Leitfaden zur Migration von Databricks zu Snowflake¶
Snowflake-Migrationsframework¶
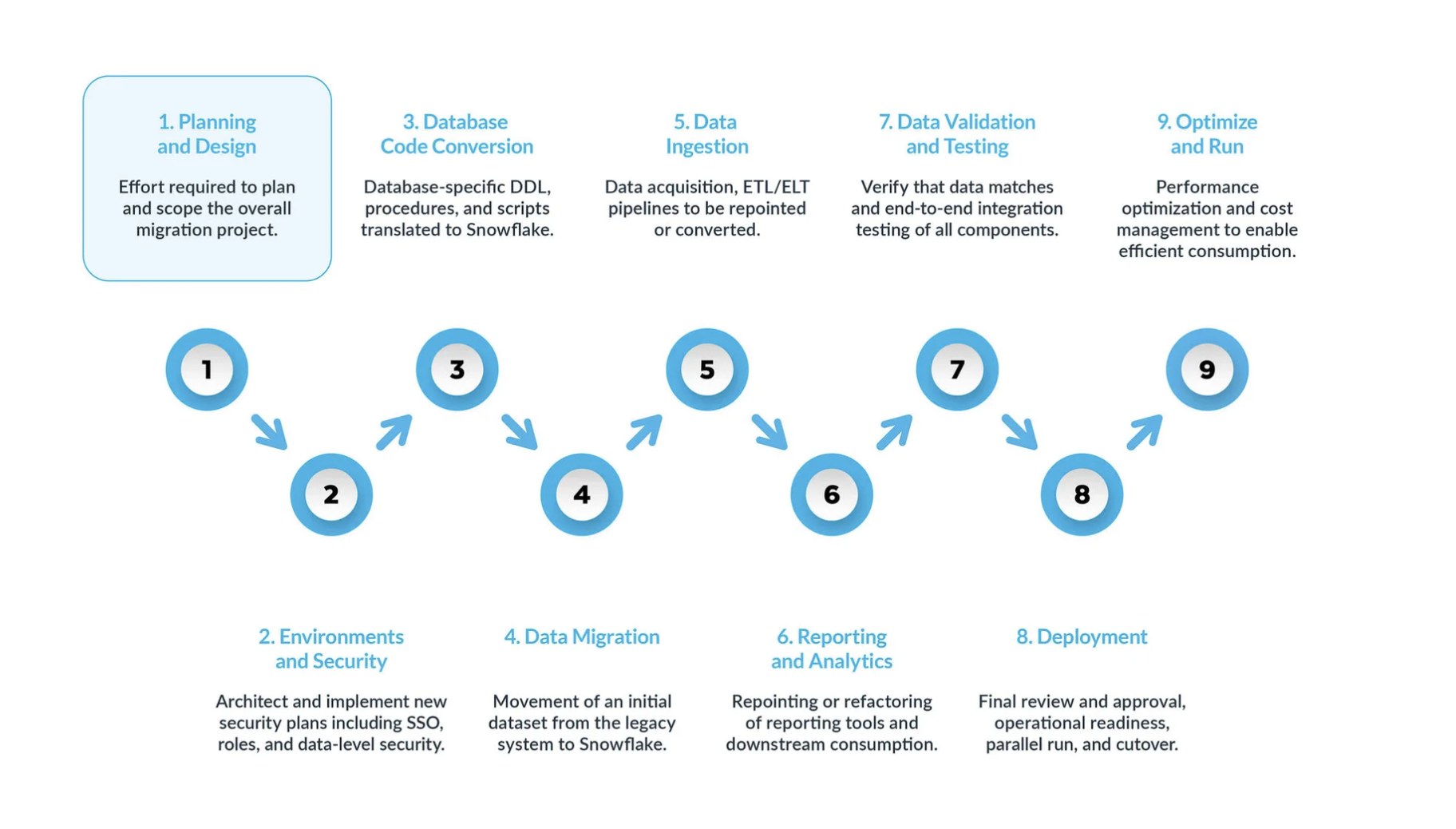
Eine typische Databricks-zu-Snowflake-Migration kann in fünf Hauptschritte unterteilt werden:
Planung und Entwurf sind oft übersehene Schritte im Migrationsprozess. Der Hauptgrund ist, dass Unternehmen in der Regel schnell Fortschritte zeigen möchten, auch wenn sie den Umfang des Projekts nicht vollständig verstanden haben. Daher ist diese Phase entscheidend, um das Migrationsprojekt zu verstehen und zu priorisieren.
