Scala、 SQL )、ジョブ、ワークフロー、ユーザー定義関数( UDFs )、外部統合など、すべてのDatabricks資産を綿密に特定し、文書化します。
クエリワークロードを分析する: Databricksの監視ツールとログを活用して、頻繁に実行され、リソースを大量に消費するクエリを特定します。これらのクエリは、移行後のパフォーマンス検証に不可欠です。
データ資産を分類する: 実稼働データと非実稼働データを区別し、アクティブなオブジェクトと非推奨のオブジェクトを識別して、移行から除外できる冗長な資産を特定します。これにより、移行するデータとコードの量が大幅に削減され、労力、時間、コストを節約できます。
セキュリティとコンプライアンス要件を評価する: 既存のDatabricks環境における機密データ、規制上の義務( GDPR 、 HIPAA など)、潜在的な脆弱性を特定します。この情報は、Snowflakeで堅牢なセキュリティ設定を設計する上で非常に重要です。
明確な移行目標と成功の指標を定義する: これらの目標の正確な定義を見落とすと、「目標の不確実性」やプロジェクトの失敗につながる可能性があります。
戦略的推進要因を明確化する: Snowflakeへの移行におけるビジネスの推進要因(コスト削減、 BI パフォーマンスの向上、運用の簡素化、ガバナンスの強化など)と技術目標を明確に示します。
測定可能な成功の指標を確立する: 進捗状況を追跡し、 ROI を実証するための定量化可能な指標を定義します。たとえば、クエリパフォーマンスの向上(平均クエリレイテンシのX%削減など)、実証可能なコスト削減(月間クラウド費用のY%削減など)、運用インシデントの測定可能な減少、ユーザー満足度の向上、データ精度の検証などです。
移行アプローチを選択する:段階移行方式と一括移行方式: 移行戦略の選択は、基本的にリスク管理上の意思決定です。
段階移行方式: このアプローチでは、データとワークロードを、より小規模で管理しやすいセグメント(分野、データマート、事業部門、またはアプリケーションごと)に分割して移行します。ダウンタイムをゼロまたは最小限に抑え、継続的なテスト、反復学習、そして段階的なワークロード移行を可能にするため、このアプローチは強く推奨されます。このアプローチは、徹底的な検証のための並列実行を容易にします。
一括移行方式: このアプローチでは、すべてのデータとワークロードを一度に移行し、その後すぐに切り替えを行います。非常にシンプルなシステムであれば移行時間が短縮される可能性がありますが、予期せぬ問題が発生するリスクが高く、ダウンタイムゼロを維持するには一般的に安全性が低くなります。
堅牢な移行準備フレームワークを構築する: すべての利害関係者の早期かつ継続的な関与が不可欠です。
正式な移行準備評価( MRA )を実施する: 専門家(コード変換、データ移行、データ取り込み、データ検証、レポーティングと分析)と、ビジネス側と技術側の両方の代表者からなる部門横断的なチームを関与させます。
詳細なプロジェクトタイムラインと RACI マトリックスを作成する: すべての移行タスクにおける役割と責任を明確にします。
明確な賛同を得る: 経営幹部やビジネスユーザーを含むすべての主要な利害関係者から、最初から賛同を得てください。技術的に完璧な移行であっても、ビジネスユーザーが十分な準備、トレーニング、または関与をしていないと、失敗する可能性があります。
フェーズ2:環境とセキュリティ¶
必要な環境とセキュリティ対策をセットアップすることは、移行を開始する前の重要な初期段階です。Snowflakeはプラットフォームと管理者間での共有セキュリティモデルの下で運用されます。
行動可能なステップ:
環境をセットアップする: 必要なSnowflakeアカウントの数を決定します。最低限、実稼働環境と開発環境をセットアップします。戦略に基づき、テストステージごとに追加の環境を検討してください。
セキュリティ対策を実施する:
まず、 VPN 内の承認されたユーザーのみがSnowflakeシステムにアクセスできるように、ネットワークポリシーを設定します。
Snowflakeのユーザーアクセス制御はロールベースであるため、ビジネスニーズに基づいてロールを定義します。
ユーザーアカウントを作成し、すべてのユーザーに多要素認証( MFA )またはシングルサインオン( SSO )を強制します。
従来のユーザー名とパスワードの認証に頼ることなく、サービスアカウントを設定します。
移行中のロールを定義する: 移行チームに固有のロールを定義します。チームの自由度が高い非実稼働環境であっても、実際のデータを扱うため、堅牢なセキュリティを維持する必要があります。
アクセスモデルを再検討する: 今回の移行を利用してアクセス階層を整理および最適化し、必要なユーザーのみが特定のリソースにアクセスできるようにします。
財務部門と連携する: 財務部門と連携して、Snowflakeの消費量ベースの価格設定モデルとオブジェクトのタグ付けを活用してコストを配分し、部門ごとのSnowflakeの使用状況を追跡します。
フェーズ3:データベースコード変換¶
このフェーズでは、Databricksデータベースコード( DDL 、 SQL 、Sparkコード)をSnowflake互換の SQL とSnowparkに変換することに焦点を当てます。
