SnowConvert AI – Skripte – Dateien¶
Bemerkung
Diese Seite der Dokumentation gilt nur für Teradata.
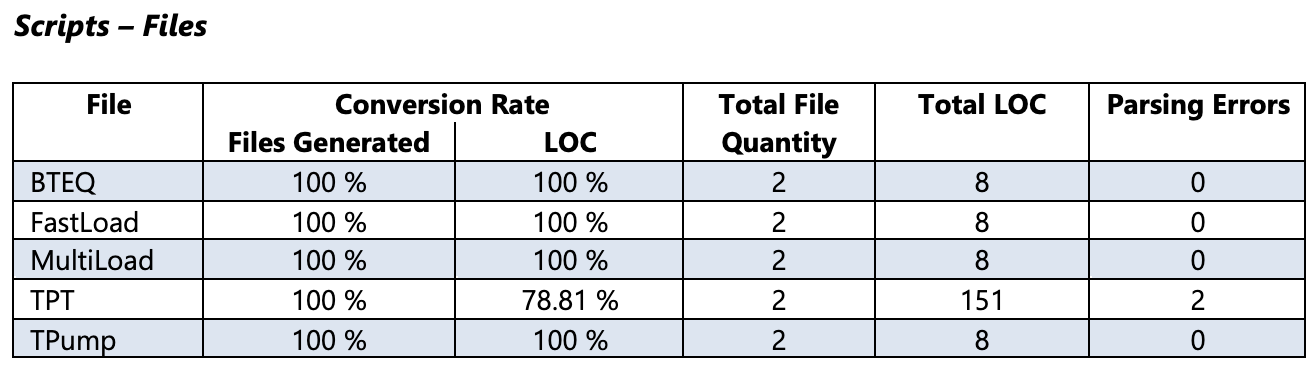
Conversion Rate - Files Generated¶
Zeigt den Prozentsatz der Dateigenerierung gruppiert nach gültiger Dateierweiterung an (siehe Abbildung oben).
Bemerkung
Weitere Informationen zu diesem Thema finden Sie im Abschnitt Modi der Konvertierungsrate in unserer Dokumentation.
Formel¶
Zugehörige CSV-Feldnamen¶
BTEQ Files Conversion Rate: BTEQFilesConversionRate
FastLoad Files Conversion Rate: FastLoadFilesConversionRate
MultiLoad Files Conversion Rate: MultiLoadFilesConversionRate
TPT Files Conversion Rate: TPTFilesConversionRate
TPump Files Conversion Rate: TPumpFilesConversionRate
Conversion Rate - LOC¶
Zeigt den prozentualen Anteil der Konvertierung von Codezeilen pro Dateierweiterung an.
Formel¶
Zugehörige CSV-Feldnamen¶
BTEQ LOC Conversion Rate: BTEQLoCConversionRate
FastLoad LOC Conversion Rate: FastLoadLoCConversionRate
MultiLoad LOC Conversion Rate: MultiLoadLoCConversionRate
TPT LOC Conversion Rate: TPTLoCConversionRate
TPump LOC Conversion Rate: TPumpLoCConversionRate
Total File Quantity¶
Zeigt die Gesamtzahl der Dateien jedes Typs an. Wird verwendet, um die Konvertierungsrate der generierten Dateien (Files Generated) zu berechnen.
Zugehörige CSV-Feldnamen¶
BTEQ Total File Quantity: BTEQFileCount
FastLoad Total File Quantity: FastLoadFileCount
MultiLoad Total File Quantity: MultiLoadFileCount
TPT Total File Quantity: TPTFileCount
TPump Total File Quantity: TPumpFileCount
Beispiel¶
Aus dem Vorhergehenden erhalten wir:
Anzahl der BTEQ-Dateien: 1
Anzahl der TPT-Dateien: 1
Total LOC¶
Zeigt die Gesamtzahl der Codezeilen pro Dateierweiterung an. Wird verwendet, um die Konvertierung der Codezeilen zu berechnen.
Zugehörige CSV-Feldnamen¶
BTEQ Total LOC: BTEQLinesCount
FastLoad Total LOC: FastLoadLinesCount
MultiLoad Total LOC: MultiLoadLinesCount
TPT Total LOC: TPTLinesCount
TPump Total LOC: TPumpLinesCount
Zeigt die Gesamtzahl der Parsing-Fehler pro Dateierweiterung an.
Zugehörige CSV-Feldnamen¶
BTEQ Total Parsing Errors: BTEQTotalParsingErrors
FastLoad Total Parsing Errors: FastLoadTotalParsingErrors
MultiLoad Total Parsing Errors: MultiLoadTotalParsingErrors
TPT Total Parsing Errors: TPTTotalParsingErrors
TPump Total Parsing Errors: TPumpTotalParsingErrors
Beispiel¶
Erläuterung: Im obigen Beispiel tritt beim Erstellen der Tabelle ein Parsing-Fehler auf, der auf die falsche Verwendung der eckigen Klammern ([]) zurückzuführen ist (Zeile 1 und 3). Dies wird im Bericht als 1 Parsing-Fehler in der Zeile der TPT-Dateien angezeigt.