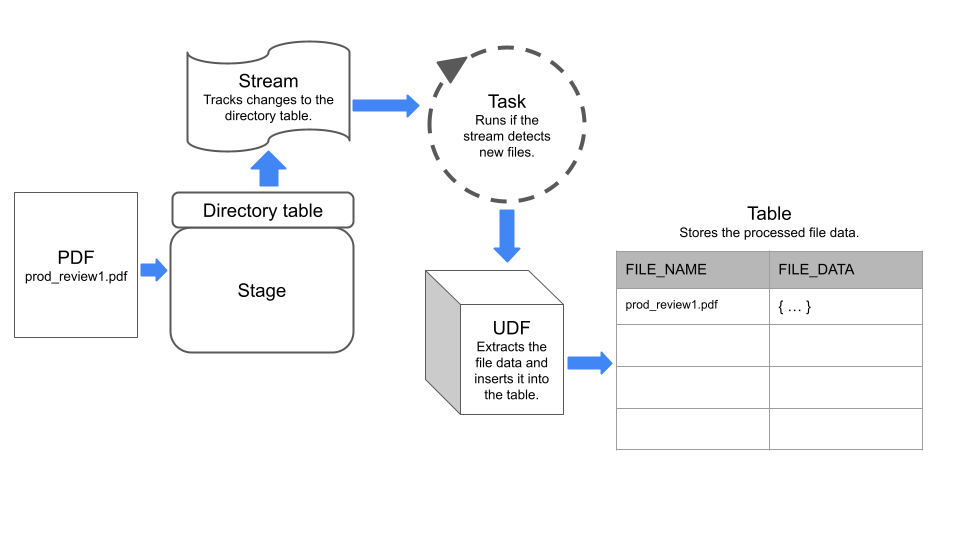
ステップ4: ファイルのコンテンツを格納するテーブルを作成する
次に、各行がステージ上のファイルに関する情報を file_name と file_data という名前の列に格納するテーブルを作成します。後のステップで作成するタスクは、このテーブルにデータをロードします。
CREATE OR REPLACE TABLE prod_reviews (
file_name varchar,
file_data variant
);
ステップ6: タスクを実行してパイプラインをテストする
パイプラインが機能することを確認するには、ステージにファイルを追加し、手動でタスクを実行し、 product_reviews テーブルをクエリします。
まず PDF ファイルを my_pdf_stage ステージに追加し、ステージをリフレッシュします。
PUT file:///my/file/path/prod_review1.pdf @my_pdf_stage AUTO_COMPRESS = FALSE;
PUT file:///my/file/path/prod_review2.pdf @my_pdf_stage AUTO_COMPRESS = FALSE;
ALTER STAGE my_pdf_stage REFRESH;
ストリームをクエリして、ステージに追加した2つのファイル PDF が記録されていることを確認できます。
SELECT * FROM my_pdf_stream;
ここで、タスクを実行して PDF ファイルを処理し、 product_reviews テーブルを更新します。
EXECUTE TASK load_new_file_data;
+----------------------------------------------------------+
| status |
|----------------------------------------------------------|
| Task LOAD_NEW_FILE_DATA is scheduled to run immediately. |
+----------------------------------------------------------+
1 Row(s) produced. Time Elapsed: 0.178s
product_reviews テーブルをクエリして、タスクが各 PDF ファイルの行を追加したことを確認します。
select * from prod_reviews;
+------------------+----------------------------------+
| FILE_NAME | FILE_DATA |
|------------------+----------------------------------|
| prod_review1.pdf | { |
| | "FirstName": "John", |
| | "LastName": "Johnson", |
| | "Middle Name": "Michael", |
| | "Product": "Tennis Shoes", |
| | "Purchase Date": "03/15/2022", |
| | "Recommend": "Yes" |
| | } |
| prod_review2.pdf | { |
| | "FirstName": "Emily", |
| | "LastName": "Smith", |
| | "Middle Name": "Ann", |
| | "Product": "Red Skateboard", |
| | "Purchase Date": "01/10/2023", |
| | "Recommend": "MayBe" |
| | } |
+------------------+----------------------------------+
最後に、 FILE_DATA 列のオブジェクトを別々の列に解析するビューを作成します。その後、ファイルのコンテンツを分析して作業するために、ビューをクエリできます。
CREATE OR REPLACE VIEW prod_review_info_v
AS
WITH file_data
AS (
SELECT
file_name
, parse_json(file_data) AS file_data
FROM prod_reviews
)
SELECT
file_name
, file_data:FirstName::varchar AS first_name
, file_data:LastName::varchar AS last_name
, file_data:"Middle Name"::varchar AS middle_name
, file_data:Product::varchar AS product
, file_data:"Purchase Date"::date AS purchase_date
, file_data:Recommend::varchar AS recommended
, build_scoped_file_url(@my_pdf_stage, file_name) AS scoped_review_url
FROM file_data;
SELECT * FROM prod_review_info_v;
+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| FILE_NAME | FIRST_NAME | LAST_NAME | MIDDLE_NAME | PRODUCT | PURCHASE_DATE | RECOMMENDED | SCOPED_REVIEW_URL |
|------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| prod_review1.pdf | John | Johnson | Michael | Tennis Shoes | 2022-03-15 | Yes | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/RZ4s%2bJLa6iHmLouHA79b94tg%2f3SDA%2bOQX01pAYo%2bl6gAxiLK8FGB%2bv8L2QSB51tWP%2fBemAbpFd%2btKfEgKibhCXN2QdMCNraOcC1uLdR7XV40JRIrB4gDYkpHxx3HpCSlKkqXeuBll%2fyZW9Dc6ZEtwF19GbnEBR9FwiUgyqWjqSf4KTmgWKv5gFCpxwqsQgofJs%2fqINOy%2bOaRPa%2b65gcnPpY2Dc1tGkJGC%2fT110Iw30cKuMGZ2HU%3d |
| prod_review2.pdf | Emily | Smith | Ann | Red Skateboard | 2023-01-10 | MayBe | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/g3glgIbGik3VOmgcnltZxVNQed8%2fSBehlXbgdZBZqS1iAEsFPd8pkUNB1DSQEHoHfHcWLsaLblAdSpPIZm7wDwaHGvbeRbLit6nvE%2be2LHOsPR1UEJrNn83o%2fZyq4kVCIgKeSfMeGH2Gmrvi82JW%2fDOyZJITgCEZzpvWGC9Rmnr1A8vux47uZj9MYjdiN2Hho3uL9ExeFVo8FUtR%2fHkdCJKIzCRidD5oP55m9p2ml2yHOkDJW50%3d |
+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+