行動可能なステップ:
Databricks Sparkデータ型をSnowflakeデータ型にマッピングする:
Databricks(Spark)データ型を慎重に特定し、最も適切なSnowflakeの同等物にマッピングします。複雑な型(たとえば、 TimestampType から TIMESTAMP_NTZ 、 TIMESTAMP_LTZ 、または TIMESTAMP_TZ )の精度、スケール、タイムゾーンの扱いに細心の注意を払ってください。
ByteType はSnowflakeの INTEGER にマッピングされ、 LongType (64ビット)は INTEGER (32ビット)にマッピングされる際に、切り捨てを防ぐために範囲チェックが必要になる場合があることに注意してください。
ArrayType および MapType は通常、Snowflakeの VARIANT データ型にマッピングされます。
テーブルとビューのデータ定義言語( DDL )を翻訳する:
Databricks環境から既存の DDL スクリプト(通常はDelta Lakeテーブル)を抽出します。
抽出された DDL を Snowflakeの SQL 方言との完全な互換性のために調整し、Databricks固有の機能(Delta Lakeテーブルプロパティ、クラスタリングキー以外の特定のパーティショニングスキームなど)を削除または再設計します。
論理的な分離とアクセス制御を強化するために、大規模なスキーマを複数のSnowflakeデータベースまたはスキーマに分割するなど、スキーマの再編成を検討します。
Databricks SQL およびSpark CodeをSnowflake SQL およびSnowparkに変換する:
Databricks SQL からSnowflake SQL: Snowconvert AI は、Spark SQL および Databricks SQL の評価と、 TABLES および VIEWS の翻訳をサポートするようになりました。
Spark Code( PySpark/Scala)からSnowpark: Databricksノートブックおよびジョブの PySpark またはScalaコードをSnowflakeのSnowpark API (Python、Java、Scala)に変換します。Snowpark DataFrames は、Spark DataFrames と同様の機能(filter、select、join、groupBy、agg)を提供し、Snowflake内のデータに直接処理ロジックをもたらすことを目的としています。
ユーザー定義関数( UDFs ): Databricks UDFs (Python、Scala)を Snowflake UDFs ( SQL 、 JavaScript 、Python、Java、Scala)として再実装します。複雑なSpark UDFs では、Snowparkを効果的に活用するために大幅な再設計が必要になる場合があります。
オーケストレーションロジック: StreamsやTasksなどのネイティブ機能を使用して、Databricks Jobs、Workflows、Delta Live Tables( DLT )のオーケストレーションロジックをSnowflakeに再設計および再実装し、増分変換やスケジューリングを実現します。あるいは、外部のオーケストレーター(Airflowなど)をSnowflakeに再指定し、埋め込まれたDatabricks固有のコードを書き換えます。
フェーズ4:データ移行¶
データ移行とは、既存のデータセットをDatabricks環境からSnowflakeに移行するプロセスです。このフェーズでは通常、過去データの一括転送と、継続的な増分データの取り込みの両方が行われます。
行動可能なステップ:
Databricksからデータを抽出する:
Delta Lakeテーブルの場合、Apache Sparkを使用してマニフェストファイルを生成します。このファイルは、Snowflakeが直接読み取ることができる基盤となるParquetデータファイルを指します。
大規模なテーブルの場合は、効率的な並列処理のためにデータのエクスポートをパーティション分割します。
DatabricksのネイティブSnowflakeコネクタを活用して、Databricksからデータを直接読み取り、Snowflakeのステージング領域としてクラウドストレージ(AWS S3、Azure Blob Storageなど)に書き込みます。
Snowflakeで系統と制御を維持するために、取り込み時刻を示すタイムスタンプ列とソースシステム名列を追加します。
Snowflakeにデータをロードする:
外部ステージ(クラウドストレージの場所)からSnowflakeのテーブルにデータを一括ロードするには、Snowflakeの COPY INTO コマンドを使用します。
Parquetファイルで最適なパフォーマンスを得るには、Snowflakeのベクトル化スキャナーを使用します( COPY コマンドで USE_VECTORIZED_SCANNER を設定するか、将来的にはデフォルトになる予定です)。
ロードのベストプラクティス:
ファイルサイズの最適化: 最適なスループットを得るために、圧縮(例: Parquetの場合はSnappy)を使って100~ 250MB の範囲でファイルを作成します。