Umgebung und Sicherheit – mit einem Plan, einem klaren Zeitplan, einer RACI-Matrix und der Zustimmung aller Beteiligten ist es nun an der Zeit, in die Umsetzungsphase überzugehen. Die Einrichtung der erforderlichen Umgebungen und Sicherheitsmaßnahmen vor Beginn der Migrationsphase ist äußerst wichtig, da viele Komponenten ineinandergreifen. Das Migrationsprojekt wird deutlich erfolgreicher verlaufen, wenn alle Vorbereitungen abgeschlossen sind, bevor es weitergeht.
Bei der Datenbankcode-Konvertierung wird Code direkt aus dem Datenbankkatalog des Quellsystems extrahiert, wie z. B. Tabellendefinitionen, Ansichten, gespeicherte Prozeduren und Funktionen. Sobald Sie diesen Code extrahiert haben, migrieren Sie diesen Code in entsprechende Datendefinitionssprachen (DDLs) in Snowflake. Dieser Schritt umfasst auch die Migration von Data Manipulation Language (DML)-Skripten, die von Business-Analysten zur Erstellung von Berichten oder Dashboards verwendet werden können. Der gesamte Code muss migriert und angepasst werden, damit er in Snowflake funktioniert. Die Anpassungen können von einfachen Änderungen, wie Namenskonventionen und Zuordnungen von Datentypen, bis hin zu komplexeren Unterschieden in der Syntax, der Semantik der Plattformen und anderen Faktoren reichen. Um dies zu unterstützen, bietet Snowflake eine leistungsstarke Lösung namens SnowConvert AI, die einen großen Teil des Konvertierungsprozesses von Datenbankcode automatisiert.
Datenmigration Bei der Datenmigration werden Daten zwischen verschiedenen Speichersystemen, Formaten oder Computersystemen übertragen. Im Zusammenhang mit einer Migration von Databricks nach Snowflake bezieht sich der Begriff speziell auf das Verschieben von Daten aus Ihrer Databricks-Umgebung in Ihre neue Snowflake-Umgebung.
Es gibt zwei Haupttypen, die in diesem Leitfaden behandelt werden:
Migration historischer Daten: Erstellen eines Snapshots von Databricks-Daten zu einem bestimmten Zeitpunkt und Übertragen dieser Daten auf Snowflake. Dies erfolgt oft als erste Massenübertragung.
Inkrementelle Datenmigration: Laufende Übertragung neuer oder geänderter Daten von Databricks nach Snowflake nach der anfänglichen historischen Migration. Dadurch wird sichergestellt, dass Ihre Snowflake-Umgebung mit Ihren Quellsystemen auf dem neuesten Stand bleibt.
Datenaufnahme: Nach der Migration der historischen Daten besteht der nächste Schritt in der Migration des Datenaufnahmeprozesses, bei dem Live-Daten aus verschiedenen Quellen eingelesen werden. Typischerweise folgt dieser Prozess einem Extract, Transform, Load (ETL)- oder Extract, Load, Transform (ELT)-Modell – je nachdem, wann und wo die Datenumwandlung erfolgt, bevor die Daten den Business-Usern zur Verfügung stehen.
Berichterstellung und Analysen: Da die Datenbank nun sowohl historische Daten als auch laufende Pipelines enthält, die kontinuierlich neue Daten importieren, besteht der nächste Schritt darin, aus diesen Daten durch BI Wert zu schöpfen. Die Berichterstellung kann mit Standard-BI-Tools oder benutzerdefinierten Abfragen erfolgen. In beiden Fällen muss das an die Datenbank gesendete SQL möglicherweise angepasst werden, um den Anforderungen von Snowflake zu entsprechen. Diese Anpassung kann von einfachen Namensänderungen (häufig während der Migration) bis hin zur Syntax und komplexeren semantischen Unterschieden reichen. Sie alle müssen identifiziert und erledigt werden.
Datenvalidierung und -tests: Das Ziel besteht darin, die Daten so sauber wie möglich zu haben, bevor diese Phase beginnt. Jedes Unternehmen hat seine eigenen Testmethoden und Anforderungen, um Daten in die Produktion zu verschieben. Diese müssen von Beginn des Projekts an vollständig verstanden werden.
