SnowConvert AI - Scripts - Fichiers¶
Note
Cette page de la documentation concerne uniquement Teradata.
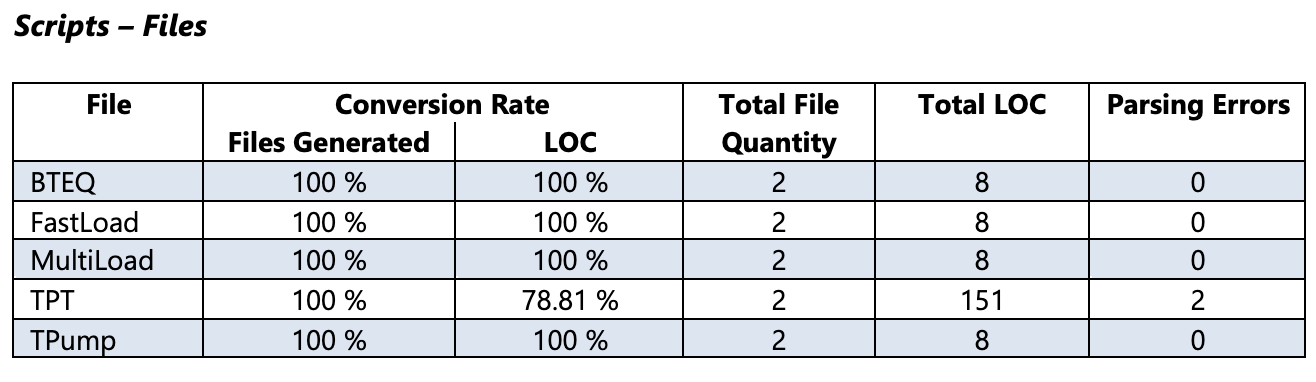
Taux de conversion - Fichiers générés¶
Indique le pourcentage de génération de fichiers groupés par extension de fichier valide (voir l’image ci-dessus).
Note
Vous trouverez de plus amples informations à ce sujet dans la section [Modes de taux de conversion de notre documentation.
Formule¶
Noms des champs CSV associés¶
Taux de conversion des fichiers BTEQ : BTEQFilesConversionRate
Taux de conversion des fichiers FastLoad : FastLoadFilesConversionRate
Taux de conversion des fichiers MultiLoad : MultiLoadFilesConversionRate
Taux de conversion des fichiers TPT : TPTFilesConversionRate
Taux de conversion des fichiers TPump : TPumpFilesConversionRate
Taux de conversion - Lignes de code (LOC)¶
Indique le pourcentage de conversion de lignes de code par extension de fichier.
Formule¶
Noms des champs CSV associés¶
Taux de conversion BTEQ LOC : BTEQLoCConversionRate
Taux de conversion FastLoad LOC : FastLoadLoCConversionRate
Taux de conversion MultiLoad LOC : MultiLoadLoCConversionRate
Taux de conversion TPT LOC : TPTLoCConversionRate
Taux de conversion TPump LOC : TPumpLoCConversionRate
Quantité totale de fichiers¶
Indique la quantité totale de fichiers de chaque type. Elle est utilisée pour calculer le taux de conversion des fichiers générés.
Noms des champs CSV associés¶
Quantité totale de fichiers BTEQ : BTEQFileCount
Quantité totale de fichiers FastLoad : FastLoadFileCount
Quantité totale de fichiers MultiLoad : MultiLoadFileCount
Quantité totale de fichiers TPT : TPTFileCount
Quantité totale de fichiers TPump : TPumpFileCount
Exemple¶
A partir de ce qui précède, nous obtiendrons :
Nombre de fichiers BTEQ : 1
Nombre de fichiers TPT : 1
Nombre total de LOC¶
Indique le nombre total de lignes de code par extension de fichier. Il est utilisé pour calculer la conversion de lignes de code.
Noms des champs CSV associés¶
Nombre total BTEQ LOC : BTEQLinesCount
Nombre total FastLoad LOC : FastLoadLinesCount
Nombre total MultiLoad LOC : MultiLoadLinesCount
Nombre total TPT LOC : TPTLinesCount
Nombre total TPump LOC : TPumpLinesCount
Indique le nombre total d’erreurs d’analyse par extension de fichier.
Noms des champs CSV associés¶
Nombre total d’erreurs d’analyse BTEQ : BTEQTotalParsingErrors
Nombre total d’erreurs d’analyse FastLoad : FastLoadTotalParsingErrors
Nombre total d’erreurs d’analyse MultiLoad : MultiLoadTotalParsingErrors
Nombre total d’erreurs d’analyse TPT : TPTTotalParsingErrors
Nombre total d’erreurs d’analyse TPump : TPumpTotalParsingErrors
Exemple¶
Explication : Dans l’exemple ci-dessus, une erreur d’analyse apparaît lors de la création de la table en raison d’une utilisation incorrecte des crochets ([]), lignes 1 et 3. Cela sera indiqué dans le rapport sous la forme d’une erreur d’analyse dans la ligne des fichiers TPT ligne de fichiers.