ステージングされたファイルのパージ: COPY コマンドで PURGE=TRUE を使用すると、ロード成功後にステージからファイルが削除され、パフォーマンスを最適化し、ストレージコストを管理できます。
エラー処理: 不良データが含まれる可能性のある大容量ファイルの場合、 COPY コマンドで ON_ERROR='CONTINUE' を使用すると、問題のある行を無視して正常なデータをロードできます。
内部ステージ: 外部ステージと比較してロード速度が速い、Snowflakeの内部ステージの使用を検討してください。ただし、ストレージコストも考慮してください。
増分データロードの場合は、Change Data Capture( CDC )パイプラインを実装し、DatabricksからSnowflakeに新しいデータや変更されたデータを複製します。FivetranやMatillionのようなツールは、これらの同期を自動化できます。
フェーズ5:データの取り込み¶
このフェーズでは、継続的なデータ取り込みプロセスと ETL/ELT パイプラインをDatabricksからSnowflakeに移行し、ライブデータの継続的なフローを確保することに重点を置きます。
行動可能なステップ:
Databricks ETL/ELT ワークフローを再設計する:
Databricks ETL/ELT ワークフロー(多くの場合、 PySpark 、Scala、または SQL とDelta Live Tables( DLT )またはDatabricks Jobsを使用して構築されます)をSnowflake用に再設計します。
複雑な ETL/ELT の場合は、SparkコードをSnowpark DataFrames および UDFs に変換します(フェーズ1で説明)。SQL ベースの変換については、Snowflake内で変換を行うためのdbt(データ構築ツール)の使用を検討してください。
Snowflakeネイティブ機能を活用する:
StreamsとTasks: Streamsを使用して DML の変更を記録し、増分処理を行います。また、Tasksを使用して SQL ステートメントまたはストアドプロシージャをスケジュールし、Snowflake内で直接増分変換とオーケストレーションを行います。
Snowpipe: 新しいデータをリアルタイムで継続的にロードするには、トリクルフィードにSnowpipeを使用します。バッチロードには、 COPY コマンドが依然として強力なオプションです。
Snowpipe Streaming: 低レイテンシのストリーミングユースケースに最適です。
データソースとシンクを再調整する:
コネクタまたはカスタム取り込みプロセスをSnowflakeステージまたはテーブルを直接指すように構成することで、現在Databricksに着信している複数のインバウンドデータソースをSnowflake取り込みパターンにリダイレクトします。
データパイプラインが安定し、データの検証が完了したら、現在Databricksから読み込んでいる下流システム(例: BI ツール、その他のアプリケーション)をSnowflakeに再指定する計画を立てます。
フェーズ6:レポートと分析の移行¶
このフェーズでは、ビジネスインテリジェンス( BI )および分析ツールが、新しいデータソースとしてSnowflakeを使用しても引き続き正しく最適に機能することの確認に重点を置きます。
行動可能なステップ:
** BI ツールとカスタムクエリの調整:**
既存のレポートツール(Tableau、Power BI 、Lookerなど)を再ポイントまたはリファクタリングし、以前Databricksに対して実行したカスタムクエリを調整します。
Snowflakeの要件に合わせて、データベースに送信される SQL クエリを調整します。要件は、単純な名前の変更から、より複雑な構文やセマンティクスの違いまで多岐にわたります。
ビジネスユーザーを巻き込み、トレーニングを提供する:
ビジネスユーザーを、移行プロセスにおける主要な利害関係者として含めます(計画段階の RACI マトリックスなど)。レガシープラットフォームからの完全な移行には、彼らの理解が不可欠です。
ビジネスユーザーにSnowflakeの操作方法をトレーニングし、プラットフォームの違いを明確に理解してもらいます。これにより、必要に応じてカスタムクエリやレポートを変更することができるようになります。
ビジネスユーザー向けの並行トレーニングコースの後に、ユーザーがプラットフォームの違いに対応して必要な調整を行うための支援を行う、移行のエキスパートによる相談時間を設けることを検討してください。
フェーズ7:データ検証とテスト¶
データ検証とテストは、移行計画プロセスでは軽視されがちなステップですが、新しいSnowflake環境でデータの整合性と正確性を確保するためには不可欠です。このフェーズに入る前に、データを可能な限りクリーンにしておくことが目標です。
行動可能なステップ:
包括的なテスト戦略を実施する: どの組織にも、実稼働環境にデータを移行するための独自のテスト方法論と要件があり、プロジェクトの開始時点からそれらを十分に理解しておく必要があります。