Bereitstellung. In dieser Phase werden die Daten validiert, ein entsprechendes System eingerichtet, alle ETLs wurden migriert und die Berichte wurden verifiziert. Sind Sie bereit, live zu gehen? Nicht so schnell – es gibt noch einige kritische Überlegungen, bevor es endgültig in die Produktion gehen kann. Erstens kann Ihre Legacy-Anwendung aus mehreren Komponenten oder Services bestehen. Idealerweise sollten Sie diese Anwendungen eine nach der anderen migrieren (obwohl eine parallele Migration möglich ist) und sie in der gleichen Reihenfolge in die Produktion überführen. Stellen Sie während dieses Prozesses sicher, dass Ihre Bridging-Strategie implementiert ist, damit Business-User nicht sowohl Snowflake als auch das Altsystem abfragen müssen. Die Datensynchronisierung für Anwendungen, die noch nicht migriert wurden, sollte im Hintergrund durch den Bridging-Mechanismus erfolgen. Wenn dies nicht geschieht, müssen die Benutzenden in einer hybriden Umgebung arbeiten und die Auswirkungen dieses Setups verstehen.
Optimieren und ausführen – sobald ein System auf Snowflake migriert wurde, wechselt es in den normalen Wartungsmodus. Alle Softwaresysteme sind lebende Organismen, die eine laufende Wartung erfordern. Diese Phase nach der Migration wird als „Optimieren und Ausführen“ bezeichnet und ist nicht Teil der Migration selbst.
¶
Wichtige Phasen¶
Eine typische Databricks-zu-Snowflake-Migration kann in mehrere Hauptphasen unterteilt werden, die jeweils unterschiedliche Ziele und Überlegungen haben. Das Einrichten dieser Phasen trägt dazu bei, einen strukturierten und erfolgreichen Übergang zu gewährleisten.
Phase 1: Planung und Entwurf¶
Diese anfängliche Phase ist entscheidend für eine erfolgreiche Migration. Sie legt die Grundlage für die Definition des Umfangs, der Ziele und der Anforderungen Ihres Projekts. Diese Phase beinhaltet ein großes Verständnis Ihrer aktuellen Databricks-Umgebung und eine klare Vorstellung von dem zukünftigen Zustand von Snowflake.
Konkrete Schritte:¶
Führen Sie eine gründliche Bewertung Ihrer Databricks-Umgebung durch: Dabei handelt es sich um mehr als nur eine technische Bestandsliste. Es handelt sich um eine Strategie, um „technische Fehler“ zu identifizieren und Möglichkeiten zur Modernisierung und Vereinfachung des Datenbestands aufzudecken.
Inventar bestehender Datenbestände: Identifizieren und dokumentieren Sie alle Databricks-Assets sorgfältig, einschließlich Datenbanken, Tabellen (insbesondere Delta Lake-Tabellen), Ansichten, Notebooks (nach Sprachen kategorisiert: Python, Scala, SQL), Jobs, Workflows, benutzerdefinierte Funktionen (UDFs) und externe Integrationen.
Abfrage-Workloads analysieren: Nutzen Sie die Überwachungstools und Protokolle von Databricks, um häufig ausgeführte und ressourcenintensive Abfragen zu identifizieren. Diese Abfragen sind für die Validierung der Leistung nach der Migration entscheidend.
Kategorisierung von Datenbeständen: Unterscheiden Sie zwischen Produktions- und Nicht-Produktionsdaten, identifizieren Sie aktive und veraltete Objekte und identifizieren Sie alle redundanten Ressourcen, die von der Migration ausgeschlossen werden können. Dadurch wird die Menge der zu migrierenden Daten und des Codes erheblich reduziert, was Aufwand, Zeit und Kosten spart.
Sicherheits- und Compliance-Anforderungen bewerten: Identifizieren Sie sensible Daten, gesetzliche Bestimmungen (z. B GDPR, HIPAA) als auch potenzielle Schwachstellen innerhalb der bestehenden Databricks-Umgebung. Diese Informationen sind entscheidend für die Gestaltung einer robusten Sicherheitseinrichtung in Snowflake.
Genaue Migrationsziele und Erfolgskriterien definieren: Ein Übersehen der genauen Definition dieser Ziele kann „die Spielregeln verändern“ und zum Scheitern von Projekten führen.
Strategische Einflussfaktoren: Geben Sie die Geschäftsfaktoren (z. B. Kostenreduzierung, Verbesserung der BI-Leistung, vereinfachte Vorgänge, verbesserte Governance) und die technischen Ziele für die Migration zu Snowflake eindeutig an.
Messbare Erfolgskriterien festlegen: Definieren Sie quantifizierbare Kennzahlen, um den Fortschritt zu verfolgen und ROI zu demonstrieren, wie z. B. Verbesserungen der Abfrageleistung (z. B. durchschnittliche Abfragelatenz vermindert durch X %), nachweisbare Kosteneinsparungen (z. B. Reduzierung der monatlichen Cloudausgaben um Y %), messbare Verringerung von Betriebsvorfällen, höhere Werte für die Benutzerzufriedenheit und verifizierte Datengenauigkeit.
Wählen Sie Ihren Migrationsansatz: Phasenweise vs. Alles auf einmal: Die Auswahl einer Migrationsstrategie ist im Wesentlichen eine Entscheidung des Risikomanagements.
Phasenweise Migration: Bei diesem Ansatz werden Daten und Workloads in kleinere, verwaltbare Segmente verschoben (nach Themenbereich, Data Mart, Geschäftsbereich oder Anwendung). Um keine oder minimale Ausfallzeiten aufrechtzuerhalten, wird dringend empfohlen, kontinuierliches Testen, iteratives Lernen und schrittweise Verschiebevorgänge des Workloads zu ermöglichen. Dieser Ansatz erleichtert parallele Ausführungen für eine gründliche Validierung.
Alles auf einmal: Bei diesem Ansatz werden alle Daten und Workloads auf einmal migriert, gefolgt von einem sofortigen Wechsel. Dieser Ansatz ist zwar potenziell schneller für sehr einfache Systeme, birgt jedoch ein hohes Risiko für unvorhergesehene Probleme und ist im Allgemeinen weniger sicher, wenn es um die Aufrechterhaltung der Ausfallzeit geht.
Ein robustes Bereitschaftsframework für die Migration einrichten: Eine frühzeitige und kontinuierliche Einbeziehung aller Interessengruppen ist von entscheidender Bedeutung.
Eine formale Bewertung der Bereitschaft zur Migration durchführen (MRA): Beziehen Sie ein funktionsübergreifendes Team von Fachexperten (Codekonvertierung, Datenmigration, Datenaufnahme, Datenvalidierung, Berichterstellung und Analyse) und Vertretern sowohl von geschäftlicher als auch von technischer Seite ein.
Einen detaillierten Projektzeitplan und eine RACI-Matrix entwickeln: Sorgen Sie für klare Rollen und Verantwortlichkeiten bei allen Migrationsaufgaben.
Sichere explizite Nutzung: Erhalten Sie von Anfang an die Unterstützung aller wichtigen Interessensvertreter, einschließlich der Führungskräfte und Benutzenden. Eine technisch korrekte Migration kann immer noch fehlschlagen, wenn die Benutzenden nicht ausreichend vorbereitet, geschult oder eingebunden sind.
Phase 2: Umgebung und Sicherheit¶
Die Einrichtung der notwendigen Umgebungen und Sicherheitsmaßnahmen ist ein entscheidender früher Schritt, bevor Sie mit der Migration beginnen. Snowflake arbeitet nach einem gemeinsamen Sicherheitsmodell zwischen der Plattform und Administratoren.
Konkrete Schritte:
Umgebungen einrichten: Entscheiden Sie sich für die Anzahl der benötigten Snowflake-Konten. Richten Sie mindestens eine Produktions- und Entwicklungsumgebung ein. Ziehen Sie auf der Grundlage Ihrer Strategie zusätzliche Umgebungen für verschiedene Testphasen in Betracht.
Sicherheitsmaßnahmen implementieren:
Beginnen Sie mit Netzwerkrichtlinien, um sicherzustellen, dass nur autorisierte Benutzende innerhalb Ihres VPN auf das Snowflake-System Zugriff erhalten.
Definieren Sie Rollen auf der Grundlage von Geschäftsanforderungen, da die Benutzerzugriffssteuerung von Snowflake rollenbasiert ist.
Erstellen Sie die Benutzerkonten, und erzwingen Sie die mehrstufige Authentifizierung (MFA) und/oder Single Sign-On (SSO) für alle Benutzenden.
Richten Sie Dienstkonten ein, ohne sich auf die herkömmliche Authentifizierung mit Benutzername und Kennwort zu verlassen.
Rollen während der Migration definieren: Definieren Sie bestimmte Rollen für Ihr Migrationsteam. Auch in nicht produktiven Umgebungen, in denen das Team möglicherweise mehr Freiheit hat, sollten Sie daran denken, dass Sie es mit echten Daten zu tun haben. Sorgen Sie also für eine robuste Sicherheit.
Das Zugriffsmodell überdenken: Verwenden Sie diese Migration, um Ihre Zugriffshierarchie zu bereinigen und zu optimieren und sicherzustellen, dass nur die erforderlichen Benutzenden Zugriff auf bestimmte Ressourcen haben.