機能テスト: 移行されたすべてのアプリケーションと機能が新しい環境内で期待どおりに動作することを確認し、データの整合性と正確性を確保します。これには、移行された ETLs とレポートが正しい結果を出すかどうかの確認も含まれます。
パフォーマンステスト: クエリのパフォーマンス、データのロード速度、システム全体の応答性を評価します。これにより、Snowflakeのパフォーマンスボトルネックを特定して対処し、新しいプラットフォームが期待どおりのパフォーマンス、またはそれを上回るパフォーマンスを実現できるようになります。
ユーザー受け入れテスト( UAT ): テストプロセスにエンドユーザーを参加させ、移行されたシステムがエンドユーザーのビジネス要件を満たしていることを確認し、フィードバックを集めて改善の余地を確認します。これは、ユーザーの信頼と採用を獲得するために不可欠です。
データ検証技術: 行数の比較、列の合計、最大値、最小値、平均値の計算、行値のハッシュ化を行い、ソースシステム(Databricks)とターゲットシステム(Snowflake)間の1対1の関連付けを行います。並列システムを一定期間稼働させることで、リアルタイムの比較が可能になります。
トレーニングとドキュメンテーションを提供する:
Snowflakeの特徴、機能、ベストプラクティスについてエンドユーザーに包括的なトレーニングを提供します。データアクセス、クエリの最適化、セキュリティなどのトピックを扱います。
システムアーキテクチャ図、データフロー図、操作手順、ユーザーガイド、トラブルシューティングガイド、 FAQs などを含め、参照しやすい包括的なドキュメントを作成し、継続的なサポートを提供します。
フェーズ8:デプロイ - 実稼働環境への導入¶
この段階では、実稼働環境への最終的な昇格前に重要な検討を行い、スムーズで調整された移行を実現します。
行動可能なステップ:
段階的なロールアウトとブリッジ戦略を計画する:
理想的には、レガシーアプリケーションを1つずつ移行し、同じ順番で本番環境に昇格します。
ビジネスユーザーがSnowflakeと従前のDatabricksシステムの両方を照会する必要がないように、ブリッジング戦略を確実に実施します。まだ移行されていないアプリケーションのデータ同期は、このメカニズムを通じて舞台裏で行われる必要があります。
利害関係者の合意と正式な承認を得る:
カットオーバーの準備ができたら、すべての利害関係者が足並みを揃え、レガシーのDatabricksプラットフォームではなく、Snowflakeが記録システムになることを理解するようにします。
作業を進める前に、すべての利害関係者から最終的かつ正式な承認を得ます。
移行されなかったレポートはビジネスユーザーの責任となること、また、早期のユーザー参加が重要であることを強調します。
Active Directoryベースのロールを含め、すべての権限がSnowflakeで適切に付与されていることを確認します。
カットオーバーに関する重要な考慮事項に対処する:
代理キー: 代理キーを使用する場合、そのライフサイクルはレガシーシステムとSnowflakeシステムで異なる可能性があることに注意してください。これらのキーはカットオーバー時に同期する必要があります。
カットオーバーのタイミング: ビジネスへの影響を最小限に抑えるため、業種に基づいて最適なカットオーバーのタイミングを検討します。
レガシープラットフォームの廃止: レガシープラットフォームのライセンスとデータ保持ポリシーを考慮し、レガシーのDatabricks環境の廃止を計画します。
フェーズ9:最適化と実行 - 継続的な改善¶
システムがSnowflakeに移行されると、通常のメンテナンスモードに入ります。「最適化と実行」と呼ばれるこのフェーズは、移行そのものには含まれませんが、継続的な最適化と改善に重点を置きます。
行動可能なステップ:
継続的な最適化とコスト管理に注力する:
チームはSnowflakeのシステムを完全に管理し、使用パターンに基づいて最適化を進めます。
Snowflakeのジョブは一般的に高速に実行されますが、パフォーマンスが期待どおりでない場合、Snowflake独自のアーキテクチャを十分に活用するために最適化が必要になることがあります。
Snowflakeのクエリ分析ツールを活用して、ボトルネックを特定し、ワークフローの特定の部分を最適化します。
移行中は重要なパフォーマンス問題のみに対処し、より広範な最適化は移行後の取り組みとして扱います。
継続的なコスト管理を実施する:
Snowflakeは、再開ごとに最低60秒の稼働時間を設け、ウェアハウスの実行時間ごとに課金するため、仮想ウェアハウスの自動一時停止タイムアウトを60秒に設定することでコストを大幅に削減します。
コンピューティングリソースとコストはウェアハウスのサイズに応じて指数関数的に増加するため、ワークロード要件に基づいて仮想ウェアハウスのサイズを縮小します。
使用パターンを継続的に監視し、財務部門と連携して各部門の使用状況を追跡し、コスト配分を行います。
ガバナンスとセキュリティを強化する:
ロールベースのアクセス制御を改良し、機密データの動的データマスキングと行アクセスポリシーを実装し、アクセスパターンを定期的に監査します。
アクセスモデルを再考し、ユーザーの階層を整理して、必要なユーザーのみが特定のリソースにアクセスできるようにします。