Koordination mit der Finanzabteilung: Stimmen Sie sich mit Ihrem Finanzteam ab, um zu verfolgen, welche Abteilungen Snowflake nutzen, wobei Sie das verbrauchsabhängige Preismodell von Snowflake und das Objekt-Tagging für die Kostenzuordnung verwenden.
Phase 3: Konvertierung von Datenbankcode¶
Diese Phase konzentriert sich auf die Konvertierung Ihres Databricks-Datenbankcodes (DDL-, SQL-, Spark-Code) in Snowflake-kompatible SQL und Snowpark.
Konkrete Schritte:
Databricks Spark-Datentypen zu Snowflake-Datentypen zuordnen:
Sie müssen Databricks (Spark)-Datentypen sorgfältig identifizieren und ihren am besten geeigneten Snowflake-Äquivalenten zuordnen. Achten Sie besonders auf Genauigkeit, Skalierung und Zeitzonenhandhabung bei komplexen Typen (z. B TimestampType zu TIMESTAMP_NTZ, TIMESTAMP_LTZ oder TIMESTAMP_TZ).
Beachten Sie, dass ByteType der INTEGER von Snowflake und LongType (64-Bit) der INTEGER (32-Bit) zugeordnet wird. Dieser Vorgang kann Bereichsprüfungen erfordern, um ein Kürzen zu verhindern.
ArrayType und MapType werden häufig dem VARIANT-Datentyp von Snowflake zugeordnet.
Datendefinitionssprache (DDL) für Tabellen und Ansichten übersetzen:
Extrahieren Sie bestehende DDL-Skripte aus Ihrer Databricks-Umgebung, normalerweise aus Delta Lake-Tabellen.
Passen Sie die extrahierte DDL für volle Kompatibilität an den SQL-Dialekt von Snowflake an, indem Sie Databricks-spezifische Features entfernen oder umstrukturieren (z. B. Eigenschaften von Delta Lake-Tabellen, spezifische Partitionierungsschemata über Gruppierungsschlüssel hinaus).
Erwägen Sie Möglichkeiten für die Umstrukturierung von Schemata, wie z. B. die Aufteilung großer Schemata in mehrere Snowflake-Datenbanken oder Schemata für eine bessere logische Trennung und Zugriffssteuerung.
Databricks SQL- und Spark-Code zu Snowflake SQL und Snowpark konvertieren:
Databricks SQL zu Snowflake SQL: Snowconvert AI unterstützt jetzt die Bewertung und Übersetzung von Spark SQL und Databricks SQL für TABLES und VIEWS.
Spark-Code (PySpark/Scala) zu Snowpark: Konvertieren von PySpark- oder Scala-Code aus Databricks-Notebooks und -Jobs in die Snowpark API (Python, Java, Scala) von Snowflake. Snowpark-DataFrames bieten ähnliche Funktionen wie Spark DataFrames (filter, select, join, groupBy, agg), um die Verarbeitungslogik direkt auf Daten in Snowflake zu übertragen.
Benutzerdefinierte Funktionen (UDFs): Databricks UDFs (Python, Scala) werden als Snowflake UDFs (SQL, JavaScript, Python, Java, Scala) neu implementiert. Komplexe Spark UDFs können eine erhebliche Umstrukturierung erfordern, um Snowpark effektiv zu nutzen.
Orchestrierungslogik: Entwerfen Sie die Orchestrierungslogik von Databricks-Jobs, -Workflows und Delta-Live-Tabellen (DLT) in Snowflake neu, und implementieren Sie diese erneut unter Verwendung nativer Features wie Streams und Aufgaben für inkrementelle Transformationen und Zeitplanung. Alternativ können Sie externe Orchestratoren (z. B. Airflow) wieder auf Snowflake verweisen und den eingebetteten Databricks-spezifischen Code neu schreiben.
Phase 4: Datenmigration¶
Die Datenmigration ist der Prozess der Übertragung vorhandener Datensets aus der Databricks-Umgebung in Snowflake. Diese Phase umfasst in der Regel sowohl den historischen Massendatentransfer als auch die laufende inkrementelle Datenaufnahme.
Konkrete Schritte:
Daten aus Databricks extrahieren:
Für Delta Lake-Tabellen generieren Sie Manifest-Dateien mit Apache Spark, die auf die zugrunde liegenden Parquet-Datendateien verweisen, die Snowflake direkt lesen kann.
Bei großen Tabellen partitionieren Sie Datenexporte für eine effiziente Parallelverarbeitung.
Nutzen Sie den nativen Snowflake-Konnektor von Databricks, um Daten direkt aus Databricks zu lesen und in den Cloudspeicher zu schreiben (z. B. AWS S3, Azure Blob Storage) als Stagingbereich für Snowflake zu schreiben.
Fügen Sie eine Zeitstempelspalte für die Erfassungszeit und eine Spalte für den Namen des Quellsystems hinzu, um die Herkunft und Kontrolle in Snowflake zu verwalten.
Daten in Snowflake laden:
Verwenden Sie den COPY INTO-Befehl von Snowflake zum Massenladen von Daten aus externen Stagingbereichen (Cloudspeicherorten) in Snowflake-Tabellen.
Für eine optimale Leistung mit Parquet-Dateien verwenden Sie den vektorisierten Scanner von Snowflake (Einstellung USE_VECTORIZED_SCANNER im COPY-Befehl, oder erwarten Sie, dass dies in Zukunft der Standard ist).
Best Practices beim Laden:
Dateigrößenoptimierung: Erstellen Sie Dateien im Bereich von 100-250MB mit Komprimierung (z. B. Snappy für Parquet) für optimalen Durchsatz.
Löschen von Stagingdateien: Verwenden Sie PURGE=TRUE im COPY-Befehl zum Entfernen von Dateien aus dem Stagingbereich nach erfolgreichem Laden, Optimieren der Leistung und Verwalten der Speicherkosten.
Fehlerbehandlung: Verwenden Sie ON_ERROR=‘CONTINUE‘ im COPY-Befehl für große Dateien mit potenziell fehlerhaften Daten, sodass gute Daten geladen werden können, während problematische Zeilen ignoriert werden.
Interne Stagingbereiche: Ziehen Sie die Verwendung der internen Snowflake-Stagingbereiche für ein schnelleres Laden im Vergleich zu externen Stagingbereichen in Betracht, aber vergleichen Sie die Speicherkosten.
Für das inkrementelle Laden von Daten implementieren Sie Change Data Capture (CDC)-Pipelines, um neue oder geänderte Daten von Databricks in Snowflake zu replizieren. Tools wie Fivetran oder Matillion können diese Synchronisierungen automatisieren.
Phase 5: Datenaufnahme¶
Diese Phase konzentriert sich auf die Migration der laufenden Datenaufnahmeprozesse und ETL/ELT-Pipelines von Databricks zu Snowflake und gewährleistet so einen kontinuierlichen Fluss von Live-Daten.
Konkrete Schritte:
Databricks ETL/ELT-Workflows neu überarbeiten:
Überarbeiten Sie Databricks ETL/ELT-Workflows (oft erstellt mit PySpark, Scala oder SQL mit Delta Live-Tabellen (DLT) oder Databricks-Jobs) für Snowflake neu.
Konvertieren Sie bei komplexen ETL/ELT Spark-Code in Snowpark DataFrames und UDFs (wie in Phase 1 beschrieben). Für SQL-basierte Transformationen sollte dbt (Datenerstellungstool) für Transformationen innerhalb von Snowflake in Betracht gezogen werden.
Native Snowflake-Features nutzen:
Streams und Aufgaben: Verwenden Sie Streams zum Aufzeichnen von DML-Änderungen für die inkrementelle Verarbeitung und Aufgaben zum Planen von SQL-Anweisungen oder gespeicherte Prozeduren für inkrementelle Transformationen und die Orchestrierung direkt innerhalb von Snowflake.
Snowpipe: Für ein kontinuierliches Laden neuer Daten in Echtzeit verwenden Sie Snowpipe für Trickle-Feeds. Für das Laden von Batches bleibt der COPY-Befehl eine leistungsstarke Option.
Snowpipe Streaming: Ideal für Streaming-Anwendungsfälle mit niedriger Latenz.
Datenquellen und -senken neu ausrichten:
Leiten Sie mehrere eingehende Datenquellen, die derzeit in Databricks eingehen, auf Snowflake-Datenaufnahmemuster um, indem Sie Konnektoren oder kundenspezifische Datenaufnahmeprozesse so konfigurieren, dass sie direkt auf Snowflake-Stagingbereiche oder -Tabellen verweisen.
Entwickeln Sie einen Plan, um nachgelagerte Systeme neu zu positionieren (z. B. BI-Tools, andere Anwendungen), die derzeit von Databricks in Snowflake lesen, sobald sich die Datenpipelines stabilisiert haben und die Datenvalidierung abgeschlossen ist.
Phase 6: Umstellung von Berichterstellung und Analyse¶
Diese Phase konzentriert sich darauf, sicherzustellen, dass Business Intelligence (BI) und Analysetools mit Snowflake als neuer Datenquelle weiterhin korrekt und optimal funktionieren.
Konkrete Schritte:
BI-Tools und kundenspezifische Abfragen anpassen:
Positionieren oder überarbeiten Sie bestehende Berichtstools (z. B. Tableau, Power BI, Looker), und passen Sie kundenspezifische Abfragen an, die zuvor für Databricks ausgeführt wurden.
Passen Sie SQL-Abfragen an, die an die Datenbank gesendet werden, um den Anforderungen von Snowflake zu entsprechen und die von einfachen Namensänderungen bis hin zu komplexeren Syntax- und semantischen Unterschieden reichen können.
Geschäftskunden und Anbieter von Schulungen einbeziehen:
Beziehen Sie Geschäftskunden als wichtige Interessengruppen in den Migrationsprozess ein (z. B. in der RACI-Matrix bei der Planung). Deren Akzeptanz ist entscheidend für einen vollständigen Umstieg weg von der alten Plattform.
Informieren Sie die Geschäftskunden über die Funktionsweise von Snowflake, und stellen Sie sicher, dass sie die Unterschiede der Plattform genau verstehen. Auf diese Weise können sie ihre kundenspezifischen Abfragen und Berichte bei Bedarf ändern.
Erwägen Sie die Einrichtung eines parallelen Schulungspfads für Geschäftskunden, gefolgt von offenen Sprechstunden mit Migrationsexperten, die dabei helfen, Plattformunterschiede zu erklären und die Benutzenden bei den notwendigen Anpassungen zu unterstützen.
Phase 7: Datenvalidierung und Testen¶
Datenvalidierung und Testen sind oft unterschätzte Schritte bei der Migrationsplanung, aber sie sind entscheidend, um die Datenintegration und -genauigkeit in der neuen Snowflake-Umgebung sicherzustellen. Das Ziel besteht darin, die Daten so sauber wie möglich zu haben, bevor diese Phase beginnt.
Konkrete Schritte:
Umfassende Teststrategien durchführen: Jede Organisation hat ihre eigenen Testmethoden und Anforderungen für das Verschieben von Daten in die Produktion, die von Beginn des Projekts an vollständig verstanden werden müssen.
Funktionstests: Überprüfen Sie, ob alle migrierten Anwendungen und Funktionalitäten in der neuen Umgebung wie erwartet funktionieren, um Datenintegration und -genauigkeit sicherzustellen. Dazu gehört auch die Überprüfung, ob migrierte ETLs und Berichte korrekte Ergebnisse liefern.
Performance-Tests: Bewerten Sie die Abfrage-Performance, die Geschwindigkeit beim Laden von Daten und die allgemeine Reaktionsfähigkeit des Systems. Dies hilft dabei, Leistungsengpässe in Snowflake zu erkennen und zu beheben, um sicherzustellen, dass die neue Plattform die Leistungserwartungen erfüllt oder übertrifft.
Benutzeraktualisierungstests (UAT): Beziehen Sie Endbenutzer in den Testprozess ein, um sicherzustellen, dass das migrierte System deren Geschäftsanforderungen entspricht, und um Feedback für mögliche Verbesserungen zu sammeln. Dies ist entscheidend, um das Vertrauen der Benutzenden und die Akzeptanz zu gewinnen.
Datenvalidierungstechniken: Vergleichen Sie die Anzahl der Zeilen, berechnen Sie Summen, Maxima, Minima und Durchschnittswerte von Spalten, und hashieren Sie Zeilenwerte für eine Eins-zu-Eins-Zuordnung zwischen Quellsystem (Databricks) und Zielsystem (Snowflake). Die Ausführung paralleler Systeme über einen bestimmten Zeitraum ermöglicht den Vergleich in Echtzeit.
Training und Dokumentation bereitstellen:
Bieten Sie umfassende Schulungen für Endbenutzende zu Features, Funktionen und Best Practices von Snowflake zu Themen wie Datenzugriff, Abfrageoptimierung und Sicherheit an.
Erstellen Sie eine umfassende Dokumentation, einschließlich Abbildungen der Systemarchitektur, Datenflussdiagramme, betriebliche Prozeduren, Benutzerhandbücher, Anleitungen zur Problembehandlung und FAQs zum einfachen Verweisen und zur kontinuierlichen Unterstützung.
Phase 8: Bereitstellung - Live gehen¶
Diese Phase umfasst kritische Überlegungen vor der endgültigen Produktion, um einen reibungslosen und koordinierten Übergang zu gewährleisten.
Konkrete Schritte:
Phasenweise Einführung und Überbrückungsstrategie planen:
Im Idealfall migrieren Sie ältere Anwendungen nacheinander, und stellen sie in der gleichen Reihenfolge in der Produktion bereit.
Stellen Sie sicher, dass eine Überbrückungsstrategie implementiert ist, damit Geschäftskunden nicht sowohl Snowflake als auch das Altsystem von Databricks abfragen müssen. Die Datensynchronisierung für Anwendungen, die noch nicht migriert wurden, sollte im Hintergrund durch diesen Mechanismus erfolgen.
Abstimmung der Interessengruppen und formale Genehmigungen sicherstellen:
Wenn Sie für die Umstellung bereit sind, stellen Sie sicher, dass alle Interessengruppen auf einer Liste abgestimmt sind und verstehen, dass Snowflake das System der Datensätze und nicht die alte Databricks-Plattform sein wird.
Sie benötigen die endgültigen und formalen Genehmigungen aller Beteiligten, bevor Sie fortfahren.
Heben Sie die Bedeutung einer frühzeitigen Einbeziehung der Benutzenden hervor, und betonen Sie, dass für alle Berichte, die nicht migriert wurden, nun die Geschäftskunden verantwortlich sind.
Überprüfen Sie, ob alle Berechtigungen in Snowflake ordnungsgemäß erteilt wurden, einschließlich aller Active Directory-basierten Rollen.
Kritische Hinweise zur Umstellung:
Ersatzschlüssel: Wenn Sie Ersatzschlüssel verwenden, müssen Sie beachten, dass sich deren Lebenszyklus zwischen älteren Systemen und Snowflake-Systemen unterscheiden kann. Diese Schlüssel müssen während der Umstellung synchronisiert werden.
Cutover-Zeitpunkt: Überlegen Sie sich den optimalen Zeitpunkt für die Umstellung auf der Grundlage Ihrer Branche, um die Auswirkungen auf das Geschäft zu minimieren.
Alte Plattform stilllegen: Planen Sie die Stilllegung der alten Databricks-Umgebung, einschließlich der Überlegungen zu älteren Plattformlizenzen und Datenaufbewahrungsrichtlinien.
Phase 9: Optimieren und Ausführen - Kontinuierliche Verbesserung¶
Sobald ein System auf Snowflake migriert wurde, wechselt es in den normalen Wartungsmodus. Diese Phase, die als „Optimieren und Ausführen“ bezeichnet wird, ist nicht Bestandteil der Migration selbst, sondern konzentriert sich auf die laufende Optimierung und die kontinuierliche Verbesserung.
Konkrete Schritte:
Auf die laufende Optimierung und das Kostenmanagement konzentrieren:
Das Team übernimmt die volle Eigentümerschaft für das System in Snowflake, wobei die Optimierung von den Nutzungsmustern abhängt.
Während Jobs in Snowflake im Allgemeinen schneller ausgeführt werden, kann eine Optimierung erforderlich sein, wenn die Leistung nicht den Erwartungen entspricht, um die einzigartige Architektur von Snowflake voll auszunutzen.
Verwenden Sie die Abfrageanalyse-Tools von Snowflake, um Engpässe zu erkennen und bestimmte Teile des Workflows zu optimieren.
Beheben Sie nur kritische Leistungsprobleme während der Migration, und betrachten Sie die umfassende Optimierung als eine Aufgabe nach der Migration.
Kontinuierliches Kostenmanagement implementieren:
Legen Sie Timeouts für die automatische Unterbrechung von virtuellen Warehouses auf 60 Sekunden fest, um die Kosten erheblich zu senken, da Snowflake Gebühren für jede Sekunde erhebt, in der ein Warehouse ausgeführt wird, mit einem Minimum von 60 Sekunden pro Fortsetzen.
Reduzieren Sie die Größe der virtuellen Warehouses auf der Grundlage der Workload-Anforderungen, da Computeressourcen und Kosten exponentiell mit der Größe des Warehouses skalieren.
Überwachen Sie kontinuierlich die Nutzungsmuster, und stimmen Sie sich mit der Finanzabteilung ab, um die Nutzung durch die Abteilungen für die Kostenzuteilung zu verfolgen.
Governance und Sicherheit verbessern:
Verfeinern Sie die rollenbasierte Zugriffssteuerung, implementieren Sie eine dynamischen Datenmaskierung und Zeilenzugriffsrichtlinien für sensible Daten, und überprüfen Sie regelmäßig die Zugriffsmuster.
Überarbeiten Sie das Zugriffsmodell, um die Hierarchie der Benutzenden zu bereinigen und sicherzustellen, dass nur die erforderlichen Benutzenden Zugriff auf bestimmte Ressourcen haben.